双臂机器人操作的深度模仿学习【文献解读】
原文标题 : Deep Imitation Learning for Bimanual Robotic Manipulation
发表会议 : NeurIPS 2020
作者 : Fan Xie, Alexander Chowdhury, M. Clara De Paolis Kaluza, Linfeng Zhao, Lawson L.S. Wong, Rose Yu
一、文献解决的关键科学问题与技术挑战
1.1 研究背景
机器人操作(Robotic Manipulation)是机器人学中最基础且最具挑战性的能力之一。尽管单臂操作已在工业场景中取得广泛应用,双臂协同操作(Bimanual Manipulation)仍然是该领域的核心难题。双臂操作任务要求机器人同时控制两只机械臂协调配合,完成如抬举大型物体、装配零件等复杂动作,其难度远超单臂操作。
1.2 关键科学问题
本文聚焦于以下核心科学问题:
如何在连续状态-动作空间中,使机器人通过模仿学习有效地习得双臂协同操作技能,并将所学技能泛化到不同空间位置的物体上?
这一问题可分解为三个层面的技术挑战:
挑战一:高维复杂交互动力学建模。 双臂操作涉及两只机械臂与物体之间复杂的多体交互,包括接触力、摩擦力、力矩传递等物理效应。传统的基于解析模型的控制方法难以精确描述这些动力学特性,尤其在物体几何参数和初始位姿存在不确定性时。
挑战二:多模态动力学的有效分解。 一个完整的双臂操作任务(如抬举桌子)包含多个具有不同动力学特征的阶段------抓取、移动、抬升、伸展、放置、撤回。这些阶段(即运动基元,Movement Primitives)之间的动力学特性差异显著,单一模型难以同时精确建模所有阶段。
挑战三:空间泛化能力的提升。 在实际应用中,被操作物体的位置不可能与训练时完全一致。如何使学习到的策略模型能够泛化到训练分布之外的物体位置,是模仿学习走向实用的关键瓶颈。本文的核心假说是:对环境中的关系信息(Relational Information)进行显式建模,可以显著提升策略的泛化能力。
二、研究方法与算法原理
2.1 整体框架:层次化深度关系模仿学习(HDR-IL)
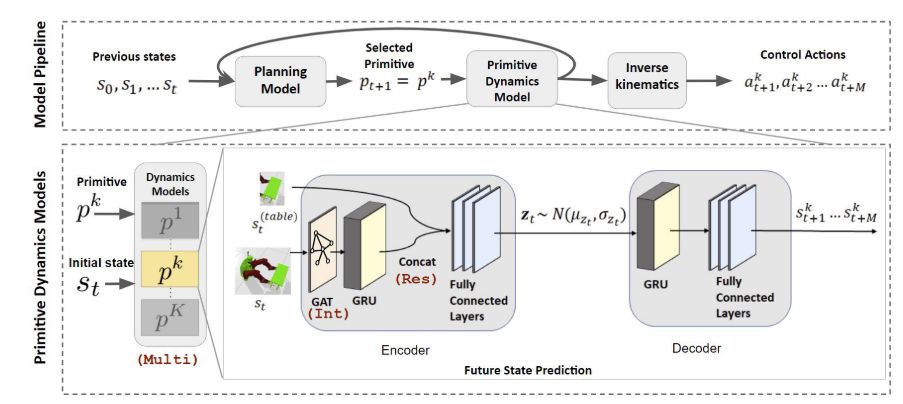
本文提出了层次化深度关系模仿学习框架(Hierarchical Deep Relational Imitation Learning, HDR-IL),其核心思想是将复杂的双臂操作策略分解为层次化的模块化架构,并通过图神经网络捕获实体间的关系信息。整体框架由两个层次组成:
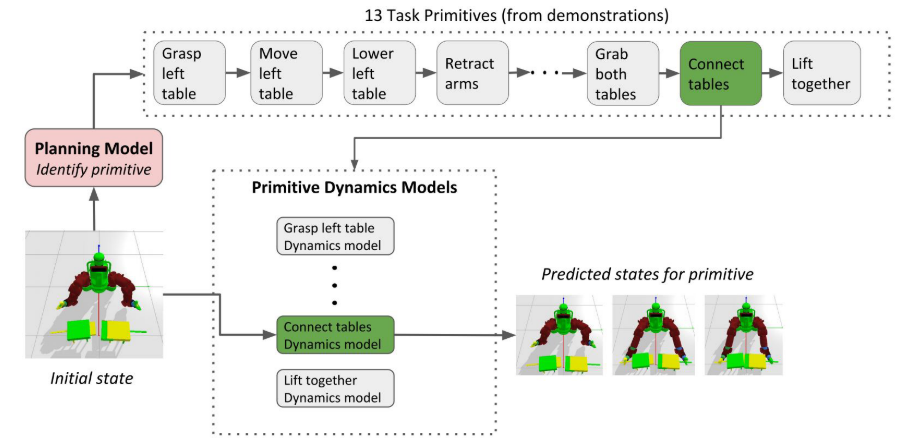
- 高层规划器(High-level Planner):根据当前观测到的状态序列,预测当前应执行的运动基元(Primitive)类别,实现任务的时序分解与调度。
- 低层动力学模型(Low-level Dynamics Model):针对每种运动基元,使用专用的循环图神经网络预测未来若干时间步的状态轨迹,并结合逆运动学求解器将其转换为机器人关节控制指令。
图1:HDR-IL模型执行表的"钉入孔"构造的示例。完成此任务的基元的轨迹显示在最上面的行中。从演示中学习高级基元的序列。基于识别的基元预测状态轨迹。基元的最终预测状态成为下一个基元的初始状态。
2.2 问题形式化
