嗨~大家好,这里是春栀怡铃声的博客~
"做你害怕的事,然后发现,不过如此~"
目录
[vector 与 list比对](#vector 与 list比对)
[核心入队操作:push 与 向上调整 (AdjustUp)C++](#核心入队操作:push 与 向上调整 (AdjustUp)C++)
[核心出队操作:pop 与 向下调整 (AdjustDown)](#核心出队操作:pop 与 向下调整 (AdjustDown))
[5. 其他辅助接口C++](#5. 其他辅助接口C++)
适配器模式
适配器的作用,简单说就是:把一个"已有的东西"的接口改一改,变成"你想要的样子"。在 C++ 里,stack、queue 这类就属于容器适配器。
以 stack 为例:
vector 本来支持很多操作:
-
push_back()
-
pop_back()
-
back()
-
下标访问 \[\]
-
insert()
-
erase()
但"栈"这种数据结构只希望你用这些规则:
-
只能从栈顶放入元素
-
只能从栈顶删除元素
-
只能访问栈顶元素
所以适配器做的事就是:
-
底层仍然用 vector 存数据
-
对外不暴露 vector 的全部功能
-
只包装成栈需要的接口:push、pop、top、empty、size
也就是:
-
push() 本质调用 vector::push_back()
-
pop() 本质调用 vector::pop_back()
-
top() 本质调用 vector::back()
它的意义:
- 复用已有容器
不用自己重新写一套存储结构,直接拿 vector 来用。
- 限制接口
防止用户乱用,比如栈不应该让你随便访问中间元素。
- 突出数据结构语义
用户一看 stack 就知道这是"后进先出",而不是普通数组。
你可以把它理解成:
-
vector 是"原材料"
-
stack 适配器是"加工层"
-
