CUDA
CUDA 编程模型是一种用于对大规模并行处理器进行编程的编程模型。
根据《NVIDIA CUDA C++ 编程指南》,CUDA 编程模型中有三个关键抽象:
线程组层次结构(Hierarchy of thread groups)。程序在线程中执行,但可以在从块(blocks)到网格(grids)的嵌套层次结构中引用线程组。
内存层次结构(Hierarchy of memories)。层次结构中每一层的线程组都可以访问一种内存资源,用于在组内进行通信。访问内存层次结构的最低层,其速度应该几乎与执行一条指令一样快。
屏障同步(Barrier synchronization)。线程组可以通过屏障(barriers)来协调执行。
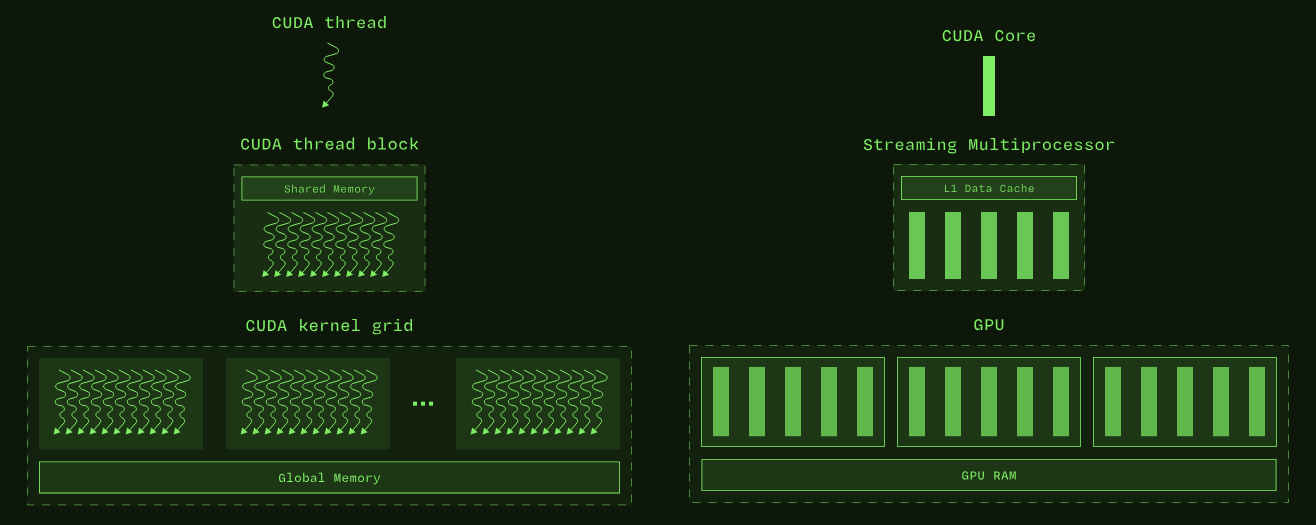
左图:CUDA 编程模型的抽象线程组和内存层次结构。右图:实现这些抽象的匹配硬件。
SASS(流式汇编器)
流式汇编器(Streaming ASSembler,SASS)是在 NVIDIA GPU 上运行的程序的汇编格式。它是 NVIDIA CUDA 编译器驱动程序 nvcc 输出的格式之一,另一种是 PTX。在执行期间,它会被转换为特定于设备的二进制微代码。
SASS 是有版本控制的,并且与特定的 NVIDIA GPU SM 架构绑定。
PTX(并行线程执行)
并行线程执行(Parallel Thread eXecution,PTX)是将在并行处理器(几乎总是 NVIDIA GPU)上运行的代码的一种中间表示(IR)。它是 NVIDIA CUDA 编译器驱动程序 nvcc 输出的格式之一。
PTX 编程模型向程序员暴露了多个级别的并行性。这些级别通过 PTX 机器模型直接映射到硬件上,如相关图表所示。
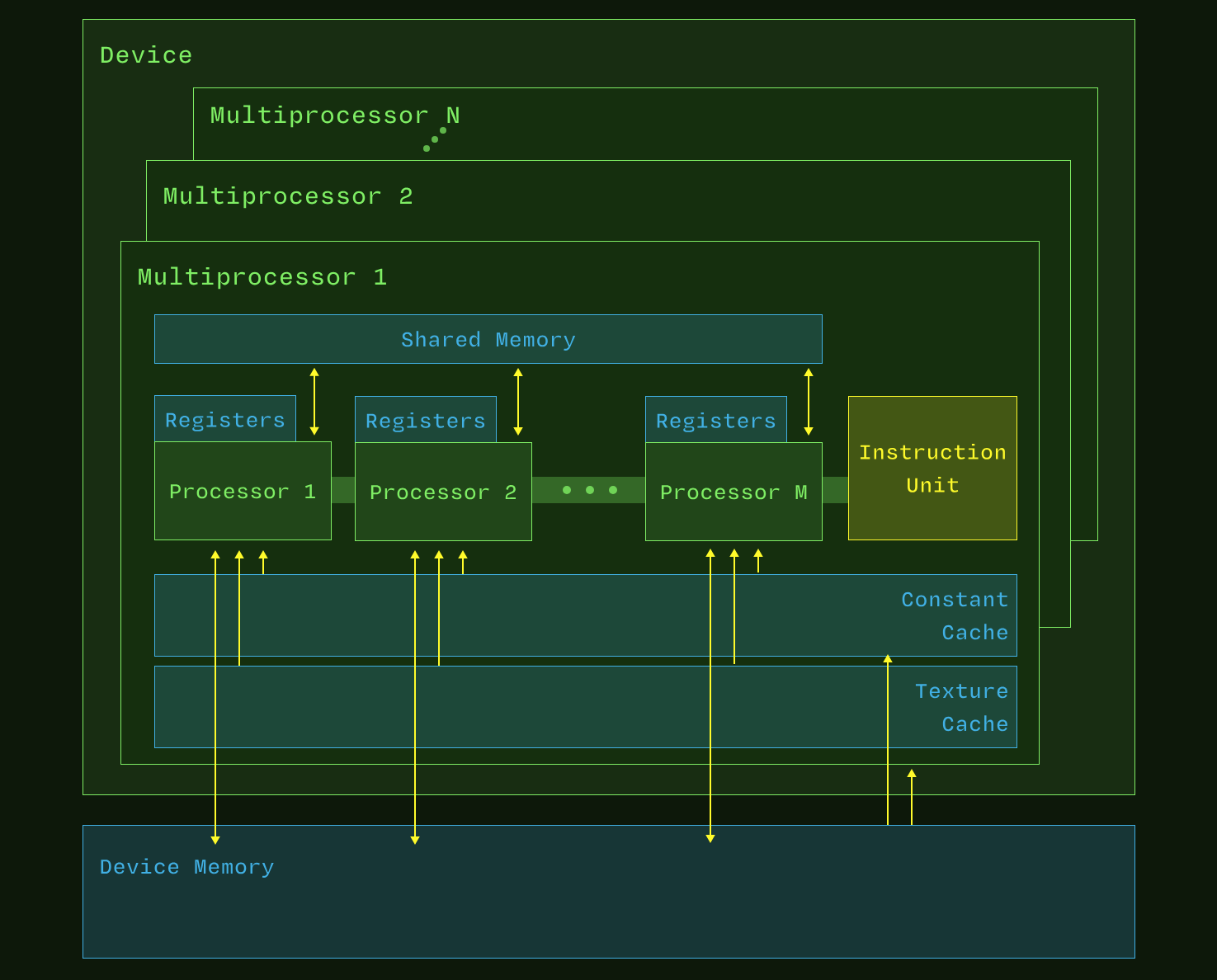
值得注意的是,在这个机器模型中,多个处理器共享一个指令单元。虽然每个处理器运行一个线程,但这些线程必须执行相同的指令------因此称为并行线程执行(PTX)。它们通过共享内存相互协调,并通过私有寄存器产生不同的结果。
Warp
线程束(Warp)是一组被共同调度并并行执行的线程。一个线程束中的所有线程都被调度到同一个流式多处理器(SM)上。单个 SM 通常会执行多个线程束,至少会执行来自同一个协作线程阵列(Cooperative Thread Array,即线程块 / thread block)的所有线程束。
线程束是 GPU 上典型的执行单元。在正常执行中,一个线程束的所有线程并行执行同一条指令------即所谓的"单指令多线程(Single-Instruction, Multiple Thread,SIMT)"模型。当一个线程束中的线程相互分离以执行不同的指令时(这也称为线程束发散 / warp divergence),性能通常会急剧下降。
线程束大小在技术上是一个依赖于机器的常量,但在实践中(以及在本词汇表的其他地方),它等于 32。
如果一个线程束的下一条指令由于缺少操作数而被延迟,则称该线程束被停滞(stalled)。
当多个线程束被调度到单个 SM 上时,Warp 调度器不会等待某条指令的结果返回,而是会选择另一个线程束来执行。这种延迟隐藏(latency-hiding)正是 GPU 实现高吞吐量,并确保其所有核心在执行期间始终有工作可做的原理。出于这个原因,最大化调度到每个 SM 上的线程束数量通常是有益的,这能确保 SM 始终有符合条件(eligible)的线程束可以运行。线程束被发射指令的周期所占的比例被称为发射效率(issue efficiency) 。线程束调度中的并发程度被称为占用率(occupancy)。
