虽然在clickhouse上已经可以进行快速且复杂的数据清洗和挖掘操作,但是将spark架在clickhouse上,也有一些显而易见的好处。比如,Spark支持多语言(Scala、Python、SQL)和丰富生态(MLlib、GraphX),可以方便的扩展ClickHouse在机器学习、图计算等场景的应用。所以这一篇,我们尝试在clickhouse上嫁接spark环境。
同样,开篇首先交代版本: 本篇所有版本都在Spark 3.4上,java版本11.0.0.2,scala版本2.12.17。clickhouse使用了两种版本,分别时23.8和26.3,对应尝试不同的jdbc连接方式。
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.0
/_/一、Clickhouse测试环境
之前详细讨论过clickhosue的各种安装方式,这里仅为测试起见,采用最简单方便的方法------使用Docker安装Clickhosue单机测试环境
1. pull镜像
Pull ClickHouse 23.8和26.3版本的镜像
PS C:\Users\HOME-PIG> docker images
i Info → U In Use
IMAGE ID DISK USAGE CONTENT SIZE EXTRA
centos:7 eeb6ee3f44bd 204MB 0B
clickhouse/clickhouse-server:23.8.2 8fa4e9bd3538 1.01GB 0B U
clickhouse/clickhouse-server:26.3-distroless 7e51a3802634 818MB 0B
clickhouse/clickhouse-server:latest 05cef07cca67 879MB 0B2. 新建专用卷
这一步是在clickhouse上架spark环境中最大的坑。不能直接将Windows的目录映射为clickhouse的数据目录(如果docker装在linux上会不会如此我没试过,不过原理是一样的)。因为clickhouse有自己默认的用户,如果直接映射,则会因为目录所有者权限问题,造成jdbc无法读取文件,且报错信息十分隐晦,很难排查根因。
比如,如果用-v选项直接映射windows文件夹到clickhouse目录:
PS C:\Users\HOME-PIG> docker run -d `
>> --name clickhouse-server-23 `
>> -p 8123:8123 `
>> -p 9000:9000 `
>> -p 9004:9004 `
>> -p 9005:9005 `
>> -v g:/data/23:/var/lib/clickhouse `
>> -v g:/data/23/logs:/var/log/clickhouse-server `
>> -e CLICKHOUSE_PASSWORD="123456" `
>> -e CLICKHOUSE_USER=default `
>> -e CLICKHOUSE_UID=101 `
>> -e CLICKHOUSE_GID=101 `
>> --restart=always `
>> clickhouse/clickhouse-server:23.8.2
7f3cb1a254f2d9ea94cad5bb66b3c63417dfc87aaa3bc810b3bbe353e77748fb写表时会有异常如下,因报错信息比较隐晦,并不容易判断根因:
scala> df.write.mode("append").jdbc(ckUrl, ckTable, ckProp)
26/05/31 12:02:57 WARN ClickHouseDriver: ******************************************************************************************
26/05/31 12:02:57 WARN ClickHouseDriver: * This driver is DEPRECATED. Please use [com.clickhouse.jdbc.ClickHouseDriver] instead. *
26/05/31 12:02:57 WARN ClickHouseDriver: * Also everything in package [ru.yandex.clickhouse] will be removed starting from 0.4.0. *
26/05/31 12:02:57 WARN ClickHouseDriver: ******************************************************************************************
26/05/31 12:02:58 WARN JdbcUtils: Requested isolation level 1, but transactions are unsupported
26/05/31 12:02:58 WARN JdbcUtils: Requested isolation level 1, but transactions are unsupported
26/05/31 12:02:58 ERROR Executor: Exception in task 15.0 in stage 4.0 (TID 47)
ru.yandex.clickhouse.except.ClickHouseUnknownException: ClickHouse exception, code: 1002, host: localhost, port: 8123; std::exception. Code: 1001, type: std::exception, e.what() = std::exception (version 26.3.12.3 (official build))
at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.getException(ClickHouseExceptionSpecifier.java:100)
at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.specify(ClickHouseExceptionSpecifier.java:57)
at ru.yandex.clickhouse.except.ClickHouseExceptionSpecifier.specify(ClickHouseExceptionSpecifier.java:30)
at ru.yandex.clickhouse.ClickHouseStatementImpl.checkForErrorAndThrow(ClickHouseStatementImpl.java:1094)
at ru.yandex.clickhouse.ClickHouseStatementImpl.sendStream(ClickHouseStatementImpl.java:1056)