最后对外提供"栈"这种更符合需求的用法
总结:
适配器的本质就是:底层复用别人的实现,表面包装成另一种更合适的接口。
类模板实例化
类模板实例化时,按需实例化,使用那些成员就实例化那些,不会全部实例化
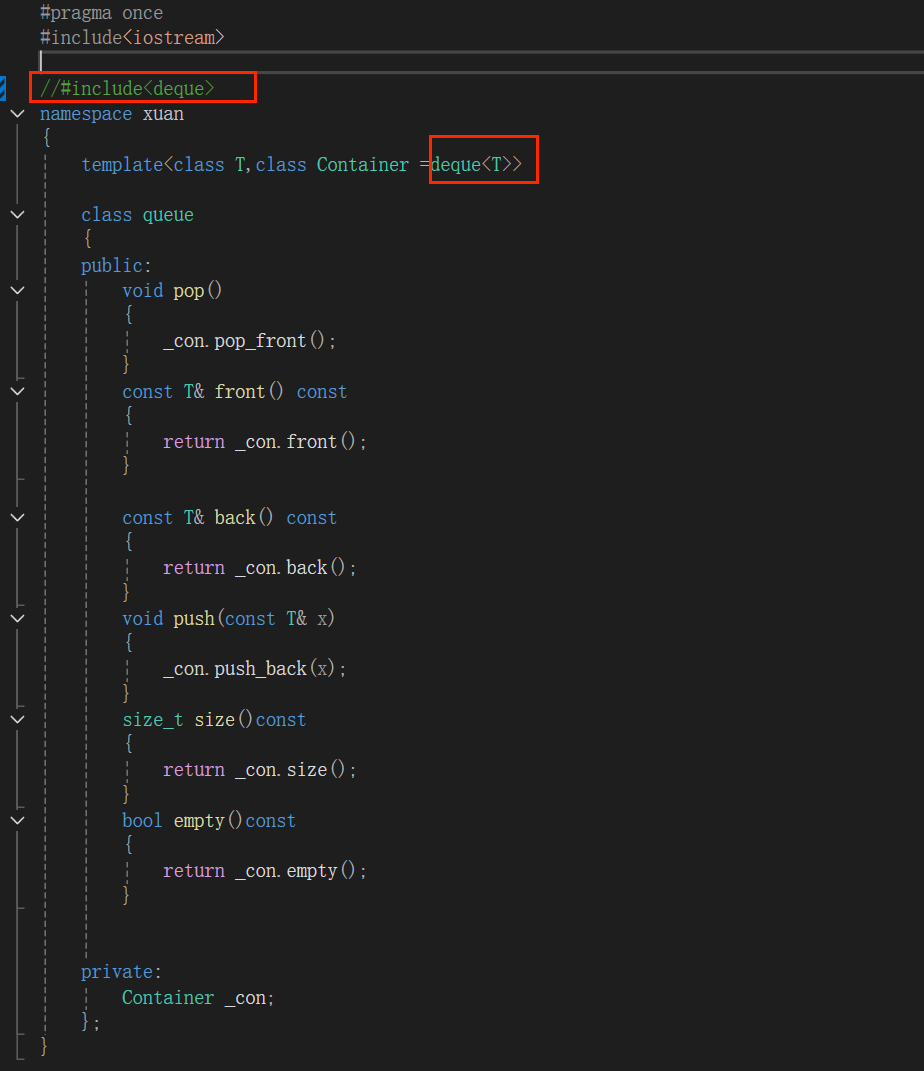
这个代码中并没有包 #include<deque> ,模板也没有报错
模板实例化(使用) 才会检查出错误
vector 与 list比对
vector 优点:支持随机访问、尾插尾删效率不错
物理空间连续,所以高速缓存利用率高
缺点:头部和中间位置 插入、删除麻烦
需要扩容,扩容会有代价(效率和空间浪费)
list 优点:任意位置插入、删除
按照需要申请空间,不需要扩容
缺点:不支持随机访问
deque
vector 和 list 缝合怪
原理图
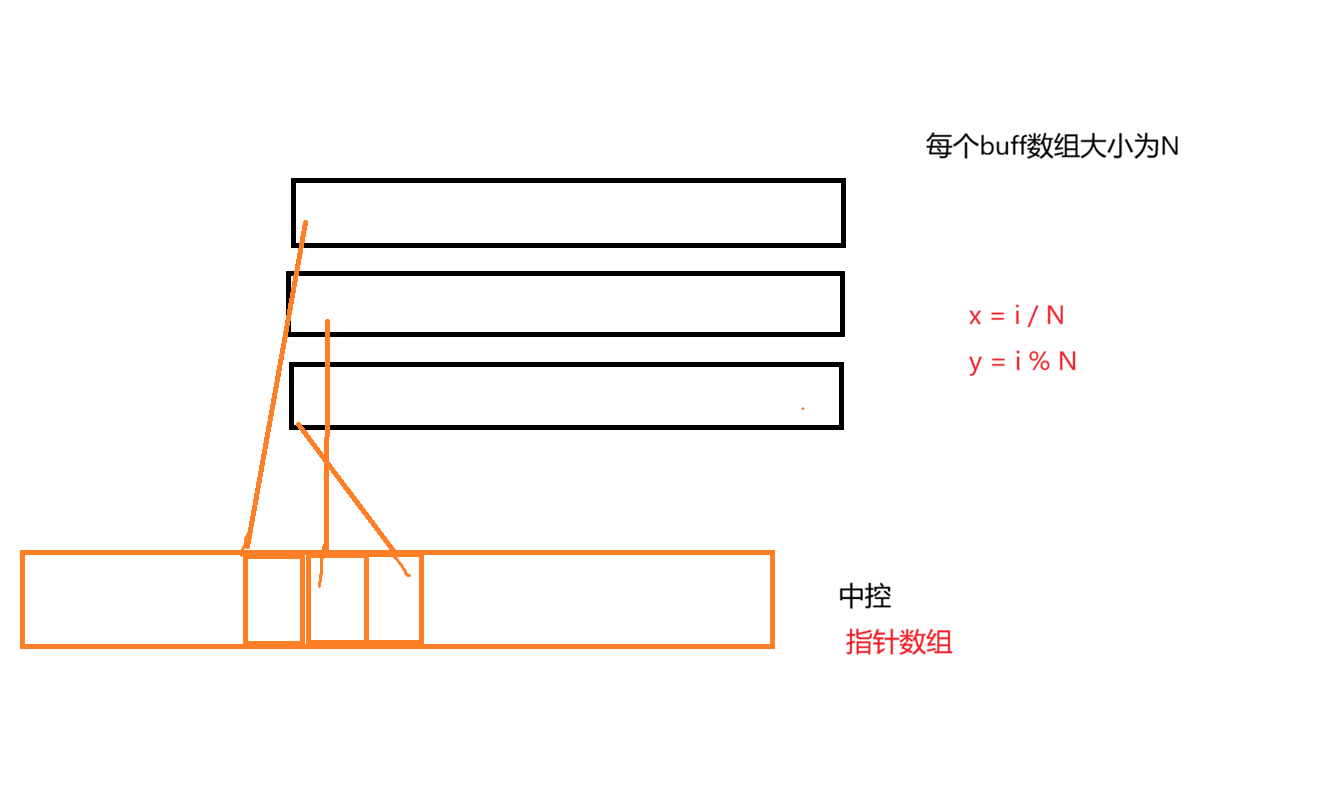
中控数组中 存放着指向每一个buff数组的 指针,buff数组中存放数据
扩容发生在中控数组,扩容会生成新的中控数组,只需要拷贝指针
deque的迭代器
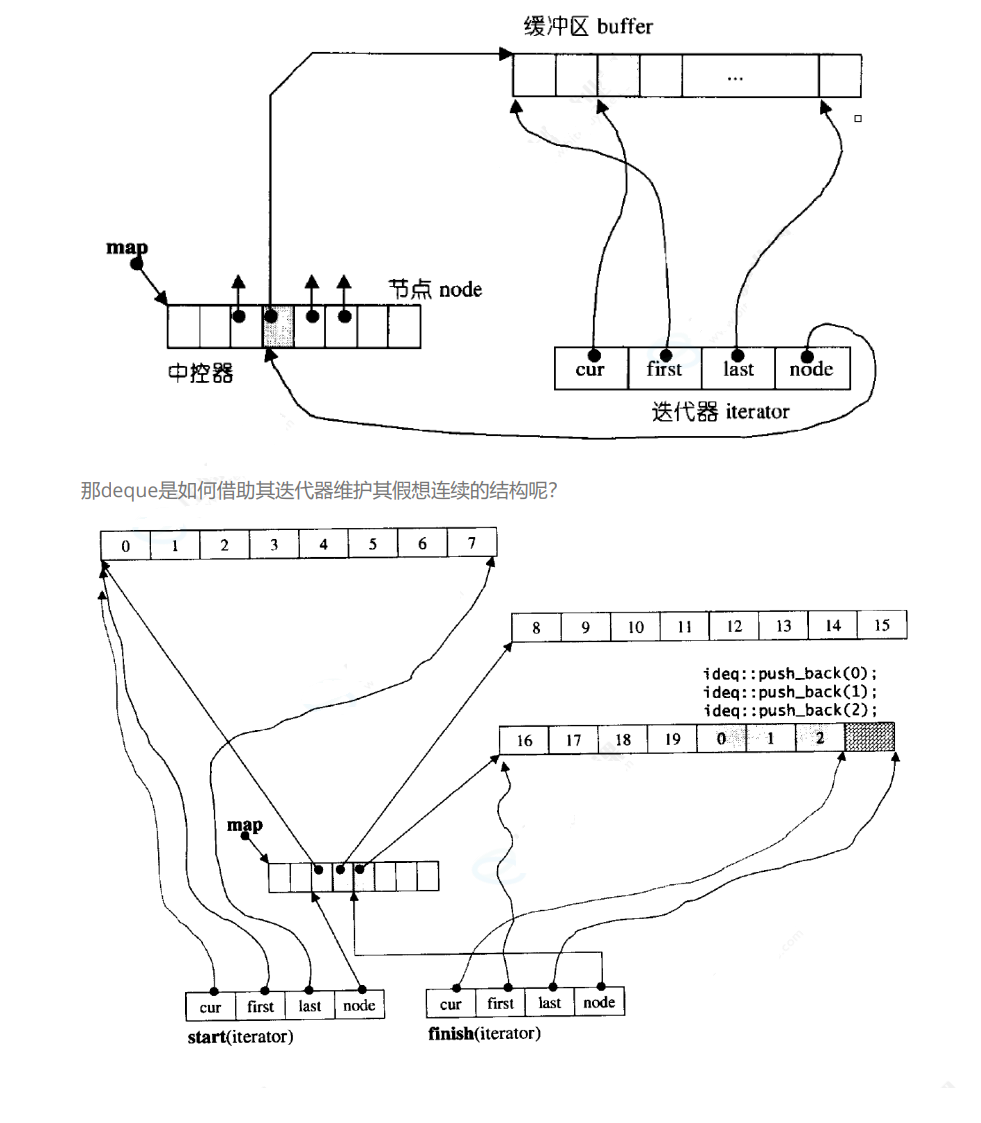
deque迭代器有4个指针
node:二级指针,指向中控数组
cur:在访问buff的第几个数组
first:指向buff的开始
last:指向buff的结束
cpp
iterator it = begin();
while(it!= end())
{
cout<<*it<<" ";
++it;
}内部迭代器的遍历
operator++()
{
++cur;
if(cur == last)
{
set_node(node+1); //让当前node加1 到下一个node
cur=first;
}
return *this;
}
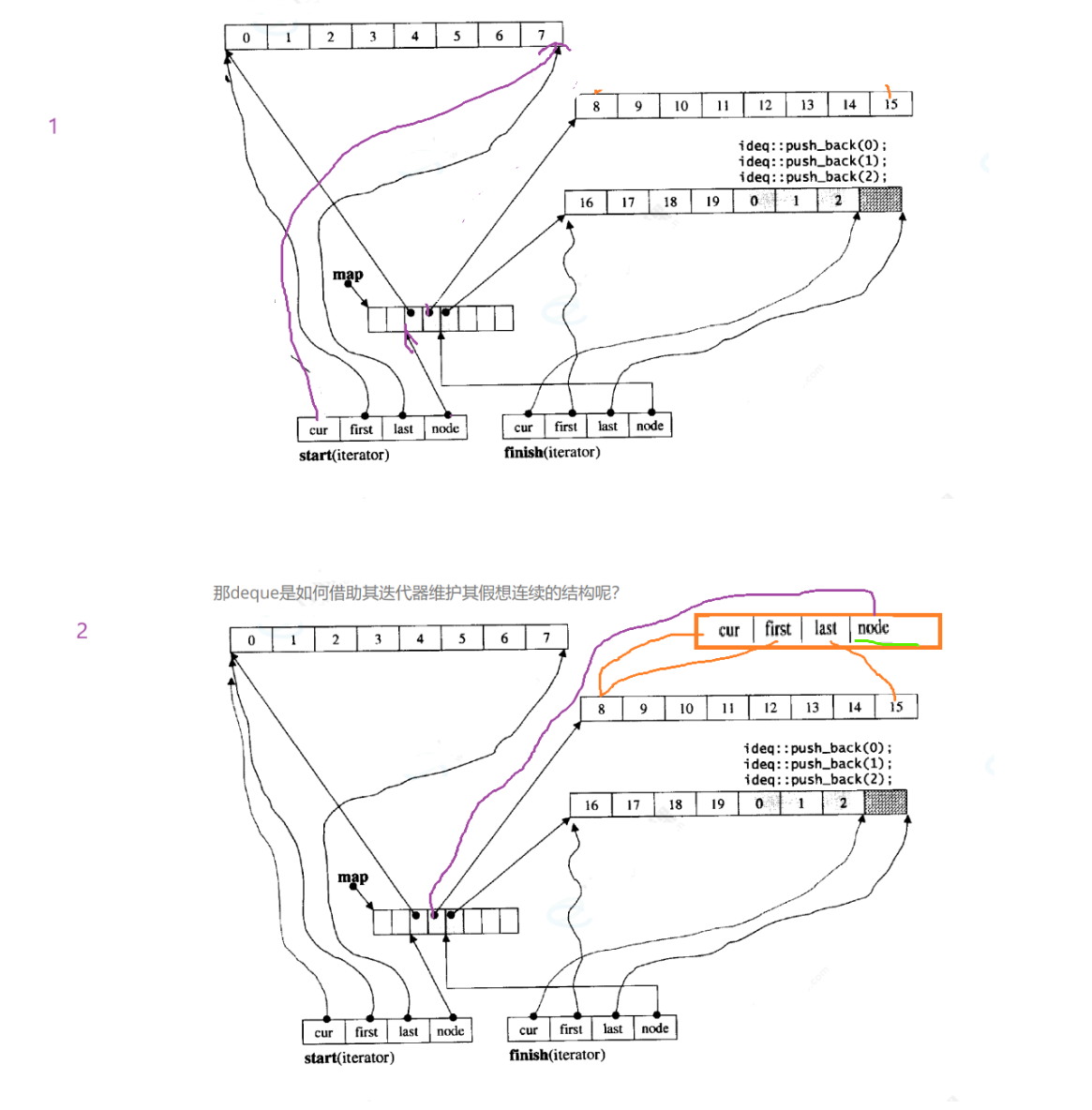
