关于常见 map的一些比较探究
前言
除了数组和链表之外,map(或者字典) 在软件开发中用到的最多的数据结构之一了(一般来说,链表用到的比map还少)。 突来兴趣,想研究比较一下软件开发过程中涉及到的一些语言库(go 中的 map、java 中的 hash map)、或者组件中(redis 中的 map )用到的map 。简单记录一下,希望可以便人便己。
map 这种数据结构,中最重要的就hash函数 和 hash 冲突时的解决方法 。对于现实中应用到的 map 来说,还有一个为了防止元素过多或者太空而引起查询效率降低, 而引入的 map 的扩缩容问题。
一、hash 冲突解决策略
对于 map 这种数据结构,理想的情况是对于不同的 key,会被 hash 函数映射到不同的位置,这样读写都是 O(1), 就不会出现冲突的情况了。 但是实际的内存不是无限的(也不能做成无限的),所以冲突是无法避免的(所以 hash 函数的一个重点作用就是要尽量减少碰撞)。
hash 函数不同的编程语言(中间件)使用的有些不同,今天暂不讨论。主要说说 hash 的冲突解决策略。就我所知,大部分hash 的冲突解决策略都是使用的同一个框架:拉链法 ,经过 hash 函数映射后,再散到长度为 k 的桶中,每个桶中拉起一个链表,把相同映射的 key 串起来。看起来简单明了。
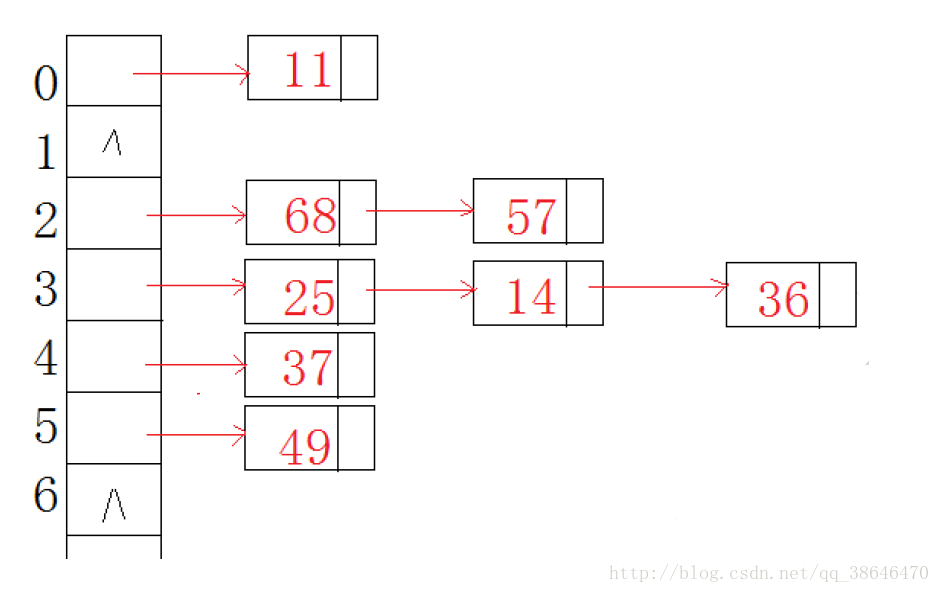
redis 是这样用的。
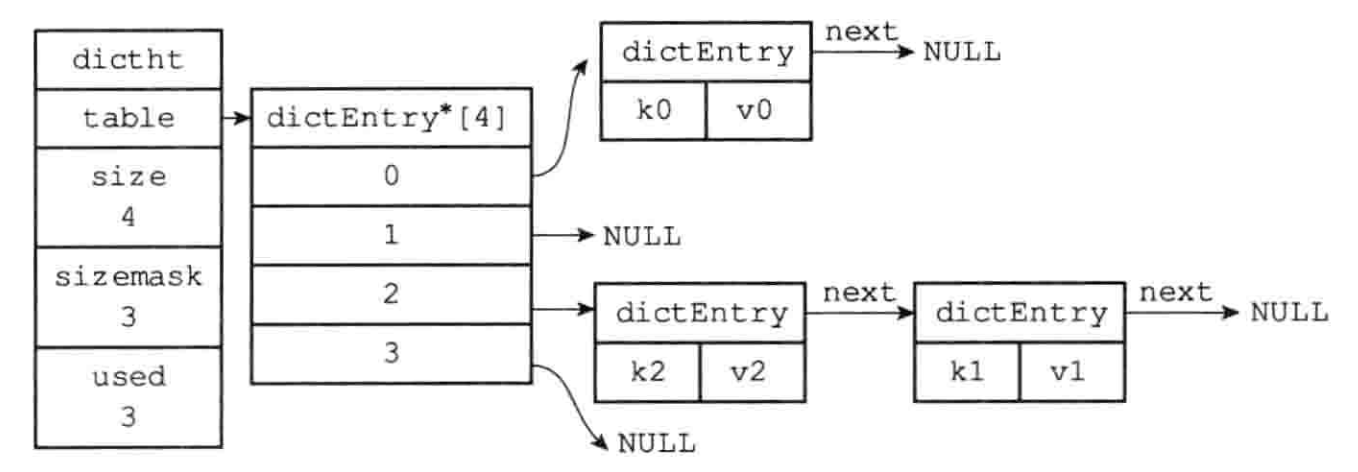
java hashMap 是这样用的。
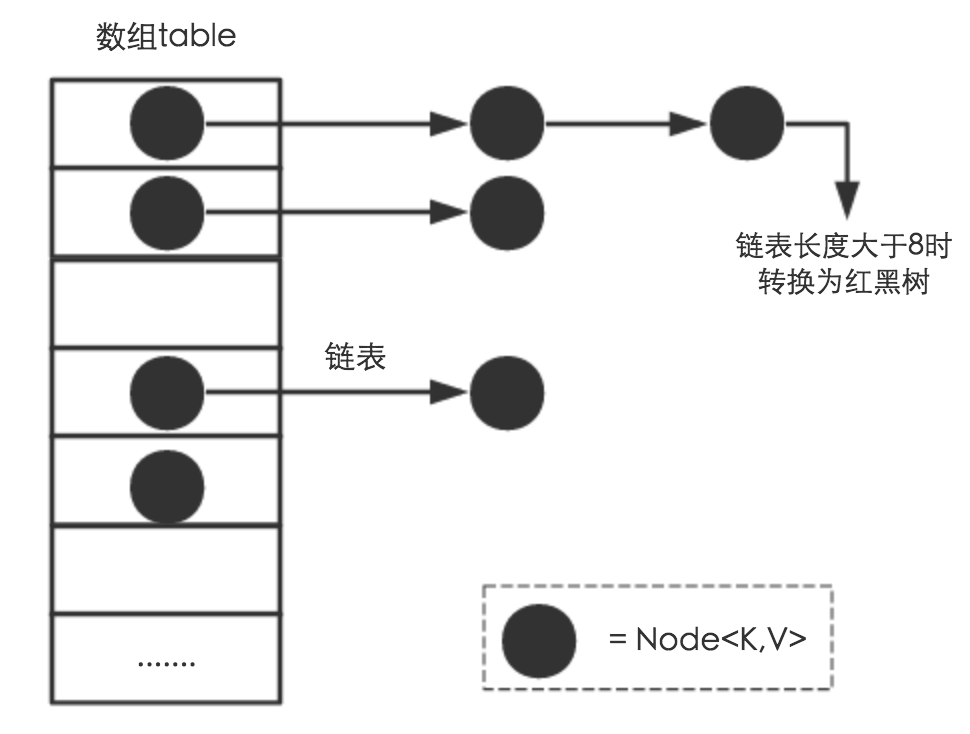