at ru.yandex.clickhouse.ClickHouseStatementImpl.sendStream(ClickHouseStatementImpl.java:1022)
at ru.yandex.clickhouse.ClickHouseStatementImpl.sendStream(ClickHouseStatementImpl.java:1015)因此,必须使用docker volume create命令新建docker本地卷,再直接映射本地卷到clickhouse。
bash
PS C:\Users\HOME-PIG> docker volume create clickhouse_data
clickhouse_data
PS C:\Users\HOME-PIG> docker volume create clickhouse_logs
clickhouse_logs3. 启动容器
完成本地卷创建后,再启动容器即可
bash
PS C:\Users\HOME-PIG> docker run -d `
>> --name clickhouse-server-23 `
>> -p 8123:8123 `
>> -p 9000:9000 `
>> -p 9004:9004 `
>> -p 9005:9005 `
>> -v clickhouse_data:/var/lib/clickhouse `
>> -v clickhouse_logs:/var/log/clickhouse-server `
>> -e CLICKHOUSE_USER=default `
>> -e CLICKHOUSE_PASSWORD=****** `
>> --restart=always `
>> clickhouse/clickhouse-server:23.8.2
3093d72a1a9d3495030eaa3d0a865afd53549b643155ef65156a900ebadcb575
PS C:\Users\HOME-PIG>4. 进入容器用clickhouse-client测试
clickhouse-server镜像中也是自带clickhouse-client工具的,直接进入容器即可以使用:
PS C:\Users\HOME-PIG> docker exec -it clickhouse-server-23 bash
root@7f3cb1a254f2:/#
root@7f3cb1a254f2:/# clickhouse-client -u default --password '******'
ClickHouse client version 23.8.2.7 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 23.8.2 revision 54465.
7f3cb1a254f2 :) show databases
SHOW DATABASES
Query id: e067c3ff-9bdf-455a-91a1-f1ce2b3267a0
┌─name───────────────┐
│ INFORMATION_SCHEMA │
│ default │
│ information_schema │
│ system │
└────────────────────┘5. 使用WEB界面进行测试
更简单一些的话,也可以直接登录本地WEB页面8123端口进行访问:
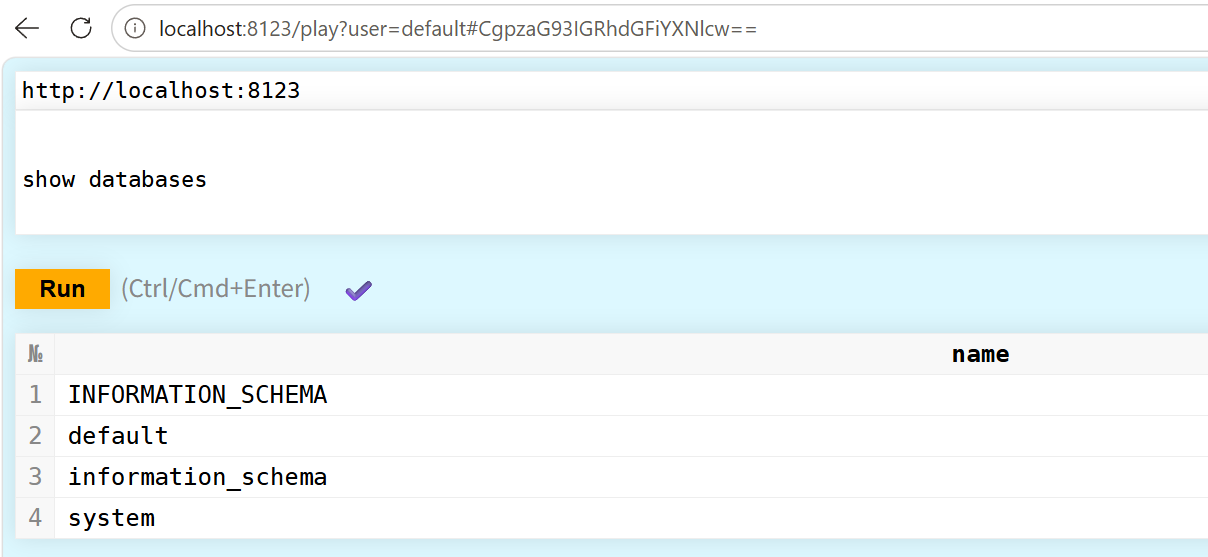
