文章目录
-
- 引言
- 一、核心概念:什么是多模态
-
- [1.1 "模态"一词到底指什么](#1.1 "模态"一词到底指什么)
- [1.2 大白话类比:从"读书人"到"生活家"](#1.2 大白话类比:从"读书人"到"生活家")
- [1.3 多模态模型的四个能力层次](#1.3 多模态模型的四个能力层次)
- [1.4 技术原理:多模态模型"看"图的底层机制](#1.4 技术原理:多模态模型"看"图的底层机制)
- [二、Claude vs DeepSeek:多模态能力的分水岭](#二、Claude vs DeepSeek:多模态能力的分水岭)
-
- [2.1 Claude 的多模态:原生"视觉皮层"](#2.1 Claude 的多模态:原生"视觉皮层")
- [2.2 DeepSeek 为什么不是多模态](#2.2 DeepSeek 为什么不是多模态)
- [2.3 架构本质差异:为什么"加个看图功能"没那么简单](#2.3 架构本质差异:为什么"加个看图功能"没那么简单)
- 三、多模态有什么用:六大落地场景
-
- [3.1 场景一:文档智能理解](#3.1 场景一:文档智能理解)
- [3.2 场景二:图表与数据分析](#3.2 场景二:图表与数据分析)
- [3.3 场景三:UI开发------从截图到代码](#3.3 场景三:UI开发——从截图到代码)
- [3.4 场景四:教育与学习辅助](#3.4 场景四:教育与学习辅助)
- [3.5 场景五:医疗影像辅助诊断](#3.5 场景五:医疗影像辅助诊断)
- [3.6 场景六:多模态 Agent------AI 的"完整感官"](#3.6 场景六:多模态 Agent——AI 的"完整感官")
- 四、总结与延伸阅读
引言
想象一下,你在一个只有文字的聊天框里活了一辈子。别人给你描述日落------"红色的、橙色的光洒在云层上"------你每个词都认识,但你从没真正见过。给你一张餐厅账单的照片,你完全不知道上面写了什么,因为你的世界里根本没有"图像"这个概念。
这就是2023年底之前,所有大语言模型的真实处境。
ChatGPT 刚出来的时候,大家惊叹于它的文字能力------写诗、写代码、回答问题,样样精通。但如果你丢给它一张图片,比如一张手绘的UI草图、一张会议白板照片、一张心电图报告,它只能"抱歉,我只能处理文本"。这就像一个智商200的天才,却天生失明。
多模态(Multimodal)AI的出现,给这个天才装上了"眼睛",后来又加上了"耳朵"。本篇文章带你从零理解多模态是什么、它背后的技术原理是什么、为什么 Claude 能"看见"而 DeepSeek 不能,以及这些能力到底能用来干什么。
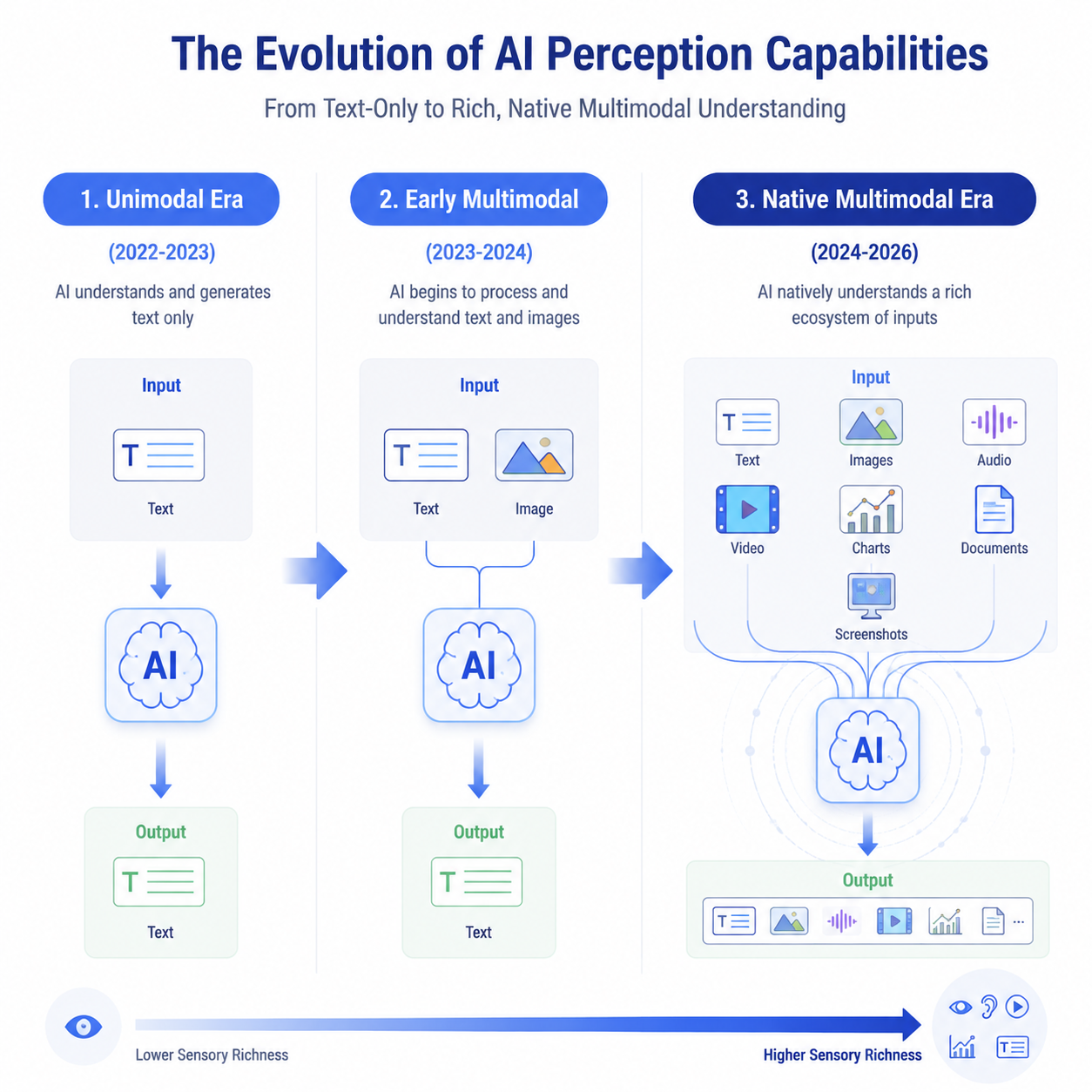
