今天我们来聊聊在Mac Studio M4 Max(32核GPU)上,使用oMLX平台部署gemma-4-26B-A4B-it-QAT-MLX-4bit模型的真实性能表现。
测试环境与模型配置
测试机器是一台Mac Studio,搭载M4 Max芯片(32核GPU),统一内存规格足够支撑大模型运行。模型采用的是4bit量化版本,显存占用约15.3GB,这对于一台内存36G的Mac来说并不算吃力。
模型名称中的"QAT"代表量化感知训练,这种量化方式相比传统的AWQ或GPTQ,能在保持模型质量的同时实现更高效的推理。
| 上下文长度 | 首Token延迟 | 生成速度 | 峰值内存 |
|---|---|---|---|
| 1K tokens | 905 ms | 89.4 tok/s | 14.27 GB |
| 4K tokens | 3.48 s | 85.6 tok/s | 14.89 GB |
| 8K tokens | 7.05 s | 81.0 tok/s | 15.09 GB |
| 16K tokens | 14.93 s | 72.3 tok/s | 15.56 GB |
| 32K tokens | 33.28 s | 61.9 tok/s | 16.49 GB |
| 64K tokens | 80.50 s | 44.1 tok/s | 18.50 GB |
| 128K tokens | 381.30 s | 37.0 tok/s | 21.71 GB |
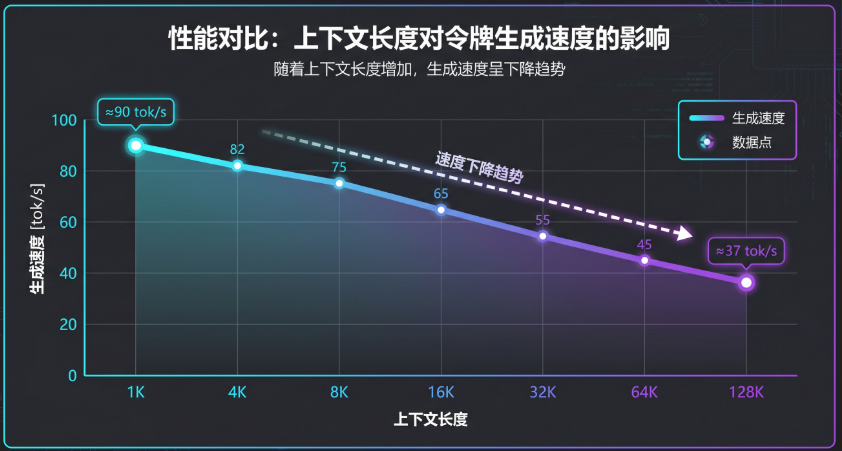 图1:Token生成速度随上下文长度的变化趋势
图1:Token生成速度随上下文长度的变化趋势
短上下文场景:流畅体验
先看短提示词场景。当提示词长度为1024 tokens时:首次Token延迟仅905毫秒,Token生成速度达到89.4 tokens/秒,端到端总延迟2.3秒,峰值内存14.27GB。
这个成绩相当不错。不到一秒钟就能看到模型开始输出,89 tokens/秒的生成速度意味着每秒可以生成将近90个中文字符,日常对话和写作辅助场景下,体验已经很接近云端服务了。
当提示词扩展到4096 tokens时,性能依然稳定:首次Token延迟3.48秒,生成速度85.6 tokens/秒,峰值内存14.89GB。生成速度几乎没有下降,内存也只增加了约600MB。这个阶段的表现说明MLX对中等长度上下文的处理是游刃有余的。
中等上下文:开始承压
8192 tokens的提示词是一个分水岭。测试数据显示:首次Token延迟7秒,生成速度下降到81 tokens/秒,峰值内存15.09GB。
首次Token延迟明显增加,但生成速度还能维持在80以上。这对于需要处理较长文档的场景(比如文章摘要、代码分析)来说,依然是可用的状态。
到了16384 tokens时:首次Token延迟接近15秒,生成速度降至72.3 tokens/秒,峰值内存15.56GB。延迟开始变得明显,但生成速度的下降还算温和。如果你的使用场景是处理较长的技术文档或书籍章节,这个速度勉强可以接受,但需要一些耐心。
