问题与思考:
为什么会有梯度消失?
导数最大为0.25,0.25^5 接近0,会导致导数、梯度值无限接近0,网络参数将更新极其缓慢,或者无法更新。
x > 6 或 x < -6 时,导数接近0,会导致梯度无线接近0,网络参数将更新极其缓慢,或者无法更新。
模型构建、训练、评估流程总结
1.数据处理
1.1 构建数据集对象:
数据读取、转换为tensor、格式float32
TensorDataset() # 将x、y对应起来
dataloader = DataLoader() # 切分数据
- 模型构建
class CreatModel(nn.Module):
def init (self, input_num, output_num):
super().init ()
layer1 = torch.nn.Linear()
def forward(self, x):
添加激活函数,并进行dropout
x = self.dp(torch.relu(self.layer1(x)))
model = CreatModel(input_num=20, output_num=4)
3.模型训练
3.1 构建损失函数:
error = torch.nn.CrossEntropyLoss(分类任务)| error = torch.nn.SmoothL1Loss(回归任务)
3.2 创建优化器: 用于之后更新梯度、梯度下降优化 ------ opentimier = torch.optim.SGD() | optimizer = optim.Adam(params=w, lr=0.001, betas=(0.9, 0.8))
for epoch in range(epochs):
for x,y_true in dataloader:
3.3 模型预测:y_pred = model(x)
3.4 计算损失:loss = error(y_pred,y_true)
3.5 梯度归零
自动微分、更新参数
3.6 计算梯度:loss.backward()
3.7 更新梯度:opentimier.step()
4.模型评估
4.1 加载模型训练好的参数:
model.load_state_dict(torch.load(r"model.pth", weights_only=True))
4.2 计算准确率
for x, y in test_dataloader:
y_pred = model(x)
y_pred = torch.argmax(y_pred, dim=-1)
correct += (y_pred == y).sum()
print(f"准确率:{correct/len(dataloader.dataset)}")
一、神经网络
1、什么是神经网络?
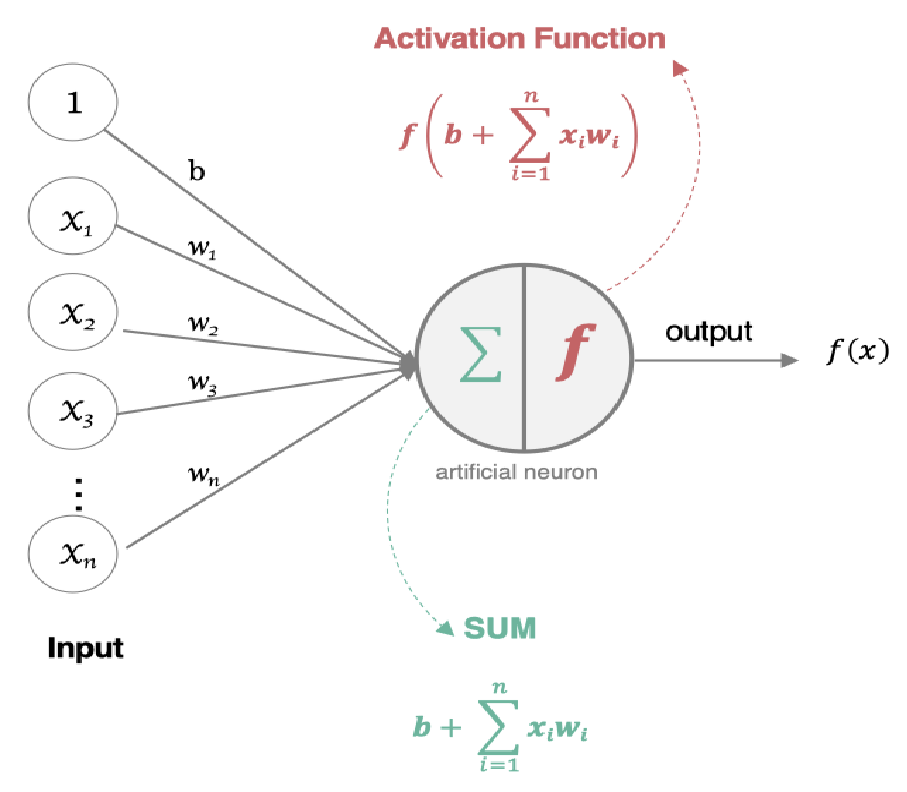
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型,由多个神经元构成(加权和+激活函数)
人脑中的神经元:各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通过轴突输出信号。当电信号通过树突进入到细胞核时,会逐渐聚集电荷。达到一定的电位后,细胞就会被激活,通过轴突发出电信号
① 什么是神经元?
神经元构成(加权和+激活函数)
不同的输入的特征(每个特征权重不同)的信息, 进行的加权计算, 输入到神经元中做加和(类似线性回归),再通过激活函数(非线性函数)输出预测值。
作用:拟合特征与目标值,接收输入的特征、拟合之后输出预测值。
② 多个神经元来构建神经网络
相邻层之间的神经元相互连接,并给每一个连接分配一个强度(权重)
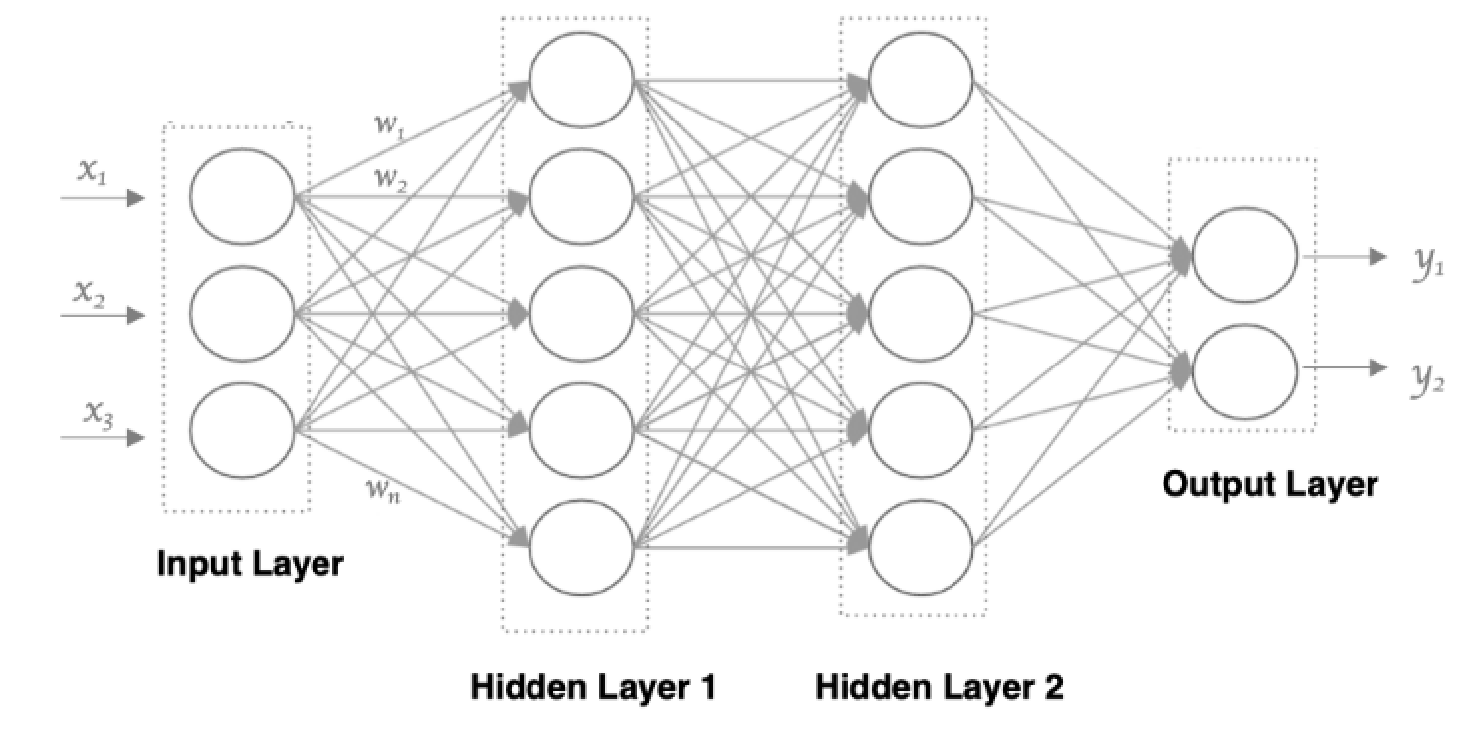
③ 神经网络的构成:
神经网络中信息只向一个方向移动,即从输入节点向前移动,通过隐藏节点,再向输出节点移动。其中的基本部分是:
输入层: 即输入 x 的那一层
输出层: 即输出 y 的那一层
隐藏层: 输入层和输出层之间都是隐藏层
特点是:
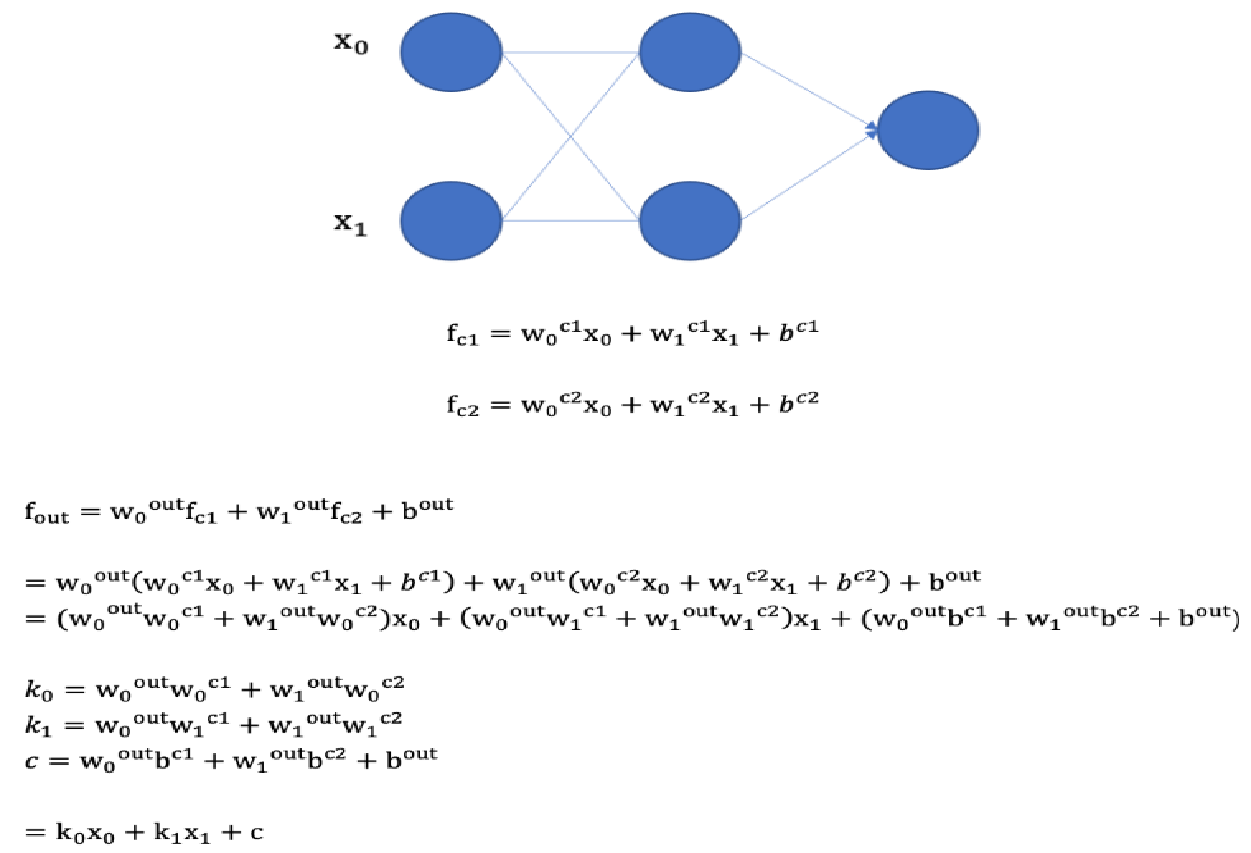