Warpgroup
线程束组(Warpgroup)是由四个连续的线程束(warps)组成的一组,其中第一个线程束的"线程束秩(warp-rank)"必须是 4 的倍数。
在分发线程束组级别的指令时,我们会协调 128 个线程------即每个线程束组 4 个线程束 × 每个线程束 32 个线程。
在并行线程执行(PTX)中间表示中,一个线程束的线程束秩计算方式如下:
cpp
int linearIdx = (%tid.x + %tid.y * %ntid.x + %tid.z * %ntid.x * %ntid.y);
int warpRank = linearIdx / 32;其中 tid 是线程索引,可通过特殊的 PTX 寄存器进行访问。
因此,对于包含 8 个线程束的分发任务,有效的线程束组为:
-
线程束组 0(Warpgroup 0):线程束秩 0、1、2 和 3
-
线程束组 1(Warpgroup 1):线程束秩 4、5、6 和 7。
Cooperative Thread Array(合作线程阵列)
协作线程阵列(Cooperative Thread Array,CTA)是被调度到同一个流式多处理器(SM)上的一组线程的集合。CTA 是 CUDA 编程模型中"线程块(thread blocks)"在 PTX/SASS 层面的实现。CTA 由一个或多个线程束(warps)组成。
程序员可以指示一个 CTA 内的线程相互协调。位于 SM 的 L1 数据缓存中、由程序员管理的共享内存(shared memory)使得这种协调非常迅速。与一个 CTA 内的线程不同,不同 CTA 中的线程不能通过屏障(barriers)相互协调,而是必须通过全局内存(global memory)进行协调,例如通过原子更新指令(atomic update instructions)。由于驱动程序在运行时控制 CTA 的调度,因此 CTA 的执行顺序是不确定的,让一个 CTA 阻塞等待另一个 CTA 很容易导致死锁(deadlock)。
能够被调度到单个 SM 上的 CTA 数量决定了可实现的占用率(occupancy),而这取决于许多因素。根本而言,SM 的资源是有限的------寄存器堆中的行、用于线程束的"槽位(slots)"、L1 数据缓存中共享内存的字节数------并且当每个 CTA 被调度到 SM 上时,都会使用一定数量的这些资源(这些消耗量是在编译时计算好的)。
CUDA Kernel
内核(Kernel)是程序员通常编写和组合的 CUDA 代码单元,类似于针对 CPU 的编程语言中的函数(function)。
与函数不同,内核被调用("启动")一次并返回一次,但会被执行许多次------由众多线(threads)各自执行一次。这些执行通常是并发的(它们的执行顺序是不确定的)并且是并行的(它们在不同的执行单元上同时发生)。
执行一个内核的所有线程的集合被组织为一个内核网格(kernel grid) ------也就是线程块网格(thread block grid),这是 CUDA 编程模型中线程层次结构(thread hierarchy)的最高层级。内核网格跨越多个流式多处理器(SM)执行,因此其运行规模覆盖整个 GPU。与其匹配的内存层次结构层级是全局内存(global memory)。