6 建一个测试表
最后一步,我们先在clickhouse中新建一个测试表,以便后续测试使用spark读表、写表的过程。网上各种讨论spark on clickhouse的文章都强烈建议,不要在spark中建表(虽然支持这种操作),似乎容易引起一些不可预测的问题。所以,未免不必要的麻烦,此处也自觉规避。
create table if not exists testTable
(
id UInt8,
name String
)
engine = MergeTree()
order by (id);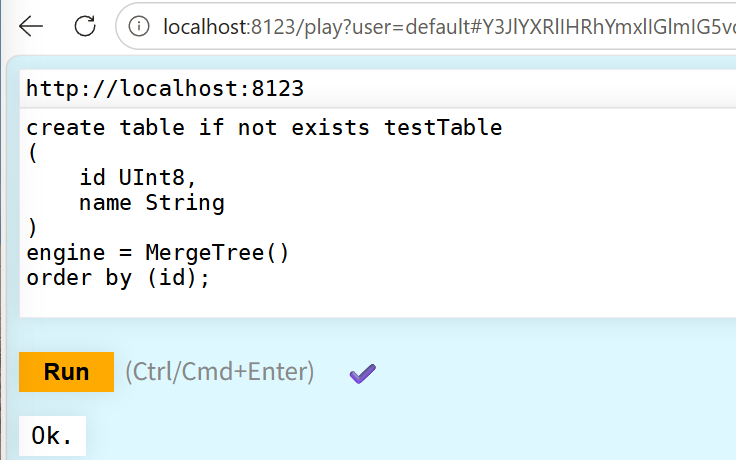
二、使用ru.yandex.clickhouse.ClickHouseDriver驱动配合ClickHouse
ru.yandex.clickhouse.ClickHouseDriver是老版本的JDBC驱动,官方已经表态未来不再支持。且改驱动仅支持有限的与clickhosue交互能力,一些clickjhouse的高级数据类型是不支持读取的。此处尝试该驱动,完全是在直接尝试安装官方推荐接口不畅时,盲目相信豆包的结果------豆包义正言辞地说,spark官方接口太新且不稳定,clickhouse压根没打算让spark用,当前生产环境都用这个老的云云......
后面当然证实了,豆包单纯属于瞎咧咧。现在的人工智能智能不智能不知道,确实很人性......
1. 下载对应的JAR包
ru.yandex.clickhouse.ClickHouseDriver的驱动包在如下地址下载,经测试这个0.3.2-patch11版本可用。其它版本未测试。
URL:Central Repository: com/clickhouse/clickhouse-jdbc/0.3.2-patch11
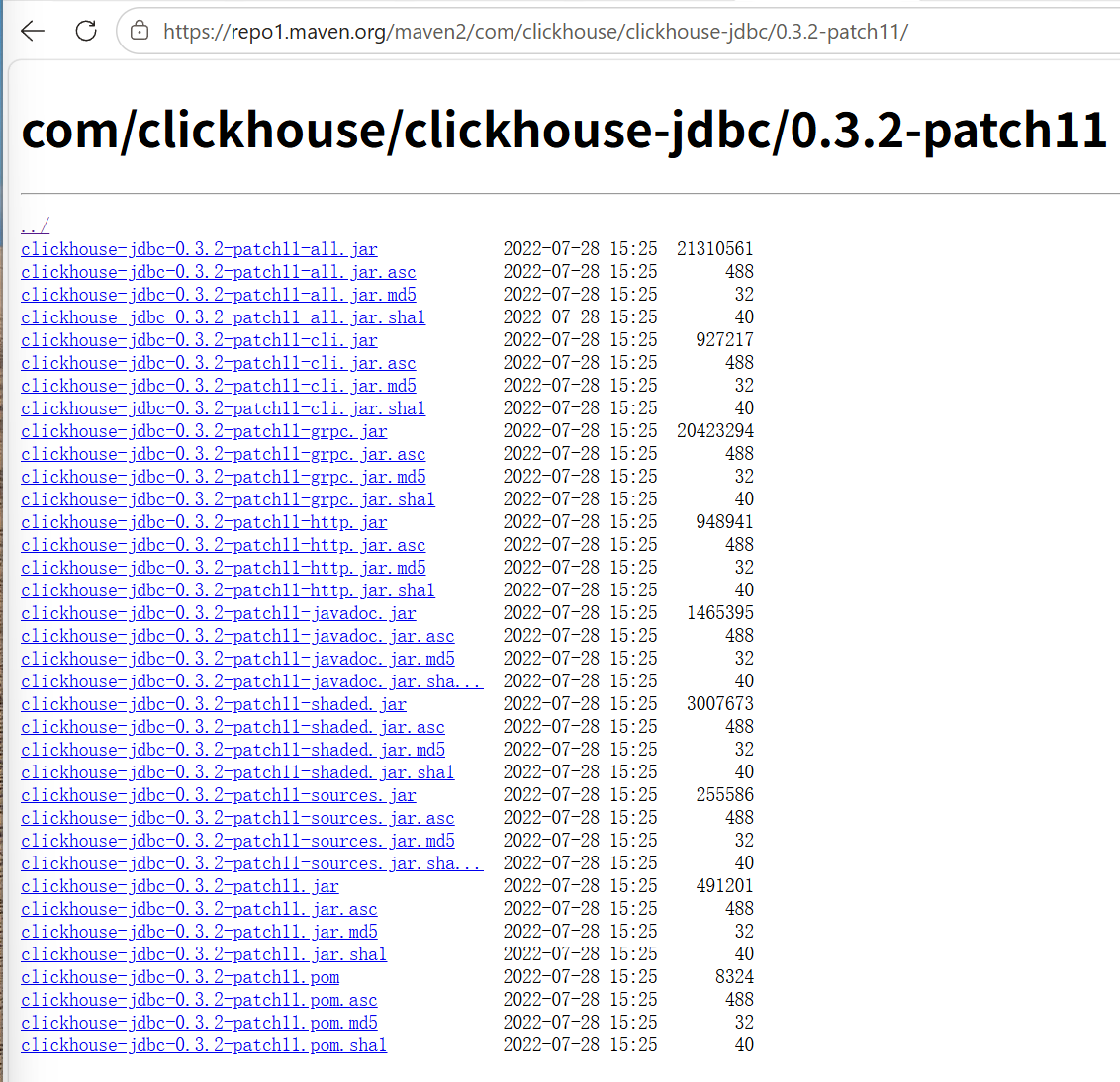
下载 clickhouse-jdbc-0.3.2-patch11-shaded.jar,并将其放在当前用户目录和windows/system32 目录下。之所以同时放在这两个目录下,可能与我启动spark-shell时偶尔的不同启动路径有关。有时spark-shell会报在用户目录下找不到jar包,有时又会说在system32下找不到。所以干脆一劳永逸,都拷贝一份。
2. 使用--jars参数启动SPARK
当然如果在--jars参数中明确指明绝对路径,也可不必到处拷贝jar包。
PS C:\Users\HOME-PIG> spark-shell --jars clickhouse-jdbc-0.3.2-patch11-shaded.jar
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
26/05/30 20:29:39 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://DESKTOP-GHGEHH9:4041
Spark context available as 'sc' (master = local[*], app id = local-1780144179802).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.0
/_/
Using Scala version 2.12.17 (OpenJDK 64-Bit Server VM, Java 11.0.0.2)
Type in expressions to have them evaluated.
