站在云原生高并发天花板:拆解 Go 语言 GMP 模型与 I/O 多路复用的神级配合
在现代高并发后端编程中,Go 语言(Golang)凭借超高的并发吞吐量和极低的内存消耗,直接成为了 Docker、Kubernetes 等云原生基础设施的御用语言。
大家都知道 Java 靠多线程、Node.js 靠单线程事件循环,而 Go 则是靠"协程(Goroutine)"。协程非常轻量(只需几 KB 内存),单机轻松开启百万个。
但是,底层的物理 CPU 是如何高效调度这百万个轻量协程的?当协程遇到网络 I/O 阻塞时,Go 实现非阻塞的底层逻辑到底是什么?今天这篇博客,带你用最通俗的逻辑,彻底扒开 Go 语言高并发的核心底牌------GMP 模型与 Netpoller 的完美结合。
🚀 补充:进阶高并发前置基石
在深入 GMP 之前,我们必须先厘清两个在服务端开发中极易被混淆的底层概念:并发 与 并行 ,以及 I/O 的本质 。这是理解任何高性能架构的物理边界。
关于这部分的详细介绍可以看看我的这篇彻底搞懂 I/O 多路复用:并发、线程与五大语言高并发模型底层差异
1. 并发(Concurrency)vs 并行(Parallelism)
- 并行 :同一时刻,多个任务同时真正执行。这必须依赖多核 CPU 的硬件支持,是物理层面的同时运行。比如 CPU 有 8 个核心,同一瞬间可以同时跑 8 个物理线程,互不抢占。
- 并发 :同一时间段内,多个任务交替切换执行,宏观上看起来同时运行。它是通过软件调度算法(如时间片轮转)实现的视觉假象。单核 CPU 无法实现并行,只能实现并发。
2. 什么是 I/O 模型?
I/O(Input/Output,输入/输出) 是程序与外部设备(硬盘、网卡、键盘等)进行数据交互的桥梁。
- I (输入) :数据从外设 → \rightarrow → 进程内存。例如:读取磁盘文件、接收网卡数据。
- O (输出) :数据从进程内存 → \rightarrow → 外设。例如:向磁盘写文件、通过网卡向客户端发送数据。
操作系统的残酷视角 :CPU 的运算速度是纳秒级的,而磁盘、网卡等外设的响应速度通常在微秒到毫秒级。在传统的 I/O 操作中,绝大多数时间进程都在死等硬件就绪。这种物理级"速度差",是各种高级 I/O 模型出现的根本原因。
一、 什么是 GMP?(三大核心角色拆解)
在传统语言(如 Java、C++)中,高并发依赖操作系统线程,但线程太重了。Go 语言在用户态自己实现了一套高效的调度器,其核心由三个角色组成,简称 GMP:
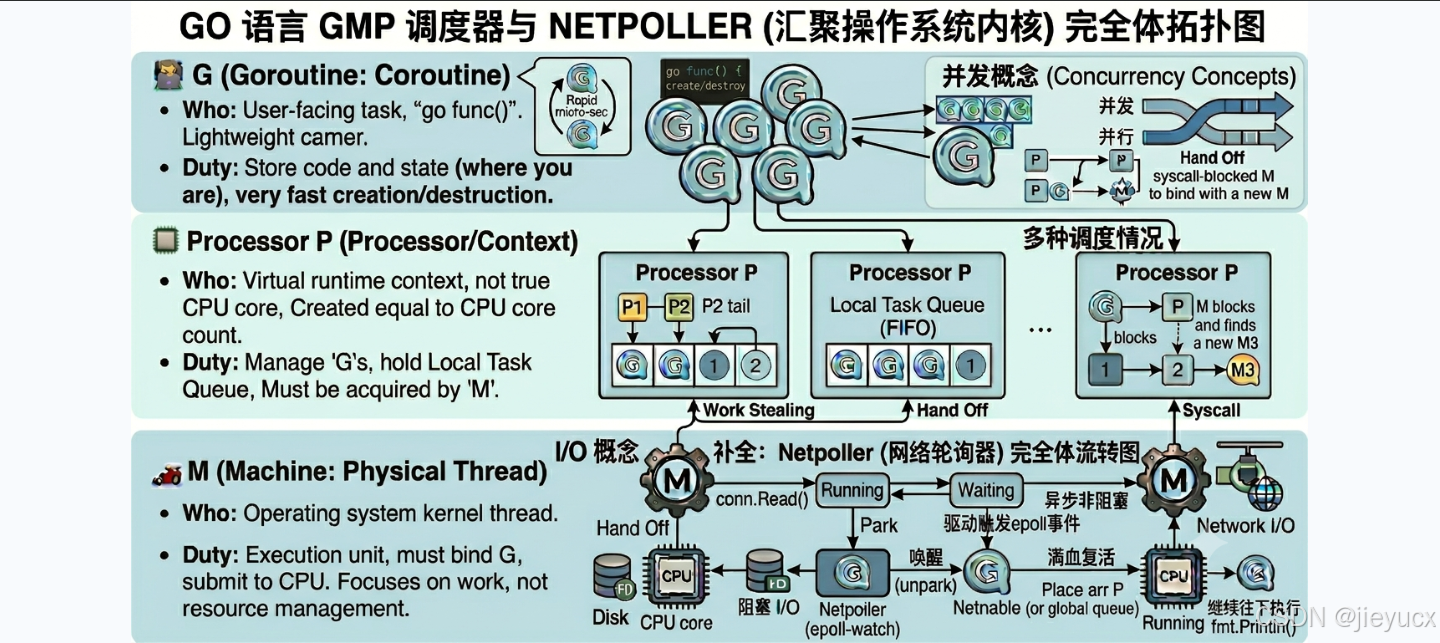
🧑💻 G(Goroutine:协程)
- 它是谁 :你在代码里写