同一层的神经元之间没有连接。
第 N 层的每个神经元和第 N-1层 的所有神经元相连(这就是full connected的含义),这就是全连接神经网络。
第N-1层神经元的输出就是第N层神经元的输入。
每个连接都有一个权重值(w系数和b系数)。
2、【重要】常见的激活函数
**概念:**激活函数用于对每层的输出数据进行变换, 进而为整个网络注入了非线性因素。使神经网络可以拟合各种曲线,相当于公式中的 f。
作用: 通过给网络输出增加激活函数, 实现引入非线性因素, 使得网络模型可以逼近任意函数, 提升网络对复杂问题的拟合能力
没有引入非线性因素(激活函数)的网络等价于使用一个线性模型来拟合
公式所示:
2.1 sigmoid 激活函数
激活函数公式:
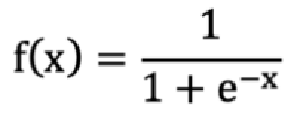
激活函数求导公式:
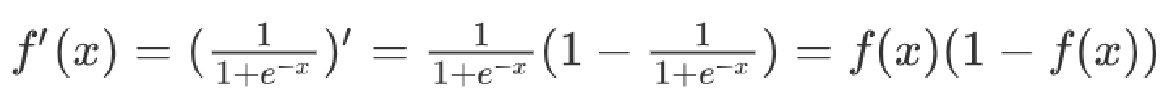
sigmoid 激活函数的函数图像如下:
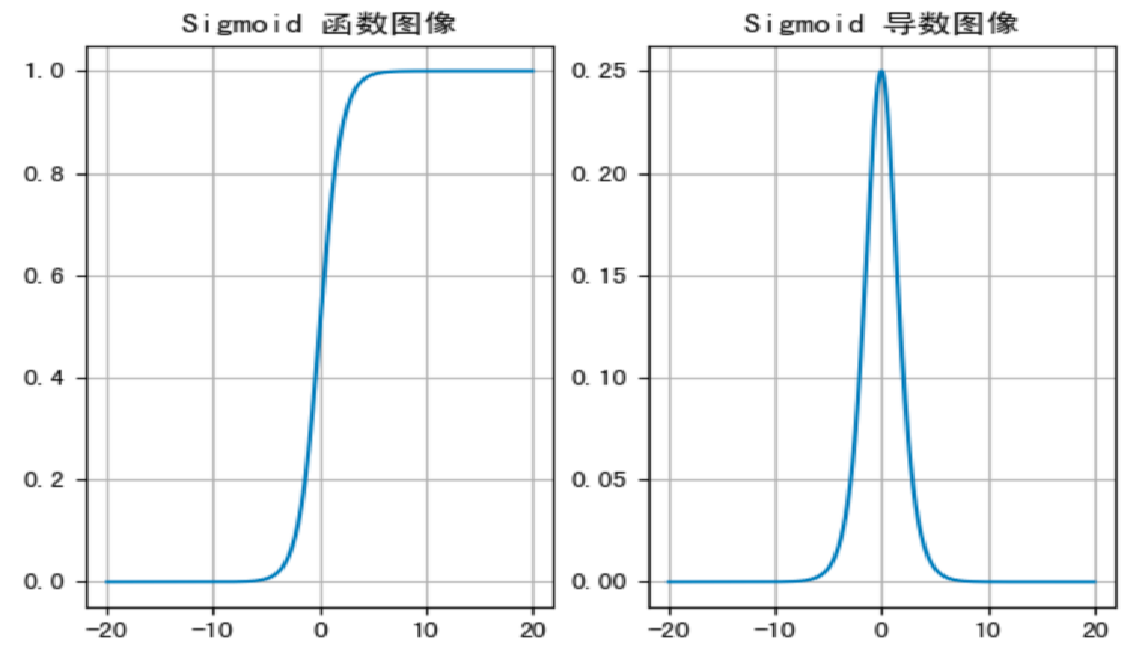
作用:
sigmoid 函数可以将任意的输入映射到 (0, 1) 之间,输入值在 -6, 6 之间输出值才会有明显差异,输入值在 -3, 3 之间才会有比较好的效果。
缺点:
当输入的值大致在 <-6 或者 >6 时,意味着输入任何值得到的激活值都是差不多的,这样会丢失部分的信息。比如:输入 100 和输出 10000 经过 sigmoid 的激活值几乎都是等于 1 的,但是输入的数据之间相差 100 倍的信息就丢失了。
当输入 <-6 或者 >6 时,sigmoid 激活函数图像的导数接近为 0,此时网络参数将更新极其缓慢,或者无法更新。
sigmoid 网络在 5 层之内就会产生梯度消失现象。
适用场景:
sigmoid函数一般只用于二分类 的**输出层,**不要在隐藏层中使用
输入值在 -6, 6 之间输出值才会有明显差异,输入值在 -3, 3 之间才会有比较好的效果。
2.2 tanh 激活函数
Tanh 的公式如下:
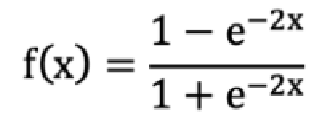
激活函数求导公式:
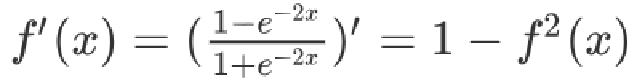
Tanh 的函数图像、导数图像如下:
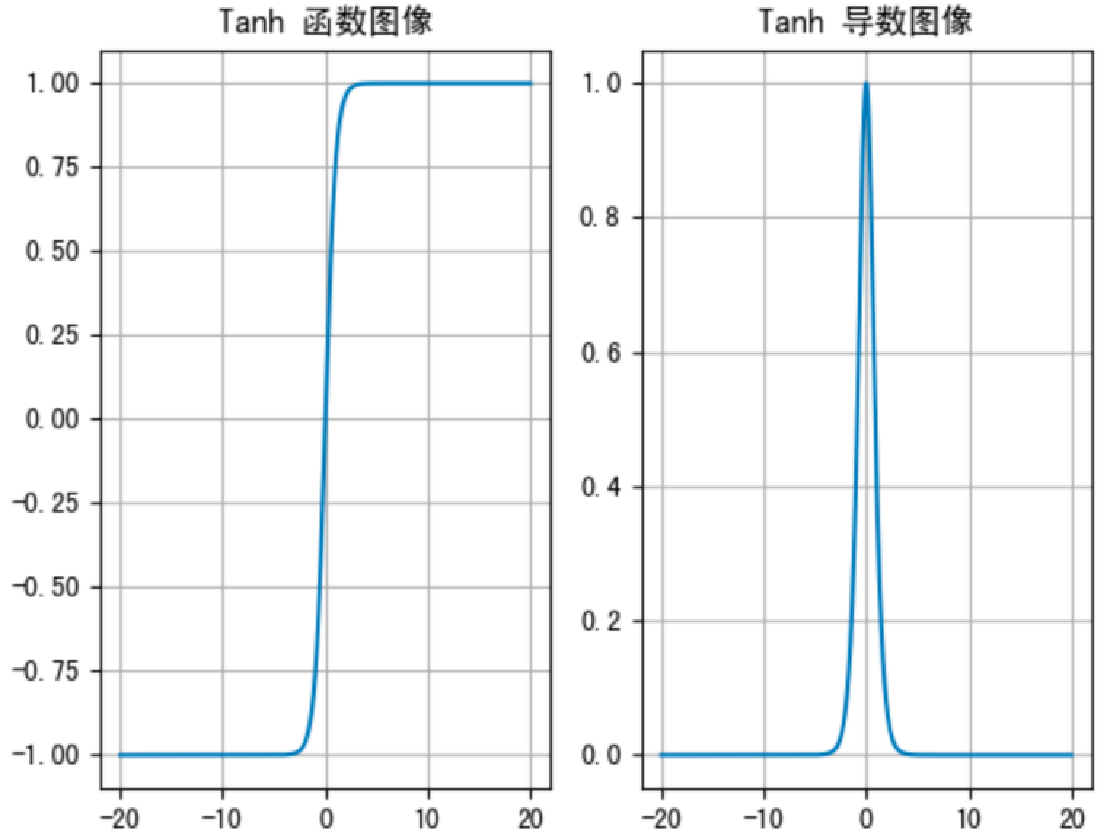
作用:
Tanh 函数将输入映射到 (-1, 1) 之间,图像以 0 为中心,在 0 点对称,当输入 大概<-3 或者 >3 时将被映射为 -1 或者 1。其导数值范围 (0, 1),当输入的值大概 <-3 或者 > 3 时,其导数近似 0。
缺点:
输入 <-3 或者 >3 时,的导数也为 0,同样会造成梯度消失。(可以将数据标准化,从而使数据集中在-3,3间,来避免这个问题)
适用场景:
若使用时可在隐藏层使用tanh函数,在输出层使用sigmoid函数
2.3 ReLU 激活函数
ReLU 公式如下:
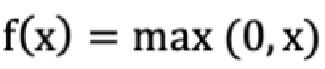
激活函数求导公式:
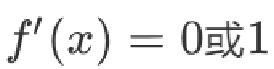
ReLU 的函数图像如下:
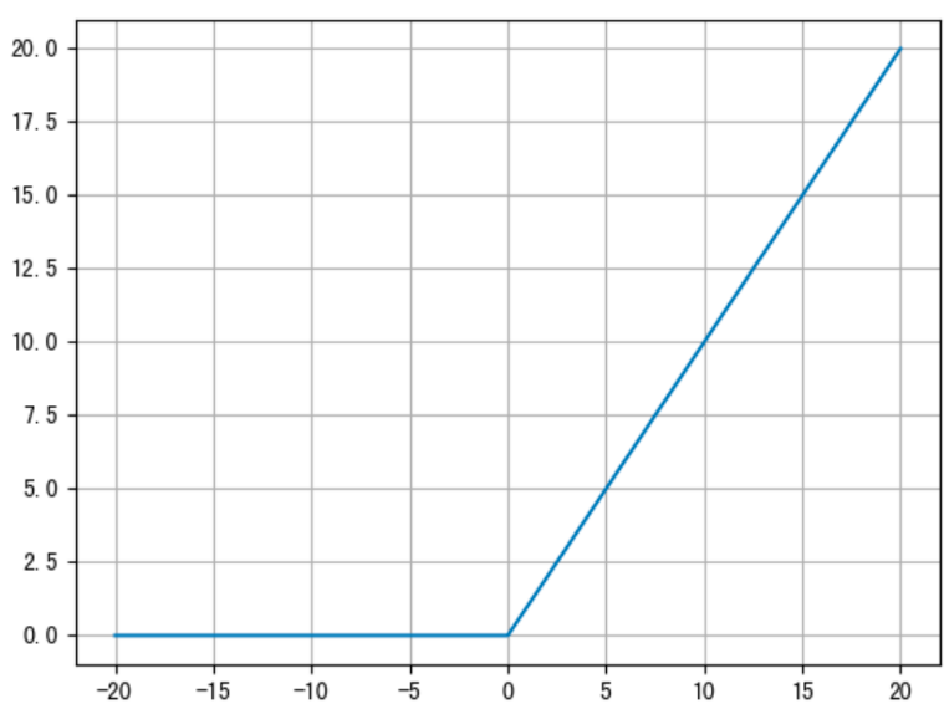
作用:
ReLU 能够在x>0时保持梯度不衰减(不改变x的梯度),从而缓解梯度消失问题。
将小于 0 的值映射为 0,导致对应权重无法更新。这种现象被称为"神经元死亡",这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率
缺点:
输入落入小于0区域,导致对应权重无法更新。这种现象被称为"神经元死亡"
使用场景:
ReLU是目前最常用的激活函数,无脑用ReLU,不行再使用其它
2.4 SoftMax 激活函数
计算方法如下图所示:

作用:
softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来
函数值域:0 - 1