Type :help for more information.
scala>3. 配置Clickhouse参数
ru.yandex.clickhouse.ClickHouseDriver驱动的使用约定,是首先定义属性,包括驱动、用户名和口令等,然后在后续read/write时使用。
如下,导入java.util.Properties类,定义属性设置函数
Scala
scala> import java.util.Properties
import java.util.Properties
scala> def getCKJdbcProperties(): Properties = {
| val p = new Properties()
| p.put("driver", "ru.yandex.clickhouse.ClickHouseDriver")
| p.put("user", "default")
| p.put("password", "******")
| p.put("batchsize", "100000")
| p.put("socket_timeout", "300000")
| p.put("num_partitions", "16")
| p.put("rewriteBatchedStatements", "true")
| p
| }设置ClickHouse的URL和表名。这个默认的clickhouse server中,cluster和database的名称都是default。testTable就是前面建的表。
Scala
scala> val ckUrl = "jdbc:clickhouse://localhost:8123/default"
ckUrl: String = jdbc:clickhouse://localhost:8123/default
scala> val ckTable = "default.testTable"
ckTable: String = default.testTable
scala> val ckProp = getCKJdbcProperties()
ckProp: java.util.Properties = {socket_timeout=300000, password=123456, driver=ru.yandex.clickhouse.ClickHouseDriver, rewriteBatchedStatements=true, num_partitions=50, user=default, batchsize=100000}4. 在Spark中初始化一个DataFrame以测试写表
Scala
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> val schema = StructType(Seq(
| StructField("id", ByteType, true),
| StructField("name", StringType, true)
| ))
schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,ByteType,true),StructField(name,StringType,true))
scala> val data = Seq(
| Row(1.toByte, "Alice"),
| Row(2.toByte, "Bob")
| )
data: Seq[org.apache.spark.sql.Row] = List([1,Alice], [2,Bob])
scala>
scala> val df = spark.createDataFrame(
| spark.sparkContext.parallelize(data),
| schema
| )
