并发容器实现原理
-
- 1、CopyOnWriteArrayList实现原理
- 2、ConcurrentHashMap实现原理
-
- 2.1、HashTable设计原理
- [2.2、ConcurrentHashMap 1.7设计原理](#2.2、ConcurrentHashMap 1.7设计原理)
- [2.3、ConcurrentHashMap 1.8设计原理](#2.3、ConcurrentHashMap 1.8设计原理)
- 2.4、源码分析
- 3、ConcurrentSkipListMap实现原理
- 4、LinkedBlockingQueue实现原理
- 5、ArrayBlockingQueue实现原理
- 6、SynchronousQueue实现原理
- 7、LinkedBlockingDeque实现原理
1、CopyOnWriteArrayList实现原理
ArrayList是实际开发中高频使用的集合类,但不是线程安全的。JDK1.5提供了线程安全的数组:CopyOnWriteArrayList。CopyOnWriteArrayList采用了一种读写分离的并发策略。CopyOnWriteArrayList对读操作采用的是无锁设计,性能非常好。对于写操作,CopyOnWriteArrayList会将当前数组复制一份,然后在新副本上执行写操作,写结束之后会将数组指针指向新的数组。基于上述特征,CopyOnWriteArrayList适合在高频读操作、低频写操作的场景里使用。
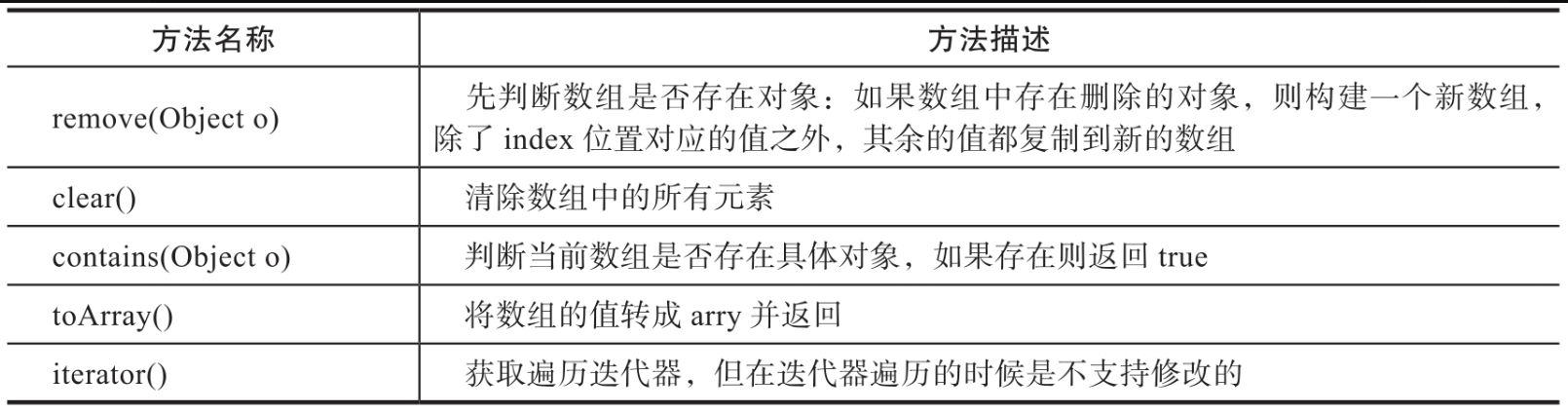
CopyOnWriteArrayList提供了线程安全的数组读取与修改方法,如表所示。

在使用CopyOnWriteArrayList的iterator迭代器的时候需要注意,CopyOnWriteArrayList的迭代器只能进行数据读取,不能进行数据修改。在CopyOnWriteArrayList迭代器中,调用数据修改的方法会抛出UnsupportedOperationException异常。
