引言
HTTP 框架的核心职责只有一件事:为每个请求找到正确的处理函数。
主流 Go 框架------Gin、Echo、Fasthttp、Hertz------全部用 Radix Tree 解决这个问题。它把公共前缀压缩成单个节点,匹配时一步跨过一个路径段;参数节点和通配节点内嵌在树中,查找按 static > param > any 的优先级回溯,兼顾性能和灵活性。
Hertz 的路由树源自 Fasthttp,在字节跳动内部做了优化(比如 param/any 节点独立存储,O(1) 定位)。本文将聚焦树的构建过程 ------从 addRoute 的路径拆解到 insert 的节点分裂------逐步剖析这棵树是如何在路由注册时长出来的。
一、从路由注册入手
go
func main() {
h := server.Default(server.WithHostPorts("127.0.0.1:8080"))
h.GET("/account", handle("/account"))
h.Spin()
}这是写业务代码时的顶层调用入口,三步:建 → 注册 → 启动 。h.GET 触发 Radix Tree 构建,h.Spin() 开始接收请求。
点开GET函数
go
func (group *RouterGroup) GET(relativePath string, handlers ...app.HandlerFunc) IRoutes {
return group.handle(consts.MethodGet, relativePath, handlers)
}可以看到实际上干活的是group.handle,这里的h是一个*Hertz类型内嵌了*Engine,而*Engine又内嵌了RouterGroup类型,因此可以调用GET方法。
点开handle函数
go
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers app.HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath) // 拼完整路径
handlers = group.combineHandlers(handlers) // 合并中间件
group.engine.addRoute(httpMethod, absolutePath, handlers) // 插入路由树
return group.returnObj() // 返回自身,支持链式调用
}可以看到其中最核心的就是group.engine.addRoute这个函数,这里传入的有三个参数,httpmethod决定查哪棵树(Hertz对不同的method生成不同的路由树,所有根节点放在Engine的tree字段中 ),absolutePath决定在树里的位置,handlers 是最终要执行的东西。
点开engine.addRoute
go
func (engine *Engine) addRoute(method, path string, handlers app.HandlersChain) {
if len(path) == 0 {
panic("path should not be ''")
}
utils.Assert(path[0] == '/', "path must begin with '/'")
utils.Assert(method != "", "HTTP method can not be empty")
utils.Assert(len(handlers) > 0, "there must be at least one handler")
if !engine.options.DisablePrintRoute {