使用场景:
多分类任务的输出,将输出结果转换为概率形式。
2.5 其他常见的激活函数
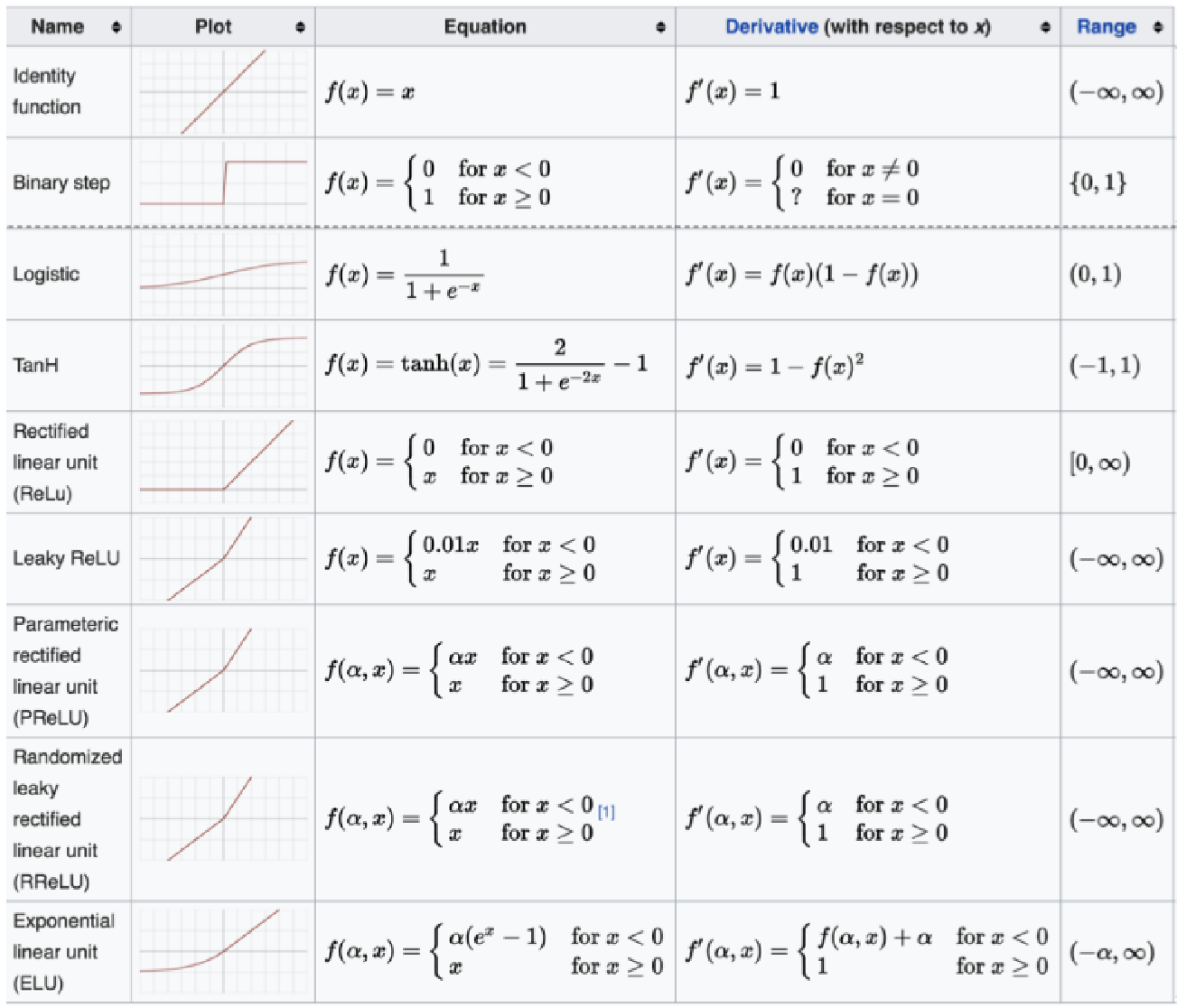
2.6 【理解】激活函数的选择方法
对于隐藏层:
优先选择ReLU激活函数
如果ReLu效果不好,那么尝试其他激活,如Leaky ReLu等。
如果你使用了ReLU, 需要注意一下Dead ReLU问题, 避免出现大的梯度从而导致过多的神经元死亡。
少用使用sigmoid激活函数,可以尝试使用tanh激活函数
对于输出层:
二分类问题选择sigmoid激活函数
多分类问题选择softmax激活函数
回归问题选择identity激活函数
3、【了解】常见的参数初始化方法
参数初始化的作用:初始化w 和 b。
但在实际使用中 无论用何种初始化方法,都需对模型进行大量训练才能得到结果,和初始化方法关联不大。所以在使用中,一般使用默认的初始化方法 xavier初始化。
① kaiming 初始化,也叫做 HE 初始化 HE
初始化分为正态分布的 HE 初始化、均匀分布的 HE 初始化.
正态化的he初始化
stddev = sqrt(2 / fan_in)
均匀分布的he初始化
它从 -limit,limit 中的均匀分布中抽取样本, limit是 sqrt(6 / fan_in)
fan_in 输入神经元的个数
② xavier 初始化,也叫做 Glorot初始化
该方法也有两种,一种是正态分布的 xavier 初始化、一种是均匀分布的 xavier 初始化.
正态化的Xavier初始化
stddev = sqrt(2 / (fan_in + fan_out))
均匀分布的Xavier初始化
-limit,limit 中的均匀分布中抽取样本, limit 是 sqrt(6 / (fan_in + fan_out))
fan_in 是输入神经元的个数, fan_out 是输出的神经元个数
python
from torch import nn
# 初始化w、b
# 1、均匀分布
layer = nn.Linear(5, 3)
nn.init.uniform_(layer.weight)
nn.init.uniform_(layer.bias)
print(layer.weight.data)
print(layer.bias.data)
# 2、正态分布
layer = nn.Linear(5, 3)
nn.init.normal_(layer.weight)
nn.init.normal_(layer.bias)
print(layer.weight.data)
print(layer.bias.data)
# 3、全1分布
layer = nn.Linear(5, 3)
nn.init.ones_(layer.weight)
nn.init.ones_(layer.bias)
print(layer.weight.data)
print(layer.bias.data)
# 4、kaiming分布
layer = nn.Linear(5, 3)
nn.init.kaiming_uniform_(layer.weight)
# nn.init.kaiming_normal_(layer.weight)
print(layer.weight.data)
# 5、xavier默认使用
print(layer.weight.data)
print(layer.bias.data)4、【实践】神经网络模型的搭建
在pytorch中定义深度神经网络其实就是层堆叠的过程,继承自nn.Module,实现两个方法: init:(初始化)
① 定义一个全连接层(线性层),用于对输入数据进行特征维度的线性变换
②初始化参数(一般不用,使用默认的初始化方式就行)
③ 根据层数 循环的执行 ①、② 步骤。
forward: (前向传播)
① 数据传入第一隐藏层
② 使用激活函数(隐藏层优先使用ReLU,输出层根据需要使用 softmax,tanlu等)
③ 根据层数 循环的执行 ①、② 步骤。
python
import torch
