文章简介
这是Jon Gjengset的演讲稿,原文为《The Cost of Concurrency Coordination》。
文章指出,让并发变慢的不是锁本身,而是核心之间的协调------其背后真正原因是CPU的缓存一致性协议。
作者简介
Jon Gjengset是Rust社区知名的技术专家和布道者,是书籍《Rust for Rustaceans》的作者。
他毕业于麻省理工,拥有并行与操作系统组的博士学位;期间开发了Noria项目,后来商业化成功并以初创公司ReadySet形式继续推进。
他现于欧洲顶级防务AI公司Helsing担任首席工程师(Principal Engineer),在这之前,曾在AWS维护Rust Build基础设施。
性能崩塌现象
简单测试:一个共享计数器
Rust
// 来自Jon Gjengset
let counter = Arc::new(Mutex::new(0u64));
loop {
letmut guard = counter.lock().unwrap();
std::hint::black_box(*guard);
}首先定义了一个计数器counter,它的初始值为一个64位无符号整数0。
Arc<Mutex<T>>负责多线程之间数据的安全并发共享。
循环里的操作就是尝试读这个计数器counter。
black_box防止Rust编译器把这个看似无意义的循环优化掉。
在这个过程中,只对数据进行读取,而没有写操作。
测试结果:Mutex与RWLock没区别?
图来自于Jon Gjengset的视频。
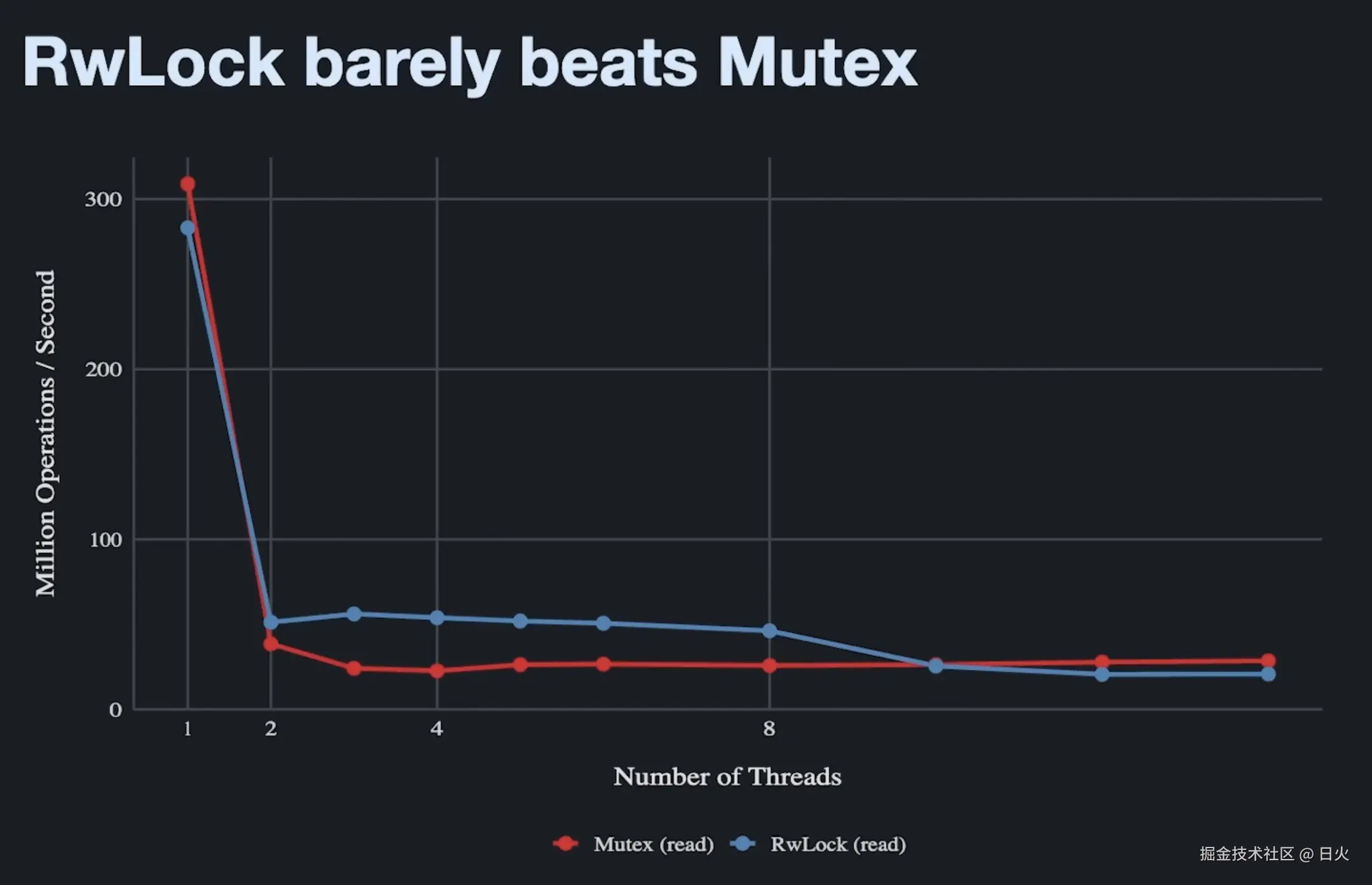
在上面的测试基础上,Jon Gjengset对比了Mutex和RWLock在多线程下的表现。
对于Mutex来说,单线程时,它每秒能够达到2.5亿次操作。这意味着,在一个2.5GHz的CPU上,完成加锁读取的操作大约只需要10个时钟周期。
然而,一旦线程数增加到2,那么性能会直接断崖式下跌到原来的十分之一,从2.5亿次操作每秒降到2500万次每秒。
而之后,继续增加线程,下降也不再明显,折线图趋势较为平坦。
互斥锁的测试结果也许在意料之中,然而读写锁的测试结果却和互斥锁极为相似。
同样地,RwLock也在线程数增加到2的时候性能暴跌差不多十倍左右。