debugPrintRoute(method, path, handlers)
}
methodRouter := engine.trees.get(method)
if methodRouter == nil {
// 假如当前方法没有路由树,就创建一个路由树,并且初始化一个空节点
methodRouter = &router{method: method, root: &node{}}
engine.trees = append(engine.trees, methodRouter)
}
methodRouter.addRoute(path, handlers)
// Update maxParams
if paramsCount := countParams(path); paramsCount > engine.maxParams {
engine.maxParams = paramsCount
}
}可以看到基本都是一些胶水代码,核心的就是一个methodRouter.addRoute,path是我们的原始路径
二、深入methodRouter.addRoute函数
go
func (r *router) addRoute(path string, h app.HandlersChain) {
checkPathValid(path)
var (
pnames []string // Param names
ppath = path // Pristine path
)
if h == nil {
panic(fmt.Sprintf("Adding route without handler function: %v", path))
}
// Add the front static route part of a non-static route
for i, lcpIndex := 0, len(path); i < lcpIndex; i++ {
// param route
if path[i] == paramLabel {
j := i + 1
r.insert(path[:i], nil, skind, nilString, nil)
for ; i < lcpIndex && path[i] != '/'; i++ {
}
pnames = append(pnames, path[j:i])
path = path[:j] + path[i:]
i, lcpIndex = j, len(path)
if i == lcpIndex {
// path node is last fragment of route path. ie. `/users/:id`
r.insert(path[:i], h, pkind, ppath, pnames)
return
} else {
r.insert(path[:i], nil, pkind, nilString, pnames)
}
} else if path[i] == anyLabel {
r.insert(path[:i], nil, skind, nilString, nil)
pnames = append(pnames, path[i+1:])
r.insert(path[:i+1], h, akind, ppath, pnames)
return
}
}
r.insert(path, h, skind, ppath, pnames)
}这一段逻辑比较复杂,主要做的事情就是对我们的path进行处理,然后分段insert,例如要插入/shop/:category/items
- 第一次 insert:插 "/shop/" → static 节点
- 第二次 insert:插 ":category" → param 节点