本文将双臂操作建模为马尔可夫决策过程(Markov Decision Process, MDP),定义为元组 ⟨ S , A , T , R , γ ⟩ \langle \mathcal{S}, \mathcal{A}, T, R, \gamma \rangle ⟨S,A,T,R,γ⟩,其中:
- S \mathcal{S} S 为连续状态空间,包含机器人末端执行器、被操作物体的位置和姿态(以四元数表示);
- A \mathcal{A} A 为连续动作空间,即机器人各关节的目标角度;
- T : S × A → Δ ( S ) T: \mathcal{S} \times \mathcal{A} \rightarrow \Delta(\mathcal{S}) T:S×A→Δ(S) 为状态转移函数;
- R : S × A → R R: \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R} R:S×A→R 为奖励函数;
- γ \gamma γ 为折扣因子。
系统的状态表征包含场景中所有实体(左右末端执行器、物体各关键点)的三维坐标 ( x , y , z ) (x, y, z) (x,y,z) 和四元数姿态。
2.3 低层动力学模型
低层动力学模型是框架的核心组件,采用序列到序列 (Sequence-to-Sequence)架构,结合变分自编码器(Variational Auto-Encoder, VAE)生成隐状态:
Z t ∼ N ( μ z t , σ z t ) Z_t \sim \mathcal{N}(\mu_{z_t}, \sigma_{z_t}) Zt∼N(μzt,σzt)
编码器-解码器均使用门控循环单元(GRU)作为骨干网络,隐状态维度为 512--1024。模型的三大关键创新设计如下:
2.3.1 图注意力网络捕获关系特征(Int)
为显式建模场景中各实体间的交互关系,本文引入图注意力网络(Graph Attention Network, GAT)。将场景中的每个实体(如左/右末端执行器、物体的各个关键点)视为图的节点,构建完全连接图。GAT 的注意力机制自适应地学习节点间的交互强度:
边注意力系数计算:
e u v ( l ) = LeakyReLU ( a ( l ) ( W ( l ) h u ( l ) ∥ W ( l ) h v ( l ) ) ) e_{uv}^{(l)} = \text{LeakyReLU}\left(\mathbf{a}^{(l)} \left(\mathbf{W}^{(l)} h_u^{(l)} \| \mathbf{W}^{(l)} h_v^{(l)}\right)\right) euv(l)=LeakyReLU(a(l)(W(l)hu(l)∥W(l)hv(l)))
其中 W ( l ) \mathbf{W}^{(l)} W(l) 为第 l l l 层的可学习权重矩阵, a ( l ) \mathbf{a}^{(l)} a(l) 为注意力参数向量, ∥ \| ∥ 表示向量拼接操作。
注意力权重归一化:
α u v = softmax ( e u v ) = exp ( e u v ) ∑ w ∈ N u exp ( e u w ) \alpha_{uv} = \text{softmax}(e_{uv}) = \frac{\exp(e_{uv})}{\sum_{w \in \mathcal{N}u} \exp(e{uw})} αuv=softmax(euv)=∑w∈Nuexp(euw)exp(euv)
节点特征更新:
h u ( l + 1 ) = σ ( ∑ v ∈ N u α u v W ( l ) h v ( l ) ) h_u^{(l+1)} = \sigma\left(\sum_{v \in \mathcal{N}u} \alpha{uv} \mathbf{W}^{(l)} h_v^{(l)}\right) hu(l+1)=σ(v∈Nu∑αuvW(l)hv(l))
其中 σ \sigma σ 为非线性激活函数, N u \mathcal{N}_u Nu 为节点 u u u 的邻居集合。
2.3.2 残差跳跃连接(Res)
本文设计了一条从目标物体特征到 GRU 最终隐层的残差连接(Residual/Skip Connection),使目标物体的状态信息可以直接传递到动力学预测的输出端。这一设计的直觉是:在操作任务中,末端执行器的最终目标位置与被操作物体的位置高度相关,残差连接有助于网络更高效地学习目标导向的动力学。
2.3.3 模块化多模型架构(Multi)
不同于使用单一网络建模所有运动阶段,本文为每种运动基元(Primitive)分配独立的神经网络模块。例如,在抬桌任务中定义了六种基元:抓取(Grasp)、移动(Move)、抬升(Lift)、伸展(Extend)、放置(Place)、撤回(Retract),每种基元由独立的动力学模型负责预测。这种模块化设计使每个子网络可以专注于学习特定时段的动力学特征,有效避免了多模态动力学之间的相互干扰。
2.3.4 逆运动学控制器
低层模型预测的是末端执行器和物体的未来状态轨迹(位置和姿态),而非直接的关节角度指令。本文通过逆运动学求解器 (Inverse Kinematics, IK)将预测的状态序列 ( s t k , s t + 1 k , ... ) (s_t^k, s_{t+1}^k, \dots) (stk,st+1k,...) 转换为机器人各关节的目标角度 ( a 1 k , a 2 k , ... ) (a_1^k, a_2^k, \dots) (a1k,a2k,...),从而生成可执行的运动控制指令。
2.4 高层规划器
高层规划器定义为从观测状态序列到运动基元标签的映射:
π h : S → P \pi_h: \mathcal{S} \rightarrow \mathcal{P} πh:S→P
其中 P = { p 1 , p 2 , ... , p K } \mathcal{P} = \{p^1, p^2, \dots, p^K\} P={p1,p2,...,pK} 为预定义的 K K K 种运动基元集合。规划器采用与低层模型相同的 GAT 架构,但不包含残差跳跃连接,其输出为当前时刻应执行的基元类别的概率分布。
2.5 训练策略
高层规划器和低层动力学模型分别独立训练,均采用有监督学习方式:
- 高层规划器 :以专家演示中标注的基元标签为监督信号,使用交叉熵损失函数(Cross-Entropy Loss)进行分类训练。
- 低层动力学模型 :以专家演示中的真实状态序列为监督信号,使用均方误差损失函数(Mean-Square Error, MSE)进行回归训练:
L = 1 T ∑ t = 1 T ∥ s ^ t − s t ∥ 2 \mathcal{L} = \frac{1}{T}\sum_{t=1}^{T} \| \hat{s}_t - s_t \|^2 L=T1t=1∑T∥s^t−st∥2
其中 s ^ t \hat{s}_t s^t 为模型预测的状态, s t s_t st 为演示中的真实状态。