from torch import nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 创建第一个隐藏层模型, 3个输入特征,3个输出特征
self.layer1 = nn.Linear(3, 3)
# 初始化权重
nn.init.xavier_uniform_(self.layer1.weight)
# 创建第二个隐藏层模型, 3个输入特征,2个输出特征
self.layer2 = nn.Linear(3, 2)
# 初始化权重
nn.init.kaiming_normal_(self.layer2.weight)
# 创建输出, 2个输入特征,2个输出特征
self.layer_out = nn.Linear(2, 2)
# 初始化权重
nn.init.xavier_uniform_(self.layer_out.weight)
def forward(self, x):
# 数据经过第一个线性层
x = self.layer1(x)
# 使用relu激活函数
x = torch.relu(x)
# 数据经过第2个线性层
x = self.layer2(x)
# 使用tanh激活函数
x = torch.tanh(x)
# 数据经过输出层
x = self.layer_out(x)
# 使用softmax激活函数
# dim=-1:每一维度行数据相加为1
x = torch.softmax(x, dim=-1)
return x
if __name__ == '__main__':
model = Model()
x = torch.randn([10, 3])
out = model(x)
print(out)
print(out.shape)5、神经网络模型参数的计算方法
**作用:**统计每一层中的权重w和偏置b的数量
模型参数的计算:
以第一个隐层为例:该隐层有3个神经元,每个神经元的参数为:4个(w1,w2,w3,b1),所以一共用3x4=12个参数。
输入数据和网络权重是两个不同的事儿。
输入数据:是用户输入的数据,包含特征和目标值的样本
权重:在模型训练中生成,训练,然后形成最优权重
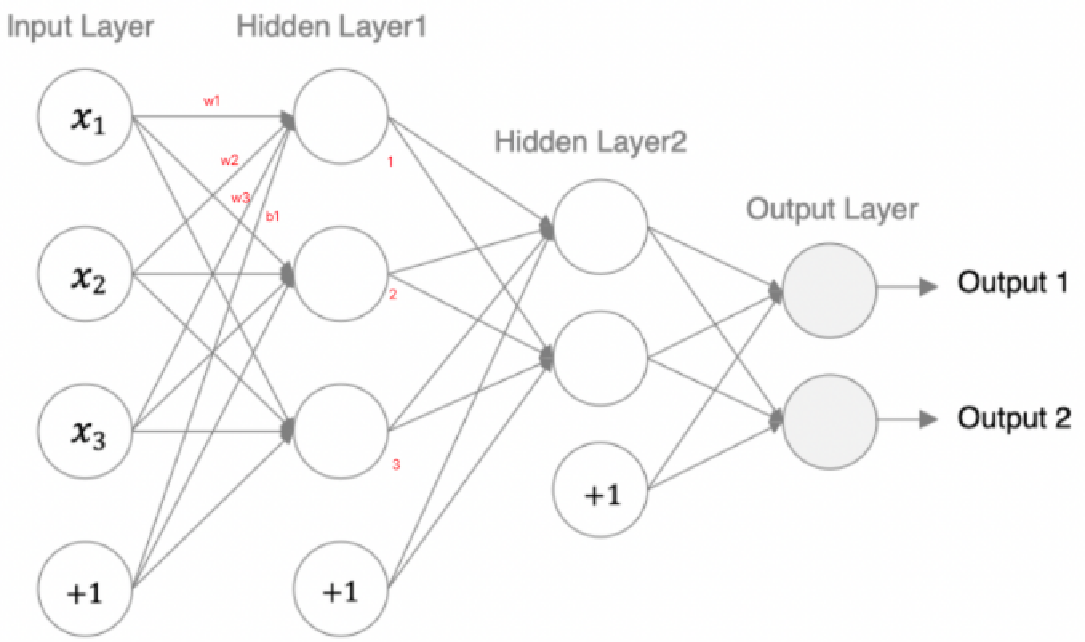
调用API,查询参数:
python
import torch
from torch import nn
from torchsummary import summary
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 创建第一个隐藏层模型, 3个输入特征,3个输出特征
self.layer1 = nn.Linear(3, 3)
# 初始化权重
nn.init.xavier_uniform_(self.layer1.weight)
# 创建第二个隐藏层模型, 3个输入特征,2个输出特征
self.layer2 = nn.Linear(3, 2)
# 初始化权重
nn.init.kaiming_normal_(self.layer2.weight)
# 创建输出, 2个输入特征,2个输出特征
self.layer_out = nn.Linear(2, 2)
# 初始化权重
nn.init.xavier_uniform_(self.layer_out.weight)
def forward(self, x):
# 数据经过第一个线性层
x = self.layer1(x)
# 使用relu激活函数
x = torch.relu(x)
# 数据经过第2个线性层
x = self.layer2(x)
# 使用tanh激活函数
x = torch.tanh(x)
# 数据经过输出层
x = self.layer_out(x)
# 使用softmax激活函数
# dim=-1:每一维度行数据相加为1
x = torch.softmax(x, dim=-1)
return x
if __name__ == '__main__':
model = Model()
x = torch.randn([10, 3])
out = model(x)