也许开始的时候,读写锁性能下降到程度比读写锁稍微好一点,然而,随着线程的增加,最终读写锁的性能甚至比互斥锁还要差一点。
这是一个违反直觉的结论,因为读写锁RWLock在设计之初就是为了读多写少的场景设计的,然而在这里------全读操作的测试表现却并没有比互斥锁优越很多、甚至可能还要差。
这是为什么呢?
幕后黑手:CPU缓存一致性
CPU缓存
图来自于Jon Gjengset的视频。

从制造工艺、材质特性与物理距离来说,RAM的访问延迟速度比CPU大得多,大概在百倍左右。
为了平衡它们之间的速度差距,于是有CPU缓存。
而CPU缓存能够提升速度的原因,主要在于程序运行的局部性原理。
一是时间局部性,刚被使用过的数据,短时间内大概率还会被重复访问;二是空间局部性,如果一段数据被访问了,那么它周围的数据大概率会被接连访问。
同时,为了兼顾速度与成本,CPU缓存一般有三级缓存。
这其中,L1缓存速度最快、容量极小,离CPU最近,并且每个CPU核心独享;L3缓存离CPU比较远、离内存更近,速度较慢、容量较大,所有核心共享;L2缓存一般介于二者之间。
缓存一致性协议与缓存行
在上述提到的CPU缓存中,有些是CPU核心独享的,例如L1缓存。
那么当核心A和核心B都在缓存中独享了一份变量的副本后,如果A将变量的值改变,而B不知道,那么就会因为数据错误而导致程序崩盘。
这就是缓存一致性带来的问题。
于是,为了解决缓存一致性问题,需要某种缓存一致性协议(MESI)来商量由谁写、什么时候写入,并确保正确的值最终能够回到内存。
也许这个协议还有很多变体(MSI、MOESI等),但它们大多数都与MESI类似。
MESI的核心思路是为缓存行标记4种不同的状态,协议的名字正是这四个字母的缩写:
- Modified:已修改。该缓存行已被当前核心修改,与主存中不一致。
- Exclusive:独占。该缓存行数据与主存一致,且由当前CPU核心缓存独占。
- Shared:共享。该缓存行数据与主存一致,同时存在于其他核心缓存中,只读不写。
- Invalid:无效。该缓存行数据已失效,需重新获取。
同时,缓存行是CPU缓存中的最小存储单位。
CPU从内存中读取数据时,不是按照字节读的,而是按照缓存行读取的。
缓存行大小一般为64字节。
RWLock为何会慢?