通过遍历迭代器进行打印时,第一步的cur ==last 这时需要node++ 来到第二步
让cur 变成新node 的first ,继续遍历
头插
node向左走
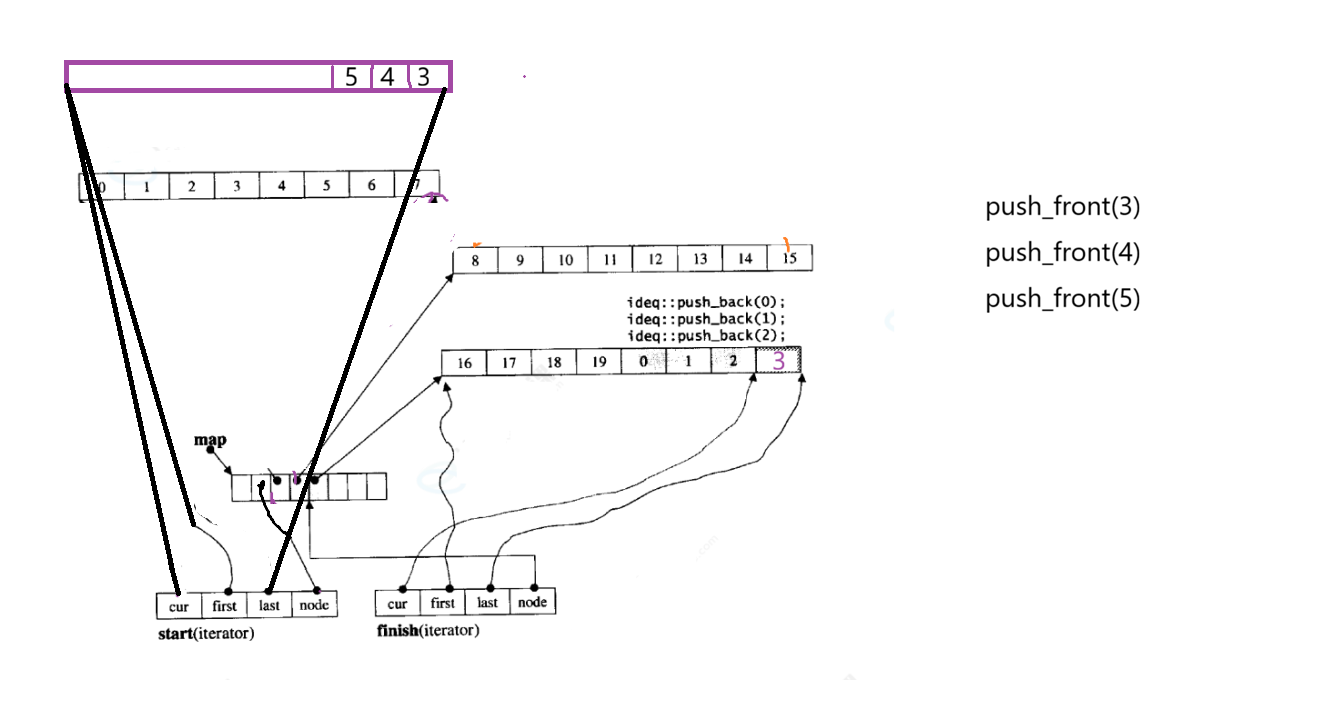
新开一个buff 数组,进行插入,
上一个的node-- 就是指向新buff数组的中控数组
注意!在新的buff数组插入是从后向前进行插入
尾插
node向右走
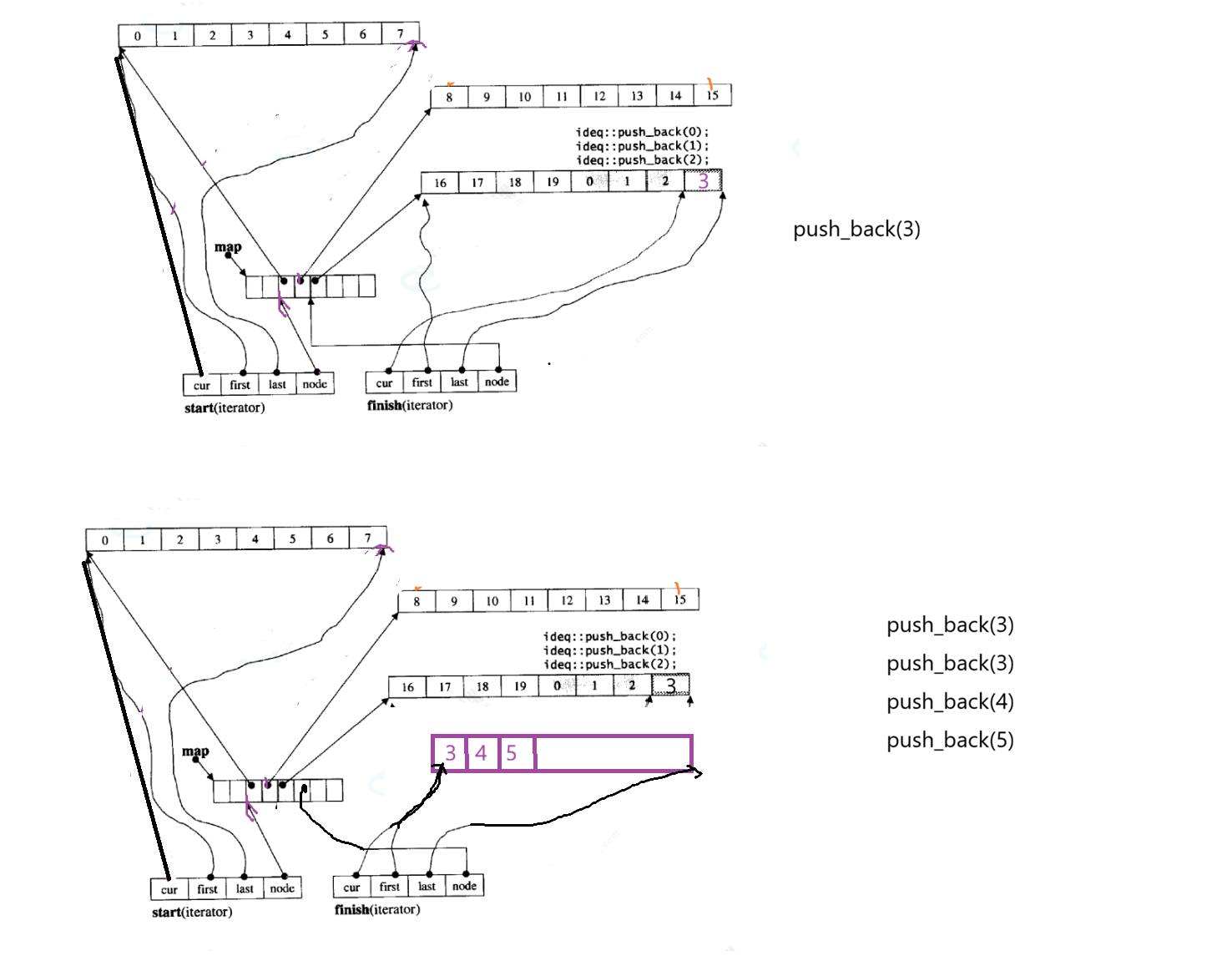
如果尾插时,空间还未达到last,直接插在last 前面
如果已经达到,就新开一个buff 数组,进行插入,
上一个的node++ 就是指向新buff数组的中控数组
vector 排序 与 deque 排序对比
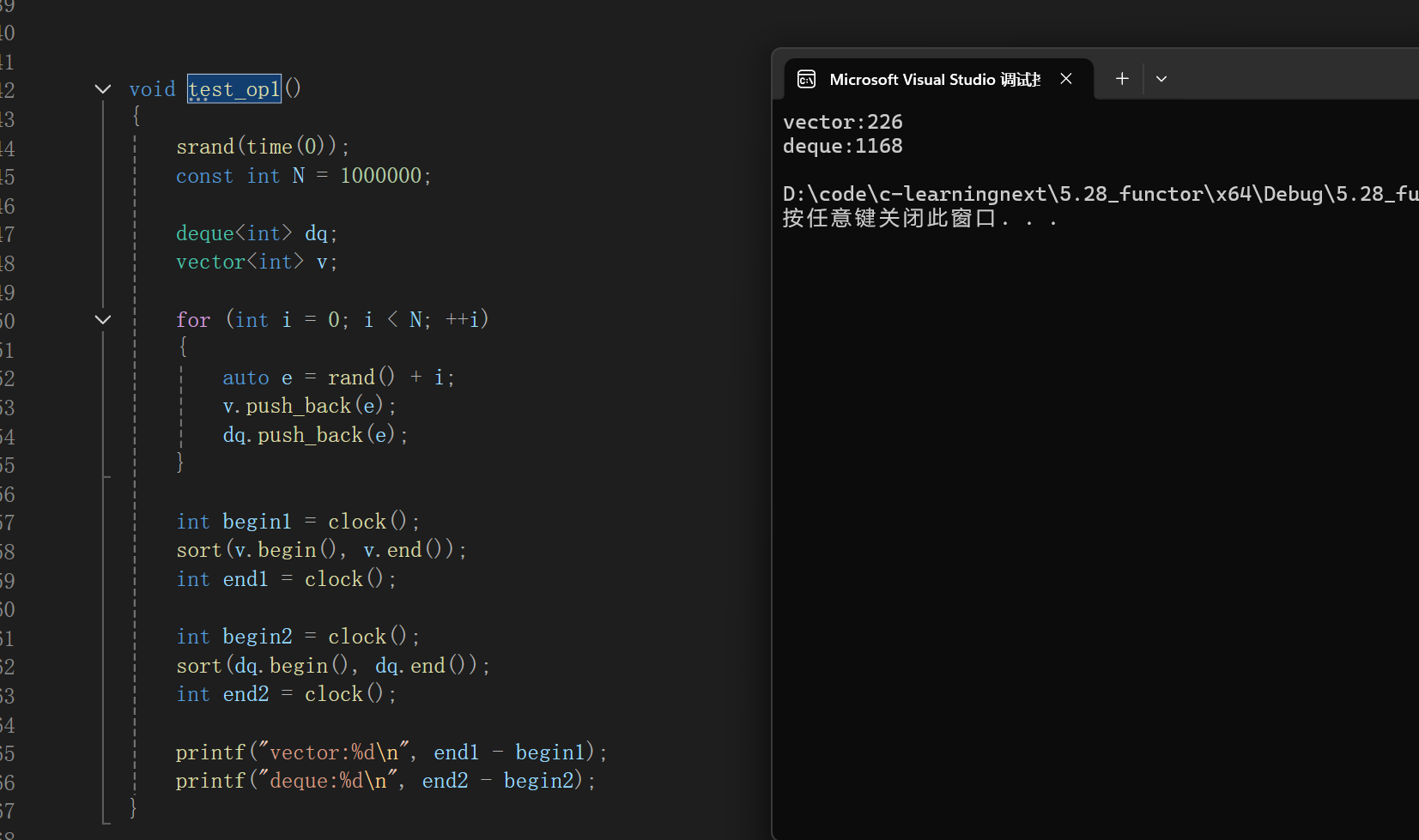
总结:
1.deque 头插尾插效率高,优于vector list
2.下标随机访问效率还可以,比不过vector
3.在中间插入删除效率低
封装:不管底层,直接使用封装好的(菜上桌了,只管吃,不需要管怎么制作)
栈(保持先进后出)和队列(先进先出)要保持,使用迭代器反而不好实现,使用适配器更优
1.用deque 适配队列
cpp
template<class T,class Container =deque<T>>
class queue
{
public:
void pop()
{
_con.pop_front();
}
const T& front() const
{
return _con.front();
}
const T& back() const
{
return _con.back();
}
void push(const T& x)
{
_con.push_back(x);
}
size_t size()const
{
return _con.size();
}
bool empty()const
