摘要
电脑用久之后,经常会出现大量重复文件:下载过多次的安装包、重复导出的照片、备份目录里的 Office 文档、压缩包副本等。手动查找既费时间,也容易误删。
本文记录一个完整的 Python 桌面工具项目:使用 wxPython 编写界面,使用 MD5 判断文件内容是否重复,使用 SQLite 保存扫描记录,使用 JSON 保存用户配置,并在删除时将文件放入 Windows 回收站,而不是直接永久删除。
项目目标不是做一个复杂的商业软件,而是做一个可运行、可维护、操作安全的本地小工具。
C:\Users\86182\Desktop\文件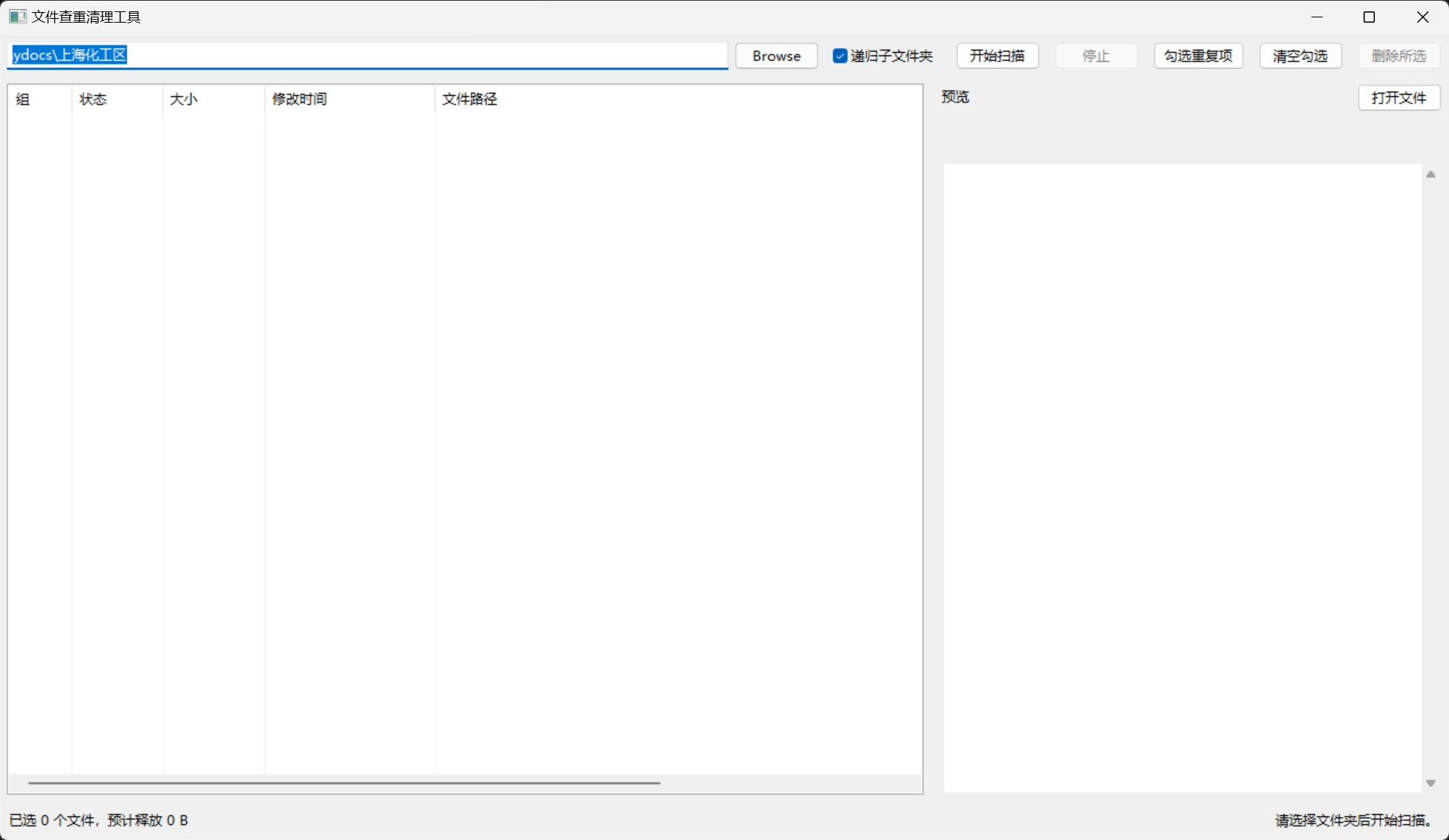
查重
功能效果
这个工具支持以下功能:
- 选择一个文件夹进行查重。
- 支持递归扫描子文件夹。
- 使用 MD5 判断文件内容是否完全相同。
- 重复文件按文件大小从大到小显示。
- 每组重复文件默认保留修改时间最新的文件。
- 支持批量勾选需要删除的重复文件。
- 实时显示已选文件数量和预计释放空间。
- 删除前弹窗确认。
- 删除时放入回收站,不直接永久删除。
- 支持图片预览、ZIP 文件列表预览。
- PDF、Word、Excel、视频等文件显示基本信息,并可调用系统默认程序打开。
- 使用 SQLite 保存扫描结果。
- 使用配置文件保存上次选择的目录和窗口设置。
项目结构
项目拆成多个小模块,每个文件只负责一类事情:
text
文件查重/
├── app.py # wxPython 主界面
├── config.py # JSON 配置读写
├── database.py # SQLite 数据库操作
├── duplicate_finder.py # MD5 扫描和重复文件分组
├── models.py # 数据模型
├── preview.py # 文件预览信息
├── recycle.py # 回收站删除
├── start.bat # Windows 启动脚本
├── README.md # 项目说明
└── tests/ # 单元测试这样拆分的好处是:MD5 扫描、数据库、配置、删除逻辑都可以独立测试,不会全部堆在 GUI 代码里。
一、数据模型设计
文件信息使用 FileRecord 表示,重复文件组使用 DuplicateGroup 表示:
python
@dataclass(frozen=True)
class FileRecord:
path: str
md5: str
size: int
modified_at: float
@dataclass(frozen=True)
class DuplicateGroup:
md5: str
size: int
files: tuple[FileRecord, ...]
@property
def keep_file(self) -> FileRecord:
return self.files[0]
@property
def delete_candidates(self) -> tuple[FileRecord, ...]:
return self.files[1:]这里约定:每组重复文件内部,files[0] 是要保留的文件。程序默认按修改时间倒序排序,所以最新文件排在第一位,其余文件作为可删除候选。
二、为什么用 MD5 查重
判断重复文件,不能只看文件名。因为相同内容的文件可能名字不同,例如:
text
report.docx
report - 副本.docx
final-report.docx也不能只看大小。两个文件大小相同,不代表内容相同。
本项目采用两步判断:
- 先按文件大小分组,只有大小相同的文件才可能重复。
- 再对同大小文件计算 MD5,MD5 相同则认为内容重复。
核心逻辑在 duplicate_finder.py 中:
python
by_size: dict[int, list[Path]] = defaultdict(list)
for path in paths:
by_size[path.stat().st_size].append(path)
by_hash: dict[str, list[FileRecord]] = defaultdict(list)
for size, same_size_paths in by_size.items():
if len(same_size_paths) < 2:
continue
for path in same_size_paths:
record = self._record_for(path, size)
if record is not None:
by_hash[record.md5].append(record)这个设计能减少不必要的 MD5 计算。因为只有同大小文件才需要进一步计算哈希,对于大量不重复文件来说会更快。
MD5 计算采用分块读取,避免大文件一次性读入内存:
python
def md5_for_file(self, path: Path) -> str:
hasher = hashlib.md5()
