内容
- [Knowledge Graph Embedding](#Knowledge Graph Embedding)
- [Abductive Learning](#Abductive Learning)
- Relphormer-汇报
- HAHA
- 画图&草稿
Knowledge Graph Embedding

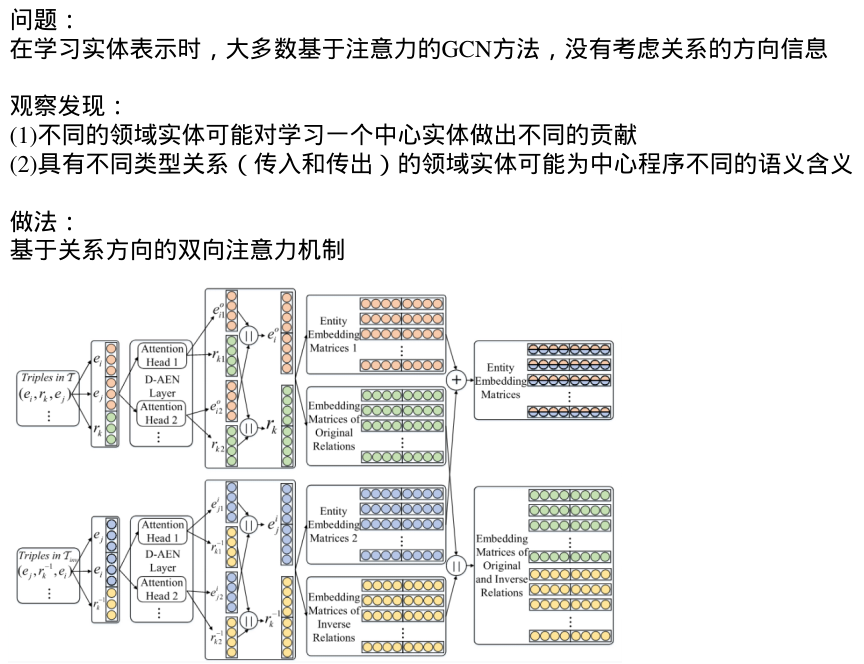
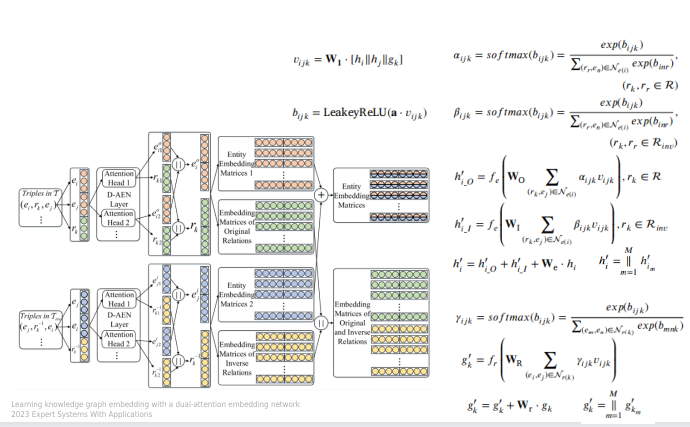
问题:
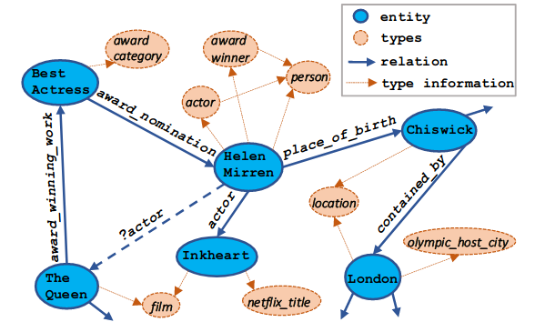
在学习实体表示时,大多数基于注意力的GCN方法,没有考虑关系的方向信息
观察发现:
(1)不同的领域实体可能对学习一个中心实体做出不同的贡献
(2)具有不同类型关系(传入和传出)的领域实体可能为中心程序不同的语义含义