go func()启动的东西。 - 职责:它是任务的载体。它自己没有执行能力,里面存放着你需要执行的代码、当前运行到了哪一行(上下文状态)。它极其轻量,可以被瞬间创建和销毁。
🏎️ M(Machine:物理线程)
- 它是谁:由操作系统内核真正的物理线程。
- 职责:它是真正的执行者。G 里面的代码必须绑定到 M 上,由 M 提交给 CPU 才能真正跑起来。M 只管干活,不管理资源。
调度器 P(Processor:处理器/上下文)
- 它是谁:Go 语言运行时(Runtime)虚拟出来的处理器,不是真正的 CPU 核心。
- 职责:它是资源的管理者。P 的数量通常等于服务器的 CPU 核心数。P 手里抓着一个"本地任务队列",里面排队放着等待运行的 G。M 必须先绑定一个 P,才能从 P 的队列里领到 G 去执行。
二、 为什么要加一个 P?(从"排队加锁"到"无锁本地化")
在早期的 Go 1.1 版本之前,其实只有 G 和 M,并没有 P。当时的做法是:所有的 M 想要干活,都必须去一个全局的任务队列里抢 G 跑。
旧模型的致命短板
这就好比一个大型工厂,只有一个共享的材料库。成百上千个工人(M)为了拿材料(G),必须在门口排队"加锁"。谁抢到锁谁才能拿,导致大量时间浪费在"排队和抢锁"的内耗上,根本无法发挥多核 CPU 的并行优势。
【拓扑图:老旧的单队列无 P 模型】
text
物理线程 M1 ──┐
物理线程 M2 ──┼─> [ 全局 G 任务队列 ] (必须加锁 Mutex 竞争,导致高内耗与多核瓶颈)
物理线程 M3 ──┘新模型引入 P 的神级逆袭
Go 团队在中间加了 P(本地库房)。现在每个工人(M)都分配了一个专属的项目经理(P),项目经理手里有自己的小库房(本地队列)。M 只需要从小库房拿任务就行,绝大多数时候互不干扰,彻底摆脱了全局锁的限制。
【拓扑图:引入 P 的本地化无锁模型】
text
物理线程 M1 ──> 绑定 ──> 处理器 P1 ──> [ P1 的本地私有队列 (G1, G2, G3...) ]
物理线程 M2 ──> 绑定 ──> 处理器 P2 ──> [ P2 的本地私有队列 (G4, G5, G6...) ]三、 大计算场景下,GMP 调度器的两大神级机制
我们把整个 Go 运行时(Runtime)调度场景比作一家"高效的外包公司":
- G 是客户提来的业务订单(需求)。
- P 是项目经理(带工位和专属资源),手里有一个待办需求清单(本地队列)。
- M 是苦力程序员(真正干活的系统线程)。
在面对大计算量、CPU 密集型任务时,Go 靠以下两个机制榨干硬件性能:
1. 工作窃取机制(Work Stealing)------ 绝不养闲人
如果程序员 M1 手速极快,把自己对应的项目经理 P1 手里的订单(G)全部做完了,全局队列也空了,这时候他会闲着围观吗?