- 第三次 insert:插 "/items" → static 节点,带 handler
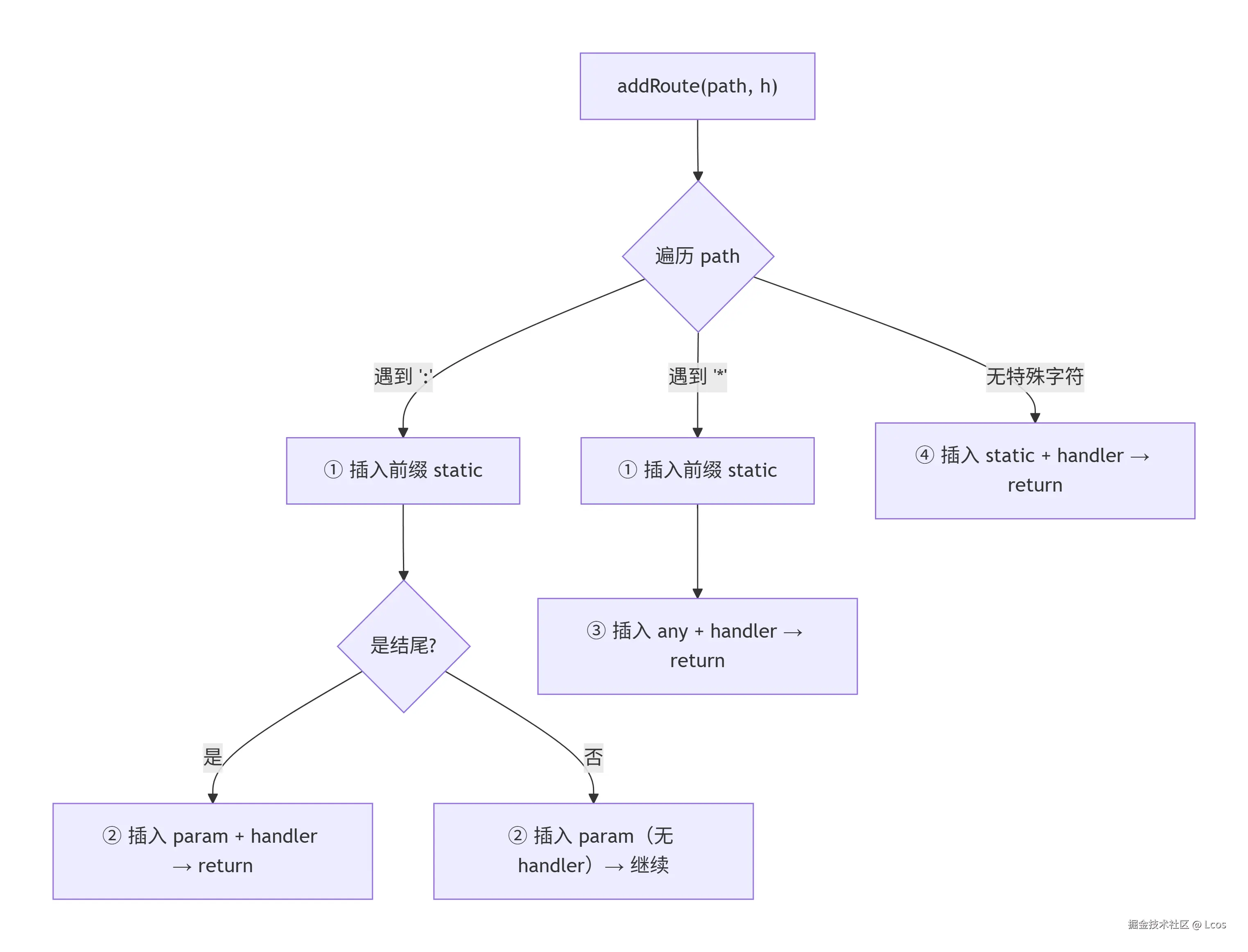
这里有pnames在构建路由树的时候并没有实际作用,但是会在后续insert的过程中以[]string的形式存储到叶子节点中,其目的是为了给后续匹配路由成功之后对参数节点和通配符节点建立一个映射,用于给handlers处理链根据key获得具体的value
大家看到这里可能有一个问题,为什么要在这个addRoute函数这里对要插入的路径处理之后进行分段插入,对比别的web框架可以发现,只有Hertz框架在insert之前处理了并且有多段插入,别的框架都是一次性insert。
其实这个问题的答案正是Hertz的路由数区别别的路由树的一个重要特性------Hertz在构建路由树的时候把节点分为三个状态分别是
- 普通的静态路由节点
skind - 参数节点
pkind - 通配符节点
akind
由于不同类型节点的处理逻辑完全不同,因此需要分段insert,核心目的就是为了让参数节点和通配符节点成为独立的节点。后续我会继续出一期三分钟吃透 Radix Tree:Hertz 路由匹配全拆解里面对find函数的拆解会观察到三种状态的作用和流转
三、直面insert函数
insert函数是构建路由树的核心函数,我会结合例子和路由树可视化来讲解,
先看完整源码
go
func (r *router) insert(path string, h app.HandlersChain, t kind, ppath string, pnames []string) {
currentNode := r.root
// 判定节点不为nil,此处为防御性编程
if currentNode == nil {
panic("hertz: invalid node")
}
search := path
for {
searchLen := len(search)
prefixLen := len(currentNode.prefix)
lcpLen := 0
max := prefixLen
if searchLen < max {
max = searchLen
}
// 查找公共前缀
for ; lcpLen < max && search[lcpLen] == currentNode.prefix[lcpLen]; lcpLen++ {
}
// 如果公共前缀为空,说明当前节点的前缀与搜索路径的前缀不匹配,需要创建一个新的节点
if lcpLen == 0 {
// At root node
currentNode.label = search[0]
currentNode.prefix = search
if h != nil {
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}
// 如果当前节点没有子节点,说明当前节点是一个叶子节点
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
// 如果公共前缀大于0且小于当前节点的前缀,说明节点需要分裂
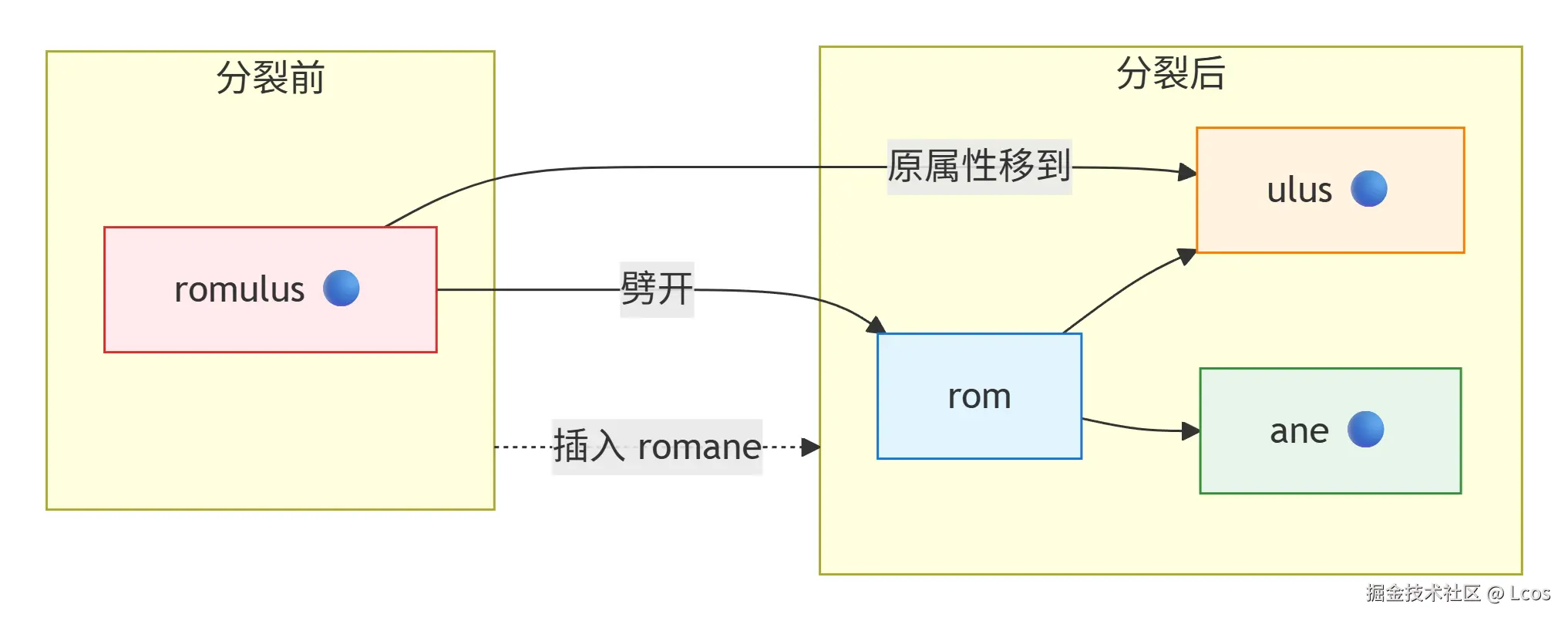
} else if lcpLen < prefixLen {
// Split node
n := newNode(
currentNode.kind,
currentNode.prefix[lcpLen:],
currentNode,
currentNode.children,
currentNode.handlers,
currentNode.ppath,