做法:
基于关系方向的双向注意力机制
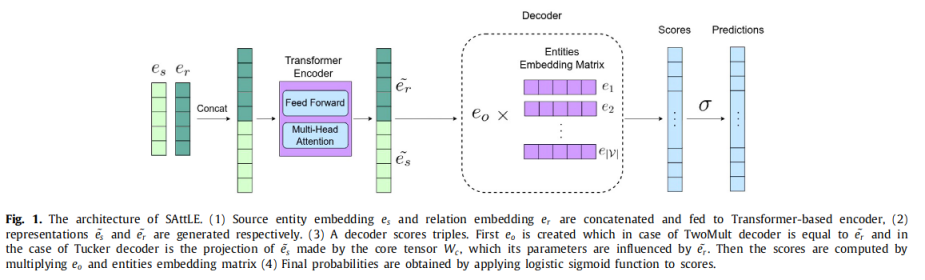
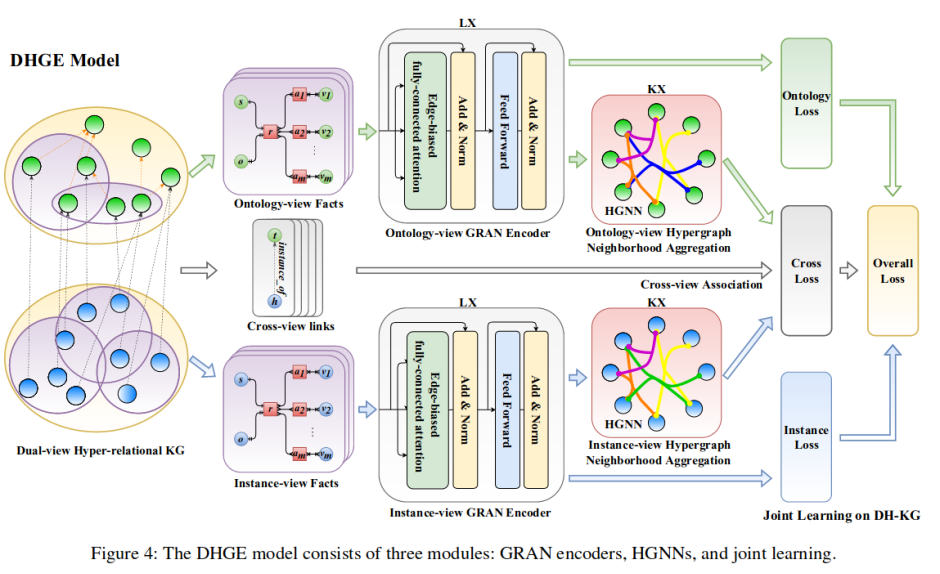
问题:知识图谱补全中许多先进的结果是以增加嵌入的维度为代价获得的,这在巨大的知识库情况下导致可伸缩性问题
核心思想:
利用自我注意,通过吸收实体和关系之间的信息、交互和依赖关系来获得强大的表征
方法:
一个Transformer编码器模块+多个注意力头(64头)
TwoMult简单有效的解码方法
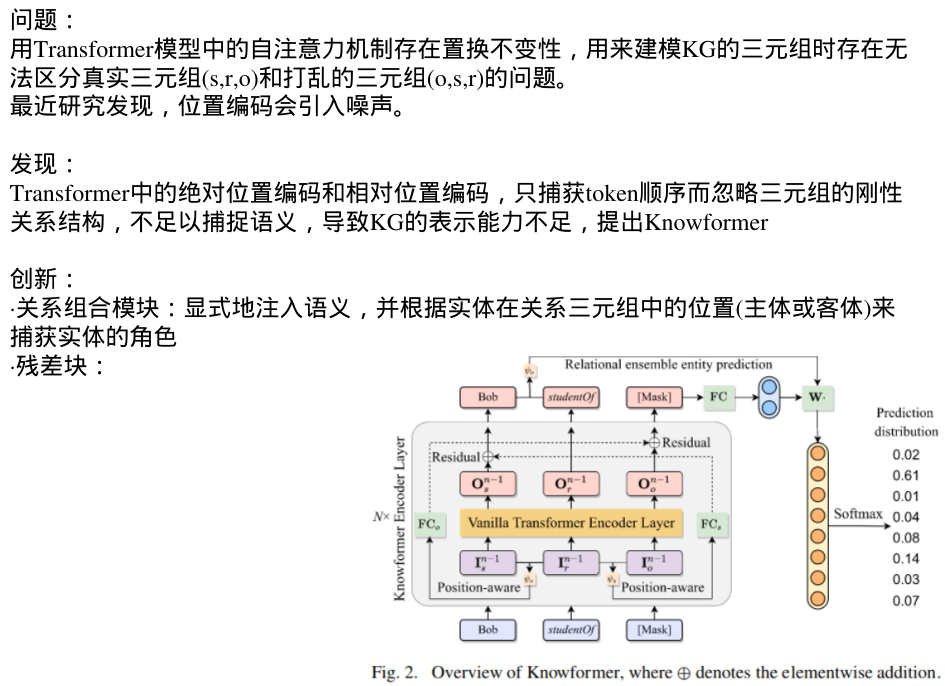
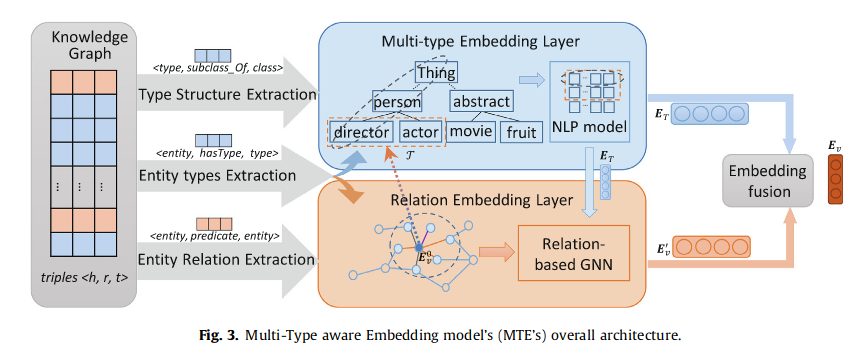
问题:
用Transformer模型中的自注意力机制存在置换不变性,用来建模KG的三元组时存在无法区分真实三元组(s,r,o)和打乱的三元组(o,s,r)的问题。