CUDA Thread Hierarchy
线程层次结构(Thread hierarchy)是 CUDA 编程模型的关键抽象之一,与内存层次结构(memory hierarchy)并列。它将并行程序的执行跨越多个层级进行组织,从单个线程一直到整个 GPU 设备。
在最低层级是单个线程(individual threads)。就像 CPU 上的执行线程一样,每个 CUDA 线程执行一个指令流。执行算术和逻辑指令的硬件资源被称为核心(cores),有时也称为"管道(pipes)"。线程由 Warp 调度器(Warp Scheduler)选择执行。
中间层级由线程块(thread blocks) 组成,它们在 PTX 和 SASS 中也被称为合作线程阵列(cooperative thread arrays)。每个线程在其线程块内都有一个唯一的标识符。这些线程标识符是基于索引的,以支持根据输入或输出数组的索引轻松地将工作分配给各线程。一个线程块内的所有线程都会被同时调度到同一个流式多处理器(SM)上。它们可以通过共享内存(shared memory)进行协调,并使用屏障(barriers)进行同步。
在最高层级,多个线程块被组织成一个跨越整个 GPU 的线程块网格(thread block grid)。线程块在协调和通信方面受到严格限制。网格内的线程块彼此并发执行,没有保证的执行顺序。编写 CUDA 程序时必须确保线程块的任何交错执行方式都是有效的,从完全串行到完全并行均可。这意味着,例如,线程块不能使用屏障进行同步。像线程一样,每个线程块也有一个唯一的、基于索引的标识符,以支持基于数组索引的工作分配。
这种层次结构直接映射到 GPU 硬件上:线程在各个核心 上执行,线程块被调度到 SM 上,而网格则利用设备上所有可用的 SM。
Thread Block
线程块(Thread block)是 CUDA 编程模型线程层次结构(thread hierarchy)中的一个层级,位于网格(grid)之下、线程(thread)之上。它是 CUDA 编程模型中对应于 PTX/SASS 里具体的协作线程阵列(cooperative thread arrays,CTA)的抽象等价物。
在 CUDA 编程模型中,线程块是向程序员暴露的最小的线程协调单元。线程块必须独立执行,因此线程块的任何执行顺序都是有效的,无论是任意顺序的完全串行执行,还是各种形式的交错并发执行(interleavings)。
单次 CUDA 内核(kernel)启动会产生一个或多个线程块(以线程块网格 / thread block grid 的形式),每个线程块包含一个或多个线程束(warps)。线程块的大小可以是任意指定的,在当前设备上的最大限制为 1024 个线程,但在实际应用中,它们通常被设置为线程束大小(当前设备上为 32)的整数倍。
Thread Block Grid
当一个 CUDA 内核(kernel)被启动时,它会创建一个被称为线程块网格(thread block grid)的线程集合。网格可以是一维、二维或三维的。它们由线程块(thread blocks)组成。
与之匹配的内存层次结构层级是全局内存(global memory)。
线程块实际上是独立的计算单元。它们并发执行,也就是说,执行顺序是不确定的;从在只有单个流式多处理器(SM)的 GPU 上完全串行执行,到在具有足够资源以同时运行所有线程块的 GPU 上完全并行执行,均有可能。
