我想让 Claude Code 能自己打开浏览器,访问亚马逊,搜竞品,拿价格和评分,截图存下来------全程不动手。
查了一圈,发现微软官方出了个 Playwright MCP Server,专门干这个的。但中文教程几乎为零,英文资料也零零散散。
这篇文章就是我从零到跑通的完整记录。中间踩了 3 个坑,第 2 个坑花了我最久。
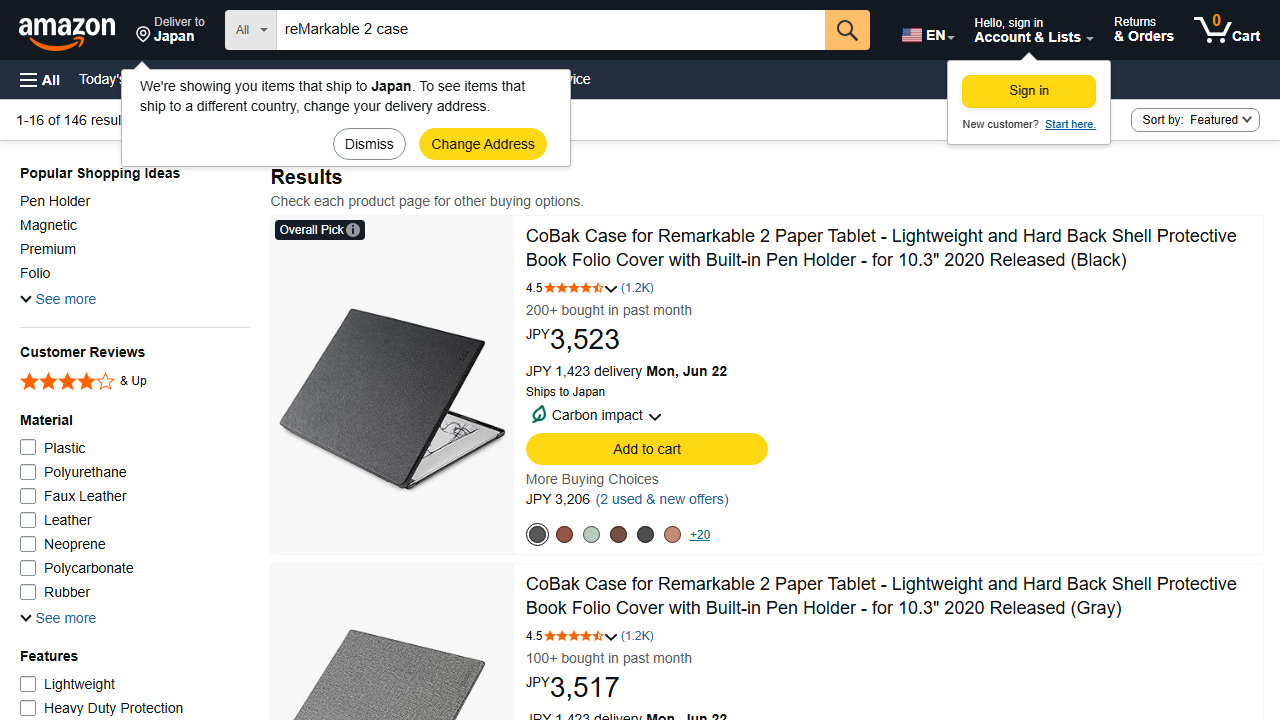
先看最终效果:Claude Code 通过 Playwright MCP 操控 Chromium,访问亚马逊搜索 "reMarkable 2 case",5 秒内提取了 5 个产品的标题、价格、评分,并保存了截图。
背景:我为什么需要浏览器自动化
我是做跨境电商运营的,经常需要分析亚马逊竞品。以前的做法是:
- 手动打开浏览器
- 搜索关键词
- 一个一个复制标题、价格、评分
- 粘贴到表格里
一个品类 20 个竞品,光采集数据就要 30 分钟。如果能让 Claude Code 自动做这件事,我只需要说一句"帮我分析 reMarkable 2 保护套的竞品情况"。
MCP(Model Context Protocol)协议是 2024 年底 Anthropic 推出的,2026 年上半年开始爆发式增长。它的核心思路很简单:让 AI 能调用外部工具。Playwright MCP 就是微软基于这个协议做的浏览器自动化 Server------让 Claude Code 能操控真实的 Chrome 浏览器。
📷 截图:Claude Code MCP 架构示意图
环境准备
我的环境:
Windows 11
Node.js v22.14.0
npm 10.9.2
Claude Code v2.1.168安装过程
Step 1:安装 @playwright/mcp
npm install @playwright/mcp3 个包就装好了,速度很快。到这一步没有任何问题------我当时还以为这玩意儿很简单。
然而这才是第一个坑的开始。
坑 1:装了包 ≠ 能用,Chromium 浏览器要单独装
装完 @playwright/mcp 后,我兴冲冲写了个测试脚本:
const { chromium } = require('playwright');
const browser = await chromium.launch({ headless: true });运行,直接报错:
browserType.launch: Executable doesn't exist at
C:\Users\...\ms-playwright\chromium_headless_shell-1224\chrome-headless-shell.exe
Looks like Playwright was just installed or updated.