df: org.apache.spark.sql.DataFrame = [id: tinyint, name: string]
scala> df.show()
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob|
+---+-----+此处是经典的指定schema的dataframe构建语句,不赘述。
5. 将测试表写入Clickhouse
然后,调用write函数即可以将这个dadaframe写入到clickhouse中
Scala
scala> val ckProp = getCKJdbcProperties()
scala> val ckUrl = "jdbc:clickhouse://localhost:8123/default"
scala> val ckTable = "default.testflow"
scala> df.write.mode("append").jdbc(ckUrl, ckTable, ckProp)
26/05/30 21:48:12 WARN JdbcUtils: Requested isolation level 1, but transactions are unsupported
26/05/30 21:48:12 WARN JdbcUtils: Requested isolation level 1, but transactions are unsupported6. 读出clickhouse中表的数据
反过来,使用read函数,即可以读出刚刚写入的内容:
Scala
scala> val ckProp = getCKJdbcProperties()
scala> val ckUrl = "jdbc:clickhouse://localhost:8123/default"
scala> val ckTable = "default.testflow"
scala> spark.read.jdbc(ckUrl, ckTable, ckProp).show
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob|
+---+-----+也可以直接从WEB页面中查询验证:
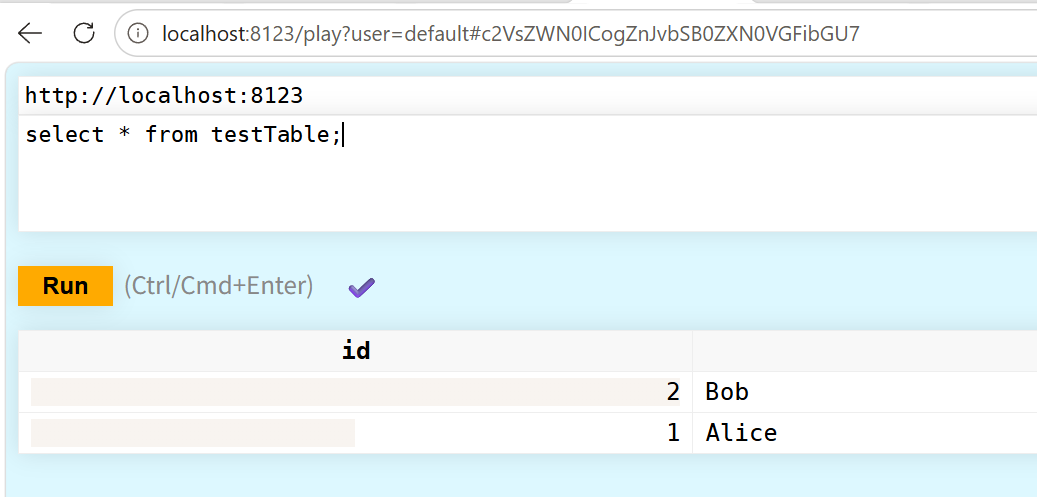
三、使用官方Spark原生连接器
1. API模式选择
官方spark原生连接器有两种访问模式,不过既然我们都放弃使用ru.yandex.clickhouse.clickhouseDriver,当然就是奔着完整功能的支持版本来的,所以必须是Catalog API。

2. 兼容性问题
官方版本的连接器之所以难装,主要还是版本对齐问题。官方网页上给出了半详细的参考如下:
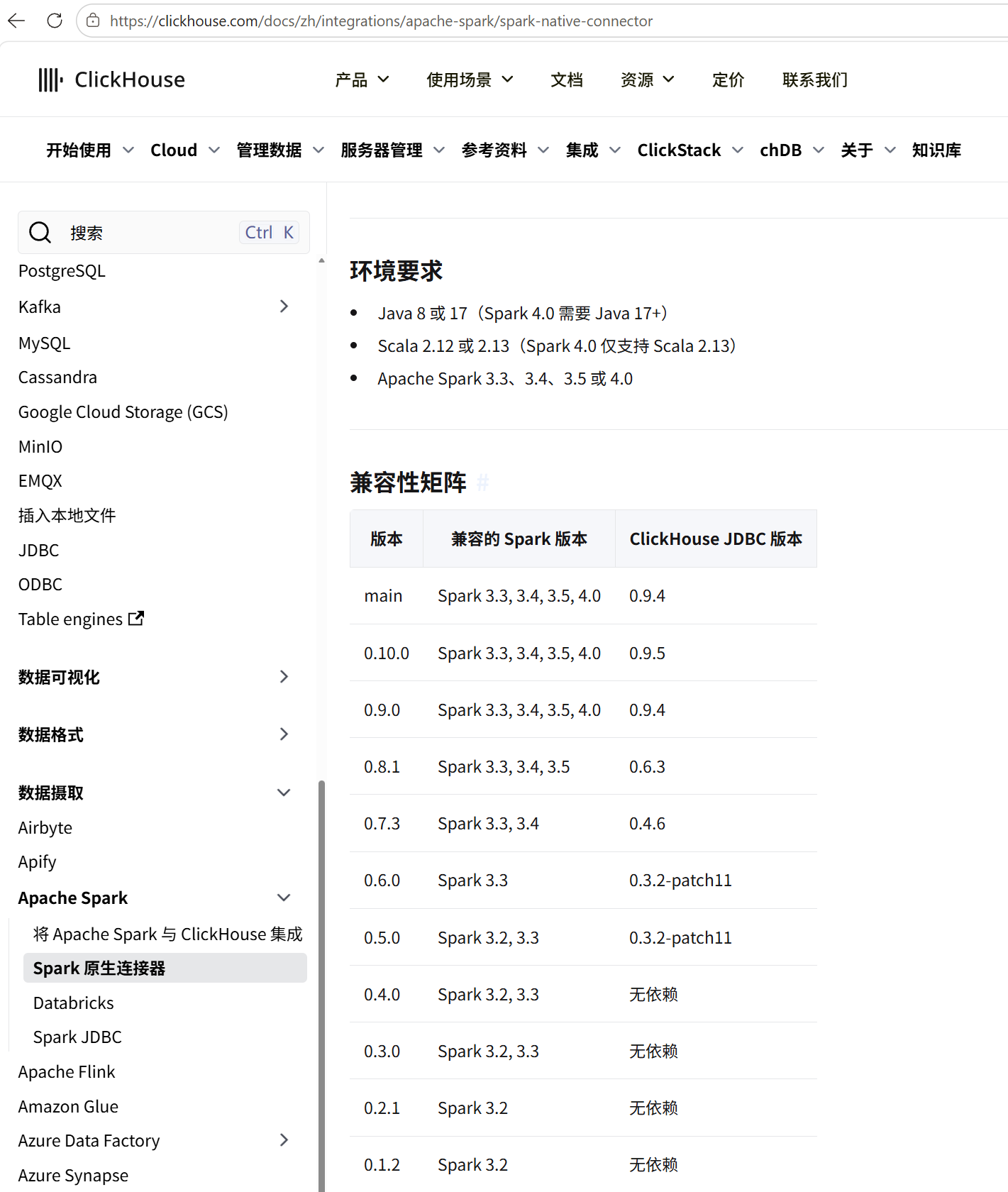
3.下载插件
(1)确定spark和scala的版本
之所以说是半详细,是指页面上给出的版本对应关系基本是对的,但是具体到每个版本应该下载哪些jar包,却是语焉不详了。所以,再次明确一下版本对应关系,我的是spark 3.4.0;scala 2.12.17;java 11.0.0.2;click house 26.3。
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://****
Spark context available as 'sc' (master = local[*], app id = local-****).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.4.0
/_/
Using Scala version 2.12.17 (OpenJDK 64-Bit Server VM, Java 11.0.0.2)
Type in expressions to have them evaluated.