java 的 hashMap 中如果链表的长度比较长,会转换成红黑树(之所以这样,是因为 java8 为了解决 java 7 中链表过长导致的性能退化和安全漏洞(因为 java语言的兼容性和语言特点(hashCode 可以由用户自己定义),极端情况下,会有可能造成大量的 key映射到同一个链表中,造成性能急剧下降))。 转换成红黑树之后,长链表的 O(N)会复杂度会O(lgN)级别。
go 中是这样的。
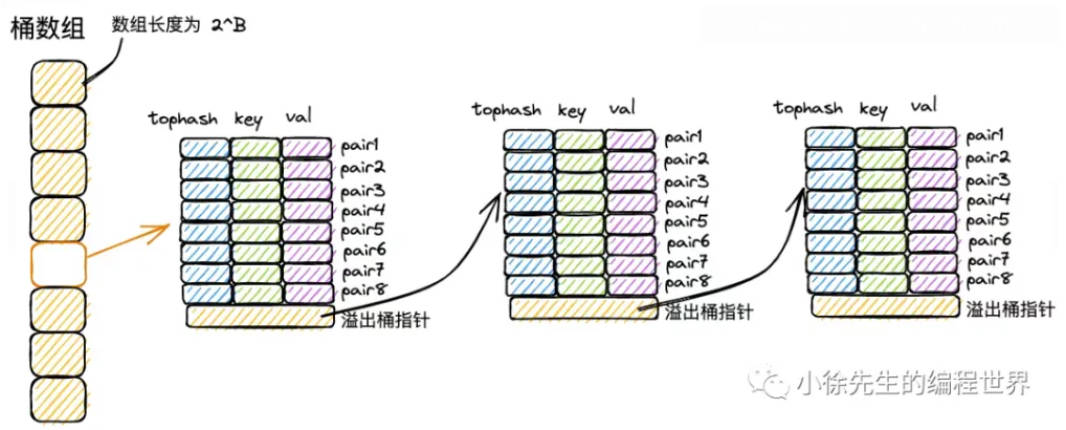
go 中的拉链元素看起来有些不一样。它每个元素是一个包含了 8 个元素的数组(然后再用溢出桶来连着下一个元素)。这样的话,可以一次性把 8 个散到同一个 index 的 key 加载到内存中,加快访问效率。
这里多说一点,go 中基本不会出现像 java 那样因为hash 冲突造成大量元素映射到同一个链表的安全漏洞,因为 go 的 hash 函数一般是运行时库实现的。