答案是:绝不。 M1 会悄悄走到隔壁项目经理 P2 那里瞅一眼,然后毫不客气地从 P2 的本地队列尾部直接偷走一半的 G 拿回自己的队列里接着干。
意义:保证了多核 CPU 下,没有任何一个线程在处于饥饿或闲置状态,全员满载工作。
【拓扑图:Work Stealing 工作窃取流动轨迹】
text
【P1 队列已空】 物理线程 M1 ──> 跨界侦查 ──> 发现 P2 队列很满 (有 G7, G8, G9, G10)
│
▼
【直接从 P2 队列尾部偷走一半任务 (G9, G10)】2. 遇难脱身机制(Hand Off)------ 遇阻塞果断离婚
如果程序员 M1 正在做订单 G1,结果 G1 遇到了一个耗时极长的磁盘 I/O 任务(比如向硬盘读取一个 10G 的大文件,这在计算机里叫系统调用阻塞)。操作系统会把 M1 连同 G1 一起强行卡死(阻塞)在原地。
Go 的骚操作:项目经理 P1 看到 M1 被卡死了,不能让手下剩下的 G 跟着一起干等啊!P1 会立刻和 M1 果断解绑(Hand Off),带着剩下排队的 G 去找一个全新的空闲程序员 M2 绑定,让 M2 带着剩下的兄弟继续往前冲。
M1 忙完回来时:大文件读完了,M1 恢复清醒。它会把做完的 G1 放回安全的地方,然后去看看能不能重新找个项目经理(P)绑定。如果大家都满员了,M1 就会把自己放进休眠线程池,等待下次被呼叫。