with path.open("rb") as handle:
for chunk in iter(lambda: handle.read(self.chunk_size), b""):
hasher.update(chunk)
return hasher.hexdigest()三、重复组排序策略
用户最关心的通常是"能释放多少空间",所以扫描结果按文件大小从大到小排序:
python
return sorted(groups, key=lambda group: group.size, reverse=True)每组内部则按修改时间从新到旧排序:
python
files=tuple(sorted(records, key=lambda item: item.modified_at, reverse=True))因此界面中每组第一条是默认保留文件,其余文件可以批量勾选删除。
四、配置文件:保存用户习惯
配置使用 JSON 保存,例如上次选择的文件夹、是否递归扫描、窗口大小等。
python
@dataclass(frozen=True)
class AppConfig:
last_folder: str = ""
recursive: bool = True
keep_strategy: str = "newest"
window_width: int = 1180
window_height: int = 760加载配置时,如果文件不存在或 JSON 损坏,就返回默认配置:
python
@classmethod
def load(cls, path: Path) -> "AppConfig":
if not path.exists():
return cls()
try:
data = json.loads(path.read_text(encoding="utf-8"))
except (OSError, json.JSONDecodeError):
return cls()
valid = {field: data[field] for field in cls.__dataclass_fields__ if field in data}
return cls(**valid)这个处理比较稳健,不会因为配置文件异常导致程序无法启动。
五、SQLite:保存扫描记录
项目使用 SQLite 保存扫描会话和重复文件记录。数据库包含两张表:
scan_sessions:记录扫描目录和扫描时间。duplicate_files:记录每个重复文件的路径、大小、MD5、修改时间、是否保留、是否删除。
建表逻辑如下:
python
CREATE TABLE IF NOT EXISTS scan_sessions (
id INTEGER PRIMARY KEY AUTOINCREMENT,
folder TEXT NOT NULL,
scanned_at REAL NOT NULL
)
python
CREATE TABLE IF NOT EXISTS duplicate_files (
id INTEGER PRIMARY KEY AUTOINCREMENT,
session_id INTEGER NOT NULL,
group_index INTEGER NOT NULL,
md5 TEXT NOT NULL,
path TEXT NOT NULL,
size INTEGER NOT NULL,
modified_at REAL NOT NULL,
keep_file INTEGER NOT NULL,
deleted INTEGER NOT NULL DEFAULT 0,
FOREIGN KEY(session_id) REFERENCES scan_sessions(id)
)保存扫描结果时,会先插入一次扫描会话,再插入每个文件记录:
python
session_id = int(cursor.lastrowid)
for group_index, group in enumerate(groups, start=1):
keep_path = group.keep_file.path
for record in group.files:
conn.execute(
"""
INSERT INTO duplicate_files(
session_id, group_index, md5, path, size, modified_at, keep_file
)
VALUES (?, ?, ?, ?, ?, ?, ?)
""",
(
session_id,
group_index,
group.md5,
record.path,
record.size,
record.modified_at,
1 if record.path == keep_path else 0,
),
)这里有一个细节:数据库连接使用 contextlib.closing 明确关闭。Windows 下如果 SQLite 连接没有及时关闭,可能导致数据库文件被占用,测试或删除临时目录时会失败。