Please run the following command to download new browsers:
npx playwright install@playwright/mcp 只是一个 JS 包,它依赖的 Chromium 浏览器二进制需要单独下载。 而且大小不小:
npx playwright install chromium
# 下载 Chrome for Testing 149.0.7827.3 ------ 183.5 MiB
# 下载 Chrome Headless Shell ------ 113.6 MiB
# 合计约 300MB这个坑耽误了我 10 分钟。官方的 README 里提了一句 Requirements,但没有强调"装完包之后还要装浏览器"。对于第一次接触 Playwright 的人来说,这个很容易漏掉。
教训:npm install @playwright/mcp 之后,马上执行 npx playwright install chromium,不要跳过。
Step 2:把 Playwright MCP 接入 Claude Code
安装完成后,用 Claude Code 的 MCP 命令添加:
claude mcp add playwright -- npx @playwright/mcp@latest返回:
Added stdio MCP server playwright with command: npx @playwright/mcp@latest to local config验证连接:
claude mcp list
# playwright: npx @playwright/mcp@latest - ✓ Connected看到 ✓ Connected 就说明通了。
坑 2:--headless 参数传不进去
我想让浏览器在后台跑(headless 模式),所以试了这个命令:
claude mcp add playwright -- npx @playwright/mcp@latest --headless结果 Claude Code 报错:
error: unknown option '--headless'
(Did you mean --header?)排查了半天才搞明白:claude mcp add 会把 --headless 当成自己的参数,而不是传给 npx 的参数。
解决办法:不需要手动传 --headless。 Claude Code 调用 MCP 工具时,Playwright 默认在 headless 模式启动浏览器。如果你直接写 Playwright 脚本(像我后面的测试),在 chromium.launch({ headless: true }) 里指定就行。
这是一个工具链之间的"参数边界"问题------每个 CLI 工具的参数解析器各管各的,参数不会自动穿透。以后遇到类似的 MCP Server 配置,记住:传给 MCP Server 的参数和传给 Claude Code 的参数是两回事。
Step 3:验证------写一个测试脚本跑亚马逊
MCP Server 连上了,但我想确认它真的能操控浏览器。于是写了一个直连 Playwright 的测试脚本(不走 MCP,直接调 Playwright API):
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext({
userAgent: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
});
const page = await context.newPage();
// 访问亚马逊搜索页
await page.goto('https://www.amazon.com/s?k=reMarkable+2+case', {
timeout: 30000,
waitUntil: 'domcontentloaded'
});
console.log('页面标题:', await page.title());
// 提取前5个产品
const products = await page.evaluate(() => {
const items = document.querySelectorAll('[data-component-type="s-search-result"]');
return Array.from(items).slice(0, 5).map(item => {
const title = item.querySelector('h2')?.textContent?.trim() || 'N/A';
const priceWhole = item.querySelector('.a-price-whole')?.textContent?.trim() || '';
const priceFraction = item.querySelector('.a-price-fraction')?.textContent?.trim() || '';
const price = priceWhole ? `$${priceWhole}${priceFraction ? '.' + priceFraction : ''}` : 'N/A';
const rating = item.querySelector('.a-icon-alt')?.textContent?.trim() || 'N/A';
return { title: title.substring(0, 100), price, rating };
});
});
console.log(JSON.stringify(products, null, 2));
// 截图保存
await page.screenshot({ path: 'amazon_test.png' });
console.log('截图已保存');
await browser.close();
})();运行结果:
=== 启动 Chromium (headless) ===
页面标题: Amazon.com : reMarkable 2 case
[1] CoBak Case for Remarkable 2 Paper Tablet - Lightweight...
价格: $35.23 | 评分: 4.5 out of 5 stars
[2] CoBak Case for Remarkable 2 Paper Tablet - Lightweight...
价格: $35.17 | 评分: 4.5 out of 5 stars
[3] CoBak Premium PU Leather Case for 10.3" Remarkable 2...
价格: $113.90 | 评分: 4.5 out of 5 stars
[4] MoKo Case for Remarkable 2 Tablet, Ultra-Thin Magnetic...
价格: $28.82 | 评分: 4.5 out of 5 stars
[5] CoBak Case for Remarkable 2 Paper Tablet with Two Viewing...