图:AI感知能力的演进------从纯文本的"失明时代"到原生多模态的"完整感官"
一、核心概念:什么是多模态
1.1 "模态"一词到底指什么
在AI领域,模态(Modality)指的是信息的一种独立表现形式。
人类天然是多模态的:我们用眼睛看(视觉模态)、用耳朵听(听觉模态)、用手摸(触觉模态)、用鼻子闻(嗅觉模态)。这些感官各自捕捉不同类型的信息,大脑将它们融合在一起,形成对世界的完整理解。
AI 的模态则主要指:
| 模态类型 | 数据形式 | 典型例子 |
|---|---|---|
| 文本(Text) | 自然语言文字序列 | 一篇文章、一段对话、一段代码 |
| 图像(Image) | 像素矩阵 | 照片、图表、截图、X光片 |
| 音频(Audio) | 波形采样序列 | 语音、音乐、环境声 |
| 视频(Video) | 图像序列 + 音频 | 监控录像、教学视频、直播 |
单模态模型(Unimodal Model) 只能处理其中一种。GPT-3、DeepSeek-V3 都是纯文本模型------你给它们文字,它们回你文字,仅此而已。
多模态模型(Multimodal Model) 则能同时处理两种或以上的模态。Claude 3/4、GPT-4V、Gemini 都属于这一类------你给它们一张图加一段文字,它们能理解两者并给出回答。
1.2 大白话类比:从"读书人"到"生活家"
如果拿人来打比方:
纯文本模型(如 DeepSeek) 像一个从小在图书馆里泡大的人。他读了世界上所有的书,对文字的驾驭能力炉火纯青。但你把他拉到大街上,他认不出红绿灯,看不懂路牌上的箭头,给他一张超市小票他也一头雾水。他的知识全部来自书本,对"真实世界长什么样"没有直接感知。
多模态模型(如 Claude) 则像一个人既博览群书,又有一双好眼睛。他不仅能读文字,还能自己看世界------给他一张建筑照片,他能说出是什么风格;给他一份数据图表,他能分析趋势;给他一张手绘草图,他能理解设计意图。
这就是为什么有些任务,纯文本模型无论参数多大都做不好------不是不够聪明,是缺了一个感官。
1.3 多模态模型的四个能力层次
多模态不是"能不能看图"这么简单的二元问题。实际上,多模态能力可以分四个层次:
第一层:图像描述(Image Captioning)。 给一张图,用文字描述里面有什么。"图中有一个人、一只狗、一棵树"------这是最早期的多模态能力,2015年左右就已经实现。
第二层:图文理解(Vision-Language Understanding)。 不仅能描述,还能理解图中事物的关系、逻辑和含义。比如给一张财报图表,能说出"Q3利润率下降了3个百分点,主要原因是营销费用增长"------这需要真正的"看懂"。