1.1、设计原理
CopyOnWriteArrayList采用读写分离的并发控制策略,它能支持多线程同时读取数据与单线程修改数据。数据修改采用了独占锁+写时复制+指针重定向的策略组合。Copy-OnWriteArrayList内部定义了一个独占锁。线程只有获取到锁才能修改数据。获取到锁之后,将原来的数组复制一份,然后对副本数据进行修改。在完成数据修改后,将数组指针指向新的数组。CopyOnWriteArrayList设计原理如图所示。
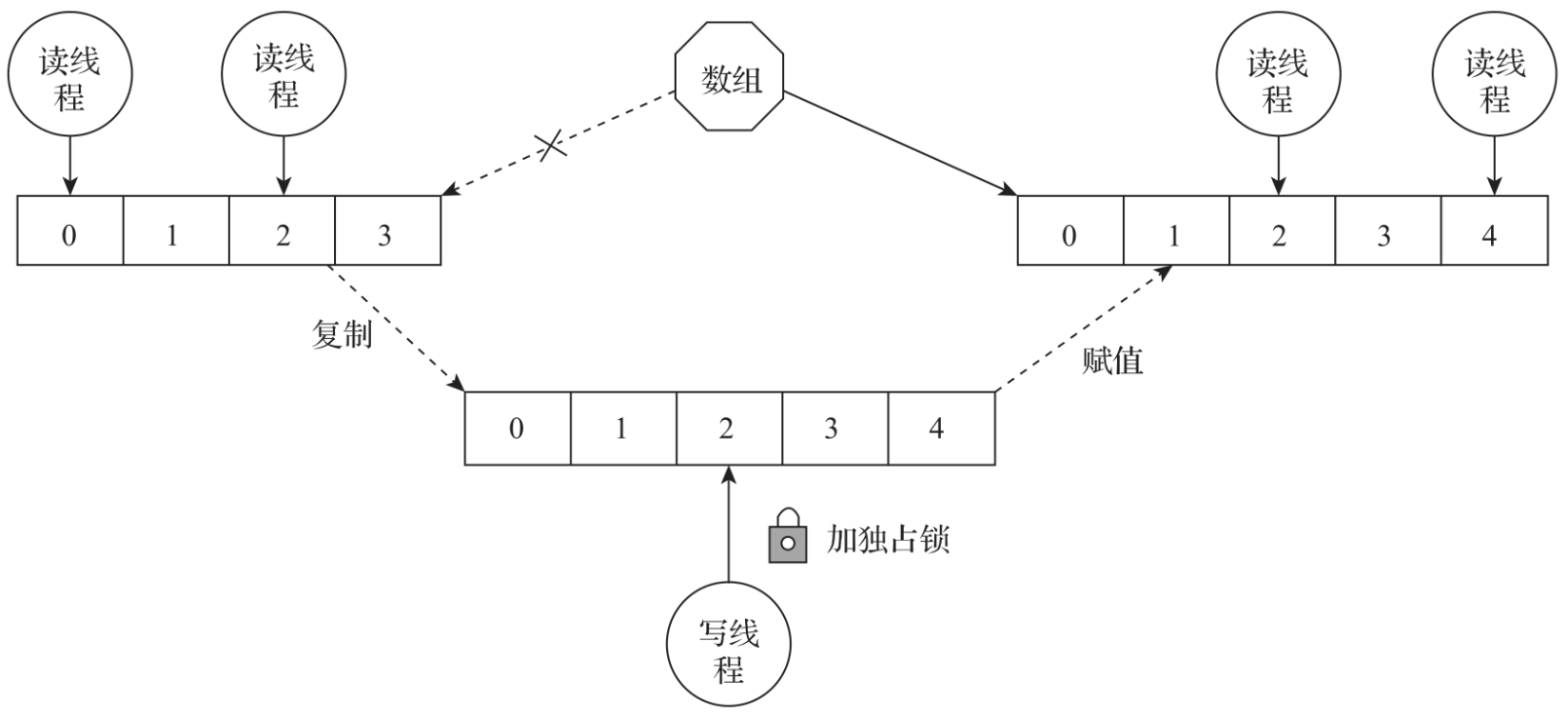
读写分离设计的优点非常明显,在任意时刻,数据的修改都不会影响数据的读取,数据读取的性能非常好。但也有2个缺点:数据修改非常耗费内存与CPU,并且存在数据的实时一致性问题。每次修改数据都会构建一个新的数组,并且会把原来的数据复制过来,会非常耗费内存与CPU的资源。如果在数据非常多的情况下,频繁地对数据进行修改会严重影响系统的性能。由于使用了写时复制技术,因此读线程不能立即读取到新修改的数据。
1.2、源码分析
CopyOnWriteArrayList实现了3个接口:RandomAccess、Cloneable与List。RandomAccess是个标记接口,实现了该接口的子类,支持随机访问。Cloneable也是一个标记接口,实现了这个接口的子类可以支持克隆功能。CopyOnWriteArrayList实现了List接口,支持数据读取、数据修改、数据遍历等功能。CopyOnWriteArrayList的UML图如图所示。
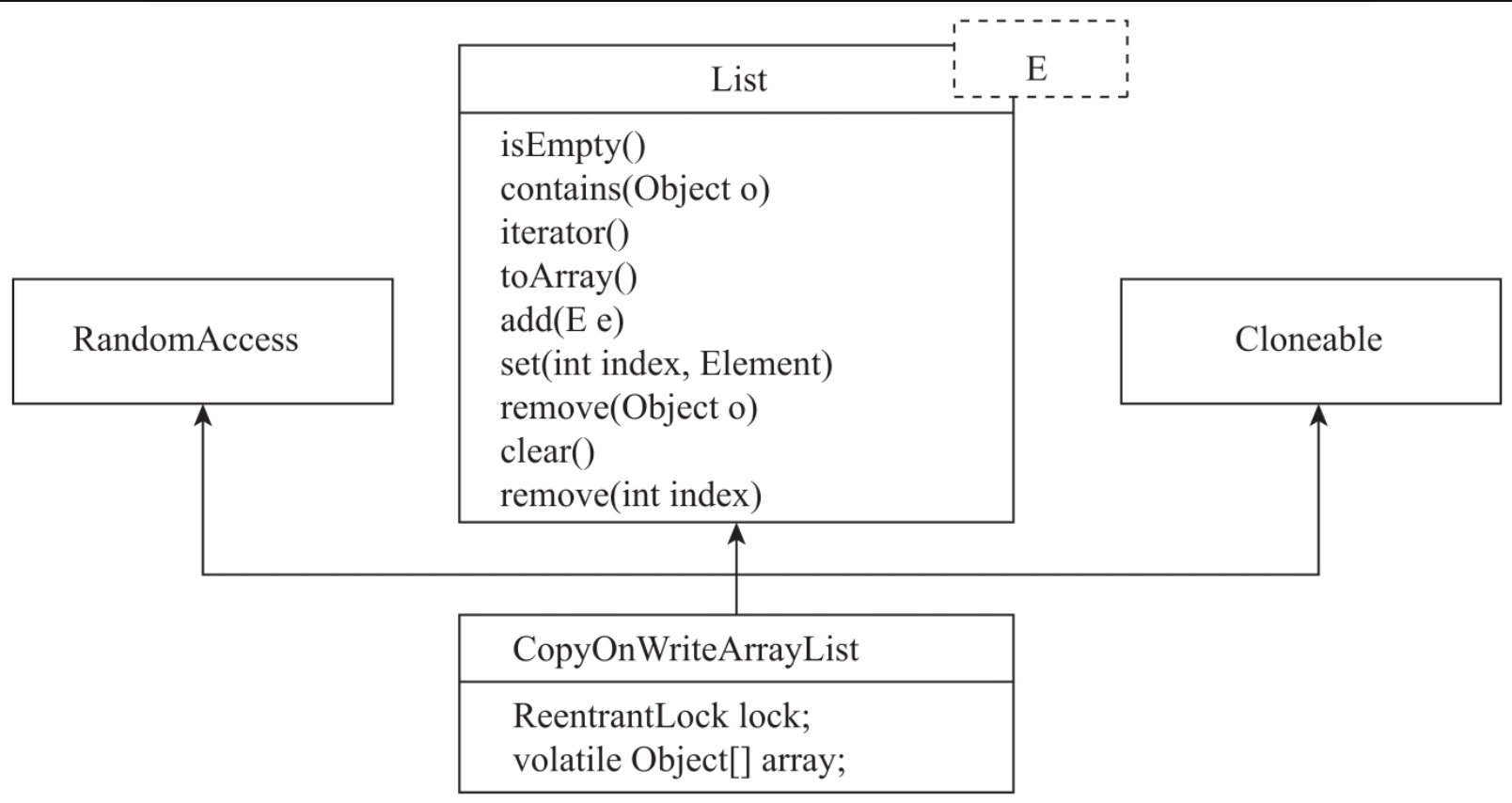
CopyOnWriteArrayList定义了2个属性:一个是Object的实例lock,另一是Object数组array。lock用来实现数据修改的并发控制,array指向对象数组。CopyOnWriteArrayList属性定义如代码所示。