{
return _con.empty();
}
private:
Container _con;
};2.用vector 适配栈
把vector 尾部当作栈顶
cpp
template<class T,class Container=deque<T> >
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
const T& top()
{
return _con.back(); //尾部是栈顶
}
size_t size()const
{
return _con.size();
}
bool empty()const
{
return _con.empty();
}
private:
Container _con;
};优先级队列(priority_queue)
优先级队列 默认大的优先级高 底层是堆
仿函数
在排序算法中为什么使用仿函数
因为排序算法本身不知道你想按什么规则排。
它只负责"重排元素",至于:
-
是从小到大还是从大到小
-
是按年龄排还是按分数排
-
分数相同再按名字排
这些规则都要你提供。仿函数就是一种"把比较规则封装起来"的方式。
最直接地说:
sort 需要一个"比较器",仿函数就是比较器的一种实现。
为什么不用算法自己判断
比如两个 Student:
cpp
struct Student {
string name;
int score;
};排序时算法看到两个学生对象,并不知道:
-
比较 name
-
还是比较 score
-
还是先比 score,再比 name
所以你必须告诉它"谁应该排前面"。
仿函数的作用
仿函数本质上是"像函数一样使用的类对象"。
例如:
cpp
template <class T>
class Less
{
public:
bool operator()(const T& x, const T& y)
{
return x < y;