第三层:跨模态推理(Cross-modal Reasoning)。 能综合图像信息和文本信息进行推理。比如给你一张代码截图和一段需求描述:"这个函数的实现和需求文档哪里不一致?"------这需要同时理解图像中的代码和文字中的需求,并做对比分析。
第四层:多模态生成(Multimodal Generation)。 不仅能理解多种输入,还能生成多种输出。比如根据一段文字描述生成一张图片,或者根据一张图片生成一段视频。这是目前最前沿的方向。
Claude 3/4、GPT-4V、Gemini 2.0 这些顶级模型目前主要集中在第二层和第三层,并在向第四层扩展。
1.4 技术原理:多模态模型"看"图的底层机制
要理解为什么有的模型能做多模态、有的不能,需要看一下底层技术架构。
多模态模型的核心设计思路是:用不同的编码器处理不同类型的数据,然后在"语义空间"中把它们对齐。
整个过程分三步:
第一步:各自编码。 文本经过文本编码器(比如一个 Transformer 模型)转成一串数字向量。图像经过图像编码器(通常是一个 Vision Transformer,ViT)也转成一串数字向量。两种向量都捕获了原始内容的"语义"。
第二步:语义对齐。 这是最关键的一步。通过一个对齐层(通常是交叉注意力机制或简单的投影矩阵),把文本向量和图像向量映射到同一个"语义空间"里。在这个空间里,"猫"这个文字和猫的图片在数学上会很接近。
第三步:联合推理。 对齐后的向量一起输入到大语言模型的主干网络中,LLM 同时对文字信息和图像信息进行推理,生成最终回复。
这里面有个关键点:多模态模型不是在 LLM 外面套了一层"看图插件",而是从一开始就同时用文本和图像数据一起训练的。这意味着视觉理解不是事后打补丁,而是模型"母语"的一部分。这也是为什么 Claude 这类原生多模态模型在图像理解上比"纯文本模型+外部OCR"方案要稳定得多。
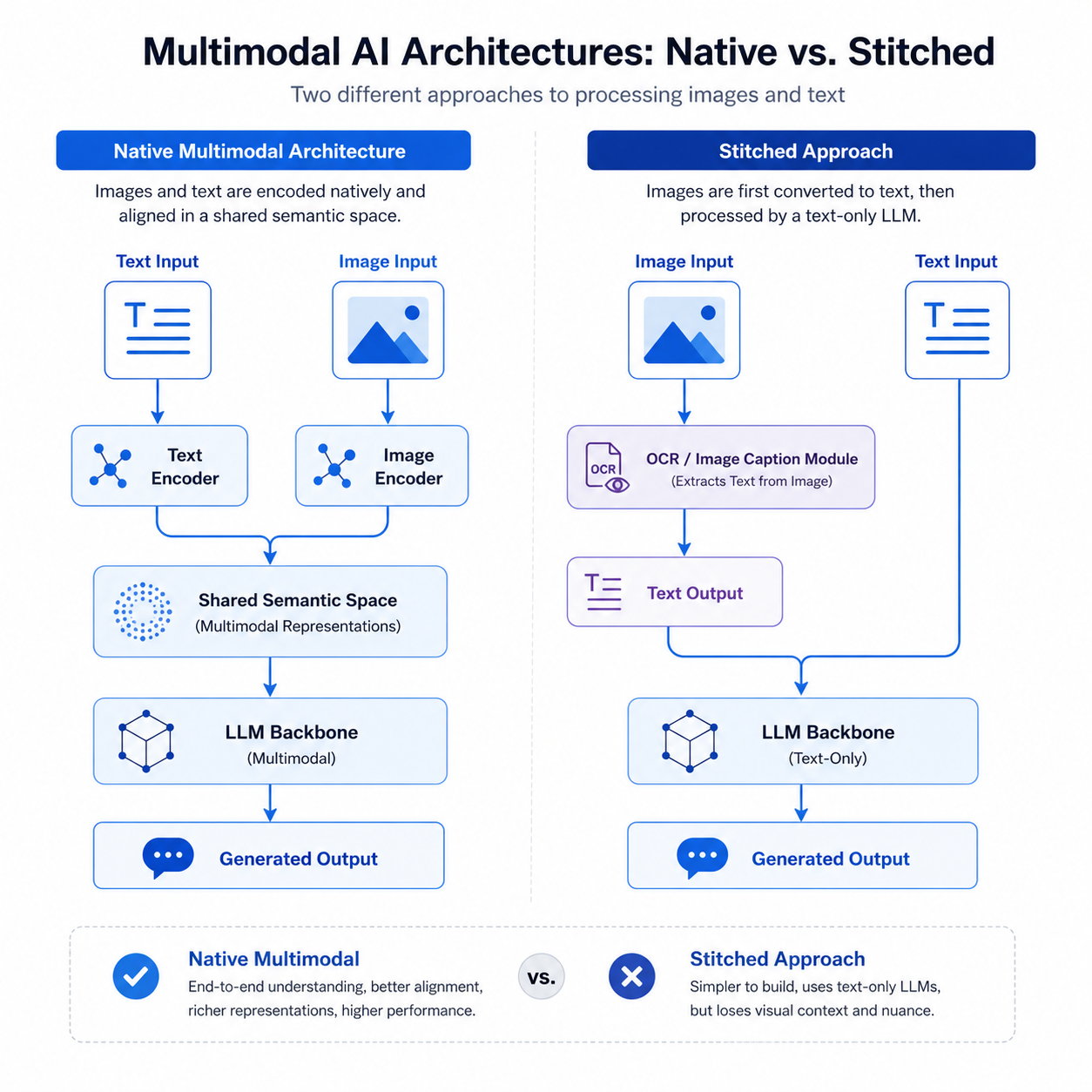
图:原生多模态模型架构 vs 拼接式多模态方案的技术对比
二、Claude vs DeepSeek:多模态能力的分水岭
2.1 Claude 的多模态:原生"视觉皮层"
Claude 从 3.0 版本开始就是原生多模态模型。所谓"原生",指的是它在预训练阶段就同时学习了文本和图像数据,而不是后来再"嫁接"一个视觉模块。
Claude 的多模态能力具体表现在以下几个方面:
能看懂各种图像类型。 照片、截图、图表、手写笔记、PDF 文档、白板照片、UI 设计稿------这些 Claude 都能直接处理。你不需要把图片先 OCR 成文字再喂给它,直接把图片拖进去就行。