对共享数据的写操作需要在CPU核心之间进行协调。
如果当前有一个处于"共享状态"的缓存行,并且当前CPU核心想修改它,那么这个核心需要和其他核心进行协调,因为它要保证其他核心不会在这个时候去修改、读取这个缓存行。
而这种跨核心通信正是部分性能开销都来源。
RWLock的底层实现
Rust
// 来自Jon Gjengset
pub fn read(&self) -> RwLockReadGuard {
self.reader_count.fetch_add(1, ...);
}而读写锁,在底层实现中,本质上是一个状态机。
它一般由计数器、写锁标志、内部互斥锁和等待队列组成。
计数器用来记录当前读者线程数量,上面的伪代码就是一个计数器reader_count实现的一部分,所以哪怕只是读操作,也需要对这个计数器执行+1的写操作。
跨核心传输的消耗
 (图来自Jon Gjengset的视频)
(图来自Jon Gjengset的视频)
那么,当两个核心Core 0和Core 1都想获取读锁时:
- 初始状态:Core 0独占计数器
reader_count,Core 1缓存里没有这个计数器 - Step 1:Core 0加读锁
- Core 0加读锁,把计数器
+1,由于它本来就独占计数器,所以不需要通知任何核心,状态从E(独占)改为M(已修改) - Core 1状态仍旧是I(无效)。
- Core 0加读锁,把计数器
- Step 2:Core 1也要加读锁
- Core 1也要加读锁,但是发现自己的状态是I(无效),于是向总线广播,表示它要修改这个计数器。
- Core 0收到了这个消息,于是把修改后的数据和控制权一起转移给Core 1,让Core 1把计数器继续
+1。 - 此时,Core 0的状态为I(无效),Core 1的状态为M(已修改)。
- Step 3:Core 0释放读锁
- Core 0打算释放读锁,把计数器
-1,然而发现自己状态无效。 - 于是重走了一遍Step 2,Core 1把值为
2的计数器和控制权一起转回给Core 0. - 此时Core 0的状态变为M(已修改),Core 1的状态变为I(无效)。
