目录
[1.安装 NVIDIA 驱动](#1.安装 NVIDIA 驱动)
[2.安装 Visual Studio Build Tools 2022](#2.安装 Visual Studio Build Tools 2022)
[4.创建 Conda 环境](#4.创建 Conda 环境)
[6.安装 Triton 3.1.0](#6.安装 Triton 3.1.0)
[7.编译安装 causal-conv1d 1.4.0](#7.编译安装 causal-conv1d 1.4.0)
[8.编译安装 mamba-ssm 2.2.2](#8.编译安装 mamba-ssm 2.2.2)
一、前言
最近在 Windows 平台上配置 Vivim、Mamba2、VMamba 等项目时,遇到了 mamba-ssm、causal-conv1d 和 triton 安装问题。原版 mamba-ssm 及相关依赖主要面向 Linux 环境,在Windows 下无法直接通过 pip install 安装。
整理部分文章的 Windows Mamba 安装方案,并结合本人实际配置过程,大幅化简安装流程。本文使用的本地安装包已经整理到 GitHub 仓库,https://github.com/1552186151/mamba2_for_windows,路过的小伙伴麻烦点个小星星 Star:
https://github.com/1552186151/mamba2_for_windows本教程主要安装以下三个核心依赖:
triton 3.1.0
causal-conv1d 1.4.0
mamba-ssm 2.2.2二、安装教程
1.安装 NVIDIA 驱动
先确认显卡驱动正常,打开 cmd 命令行窗口,输入nvidia-smi,如果能看到 GPU 型号、驱动版本、CUDA 支持信息,说明驱动正常。推荐安装 CUDA 12.4,实测 12.1 也不影响后续安装,若目前已安装先忽略 CUDA 版本。
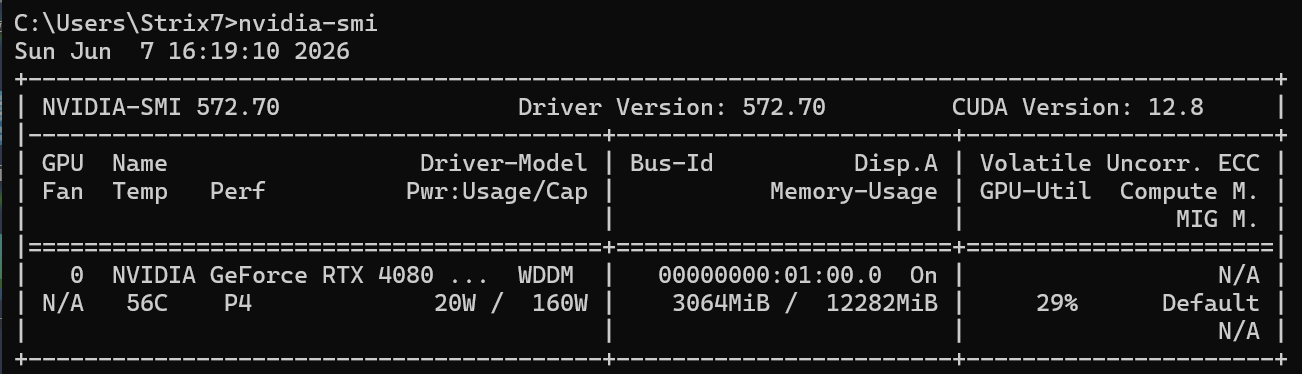