六、wxPython 界面设计
主界面由四部分组成:
- 顶部工具栏:选择文件夹、递归选项、开始扫描、停止、批量勾选、清空勾选、删除所选。
- 左侧列表:显示重复文件。
- 右侧预览:显示图片、ZIP 内容或文件基本信息。
- 底部状态栏:显示已选数量、预计释放空间和扫描进度。
列表使用 wx.ListCtrl:
python
self.result_list = wx.ListCtrl(list_panel, style=wx.LC_REPORT | wx.LC_SINGLE_SEL)
if hasattr(self.result_list, "EnableCheckBoxes"):
self.result_list.EnableCheckBoxes(True)列设计如下:
python
columns = [
("组", 56),
("状态", 80),
("大小", 90),
("修改时间", 150),
("文件路径", 520),
("MD5", 220),
]这种布局适合工具类软件:信息密度较高,用户可以快速比较路径、大小和修改时间。
七、扫描线程:避免界面卡死
文件扫描和 MD5 计算可能比较耗时,如果直接在主线程执行,GUI 会卡住。因此程序使用后台线程扫描:
python
self.scan_thread = threading.Thread(
target=self._scan_worker,
args=(folder, self.recursive_checkbox.GetValue()),
daemon=True,
)
self.scan_thread.start()后台线程不能直接操作 wxPython 控件,需要使用 wx.CallAfter 回到主线程更新界面:
python
progress=lambda path: wx.CallAfter(self.progress_label.SetLabel, f"正在计算: {path}")扫描完成后同样通过 wx.CallAfter 填充列表:
python
wx.CallAfter(self._scan_finished, session_id, rows)八、批量勾选和总大小统计
用户可以点击"勾选重复项",程序会自动勾选每组中除保留文件以外的候选文件:
python
def on_select_duplicates(self, _event) -> None:
for index, row in enumerate(self.rows):
if hasattr(self.result_list, "CheckItem"):
self.result_list.CheckItem(index, not row["keep"] and not row["deleted"])
self._update_selected_summary()统计已选文件路径:
python
def _selected_paths(self) -> list[str]:
paths = []
if not hasattr(self.result_list, "IsItemChecked"):
return paths
for index, row in enumerate(self.rows):
if self.result_list.IsItemChecked(index) and not row["keep"] and not row["deleted"]:
paths.append(row["path"])
return paths统计预计释放空间:
python
def _selected_size(self) -> int:
selected = set(self._selected_paths())
return sum(row["size"] for row in self.rows if row["path"] in selected)底部实时显示:
python
self.summary_label.SetLabel(f"已选 {len(paths)} 个文件,预计释放 {format_size(total)}")九、文件预览设计
预览模块并不强行解析所有格式,而是分层处理:
- 图片:内置缩略图预览。
- ZIP:读取压缩包文件列表。
- PDF、Word、Excel、视频:显示文件基本信息,并提供"打开文件"按钮。
- 其他文件:显示路径、大小、MIME 类型等基础信息。
判断逻辑如下:
python
def build_preview(path: Path) -> Preview:
suffix = path.suffix.lower()
if suffix in IMAGE_EXTENSIONS:
return Preview("image", _metadata_text(path), str(path))
if suffix == ".zip":
return Preview("zip", _zip_text(path))
if suffix in DOCUMENT_EXTENSIONS:
return Preview("document", _metadata_text(path) + "\n\n可使用"打开文件"调用系统默认程序查看。")
if suffix in VIDEO_EXTENSIONS:
return Preview("video", _metadata_text(path) + "\n\n可使用"打开文件"调用系统默认播放器查看。")
return Preview("generic", _metadata_text(path))这种设计比较实用。Office、PDF、视频如果都做内嵌预览,会引入很多依赖和兼容问题;调用系统默认程序反而更稳定。
十、删除安全:放入回收站
删除重复文件是高风险操作,所以程序做了三层保护:
- 默认保留每组最新文件。
- 删除前弹窗确认。
- 删除时放入回收站,而不是直接永久删除。
确认框会显示删除数量和预计释放空间:
python
message = f"确认将 {len(paths)} 个文件放入回收站?\n预计释放空间:{format_size(total)}"
if wx.MessageBox(message, "确认删除", wx.YES_NO | wx.NO_DEFAULT | wx.ICON_WARNING) != wx.YES:
return回收站删除优先使用 send2trash:
python
try:
from send2trash import send2trash
except ImportError:
_windows_recycle(path)
else:
send2trash(path)如果没有安装 send2trash,则使用 Windows Shell API 作为备用方案:
python
operation.wFunc = 3
operation.pFrom = path + "\0\0"
operation.fFlags = 0x0040 | 0x0010 | 0x0400
result = shell32.SHFileOperationW(ctypes.byref(operation))删除完成后,数据库会标记文件状态:
python
def mark_deleted(self, paths: list[str]) -> None:
if not paths:
return
with closing(self._connect()) as conn:
conn.executemany(
"UPDATE duplicate_files SET deleted = 1 WHERE path = ?",
[(path,) for path in paths],
)
conn.commit()十一、启动脚本
为了方便双击启动,项目提供了 start.bat:
bat
@echo off
cd /d "%~dp0"
python app.py
if errorlevel 1 (
echo.
echo Failed to start the application.
echo Please check that Python and wxPython are installed.
pause
)cd /d "%~dp0" 可以切换到 bat 文件所在目录,避免双击运行时工作目录不正确。
十二、测试验证
项目使用 Python 自带的 unittest 做核心逻辑测试,覆盖内容包括:
- 配置文件默认值和读写。
- MD5 重复文件分组。
- 重复组按大小降序排序。
- 每组默认保留最新文件。
- SQLite 保存和读取扫描结果。
- ZIP 和普通文件预览。
- 回收站删除抽象。
运行测试:
powershell
python -m unittest discover -s tests -v语法检查:
powershell
python -m py_compile app.py config.py database.py duplicate_finder.py models.py preview.py recycle.py检查 wxPython:
powershell
python -c "import wx; print('wxPython ok', wx.version())"十三、运行方式
安装依赖:
powershell
pip install wxPython send2trash启动程序:
powershell
python app.py或者双击:
text
start.bat总结
这个项目虽然不大,但包含了一个桌面工具常见的完整闭环:
- GUI 交互
- 后台耗时任务
- 文件哈希计算
- SQLite 持久化
- 配置保存
- 文件预览
- 安全删除
- 单元测试
其中最重要的设计点有三个:
- 先按大小分组,再计算 MD5,减少不必要的哈希计算。
- 扫描线程和 GUI 线程分离,避免界面卡死。
- 删除进入回收站并二次确认,降低误删风险。
如果后续继续扩展,可以考虑加入扫描历史管理、导出 Excel 报告、按文件类型筛选、忽略目录规则、多语言界面,以及更强的预览能力。