1. 数据读取
CopyOnWriteArrayList数据读取的方法和ArrayList是一样的,都是按照数据的下标从数据中获取数据。数据读取的实现如代码所示。


2. 数据修改
CopyOnWriteArrayList提供了3个方法来实现数据修改,add方法负责往数组中插入元素,remove方法负责从数组中移除数据,clear方法负责清除整个数组。
如代码所示,add方法先通过synchronized对lock进行加锁,然后调用Arrays的copyOf方法复制一个新的数组,最后将数据放入新数组的尾部。在修改完数据后,调用setArray方法将新的数组赋值给array属性字段。

remove方法的功能是删除数组中指定位置的数据,它会构建一个新的数组,然后将除了待删除之外的数据都复制到新数组中。remove方法的实现如代码所示。

clear方法是清空数组。它会通过synchronized对lock对象加锁,然后构建一个空数组,最后将数组指针指向空数组。clear方法的实现如代码所示。

3. 数据迭代器
CopyOnWriteArrayList的内部实现了COWIterator迭代器。COWIterator迭代器只实现了数据遍历读取功能,屏蔽了数据修改的功能,在迭代器中调用数据修改方法会一律抛出UnsupportedOperationException异常,因为这些方法不支持数据遍历修改的功能。
2、ConcurrentHashMap实现原理
在JDK1.7及其以下的版本中,ConcurrentHashMap是采用分治思路设计,由Segments数组+HashEntry数组+链表组合实现。在JDK1.8中,ConcurrentHashMap采用了数组+链表+红黑树的数据结构,通过CAS与synchronized组合模式进行并发控制,从而提高了性能。
2.1、HashTable设计原理
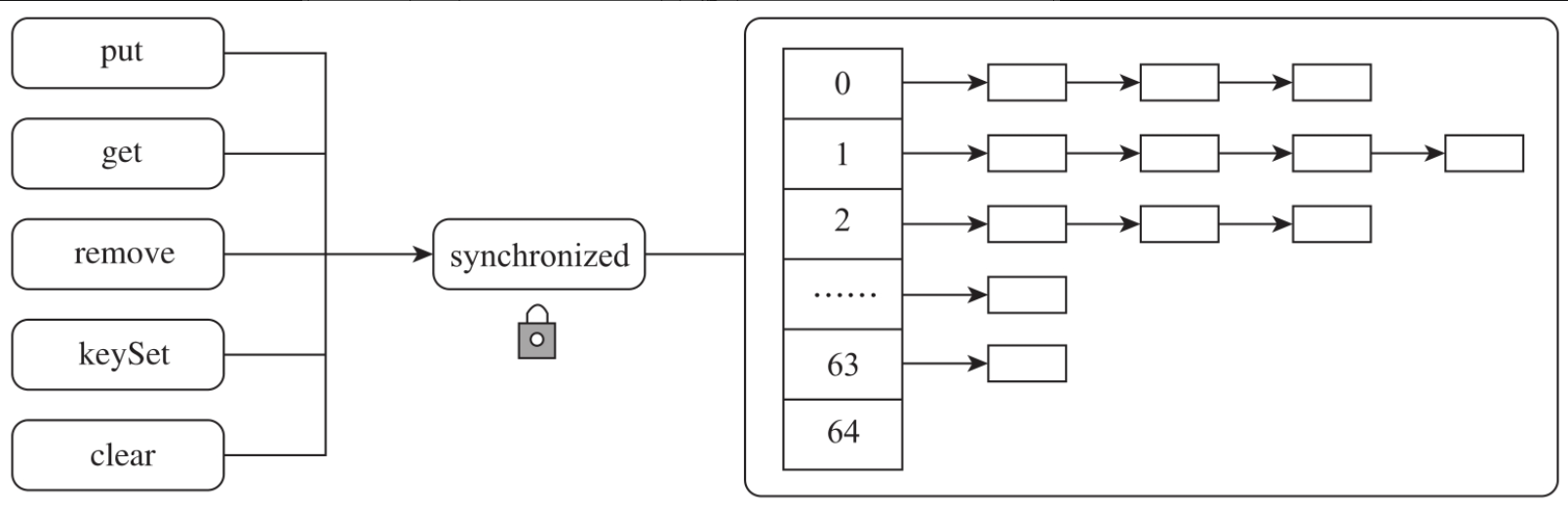
在JDK1.5以前,Java提供的线程安全的Hash容器是HashTable。HashTable的所有public方法都是用synchronized关键字修饰的,采用了Java底层的同步机制来实现线程安全。任意一个时刻都只允许一个线程对HashTable操作,其他线程都会进入阻塞状态,整个HashTable的并发性能非常低,所以在实际开发中,我们很少使用HashTable。HashTable设计原理如图所示。
2.2、ConcurrentHashMap 1.7设计原理
