文章目录
- [1. 功能概述](#1. 功能概述)
-
- [1.1 知识库管理](#1.1 知识库管理)
- [1.2 核心能力](#1.2 核心能力)
- [1.3 整体流程](#1.3 整体流程)
- [2. 从零实现知识库管理](#2. 从零实现知识库管理)
-
- [2.1 创建知识库模型](#2.1 创建知识库模型)
- [2.2 实现 KnowledgeBaseService](#2.2 实现 KnowledgeBaseService)
- [2.3 实现 VectorStoreManager](#2.3 实现 VectorStoreManager)
- [2.4 实现 DocumentProcessingService](#2.4 实现 DocumentProcessingService)
- [2.5 实现 KnowledgeBaseController](#2.5 实现 KnowledgeBaseController)
- [2.6 前端页面实现](#2.6 前端页面实现)
- [2.7 调用示例](#2.7 调用示例)
- [3. 架构小结](#3. 架构小结)
1. 功能概述
1.1 知识库管理
本 Demo 演示了一种多知识库隔离 + 文档向量化 的管理思路:用户可以创建多个独立的知识库,每个知识库绑定不同的 Embedding 模型供应商,上传文档后自动完成解析、分块、向量化全流程,最终在对话时按知识库名称检索对应的向量数据。
这套思路的通用价值在于:通过元数据 (knowledge_name)实现同一向量存储中的多租户隔离,无需为每个知识库单独部署向量数据库。无论是文件型、手动录入型、网页采集型还是数据库型知识库,核心的「上传 → 解析 → 分块 → 向量化 → 检索」流水线保持不变。
1.2 核心能力
多知识库管理 :创建、删除、启用/禁用知识库,每个知识库独立配置 Embedding 供应商。
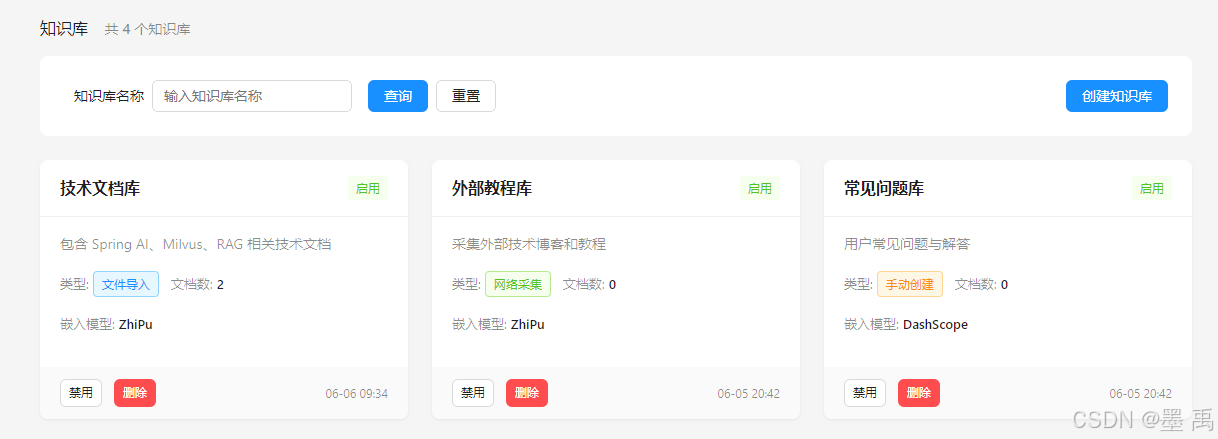
文档自动处理 :上传 PDF / DOCX / HTML / MD / TXT 等格式,自动解析并分块。
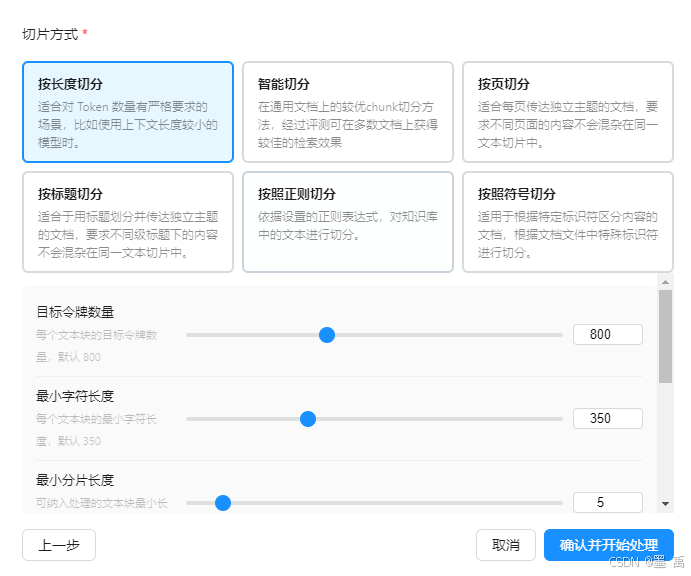
可配置的分块策略:支持按长度切分,提供块大小、重叠量、最小字符数等参数调节。
其他功能:
- 向量化存储 :分块后自动向量化并写入向量数据库,元数据注入
knowledge_name实现隔离 - 分块可视化:详情页展示每个文档的分块预览和元数据,方便调试检索效果
- 命中测试:提供检索测试入口,验证知识库的召回质量
1.3 整体流程
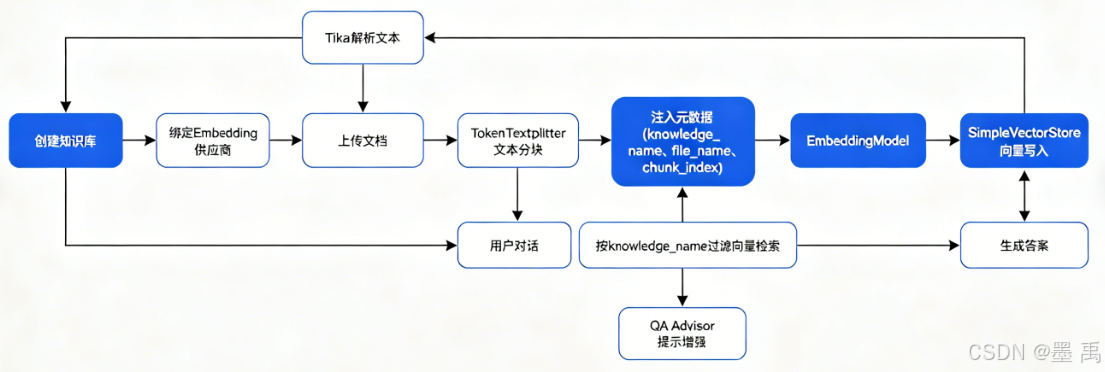
2. 从零实现知识库管理
以下从数据模型开始,逐步实现完整的知识库管理模块。
2.1 创建知识库模型
KnowledgeBase 是知识库的核心 DTO,存储名称、类型、绑定的嵌入模型、文档列表等所有状态。
java
public class KnowledgeBase {
private String name; // 唯一标识
private String description; // 描述
private String knowledgeType; // file / manual / web / database
private String embeddingModelName; // 绑定的 Embedding 供应商,如 ZhiPu
private int documentCount; // 文档数量
private boolean enabled; // 是否启用
private final List<DocumentInfo> documents = new ArrayList<>(); // 文档列表
private LocalDateTime createTime;
private LocalDateTime updateTime;
// 文档信息
public static class DocumentInfo {
private final String name; // 文件名
private final long size; // 字节大小
private final int chunks; // 分块数量
private final String uploadTime;
private final List<ChunkDetail> chunkDetails; // 分块详情
}
// 分块详情
public static class ChunkDetail {
private final int index; // 分块序号
private final String preview; // 内容预览(前 200 字符)
private final String metadataJson; // 元数据 JSON
}
// 添加上传文档
public void addDocument(String name, long size, int chunks) {
documents.add(new DocumentInfo(name, size, chunks, List.of()));
this.documentCount = documents.size();
this.updateTime = LocalDateTime.now();
}
// 更新最后一个文档的分块详情(处理完成后回填)
public void updateLastDocumentChunks(int chunks, List<ChunkDetail> chunkDetails) {
if (!documents.isEmpty()) {
var last = documents.get(documents.size() - 1);
documents.set(documents.size() - 1,