最近研究发现,位置编码会引入噪声。
发现:
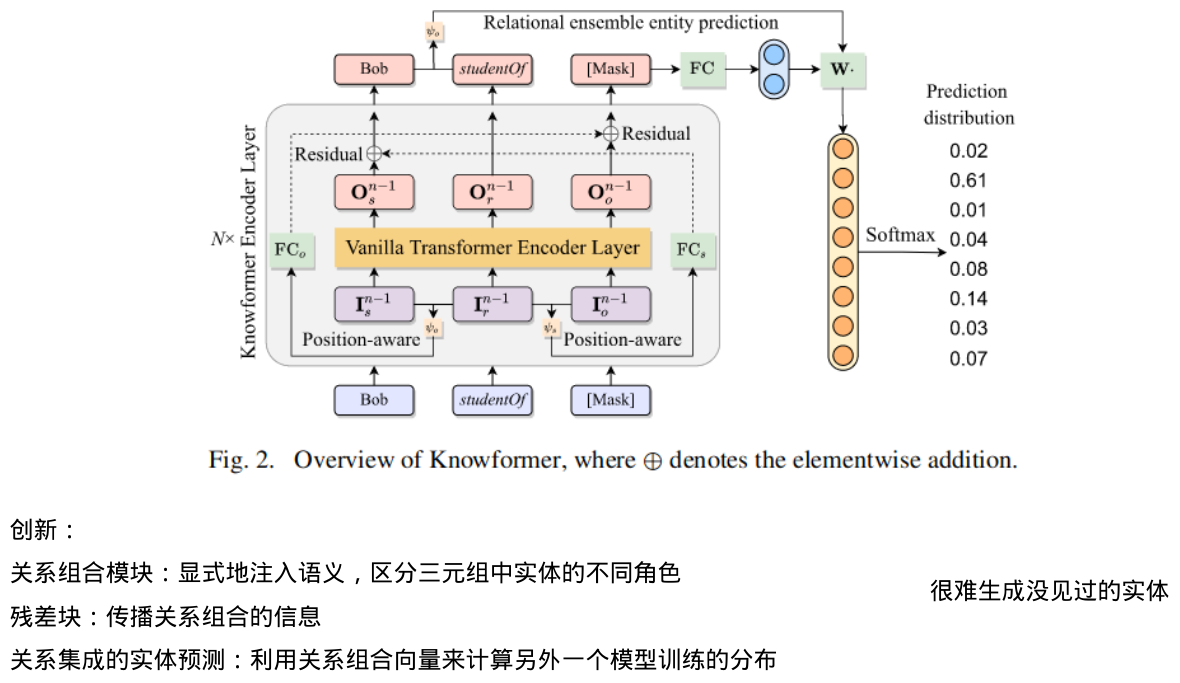
Transformer中的绝对位置编码和相对位置编码,只捕获token顺序而忽略三元组的刚性关系结构,不足以捕捉语义,导致KG的表示能力不足,提出Knowformer
创新:
·关系组合模块:显式地注入语义,区分三元组中实体的不同角色
·残差块:传播关系组合的信息
·关系集成的实体预测:利用关系组合向量来计算另外一个模型训练的分布
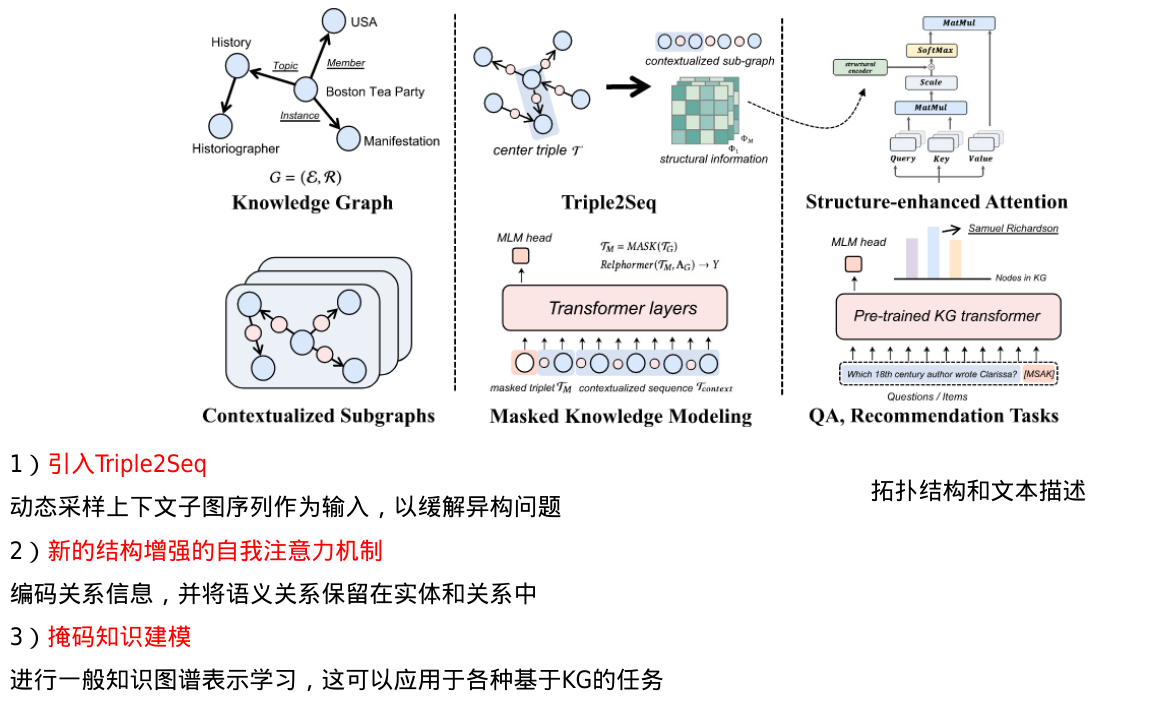
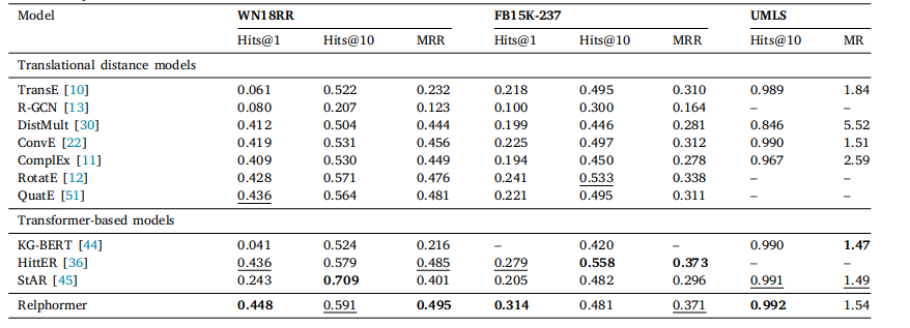
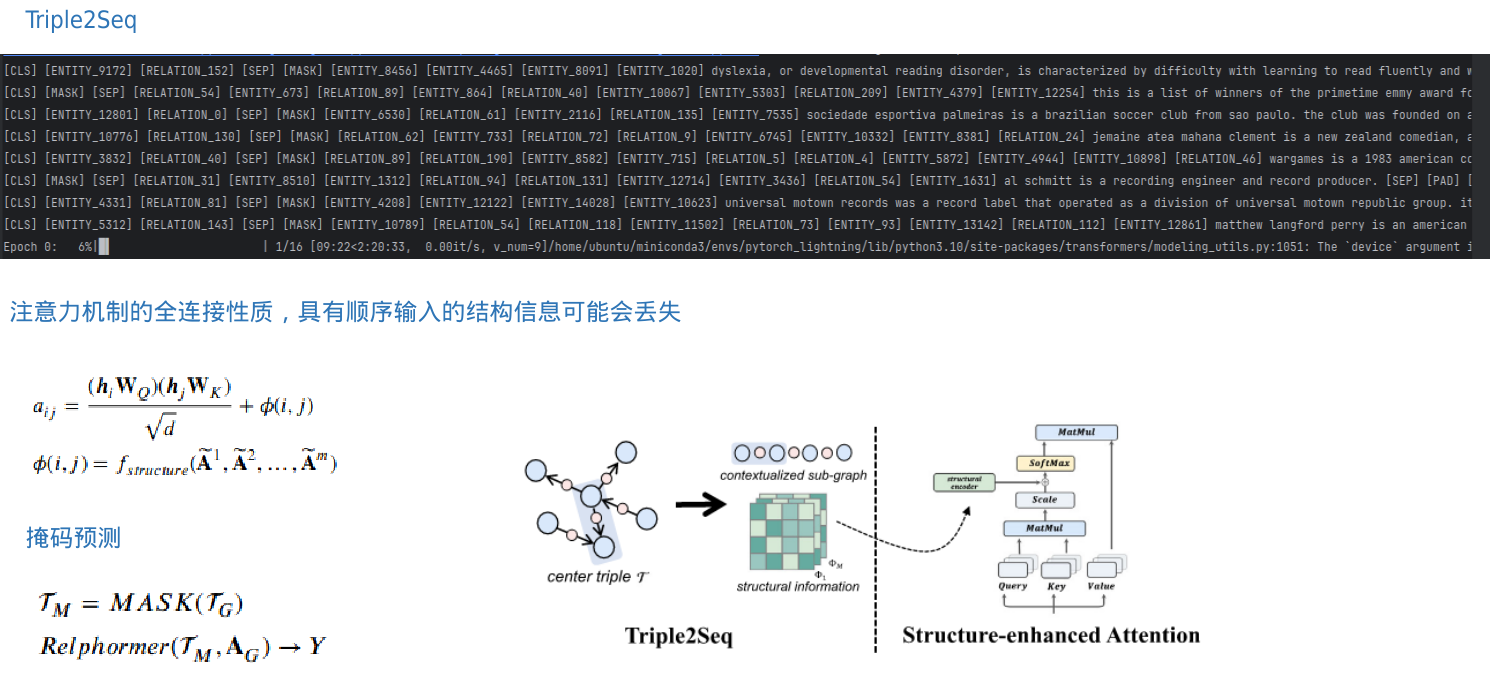