能进行精细的视觉推理。 Claude 不仅能看到"图里有什么",还能理解图像中的逻辑关系。比如你给它一张复杂的数据报表截图,它能说出"从这张表来看,华北区 Q2 的营收增速低于全国平均水平,主要拖累因素是线下渠道"------这需要同时理解表格结构、数字含义和业务逻辑。
能处理多图关联。 你可以同时上传多张图片,让 Claude 比较、关联、综合分析。比如上传两个版本的 UI 设计稿,问它"这两个版本在信息架构上有什么差异?"
典型的"多模态能力"测试场景------Claude 能搞定的:
- 上传一张手绘的数据库 ER 图照片,让它生成建表 SQL 语句
- 上传一份合同截图,让它提取关键条款并做风险分析
- 上传一张数学题的照片,让它解题并解释每一步
- 上传一个网页的截图,让它还原出 HTML/CSS 代码
这些能力不是"看图的插件"能做到的------它需要模型在预训练阶段就建立了图像像素和语义概念之间的直接映射。
2.2 DeepSeek 为什么不是多模态
DeepSeek 系列模型(包括最新的 DeepSeek-V3 和 DeepSeek-R1)是纯文本模型(Text-only Model)。它们接受文本输入,产生文本输出,没有视觉模态。
这不是说 DeepSeek 的技术不行------恰恰相反,DeepSeek-V3 在数学推理、代码生成等文本任务上的表现已经逼近甚至超越了 GPT-4。不做多模态是 DeepSeek 的战略选择,而不是技术短板。
这里有几个深层原因:
第一,训练成本。 多模态模型的训练需要海量的图文配对数据(image-text pairs),以及巨大的计算资源来训练视觉编码器和跨模态对齐层。对于一个以"极致性价比"著称的团队来说,把资源集中在文本能力的深度上,比分散到多模态上 ROI 更高。
第二,专注带来深度。 DeepSeek 选择了一条"把文本推理做到极致"的路线。DeepSeek-R1 在数学和编程上的推理能力是行业顶尖的------而这恰好是纯文本能力。当你把模型容量全部用于文本时,在文本上的表现自然会更好。这是一个"通用但不够深"vs"专注但足够深"的取舍。
第三,开源策略。 DeepSeek 是开源的,而且更注重让社区能低成本部署和微调。纯文本模型在推理部署上比多模态模型简单得多------不需要图像预处理管线、不需要 GPU 做视觉编码。这对于"让每个人都能在自己的服务器上跑起来"的目标更友好。
用一个类比来理解:
如果说 AI 模型是一个运动员,那多模态模型(如 Claude)就像十项全能选手------跑步、跳高、标枪都会,但每一项不一定是最顶级的。DeepSeek 则像专项运动员------就练100米,在这个项目上跑到世界前三。两种策略没有高下之分,只是目标不同。
2.3 架构本质差异:为什么"加个看图功能"没那么简单
很多人会问:"既然 DeepSeek 推理能力这么强,给它外面接一个图片识别工具不就行了吗?"