currentNode.pnames,
currentNode.paramChild,
currentNode.anyChild,
)
// Update parent path for all children to new node
for _, child := range currentNode.children {
child.parent = n
}
if currentNode.paramChild != nil {
currentNode.paramChild.parent = n
}
if currentNode.anyChild != nil {
currentNode.anyChild.parent = n
}
// Reset parent node
currentNode.kind = skind
currentNode.label = currentNode.prefix[0]
currentNode.prefix = currentNode.prefix[:lcpLen]
currentNode.children = nil
currentNode.handlers = nil
currentNode.ppath = nilString
currentNode.pnames = nil
currentNode.paramChild = nil
currentNode.anyChild = nil
currentNode.isLeaf = false
// Only Static children could reach here
currentNode.children = append(currentNode.children, n)
// 如果分裂后的父节点当前需要的search路径一致就直接更新这个父节点的属性
if lcpLen == searchLen {
// At parent node
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
// 否则创建一个新的子节点
} else {
// Create child node
n = newNode(t, search[lcpLen:], currentNode, nil, h, ppath, pnames, nil, nil)
// Only Static children could reach here
currentNode.children = append(currentNode.children, n)
}
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
// 如果公共前缀大于0且等于当前节点的前缀且搜索路径大于当前前缀,说明需要深入子节点
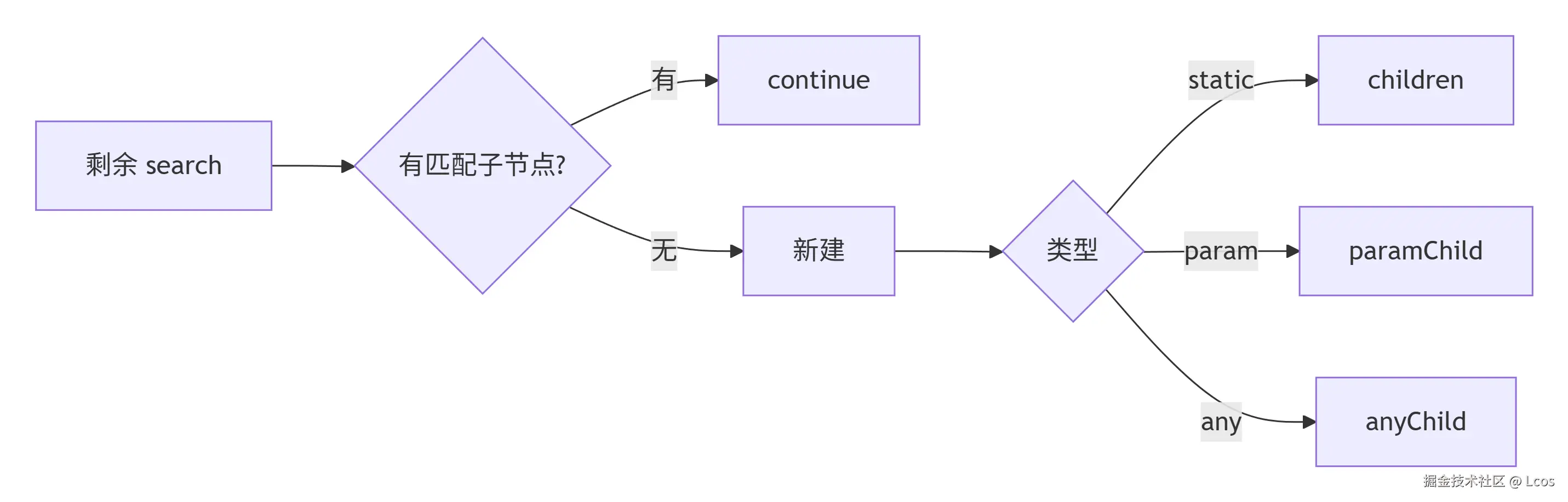
} else if lcpLen < searchLen {
// 新的搜索路径为公共前缀后的路径
search = search[lcpLen:]
// 寻找符合首字符的子节点
c := currentNode.findChildWithLabel(search[0])
if c != nil {
// Go deeper
// 找到了符合首字符的子节点,继续深入子节点
// 设置子节点为新的currentNode
currentNode = c
continue
}
// 没有找到符合首字符的子节点,创建一个新的子节点
// Create child node
n := newNode(t, search, currentNode, nil, h, ppath, pnames, nil, nil)
// 分开处理静态节点、参数节点和通配符节点