# print(out)
# print(out.shape)
# 统计网络参数
summary(model=model, batch_size=5, input_size=(3,), device="cpu")
for name, params in model.named_parameters():
print(name, params)
二、损失函数
**定义:**计算预测值与真实值的差异,是用来衡量模型参数的质量的函数
损失函数的其它命名方式:
下边的四个
1、分类任务的损失函数
1.1 【掌握】多分类损失函数:
交叉熵 :
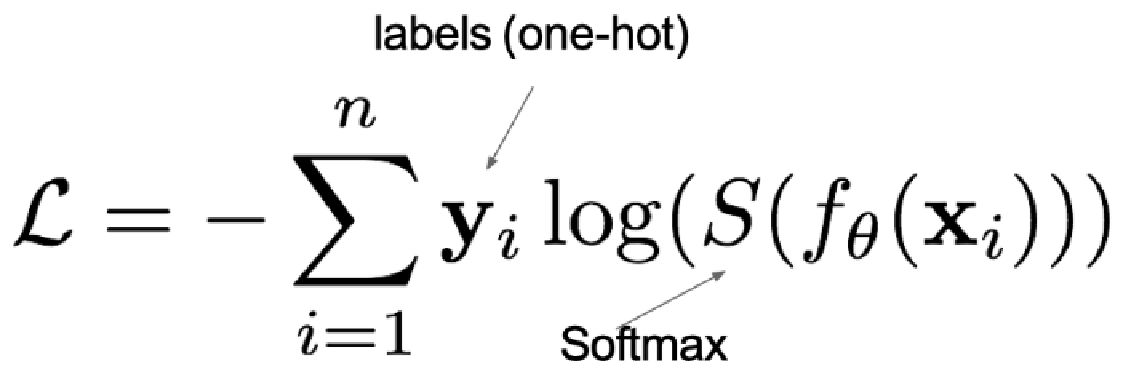
参数:
y是样本x属于某一个类别的真实概率,有两种表达方式(热编码、索引)
f(x)是样本属于某一类别的预测分数
S是softmax激活函数,将属于某一类别的预测分数转换成概率
L用来衡量真实值y和预测值f(x)之间差异性的损失结果
计算预测值与真实值的差异时,真实值可以以热编码 或者 索引形式出现。
什么是热编码?
将真实值转换为 0,1形式
例如分类有 猫、狗、猪三种,真实值为猫、狗、猪 可以转换为 \[1,0,0,0,1,0,0,0,1]
公式是怎么进行计算的?
①
② 对上边的函数注入softmax激活函数,转换有的函数值域在0,1,代表对应的概率
③ 真实值热编码为类似 1,0,0 ,只有为1时才有意义,结果为损失值,值越小代表预测越准确。
为什么要使用这个公式?
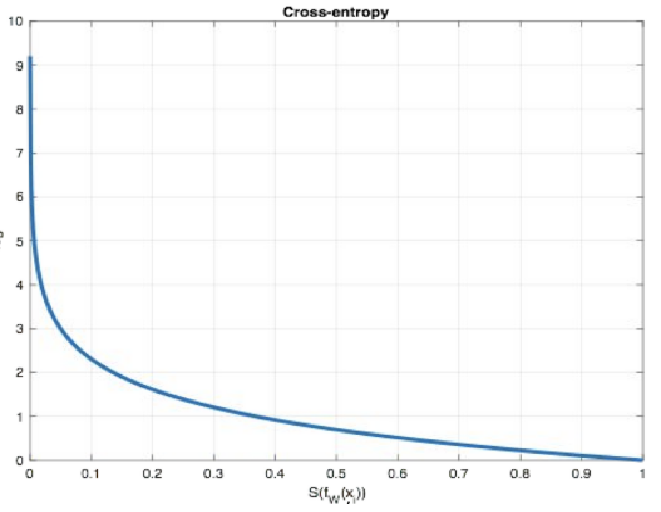
① -ln(x) 函数 在x在0,1区间,函数图像如上图所示。在x趋于0时 y值趋于无穷大,x等于1时y等于0。
② loss函数经过softmax激活函数之后,转换为概率,取值在0,1之间,值越接近1时,损失函数越小
③ 完美契合-ln(x) 函数
调用API,代码实现
使用nn.CrossEntropyLoss() 实现
python
from torch import nn
import torch
# 真实值为one-hot
# y_true = torch.tensor([[0,1,0],[1,0,0],[0,0,1]],dtype=torch.float32)
# 真实值为索引
y_true = torch.tensor([1, 0, 2], dtype=torch.int64)
y_pred = torch.tensor([
[3, 67, 5],
[28, 4, 6],
[8, 7, 23]
], dtype=torch.float32)
loss = nn.CrossEntropyLoss()
print(loss(y_pred, y_true))
# 输出
# tensor(1.5895e-07)1.2 【了解】二分类任务损失函数:
二分类交叉熵公式:
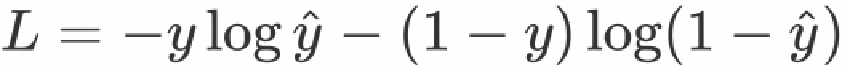
参数:
y是样本x属于某一个类别的真实概率
y^是样本属于某一类别的预测概率
L用来衡量真实值y与预测值y^之间差异性的损失结果。
调用API,代码实现:
python
import torch
# 真实值
y_true = torch.tensor([0, 1, 0], dtype=torch.float32)
# 预测值
y_pred = torch.tensor([0.2, 0.8, 0.1], dtype=torch.float32)
loss = torch.nn.BCELoss()
print(loss(y_pred, y_true))
# 输出:tensor(0.1839)2、回归任务的损失函数
2.1 【了解】MAE
概念: Mean absolute loss(MAE)也被称为L1 Loss,是以绝对误差作为距离。
损失函数公式:
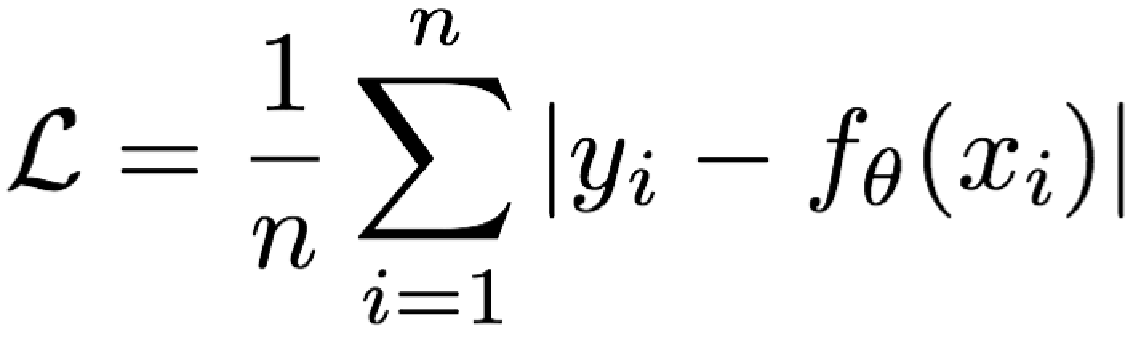
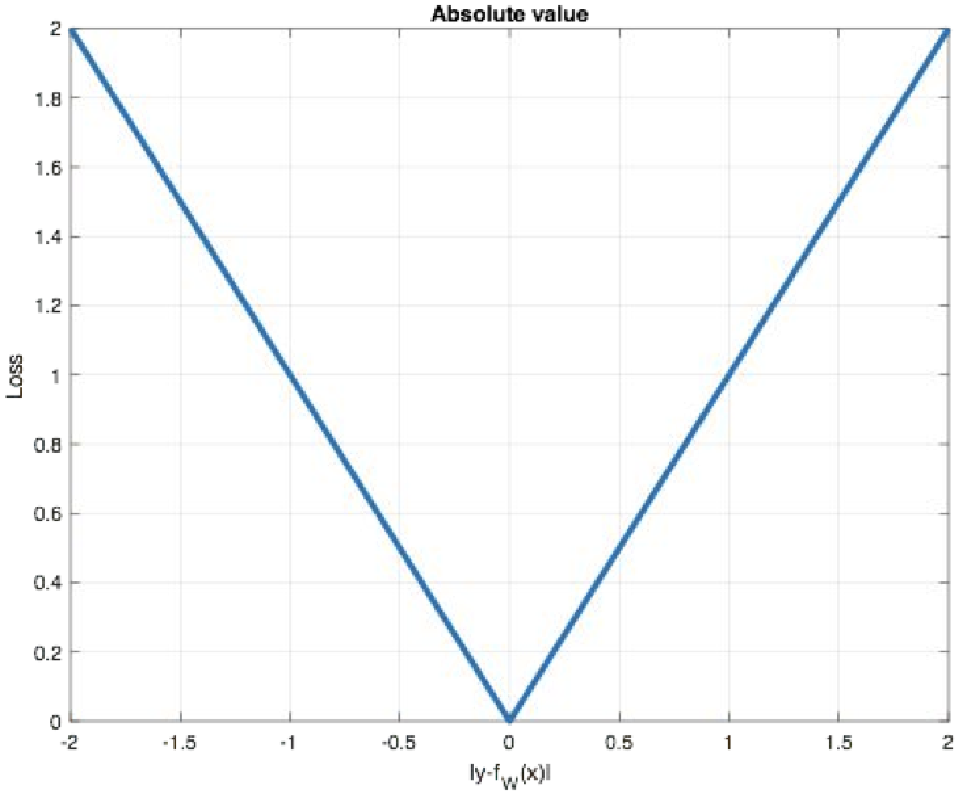
特点:
-
由于L1 loss具有稀疏性,为了惩罚较大的值,因此常常将其作为 正则项添加到其他loss中作为约束。
-
L1 loss的最大问题是梯度在零点不平滑,导致会跳过极小值。