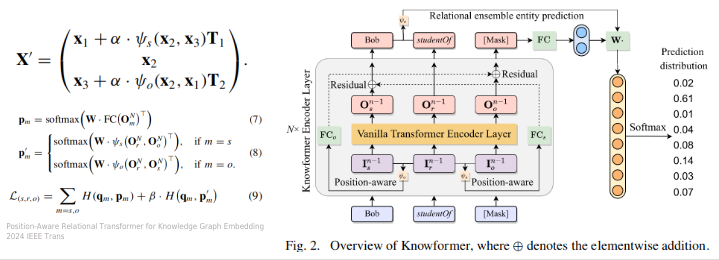 Position-Aware Relational Transformer for Knowledge Graph Embedding
Position-Aware Relational Transformer for Knowledge Graph Embedding
2024 IEEE Trans
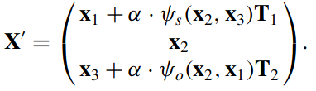
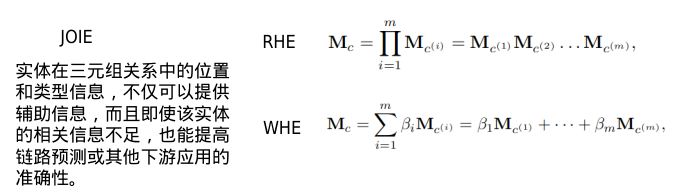
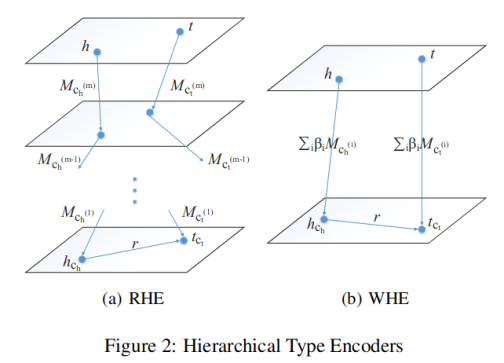


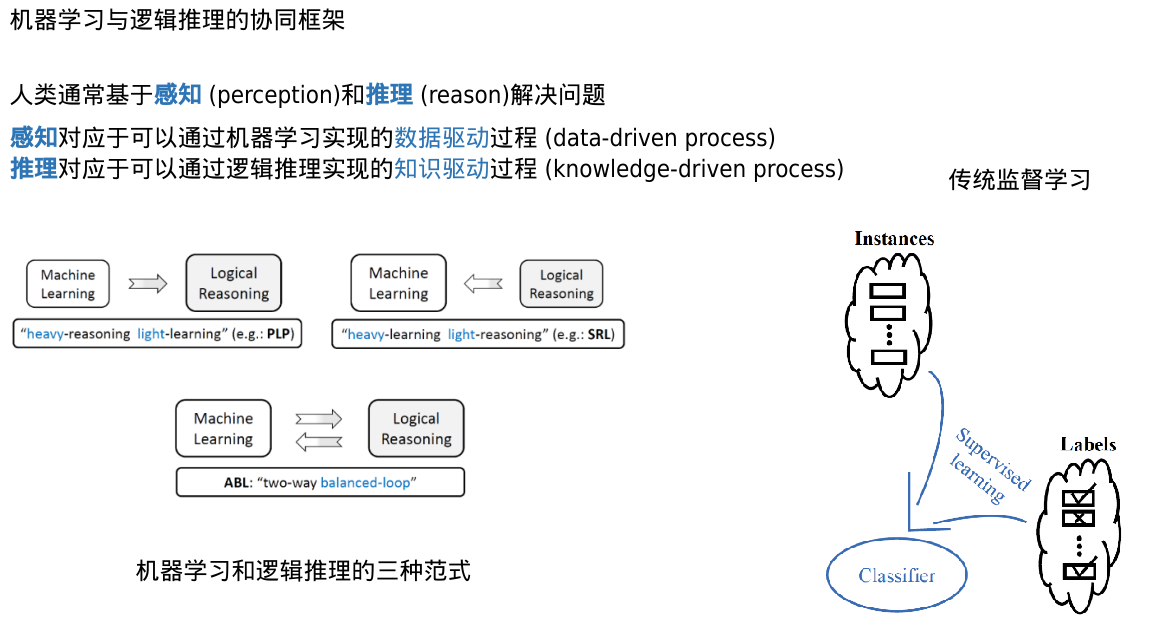
Abductive Learning
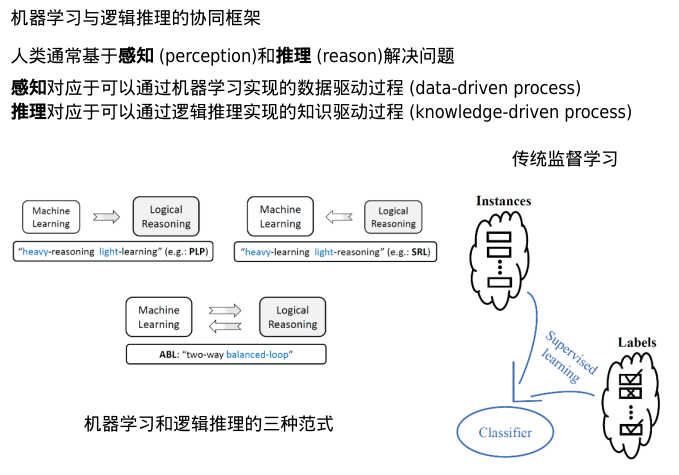
