引言
在文件压缩的时候,因为二进制的表示太占用空间,所以我们常常会用一个字符表示一串二进制数,当打开文件的时候,按照我们给定的逻辑进行解码。
假设我们 a 0 b 01 c 11 d 12
那么对于一串 1101010100011 我们就可以进行对应的压缩,这样子大大的减少了空间的利用。但是我们会面对两个问题:
第一个问题就是我们的每一个字符的对应关系是随便设计的吗?肯定不是。因为有的字符出现的多,有的字符出现的少,就拿我们的中文来说,我们有这么多的汉字,如果每个汉字对应的位数相同,那么我们很可能每个汉字都要用16位的数据,这很浪费空间,所以我们每个汉字对应的位数不同。常用的位数比较少,不常用的位数就很多。
第二个问题是我们在解码的时候,很可能解不出来,因为00011这表示的是aab呢,还是aaac呢。这个问题的出现是因为有相同的前缀和,而我们敏锐的发现,二叉树这个数据结构就是和前缀和相关的,所以我们选择用二叉树来解决这个问题
数据结构
假设一棵树有n个叶子结点,并且所有节点的度要么是0要么是2,那么度为2的结点有n-1个。
我们一个结点的权值就代表着这个结点的出现频率,所以一个结点的出现频率越大,那么就应该离根节点越近。而如何到达一个结点,从根节点出发,向左向右对应的1和0,而最后到达这个结点所经过的所有数字,就是这个结点对应的编码。
因为这n个结点全部都是叶子结点,所以不存在一个叶子节点是另一个叶子节点的前缀和。这样子就解决了这两个问题。
那么我们应该怎么构建这一棵树呢?我们先把所有的结点都当成一颗单独的树,然后每一次都选择权值最小的两个结点组成一棵树,然后生成新的结点。然后新的结点继承这两个树的权值,变成一个新的结点。这个结点的不存在父节点。然后重复这个过程。这样子就可以保证权值最小的结点在最下面,权值最大的在最上面,并且所有的目标值都是叶子结点。
遍历顺序
然后就是关键点:我们怎么构造这个数据结构。很明显,如果我们要查找一个数据,我们应该是从要查找的数据开始遍历,如果是从根节点开始遍历的话,那我们是不知道这个数据在哪里的,还有把整个数据结构全部遍历一遍,十分的浪费时间,很不友好。所以我们需要从底部向上遍历。但是我们在构建二叉树的时候,又必须要从上向下遍历。所以我们用双亲表示法加孩子表示法,这种写法一般是用数组来存储。对于具体的细节,我们代码再说
cpp
struct Node {
int w; // 权重
int father; // 父节点的下标
int lchild; // 左子节点的下标
int rchild; // 右子节点的下标
};代码
这是main()函数里,我们的a数组是存储字符,w是存储权值,而接下来我们就要通过这个创建一个哈夫曼树
cpp
int n; // 对n个字符进行编码
char a[105]; // 存字符
int w[105]; // 存权重
std::cin >> n;
getchar();
std::string line;
getline(std::cin, line);
for(int i = 0; i < line.size(); i++) {
char ch = line[i];
a[i] = ch;
}
for(int i = 0; i < n; i++) {
std::cin >> w[i];
}
// 构造哈夫曼树
HuffmanNodePtr tree = CreateHuffmanTree(w, n);哈夫曼树的构造
首先就是初始化,每个结点都是一颗树,然后通过Find()函数找到最小的两个结点,然后进行一系列的赋值。有一个细节大家注意一下,我们并没有把原来的结点因为加入了树中所以代替,而是开辟了新的空间,也就是循环从第n个开始,原因就是我们最后要找树的时候是总底部开始,你要是给代替了,从哪开始呢?
cpp
HuffmanNodePtr CreateHuffmanTree(int* w, int n) {
int m = 2 * n - 1; // 最终哈夫曼树的结点个数是2n-1个
HuffmanNodePtr tree = new HuffmanNode[m];
if(tree == nullptr) {
return nullptr;
}
for(int i = 0; i < n; i++) {
// 先把n个叶子节点,各自做一棵树,分别放到tree数组中
tree[i].w = w[i];
tree[i].father = -1; // 根节点父亲的下标是-1
tree[i].lchild = -1;
tree[i].rchild = -1;
}
int s1, s2; // 存储两个根节点最小的下标
// 合并n-1次,每次选择根节点权值最小的两颗树,合并
for(int i = n; i < m; i++) { // 这里是从0开始放,所以要减去1
// 本次合并 新添加的结点放到下表i的位置
Find(tree, i, s1, s2);
tree[i].father = -1; // 新添加的结点是根节点,所以父亲的下标是-1
tree[i].lchild = s1; // 这个顺序是随便的
tree[i].rchild = s2;
tree[i].w = tree[s1].w + tree[s2].w;
tree[s1].father = i;
tree[s2].father = i;
}
return tree;
}Find()函数的实现
这个函数首先要找到没有父节点的结点,这样子就可以保证找到我们新生成的结点,而不是已经在树里面的结点。
还有一个细节大家需要注意,就是在找第二个结点的时候,我们需要额外增加一个条件就是不等于第一个最小值,不然就不停的循环了
cpp
void Find(HuffmanNodePtr tree, int x, int& s1, int& s2) {
// 在tree[0]~tree[x]中找权值最小的结点的下标
int min;
for(int i = 0; i < x; i++) { // 先找到一个根节点
if(tree[i].father == -1) {
min = i;
break;
}
}
// 更新最小的根节点
for(int i = 0; i < x; i++) {
if(tree[i].father == -1 && tree[i].w < tree[min].w) {
min = i;
}
}
s1 = min;
// 找第二小的根节点