switch t {
case skind:
currentNode.children = append(currentNode.children, n)
case pkind:
currentNode.paramChild = n
case akind:
currentNode.anyChild = n
}
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
// 如果最大公共前缀等于搜索路径且等于当前节点的前缀,说明当前节点已经存在,需要更新当前节点的属性
} else {
// Node already exists
if currentNode.handlers != nil && h != nil {
panic("handlers are already registered for path '" + ppath + "'")
}
if h != nil {
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}
}
return
}
}源码逻辑比较复杂,这里我们拆开来讲解
1. 初始化与LCP计算
go
func (r *router) insert(path string, h app.HandlersChain, t kind, ppath string, pnames []string) {
currentNode := r.root
// 判定节点不为nil,此处为防御性编程
if currentNode == nil {
panic("hertz: invalid node")
}
search := path
for{这里初始化了当前节点currentNode和需要插入的路径search,然后进入主循环
go
searchLen := len(search)
prefixLen := len(currentNode.prefix)
lcpLen := 0
max := prefixLen
if searchLen < max {
max = searchLen
}
// 查找公共前缀
for ; lcpLen < max && search[lcpLen] == currentNode.prefix[lcpLen]; lcpLen++ {
}这里通过一个循环取得了待插入路径search和当前节点前缀currentNode.prefix的最大公共前缀
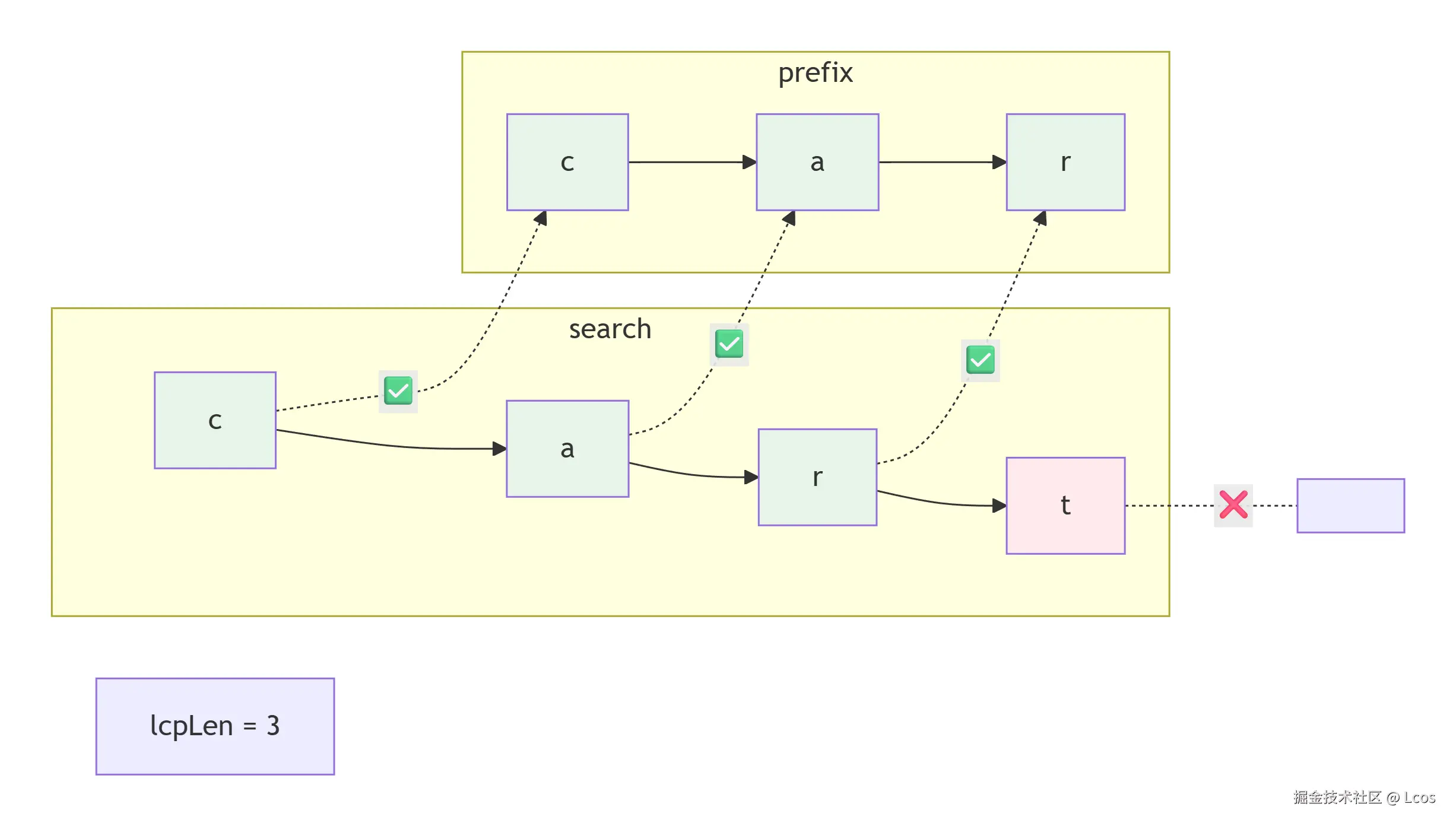
2. 基于LCP的四种情况
LCP == 0
go
// 如果公共前缀为空,说明当前节点是一个全新节点
if lcpLen == 0 {
// At root node
currentNode.label = search[0]
currentNode.prefix = search
if h != nil {
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}
// 如果当前节点没有子节点,说明当前节点是一个叶子节点
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
// 如果公共前缀大于0且小于当前节点的前缀,说明节点需要分裂
}没有公共前缀那么就说明这是整棵树刚创建时的第一次 insert
没有那就创建~
将会赋值所需的属性, 并判断是否为叶节点
LCP < prefixLen
此时公共前缀小于当前节点的前缀,这就说明需要节点分裂,需要拆分当前节点,并创建一个新的中间节点来存储共同前缀的部分对路径进行分割
go
} else if lcpLen < prefixLen {
// Split node