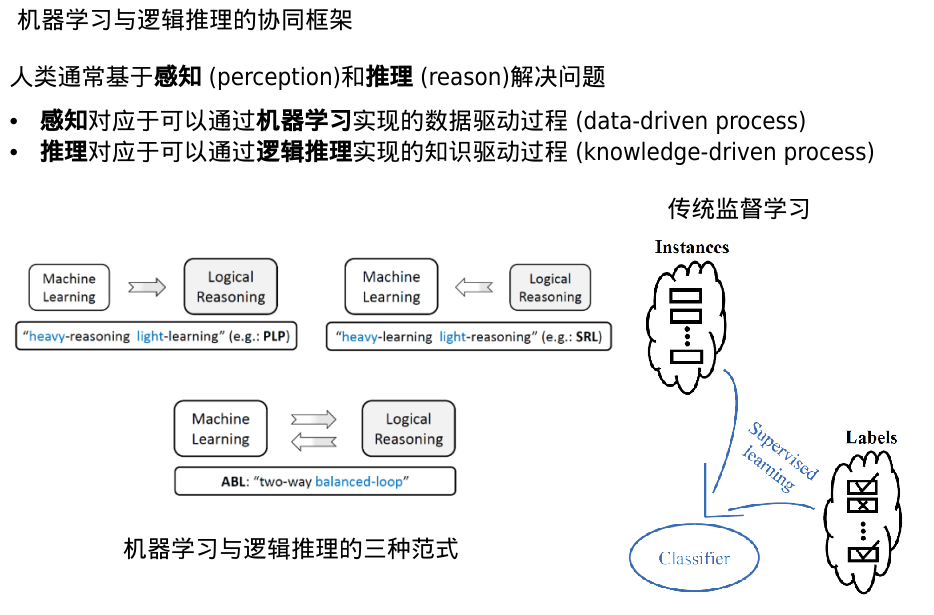
ABL
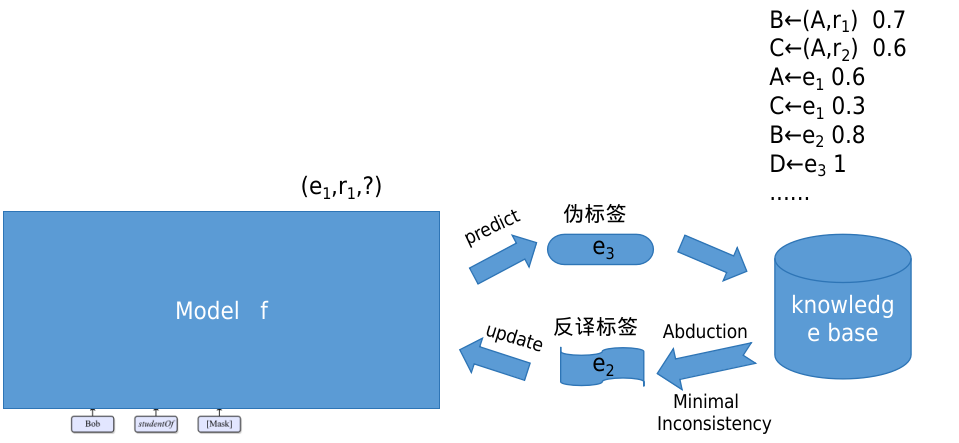
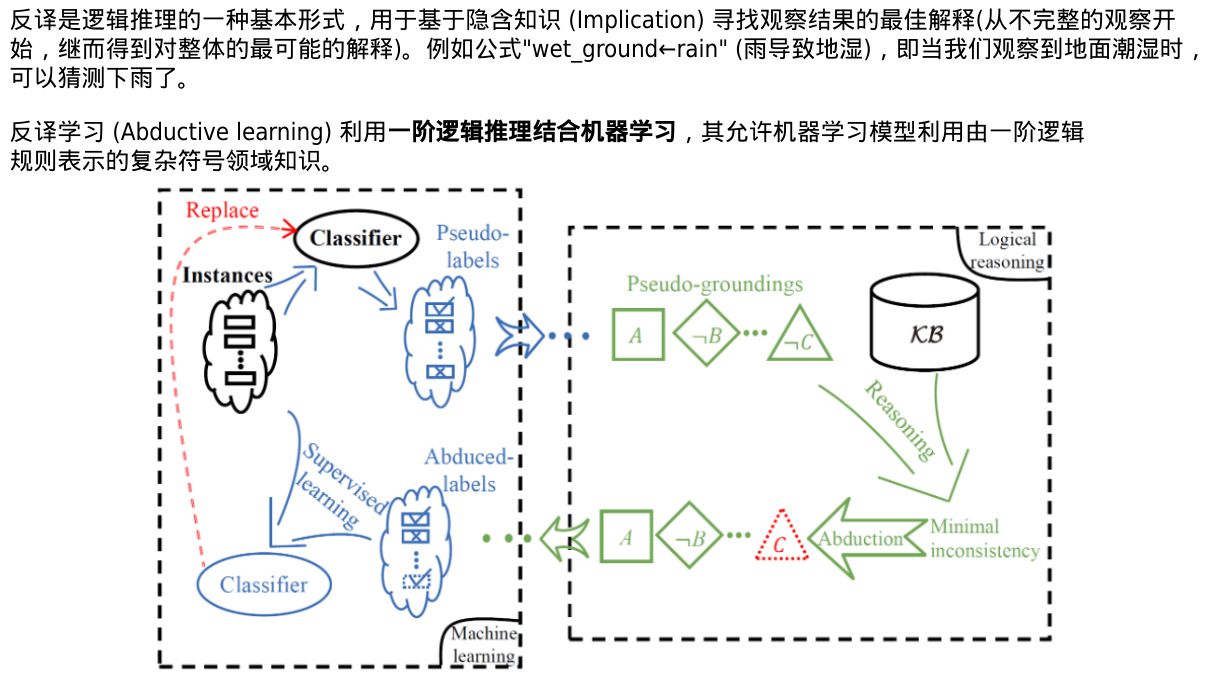
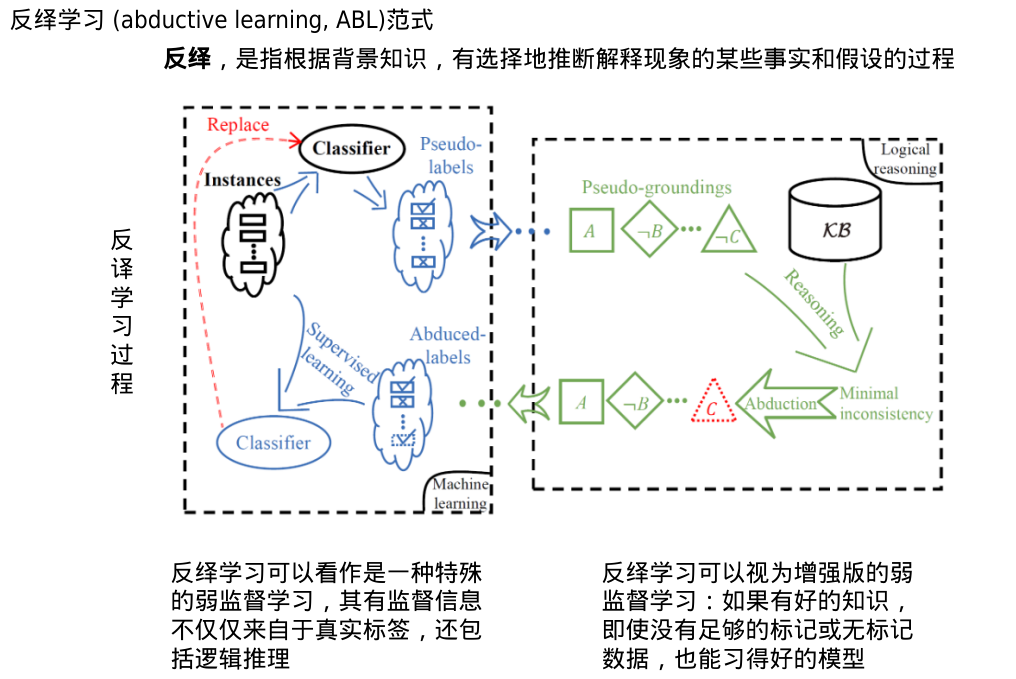
反译学习(溯因推理)
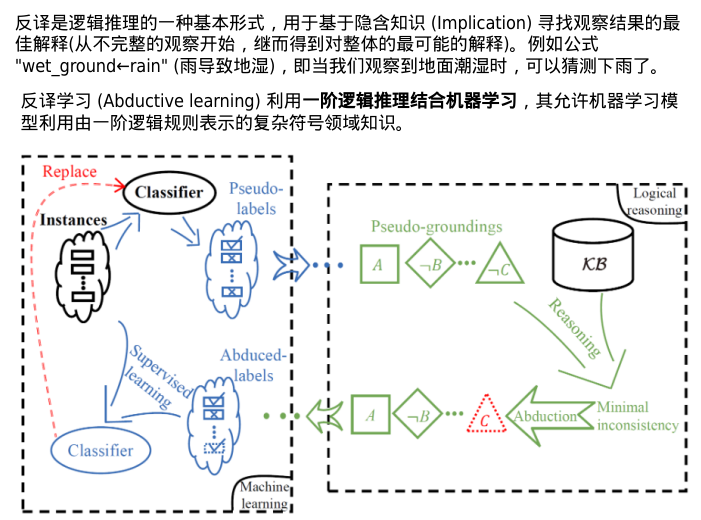
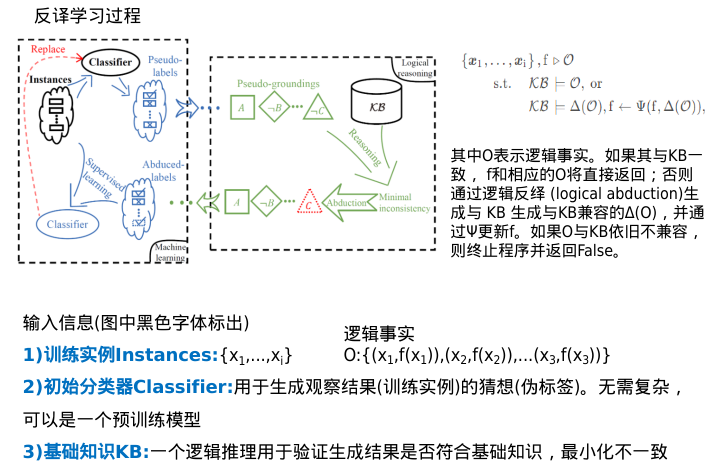
伪标签也将被转换为如同A,非B,...,非C的伪基础事实O。
然后,一个逻辑推理用于验证生成结果是否符合基础知识。如果不一致,将通过逻辑反绎生成最小化不一致的假设修订。例如,假设非C已经被修正为C,将其进一步生成反绎标签。
反绎标签将用于训练一个新的分类器Ψ并替换原始分类器。
这个过程将迭代,直到分类器不再更新,或者逻辑事实与基础知识统一。