训练使用 Adam 优化器,批次大小为 70--130,训练轮次为 12,000--19,000,学习率范围为 1 × 10 − 5 1 \times 10^{-5} 1×10−5 至 2 × 10 − 4 2 \times 10^{-4} 2×10−4。
图2:HDR-IL Pipeline:规划模型从任务的演示中学习基元序列
2.6 技术路线总览
整体技术路线可概括为以下流程:
- 数据采集:在 PyBullet 物理仿真环境中,通过人工遥操作或脚本控制 Baxter 双臂机器人执行操作任务,采集大量专家演示数据;
- 数据标注:对演示轨迹进行分段,手动标注每段对应的运动基元类型;
- 高层规划器训练:使用标注数据训练基元分类器;
- 低层动力学模型训练:按基元类型分组,分别训练独立的动力学预测网络;
- 在线推理与执行:部署时,高层规划器根据当前观测实时选择基元,低层模型预测状态轨迹,IK 求解器生成关节指令,形成闭环控制。
三、实验设计与结果分析
3.1 实验环境
实验在 PyBullet 物理仿真引擎 中搭建,使用 Baxter 双臂机器人(每臂 7 自由度)模型。仿真环境中包含机器人 URDF 模型和被操作物体的三维模型,状态信息包括各实体的三维坐标和四元数姿态。
3.2 任务一:桌子抬升(Table Lifting)
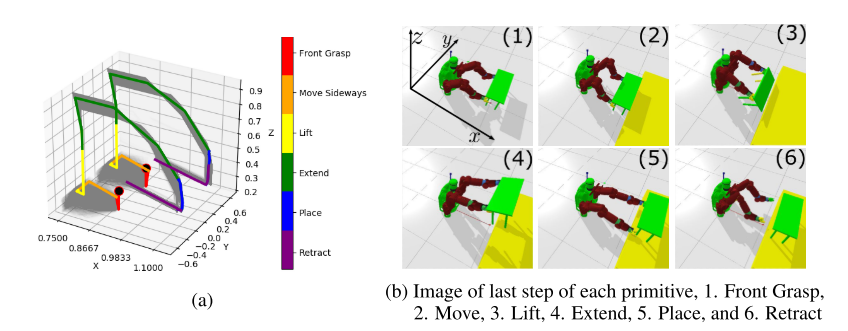
任务描述:Baxter 机器人需要使用双臂协同将一张桌子(尺寸 35cm × 85cm)从初始位置抬升并放置到目标平台上。该任务包含六个运动基元阶段:抓取(Grasp)→ 移动(Move)→ 抬升(Lift)→ 伸展(Extend)→ 放置(Place)→ 撤回(Retract)。
数据集:采集 2,500 条专家演示轨迹,训练与测试使用不同的桌子初始位置以评估泛化能力。
图3:抬桌任务的演示。图(a)显示了2500个演示的左右抓手(x,y,z)中的训练轨迹。一个样本轨迹以彩色显示,以突出显示每个基元的轨迹,而其余的是灰色。黑点是开始位置。图(b)显示了在我们的模拟器中执行的任务。每个图像代表每个基元的最后一步。
基线模型对比:
| 模型 | 图结构 | 跳跃连接 | 多模型 | 欧氏距离 | 角度距离 | DTW距离 | 成功率 |
|---|---|---|---|---|---|---|---|
| GRU-GRU | --- | --- | --- | 6.53±7.05 | 0.139±0.182 | 0.135 | 13% |
| Res | --- | ✓ | --- | 7.74±5.88 | 0.143±0.194 | 0.124 | 13% |
| Int | ✓ | --- | --- | 6.67±5.80 | 0.145±0.177 | 0.123 | 17% |
| ResInt | ✓ | ✓ | --- | 5.64±5.17 | 0.121±0.205 | 0.128 | 72% |
| Res Multi | --- | --- | ✓ | 4.97±5.83 | 0.123±0.191 | 0.121 | 92% |
| HDR-IL | ✓ | ✓ | ✓ | 5.01±5.33 | 0.112±0.208 | 0.119 | 100% |
关键发现:
单独使用图注意力网络(Int)或残差连接(Res)的提升有限,成功率仅从 13% 分别提升至 17% 和 13%。但两者结合(ResInt)后成功率跃升至 72%,表明关系建模与目标导向设计具有显著的互补效应。进一步引入模块化多模型架构后,HDR-IL 实现了 100% 的成功率,相比基线 GRU-GRU 的 13% 提升了近 8 倍。
