目录
[1 QK-LSTM 复现](#1 QK-LSTM 复现)
[1.1 环境准备](#1.1 环境准备)
[1.2 数据准备与预处理](#1.2 数据准备与预处理)
[1.3 模型搭建](#1.3 模型搭建)
[1.3.1 LSTM](#1.3.1 LSTM)
[2 总结](#2 总结)
摘要
本周尝试复现了前面看过的《Quantum Kernel-Based Long Short-term Memory for Climate Time-Series Forecasting》这篇论文的数据预处理部分,对其整体流程有了更全面的认识,对AQI计算、插值以及异常检测等也有了更深的理解。
Abstract
This week, I attempted to reproduce the data preprocessing part of the previously read paper "Quantum Kernel-Based Long Short-term Memory for Climate Time-Series Forecasting", gaining a more comprehensive understanding of its overall workflow, as well as a deeper understanding of AQI calculation, interpolation, and anomaly detection, among other things.
1 QK-LSTM 复现
1.1 环境准备
创建 python3.10 的虚拟环境,并下载对应的函数库,具体包括PyTorch、PennyLane、pandas、NumPy、scikit-learn、matplotlib 与 tqdm 等。
其中PyTorch负责Tensor运算、自动求导等,主要用于实现LSTM和QK-LSTM;PennyLane负责创建量子设备、构建量子线路等量子相关的部分,主要用于实现量子核;pandas与NumPy主要负责数据预处理,包括数据读取、排序、差值与底层运算等;scikit-learn主要负责数据归一化与评估;matplotlib主要负责可视化;tqdm主要负责训练监控。