自JDK1.5以后,Java提供了另一种线程安全的Hash容器ConcurrentHashMap,它的性能比HashTable有很大的提高。ConcurrentHashMap经过1.5、1.6、1.7、1.8等多个版本的持续优化,每一次的优化性能都有进一步提升。
在JDK1.7及其以下版本中,ConcurrentHashMap是采用分治思想设计的,即采用两层Hash表的结构。
第一层Hash表是由Segment数组构成的。每个Segment内部采用HashEntry数组与链表构成了两层的Hash表。Segment通过继承ReentrantLock获得了可重入的独占锁能力。整个Hash表由Segment数组构成。Segment数组中的每一个元素就是一个独立的数据段(即Segment)。每个独立数据段的修改都是通过ReentrantLock的锁机制来确保线程的安全性的。在高并发场景下,每次修改只会锁住Segment数组中的某个具体数据段,所以多个数据段可以同时进行修改,互不影响。ConcurrentHashMap的concurrentLevel(默认并发级别)是16。因此理论上,它可以支持16个线程同时对ConcurrentHashMap进行修改,从而极大地提高了并发性能。JDK1.7的设计原理如图所示。
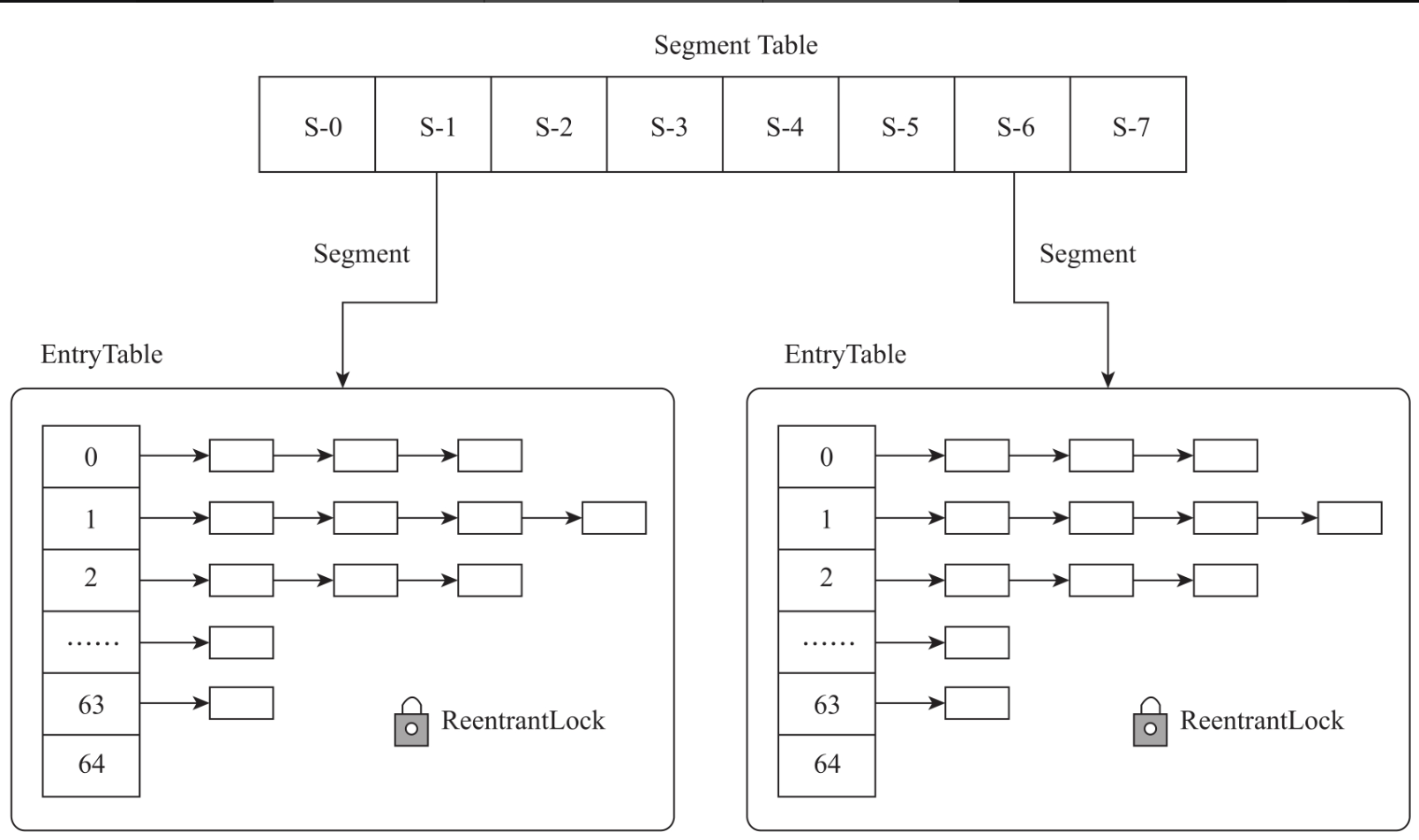
相比HashTable的整个Hash表的一把锁,JDK1.7的ConcurrentHashMap采用多个Segment,每个Segment一把锁,这种分治思想的设计极大地提高了并发性能。但如果Segment里面链表元素过多,每次修改都会非常耗时,会极大地影响并发性能。
2.3、ConcurrentHashMap 1.8设计原理
在JDK1.8中,ConcurrentHashMap对底层做了比较大的改动,整体抛弃了JDK1.7的分段锁的设计方案,采用了数组+链表+红黑树的数据结构。在并发控制方面,ConcurrentHashMap采用了CAS+synchronized的组合方案来实现线程的安全性。ConcurrentHashMap 1.8设计原理如图所示。
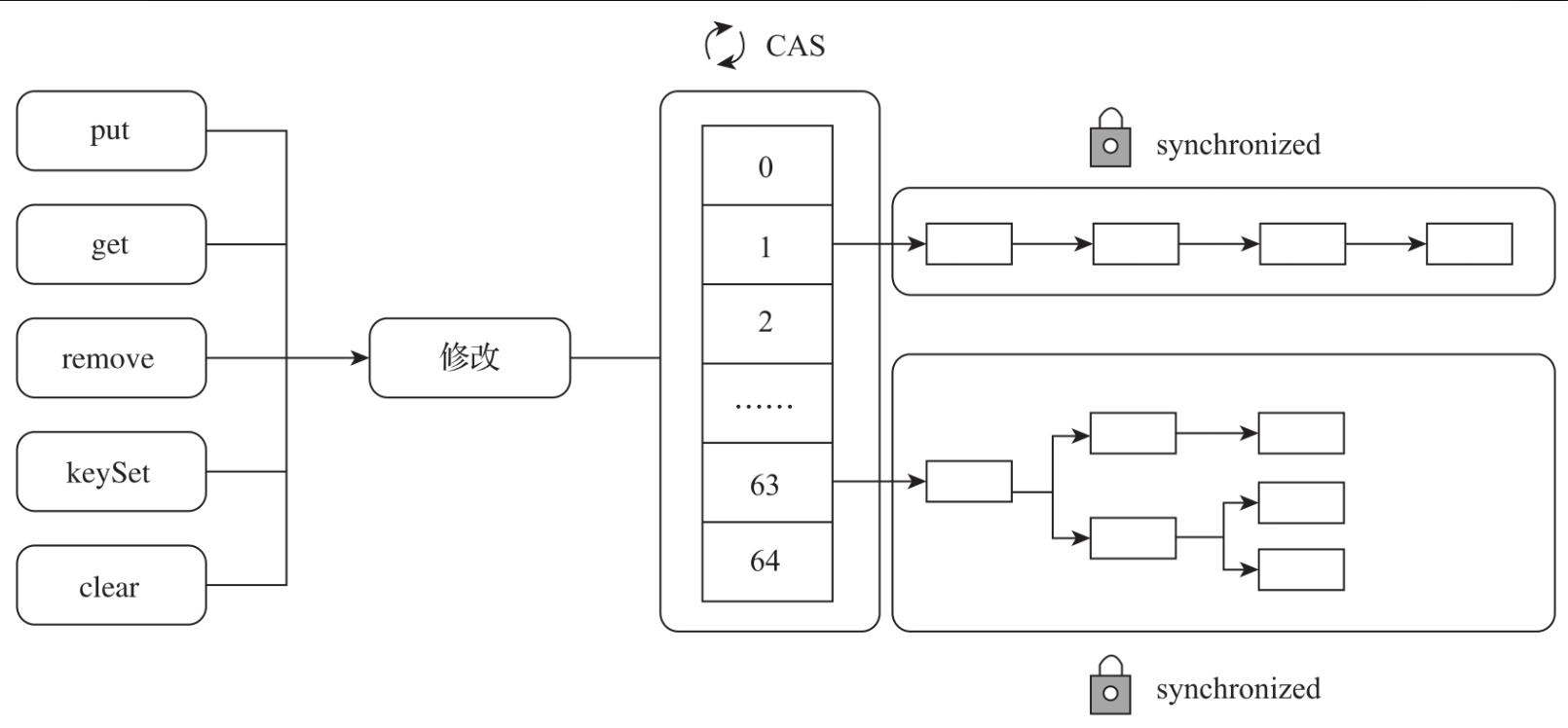
1. 为什么引入红黑树
链表的时间复杂度为O(N),红黑树的时间复杂度为O(logN)。在数据量大的情况,红黑树的检索效率明显高于链表。
2. 为什么抛弃分段锁
每个Segment里都包含一个HashEntry数组,而每一个HashEntry数组需要一段连续的内容空间。在大多情况下,HashEntry数组都是不满的,会造成内存空间的浪费。同时,每个Segment需要维护一个ReentrantLock锁,而ReentrantLock是依赖AQS来实现并发控制的。AQS内部维护了双向指针的排队队列,这也需要占用一定的内存空间。