Type :help for more information.所以按照上面的对应表,我们需要对照的是0.10.0和0.9.5这两个版本好。
(2)下载runtime插件
0.10.0这个版本号对应的runtime插件的版本,其小版本号中还需要对应scala的版本,这里是2.12。
下载位置与上面提到的老版本JDBC驱动的网站地址是一样的,目录不一样,如下下载就是:

(3)下载jdbc插件
0.9.5则对应的是jdbc驱动的版本号,这个比较搞笑的是有clickhouse-jdbc-0.9.5-all和clickhouse-jdbc-all-0.9.5两种jar包在这个repo站上。且前者还有诸如shaded之类的其它封装版本,主要区别在于不同的依赖封装方式------有些可能缺一些依赖,以避免和其它平台的依赖冲突)。这里直接下后者,避免因缺乏依赖造成读写失败。
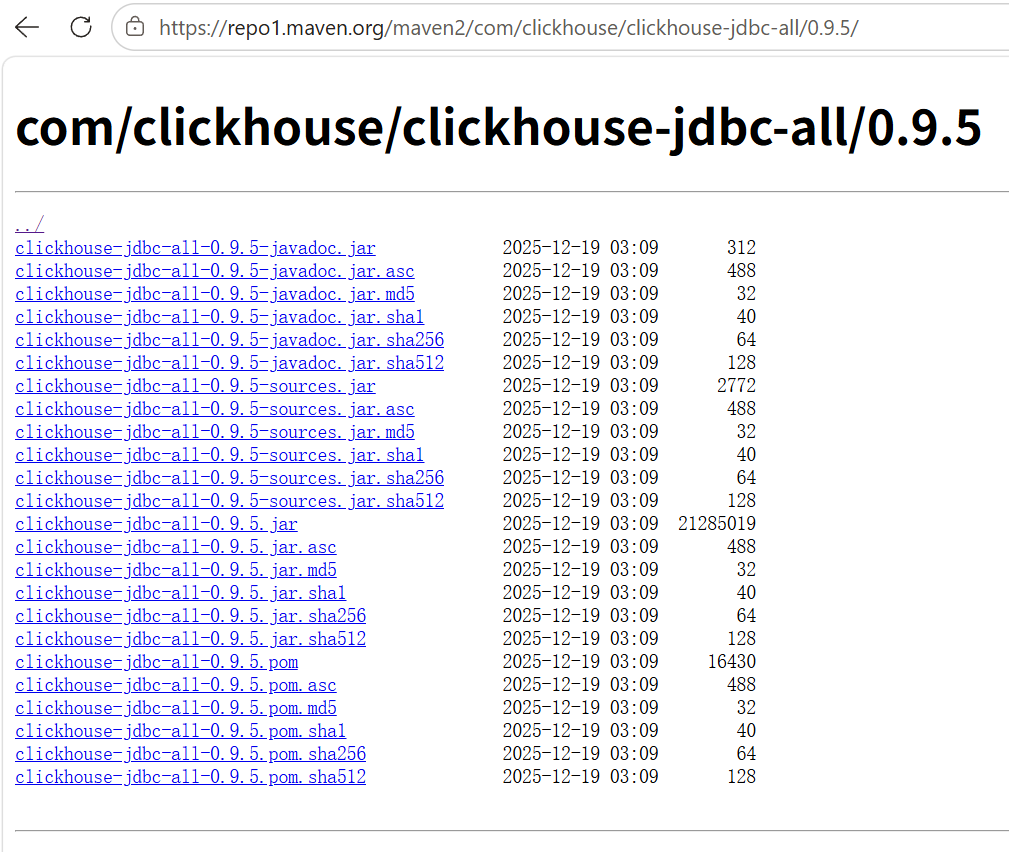
4. 测试
使用--jars参数指定运行时与jdbc插件,启动spark-shell
bash
spark-shell --jars clickhouse-spark-runtime-3.4_2.12-0.10.0.jar,clickhouse-jdbc-all-0.9.5.jar使用CataLog API需要先注册数据库信息,后续就可以直接调用read/write函数,实际比老接口感觉还要方便些。
(1)注册CataLog
注册CataLog API,填写数据库表信息与用户名口令信息等,注意驱动必须是"com.clickhouse.spark.ClickHouseCatalog"。
Scala
spark.conf.set("spark.sql.catalog.clickhouse", "com.clickhouse.spark.ClickHouseCatalog")
spark.conf.set("spark.sql.catalog.clickhouse.host", "localhost")
spark.conf.set("spark.sql.catalog.clickhouse.protocol", "http")
spark.conf.set("spark.sql.catalog.clickhouse.http_port", "8123")
spark.conf.set("spark.sql.catalog.clickhouse.user", "default")
spark.conf.set("spark.sql.catalog.clickhouse.password", "******")
spark.conf.set("spark.sql.catalog.clickhouse.database", "default")如有需要,还可以加些设置传输接口与传输编码压缩方式:
Scala
//关闭读写压缩,若LZ4 校验失败
spark.conf.set("spark.clickhouse.compression", "none")
//关闭JSON,规避 JSON 解析异常
spark.conf.set("spark.clickhouse.output.format", "JSONCompactEachRow")
//走TCP通道
spark.conf.set("spark.sql.catalog.clickhouse.protocol", "tcp")
spark.conf.set("spark.sql.catalog.clickhouse.tcp_port", "9000")(2)读表
Scala
scala> spark.sql("select * from clickhouse.default.testTable").show()
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob|
+---+-----+或使用 TableProvider API(基于格式的访问)读表
Scala
scala> spark.read.
| format("clickhouse").
| option("host", "localhost").
| option("protocol", "http").
| option("http_port", "8123").