在各基元的逐段误差分析中(表5),HDR-IL 在 Grasp、Move、Lift、Place 阶段均取得最低误差,但在 Extend(伸展)阶段误差仍然较高(12.78±8.71),这归因于该阶段步幅较大导致动力学预测累积误差增大。
3.3 任务二:榫卯装配(Peg-in-Hole)
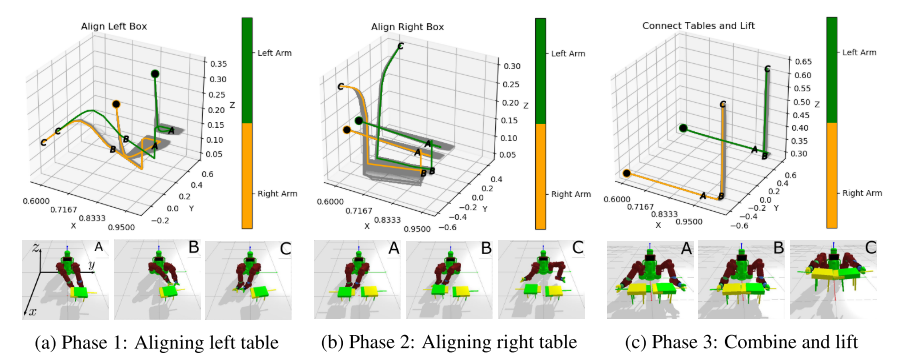
任务描述:机器人需要将两块桌子(各 35cm × 42.5cm)对齐拼合后同时抬起,模拟精密装配场景。该任务涉及更复杂的多阶段协同操作。
数据集:采集 4,700 条专家演示轨迹。
图4:钉入孔任务中夹持器xyz坐标的轨迹。最上面的一行总结了三个阶段发生的动作。3D图中的黑点代表起点。字母对应于底部图像。此任务的提升成功定义为两个表均匀地高于地面,这只有在两个表连接时才能实现。
实验结果:
| 模型 | 欧氏距离 | 角度距离 | DTW距离 | 成功率 |
|---|---|---|---|---|
| GRU-GRU | 2.11±1.11 | 0.029±0.022 | 0.121 | 1% |
| ResInt | 1.59±0.83 | 0.024±0.012 | 0.117 | 15% |
| HDR-IL | 0.90±1.01 | 0.013±0.010 | 0.113 | 29% |
HDR-IL 在榫卯装配任务中达到 29% 的成功率,虽然绝对数值不高,但相比 GRU-GRU 基线的 1% 提升了 29 倍,表明该任务对泛化能力的要求远高于抬桌任务。误差分析显示,x 轴方向的泛化难度最大,且后期阶段的预测精度下降限制了整体成功率。
3.4 关系数据与绝对坐标的对比
本文还对比了关系型输入(实体间相对位置)与绝对坐标输入的效果。实验发现,结合图结构的绝对坐标输入(ResInt, 72%)远优于纯关系型输入(Res Relational, 16%),表明图注意力网络能够有效地从绝对坐标中自动提取关系特征,而手工设计的相对坐标反而丢失了全局位置信息。
四、主要创新点与学术贡献
4.1 创新点一:层次化深度关系模仿学习框架(HDR-IL)
本文首次提出了将层次化架构与关系建模相结合的模仿学习框架,用于解决双臂机器人操作问题。该框架创造性地将任务分解为高层规划(选择执行哪种基元)和低层控制(预测具体状态轨迹)两个子问题,有效降低了学习策略的复杂度。
4.2 创新点二:基于图注意力网络的关系动力学建模
本文提出使用图注意力网络(GAT)显式建模操作场景中各实体之间的交互关系。不同于传统方法将状态向量拼接后直接输入网络,GAT 通过注意力机制自适应地学习实体间的交互强度,使模型能够更好地理解多体操作的物理本质。这一设计是提升泛化能力的关键因素。
4.3 创新点三:残差跳跃连接的目标导向设计
通过将被操作物体的状态特征直接连接到动力学预测的输出端,残差连接使网络能够更高效地学习目标导向的运动模式。这一简洁而有效的设计与图注意力网络形成了强互补效应------两者的组合(ResInt)将成功率从单独的 13--17% 提升至 72%。
4.4 创新点四:模块化多基元动力学建模
为每种运动基元分配独立的动力学模型,避免了单一模型在多模态动力学之间的折衷问题。实验证明,模块化设计将抬桌任务的成功率从 72%(单模型 ResInt)进一步提升至 100%(HDR-IL),验证了任务分解与专门化建模的有效性。