CUDA 下载链接:CUDA Toolkit Archive | NVIDIA Developer
详细安装教程移步到本人另篇博客:【2023最新方案】安装CUDA,cuDNN,Pytorch GPU版并解决torch.cuda.is_available()返回false等问题_torch cuda-CSDN博客
2.安装 Visual Studio Build Tools 2022
Windows 编译 mamba-ssm 和 causal-conv1d 需要 MSVC 编译器。
Visual Studio Installer 下载链接:https://aka.ms/vs/17/release/vs_BuildTools.exe
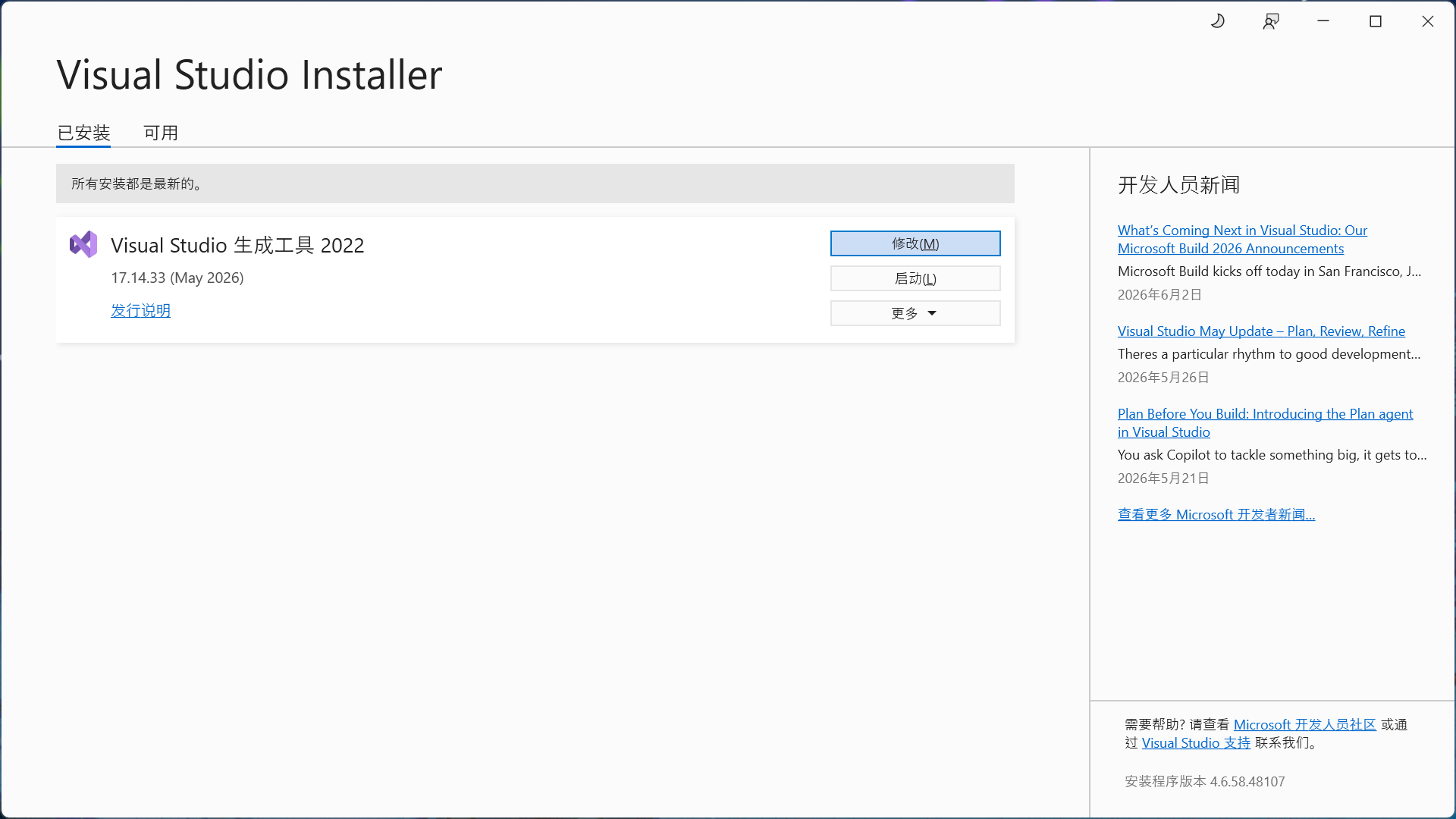
安装完成后,打开 Visual Studio Installer 。如果界面中已经显示 Visual Studio 生成工具 2022 ,说明 Build Tools 已安装成功。点击右侧的 "修改(M)" 按钮,切换到 "单个组件" 页面。
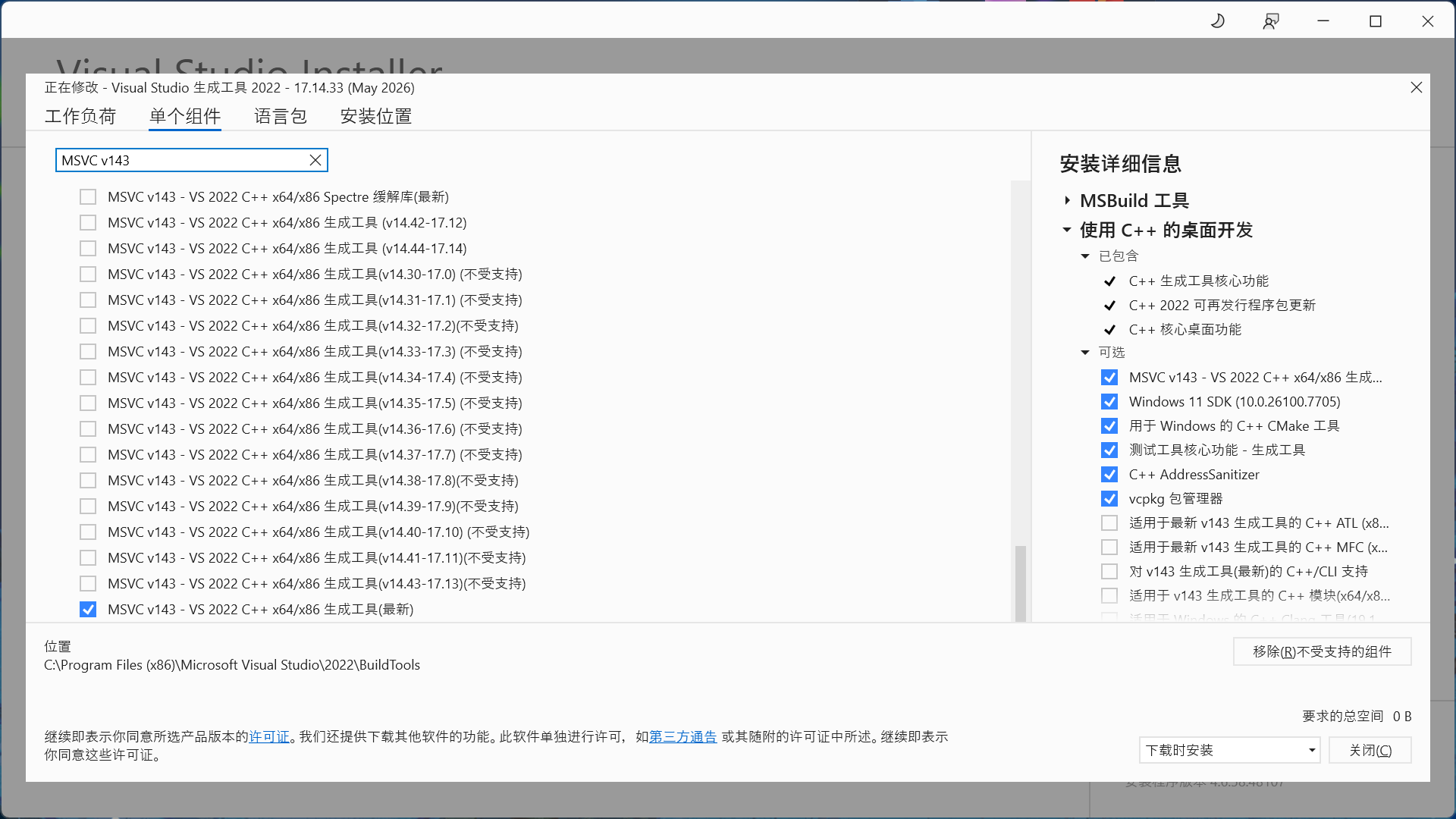
搜索 MSVC v143 并勾选以下组件 MSVC v143 - VS 2022 C++ x64/x86 生成工具
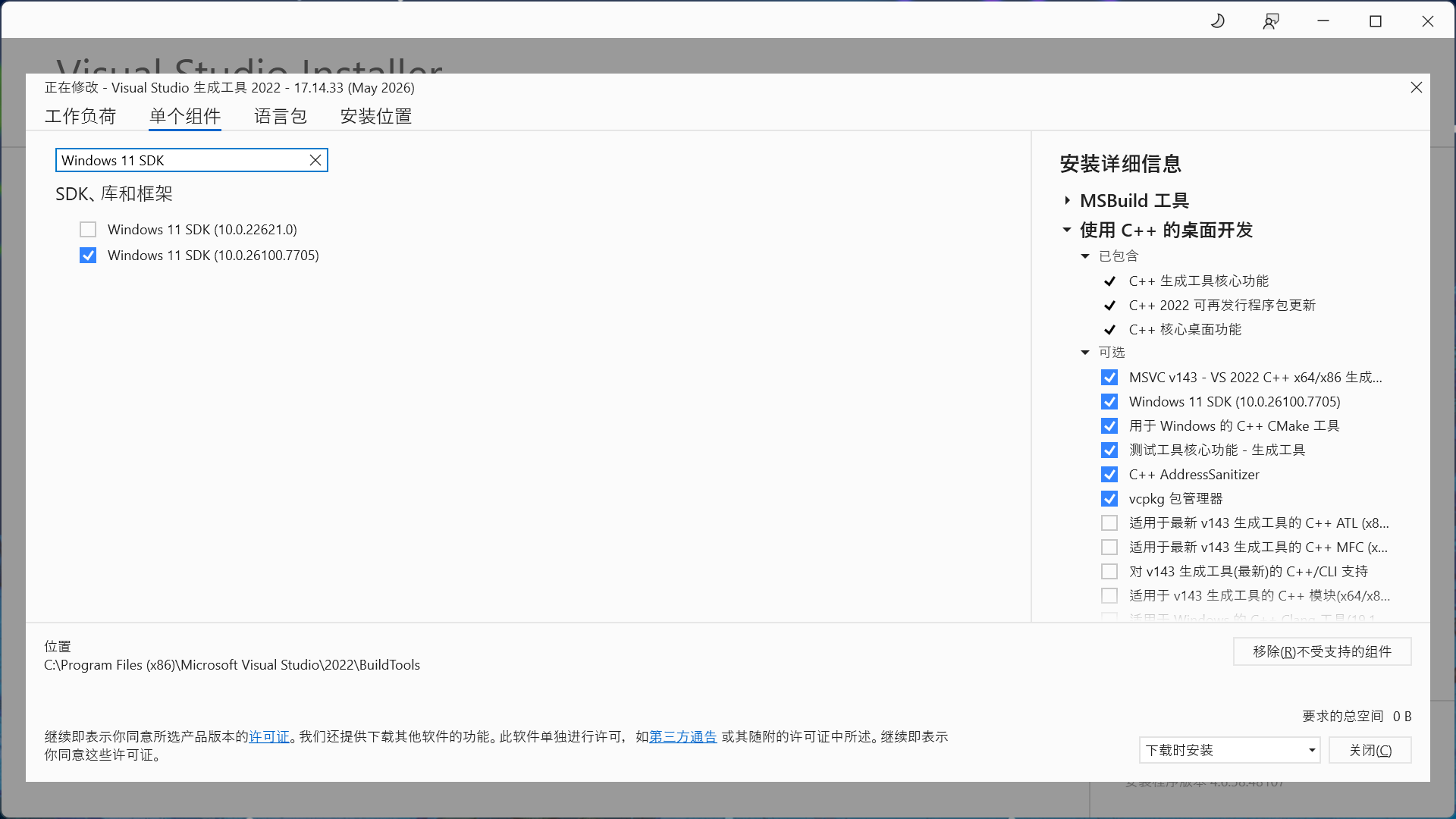
搜索 Windows 11 SDK / Windows 10 SDK 选择版本号较大的 SDK 即可。
建议至少勾选以下组件:
MSVC v143 - VS 2022 C++ x64/x86 build tools
Windows 10 SDK 或 Windows 11 SDK
C++ CMake tools for Windows
MSBuild tools
勾选完成后点击右下角的 "修改" 或 "下载时安装",等待安装完成。
3.添加环境变量