【拓扑图:Hand Off 遇难脱身解绑模型】
text
[ 发生阻塞前 ]: 物理线程 M1 ──── 绑定 ──── 处理器 P1 (排队: G2, G3, G4)
│
▼ (G1 触发文件系统调用被卡死)
[ 发生阻塞后 ]: [ 物理线程 M1 + 阻塞的 G1 ] 被隔离留在原地卡死
【 P1 连夜带队改嫁 】 ───> 寻找/创建 ───> 全新物理线程 M2
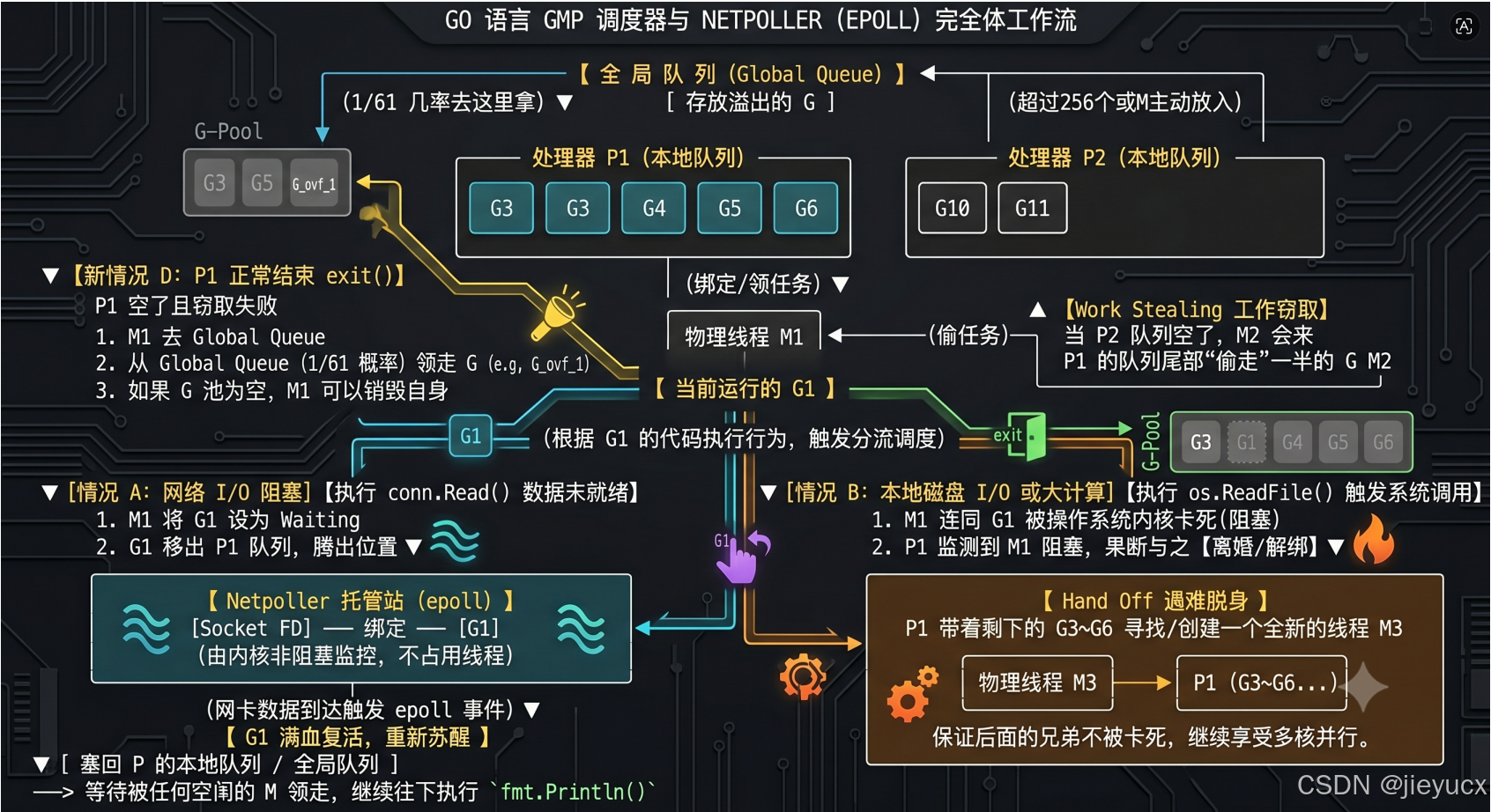
物理线程 M2 ──── 绑定 ──── 处理器 P1 (继续狂飙: G2, G3, G4)四、 终极奥义:GMP 与 I/O 多路复用(Netpoller)的深度融合
以上的 Hand Off 机制虽然完美,但它是针对磁盘 I/O 或大计算阻塞的。
现实开发中,我们 90% 的场景是网络 I/O密集型(如等待数据库回包、处理 WebSocket 长连接)。如果每个网络连接没来数据时,Go 都要为它解绑并新建一个物理线程 M M M,那线程数量还是会瞬间爆炸,重蹈传统 BIO 的覆辙。
为了解决这个问题,Go 运行时派出了隐藏的大杀器------Netpoller(网络轮询器)。
1. 什么是 Netpoller?