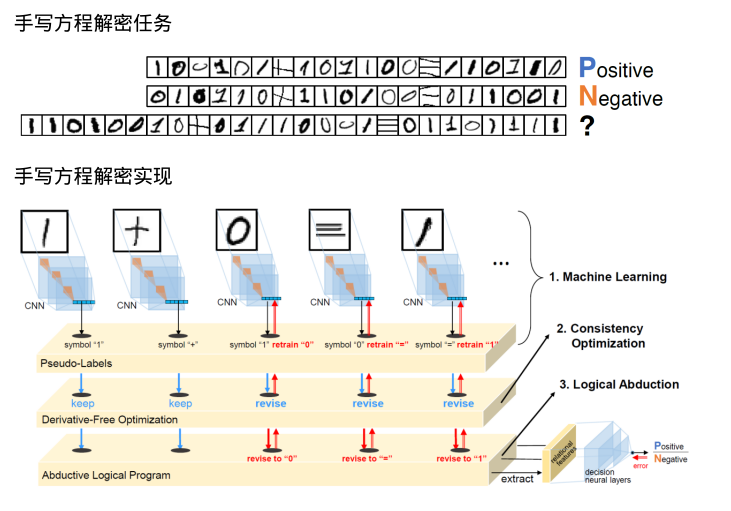
以下通过手写方程解密任务来说明反绎学习的简单实现。图6中,手写等式为 包含了多个图像字符的序列。每个序列由符号0、1、+、=并通过未知操作生成,且对应一个标示其是否正确的标签,即正positive或者negative。我们需要从此类方程的训练集学习,然后预测未知方程的标签。需要额外注意的是,控制标签分配的操作规则是未知的,方程的大小亦可不同。
逻辑反绎通过Prolog实现的ALP进行。不一致最小化问题由无导数优化工具解决,其在连续和离散域上均能进行优化。生成的模型与神经符号系统 (neural-symbolic systems)有关,因为它涉及神经网络和符号计算

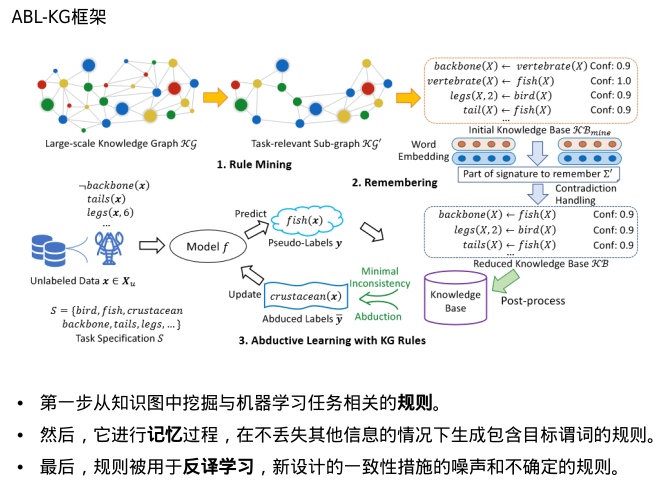