1.2 数据准备与预处理
数据来源:Guilin Air Pollution: Real-time Air Quality Index (仅观测数据,单位均为,未经过充分验证与分析)
观察发现数据主要涵盖2026年5月至2014年1月的污染物浓度指数,污染物种类包括pm2.5、pm10、O3、NO2、SO2与CO。
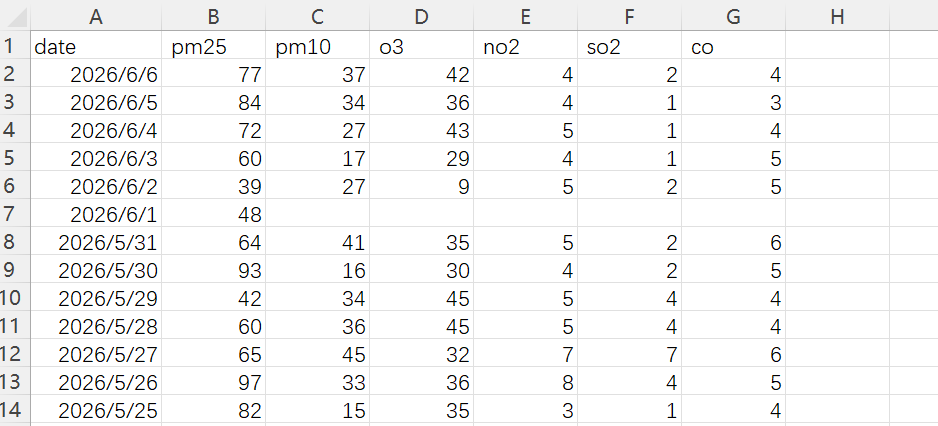
其中2025年12月到2026年5月的数据大致如下:
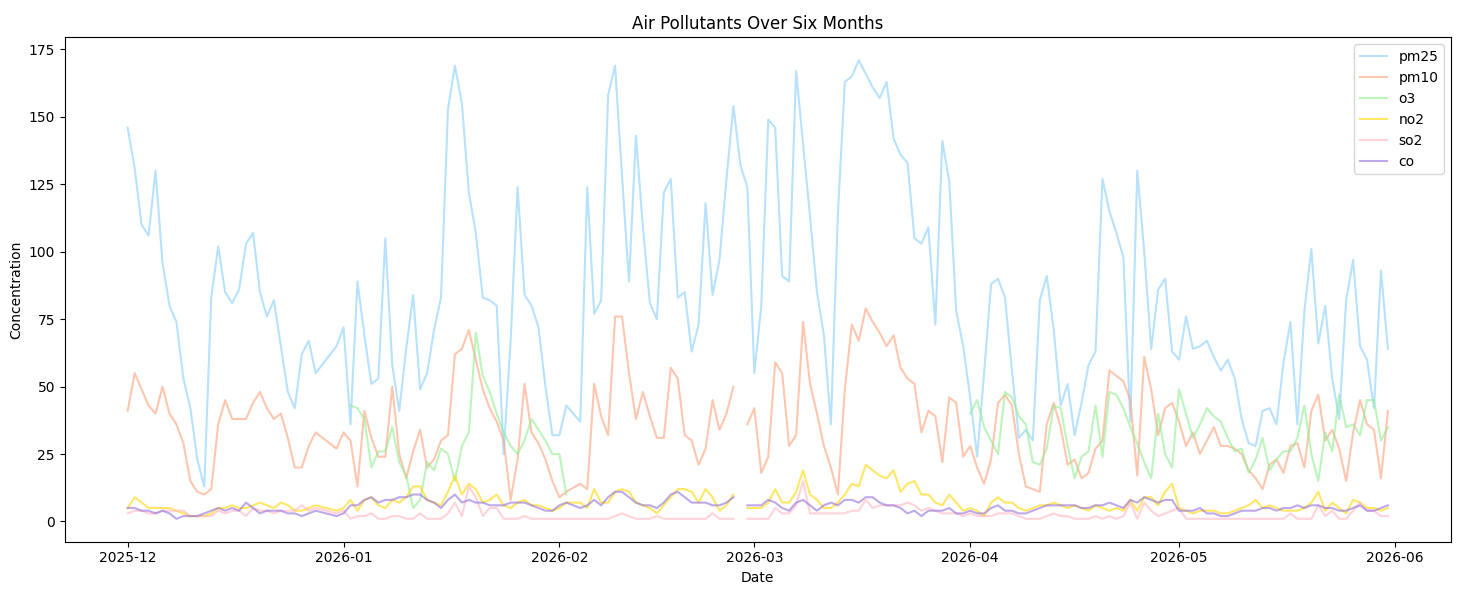
观察上图,可发现存在明显缺失,故先对原始数据进行线性插值。线性插值主要基于相邻已知数据点之间的线性关系估计缺失数据点,能够最大限度地减少由内插引起的突变,保持数据集的光滑性和连续性。其代码如下:
python
df_6months[pollutants] = df_6months[pollutants].interpolate(method="linear")论文中AQI计算公式如下,共11种特征:
复现采用同样的公式,不过数据仅6种特征。
另外原文对 的描述为通过使用已建立的AQI断点将污染物的实际浓度映射到标准化标度而获得的对应污染物分类指数,由于不确定所谓AQI断点为何,且复现数据中各污染物浓度单位均为
,故复现单纯选用最大值。代码如下:
python
df_6months["AQI"] = df_6months[pollutants].max(axis=1)
aqi_6months = df_6months["AQI"].values可视化效果如下:
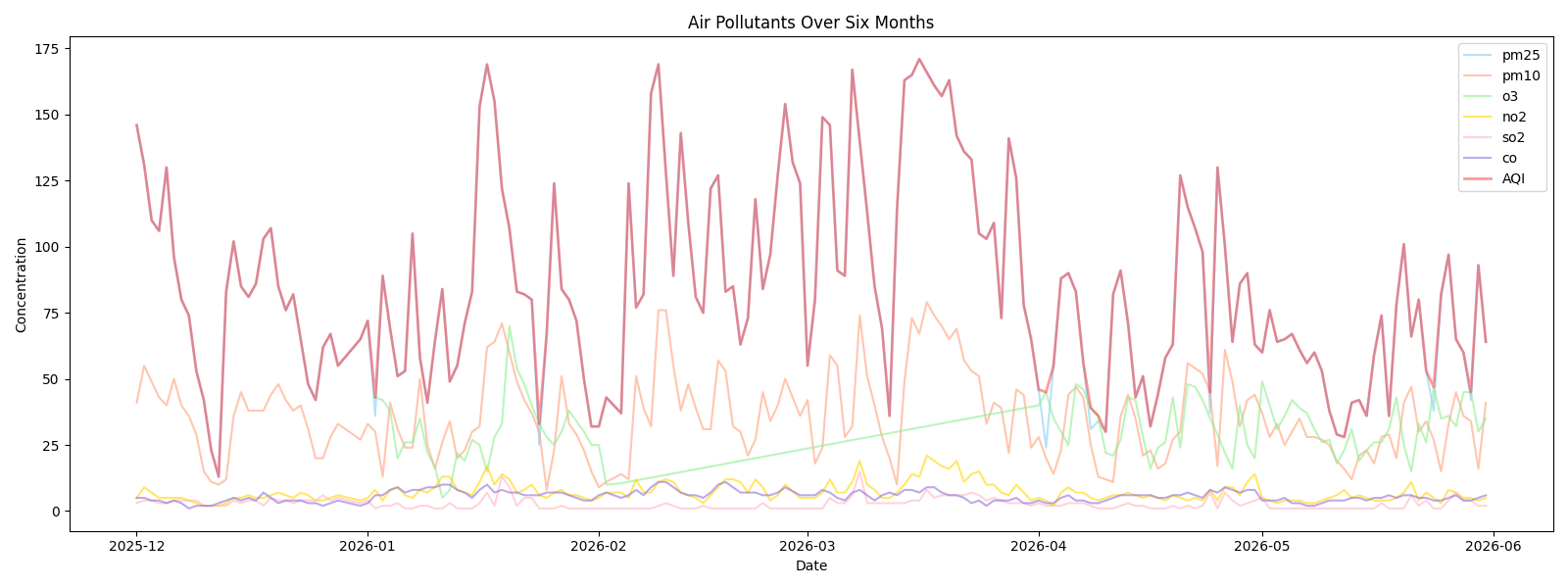
原文中采用Z-Score方法衡量数据点与平均值的标准偏差有多大来检测异常值。如果数据点的绝对Z分数超过预定义的阈值则将其视为异常值,代码如下:
python