2.2 【了解】MSE
**概念:**Mean Squared Loss/ Quadratic Loss(MSE loss)也被称为L2 loss,或欧氏距离,它以误差的平方和的均值作为距离
损失函数公式:
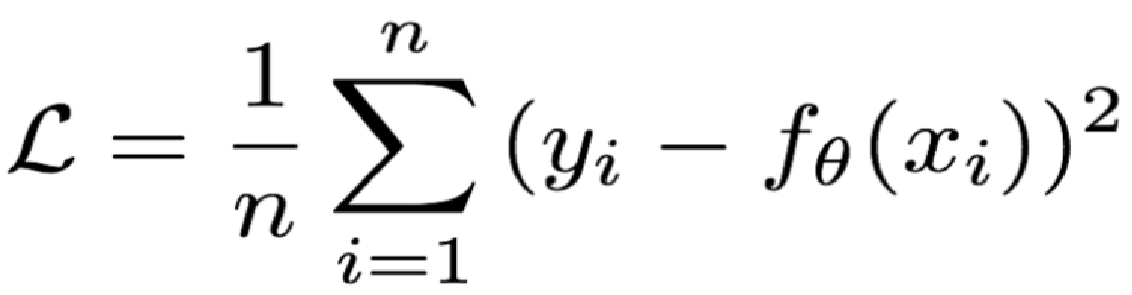
特点:
L2 loss也常常作为正则项。
当预测值与目标值相差很大时, 梯度容易爆炸。
2.3 【掌握】smooth L1
概念:
smooth L1说的是光滑之后的L1
损失函数公式:
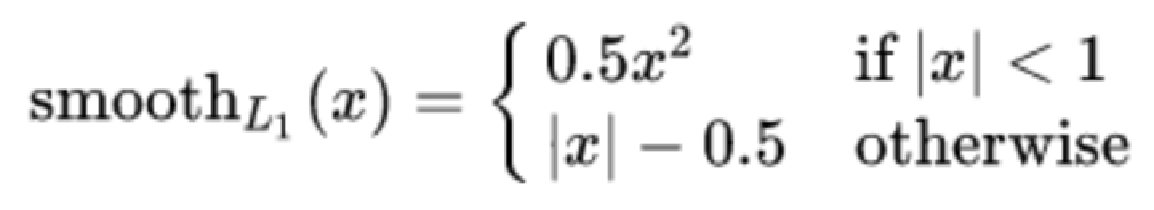
其中:𝑥=f(x)−y 为真实值和预测值的差值。
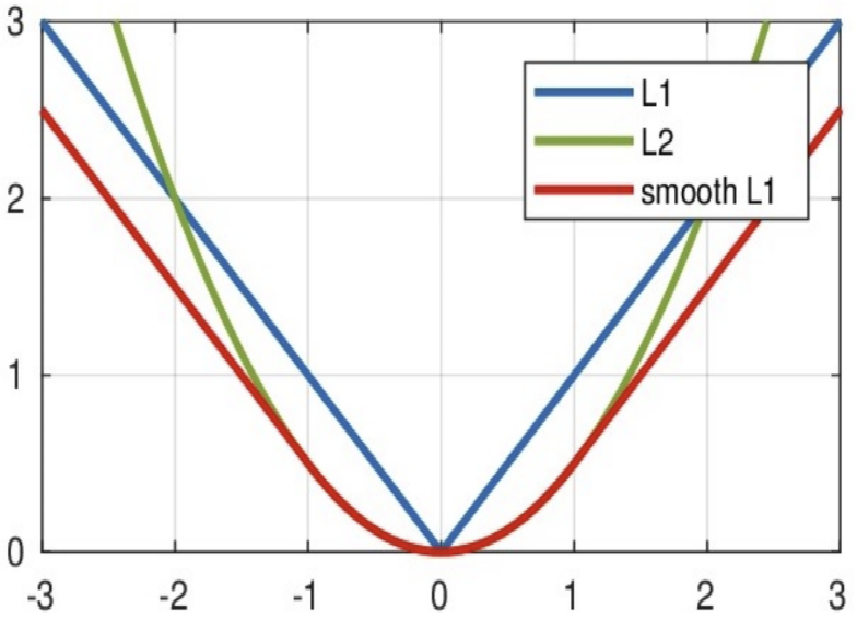
特点:
从上图中可以看出,该函数实际上就是一个分段函数
在-1,1之间实际上就是L2损失,这样解决了L1的不光滑问题
在-1,1区间外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题
API调用,代码实现
python
import torch
y_true = torch.tensor([2.0, 1.2, 3.4], dtype=torch.float32)
y_pred = torch.tensor([3.4, 5.2, 1.4], dtype=torch.float32)
loss = torch.nn.MSELoss()
print("MSE:", loss(y_pred, y_true))
loss = torch.nn.L1Loss()
print("MAE:", loss(y_pred, y_true))
loss = torch.nn.SmoothL1Loss()
print("SmoothL1:", loss(y_pred, y_true))
# 输出
"""
MSE: tensor(7.3200)
MAE: tensor(2.4667)
SmoothL1: tensor(1.9667)
"""三、网络优化方法
1. 梯度下降算法
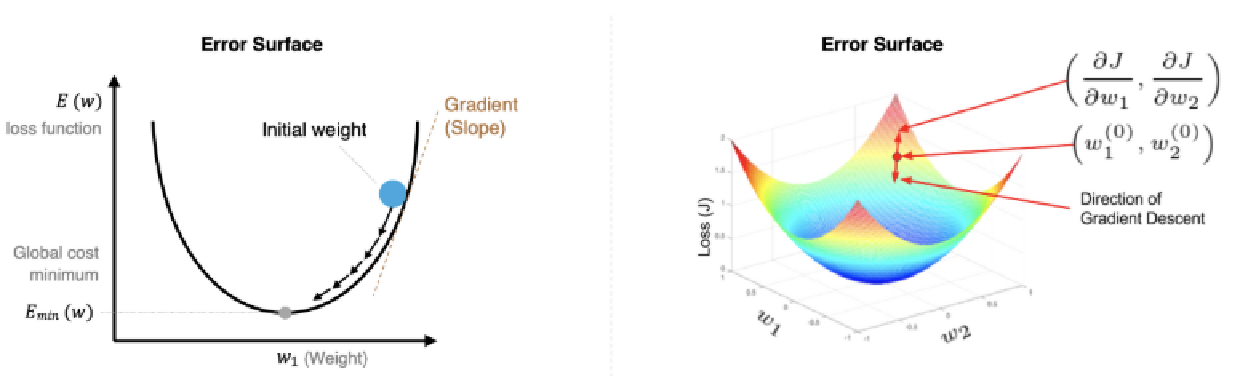
**概念:**梯度下降法是一种寻找使损失函数最小化的方法。从数学上的角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向
计算公式:
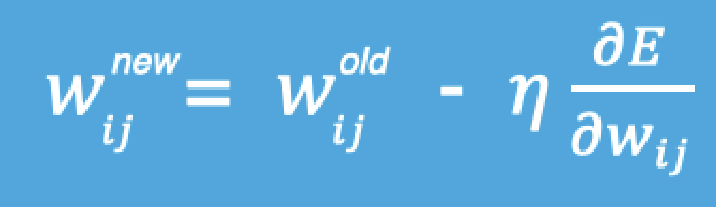
η是学习率:
学习率太小,那么每次训练之后得到的效果都太小,增大训练的时间成本
学习率太小,那么每次训练之后得到的效果都太小,增大训练的时间成本
解决的方法就是:学习率也需要随着训练的进行而变化
2 . 网络训练过程中的epoch, batch,iter参数
Epoch: 使用全部数据对模型进行以此完整训练,训练轮次
Batch_size: 使用训练集中的小部分样本对模型权重进行以此反向传播的参数更新,每次训练每批次样本数量
Iteration: 使用一个 Batch 数据对模型进行一次参数更新的过程
3. 【理解】反向传播算法(BP算法)过程
**前向传播:**指的是将特征输入到神经网络中,逐层向前传输,一直到运算到输出层为止。
反向传播(Back Propagation):利用损失函数 ERROR,从后往前,结合梯度下降算法,依次求各个参数的偏导,并进行参数更新的过程。
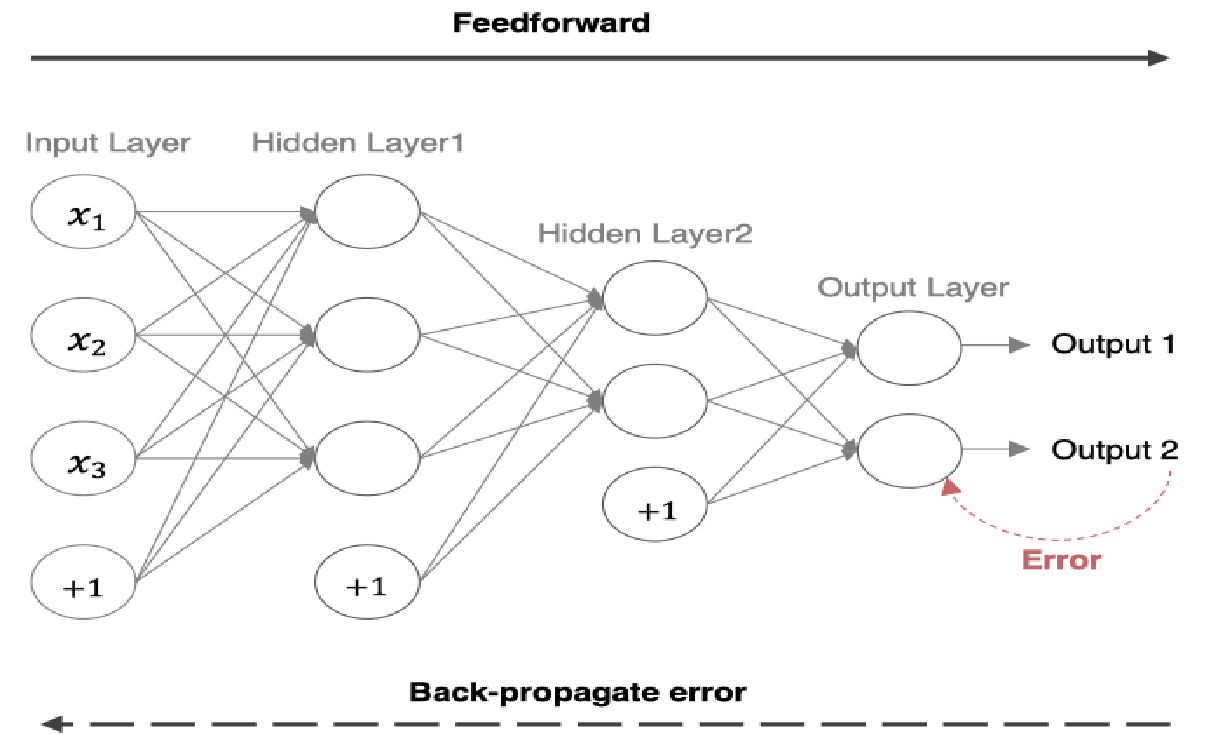
反向传播示例(激活函数为sigmoid):
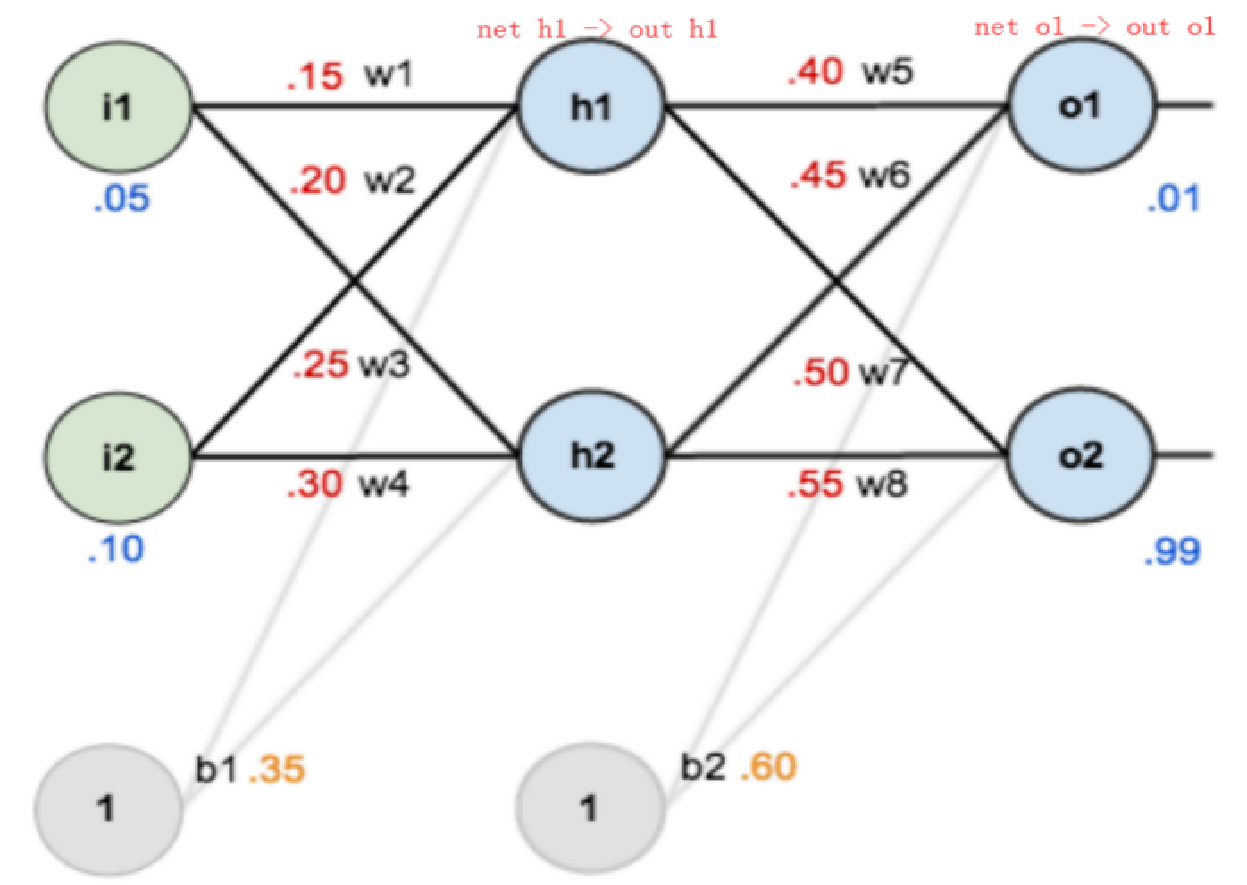
前向传播运算过程:

反向传播过程:
求误差E对w5的导数:
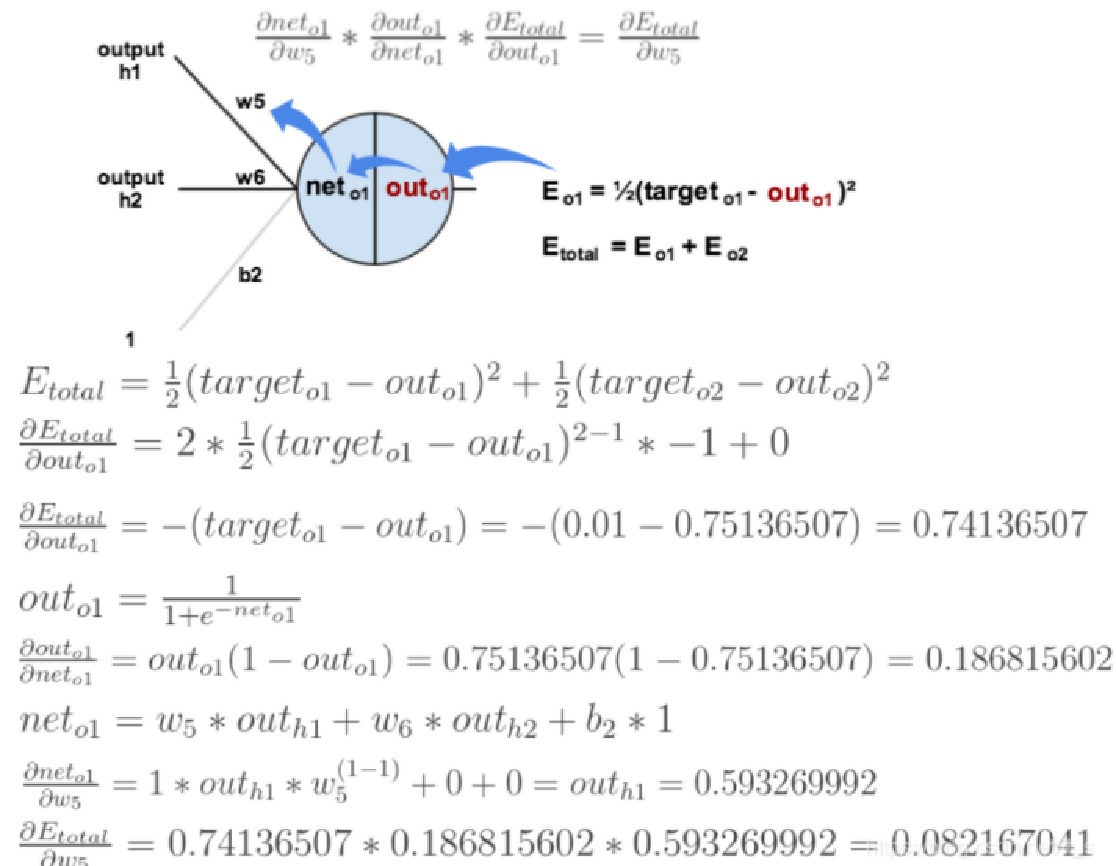
更新参数:

求误差E对w1的导数:
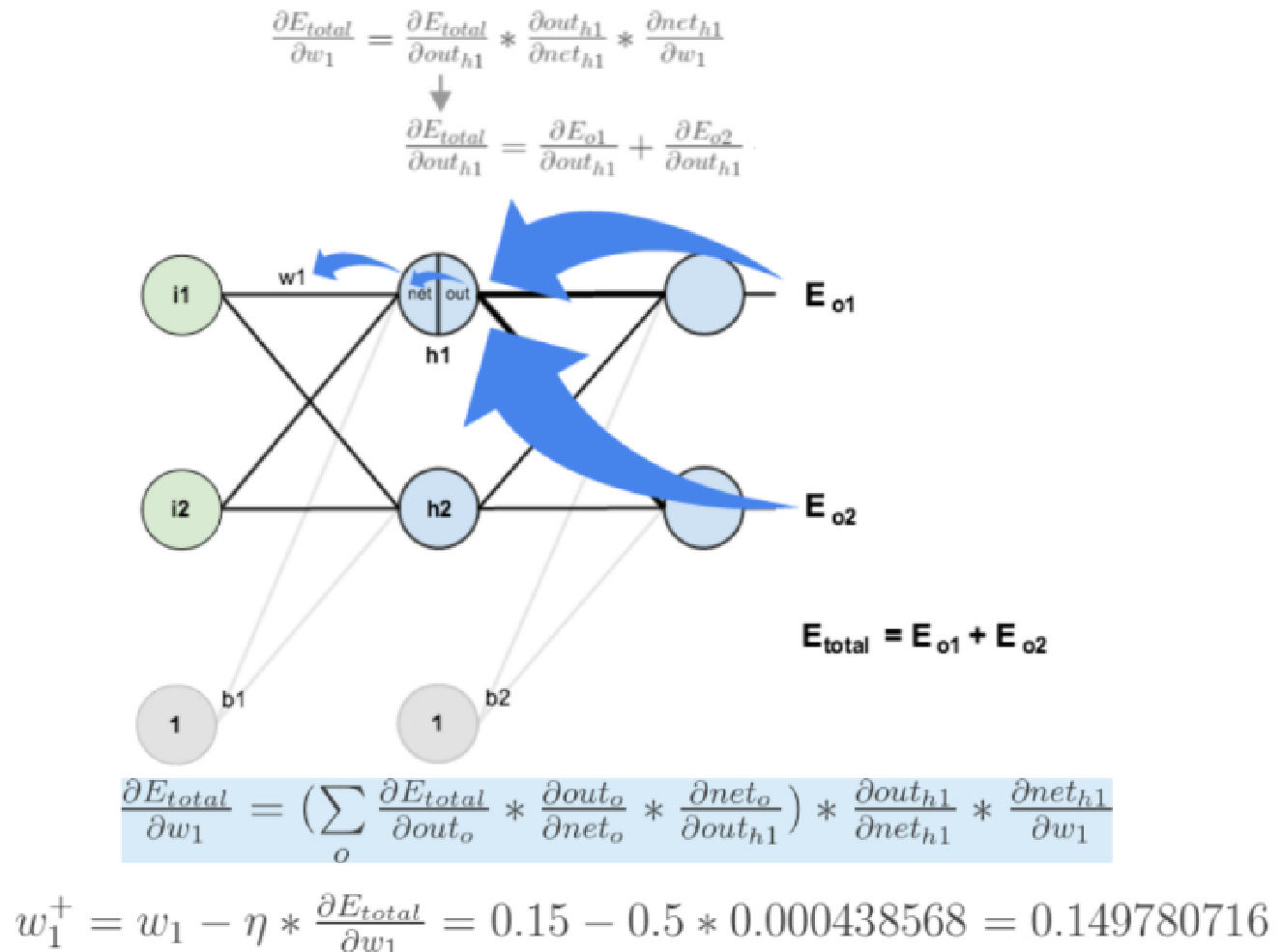
4. 【掌握】梯度下降的优化方法
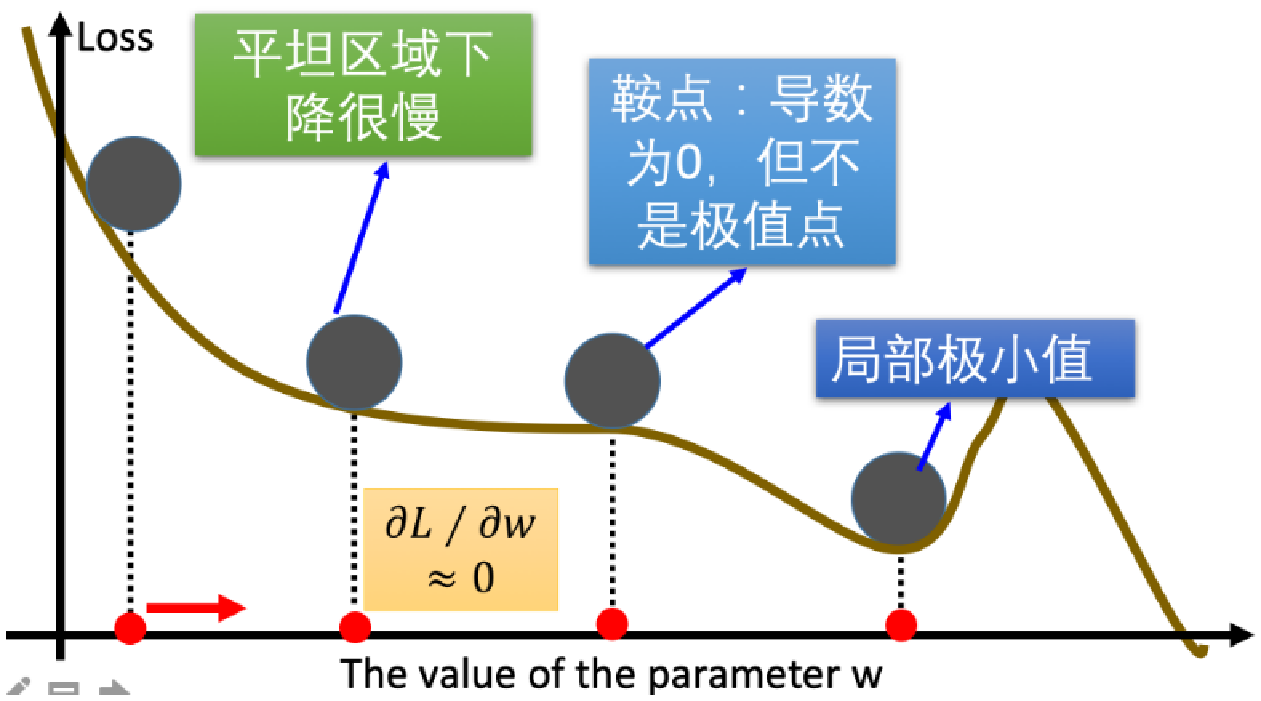
为什么要对梯度下降进行优化?
