一般送给模型之前的输入数据,如果不考虑embedding,直接linear、gru、RNN、transformer这种模型,一般输入就是三维的 batch_size, sql_len, embedding_dim;但如果中间要经过embedding层,那么在送给embedding之前,一定是 batch_size, seq_len;

embedding类似于linear层,在内部定义了一个矩阵,这个矩阵的行是num_embeddings、列是embedding_dim;
bash
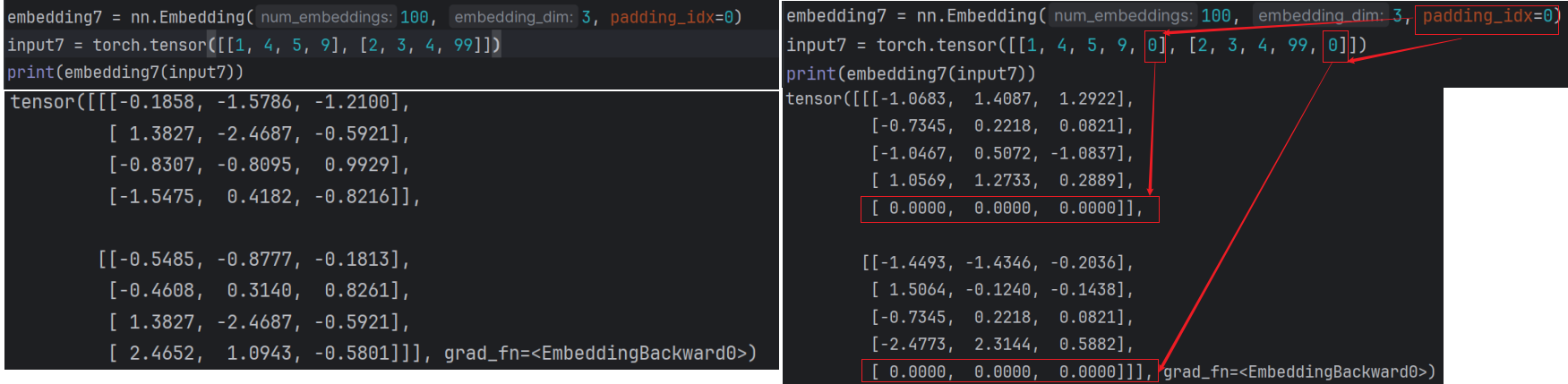
embedding6 = nn.Embedding(10, 30)
input5 = torch.tensor([[1, 4, 5, 9], [2, 3, 4, 10]])使用时根据数字,数字其实对应的就是索引,根据索引查对于的向量:1对应第2行,有30个数;经过embedding后原始的维度会升一维,由 2, 4 升到 2, 4, 30;
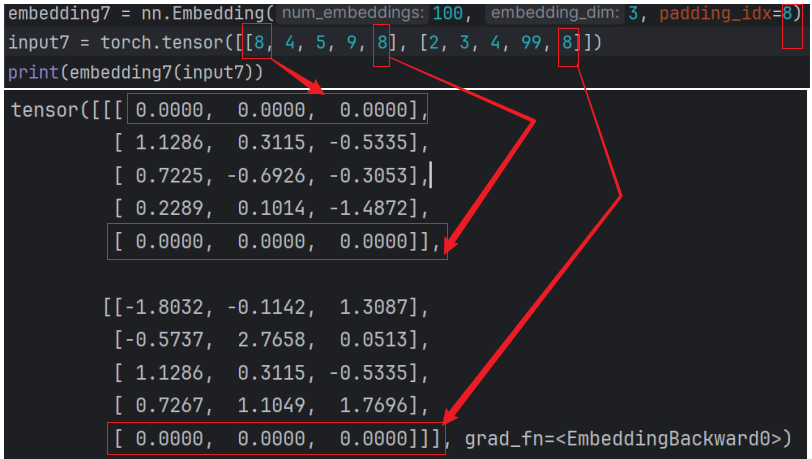
padding_idx:表示指定的数字初始化为0 ,指定哪个数 其对应的向量初始化值就是0;
3.4.2 Embedding的代码实现:
nn.embedding核心就是创建一个矩阵:nn.Embedding(num_embeddings=xx, embedding_dim=xx),有多少单词需要进行词嵌入,它的行数 num_embeddings就是多少;一个单词的词嵌入维度是多少,它的列数 embedding_dim就是多少;下图是 embedding的解释:

首先 nn.Embedding(vocabs, embedding_dim):vocabs:代表去重之后的词汇总量、embedding_dim:代表你想表示每个词的词向量维度,本质,一旦运行完即实例化完这个对象,它就会在神经网络中初始化一个矩阵,形状为:vocabs * embedding_dim;现在有一句 "我爱女的",分成四个字即 vocabs=4,想把每个单词用三维向量表示 即 embedding_dim=3 ,实例化完这个对象就变成了图中 4行3列的矩阵,如何得知某个单词对应的向量,比如"我"?:一旦初始化之后旧不会再变了,"我"对应的是第 1行的向量、"爱"对应的是第 2行的向量,...;根据索引去查表:look up table查表,即一旦分词完,每个词的索引就固定了,然后根据索引找向量(每行);
代码中:seq_ids = tokenizer.texts_to_sequences(word_list)将文本序列转换成数字序列,为什么要转数字?:因为这个是索引,只有数字才能充当索引;所以nn.Embedding(num_embeddings=xx, embedding_dim=xx)中 num_embeddings是 int类型,即 id是整数;
Embedding本质就是一个矩阵,根据每个单词对应的数字(此数字即为索引),拿着索引查表,查到的那行向量就是这个单词对应的向量,一开始他是标准正太分布初始化分布的,随着模型的迭代会随着任务而更新,此为 nn.embedding;