Segment整个数据结构也比较复杂,在初始化与扩容等功能的实现上的复杂度都非常高。
3. 设计难点解析
下面将详细探讨一下ConcurrentHashMap设计上的难点:数量统计、并发扩容。
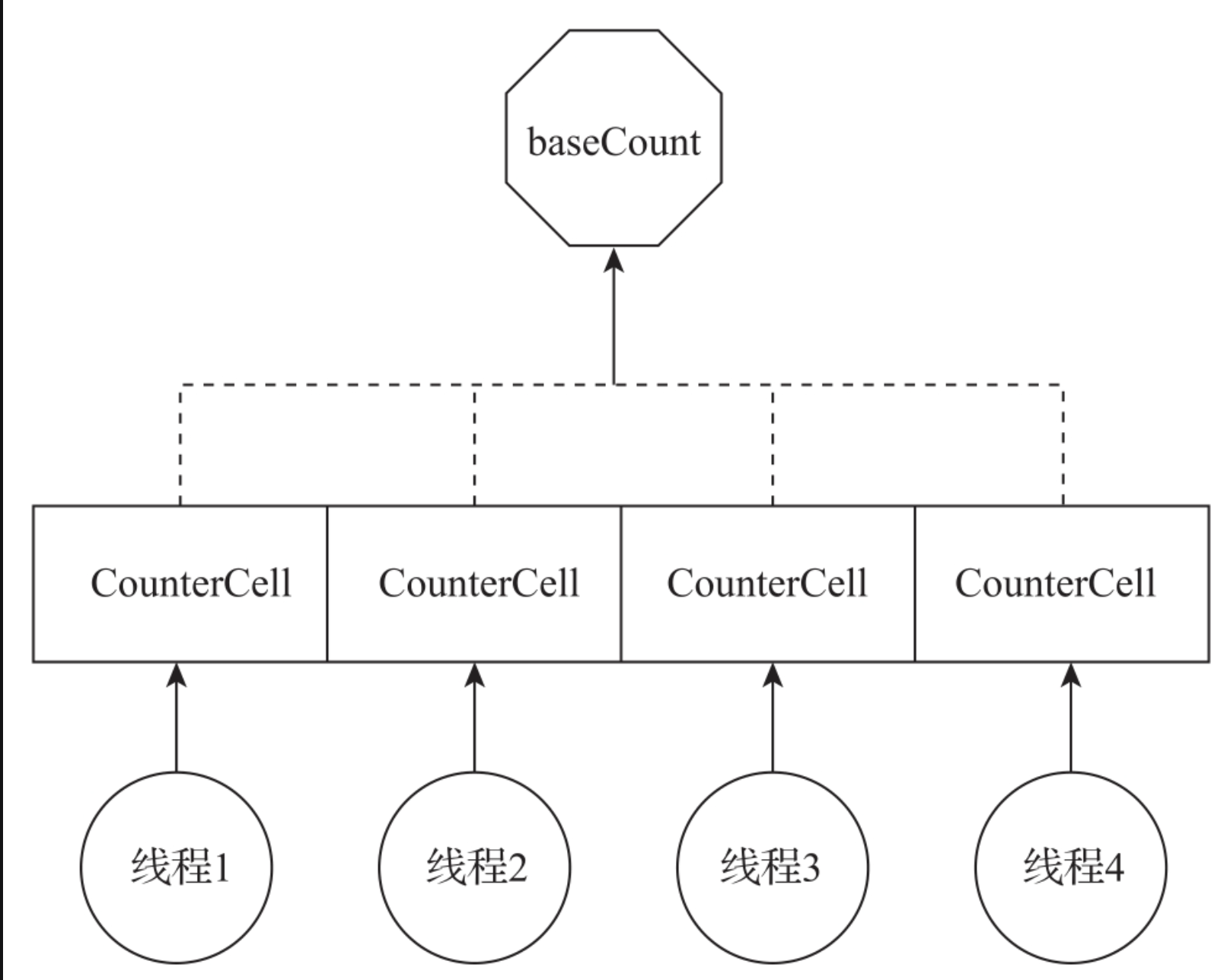
在一个高并发修改的Hash表中,要精准地统计元素个数是一件很困难的事。因为在统计时,数据会被修改。如果想要正确地统计数据,除非先对整个ConcurrentHashMap加全局锁,再进行统计。但如果加上全局锁,那么所有数据的修改都要获取这个锁,那基本上就退化成了HashTable。设计者巧妙地借鉴了LongAdder的设计思想。计数设计包含两部分:基础计数baseCount、计算单元数组counterCells。baseCount是个全局计数器,多线程可以通过CAS方式对baseCount进行修改。如果修改失败了,ConcurrentHashMap就会采用counterCells数组进行计数。counterCells是由CounterCell(计数单元)构成的数组,每个CounterCell(计数单元)都能实现long数据的单独计算。每个线程会根据线程ID对CounterCell数组取模,获取到对应的计算单元,这样每个线程就只会对当前线程对应的CounterCell进行操作。在统计整个ConcurrentHashMap的数量时,将baseCount+counterCells数组求和就可以了。数量统计的设计如图所示。
在一个高并发修改的Hash表中,要实现整体扩容也是一件很困难的事,因为HashMap中的数据时刻在变。ConcurrentHashMap的扩容方案设计得非常巧妙,是将倍数扩容、多线程扩容、数据隧道等技术结合在一起实现的。
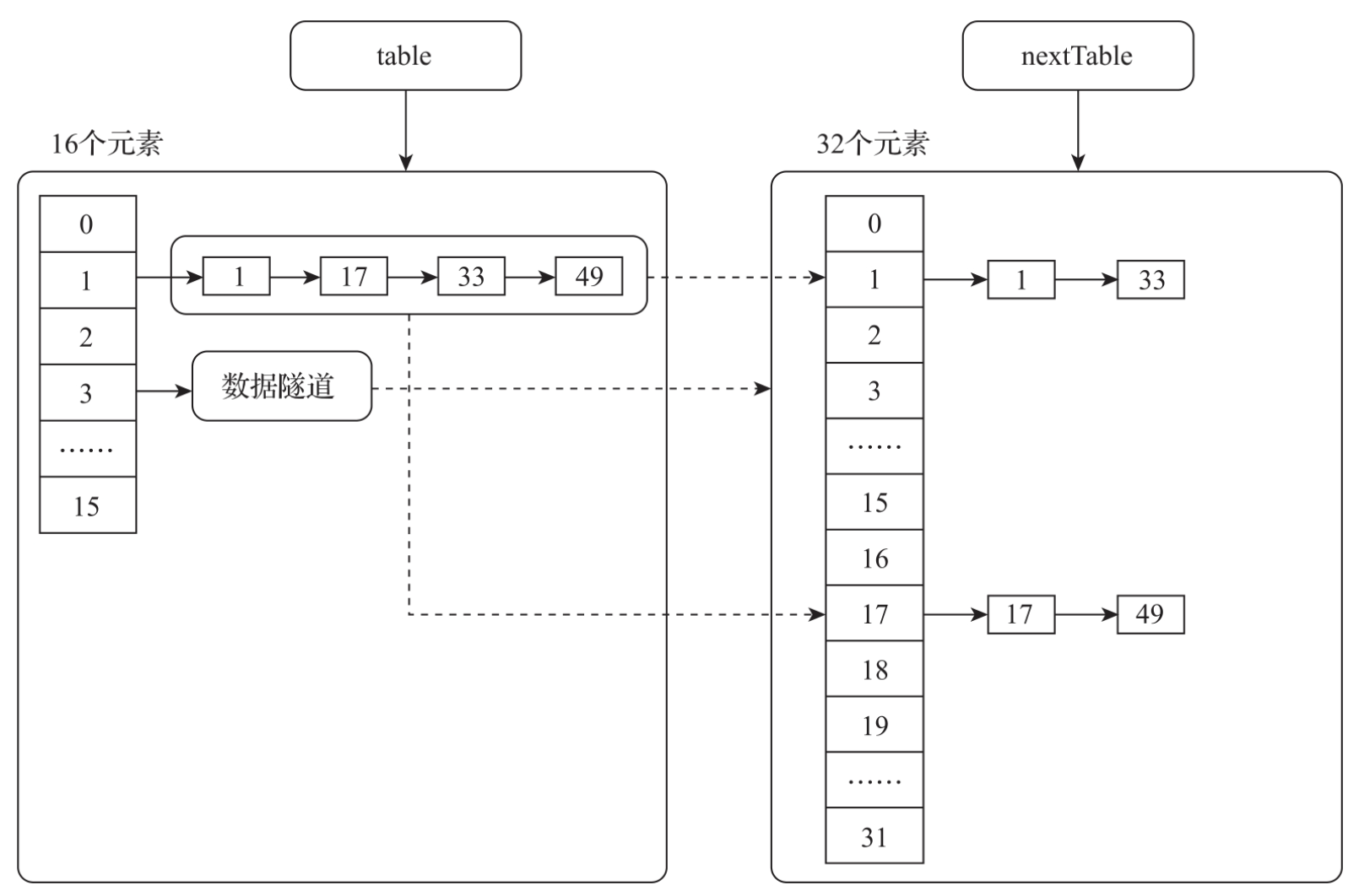
ConcurrentHashMap中定义了两个变量:table指针与nextTable指针,table指向当前使用的数组,nextTable指向扩容的数组。数组的长度是2n(2的n次方),默认的数组长度是16,即24(2的4次方)。扩容机制是倍数扩容,例如table数组的长度为16,扩容的时候,ConcurrentHashMap会构建一个长度为32个nextTable数组。这么设计有一个非常大的好处,table数组中同一个索引上的数据会均匀地迁移到nextTable数组的两个索引限定的位置上。例如,在原来的table数组中,索引为1的链表数据会迁移到nextTable数组中索引为1和17的两个链表中。而nextTable数组中索引1和17位置上的数据只会来自table数组的1号索引位置。扩容的过程如图所示。