Netpoller 是 Go 运行时内部一个独立的组件,它的底层是对操作系统 I/O 多路复用(Linux 下是 epoll,macOS 下是 kqueue)的极致封装。它专门用来托管所有"因为等待网络数据而进入阻塞"的协程 G。
2. 网络 I/O 下的完全体调度链路
我们以一个真实的场景来拆解:协程 G1 正在等待客户端发送网络数据(执行 conn.Read())。
- 阶段一:数据未就绪,G1 移交托管站
当 G1 调用Read()且网络数据还没到达网卡时,Go 运行时绝不会阻塞当前的物理线程 M。Go 会把 G1 的状态改为 Waiting,然后把 G1 从当前 P 的队列中抽离出来,直接丢进 Netpoller 的 epoll 监听列表里。 - 阶段二:M 和 P 光速解脱,零延迟切换
由于阻塞的 G1 被 Netpoller 接管了,物理线程 M M M 腾出了双手。它立刻从处理器 P P P 的本地队列里拿出下一个就绪的 G2 继续疯狂执行。整个切换在用户态完成,物理线程 M M M 没有任何停顿,CPU 保持 100% 利用率。 - 阶段三:网卡数据到达,Netpoller 被唤醒
过了一会儿,客户端的数据通过网络到达了网卡,操作系统内核触发中断,Linux 的 epoll 检测到对应的 Socket 描述符就绪了。
正在暗中观察的 Netpoller 立刻被唤醒,顺着就绪的 fd 找到了被托管的 G1,将它的状态改为 Runnable,并把它捞出来,重新放回某个 P 的本地队列(或全局队列)中。 - 阶段四:G1 被重新轮询执行
当某个线程 M M M 下一次领任务时,就会领到"满血复活"的 G1。G1 以为自己刚刚经历了一次正常的阻塞,但实际上,底层的物理线程 M M M 早就趁这段时间干完了好几个其他协程的工作。
【完全体架构拓扑:GMP 与 Netpoller 复合流转拓扑图】
text
==========================================================================================
GO 语言 GMP 调度器与 NETPOLLER (汇聚操作系统内核) 完全体
==========================================================================================
【 全 局 队 列 (Global Queue) 】 ───> [ 存放溢出的 G ] <───┐
│ │
│ (1/61 几率轮询) │
▼ │
┌─────────────────────────────┐ ┌──────────────┴──────────────┐
│ 处理器 P1 (本地队列) │ │ 处理器 P2 (本地队列) │
│ ┌───┐ ┌───┐ ┌───┐ ┌───┐ │ │ ┌───┐ ┌───┐ │
│ │ G3│ │ G4│ │ G5│ │ G6│ │ │ │G10│ │G11│ │
│ └───┘ └───┘ └───┘ └───┘ │ │ └───┘ └───┘ │
└──────────────┬──────────────┘ └──────────────┬──────────────┘
│ ▲
│ (绑定/领任务) │ 【Work Stealing 工作窃取】
▼ │ M2 闲时自动去抢
┌───────────┐ │ P1 的任务分担压力
│ 物理线程 M1│ ──── (主动网罗) ──────────────────┘
└─────┬─────┘
│
▼
【 当前运行的 G1 】
│
┌────────────────┴────────────────┐ (根据 G1 的代码执行行为,触发分流调度)
│ │
▼ [分流路径 A:网络 I/O 阻塞] ▼ [分流路径 B:本地磁盘 I/O / 大计算]
【执行 conn.Read() 数据未就绪】 【执行 os.ReadFile() 触发系统调用】
│ │
│ 1. M1 将 G1 状态改为 Waiting │ 1. M1 连同 G1 被内核强制卡死
│ 2. G1 脱离 P1 队列, 腾出位置 │ 2. P1 与 M1 解绑 (Hand Off 启动)
▼ ▼
┌───────────────────────────────┐ ┌─────────────────────────────────────────────┐
│ 【 Netpoller 托管站 (epoll) 】 │ │ 【 唤醒全新物理线程 M3 】 │
│ │ │ │
│ [Socket FD] ── 绑定 ── [G1] │ │ 物理线程 M3 ──── 绑定 ──── 处理器 P1 (G3...) │
│ │ │ │
│ (内核级异步多路复用,零线程开销) │ │ 保证后面的兄弟不被卡死,横向压榨多核能力。 │
└──────────────┬────────────────┘ └─────────────────────────────────────────────┘
│
(网卡收到数据,驱动触发 epoll 事件)
│
▼
【 G1 状态转为 Runnable 】
│
▼
[ 重新塞回 P 本地队列 / 全局队列 ] ──> 等待被任何空闲的 M 领走,继续顺流而下执行五、 为什么说 Go 的并发模型是"降维打击"?