n := newNode(
currentNode.kind,
currentNode.prefix[lcpLen:],
currentNode,
currentNode.children,
currentNode.handlers,
currentNode.ppath,
currentNode.pnames,
currentNode.paramChild,
currentNode.anyChild,
)
// Update parent path for all children to new node
for _, child := range currentNode.children {
child.parent = n
}
if currentNode.paramChild != nil {
currentNode.paramChild.parent = n
}
if currentNode.anyChild != nil {
currentNode.anyChild.parent = n
}这是分裂后的尾部节点,继承原来节点的所有属性
go
// Reset parent node
currentNode.kind = skind
currentNode.label = currentNode.prefix[0]
currentNode.prefix = currentNode.prefix[:lcpLen]
currentNode.children = nil
currentNode.handlers = nil
currentNode.ppath = nilString
currentNode.pnames = nil
currentNode.paramChild = nil
currentNode.anyChild = nil
currentNode.isLeaf = false
// Only Static children could reach here
currentNode.children = append(currentNode.children, n)这里把分裂出来的头部节点重置一下,然后作为父节点添加分裂出去的尾部节点为子节点,注意这里称呼为父节点但是实际上就是currentNode
go
if lcpLen == searchLen {
// At parent node
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
// 否则创建一个新的子节点
} else {
// Create child node
n = newNode(t, search[lcpLen:], currentNode, nil, h, ppath, pnames, nil, nil)
// Only Static children could reach here
currentNode.children = append(currentNode.children, n)
}
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
// 如果公共前缀大于0且等于当前节点的前缀且搜索路径大于当前前缀,说明需要深入子节点然后把此时分裂之后的父节点的前缀和我们要插入的路径做比较
如果lcpLen == searchLen则当前这个节点就是我们要找的节点,那么就更新属性,挂上handlers,否则就创建一个新的子节点
LCP == prefixLen 且 LCP < searchLen
此时公共前缀和当前节点的prefix完全匹配,但是我们要寻找的路径更长,所以需要去找到符合的子节点继续循环,不然就创建新的子节点
go
} else if lcpLen < searchLen {