}
};
cpp
template <class T>
class Greater
{
public:
bool operator()(const T& x, const T& y)
{
return x > y;
}
};优先级队列代码实现:
cpp
template<class T ,class Container =vector<T>,class Compare = Less<T>>
class priority_queue
{
public:
void AdjustUp(int child)
{
Compare com;
int parent = (child - 1) / 2;
while (child > 0)
{
if (com(_con[parent], _con[child]))
{
swap(_con[parent], _con[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void push(const T& x)
{
_con.push_back(x);
AdjustUp(_con.size() - 1);
}
void AdjustDown(int parent)
{
size_t child = parent * 2 + 1;
Compare com;
while (child < _con.size())
{
if (child + 1 < _con.size() && com(_con[child], _con[child + 1]))
{
++child;
}
if (com(_con[parent], _con[child]))
{
swap(_con[child], _con[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void pop()
{
swap(_con[0], _con[_con.size() - 1]);
_con.pop_back();
AdjustDown(0);
}
const T& top()
{
return _con[0];
}
size_t size() const
{
return _con.size();
}
bool empty() const
{
return _con.empty();
}
private:
Container _con;
};
cpp
template<class T ,class Container =vector<T>,class Compare = Less<T>>这个类采用了泛型编程(模板),包含三个参数:
-
T: 存储在优先队列中的数据类型(如int,string等)。 -
Container: 底层用于存储数据的容器,默认使用std::vector<T>。因为堆的操作需要频繁进行随机访问和在尾部增删元素,vector是最合适的选择。 -
Compare: 仿函数(Functor),用于定义元素的优先级比较规则。代码中默认设为Less<T>(通常表示<操作)。在默认情况下,这种实现会构造一个大顶堆(Max-Heap),即最大的元素放在堆顶。
cpp
private:
Container _con;_con 是底层容器的实例。所有插入到优先队列中的元素都会实际存放在这个数组中。堆的父子节点关系通过数组的索引来计算:
-
已知父节点索引
parent,其左子节点为parent * 2 + 1,右子节点为parent * 2 + 2。 -
已知子节点索引
child,其父节点为(child - 1) / 2。
核心入队操作:push 与 向上调整
cpp
void push(const T& x) {
_con.push_back(x);
AdjustUp(_con.size() - 1);