CUDA Thread
执行线程(Thread of execution)(简称"线程")是 GPU 编程中最低级别的单位,也是 CUDA 编程模型线程层次结构(thread hierarchy)的基础。一个线程拥有自己的寄存器,但除此之外几乎没有其他专有资源。
SASS 和 PTX 程序都是以线程为目标来编写的。相比之下,在 POSIX 环境中的典型 C 程序则是以进程为目标的,而进程本身是一个或多个线程的集合。与 POSIX 线程不同,CUDA 线程不用于发起系统调用(syscalls)。
就像 CPU 上的线程一样,GPU 线程可以拥有私有的指令指针(instruction pointer)/ 程序计数器(program counter)。然而,出于性能方面的考量,通常在编写 GPU 程序时,会使同一个线程束(warp)内的所有线程共享同一个指令指针,以锁步(lock-step)的方式执行指令(另见 Warp 调度器)。
同样与 CPU 上的线程类似,GPU 线程在全局内存(global memory)中拥有自己的栈,用于存储溢出的寄存器(spilled registers)和函数调用栈(function call stack),但在编写高性能内核时,通常会尽量限制这两者的使用。
单个 CUDA 核心(CUDA Core)负责执行来自单个线程的指令。
Memory Hierarchy
作为 CUDA 编程模型的一部分,线程层次结构(thread hierarchy)中的每个层级都可以访问一块由该层级对应组内的所有线程所共享的独立内存:这就是"内存层次结构(memory hierarchy)"。这种内存可用于协调与通信,并且是由程序员(而非硬件或运行时环境)来管理的。
对于线程块网格(thread block grid)而言,这种共享内存位于 GPU 的 RAM 中,被称为全局内存(global memory)。可以通过原子操作(atomic operations)和屏障(barriers)来协调对该内存的访问,但不同线程块之间的执行顺序是不确定的。
对于单个线程(single thread)而言,这种内存是流式多处理器(SM)寄存器堆(register file)中的一部分。根据 CUDA 编程模型的原始语义,这种内存(寄存器 / registers)对单个线程是私有的,但是为了在 Tensor Core(张量核心)上进行矩阵乘法而添加到 PTX 和 SASS 中的某些特定指令,会在多个线程之间共享输入和输出。
介于这两者之间,用于线程层次结构中线程块(thread block)层级的共享内存(shared memory) ,存储在每个 SM 的 L1 数据缓存中。对该缓存进行精细管理------例如,将数据加载到其中,以在必须加载新数据之前支撑最大数量的算术运算------是设计高性能 CUDA 内核(kernels)这门艺术的关键所在。
Registers
在内存层次结构(memory hierarchy)的最低层是寄存器(registers) ,它们存储由单个线程(thread)操作的信息。
寄存器中的值通常存储在流式多处理器(SM)的寄存器堆(register file)中,但它们也可能溢出(spill)到 GPU RAM 中的全局内存(global memory)里,这会带来巨大的性能损失。