这个问题的答案,恰好揭示了原生多模态和拼接式方案的本质差异。
你当然可以用"DeepSeek + OCR工具 + 图片描述模型"来间接实现"看图"。流程大概是:图片 → OCR提取文字 / 图片描述模型生成文字描述 → 把文字喂给 DeepSeek → 得到回复。
但这和原生多模态有本质区别:
| 维度 | 原生多模态(Claude/GPT-4V) | 拼接方案(DeepSeek + 外部工具) |
|---|---|---|
| 视觉理解深度 | 直接建立像素→语义的映射 | 依赖中间文字描述,丢失丰富细节 |
| 图文关联推理 | 可同时推理图中多个区域的关联 | 文字描述是线性的,难以表达空间关系 |
| 图表/布局理解 | 精准理解表格结构、UI布局 | OCR后丢失位置信息和结构关系 |
| 手写/模糊内容 | 靠视觉上下文"脑补"识别 | OCR对模糊、手写内容识别率低 |
| 推理延迟 | 单次模型调用完成 | 多次串行调用,延迟叠加 |
| 错误累积 | 端到端,无中间环节 | OCR错 → 理解错,错误逐级放大 |
举个例子------给模型一张手绘的数据库 ER 图:
原生多模态模型(Claude) 会:直接"看"到实体框、关系线、字段标注的空间位置关系------"Product 和 Order 之间有一条一对多的连线"------然后直接生成 SQL。
拼接方案 会:先让 OCR 提取图中的文字(可能识别错手写字),再让图片描述模型生成一段文字描述(大概率丢失实体之间的连线关系),然后把这段可能已经有问题的文字喂给 LLM 生成 SQL。每一步都可能出错,而且错误会传递。
这就是为什么,在需要精细视觉理解的场景中,原生多模态模型的能力边界远大于"纯文本模型+工具"的组合。