- Core 0打算释放读锁,把计数器
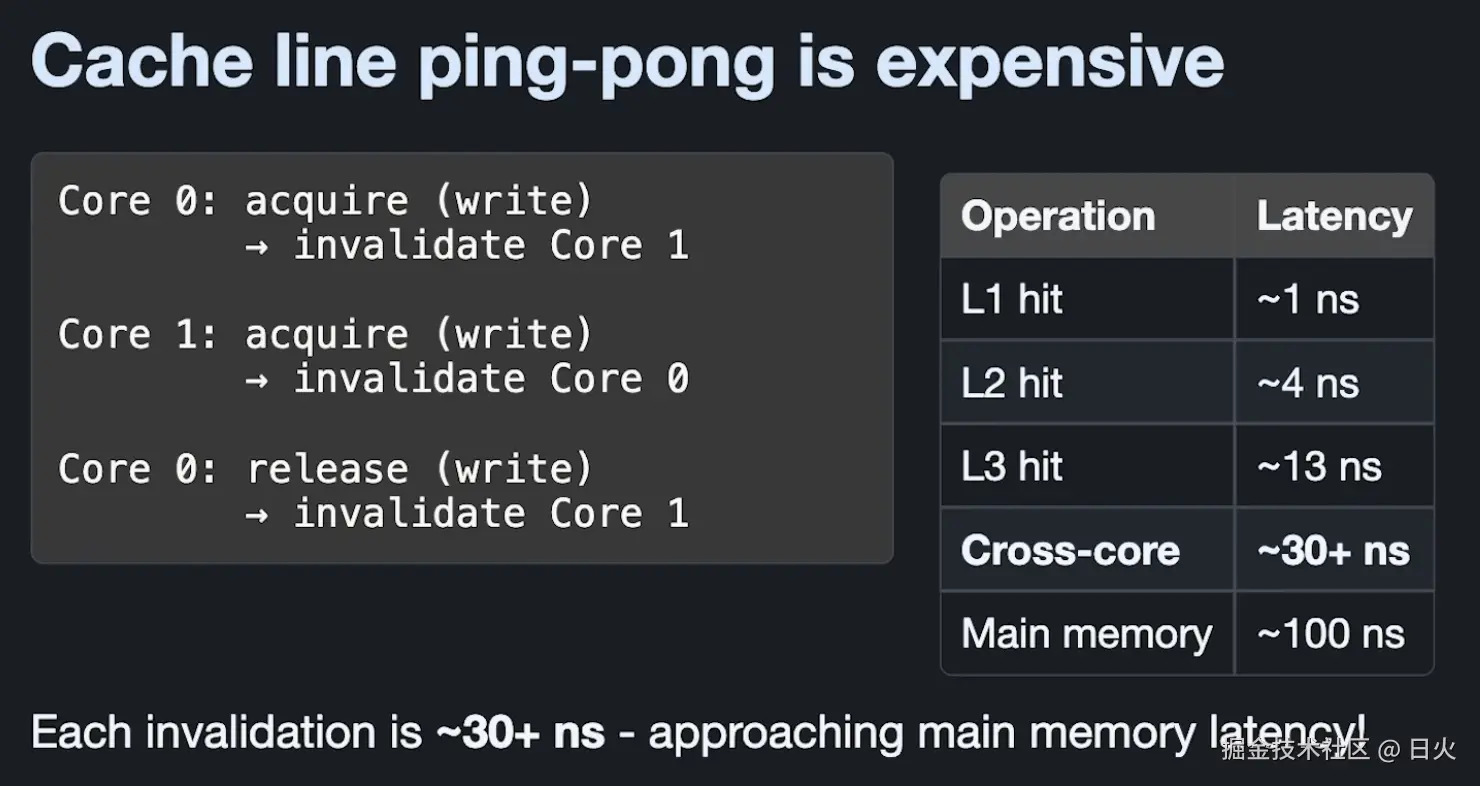 (图来自Jon Gjengset的视频)
(图来自Jon Gjengset的视频)
从上述的例子可以看到,哪怕是只有两个CPU核心参与的并发读,带有这个计数器reader_count的缓存行都在Core 0和Core 1之间来回跑了两次(Step 2和Step 3)。
而单次跨核心过程需要花费30ns左右,上述过程大约需要60ns,而相比于直接从L1缓存中读取数据所花费的1ns,实际上速度非常慢。
而如果把这个核心数放大到100个,那么原本看似互不干涉的读操作,在底层实际上会变成一个都在等待M状态的串行单行道,效率极其低下。
损耗的实际影响:长临界区 vs 短临界区
 (图来自Jon Gjengset的视频)
(图来自Jon Gjengset的视频)
所以在上述跨核心消耗不可避免的情况下,某些时候互斥锁Mutex可能会比读写锁更有优势。
因为对于互斥锁来说,每个核心在持有锁期间锁的控制权是确定的,完全可以接受一个个串行执行;而读写锁的读过程却不一定,无法避免跨核心的消耗,而这种竞争消耗随着读者的增加而变得激烈。
当与锁交互时,往往是先获取锁,运行逻辑代码,再释放锁。
如果逻辑代码很长,即拥有长临界区,那么获取释放锁的这一部分开销可以忽略不计;而如果临界区很短,那么锁的开销可能会占据90%以上,这并不划算。
解决思路:Left-Right数据结构
Left-Right原理
图来自Jon Gjengset的视频。
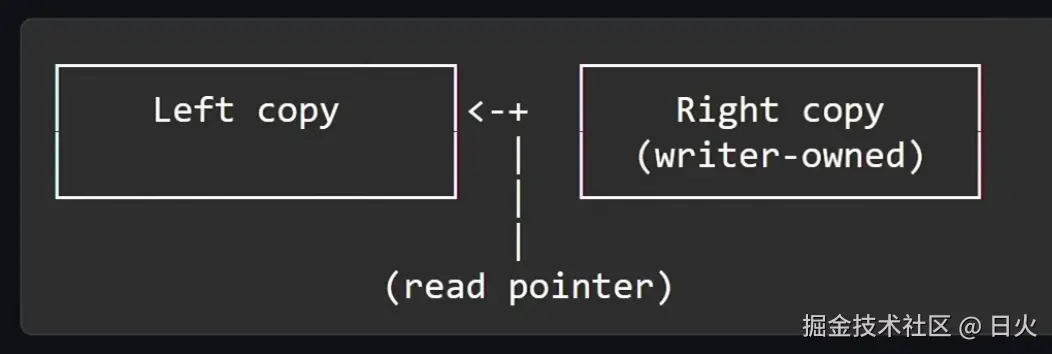
这是一种以空间换时间的算法。
它维护了两个完全一样的对象副本(Left copy和Right copy)、一个原子指针,以及为每个读线程分配的独占缓存行的计数器。
当进行读操作时,无需加锁也无需等待,它只需:
- 判断原子指针
read_pointer指向的副本,假如被指向的副本是Left copy - 在自己的专属计数器上自增
- 直接去读Left copy中的数据
在进行写操作时,有以下步骤:
- 假如当前