new DocumentInfo(last.getName(), last.getSize(), chunks, chunkDetails));
}
}
}2.2 实现 KnowledgeBaseService
知识库数据存储在当前 Demo 中使用 ConcurrentHashMap(内存),生产环境可替换为 MySQL / Redis。
java
@Service
public class KnowledgeBaseService {
private final Map<String, KnowledgeBase> store = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
// 预置 4 个示例知识库
create("技术文档库", "包含 Spring AI、Milvus、RAG 相关技术文档", "file", "ZhiPu");
create("常见问题库", "用户常见问题与解答", "manual", "DashScope");
create("外部教程库", "采集外部技术博客和教程", "web", "ZhiPu");
create("数据表格库", "结构化数据与统计表格", "database", "DashScope");
}
public List<KnowledgeBase> list(String name) {
List<KnowledgeBase> all = new ArrayList<>(store.values());
if (name != null && !name.trim().isEmpty()) {
String keyword = name.trim().toLowerCase();
all = all.stream()
.filter(kb -> kb.getName().toLowerCase().contains(keyword))
.collect(Collectors.toList());
}
all.sort(Comparator.comparing(KnowledgeBase::getUpdateTime).reversed());
return all;
}
public KnowledgeBase get(String name) {
return store.get(name);
}
public KnowledgeBase create(String name, String description,
String knowledgeType, String embeddingModelName) {
KnowledgeBase kb = new KnowledgeBase(name, description, knowledgeType);
kb.setEmbeddingModelName(embeddingModelName);
store.put(name, kb);
return kb;
}
public void delete(String name) {
store.remove(name);
}
public void enable(String name) {
KnowledgeBase kb = store.get(name);
if (kb != null) { kb.setEnabled(true); kb.setUpdateTime(LocalDateTime.now()); }
}
public void disable(String name) {
KnowledgeBase kb = store.get(name);
if (kb != null) { kb.setEnabled(false); kb.setUpdateTime(LocalDateTime.now()); }
}
}2.3 实现 VectorStoreManager
VectorStoreManager 是向量存储的统一入口。它按 Embedding 供应商缓存 SimpleVectorStore 实例,不同供应商使用各自的嵌入模型,同一个供应商下的多个知识库共享一个向量存储,通过元数据 knowledge_name 实现隔离。
java
@Component
public class VectorStoreManager {
private final KnowledgeBaseService knowledgeBaseService;
private final ModelFactory modelFactory;
private final Map<String, VectorStore> storeCache = new ConcurrentHashMap<>();
public VectorStoreManager(KnowledgeBaseService knowledgeBaseService,
ModelFactory modelFactory) {
this.knowledgeBaseService = knowledgeBaseService;
this.modelFactory = modelFactory;
}
/**
* 根据知识库名称获取对应的 VectorStore。
* 查找该知识库绑定的 Embedding 供应商,按供应商缓存实例。
*/
public VectorStore getVectorStore(String knowledgeName) {
KnowledgeBase kb = knowledgeBaseService.get(knowledgeName);
String provider = kb != null ? kb.getEmbeddingModelName() : "ZhiPu";
return storeCache.computeIfAbsent(provider, key -> {