就像在对 CPU 进行编程时一样,像 CUDA C 这样的高级语言并不会直接操作这些寄存器。它们只对诸如并行线程执行(PTX)等较低级别的语言可见。寄存器通常由编译器(如 ptxas)负责管理。编译器的目标之一是限制每个线程使用的寄存器空间,以便更多的线程块(thread blocks)能够被同时调度到单个 SM 中,从而提高占用率(occupancy)。
Shared Memory
共享内存(Shared memory)是 CUDA 编程模型中对应于线程层次结构里 线程块(thread block)层级的内存层次结构层级。通常情况下,它的容量被设计得比全局内存(global memory)小得多,但速度(在吞吐量和延迟方面)要快得多。
因此,一个相当典型的内核(kernel)工作流程大致如下:
-
从全局内存将数据加载到共享内存中
-
通过 CUDA 核心(CUDA Cores)和张量核心(Tensor Cores)对这些数据执行大量的算术运算
-
(可选)在执行这些操作时,通过屏障(barriers)来同步一个线程块内的各个线程
-
将数据写回全局内存,(可选)通过原子操作(atomics)来防止跨线程块的竞争(races)
共享内存物理上存储在 GPU 的流式多处理器(SM)的 L1 数据缓存(L1 data cache)中。
Global Memory
内存层次结构的最高层是全局内存(global memory)。全局内存的作用域和生命周期都是全局的。也就是说,它可以被线程块网格(thread block grid)中的每个线程访问,并且其生命周期与程序的执行时间一样长。
与 CPU 内存一样,可以使用原子指令(atomic instructions)在所有访问者之间同步对全局内存中数据结构的访问。在协作线程阵列(cooperative thread array,CTA)内部,访问可以进行更紧密的同步,例如使用屏障(barriers)。
这一内存层次结构层级通常在 GPU 的 RAM 中实现,并由主机(host)使用 CUDA 驱动程序 API(CUDA Driver API)或 CUDA 运行时 API(CUDA Runtime API)提供的内存分配器来进行分配。
CUDA Tile programming model
CUDA Tile 编程模型是一种针对 NVIDIA GPU 的基于分块(tile-based)的编程模型。
传统的 CUDA 编程模型向用户程序暴露了线程层次结构 和内存层次结构,这些程序接收指针并并发执行,以改变与这些指针相关的内存。相同的指令被并行地发射给多个线程,因此这种编程模型是一种"单指令多线程(SIMT)"编程模型。
传统的编程模型并不适合最新 SM 架构的 GPU,因为在这些架构中,绝大部分的算术带宽都在张量核心(Tensor Cores)上。张量核心只能执行矩阵乘法,并且必须使用线程(thread)级别的指令和异步机制进行编程,而不是使用对其余硬件进行编程的线程束(warp)级别的异步机制。
在 CUDA Tile 编程模型中,程序是在 tile-kernels(分块内核)的级别上进行表达的。它们是在分块网格(grid of tile blocks)中并发运行的程序实例,每个分块网格都是一个单一的执行线程。在理想情况下(happy path),tile-kernels 在结构化指针(structured pointers)上运行,这种指针将指针本身与关于数组的信息结合在一起:数组的总范围(形状 / shape)及其访问模式(步长 / stride)。