read_pointer指针指向Left copy,那么写者就会悄悄修改Right copy - 当Right copy里的数据被改完后,中间的指针将会从左且到右
- 此时新来的读者会读取Right copy
- 而旧的读者仍旧会读取Left copy
- 此时指针会遍历读者的计数器,等待Left copy中的读者清空
- 计数器的值变成了偶数,说明不在临界区里(进出临界区计数器都会自增)
- 计数器的值比指针切换前增加了,说明它已经去读Right copy里的内容了
- 当Left copy里的写者被清空后,写者就会进入,把两个副本的数据统一
在这个过程中,Right copy和Left copy并没有指定谁是永远读、永远写的,它们承载的读写功能是根据程序具体的运行情况灵活改变的。
而指针指向哪一边,读者就会去读哪个副本的内容。
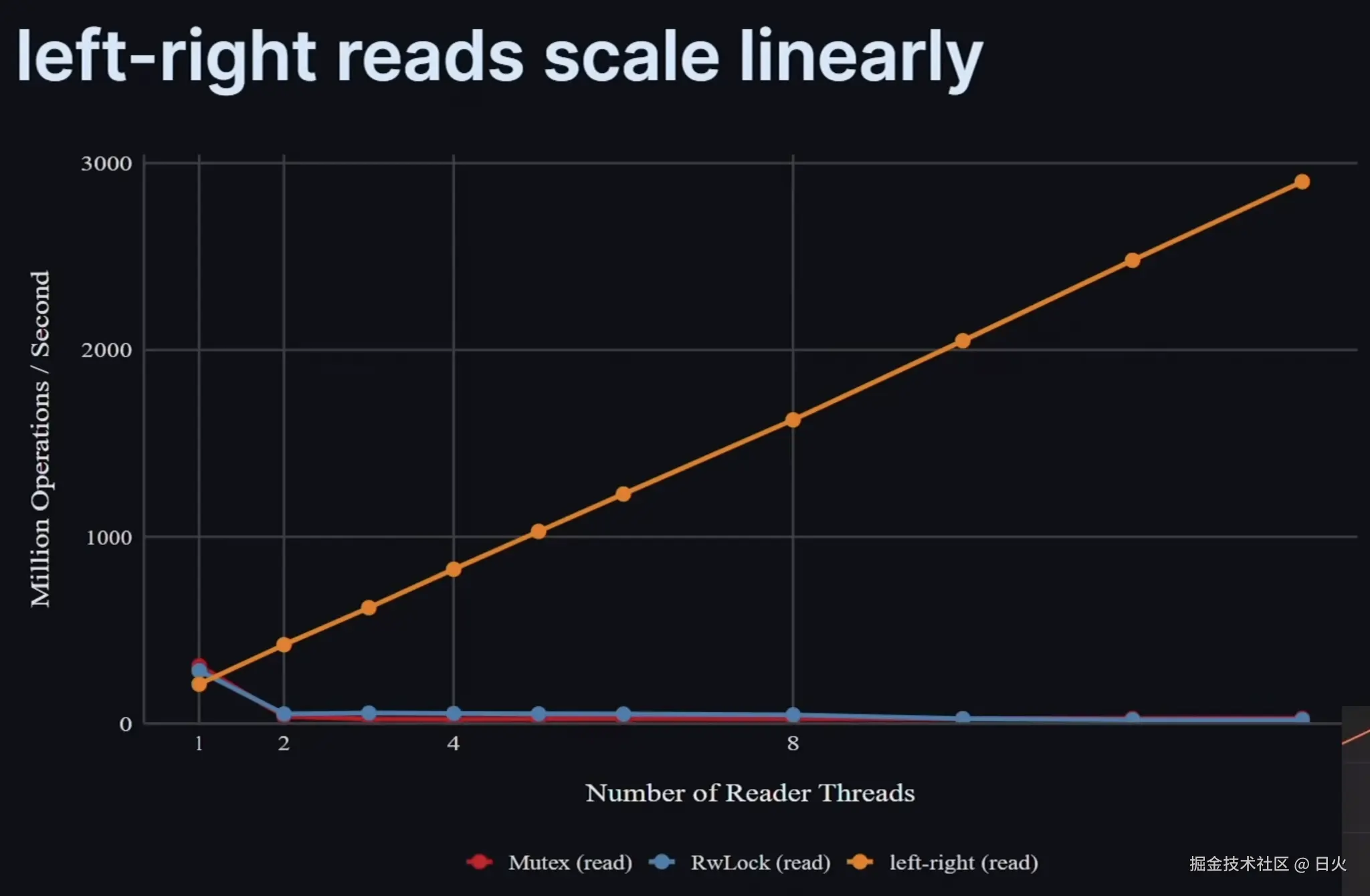
(图来自Jon Gjengset的视频)
由于每个读者都独占属于自己的计数器、不共享缓存行,所以可以避免上面的消耗,让读性能随着线程数的增加呈线型增长。
无处不在的伪共享
当Jon Gjengset对Left-Right架构进行基准测试时,遇到了一个问题。
理想情况应该是随着核心数增加,读性能也呈线性增长;然而当核心数量增加到4时,性能却断崖式下滑了将近10倍,这并不符合预期。
在排除了NUMA(非统一内存访问)或跨CPU插槽的问题之后,Jon Gjengset发现是伪共享的问题。
因为在原来的程序中,多个读者的内置计数器被分配在了同一个缓存行中,所以只要一个读者线程去对它的计数器进行写入,在同一个缓存行的其他计数器也会进入无效状态。
这又触及到了上面的跨核心传输的消耗问题。
解决方法也很简单,强制对齐填充缓存行即可------最终让每个读者的计数器都能够独占一条缓存行。
Rust
// 来自Jon Gjengset
#[repr(align(64))]
structPaddedEpoch(AtomicUsize);无锁不等于无竞争,让数据在不同CPU之间转移也是开销很大的操作。而很多的开销,并不是一些性能分析软件能够代替人来进行判断的。
Left-Right的代价