EmbeddingModel embeddingModel = modelFactory.getEmbeddingModel(key);
return SimpleVectorStore.builder(embeddingModel).build();
});
}
}2.4 实现 DocumentProcessingService
这是 RAG 流水线的核心------上传、解析、分块、向量化写入全流程。
java
@Service
public class DocumentProcessingService {
private final VectorStoreManager vectorStoreManager;
// 文件临时缓存:knowledgeName → bytes + fileName
private final Map<String, byte[]> fileCache = new ConcurrentHashMap<>();
private final Map<String, String> fileNameCache = new ConcurrentHashMap<>();
/** 缓存上传文件,等待用户配置分块参数后处理 */
public void cacheFile(String knowledgeName, String fileName, byte[] bytes) {
fileCache.put(knowledgeName, bytes);
fileNameCache.put(knowledgeName, fileName);
}
/** 按用户选择的分块参数处理缓存文件 */
public ProcessResult processCached(String knowledgeName, int chunkSize, int chunkOverlap)
throws IOException {
byte[] bytes = fileCache.get(knowledgeName);
String fileName = fileNameCache.get(knowledgeName);
if (bytes == null) throw new IOException("没有待处理的文件,请先上传");
fileCache.remove(knowledgeName);
fileNameCache.remove(knowledgeName);
return processBytes(bytes, fileName, knowledgeName, chunkSize, chunkOverlap);
}
/** 核心处理流程 */
public ProcessResult processBytes(byte[] bytes, String fileName, String knowledgeName,
int chunkSize, int chunkOverlap) throws IOException {
// 1. 解析文档 ------ Apache Tika 自动识别格式并提取文本
TikaDocumentReader reader = new TikaDocumentReader(
new InputStreamResource(new ByteArrayInputStream(bytes)));
List<Document> documents = reader.get();
// 2. 注入元数据
for (Document doc : documents) {
doc.getMetadata().put("knowledge_name", knowledgeName);
doc.getMetadata().put("file_name", fileName);
}
// 3. 文本分块 ------ TokenTextSplitter 按 Token 数切分
TokenTextSplitter splitter = new TokenTextSplitter(
chunkSize, chunkOverlap, 5, 10000, true,
List.of('.', '?', '!', '\n'));
List<Document> chunks = splitter.apply(documents);
// 4. 收集分块预览
List<ProcessResult.ChunkInfo> chunkInfos = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
Document chunk = chunks.get(i);
chunk.getMetadata().put("chunk_index", i);
chunk.getMetadata().put("chunk_total", chunks.size());
String preview = chunk.getText() != null ? chunk.getText() : "";
if (preview.length() > 200) preview = preview.substring(0, 200) + "...";
chunkInfos.add(new ProcessResult.ChunkInfo(i, preview,
new LinkedHashMap<>(chunk.getMetadata())));
}
// 5. 写入向量存储(按 knowledgeName 获取对应的 VectorStore)
vectorStoreManager.getVectorStore(knowledgeName).add(chunks);
return new ProcessResult(fileName, bytes.length, chunks.size(), chunkInfos);