4.5 学术贡献总结
本文的学术贡献可归纳为:
-
方法论层面:提出了一种将图神经网络、变分自编码器、层次化规划和逆运动学控制有机整合的深度学习模仿学习框架,为连续状态-动作空间中的双臂操作提供了有效的解决方案。
-
实验验证层面:在两项具有挑战性的双臂操作任务上进行了系统性的消融实验,充分验证了各模块设计的有效性,并提供了详细的误差分析和泛化性评估。
-
开源贡献:将仿真环境、数据集和模型代码完整开源,为后续双臂操作研究提供了可复现的基准平台。
五、局限性与未来方向
本文作者也指出了当前工作的局限性:
-
依赖完美状态信息:当前框架假设可以获得所有实体的精确位置和姿态。未来工作可结合视觉感知模块,从原始图像中估计物体位姿,实现端到端的视觉-动作策略学习。
-
手动定义运动基元:运动基元的划分依赖人工先验知识。未来可探索自动基元发现方法(如变分推断、隐马尔可夫模型),实现基元的自动学习和分段。
-
仅限仿真验证:实验仅在 PyBullet 仿真环境中进行,尚未在真实机器人上验证。由于仿真与现实之间存在差距(Sim-to-Real Gap),向真实场景的迁移仍是重要的未来工作。
-
榫卯装配任务的成功率有限:在更复杂的 Peg-in-Hole 任务中,HDR-IL 的成功率仅为 29%,说明对于高精度装配类任务,框架仍有较大的改进空间。
六、专业术语对照表
| 英文术语 | 中文翻译 | 简要说明 |
|---|---|---|
| Imitation Learning | 模仿学习 | 通过模仿专家演示来学习策略 |
| Bimanual Manipulation | 双臂操作 | 两只机械臂协同完成操作任务 |
| Movement Primitives | 运动基元 | 操作动作的基本组成单元 |
| Graph Attention Network (GAT) | 图注意力网络 | 基于注意力机制的图神经网络 |
| Variational Auto-Encoder (VAE) | 变分自编码器 | 生成模型,用于学习隐空间表示 |
| Gated Recurrent Unit (GRU) | 门控循环单元 | 一种循环神经网络单元 |
| Inverse Kinematics (IK) | 逆运动学 | 由末端位姿求解关节角度 |
| Residual/Skip Connection | 残差/跳跃连接 | 跨层直连,缓解梯度消失 |
| Dynamic Time Warping (DTW) | 动态时间规整 | 衡量时间序列相似度的算法 |
| Markov Decision Process (MDP) | 马尔可夫决策过程 | 序贯决策的数学框架 |
| Sim-to-Real Gap | 仿真-现实差距 | 仿真策略迁移到真实环境的困难 |
| Hierarchical Architecture | 层次化架构 | 分层组织的多级决策系统 |
七、参考文献
Xie, F., Chowdhury, A., De Paolis Kaluza, M.C., Zhao, L., Wong, L.L.S., & Yu, R. (2020). Deep Imitation Learning for Bimanual Robotic Manipulation. Advances in Neural Information Processing Systems 33 (NeurIPS 2020).