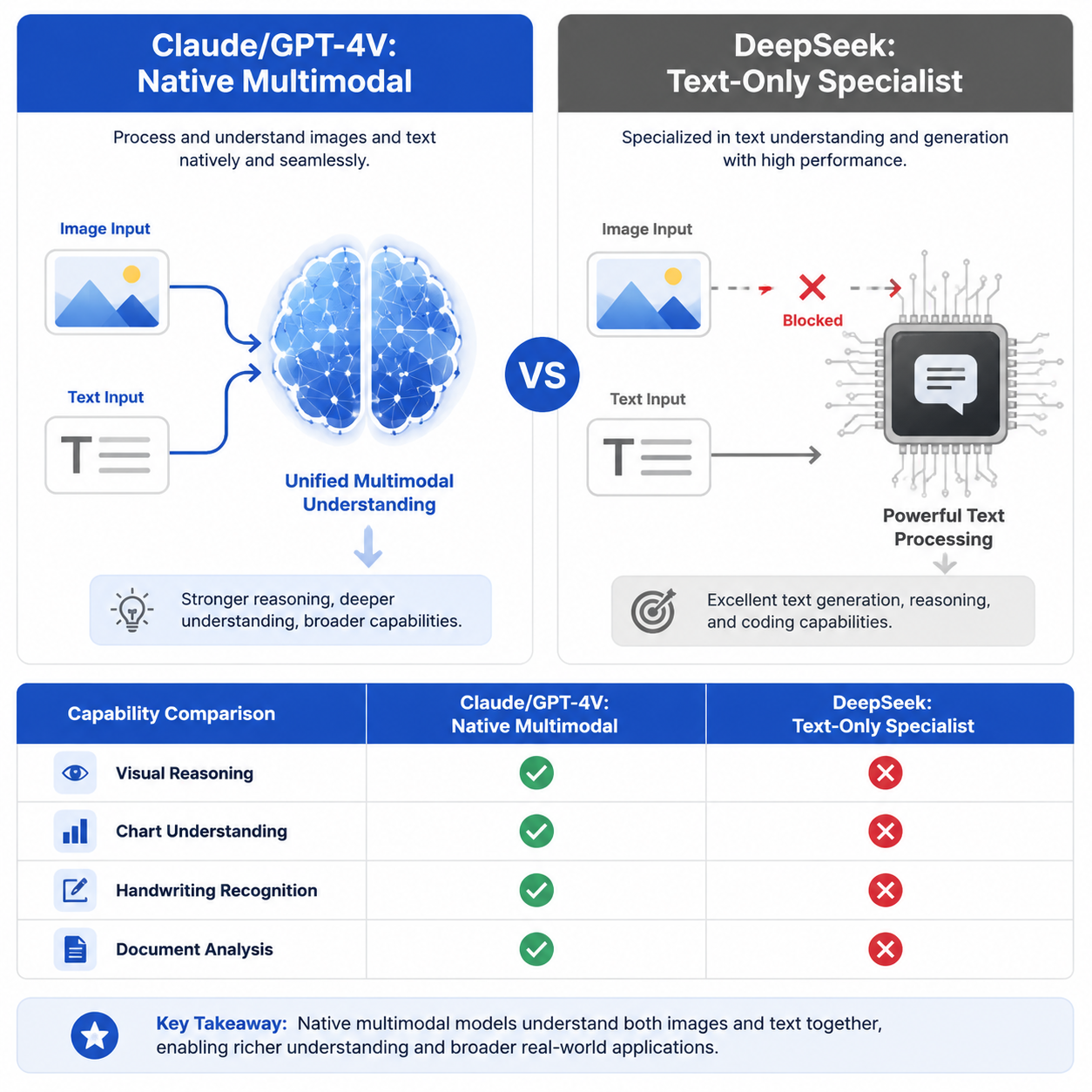
图:原生多模态 vs 纯文本+外部工具------两种技术路线的架构与能力差异
三、多模态有什么用:六大落地场景
理解了"是什么"和"为什么不同",接下来看"能干什么"。多模态不是炫技,它在实际应用中已经产生了真正的价值。
3.1 场景一:文档智能理解
这是目前最成熟、落地最广的多模态应用场景。
企业的合同、发票、报告、简历、病历、法律文书------每天有数以亿计的文档被创建和流转。这些文档中大量信息不光在文字里,还在表格里、印章里、签名字迹里、格式排版里。
多模态模型可以:直接读取 PDF/图片形式的文档,理解表格结构、手写批注、印章位置,然后提取关键信息、检查合规性、生成摘要。
比如你上传一张医疗发票照片,模型能同时看懂:印刷体的医院名称和费用项目、表格中的各项金额及其对应关系、手写体的医生备注、红章的位置和内容。然后一键生成报销单。
3.2 场景二:图表与数据分析
饼图、柱状图、折线图、散点图、热力图------商业报告里充斥着各种图表。以前这些图表是"给人看的",机器处理不了。
多模态模型能够:识别图表类型 → 理解坐标轴含义 → 读取数据值 → 识别趋势和异常 → 生成文字分析。
更进一步,它还能做跨图表关联分析。比如同时上传销售趋势图和营销投入图,问它"这两个图表之间有什么因果关系?"------这需要同时理解两张图的数值、时间轴和业务含义。
3.3 场景三:UI开发------从截图到代码
这是开发者最喜欢的能力。
给模型一张 UI 设计稿或网页截图,它能直接还原出对应的前端代码(HTML/CSS/React/Vue)。不是简单的"颜色取反"那种,而是真正理解设计意图------"这是一个登录表单,包含邮箱输入框、密码输入框和一个主操作按钮"------然后生成语义化的、可维护的代码。