}
public static class ProcessResult {
private final String fileName;
private final long fileSize;
private final int chunkCount;
private final List<ChunkInfo> chunks;
public static class ChunkInfo {
private final int index;
private final String preview;
private final Map<String, Object> metadata;
}
}
}2.5 实现 KnowledgeBaseController
Controller 同时提供页面路由和 REST API。页面使用 Thymeleaf 渲染,API 返回 JSON。
java
@Controller
public class KnowledgeBaseController {
private final KnowledgeBaseService knowledgeBaseService;
private final EmbeddingModelService embeddingModelService;
private final DocumentProcessingService documentProcessingService;
// ==================== 页面路由 ====================
@GetMapping("/knowledge")
public String list(@RequestParam(defaultValue = "1") int pageNo,
@RequestParam(defaultValue = "10") int pageSize,
@RequestParam(defaultValue = "") String name, Model model) {
List<KnowledgeBase> all = knowledgeBaseService.list(name);
// 手动分页
int total = all.size();
int totalPages = Math.max((int) Math.ceil((double) total / pageSize), 1);
int from = (pageNo - 1) * pageSize;
int to = Math.min(from + pageSize, total);
List<KnowledgeBase> page = from < total ? all.subList(from, to) : List.of();
model.addAttribute("knowledgeBases", page);
model.addAttribute("totalPages", totalPages);
model.addAttribute("totalElements", total);
model.addAttribute("currentPage", pageNo);
model.addAttribute("searchName", name);
model.addAttribute("embeddingModels", embeddingModelService.listEnabled());
return "knowledge/list";
}
@GetMapping("/knowledge/{name}")
public String detail(@PathVariable String name, Model model) {
KnowledgeBase kb = knowledgeBaseService.get(name);
if (kb == null) return "redirect:/knowledge";
model.addAttribute("kb", kb);
model.addAttribute("tab", "docs");
return "knowledge/detail";
}
// ==================== REST API ====================
@PostMapping("/admin/knowledge")
@ResponseBody
public ResponseEntity<KnowledgeBase> create(@RequestBody Map<String, String> body) {
String name = body.get("name");
String description = body.get("description");
String knowledgeType = body.get("knowledgeType");
String embeddingModelName = body.get("embeddingModelName");
if (name == null || name.trim().isEmpty()) return ResponseEntity.badRequest().build();
return ResponseEntity.ok(
knowledgeBaseService.create(name.trim(), description, knowledgeType, embeddingModelName));
}
@DeleteMapping("/admin/knowledge")
@ResponseBody
public ResponseEntity<Map<String, String>> delete(@RequestParam String name) {
knowledgeBaseService.delete(name);