对比一下高并发界的另一大杀手 Node.js (JavaScript) 以及多线程代表 Java,你就能明白 Go 模型的高明之处:
1. Node.js 的异步(回调地狱/Promise)
JS 的异步是非阻塞的,但它要求开发者在思维上做出改变,必须写复杂的异步回调或 async/await,代码思维是割裂的。
2. Java 的线程并发模型
Java 的线程天然映射系统线程,多个线程在多核 CPU 上真并行运行,然而由于它们完全共享进程内存 ,多个线程同时读写同一个全局变量时,会出现极其严重的并发冲突与数据踩踏,必须依赖复杂的锁机制(synchronized、ReentrantLock)和 CAS 原子操作来保证线程安全。
3. Go 语言的异步(看似同步阻塞,实则异步非阻塞)
Go 巧妙在:它把底层的异步非阻塞,伪装成了符合人类直觉的"同步顺序"写法。
go
// 看起来像传统的死等(同步),符合老一辈程序员最顺流而下的直觉
data, _ := conn.Read(buf)
fmt.Println(data)你在代码里写的是最简单的同步逻辑,但 Go 运行时在底层偷偷用 Netpoller (epoll) 帮你在用户态做了协程的暂停、挂起、内核托管、唤醒和重新调度。既拥有极致的性能,又拥有极低的开发心智负担。
💡 补充:五大语言主流并发模型大横评
为了拓宽视野,我们把行业内最主流的五大语言放在同一个底层维度进行横向横评:
| 语言 | 核心代码执行是多线程吗? | 多个线程能物理并行(多核)吗? | 多个线程/协程能直接修改全局变量吗? | 并发核心底层依赖 |
|---|---|---|---|---|
| JavaScript | ❌ 否(主线程纯单线程) | ❌ 否(Worker 隔离不并行) | ❌ 否(内存隔离,无法直接修改) | 单线程 + I/O 多路复用 (Libuv) |
| Python | 是 | ❌ 否(被 GIL 锁死,只能并发交替) | 是(虽然交替执行,仍需加锁防冲突) | 异步事件循环 (asyncio) / 多进程 |
| Java | 是 | 是(真·多核物理并行) | 是(自由度极高,冲突风险极大) | 多线程并行 + 多路复用优化 (NIO) |
| Go | 是(轻量级协程) | 是(真·多核物理并行) | 是(支持共享修改,但更推荐 Channel) | M:N 协程调度 + 内置 Netpoller |
| C 语言 | 是(完全由开发者人肉决定) | 是(真·多核物理并行) | 是(极度自由,指针越界直接宕机) | 原生系统调用 (epoll / kqueue) |
✍️ 总结:完全体闭环链路图
plaintext
【用户编码层】 💡 开发者写出最朴素的同步代码: conn.Read()
│
▼
【GMP 调度层】 发现网络数据未就绪 ──> 将 G1 设为 Waiting ──> 踢出 P 队列
│
▼
【内核托管层】 物理线程 M 毫无感知,继续跑 G2 <─── 【Netpoller 托管站 (epoll)】
│
(网卡数据总量到达,epoll事件就绪)
│
▼
【复活激活链】 G1 被 Netpoller 捞回 ──> 扔进 P 本地队列 ──> 等待 M 下次调用执行- 大计算量/CPU 密集型:靠 GMP 的 Work Stealing(工作窃取)和 Hand Off(解绑)在多核 CPU 间横向轮转并行。
- 网络 I/O 密集型:靠 Netpoller(底层 epoll) 将阻塞的 G 抽离出队列挂起,绝不连累 M。
这两套马车完美结合,才让 Go 语言在面对海量并发长连接流量时,既能保持极低的资源消耗,又能写出极其优雅的代码。搞懂了 GMP 与 I/O 多路复用的融合,你就真正掌握了高性能后端架构的底层通关密码。