更进一步,你可以上传两张截图:一张"现在的样子",一张"想要的样子",让模型告诉你应该改哪些代码、怎么改。
3.4 场景四:教育与学习辅助
多模态在教育领域的应用正在快速增长:
- 拍一道数学题,模型不是直接给答案,而是看你的解题过程,指出"你在第三步漏掉了分母不为零的前提条件"
- 拍一张课本上的示意图,让模型详细解释图中每个部分的含义
- 上传自己的解题手稿,让模型批改并给出改进建议
- 拍一个物理实验装置,让模型分析实验原理和可能的误差来源
这比纯文字的家教更进一步------模型能看到学生实际写了什么、画了什么。
3.5 场景五:医疗影像辅助诊断
这是多模态 AI 社会价值最高的应用方向之一。
多模态模型可以同时分析多种医疗数据:X 光片、CT 扫描、病理切片图像 + 病历文字描述 + 化验单数据。将这些来自不同"模态"的信息综合分析,辅助医生做出更准确的诊断。
比如:结合肺部 CT 影像(图像模态)和患者病史文字描述(文本模态),判断一个结节是良性还是恶性。单看 CT 或者单看病历都可能信息不完整,综合两者才能做出更准确的判断。
需要注意的是,这目前仍是"辅助"角色------最终诊断必须由专业医生做出。但多模态 AI 作为"永远不累的第二双眼睛",价值是巨大的。
3.6 场景六:多模态 Agent------AI 的"完整感官"
这是和你的上一篇 Agent 文章呼应的内容。
前面讲过,MCP 让 Agent 能调用工具,A2A 让 Agent 之间能通信。但如果 Agent 本身只能处理文字,那它的"感知能力"就有一个巨大的天花板。
多模态 Agent 则不同:它能看、能听、能读。结合 MCP 协议调用各种工具,它的能力边界大幅扩展:
- 一个"运维 Agent"能看懂监控大盘的截图,自动判断是否需要扩容