return ResponseEntity.ok(Map.of("code", "ok"));
}
@PostMapping("/admin/knowledge/enable")
@ResponseBody
public ResponseEntity<Map<String, String>> enable(@RequestParam String name) {
knowledgeBaseService.enable(name);
return ResponseEntity.ok(Map.of("code", "ok"));
}
@PostMapping("/admin/knowledge/{name}/upload")
@ResponseBody
public ResponseEntity<Map<String, Object>> uploadDocument(
@PathVariable String name, @RequestParam("file") MultipartFile file) {
KnowledgeBase kb = knowledgeBaseService.get(name);
if (kb == null) return ResponseEntity.badRequest().body(Map.of("message", "知识库不存在"));
String fileName = file.getOriginalFilename();
long fileSize = file.getSize();
documentProcessingService.cacheFile(name, fileName, file.getBytes());
kb.addDocument(fileName, fileSize, 0);
return ResponseEntity.ok(Map.of("code", "ok", "fileName", fileName,
"fileSize", String.valueOf(fileSize)));
}
@PostMapping("/admin/knowledge/{name}/process")
@ResponseBody
public ResponseEntity<Map<String, Object>> processDocument(
@PathVariable String name, @RequestBody Map<String, Object> config) {
KnowledgeBase kb = knowledgeBaseService.get(name);
if (kb == null) return ResponseEntity.badRequest().body(Map.of("message", "知识库不存在"));
int chunkSize = config.get("chunkSize") != null
? ((Number) config.get("chunkSize")).intValue() : 800;
DocumentProcessingService.ProcessResult result =
documentProcessingService.processCached(name, chunkSize, 50);
// 将分块详情回填到 KnowledgeBase
List<KnowledgeBase.ChunkDetail> details = new ArrayList<>();
for (var ci : result.getChunks()) {
String metaJson = new ObjectMapper().writeValueAsString(ci.getMetadata());
details.add(new KnowledgeBase.ChunkDetail(ci.getIndex(), ci.getPreview(), metaJson));
}
kb.updateLastDocumentChunks(result.getChunkCount(), details);
return ResponseEntity.ok(Map.of("code", "ok", "chunkCount",
String.valueOf(result.getChunkCount())));
}
}2.6 前端页面实现
列表页(templates/knowledge/list.html):
- 卡片网格展示所有知识库,每张卡片显示名称、类型标签、文档数、嵌入模型、启用状态
- 搜索栏 + 分页
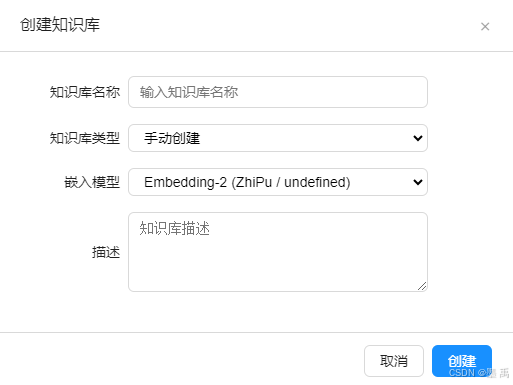
- 创建按钮弹出模态框:填写名称、类型、嵌入模型、描述
- 每个卡片提供启用/禁用、删除操作
详情页(templates/knowledge/detail.html):
- 三个标签页:
文档列表/命中测试/设置 - 文档列表:已有文档的表格展示(名称、大小、分块数、上传时间),支持查看切片详情和元数据
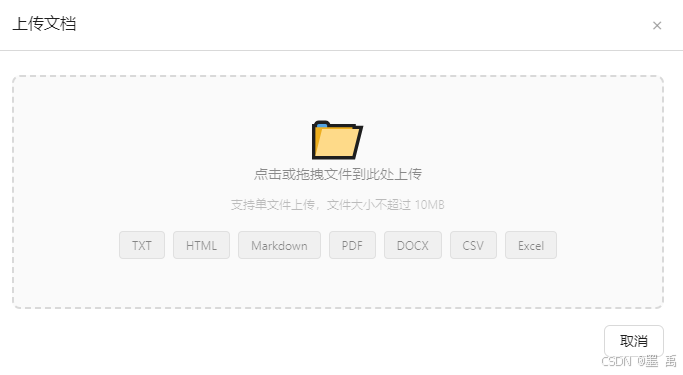
- 上传文档流程:拖拽/点击上传 → 选择切片方式 → 配置分块参数 → 确认并开始处理
- 命中测试:提供检索测试入口(
UI占位,核心逻辑在ChatService中实现)
前端交互(static/js/knowledge.js):
javascript
// 核心 API 调用封装
async function apiCall(url, options = {}) {
const response = await fetch(url, {
headers: { 'Content-Type': 'application/json' },
...options
});