for(int i = 0; i < x; i++) {
if(tree[i].father == -1 && i != s1) {
min = i;
break;
}
}
// 更新最小的根节点
for(int i = 0; i < x; i++) {
if(tree[i].father == -1 && tree[i].w < tree[min].w && i != s1) {
min = i;
}
}
s2 = min;
}以上就是哈夫曼树的构建,但是我们的目标是哈夫曼编码,所以我们下一步要做的就是把这一整棵树遍历一遍,按照深度搜素的方式遍历,不到叶子节点不回头,到了叶子结点之后,从根节点开始重新遍历下一个结点。因为我们需要记录一个结点的完全路径。
然后一个问题就是我们怎么存这个路径。我们选择的是二级指针,大致长这个样子
codes (char**)
│
└──────► ┌─────────────┐
│ codes0 │ ──────► ┌─────┬─────┬─────┬─────┬──────┐
├─────────────┤ │ '1' │ '0' │ '1' │ '\0'│ ... │
│ codes1 │ ──────► ├─────┼─────┼─────┼─────┼──────┤
├─────────────┤ │ '0' │ '0' │ '\0'│ │ │
│ codes2 │ ──────► ├─────┼─────┼─────┼─────┼──────┤
├─────────────┤ │ '1' │ '1' │ '\0'│ │ │
│ codes3 │ ──────► ├─────┼─────┼─────┼─────┼──────┤
└─────────────┘ │ '0' │ '1' │ '0' │ '1' │ '\0' │
└─────┴─────┴─────┴─────┴──────┘
↑ ↑
指针数组 每个编码字符串
(大小为 n) (动态分配的 char\[\])
为什么不用char\[\]\[\]呢?
有两个原因。第一个就是浪费空间,因为为了装下每一个结点的编码,我们必须要记录开最大的数组,但是对于那些比较小的路径,根本用不到那么多的空间,所以我们选择用动态的数组,你要多少我就开多大的数组。但是我们怎么直到你要多少呢?我们用一个临时的数组tmp来先记录一下这个结点的路径,然后把这个数组用memcpy()放到我们的永久数组里面
第二个原因是我们申请的空间是在堆上面,而你char\[\]\[\]的空间是在栈上面,所以当函数结束,你辛辛苦苦搬运的数据也没有了。
对于这个过程,我们也需要强调几个点:
第一个是因为我们是从下到上去遍历的,而我们最后在main()函数里输出路径是从上向下,方向正好相反,所以我们必须要在数组里面反方向记录,从n-1的位置开始往前写入0/1,然后直到父节点变成-1,也就是遍历到根节点了。然后根据start的位置,开辟对应大小的数组,这个时候就把这个数组放进我们已经开辟好的数组里面。
最后记得删除tmp数组哦~因为这个是在堆区开辟的
cpp
char** CreateHuffmanCodes(HuffmanNodePtr tree, int n) {
// 编码过程中,临时存放编码的数组
char* tmp = new char[n]; // 编码长度最长不超过n - 1
char** codes = new char*[n]; // 必须要是放在堆上,如果放在栈上,a[][],函数结束这个数组就会被销毁
memset(codes, 0, sizeof(char*) * n);
int start; // 存放编码字符的位置
int p, pre; // p是当前的结点,pre是p结点的父亲
for(int i = 0; i < n; i++) {
start = n - 1; // 从后往前放,到时候读取的时候就是正的读了
tmp[start] = '\0';
p = i; // 第i个叶子结点,这里相当于是从下面到顶上
pre = tree[p].father;
while(pre != -1) { // 到根节点就结束了
start--;
if(p == tree[pre].lchild) {
tmp[start] = '1';
} else {
tmp[start] = '0';
}
p = pre;
pre = tree[p].father;
}
codes[i] = new char[n - start]; // 因为start的起始的位置是n-1,加1之后就是n-1-start+1
memcpy(codes[i], tmp + start, sizeof(char) * (n - start));
}
delete[] tmp;
return codes;
}最后附上测试代码:
cpp
int main() {
int n; // 对n个字符进行编码
char a[105]; // 存字符
int w[105]; // 存权重
std::cin >> n;
getchar();
std::string line;
getline(std::cin, line);
for(int i = 0; i < line.size(); i++) {
char ch = line[i];
a[i] = ch;
}
for(int i = 0; i < n; i++) {
std::cin >> w[i];
}
// 构造哈夫曼树
HuffmanNodePtr tree = CreateHuffmanTree(w, n);
// 构造哈夫曼编码,往左标记字符1,往右标记字符0
char **codes = CreateHuffmanCodes(tree, n);
for(int i = 0; i < n; i++) {
std::cout << a[i] << " " << codes[i] << std::endl;
}
return 0;
}
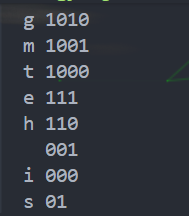
/*
9
agmteh is
1 1 1 1 2 2 3 3 5
*/
总结
哈夫曼编码使用数组来存储二叉树的,原理其实也比较简单,就是从下到上存储数据,因为每个结点之间的关系,在从上到下的时候已经设置好了。最后我们还是从上到下来去取数据的。
本篇文章到这里就结束了!!!希望大家可以对哈夫曼编码有一个更好的理解。