而且每个 map 在创建时都会初始化一个安全随机种子,哈希函数会将这个种子与 key 的内容混合起来计算最终的哈希值(也就是说同一个 key 在不同的 map 实例中,哈希值是完全不同的)。
二、关于扩缩容
对于 map来说,还有一个重点的问题,就是扩缩容。 生成一个 map,不可能预生成无限的 槽空间(尤其是在一开始元素比较少的时候),同时为了保证 map 常数时间的读写复杂度。 所以当空间不够(空间太大),或者元素太空(太空,就意味着浪费空间。对于某些实现,比如 go 来说还意味着查询效率降低)的时候,一般会进行 map空间的扩缩容。
槽空间的变动免不了要对元素进行 rehash, 对于少量的元素不是问题。但是如果一个 map 中有大量的元素,比如说十万、百万级别,一次性 rehash, 那服务基本上就要卡住了。所以很多 map 在实现的时候都或多或少采用了渐进式 reash 的方式。 通过把大量元素的 rehash 过程平摊到多个操作上,避免了集中式 rehash 带来的短时间内性能开销。
渐进式 hash 优点是有了,缺点也是有的。那就是逻辑变复杂了,rehash 时需要维护新旧两个 hash table,还需要考虑在 rehash 时元素遍历、删除、增加等操作问题。
redis的map采用两个hashTable 来进行渐进式 rehash. 每当对map 进行操作的时候顺带rehash 一个槽空间的元素。
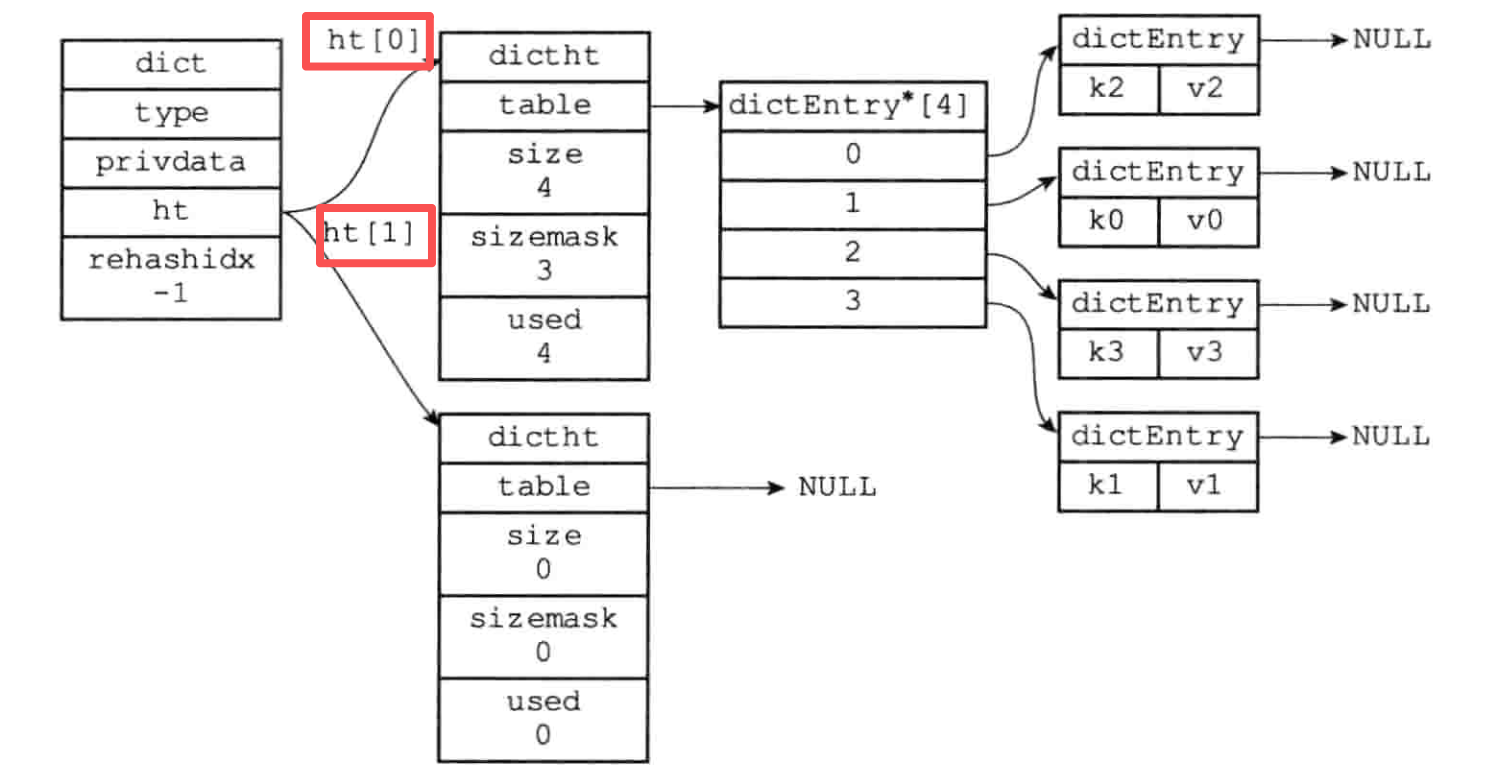
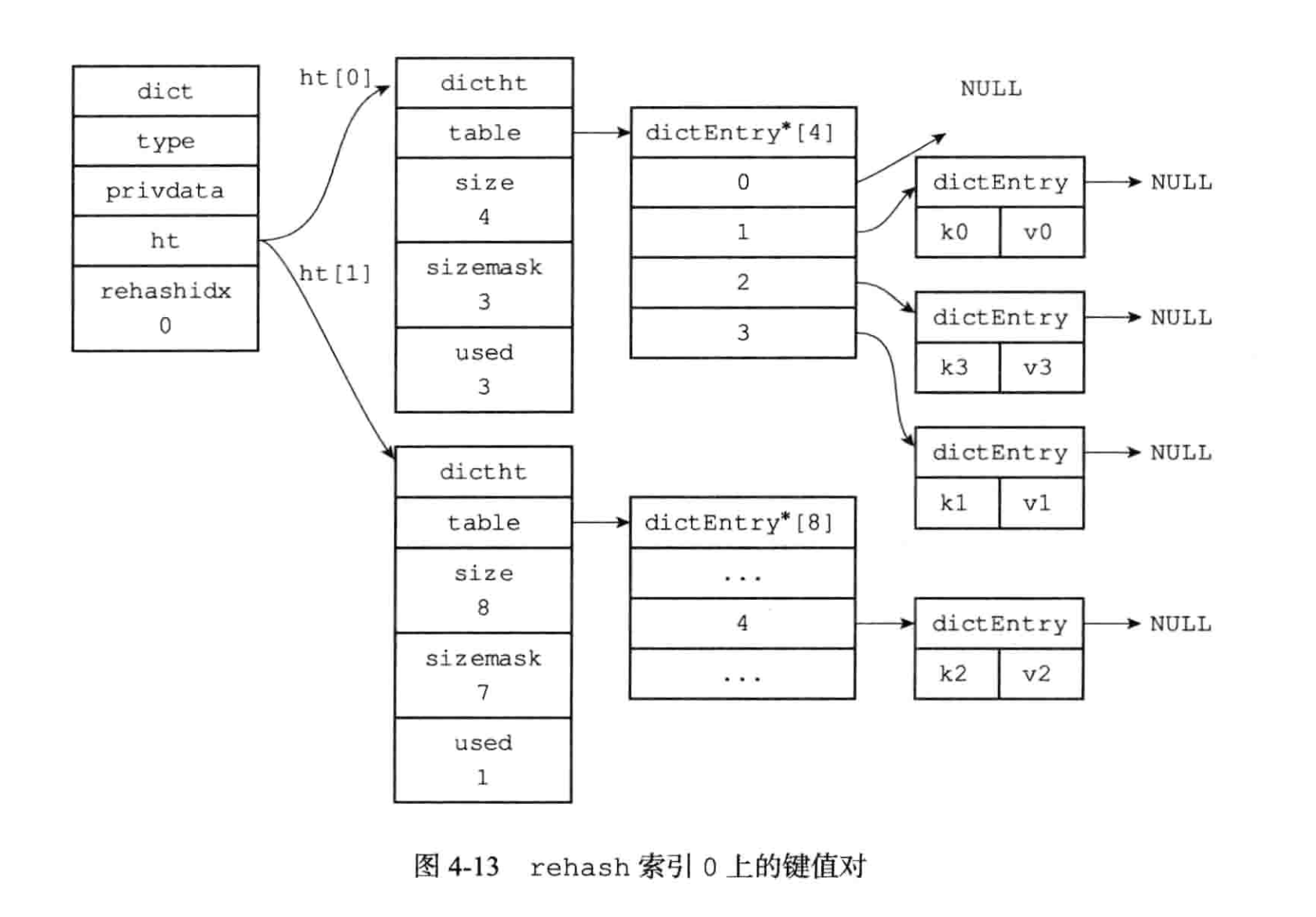
除了扩容,redis 在负载因子较小的时候也会发生类似的缩容操作。