if (!response.ok) {
const data = await response.json();
throw new Error(data.message || '请求失败');
}
return response.json();
}
// 创建知识库
async function createKnowledgeBase() {
const name = document.getElementById('kbName').value.trim();
const knowledgeType = document.getElementById('kbType').value;
const embeddingModelName = document.getElementById('kbEmbeddingModel')?.value || '';
const description = document.getElementById('kbDescription').value.trim();
await apiCall('/admin/knowledge', {
method: 'POST',
body: JSON.stringify({ name, description, knowledgeType, embeddingModelName })
});
location.reload();
}
// 上传文档 + 处理流程(detail.html 内联脚本)
// 1. 拖拽/选择文件 → POST /admin/knowledge/{name}/upload (FormData)
// 2. 选择切片方式 + 配置参数
// 3. POST /admin/knowledge/{name}/process → 返回 chunkCount
// 4. 刷新页面展示文档列表和分块详情2.7 调用示例
java
// 创建知识库
KnowledgeBase kb = knowledgeBaseService.create(
"技术文档库", "Spring AI 相关文档", "file", "ZhiPu");
// 上传并处理文档
byte[] fileBytes = Files.readAllBytes(Path.of("docs/spring-ai.pdf"));
documentProcessingService.cacheFile("技术文档库", "spring-ai.pdf", fileBytes);
ProcessResult result = documentProcessingService.processCached("技术文档库", 800, 50);
// → 输出: 共 42 个分块已写入向量库
// 获取该知识库的 VectorStore(用于检索)
VectorStore store = vectorStoreManager.getVectorStore("技术文档库");
List<Document> hits = store.similaritySearch(
SearchRequest.builder().query("什么是 RAG")
.topK(5).similarityThreshold(0.7)
.filterExpression("knowledge_name == \"技术文档库\"")
.build());3. 架构小结
┌──────────────────────────────────────────────────────┐
│ Controller │
│ GET /knowledge → 列表页 │
│ GET /knowledge/{name} → 详情页 │
│ POST /admin/knowledge → 创建 │
│ POST .../upload → 上传文件(缓存 bytes) │
│ POST .../process → 分块 + 向量化 │
└──────────┬───────────────────────────────────────────┘
│
┌──────┴──────┐
│ ▼
│ KnowledgeBaseService (ConcurrentHashMap)
│ ├─ store: Map<name, KnowledgeBase>
│ └─ KnowledgeBase.documents: List<DocumentInfo>
│
▼
DocumentProcessingService
├─ 1. cacheFile() → 暂存 bytes + fileName
├─ 2. processCached() → 取出缓存,调用 processBytes()
└─ 3. processBytes()
├─ TikaDocumentReader → 解析 PDF/DOCX/HTML/MD
├─ TokenTextSplitter → 按 Token 数切分
└─ VectorStore.add() → 向量化 + 写入存储
│
▼
VectorStoreManager
└─ storeCache: Map<provider, SimpleVectorStore>
└─ 按 Embedding 供应商缓存,元数据 knowledge_name 隔离核心设计要点:
- 两阶段上传:先上传缓存文件,用户配置分块参数后再触发处理,避免上传大文件后自动处理不符合预期
- 按供应商缓存向量存储 :同一供应商下的多个知识库共享
SimpleVectorStore,通过knowledge_name元数据隔离,简单高效 - 分块详情回溯 :处理后把每个
chunk的预览和元数据回填到KnowledgeBase,前端可直接展示,无需反查向量库 - 可切换存储后端 :
VectorStoreManager只依赖VectorStore接口,将SimpleVectorStore替换为Milvus等远程向量库零侵入