碰到平缓区域,梯度值较小,参数优化变慢
碰到 "鞍点" ,梯度为 0,参数无法优化
碰到局部最小值,参数不是最优
4.1 指数加权平均------一种处理数据的方法
作用:
使得结果更加平滑;
可以使用到之前数据,降低单次异常数据的影响
加速模型在平缓区域的收敛,同时减少目标函数平坦区域的震荡
**思想:**参考各数值,并且各数值的权重都不同,距离越远的数字对平均数计算的贡献就越小(权重较小),距离越近则对平均数的计算贡献就越大(权重越大)。
通过参数 控制,
0,1。距离越远乘以
次数就越多,影响就越小
计算公式:
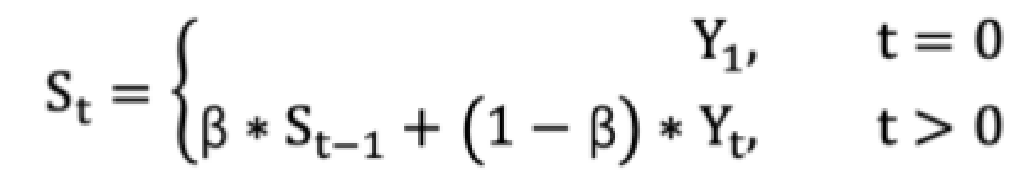
参数介绍:
St 表示指数加权平均值;
Yt 表示 t 时刻的值;
β 调节权重系数,该值越大平均数越平缓。
代码实现加权平均:
python
import torch
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("TkAgg")
tempertures = torch.randn(30) * 10
plt.scatter(range(30), tempertures)
st = []
beta = 0.8
for id, temperture in enumerate(tempertures):
if id == 0:
s = temperture
st.append(s)
continue
s = beta * st[id - 1] + (1 - beta) * temperture
st.append(s)
plt.plot(range(30), st)
plt.show()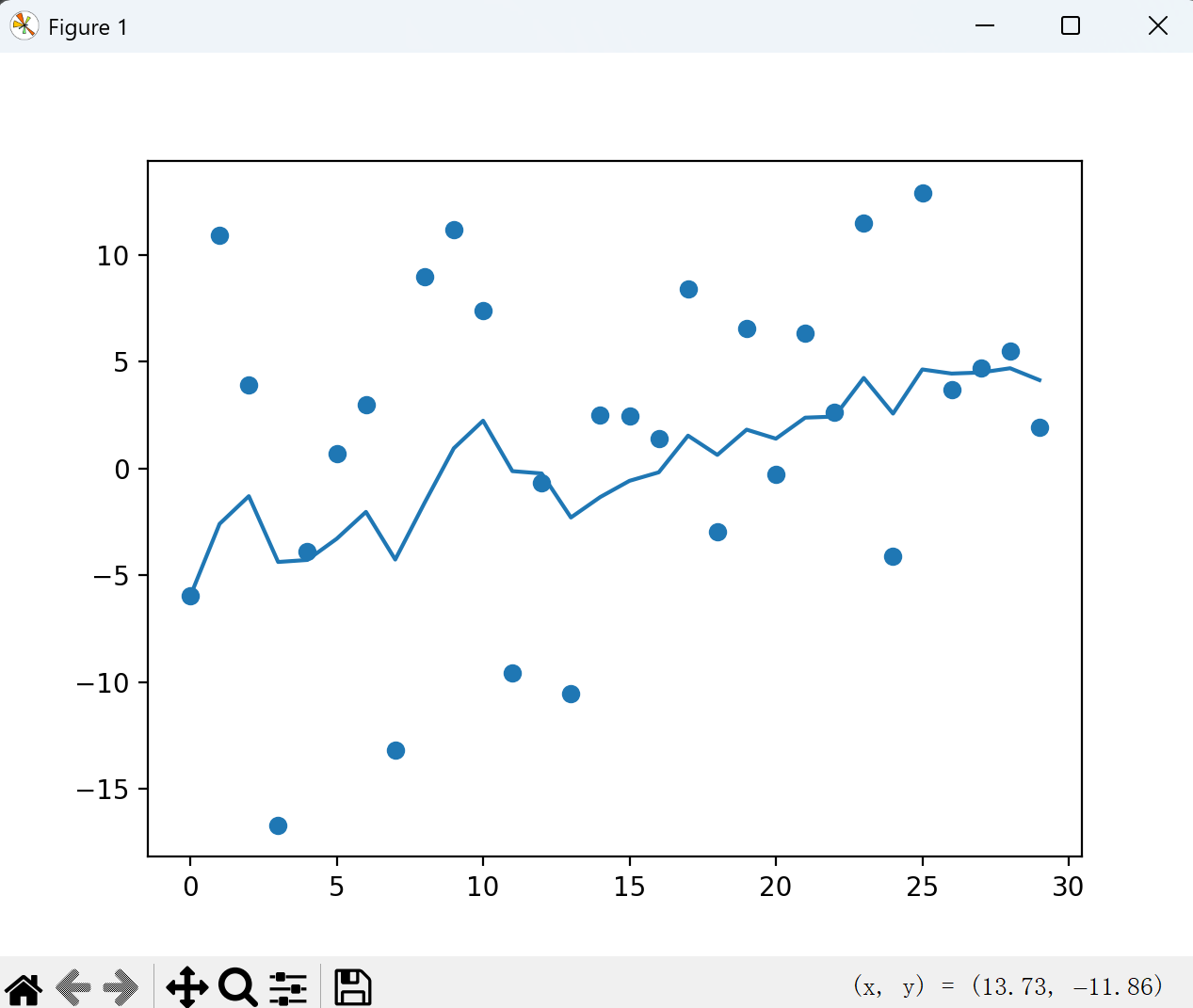
4.2 动量算法Momentum------梯度优化方法
**本质:**用历史梯度值的指数移动加权平均值,来计算当前时刻 t 的梯度值
梯度计算方法:
参数:
表示历史梯度移动加权平均值
表示当前时刻的梯度值
为当前时刻的指数加权平均梯度值
β 为权重系数
权重计算公式公式修改为:
示例: 假设权重 β 为 0.9,例如:
第一次梯度值:s1 = d1 = w1
第二次梯度值:d2=s2 = 0.9 * s1 + w2 * 0.1
第三次梯度值:d3=s3 = 0.9 * s2 + w3 * 0.1
第四次梯度值:d4=s4 = 0.9 * s3 + w4 * 0.1
梯度下降公式中梯度的计算,就不再是当前时刻 t 的梯度值,而是历史梯度值的指数移动加权平均值。
Monmentum 优化方法是如何一定程度上克服 "平缓"、"鞍点" 的问题呢?