在具体扩容的实现上,ConcurrentHashMap采取了多线程协作的方式来进行扩容。每个线程负责stride个table数组元素的数据迁移,stride的最小值是16。迁移是从table数组的尾部开始,逐渐往头部迁移,如图所示。线程T-1开始对ConcurrentHashMap进行扩容,T-1会从table数组的尾部开始迁移,将下标63~48之间的table数组数据迁移到nextTable数组中,并且将迁移的标志transferIndex设置为48。当线程T-2发现table数组正在进行扩容,它也加入进来一起迁移以提升扩容的速度,T-2线程负责将47到32号位置上的数据迁移到nextTable数组中,并且把table数组迁移的标志设置成32。同样,T-3和T-4线程也会依次进行数据迁移。
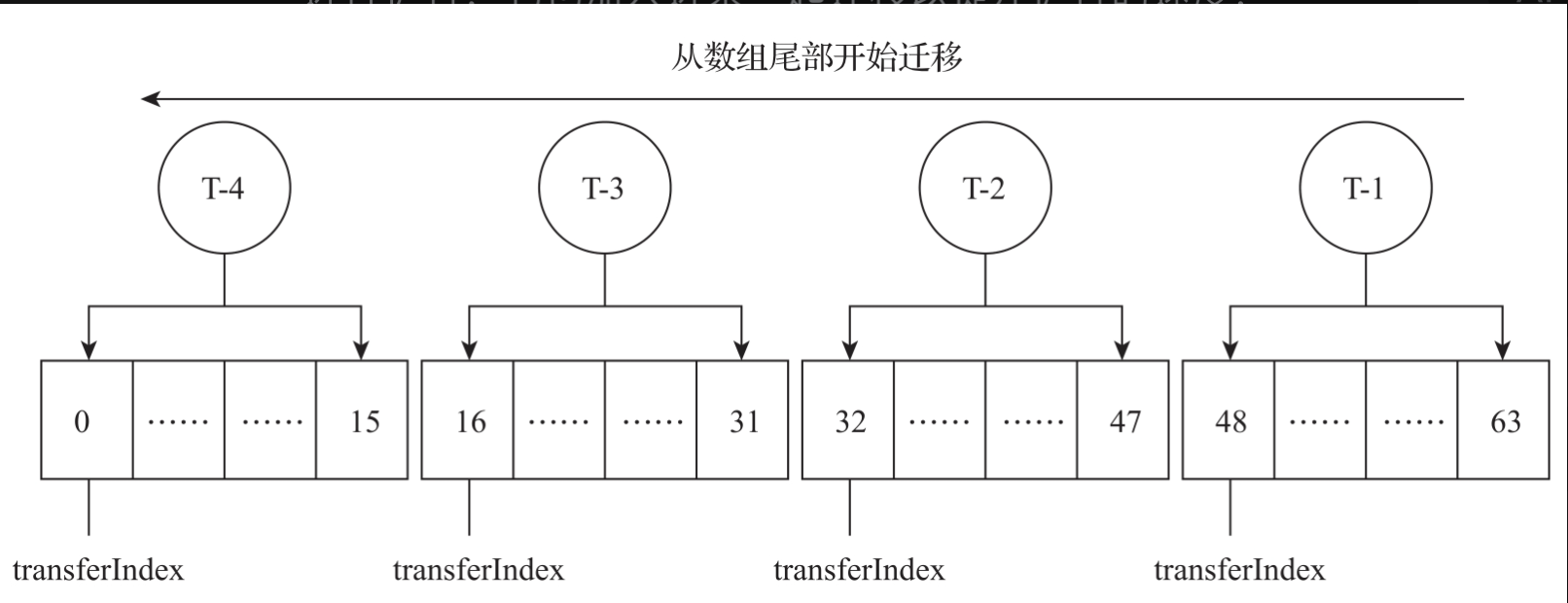
在扩容的期间,table数组中的数据迁移不是同时完成的。例如,位置0和位置1上的数据已经迁移到nextTable中了,而位置2上的数据正在进行迁移。此时,如果有线程访问0和1位置上的元素数据怎么办呢?为了解决这个问题,ConcurrentHashMap引入了数据隧道技术:ForwardingNode,如图所示。在table数组中元素的数据被迁移之后,这个位置会被设置为ForwardingNode。ForwardingNode内部封装了nextTable,在数据访问的时候可以直接访问nextTable中的数据。
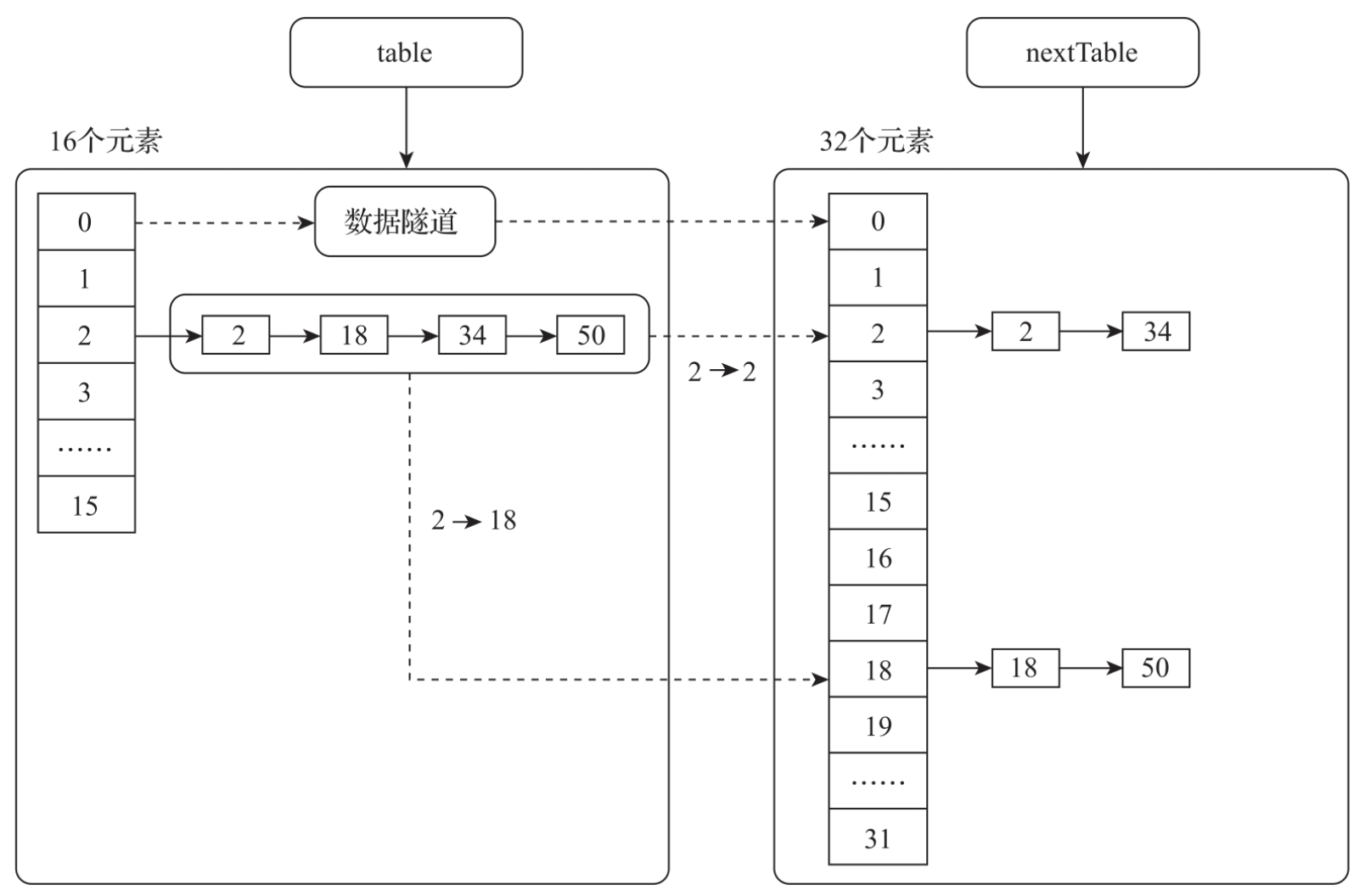
在整个迁移完成之后会将table重新指向nextTable的对应数组,并且将nextTable设置为Null,这样整个扩容就完成了。
2.4、源码分析
ConcurrentHashMap 1.8的UML图如图所示。
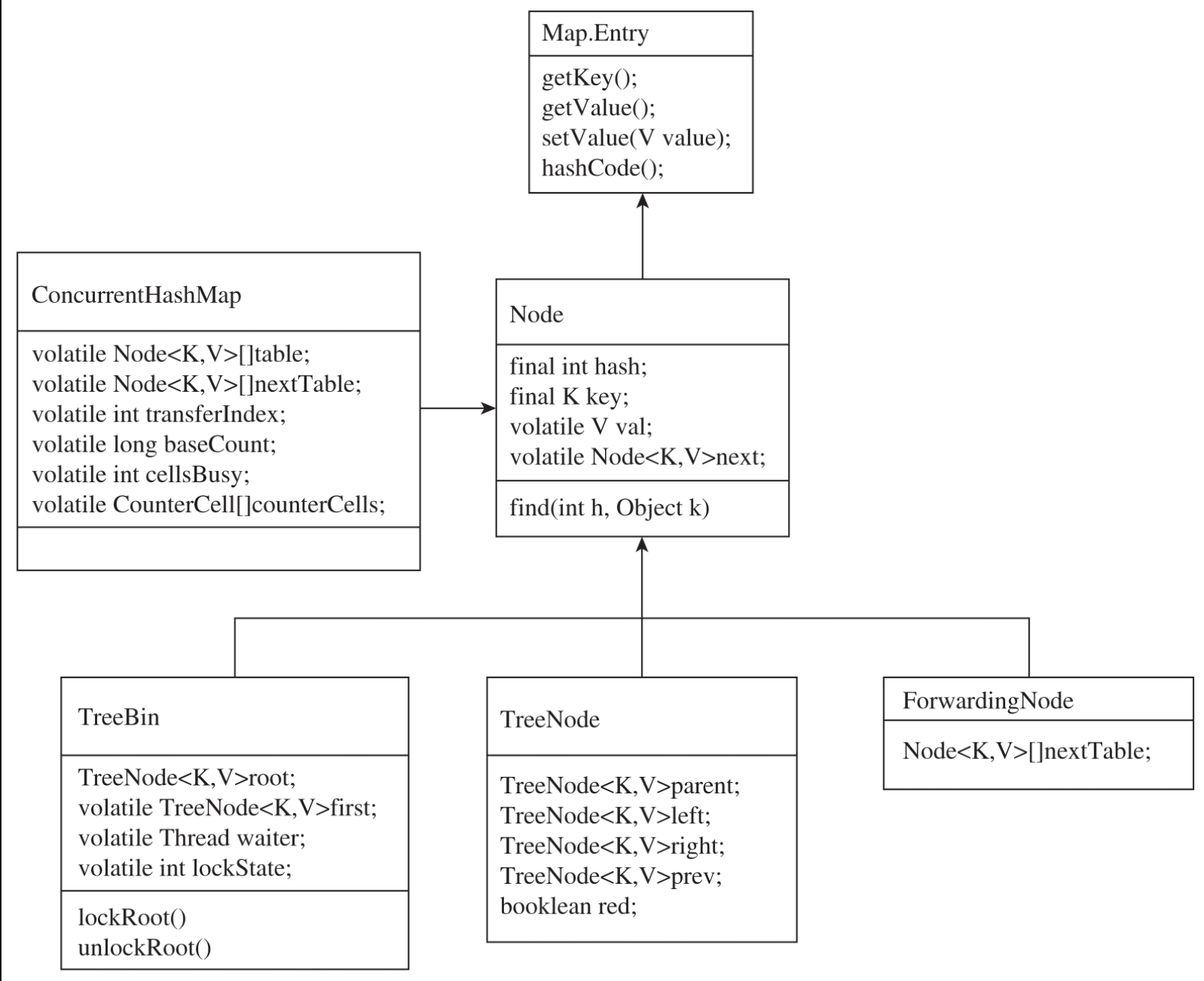
1. 底层数据结构
Node的key是数据的名称,value是数据的值,hash是key对应的Hash值,next指针指向当前节点的后继节点。为了确保线程的安全性,hash与key都是不可变的。为了确保线程的可见性,value与next都是采用volatile关键字修饰。Node实现如代码所示。