长上下文场景:内存瓶颈显现
32768 tokens的提示词是一个重要节点。测试数据显示:首次Token延迟33秒,生成速度骤降至61.9 tokens/秒,峰值内存16.49GB。
从这一步开始,生成速度的下降变得显著。33秒的首token延迟意味着你需要等待半分钟才能开始看到输出,这对交互体验是一个挑战。
当提示词达到65536 tokens时:首次Token延迟超过80秒,生成速度只有44.1 tokens/秒,峰值内存18.50GB。内存占用已经逼近20GB,生成速度几乎腰斩。这个长度已经接近很多实际应用的极限,再往上就会面临更严峻的考验。
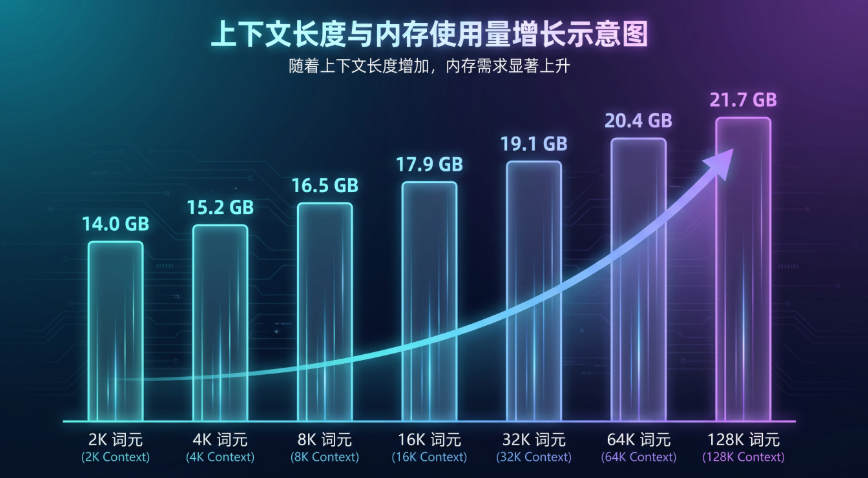 图2:峰值内存随上下文长度的变化
图2:峰值内存随上下文长度的变化
到了131072 tokens(约128K上下文)的测试:首次Token延迟381秒(超过6分钟),生成速度37 tokens/秒,峰值内存21.71GB。
这是测试的极限场景。381秒的首token延迟意味着你可能需要等上六七分钟才能看到第一个字,这对任何实际应用来说都是难以接受的。但考虑到这是一个26B参数模型在消费级硬件上处理128K tokens的上下文,这个成绩并非不可接受。
性能趋势分析
从测试数据中可以画出一条清晰的曲线:随着上下文长度的增加,Token生成速度呈现出近似线性下降的趋势。
- **1K-4K上下文:**85-90 tokens/秒,性能优秀
- **8K-16K上下文:**70-80 tokens/秒,性能良好
- **32K上下文:**约60 tokens/秒,可用但偏慢
- **64K上下文:**约45 tokens/秒,勉强可用
- **128K上下文:**约37 tokens/秒,体验受限
内存占用方面,从14GB起步,随着上下文增加而线性增长,最终在128K时达到21.7GB。这个增长是正常的,因为KV Cache需要存储所有历史token的注意力状态。
实际应用建议
基于测试数据,有几个建议:
适合的场景:
- 短对话和写作辅助(1K-4K tokens):体验与云端接近
- 文档分析和摘要(8K-16K tokens):可以接受,需要等待首token
- 书籍级别的长文本处理(32K+ tokens):需要调整预期,接受较慢的响应
需要注意的:
- 首次Token延迟会随着上下文增长而显著增加
- 超过32K tokens后,生成速度下降明显
- 如果追求流畅体验,建议控制上下文长度在16K以内
总结
M4 Max配合MLX 4bit量化,让26B参数的大模型在Mac上有了可用的体验。短上下文场景下,85-90 tokens/秒的生成速度足以支撑日常使用;长上下文场景虽然会遇到延迟增加的问题,但对于需要在本地运行大模型的用户来说,这已经是目前消费级硬件能提供的最佳方案之一。
如果你正在考虑在Mac上部署本地大模型,gemma-4-26B配合MLX是一个值得考虑的选择。根据你的实际需求选择合适的上下文长度,可以获得最佳的使用体验。