redis map一般很少遍历,这里简单提一下,对于 redis 的 map 来说,如果在scan 的过程中发生了 rehash, 那么 redis不会漏元素,但是有可能会返回重复的元素。 如果在 rehash 期间发生了新增,这些新增的数据不保证会返回【3】。
go 在负载过多的时候也会进行扩容。 如下图所示,增量扩容主要是为了扩展空间(桶扩一扩)。
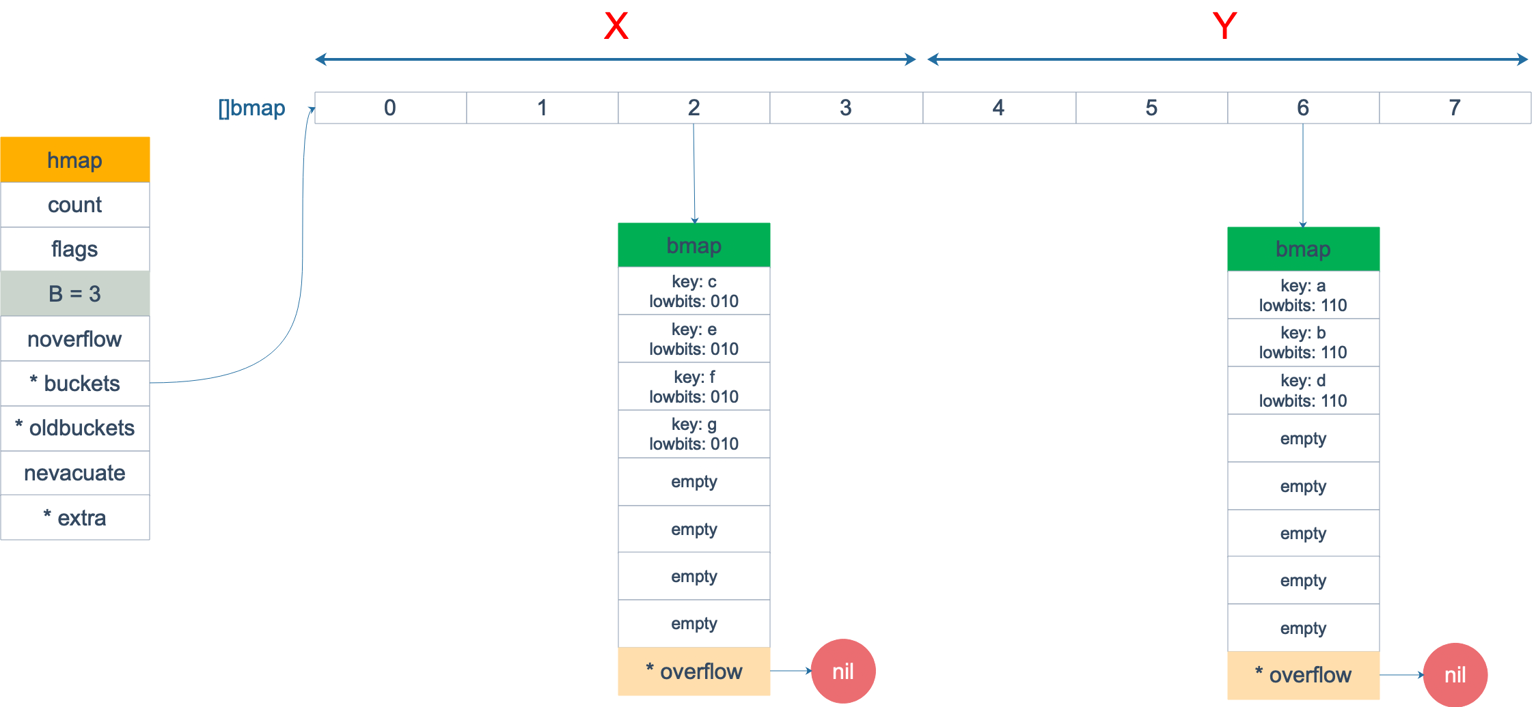
由于 go中链表中的是一个 8 个元素的数组,所以除了普通的增量扩容 rehash,还有一种等量rehash 。 等量 rehsh 主要是为了压缩元素位置(元素压一压),使元素之间更紧实(因为随着元素的插入、删除,链表中会有多个元素,但是每个元素都很空,严重影响查询效率)。 如下图。
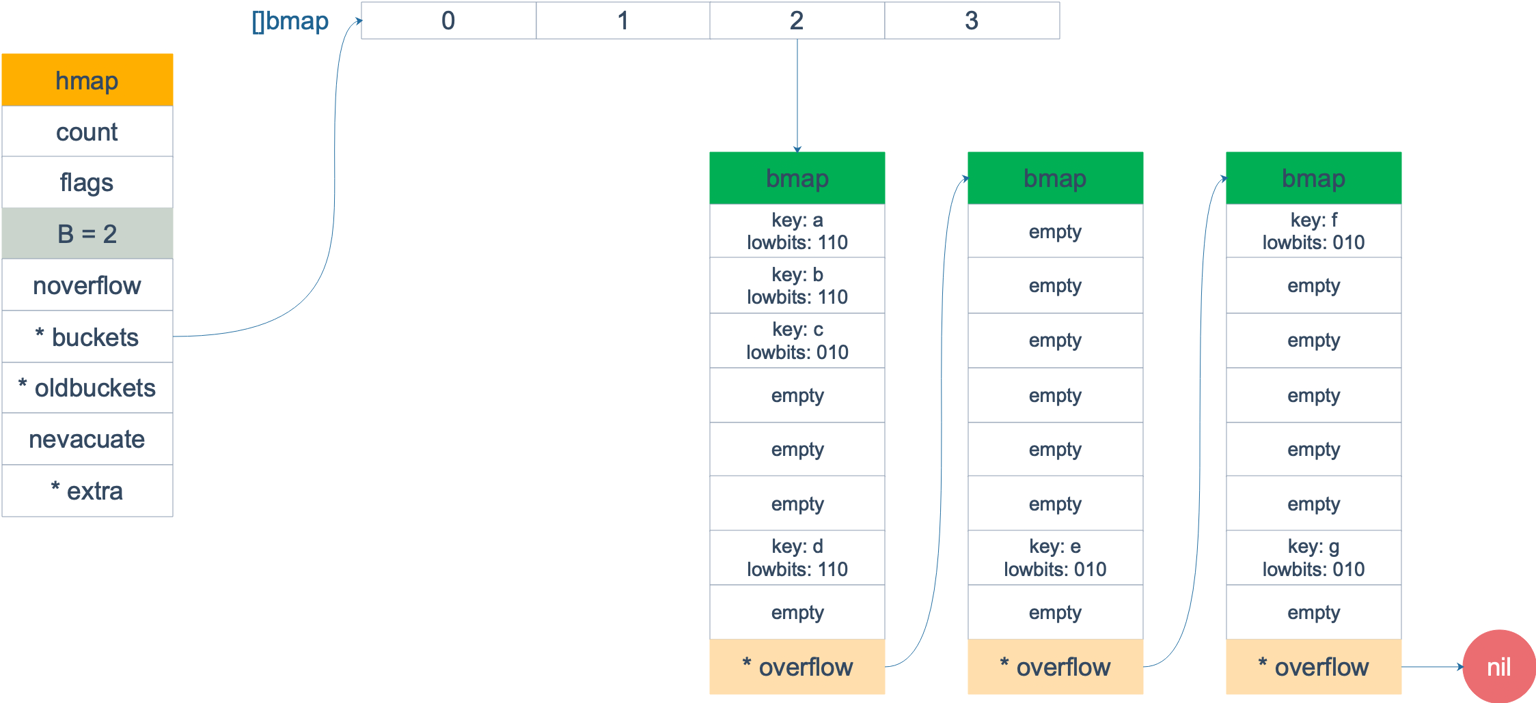
等量扩容前, 每个 bmap 显得很空。