TreeNode是红黑树的节点,内部定义了红黑树需要的parent、left、right、prev指针。findTreeNode方法根据key,通过二叉树深度遍历来查找对应的节点。findTreeNode方法会将当前节点Hash值与查找key的Hash值进行比较。如果当前节点Hash值大于要查找的Hash值,findTreeNode方法就从left节点接着向下查找。如果当前节点的Hash值小于要查找的Hash值,findTreeNode方法就从right节点向下查找。如果Hash值相等,就判断key是否相同,如果key相同就返回当前节点,如果不同就返回null。整个遍历就是典型的前序遍历方法,遍历策略采用的是递归调用。TreeNode实现如代码所示。

TreeBin是红黑树的数据结构,它的作用是将链表转换成红黑树、将红黑树退化成链表、向红黑树中添加节点、从红黑树中删除节点。TreeBin定义了根节点root、链表的first节点、红黑树的等待线程、锁的状态等属性,如代码所示。

TreeBin的构造方法是将链表转换成红黑树,核心是按照链表的next指针依次向后遍历,将链表的节点添加到TreeBin中,每次添加完一个节点都需要对红黑树进行重新涂色,以达到二叉树的平衡效果。
ForwardingNode实际上是一个数据隧道,将当前节点连接到nextTable数组,然后通过nextTable来查找数据。ForwardingNode的实现如代码所示。


2. 常量定义
ConcurrentHashMap中常量定义共分为4大部分:Hash表的容量边界、数组与红黑树的转换控制边界、并发扩容线程数、Hash表数组节点的状态。常量定义如代码所示。


我们需要深入探讨TREEIFY_THRESHOLD的定义。为什么链表的长度为8的时候,ConcurrentHashMap会将链表转成红黑树?红黑树的算法复杂度是O(logN),链表的平均复杂度是O(N/2)。当N为8的时候,红黑树的平均复杂度是3,而链表平均复杂度是4,因为超过8,红黑树的查询效率会明显大于链表的。
3. 数组初始化
ConcurrentHashMap没有在构造函数里对数组初始化,而是在首次插入数据时初始化。这样设计可以避免提前占用内存,但也带来一个问题:初始化需要并发控制。Concurrent-HashMap是用sizeCtl来实现并发控制的。initTable方法会通过CAS的方式将sizeCtl变量设置成-1。在多线程环境下,只有一个线程能将sizeCtl修改成-1。数组初始化的实现如代码所示。

在数据完成初始化之后,需要设置并发控制的线程数sizeCtl。sizeCtl的值是数组长度乘以0.75,即数组长度的3/4。
4. 数组元素读取与修改
ConcurrentHashMap提供了3个方法来实现数组元素的读取与修改。tabAt方法的功能是实时读取数组元素。casTabAt方法与etTabAt方法的功能都是通过CAS的方式实时修改数组元素值。如下代码是数组元素读取与修改的实现。

5. 插入数据
向ConcurrentHashMap插入元素是由putVal方法实现的。put方法和putIfAbsent方法都是调用该方法来实现数据插入的。插入数据的实现如代码所示。


putVal方法的执行流程如下。
- 调用spread方法去计算key的Hash值。
- 判断table数组是否为空,如果table为空,则调用initTable方法来初始化table数组。
- 根据Hash值对数组长度进行取模运算,来获取数组元素的下标i。
- 调用tabAt方法获取table数组中对应的Node。如果Node为空,则构建一个新的Node,然后调用casTabAt方法将新的Node插入table数组中。
- 如果对应的Node节点不为空,则判断当前节点是链表还是红黑树:如果是链表,就在链表尾部加入新的节点;如果是红黑树,就调用putTreeVal方法向红黑树插入新的节点。
- 判断链表的长度,如果长度大于8就转成红黑树。整个链表或者红黑树插入数据的过程是通过synchronized来实现线程安全的。
6. 查询数据
ConcurrentHashMap提供了get方法来查询数据。get方法会根据key来检索Concurrent-HashMap中的数据,如代码所示。

get方法流程如下。
- 调用spread方法重新计算key的Hash值。
- 通过取模算法获取到key在table数组中对应的元素位置。在获取到key对应的位置后,调用tabAt方法获取key对应的Node。
- 根据Node的Hash值来判断是链表还是红黑树:如果Hash值小于0是红黑树;如果Hash值大于0是链表。如果是红黑树,就调用find方法遍历查找;如果是链表,直接通过next指针依次向后遍历查找。
7. 数量统计
数量统计包含两部分:基础计数baseCount、计数单元数组counterCells。线程可以通过CAS方式来修改baseCount的值。如果baseCount修改失败了,就会启动counterCells数组进行计数。CounterCell内部定义了3个属性:baseCount、cellsBusy、counterCells,如代码所示。cellsBusy是counterCells的操作状态:0表示空闲,1表示有线程正在操作数组。


数量修改是通过addCount方法来完成的。addCount方法有2个功能:一个是修改Hash表中的数据数量,另一个是触发Hash表进行扩容。addCount方法首先会调用Unsafe的compareAndSwapLong方法尝试对baseCount进行修改。如果修改失败了,那么addCount方法再调用fullAddCount方法来对counterCells数组中的值进行修改。整个实现的过程和LongAdder方法的过程基本一样。数量修改的实现如代码所示。

数量统计是通过sumCount方法来完成的。它会先统计baseCount的值,然后遍历counter-Cells数组中的值并进行累加求和。数量统计的实现如代码所示。


8. 扩容机制
当数据量达到总容量的3/4时,ConcurrentHashMap就会启动扩容机制。Concurrent-HashMap的扩容需要多线程协同工作,每个线程最少负责16个节点的扩容。
ConcurrentHashMap的扩容是通过transfer方法来完成的。transfer方法有2个参数:tab指针与nextTab指针,tab指针指向当前的table数组,nextTab指针指向扩容的数组。每次扩容时,ConcurrentHashMap会构建一个新的nextTab数组,并将table数组中所有的数据迁移到新数组中。扩容机制的实现如代码所示。



