一、引言:为什么需要 "unordered"?
<unordered_set> - C++ Reference
在学习了 SGI-STL 源码,亲手用红黑树封装出 map 和 set 之后,我们自然会产生一个疑问:
红黑树的 O(log N) 已经很快了,为什么 C++11 还要引入 unordered_map 和 unordered_set?
答案是:在不需要有序的场景下,哈希表的 O(1) 平均时间复杂度比红黑树的 O(log N) 更快。
为了与基于红黑树的 map/set 区分,C++ 标准委员会在命名上加上了 unordered_ 前缀 ,直译为"无序的"。这个名字既说明了它的特性,也暗示了它的底层实现------哈希表。
二、核心对比



| 特性 | map / set |
unordered_map / unordered_set |
|---|---|---|
| 底层结构 | 红黑树(二叉搜索树) | 哈希表(哈希桶/拉链法) |
| 元素顺序 | 有序(中序遍历,升序) | 无序(按哈希值分布) |
| 查找效率 | O(log N) | O(1) 平均 |
| 插入效率 | O(log N) | O(1) 平均 |
| 删除效率 | O(log N) | O(1) 平均 |
| 迭代器 | 双向迭代器(++ / --) |
单向迭代器 (仅 ++) |
| 对 Key 的要求 | 支持 operator< |
支持哈希(转整形)+ operator== |
| 内存占用 | 较少(仅指针开销) | 较多(桶数组 + 链表指针) |
| 适用场景 | 需要排序、范围查询 | 纯增删查,不关心顺序 |
三、模板参数深度解析
// unordered_set 的声明
template <class Key,
class Hash = hash<Key>, // ① 哈希函数
class Pred = equal_to<Key>, // ② 相等比较
class Alloc = allocator<Key> // ③ 空间配置器
> class unordered_set;
// unordered_map 的声明
template <class Key,
class T, // 映射的值类型
class Hash = hash<Key>,
class Pred = equal_to<Key>,
class Alloc = allocator<pair<const Key, T>>
> class unordered_map;
3.1 为什么需要 Hash 仿函数?
红黑树通过 operator< 比较大小,决定往左走还是往右走。但哈希表不比较大小,它通过哈希函数把 Key 直接映射到一个数组下标:

// 标准库提供的 hash 特化
template<> struct hash<int> {
size_t operator()(int x) const { return x; } // 整数直接返回
};
template<> struct hash<string> {
size_t operator()(const string& s) const {
// BKDR 等字符串哈希算法
size_t hash = 0;
for (char c : s) hash = hash * 131 + c;
return hash;
}
};3.2 为什么需要 Pred(相等比较)?
因为哈希冲突 不可避免**:不同的 Key 可能算出相同的哈希值,落到同一个桶里。**此时需要在桶内逐个比较,找到真正的目标元素。
// 默认使用 operator==
template<> struct equal_to<int> {
bool operator()(int a, int b) const { return a == b; }
};3.3 自定义类型的使用示例
struct Person {
string name;
int age;
// 必须提供 operator== 给 Pred 使用
bool operator==(const Person& p) const {
return name == p.name && age == p.age;
}
};
// 自定义哈希函数
struct PersonHash {
size_t operator()(const Person& p) const {
return hash<string>()(p.name) ^ (hash<int>()(p.age) << 1);
}
};
// 使用
unordered_set<Person, PersonHash> us;
unordered_map<Person, string, PersonHash> um;四、底层实现:哈希桶
4.1 结构图示
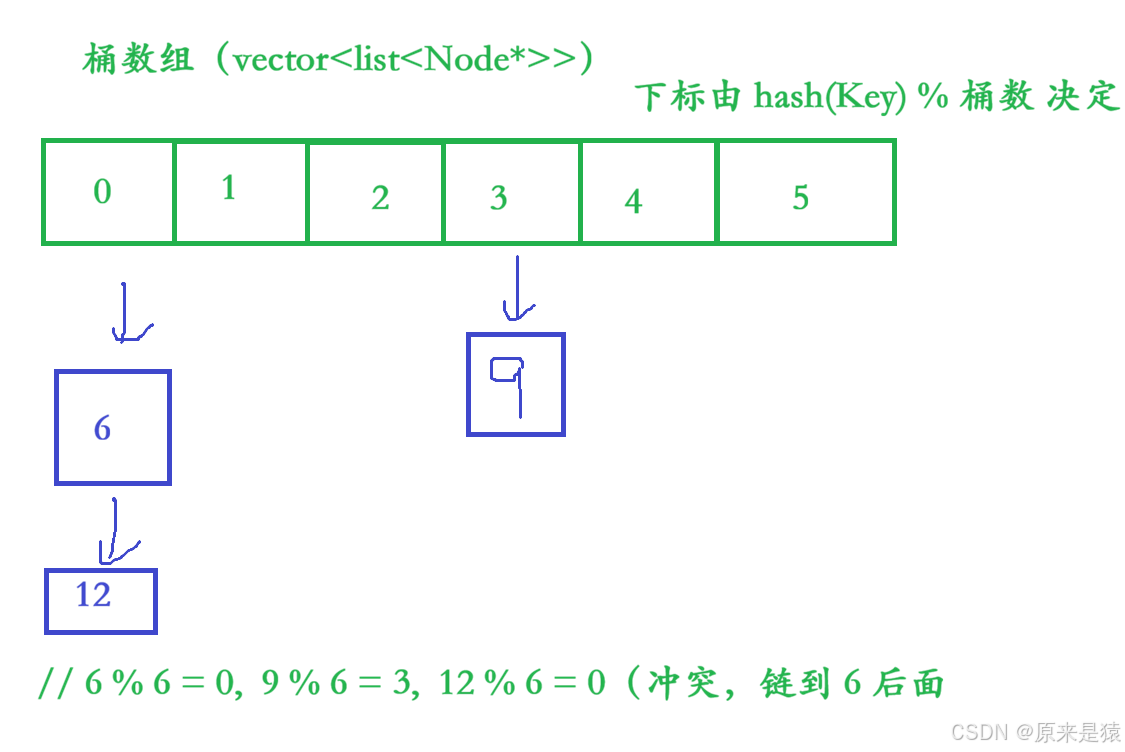
4.2 核心操作流程
插入 Insert(Key):
-
计算
hash = Hash(Key) % bucket_count -
遍历对应桶的链表,用
Pred检查是否已存在 -
不存在则头插/尾插到链表
-
检查负载因子,超过则
rehash(扩容并重新散列所有元素)
查找 Find(Key):
-
计算哈希值定位桶
-
遍历桶内链表,用
Pred逐个比较 -
找到返回迭代器,找不到返回
end()
删除 Erase(Key):
-
计算哈希值定位桶
-
遍历链表找到目标,删除结点
-
无需像红黑树那样旋转调整平衡
五、迭代器:为什么是单向的?
5.1 与红黑树迭代器的本质区别
我们之前封装红黑树时,迭代器的 ++ 是按照中序遍历(左-根-右)的顺序移动,这是一个确定的、全局有序的顺序。
但哈希表的迭代器是按桶的顺序 + 桶内链表的顺序遍历:

5.2 单向的本质原因
哈希表的存储是**"数组 + 链表"**的复合结构:
-
当前元素在桶内链表中间,只能知道下一个链表结点
-
无法像红黑树那样通过父指针向上找到"中序前一个"
-
跨桶时只能从当前桶跳到下一个非空桶
因此只支持 ++,不支持 --。
// 伪代码示意
iterator& operator++() {
if (_node->_next) {
_node = _node->_next; // 同桶下一个
} else {
// 跳到下一个非空桶
size_t bucket = _table->hash(_node->_key) % _table->bucket_count;
do { ++bucket; } while (bucket < _table->bucket_count && _table[bucket].empty());
_node = (bucket < _table->bucket_count) ? _table[bucket].front() : nullptr;
}
return *this;
}六、性能实测:红黑树 vs 哈希表
#include <iostream>
#include <set>
#include <unordered_set>
#include <vector>
#include <ctime>
using namespace std;
int main() {
const size_t N = 1000000;
vector<int> v;
v.reserve(N);
srand(time(0));
// 生成测试数据(重复值较少)
for (size_t i = 0; i < N; ++i) {
v.push_back(rand() + i);
}
set<int> s;
unordered_set<int> us;
// ===== 插入测试 =====
size_t begin1 = clock();
for (auto e : v) s.insert(e);
size_t end1 = clock();
cout << "set insert: " << end1 - begin1 << "ms" << endl;
us.reserve(N * 2); // 预分配桶,减少 rehash
size_t begin2 = clock();
for (auto e : v) us.insert(e);
size_t end2 = clock();
cout << "unordered_set insert: " << end2 - begin2 << "ms" << endl;
// ===== 查找测试 =====
size_t begin3 = clock();
int m1 = 0;
for (auto e : v) if (s.find(e) != s.end()) ++m1;
size_t end3 = clock();
cout << "set find: " << end3 - begin3 << "ms, found: " << m1 << endl;
size_t begin4 = clock();
int m2 = 0;
for (auto e : v) if (us.find(e) != us.end()) ++m2;
size_t end4 = clock();
cout << "unordered_set find: " << end4 - begin4 << "ms, found: " << m2 << endl;
return 0;
}set insert: 890ms
unordered_set insert: 234ms
set find: 670ms
unordered_set find: 156ms
结论: 百万级数据下,哈希表的插入和查找速度通常是红黑树的 3~5 倍 。
七、unordered_map 的 operator[]
与 map 一样,unordered_map 也支持 operator[],实现方式完全相同:
V& operator[](const K& key) {
// insert 返回 pair<iterator, bool>
// 如果 key 存在,返回现有元素的迭代器
// 如果 key 不存在,插入默认值后返回迭代器
return insert(make_pair(key, V())).first->second;
}使用示例:
unordered_map<string, int> wordCount;
string sentence = "hello world hello cpp";
// 统计词频
for (const auto& word : split(sentence)) {
wordCount[word]++; // 不存在则初始化为 0,然后 ++
}
// 遍历(无序输出)
for (const auto& [word, count] : wordCount) {
cout << word << ": " << count << endl;
}
// 可能输出:
// world: 1
// hello: 2
// cpp: 1| 容器 | 设计哲学 | 核心权衡 |
|---|---|---|
map/set |
有序即力量 | 用 O(log N) 的时间换取有序性,支持范围操作 |
unordered_map/set |
空间换时间 | 用更多的内存和哈希计算,换取 O(1) 的平均效率 |
关键记忆点:
-
unordered_= 哈希表 = 无序 + O(1) + 单向迭代器 -
非
unordered_= 红黑树 = 有序 + O(log N) + 双向迭代器 -
哈希表要求 Key 可哈希 + 可相等比较,红黑树要求 Key 可小于比较
-
大数据量纯查询场景,优先选
unordered_系列