价格: $47.99 | 评分: 4.5 out of 5 stars
截图已保存: amazon_test.png
✅ 浏览器自动化测试成功!跑通了! 从安装到实际跑通亚马逊数据采集,核心代码只有 30 行。
坑 3:中文路径导致 npm 初始化失败
在验证目录下执行 npm init -y 时,报错:
npm error Invalid name: "验证_playwright_mcp"npm 不支持中文目录名。不过这个不影响功能------npm install 在中文路径下仍然正常工作,只是不能 npm init。
教训:做技术验证时用英文目录名,省掉不必要的麻烦。
Claude Code 如何通过 MCP 调用 Playwright
当你在 Claude Code 里说"帮我打开亚马逊搜 reMarkable 2 case"时,背后的流程是这样的:
你说:"帮我搜亚马逊竞品"
↓
Claude Code 解析意图
↓
调用 MCP 工具:browser_navigate("https://amazon.com")
↓
Playwright MCP Server 接收指令
↓
Chromium 执行实际操作(打开网页、输入、点击、提取)
↓
返回结构化数据(accessibility tree)给 Claude Code
↓
Claude Code 分析数据,回复你结果关键点:Playwright MCP 不截图给 AI 看,而是返回页面的 accessibility tree(无障碍树)。这是一种结构化的页面描述,比截图省 token、比 HTML 更干净,AI 理解起来更准。
这解释了为什么官方 README 强调 "No vision models needed"------不需要多模态模型,纯文本模型就能"看懂"网页。
📷 截图:MCP 调用流程图
这套方案能做什么、不能做什么
✅ 适合的场景
| 场景 | 示例 |
|---|---|
| 竞品数据采集 | 搜亚马逊/淘宝关键词,提取价格、评分、评论数 |
| 网页监控 | 定时检查某个页面的价格变化、库存状态 |
| 自动化测试 | 登录→操作→断言→截图,全自动 |
| 表单填写 | 批量提交、注册测试 |
| 数据爬取 | 提取结构化信息保存为 JSON/CSV |
❌ 不推荐的场景
| 场景 | 原因 |
|---|---|
| 需要验证码的页面 | MCP 不能自动过验证码 |
| 需要登录的复杂网站 | Cookie/Session 管理复杂,容易掉 |
| 反爬严格的大型电商 | 亚马逊等有反爬机制,高频访问可能被封 IP |
| 需要人眼判断的页面 | Playwright 用无障碍树而非截图,视觉设计类任务不适合 |
⚠️ 安全提醒
不要把 MCP 浏览器自动化用在不合规的用途上。亚马逊等平台的 Terms of Service 对自动化访问有明确限制。本文演示的是技术可行性,实际使用时请遵守目标网站的 robots.txt 和服务条款。
可复制部分
完整安装命令(3 步)
# Step 1: 安装 Playwright MCP
npm install @playwright/mcp
# Step 2: 安装 Chromium 浏览器(~300MB)
npx playwright install chromium
# Step 3: 添加到 Claude Code
claude mcp add playwright -- npx @playwright/mcp@latest验证连接
claude mcp list
# 看到 playwright: ✓ Connected 就行Playwright 浏览器自动化测试脚本
完整脚本见上方 Step 3,核心流程:
chromium.launch({ headless: true })→ 启动浏览器page.goto(url)→ 访问目标页面page.evaluate()→ 提取数据page.screenshot()→ 截图browser.close()→ 关闭
MCP 配置 JSON(如果要手动配置)
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["@playwright/mcp@latest"]
}
}
}给你的 Claude Code 的提示词模板
使用 Playwright MCP 帮我做竞品分析:
1. 打开 https://www.amazon.com
2. 搜索 "[你的关键词]"
3. 提取前 10 个搜索结果的:标题、价格、评分、评论数
4. 按价格从低到高排序
5. 截图保存
6. 总结价格区间和评分分布避坑清单(建议收藏)
- 装完
npm install @playwright/mcp后,必须执行npx playwright install chromium claude mcp add的参数不会自动传给 npx,不要加--headless- 用英文目录名,避免 npm init 报错
- Chromium 下载约 300MB,确保网络和磁盘空间
- 第一次访问亚马逊可能被反爬,User-Agent 设成真实浏览器的
- MCP Server 配置保存在
.claude.json(项目级)或~/.claude.json(用户级) - Playwright MCP 返回的是无障碍树,不是截图------别指望 AI"看到"页面长什么样
总结
Playwright MCP + Claude Code 是能真实跑通的浏览器自动化方案。安装 3 步、踩 3 个坑、核心代码 30 行,就能让 AI 替你操控浏览器。但别把它想得太神------该踩的坑一个不会少,反爬、验证码、复杂登录都还是硬骨头。
对于亚马逊竞品分析这个场景,它能帮你省掉 80% 的重复劳动,但最后的判断和策略还是要你自己做。