}push逻辑 : 当有新元素入队时,首先将其放在底层数组的末尾(相当于插入到完全二叉树的最后一个叶子节点),然后调用AdjustUp对其进行"向上调整",以恢复堆的性质。
cpp
void AdjustUp(int child) {
Compare com;
int parent = (child - 1) / 2; // 计算父节点索引
while (child > 0) {
// 如果 com(父节点, 子节点) 成立(例如 父 < 子)
if (com(_con[parent], _con[child])) {
swap(_con[parent], _con[child]); // 交换父子节点
child = parent; // 子节点上移
parent = (child - 1) / 2; // 重新计算新的父节点
} else {
break; // 如果父节点已经大于等于子节点,说明堆已处于正确状态,停止调整
}
}
}AdjustUp逻辑 : 它不断将当前插入的节点与其父节点进行比较。如果父节点的值小于子节点(在Compare为Less时),就将它们交换,直到该节点到达根部(child == 0)或不再大于其父节点为止。
核心出队操作:pop 与 向下调整
cpp
void pop() {
swap(_con[0], _con[_con.size() - 1]); // 交换堆顶(首)与堆底(尾)元素
_con.pop_back(); // 删除原堆顶元素
AdjustDown(0); // 将新堆顶元素向下调整
}pop逻辑 : 优先队列出队时,只能弹出优先级最高(堆顶位置,即_con[0])的元素。为了不在数组头部删除元素(导致全体元素前移,时间复杂度为 O(N)),这里巧妙地将首尾元素交换,然后删除末尾元素(时间复杂度 O(1)),最后将交换到堆顶的元素"向下调整"恢复堆的结构。
cpp
void AdjustDown(int parent) {
size_t child = parent * 2 + 1; // 默认先指向左孩子