// 新的搜索路径为公共前缀后的路径
search = search[lcpLen:]
// 寻找符合首字符的子节点
c := currentNode.findChildWithLabel(search[0])
if c != nil {
// Go deeper
// 找到了符合首字符的子节点,继续深入子节点
// 设置子节点为新的currentNode
currentNode = c
continue
}找到了符合的子节点就继续循环
go
// 没有找到符合首字符的子节点,创建一个新的子节点
// Create child node
n := newNode(t, search, currentNode, nil, h, ppath, pnames, nil, nil)
// 分开处理静态节点、参数节点和通配符节点
switch t {
case skind:
currentNode.children = append(currentNode.children, n)
case pkind:
currentNode.paramChild = n
case akind:
currentNode.anyChild = n
}
currentNode.isLeaf = currentNode.children == nil && currentNode.paramChild == nil && currentNode.anyChild == nil
// 如果最大公共前缀等于搜索路径且等于当前节点的前缀,说明当前节点已经存在,需要更新当前节点的属性
}没找到就创建一个新的子节点,根据类型放到三种类型各自的子节点字段
LCP == prefixLen 且 LCP == searchLen
此时当前节点的prefix和插入路径完全一致
go
// 如果最大公共前缀等于搜索路径且等于当前节点的前缀,说明当前节点已经存在,需要更新当前节点的属性
} else {
// Node already exists
if currentNode.handlers != nil && h != nil {
panic("handlers are already registered for path '" + ppath + "'")
}
if h != nil {
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}
}
return
}
}如果都有handlers就说明矛盾了,那么会直接panic,因为这是有冲突的做法
如果currentnode没有handler,那么就可能是在分裂节点的过程中产生的无handler节点,或者是addroute函数中由于分段insert产生的,那么此时就给他加上了
结尾
Hertz 的路由树构建,本质上是一个复杂度换性能的决策。
addRoute 多了一层路径拆解,insert 多了三个独立字段的维护,find 用 goto 手动控制回溯------这一切,只为了每次请求查找时少一次遍历,快几纳秒。
对 99% 的项目来说,这点性能提升微乎其微,Gin 或 Echo 的简洁实现完全够用。但在字节跳动百万 QPS 的场景下,每一层循环的省略都在累积价值。没有最好的设计,只有最适合场景的取舍。
理解了 insert,你就理解了所有 Radix Tree 路由框架的核心原理------节点分裂、前缀压缩、优先级回溯,这些机制在 Gin、Echo、Fasthttp 中一脉相承。Hertz 只是在这条路上多走了一步:把热路径的判断挪到冷路径,用构建时的复杂换查找时的极简。
下一篇,我们将进入 find 函数,看这棵树如何在请求到来时,用 static → param → any 的优先级一步步找到正确的 handler。