| option("database", "default").
| option("table", "testTable").
| option("user", "default").
| option("password", "******").
| load().show()
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob|
+---+-----+(3) 写表
写表时需要注意的是不要开过多的并行写表线程,过多的线程会造成OOM错误。当然,如果数据过大,过少的写表线程也会严重限制读写速度。并行度由dataframe的coalesce函数控制,通常对应可使用的核心数。
Scala
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> val schema = StructType(Seq(
| StructField("id", ByteType, true),
| StructField("name", StringType, true)
| ))
schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,ByteType,true),StructField(name,StringType,true))
scala> val data = Seq(
| Row(3.toByte, "Alice1"),
| Row(4.toByte, "Bob1")
| )
data: Seq[org.apache.spark.sql.Row] = List([3,Alice1], [4,Bob1])
scala> val df = spark.createDataFrame(
| spark.sparkContext.parallelize(data),
| schema
| )
df: org.apache.spark.sql.DataFrame = [id: tinyint, name: string]
scala> df.show()
+---+------+
| id| name|
+---+------+
| 3|Alice1|
| 4| Bob1|
+---+------+
scala> df.coalesce(2).write. // 关键1:整合到一起,强制用N个线程
| format("clickhouse").
| option("host", "localhost").
| option("protocol", "http").
| option("http_port", "8123").
| option("database", "default").
| option("table", "testTable").
| option("user", "default").
| option("password", "******").
| option("write.batch.size", "16"). // 可选1:降低批次大小
| option("write.max-connections", "1"). // 可选2:单连接写入
| option("write.format", "json"). // 可选3:从Arrow模式换到JSON格式
| mode("append").save()
scala> spark.read.
| format("clickhouse").
| option("host", "localhost").
| option("protocol", "http").
| option("http_port", "8123").
| option("database", "default").
| option("table", "testTable").
| option("user", "default").
| option("password", "******").
| load().show()
+---+------+
| id| name|
+---+------+
| 1| Alice|
| 2| Bob|
| 3|Alice1|
| 4| Bob1|
+---+------+