Compare com;
while (child < _con.size()) {
// 1. 找出左右孩子中优先级较高(较大)的一个
if (child + 1 < _con.size() && com(_con[child], _con[child + 1])) {
++child; // 如果右孩子存在且大于左孩子,让 child 指向右孩子
}
// 2. 将较大的孩子与父节点比较
if (com(_con[parent], _con[child])) { // 如果 父 < 最大的孩子
swap(_con[child], _con[parent]); // 交换它们
parent = child; // 父节点下移
child = parent * 2 + 1; // 重新计算新的左孩子
} else {
break; // 如果父节点已经大于等于最大的孩子,停止调整
}
}
}AdjustDown逻辑 : 从指定的parent节点开始,每次比较它与它的两个子节点。先选出子节点中较大的一个,然后判断父节点是否小于这个较大的子节点。如果是,就交换它们,让父节点"下沉",一直循环直到它沉到合适的位置或者变成叶子节点。
5. 其他辅助接口
cpp
const T& top() {
return _con[0];
}
size_t size() const {
return _con.size();
}
bool empty() const {
return _con.empty();
}-
top(): 返回堆顶元素的常量引用(即_con[0]),也就是当前队列中优先级最高的元素。 -
size(): 返回队列中当前元素的个数。 -
empty(): 判断队列是否为空。
感谢花时间阅读这篇内容!
如果觉得有价值,欢迎点赞支持、收藏备用,或分享给同行。你的认可,是我持续输出高质量内容的最大动力。
我们下期再见喽!!!