- 一个"测试 Agent"能看 UI 截图,自动判断是否有样式错乱
- 一个"安全审计 Agent"能看网络拓扑图,自动识别单点故障风险
多模态给 Agent 装上感官,MCP 给 Agent 装上手脚,A2A 让 Agent 能组队------这三者合在一起,才是 Agent 时代的完整图景。
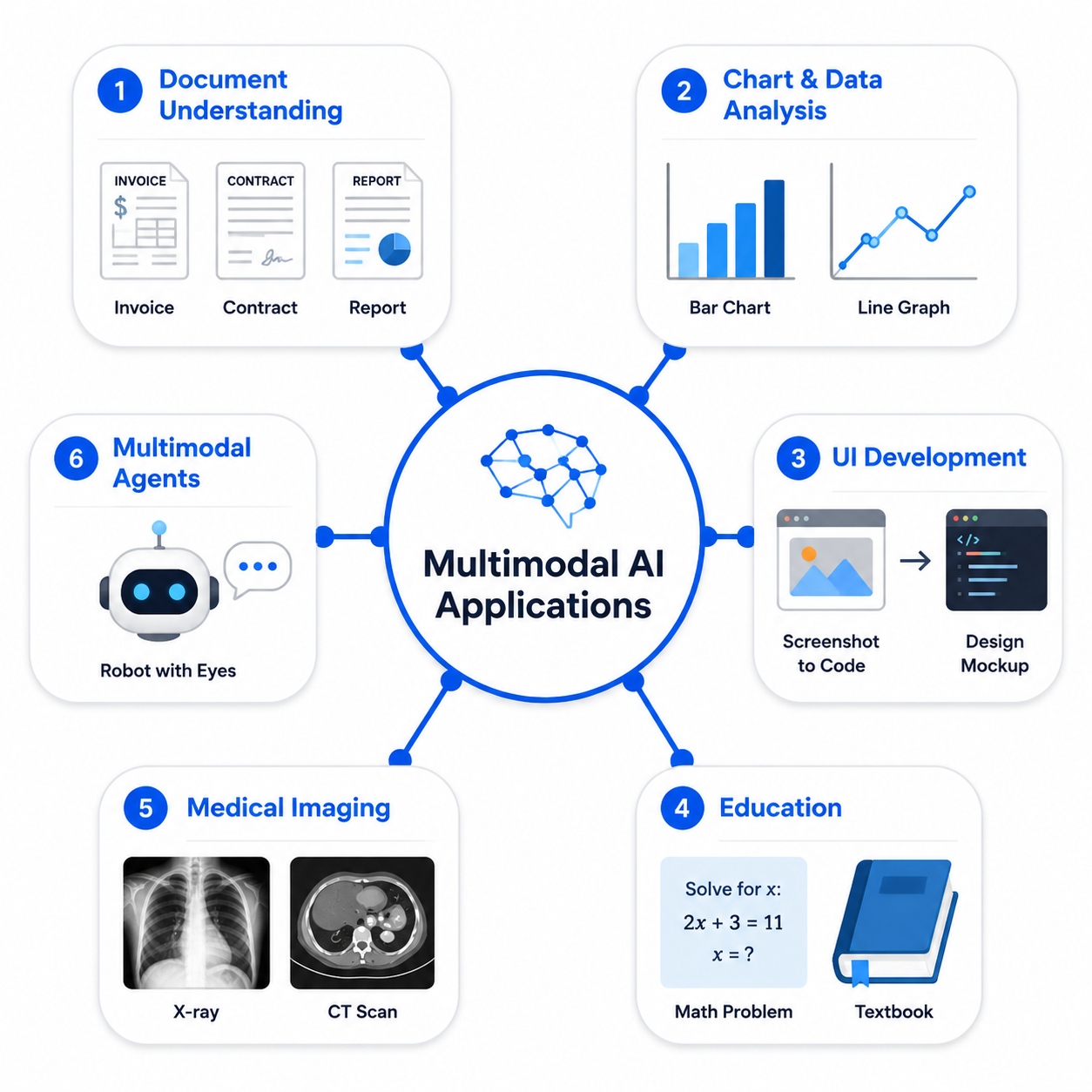
图:多模态AI的六大核心应用场景全景图
四、总结与延伸阅读
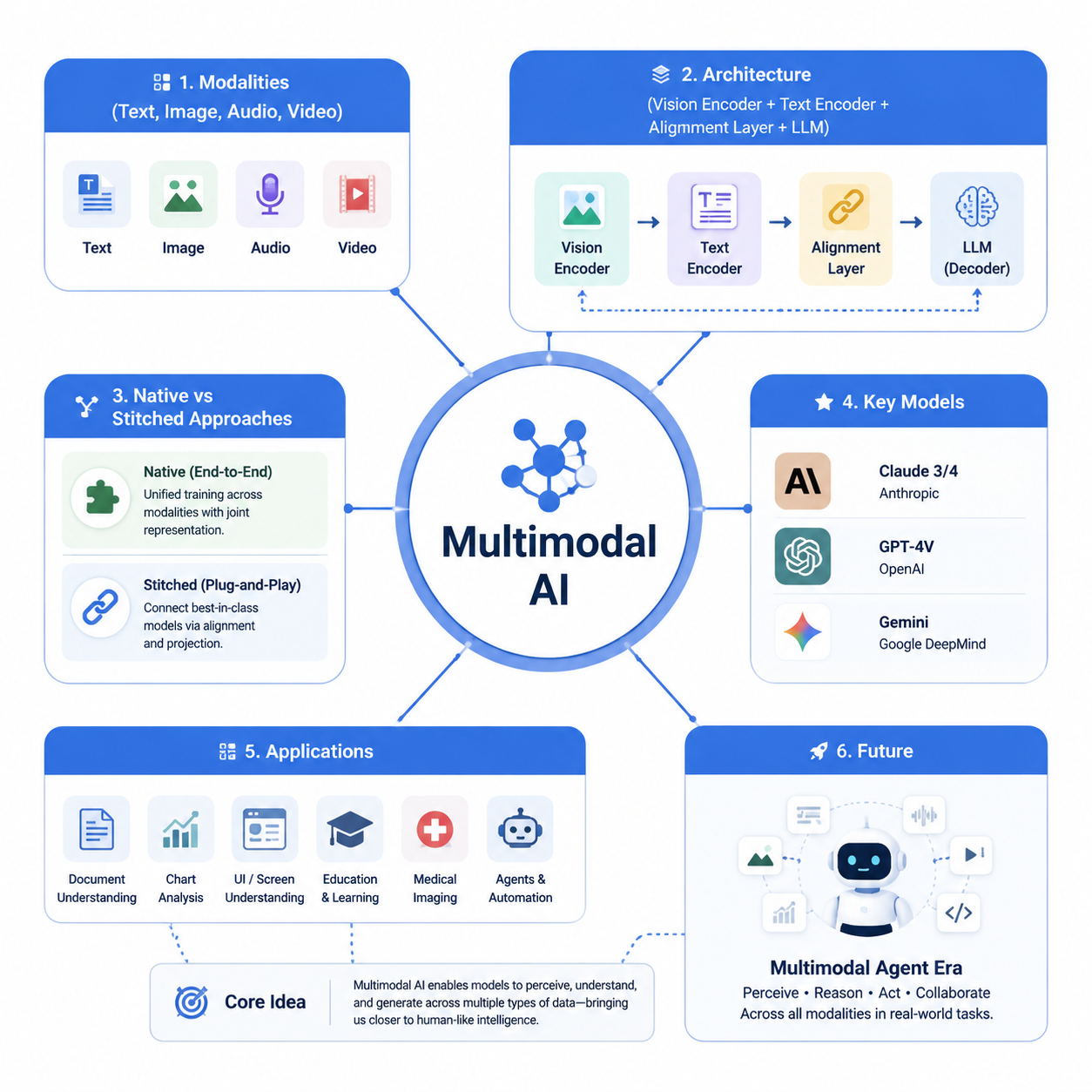
图:多模态AI核心知识体系全景图
总结
- 多模态是 AI 的感官革命。 纯文本模型像一个博学但失明的人------知识渊博但对真实世界的样子没有直接感知。多模态模型装上了"眼睛"(图像理解)和"耳朵"(音频理解),能像人类一样综合多种信息源进行推理。
- 原生多模态 vs 拼接方案有本质区别。 Claude 和 GPT-4V 是从预训练阶段就用图文数据联合训练的,不是"文字模型外面套个看图插件"。这让它们在精细视觉理解(图表、手写、布局、空间关系)上的能力远超拼接方案。
- DeepSeek 不做多模态是战略选择,不是能力不够。 DeepSeek 选择了"把文本推理做到极致"的路线,在数学和编程上做到了顶尖水平。两种路线各有优势,适用于不同场景。
- 多模态正在改变大量行业的运作方式。 文档理解、图表分析、UI 开发、教育、医疗、多模态 Agent------这些不是"未来愿景",而是现在已经能用到的能力。
- 下一站是多模态 Agent 的时代。 当多模态感知 + MCP 工具调用 + A2A 协作协议三者结合,AI Agent 才能真正"像人一样工作"------看到问题、使用工具、与同事协作、完成任务。