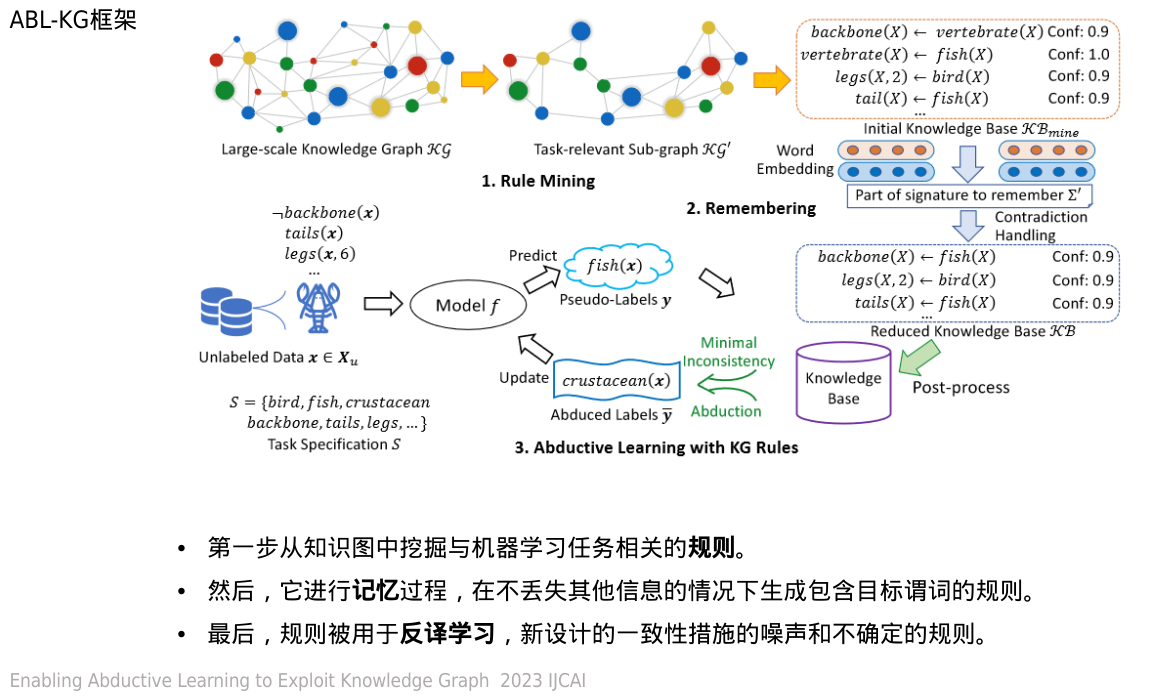
·首先,抽取出一个与机器学习任务相关的子图KG'
·然后,采用规则挖掘算法从子图KG′中挖掘FOL规则,形成初始知识库KBmine
·为了保持提取的子图的连通性,FOL规则集KBmine可能仍然包含一些与任务规范S中的名称不匹配的谓词,因此,它可以进一步减少
·矛盾处理
· ABL-KG可以使用它对KB中不可靠的规则进行后处理和过滤。此外,在溯因学习中,需要最小化溯因标签和知识库之间的不一致性

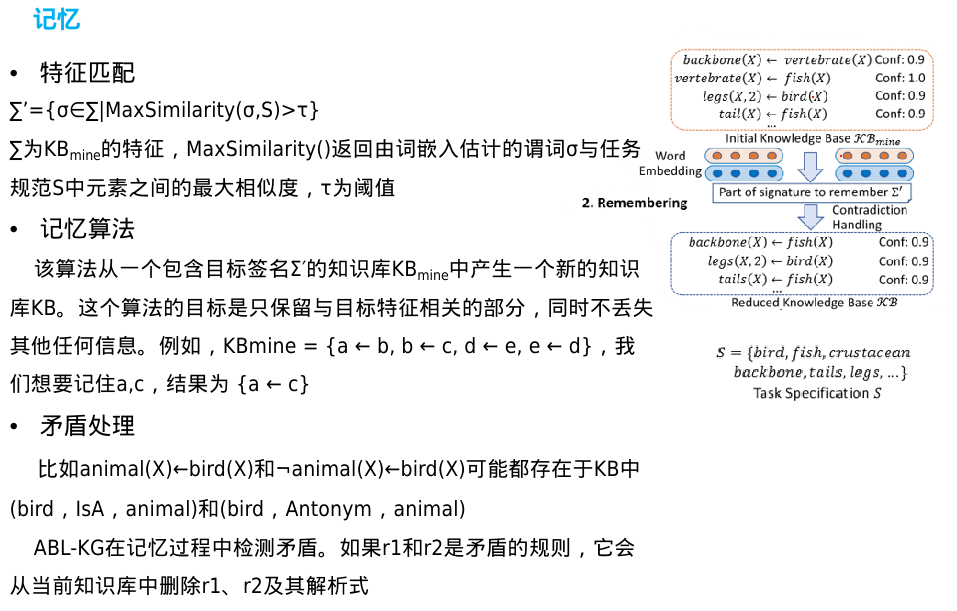
新的知识库只包含目标谓词,而没有丢失其他信息
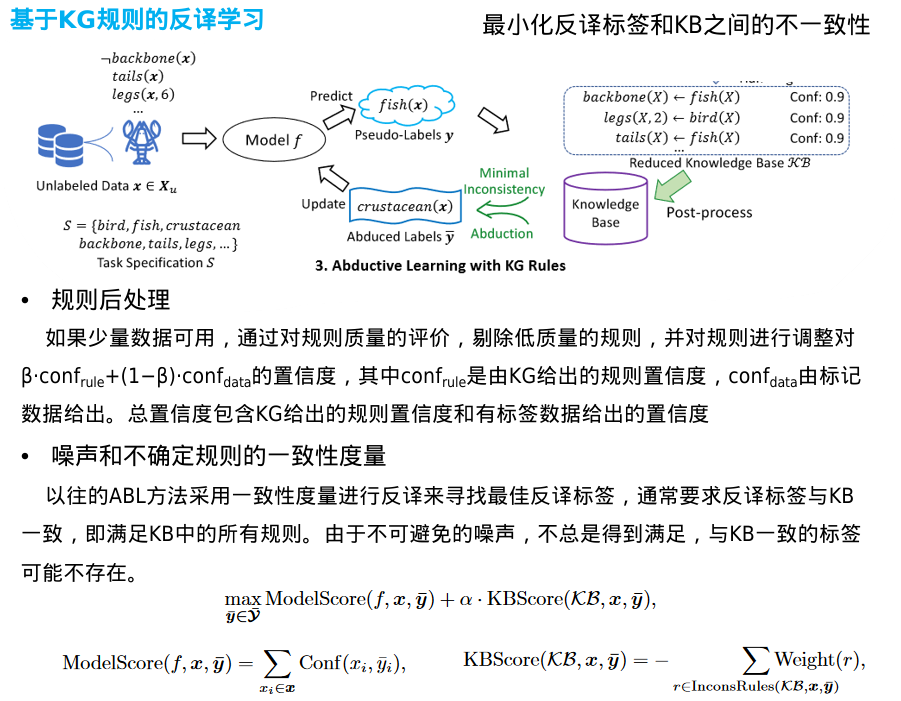
如果少量的标记数据可用,它们不仅可以用于训练初始机器学习模型f,还可以用于规则后处理
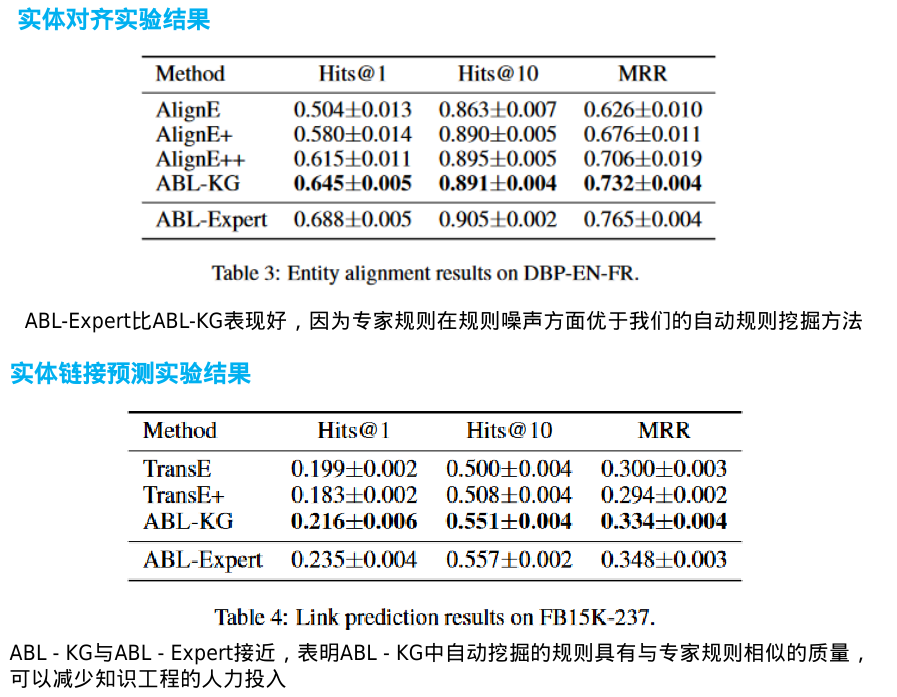