当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程。
使用场景:一般结合学习率优化策略(指定间隔衰减使用)
代码实现:
python
import torch
from torch import optim
# 初始化数据
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 实例化优化方法
optimizer = optim.SGD(params=[w], lr=0.001,momentum=0.8)
# 更新
epochs = 2
for i in range(epochs):
optimizer.zero_grad()
loss = ((w ** 2) * 0.5).sum()
loss.backward()
print(w.grad)
optimizer.step()
print(w)4.3 学习率优化方法
4.3.1 adaGrad
**作用:**随着迭代次数的增加,使学习率越来越小
学习率计算公式:
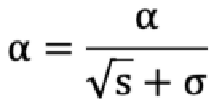
参数介绍:
初始化学习率 α
初始化梯度累积变量 s =0
g:就是梯度。 从训练集中采样 m 个样本的小批量,计算梯度 g
累积平方梯度 s = s + g*g
参数(w 权重、b 偏移量)更新公式如下:
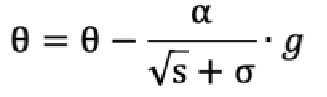
**缺点:**可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解
4.3.2 RMSProp
**作用:**对 AdaGrad 的优化。使用指数移动加权平均梯度替换历史梯度的平方和,从而避免学习率过早、过量降低的问题。
学习率 α 的计算公式如下:
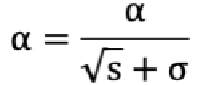
参数:
初始化学习率 α
初始化梯度累积变量 s =0
g:就是梯度。 从训练集中采样 m 个样本的小批量,计算梯度 g
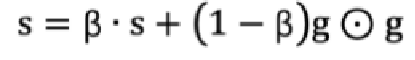 ,对梯度g*g进行指数加权平方
,对梯度g*g进行指数加权平方
参数(w 权重)更新公式如下:
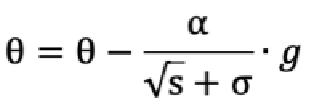
4.5 Adam------同时优化梯度和学习率
Adam优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起。
1.修正梯度: 使⽤梯度的指数加权平均
2.修正学习率: 使⽤梯度平⽅的指数加权平均。
调用API代码实现:
python
import torch
from torch import optim
# 初始化数据
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 实例化优化方法
optimizer = optim.Adam(params=[w], lr=0.001, betas=(0.9, 0.8)) # 使用Adam
# 更新
epochs = 2
for i in range(epochs):
optimizer.zero_grad()
loss = ((w ** 2) * 0.5).sum()
loss.backward()
print(w.grad)
optimizer.step()
print(w)5. 学习率优化策略
5.1 等间隔衰减
API:lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)
功能:等间隔-调整学习率,例如迭代100次,调整一次学习率
参数:
step_size:调整间隔数=50
gamma:调整系数=0.5
调整方式:lr = lr * gamma
代码实现:
python
import torch
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("TkAgg")
# 初始化数据
epochs = 200
iters = 10
x = torch.tensor([1.0], dtype=torch.float32)
y = torch.tensor([0.0], dtype=torch.float32)
w = torch.tensor([0.5], dtype=torch.float32, requires_grad=True)
# 优化器
optimizer = torch.optim.SGD(params=[w], lr=0.1, momentum=0.8)
# 学习率衰减
lr_step = torch.optim.lr_scheduler.StepLR(optimizer=optimizer, step_size=200, gamma=0.5)
# 迭代
lr_list = []
iter_list = []
for epoch in range(epochs):
for iter in range(iters):
lr_list.append(lr_step.get_last_lr())
iter_list.append(iters * epoch + iter)
loss = ((w * x - y) ** 2 * 0.5).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 学习率更新
lr_step.step()
plt.plot(iter_list, lr_list)
plt.show()结果: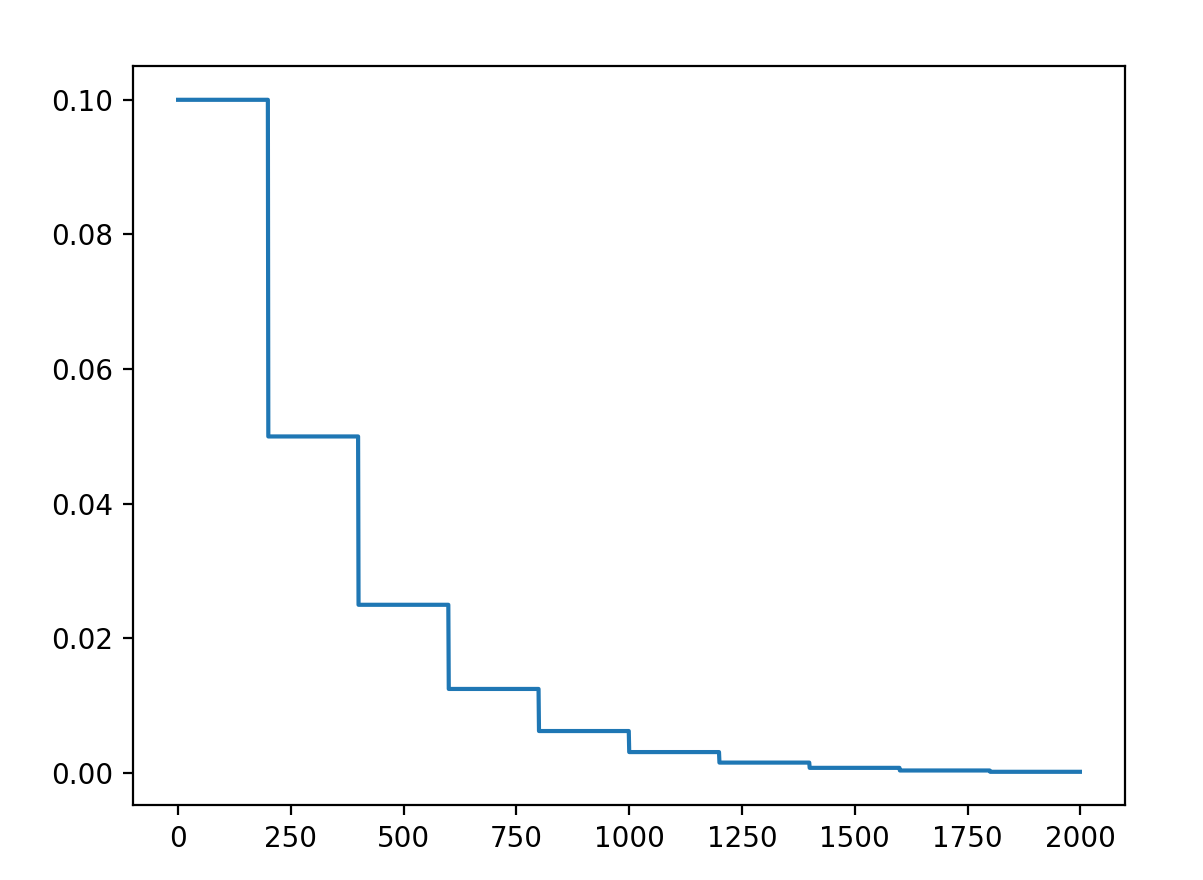
5.2 指定间隔衰减
**API:**lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1)
功能:指定间隔-调整学习率
主要参数:
milestones:设定调整轮次:50, 125, 160
gamma:调整系数
调整方式:lr = lr * gamma
5.3 【了解】按指数学习率衰减
**API:**lr_scheduler.ExponentialLR(optimizer, gamma)
功能:按指数衰减-调整学习率
主要参数:
gamma:指数的底
调整方式 :lr= lr∗ gamma^epoch
四、正则化方法
1、正则化的简介
什么是正则化?
提升模型泛化能力,减少 因神经网络的强大,而产生的过拟合的相关策略 都被成为正则化。
常见策略:集成学习(多个弱学习集成)、决策树的减枝操作、减小模型复杂度。
正则化作用:
提升模型泛化能力,减少过拟合
2、【掌握】随机失活DropOut策略
**思想:**随机将神经元的输出置为0,每一次失活的神经元都不一样
与集成学习对比
实现:
让神经元以超参数p的概率停止工作或者激活被置为0,未被置为0的进行缩放,缩放比例为1/(1-p)。
在测试过程中,随机失活不起作用。
调用API代码实现:
python
import torch
from torch import nn
# 输入数据
x = torch.randint(1, 9, [1, 5], dtype=torch.float32)
# 网络层
layer = nn.Linear(in_features=5, out_features=5)
# 输出
out = layer(x)
print(out)
drop_out = nn.Dropout(p=0.5)
print(drop_out(out))3、BN层的作用
实现步骤:先对数据标准化,再对数据重构(缩放+平移),如下所示:
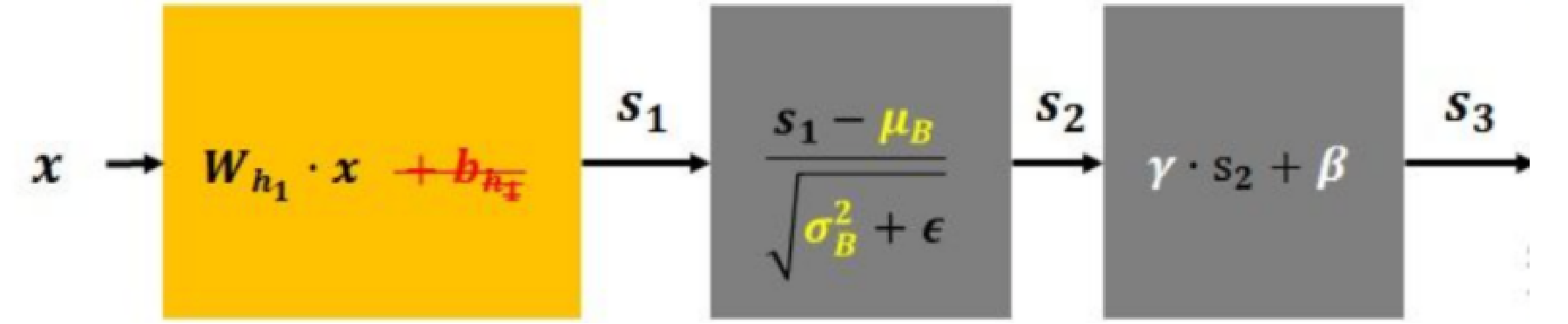
对应公式:
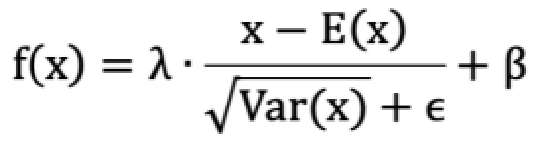
λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为系数,β 为偏移(放大数据差异)
eps 通常指为 1e-5,避免分母为 0;
E(x) 表示变量的均值;
Var(x) 表示变量的方差
使用场景:
BN(Batch normalozation): 计算机视觉、大批次
LN(layer normalozation): 自然语言处理、小批次
五、案例-价格分类案例
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。该数据为二手手机的各个性能的数据,最后根据这些性能得到4个价格区间,作为这些二手手机售出的价格区间。
我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。接下来我们还是按照四个步骤来完成这个任务:
准备训练集数据
构建要使用的模型
模型训练
模型预测评估

python
import time
import pandas as pd
import numpy as np
import torch
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
from torch import nn
from torchsummary import summary
from sklearn.preprocessing import StandardScaler
def create_data():
# 1、数据处理
# 1.1 获取数据
data = pd.read_csv(r"./data/手机价格预测.csv")
x = data.iloc[:, :-1].values
y = data.iloc[:, -1].values
# 1.2 数据标准化
transform = StandardScaler()
x = transform.fit_transform(x)
# 1.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# y_train = np.unique(y_train)
# y_test = np.unique(y_test)
# 1.4 dataset: 将x、y对应起来
dataset_train = TensorDataset(torch.tensor(x_train, dtype=torch.float32), torch.tensor(y_train, dtype=torch.int64))
dataset_test = TensorDataset(torch.tensor(x_test, dtype=torch.float32), torch.tensor(y_test, dtype=torch.int64))
# print(len(dataset_test))
# 1.5 dataloader: 切割批次
dataloader_train = DataLoader(dataset=dataset_train, batch_size=10, shuffle=True)
dataloader_test = DataLoader(dataset=dataset_test, batch_size=10, shuffle=False)
# for x_tensor, y_tensor in dataloader_train:
# print(x_tensor)
# print(y_tensor)
# break
return dataloader_train, dataloader_test
# 2、模型构建
class CreatModel(nn.Module):
def __init__(self, input_num, output_num):
super().__init__()
# 输入层
self.layer1 = nn.Linear(input_num, 128)
# 隐藏层1
self.layer2 = nn.Linear(128, 128)
# 隐藏层2
self.layer3 = nn.Linear(128, 64)
# 隐藏层3
self.layer4 = nn.Linear(64, 64)
# 输出层
self.layer5 = nn.Linear(64, output_num)
# 正则化 dropout
self.dp = nn.Dropout(p=0.2)
def forward(self, x):
x = torch.relu(self.layer1(x))
# 添加激活函数,并进行dropout
x = self.dp(torch.relu(self.layer2(x)))
x = torch.relu(self.dp(self.layer3(x)))
x = torch.relu(self.dp(self.layer4(x)))
out = self.layer5(x)
return out
# 3、模型训练
def train(dataloader, epochs, model):
# 3.1 损失函数-交叉熵
error = nn.CrossEntropyLoss()
# 3.2 优化器
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01, betas=(0.9, 0.8))
loss_sum = 0
iter_num = 0
for epoch in range(epochs):
start_time = time.time()
for x_tensor, y_true in dataloader:
# 3.3 模型预测
y_pred = model(x_tensor)
# 3.4 损失计算
loss = error(y_pred, y_true)
loss_sum += loss.item()
iter_num += 1
# 3.5 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"{epoch},time:{time.time() - start_time},loss:{loss_sum / iter_num}")
# 模型保存,保存权重
torch.save(model.state_dict(), r"./model.pth")
# 4、模型评估
def evaluate(model, dataloader):
# 加载模型训练好的参数
model.load_state_dict(torch.load(r"model.pth", weights_only=True))
correct = 0
for x, y in dataloader:
y_pred = model(x)
# print("y_pred:", y_pred)
# print("y_true:", y)
y_pred = torch.argmax(y_pred, dim=-1)
# print("y:", y_pred)
correct += (y_pred == y).sum()
# print("correct: ",correct)
# print(len(dataloader.dataset))
print(f"准确率:{correct/len(dataloader.dataset)}")
if __name__ == '__main__':
# print(summary(model=model, input_size=(20,), batch_size=16))
dataloader_train, dataloader_test = create_data()
# print(len(dataloader_test))
# # # 模型初始化
model = CreatModel(input_num=20, output_num=4)
train(dataloader=dataloader_train, epochs=30, model=model)
evaluate(model=model, dataloader=dataloader_test)
# 准确率:0.7900000214576721