总目录 大模型安全研究论文整理 2026年版:https://blog.csdn.net/WhiffeYF/article/details/159047894
Active Attacks: Red-teaming LLMs via Adaptive Environments
https://openreview.net/forum?id=aWt2SkfVhq
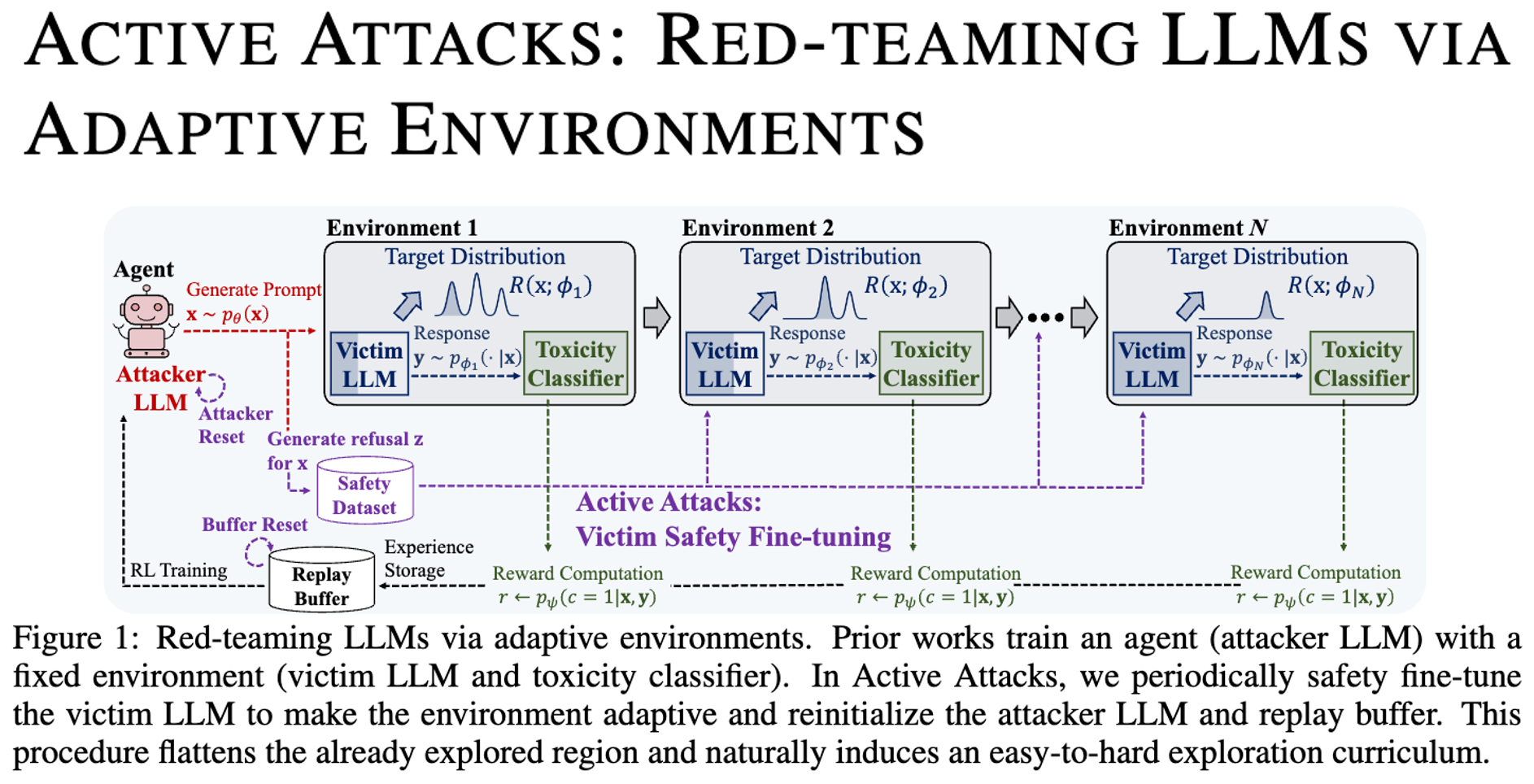
ICML 2026 | Active Attacks 提升 LLM 安全
📄 论文速递
该论文探讨了如何通过自适应环境生成多样化攻击提示词,从而提升大语言模型(LLM)的安全防御能力。以往的自动化红蓝对抗方法在发现某些高奖励的攻击模式后,往往会陷入单一模式的泥潭,难以发现更深层次、更多样化的模型漏洞。
🛠️ 方法创新
为了打破这一僵局,该论文提出了名为 Active Attacks 的创新强化学习框架。该方法的核心逻辑非常巧妙:既然攻击者总是喜欢挑软柿子捏,那我们就把软柿子变硬。该论文不再使用固定的被攻击模型,而是让环境动起来。具体而言,该论文会定期使用已收集到的攻击提示词对被攻击的 LLM 进行安全微调,这就降低了原本易受攻击区域的奖励,逼迫攻击 LLM 走出舒适区,去寻找未被发现的新漏洞。
💡 例子:
这就像一个教练在训练拳击手。如果拳击手发现对手(固定模型)左路防御弱,就会一直攻击左路,导致技能单一(模式崩溃)。但在自适应训练中,每当拳击手连续击中左路,教练就会立刻教对手补齐左路短板。拳击手为了得分,必须动脑筋去寻找对手的右路、下盘等其他未暴露的盲区。通过这种不断填补漏洞、逼迫转场的循环,拳击手最终能练出一套无死角的全方位攻击组合拳。
🔍 实验发现
该论文的实验结论令人惊喜:
- 跨方法攻击成功率实现爆发式增长,在与当前最先进的 GFlowNets 方法对抗时,跨攻击成功率从 0.07% 暴涨至 31.28%,实现了超过 400 倍的相对提升。
- 效率极高,这种自适应机制作为即插即用模块,与原有的强化学习目标结合时,仅增加了 6% 的计算开销,便换来了攻击多样性的巨大飞跃。
🚀 总结
该论文通过自适应动态防御的视角,成功构建起一种由易到难的漏洞探索范式,不仅极大拓宽了红蓝对抗的漏洞覆盖面,也为构建更安全、更鲁棒的 LLM 提供了全新的微调数据集与防御思路。