同样地,Left-Right算法也有它的局限性。
首先,它的空间开销会翻倍,毕竟为数据准备了左右两个副本。
其次就是,当遇到花费时间很长的读者时,写者可能会因迟迟等待它退出而被"卡死",无法写入数据。
不过这并不会影响数据的安全性;只是写者会一直陷入等待中,等待这个读者写好以至于无法处理后续的任何写请求,导致写入量为0。
同时,这个结构只有在写操作数量较少的情况下才起效;否则,由于在这其中写者承担了更多额外工作,效果并不会比互斥锁更好甚至会更差。
接着,由于先写完再转移读指针,读者也难免会读到过时的旧数据。
虽然也可以提供一种同步等待的机制,在旧读者完全转移到新副本之前不要返回写操作,然而这样又不可避免会给写操作带来额外的成本。
然后,它还只支持单写者。一旦有多个并发写者,为了保证数据的安全性,又得在写者之上使用互斥锁,这样子又偏离了原本追求极致并发的初衷。
最后,写入左右副本的数据还必须具有确定性。因为在同步左右副本的数据时具有一定时间差,如果在这个过程中数据进行了意料之外的变动的话,也会导致错误。
当然,这其中可能还会有许许多多的没有提到的问题,也许有些程序需要很严格的线性一致性,而Left-Right只能提供最终一致性;也许有些业务无法容忍读到旧数据,有些可以;等等。
权衡
实际上并没有一种并发原语是万能的,一切选择都需要与业务对齐、顺应底层。
这有几个关键问题:
- 读写操作比例是多少?这往往会决定采用哪种并发算法。
- 临界区是长还是短?这关系到锁开销在其中的占比。
- 程序涉及的线程数是多少?线程过少讨论这些没有意义。
- 能容忍最终一致而非线形一致吗?需要确定什么才是不可容忍的。
- 能容忍可能会读到旧数据吗?至少Left-Right有读到旧数据的可能。
最终还是看程序的核心需求是什么。
总结
这篇文章通过一个测试引入,指出在让并发变慢的不是锁本身,而跨核心的缓存一致性协调才是造成消耗的元凶。
由于它的存在,即使是为多读少写设计的RWLock在多线程并发下的表现也不尽如人意。
同时,介绍了适合多读少写的Left-Right数据结构,以及它的优劣。
最后指出,不论如何,还是要根据具体的业务需求和底层硬件来选择并发策略。适合的才是最好的。