右键 此电脑 → 属性 → 高级系统设置 → 环境变量 ,在 系统变量 中修改或新建以下变量。
修改 Path
选择系统变量中的 Path,点击 编辑,新增以下两项:
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.44.35207\bin\Hostx64\x64
C:\Program Files (x86)\Windows Kits\10\bin\10.0.26100.0\x64
新建或修改 LIB如果系统变量中没有 LIB,点击 新建 ;如果已有,则点击 编辑 。添加以下三项:
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.44.35207\lib\x64
C:\Program Files (x86)\Windows Kits\10\Lib\10.0.26100.0\ucrt\x64
C:\Program Files (x86)\Windows Kits\10\Lib\10.0.26100.0\um\x64
新建或修改 INCLUDE如果系统变量中没有 INCLUDE,点击 新建 ;如果已有,则点击 编辑。添加以下六项:
C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\14.44.35207\include
C:\Program Files (x86)\Windows Kits\10\Include\10.0.26100.0\ucrt
C:\Program Files (x86)\Windows Kits\10\Include\10.0.26100.0\um
C:\Program Files (x86)\Windows Kits\10\Include\10.0.26100.0\winrt
C:\Program Files (x86)\Windows Kits\10\Include\10.0.26100.0\cppwinrt
C:\Program Files (x86)\Windows Kits\10\Include\10.0.26100.0\shared
上面的路径中有两个版本号 14.44.35207 和 10.0.26100.0
!!! 注意版本号要按本机实际情况修改 !!!
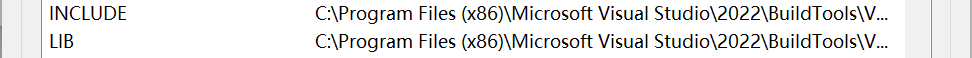
关闭当前终端,重新打开 cmd 命令行窗口,输入 where cl 和 where nvcc,用来分别确认 MSVC 编译器是否可用, CUDA 编译器是否可用。

4.创建 Conda 环境
建议新建一个独立环境,不要直接安装到已有项目环境中。
conda create -n mamba2 python=3.10 -y
conda activate mamba2升级 pip:
python -m pip install --upgrade pip安装 PyTorch 2.4.1 + cu124:
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124安装 CUDA 编译相关包:
conda install nvidia/label/cuda-12.4.0::cuda-nvcc -y
conda install nvidia/label/cuda-12.4.0::cuda-cccl -y安装基础编译依赖:
pip install ninja
pip install setuptools==68.2.2
pip install wheel
pip install einops transformers packaging检查 PyTorch 和 CUDA:
python -c "import torch; print(torch.__version__); print(torch.version.cuda); print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"
nvcc --version正常情况下应看到类似:
2.4.1+cu124
12.4
True
NVIDIA GeForce RTX ...本人实测 torch 2.5.1+cu121 也能正常安装,所以若已安装pytorch先不管版本问题。

5.下载安装包
进入项目目录,例如:
cd "D:\PycharmProjects\DeepLearning"克隆本仓库:
git clone https://github.com/1552186151/mamba2_for_windows.git
cd "D:\PycharmProjects\DeepLearning\mamba2_for_windows" 6.安装 Triton 3.1.0
Windows 下不能直接安装 Linux 版 Triton,需要安装仓库中提供的 Windows wheel:
pip install .\triton-3.1.0\triton-3.1.0-cp310-cp310-win_amd64.whl验证 Triton:
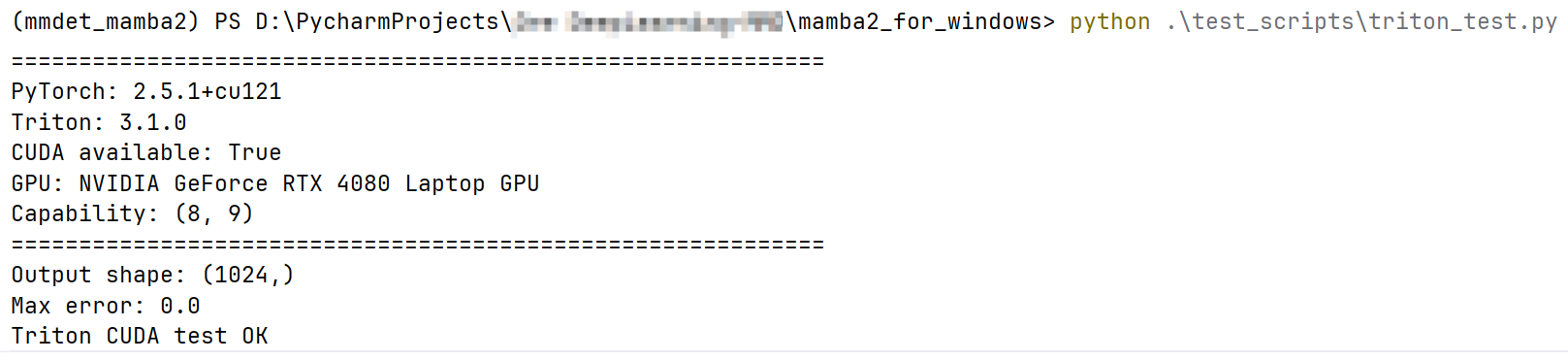
python .\test_scripts\triton_test.py如果安装正常,会输出 PyTorch、Triton、CUDA、GPU 信息
如果之前误装过其他版本 Triton,可以先卸载:
pip uninstall -y triton然后重新安装本地 wheel。
7.编译安装 causal-conv1d 1.4.0
进入 causal-conv1d 1.4.0 目录:
cd causal-conv1d-1.4.0设置强制本地编译:
set CAUSAL_CONV1D_FORCE_BUILD=TRUE建议设置单线程编译,降低 Windows 下编译失败概率:
set MAX_JOBS=1以下两条指令根据实际情况输入,第一次安装可以先不加
如果是 RTX 4090,建议只编译当前显卡架构:
set TORCH_CUDA_ARCH_LIST=8.9|-------------------------------|------|