# 异常值检测
z_scores = np.abs(zscore(df_6months["AQI"])) # 计算z分数,并取绝对值
mask = z_scores < 3 # 阈值设置为3
df_6months_clean = df_6months[mask].copy()发现无可删除异常点,计算出的最大绝对z分数约为2.313。

本次复现思路是先对原始污染物缺失进行插值,计算AQI,再对AQI进行异常检测,异常检测若有删除则再进行插值。但看到另一种思路是对污染物插值后再进行异常检测,若有删除再插值,之后再计算AQI,因为认为AQI是结果,插值应该发生在污染物层,而非AQI层。
p.s. 个人觉得后一种思路应该更好,但观察数据认为两者影响不大,重点影响还是在模型结构上,故未修改。
1.3 模型搭建
1.3.1 LSTM
基线LSTM简单构建如下(后续可能修改):
python
class LSTM(nn.Module):
def __init__(self):
super().__init__()
self.lstm = nn.LSTM(
input_size=6,
hidden_size=16, #原文参数:隐藏单元16
batch_first=True
)
self.fc = nn.Linear(16,1)
def forward(self,x):
out,_ = self.lstm(x)
return self.fc(out[:,-1,:])代码中输入大小为6,指的是原始的污染物种类,是准备用前三天的原始污染物预测第四天的AQI。但此点存疑,因为论文中有明确表述,用前三天的AQI指数预测第四天,但参数量计算采用原始污染物更接近论文中数值。
2 总结
本周主要尝试进行了复现,虽然只有预处理部分,但是感觉到了复现的工作量与思考量,也让自己对这篇论文的流程有了更完整的了解。另外,发现线性插值的效果在面对长时间的缺失时貌似略显生硬,感觉复现完这篇后可以拿这个数据尝试下不同的插值方法。下周打算复现模型、训练及评估部分,观察基线与量子核的性能差异,起码把基线的效果弄出来。