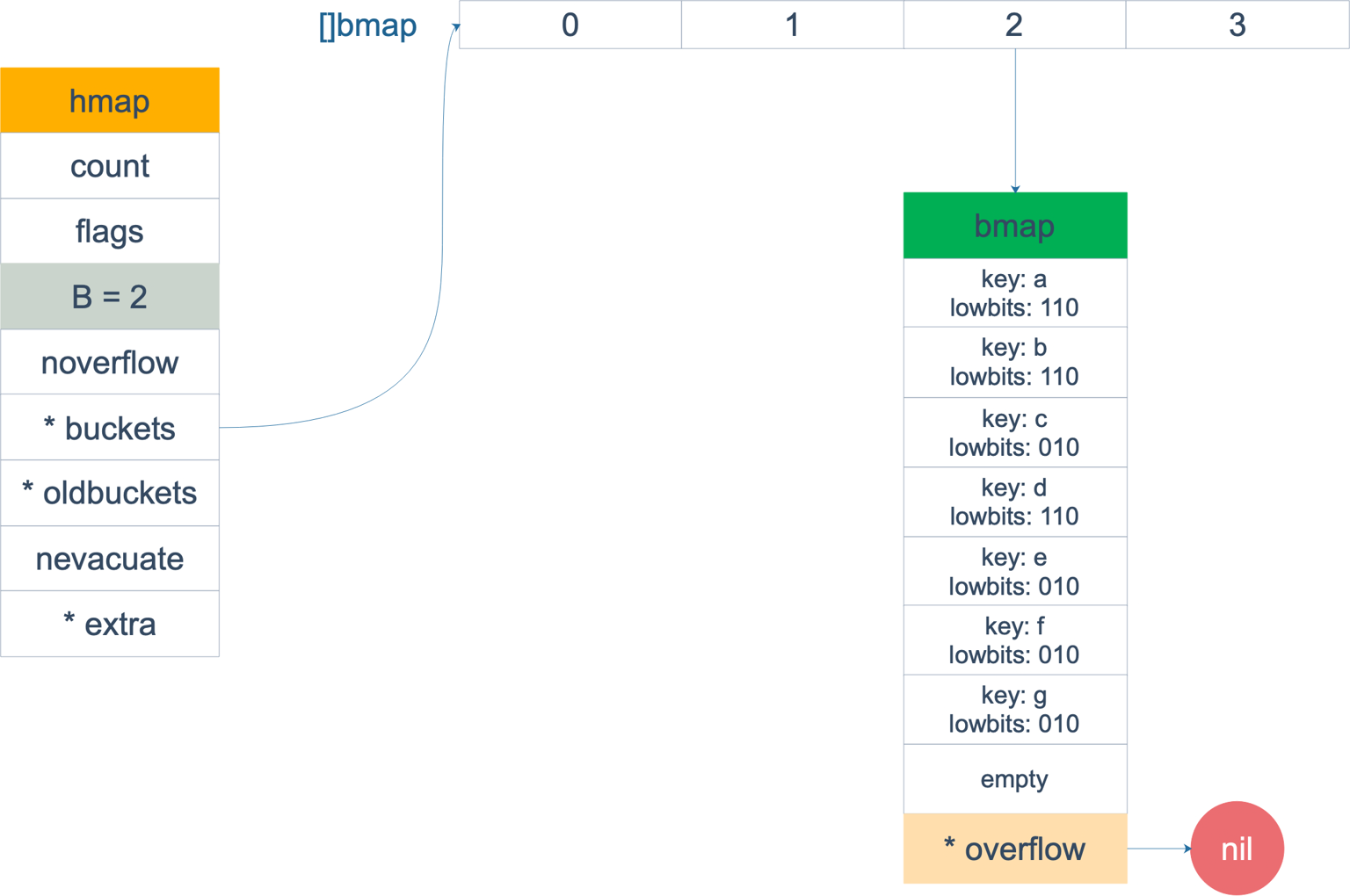
等量扩容后,压缩到同一个 bmap, 变得紧实多了。
和 redis 不同,**go 没有主动缩容的机制,因此如果map中删除了大量的元素,空间可能会浪费。这是 go的一种权衡,避免对go 频繁的扩缩容带来性能的影响。**而且大多数场景下,map 的键值对数量是 "相对稳定" 或 "增长" 的。
和redis 类似,如果go map 在 rehash 阶段发生了新增元素,在遍历的时候不保证能遍历到这个新元素。但是在遍历的时候如果删除元素,后续是遍历不到的。 不过在开发的过程中尽量不要这样操作,可读性不好,还会有隐患。
这里多说一点,其实对于大部分map 来说,元素数量其实是比较少的,即使不采用渐进式 rehash 也是 ok 的,go这里之所以这么设计,估计主要是为了为了配合Go 整体的低延迟目标。
对于java hashMap来说,它没有采用渐进式 rehash, 在需要扩容的时候直接集中式一次性扩容。之所以不使用渐进式 rehash, 可能是基于如下考虑:
- API 兼容性与历史包袱问题(迭代器的一致性保证,迭代过程中,如果 HashMap 被修改(除了迭代器自己的 remove() 方法),会立即抛出 ConcurrentModificationException(快速失败机制)) 网上找的,这里我也没有过多探究 ,╮(╯▽╰)╭)
- hashMap已经做了一部分的优化(如同一个槽上挂的key 比较多时,采用红黑树来提高查询性能),
- 渐进式 rehash 的复杂性
后记
常数时间的读写复杂度用起来挺爽,但是在实现时也却有不少地方要斟酌考虑的。
参考
【1】《Redis 设计与实现》
【3】redis scan