| 显卡系列 | 建议值 |
| GTX 1050 / 1060 / 1070 / 1080 | 6.1 |
| RTX 20 系列 | 7.5 |
| RTX 30 系列 | 8.6 |
| RTX 40 系列 | 8.9 |
| RTX 50 系列 | 12.0 |如果编译时出现 MSVC 堆空间不足,可以加入:
set CL=/Zm1000 /bigobj

开始安装:
python setup.py install安装完成后检查:
pip show causal-conv1d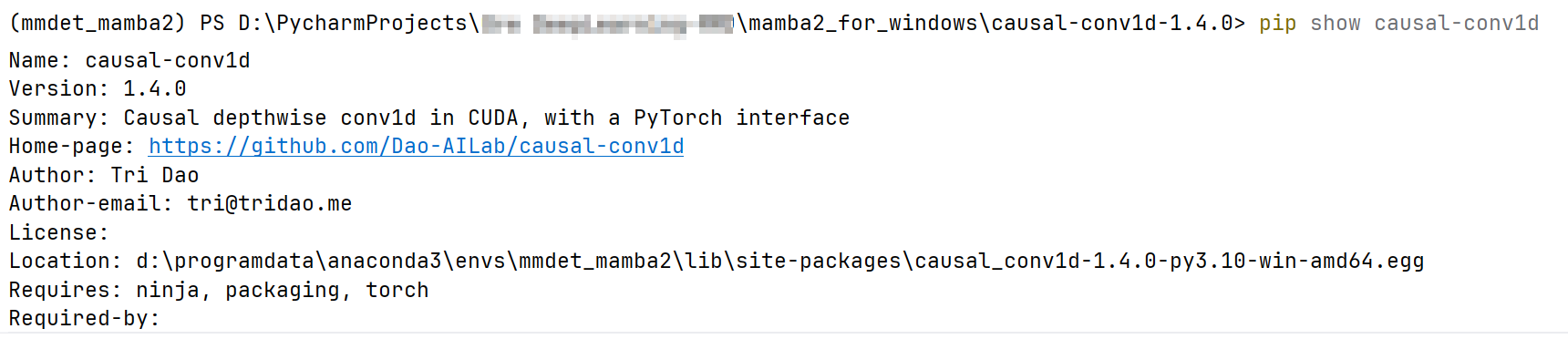
8.编译安装 mamba-ssm 2.2.2
进入 mamba-ssm 2.2.2 目录:
cd mamba-2.2.2设置强制本地编译:
set MAMBA_FORCE_BUILD=TRUE继续设置编译参数:
set MAX_JOBS=1以下两条指令根据实际情况输入,第一次安装可以先不加
set TORCH_CUDA_ARCH_LIST=8.9
set CL=/Zm1000 /bigobj
开始安装:
python setup.py install安装完成后检查:
pip show mamba-ssm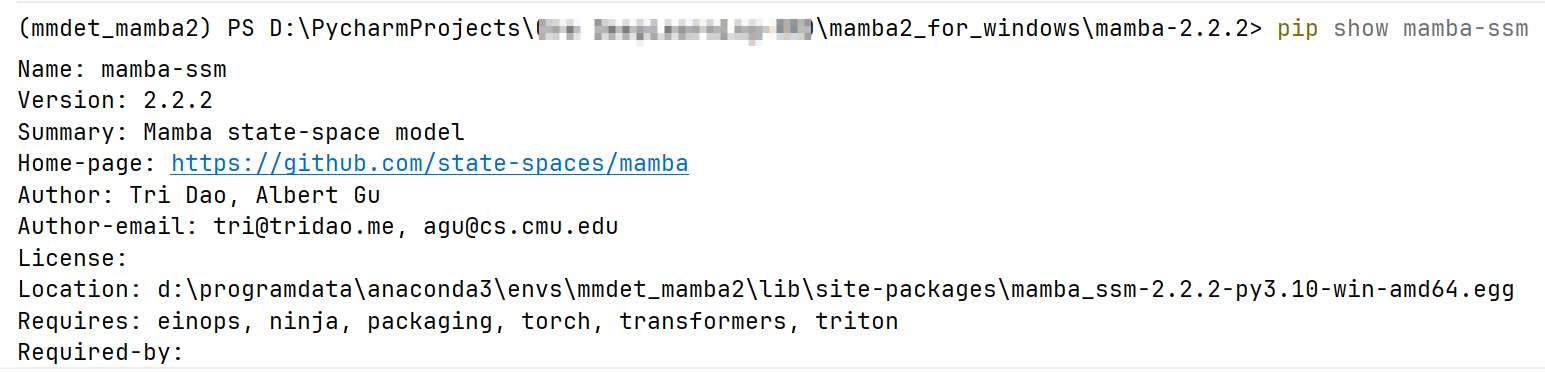
9.最终验证
回到仓库根目录,运行 Mamba 测试脚本:
python .\test_scripts\mamba_test.py如果默认测试输出类似下图,说明基础安装环境已经可以被 Python 正常识别。

三、常见问题
1.causal_conv1d_bwd.fatbin.c(4698700): fatal error C1060: 编译器的堆空间不足 RuntimeError: Error compiling objects for extension
该问题是因为 MSVC 编译 CUDA 扩展时内存压力过大。原始 setup.py 中会同时编译多个 CUDA 架构,例如:
python
cc_flag.append("-gencode")
cc_flag.append("arch=compute_53,code=sm_53")
cc_flag.append("-gencode")
cc_flag.append("arch=compute_60,code=sm_60")
cc_flag.append("-gencode")
cc_flag.append("arch=compute_62,code=sm_62")
cc_flag.append("-gencode")
cc_flag.append("arch=compute_70,code=sm_70")
cc_flag.append("-gencode")
cc_flag.append("arch=compute_72,code=sm_72")
cc_flag.append("-gencode")
cc_flag.append("arch=compute_80,code=sm_80")
cc_flag.append("-gencode")
cc_flag.append("arch=compute_87,code=sm_87")
if bare_metal_version >= Version("11.8"):
cc_flag.append("-gencode")
cc_flag.append("arch=compute_90,code=sm_90")这样会同时生成多个架构的 CUDA 编译目标,导致中间文件过大,尤其在 Windows + MSVC 环境下容易触发编译器的堆空间不足问题。
对此解决方式是在 setup.py 中新增了 add_single_cuda_arch 函数,用于自动检测当前显卡的 CUDA 计算能力,只编译当前 GPU 对应的架构,从而显著降低编译压力。修改后的代码会优先通过 PyTorch 获取当前显卡名称和 compute capability,例如 RTX 4090 会自动识别为 sm_89