·首先,抽取出一个与机器学习任务相关的子图KG'
·然后,采用规则挖掘算法从子图KG′中挖掘FOL规则,形成初始知识库KBmine
·为了保持提取的子图的连通性,FOL规则集KBmine可能仍然包含一些与任务规范S中的名称不匹配的谓词,因此,它可以进一步减少
·矛盾处理
·ABL-KG可以使用它对KB中不可靠的规则进行后处理和过滤。此外,在溯因学习中,需要最小化溯因标签和知识库之间的不一致性

Relphormer-汇报


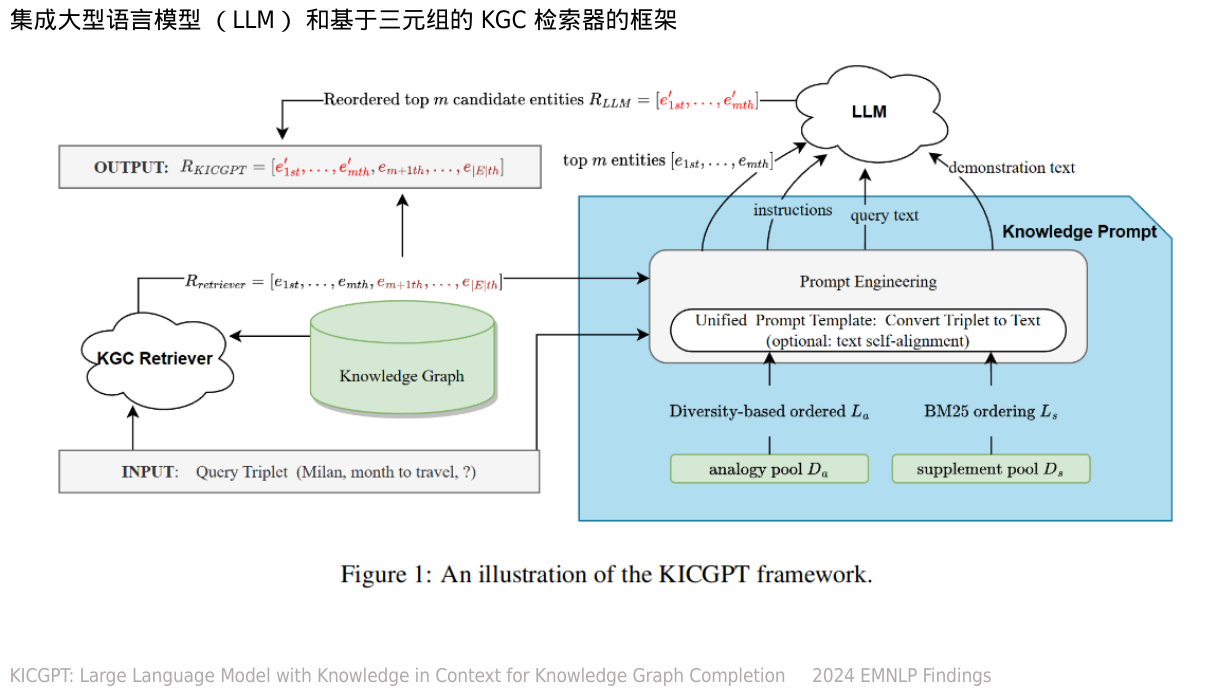
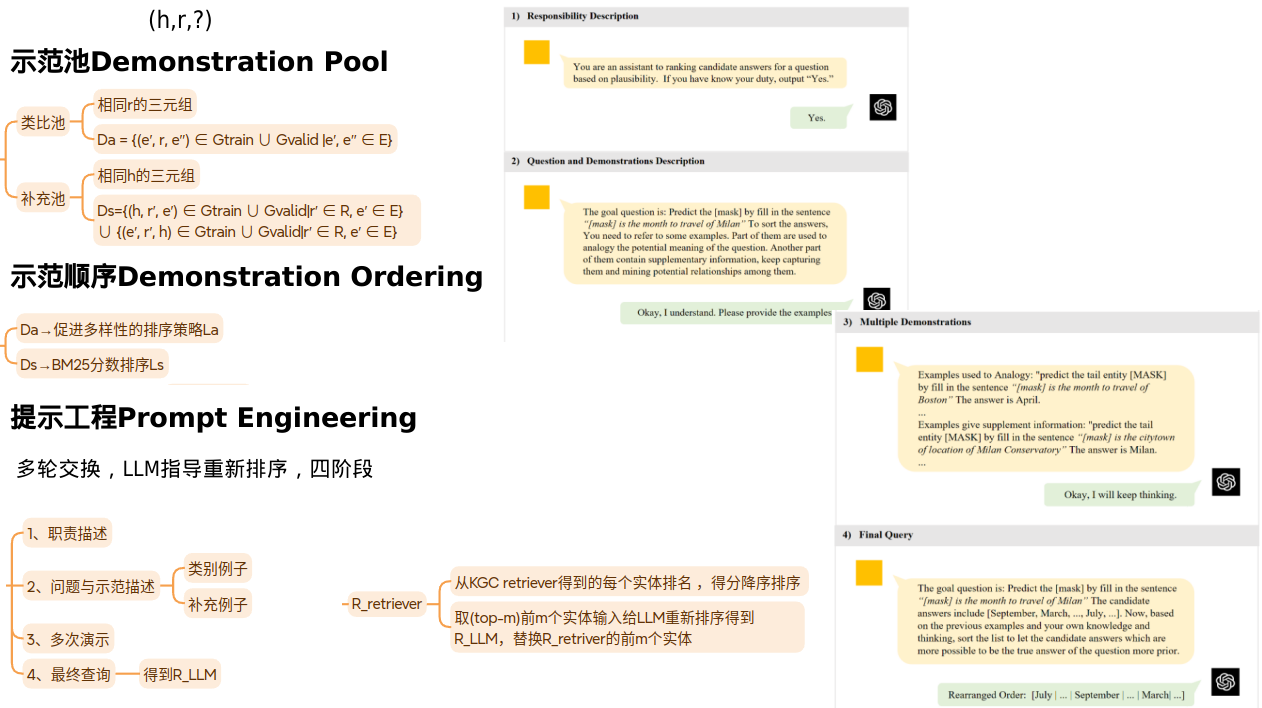
HAHA
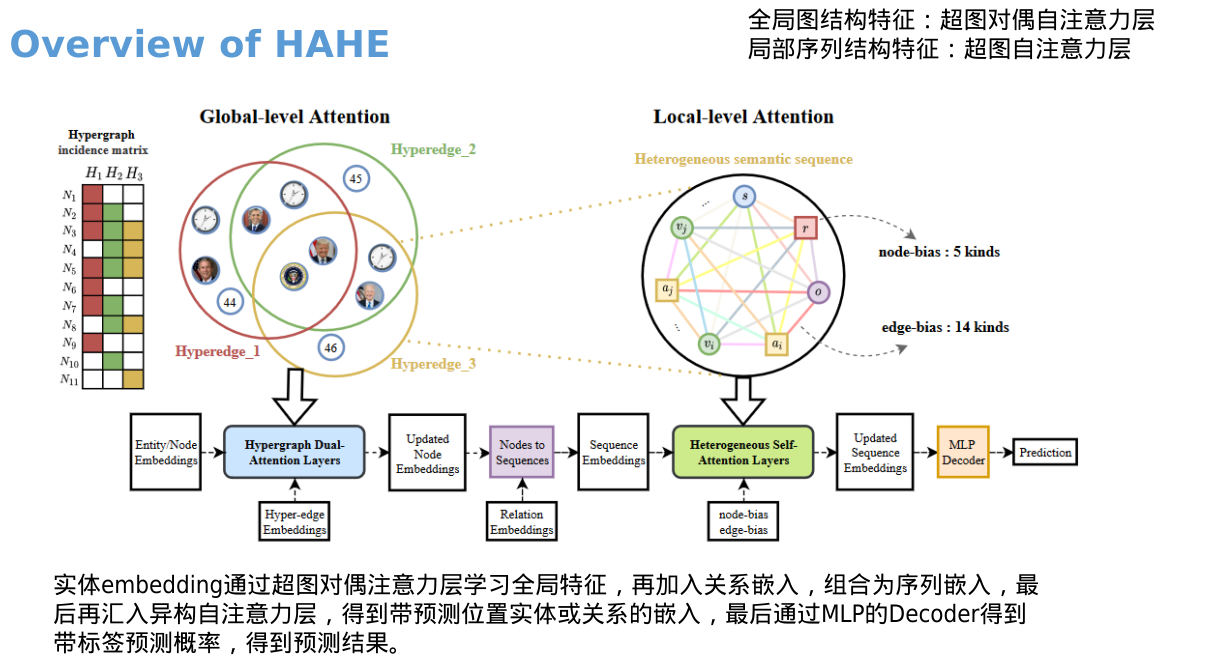
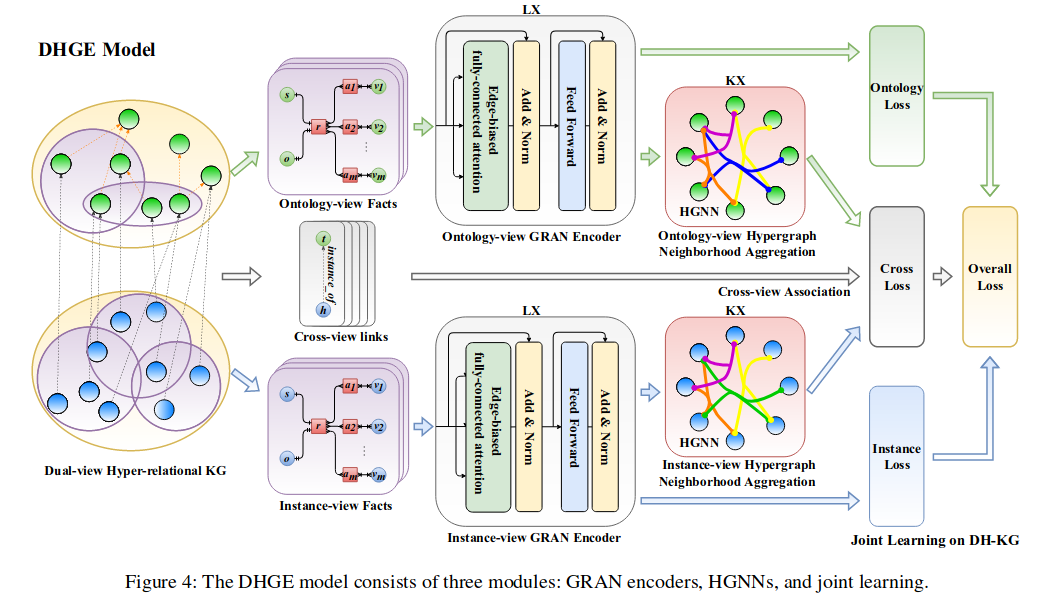
画图&草稿