transfer方法的核心逻辑如下。
- 计算每个线程需要负责扩容的任务节点数。将当前数组的长度除以8,然后除以CPU核数得出任务数stride。将stride与16进行比较:如果小于16,把stride设置为16;如果大于16,把stride设置为计算结果。只有数组的长度大于168*NCPU才会按照计算结果来设定线程的任务数。
- 构建新的数组,并将nextTable指针指向新构建的数组。新数组长度是table数组的两倍。
- 利用新构建的数组来构建数据隧道节点ForwardingNode,方便节点在迁移中访问。
- 计算当前线程负责迁移节点的任务范围,i表示开始任务的位置,bound表示结束任务的位置。数组迁移是从table数组尾部往头部推进的。例如table数组的长度为64,每个线程负责迁移16个节点。第一个线程负责迁移的任务范围就是48~63。第二个线程负责迁移的任务范围就是32~47。以此类推,当transferIndex为0的时候,表示迁移完成了。
- 迁移线程会将原来table数组中的Node节点的数据逐个迁移到nextTable数组中。
- 每次迁移完成一个Node后,会将当前节点设置成ForwardingNode,并将sizeCtl减1。
- 当所有节点迁移完成后,迁移线程会将nextTable指针指向null,table指针指向新扩容后的数组,并且将sizeCtl设置成原来数组长度的1.5倍,也就是2n*0.75。
3、ConcurrentSkipListMap实现原理
ConcurrentSkipListMap是线程安全的TreeMap。ConcurrentSkipListMap虽然实现了和TreeMap相同的功能,但在设计思路上有比较大的差异,TreeMap是基于红黑树实现的,而ConcurrentHashMap是基于跳表实现的。ConcurrentSkipListMap存取平均时间复杂度是O(logN),比较适用于大数据量存取的场景,最常见的是实现数据量比较大的缓存。
3.1、设计原理
在讲解ConcurrentSkipListMap的并发控制设计原理之前,首先介绍一下跳表的数据结构。跳表是由美国计算机科学家William Pugh在1990年发表的论文"Skip Lists:AProbabilistic Alternative to Balanced Trees"中提出的。跳表是在链表基础做了进一步扩展实现,增加了索引检索的部分,实现了类似于二叉树的功能,如图所示。跳表由若干层链表组成,上面的每一层都是一个有序链表索引,只有最底层的链表包含了所有数据。每层索引依次减少,最顶层只有极少的数据索引结构。由顶向下,每一层都是通过数据指针指向上层相同的数据。跳跃表本质是利用了空间换时间的设计思想来提高查询效率。程序总是从最顶层开始查询访问,通过判断元素值来缩小查询范围,快速检索数据信息。
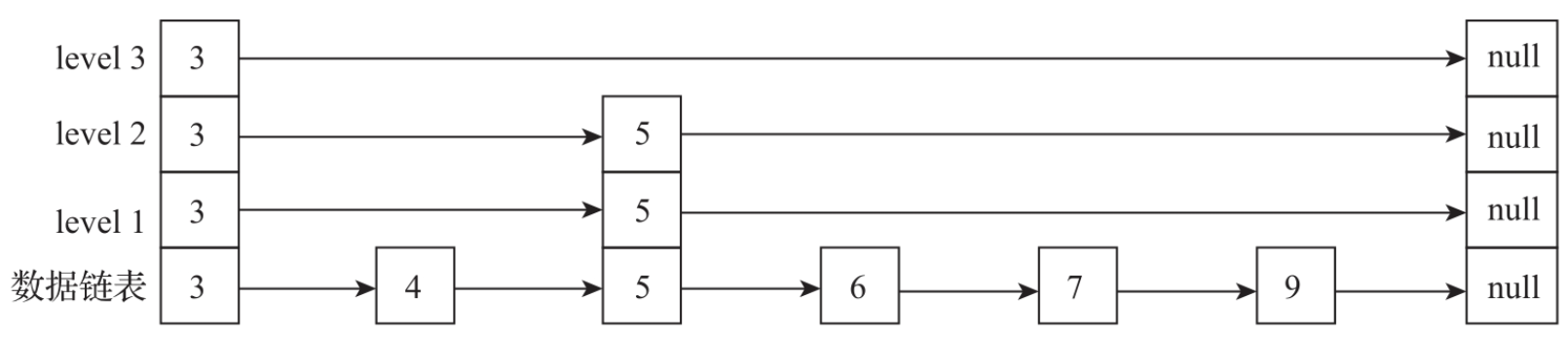
1. 跳表查询
跳表会从头节点的索引开始检索,如果查询的key大于当前节点的索引key,则继续向右查询。如果查询的key小于当前索引节点的key,或者索引的右边节点为空,则向下查询。依次从顶层开始,逐渐向右、向下搜索,直到找到底层数据链表为止。
例如在图中:
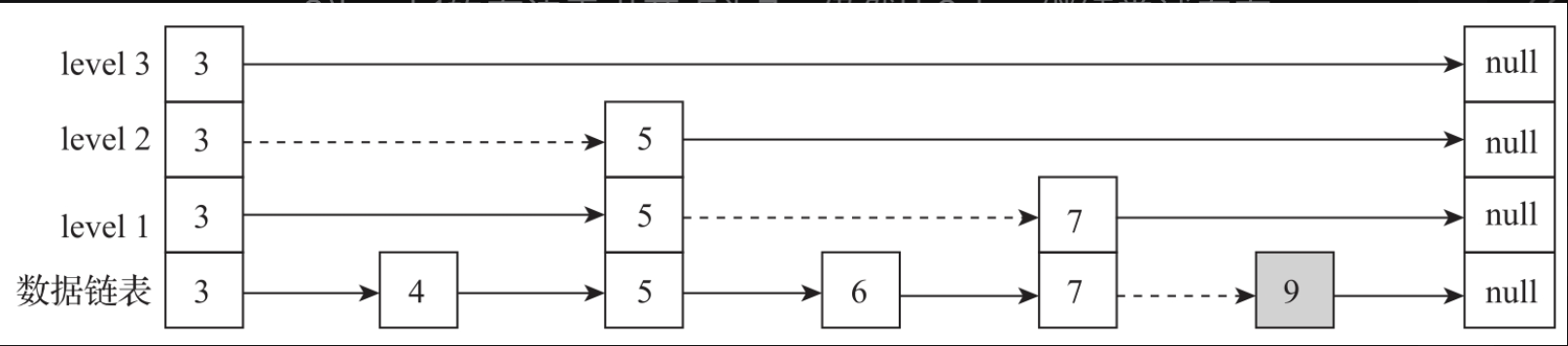
- 检索key为9的索引节点,先从level 3的头节点开始,向右查询发现3的右边索引为null,则向下到level 2查询。
- 判断level 2的右边索引节点的值为5,还是比9小,接着向右查询,而右边的索引节点为空,继续向下,到level 1查询。
- level 1的右边索引节点为7,仍然比9小,继续尝试向右查询,而7的右边索引节点为null,则继续向下,到了数据链表层。
- 从数据节点7开始向右遍历,查到了key为9的节点。
2. 跳表的插入
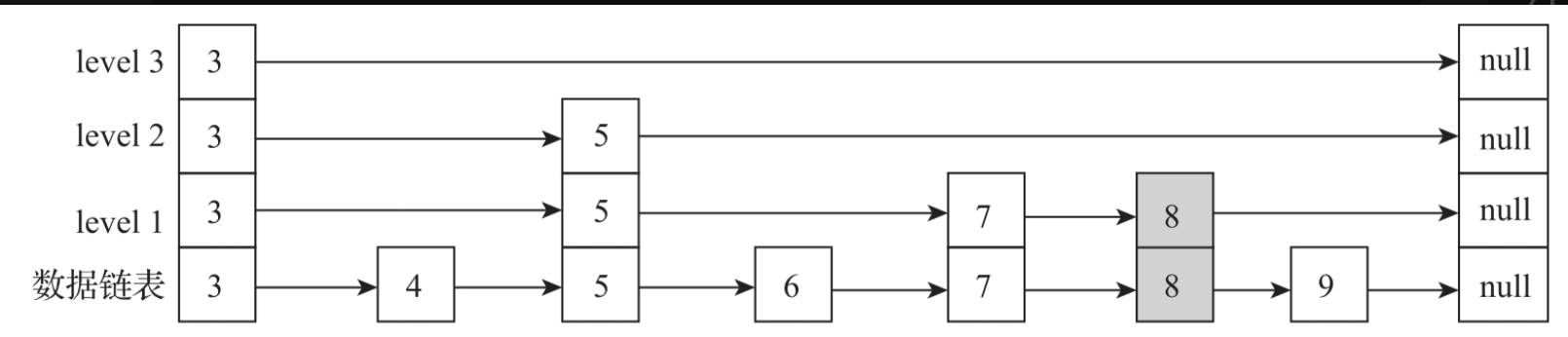
跳表的插入首先需要查找到要插入key的前驱节点,然后把新插入的节点放在前驱节点的后面,最后按照随机算法生成索引的层级,最后从下向上依次构建索引信息。如果跳表中已经存在相同的key,则直接替换value的值。
例如在下图中,增加一个key值为8的节点,通过索引检索,找到最底层链表中key为7的前驱节点,然后把8加在7的后边,并且把8的next指针指向9。然后根据随机概率算法计算出新增加节点的level值,例如图8-13中为level值为3,再根据level值从底向上依次构建索引节点信息。
3. 跳表的删除
跳表的删除包含两部分:数据删除与索引删除。例如在下图中,要删除key为7的节点,首先通过跳表检索的方法找到待删除节点,将其value值设置为null。然后把删除节点的前驱节点的next指针直接指向删除节点的后继节点,最后自顶向下删除索引信息。
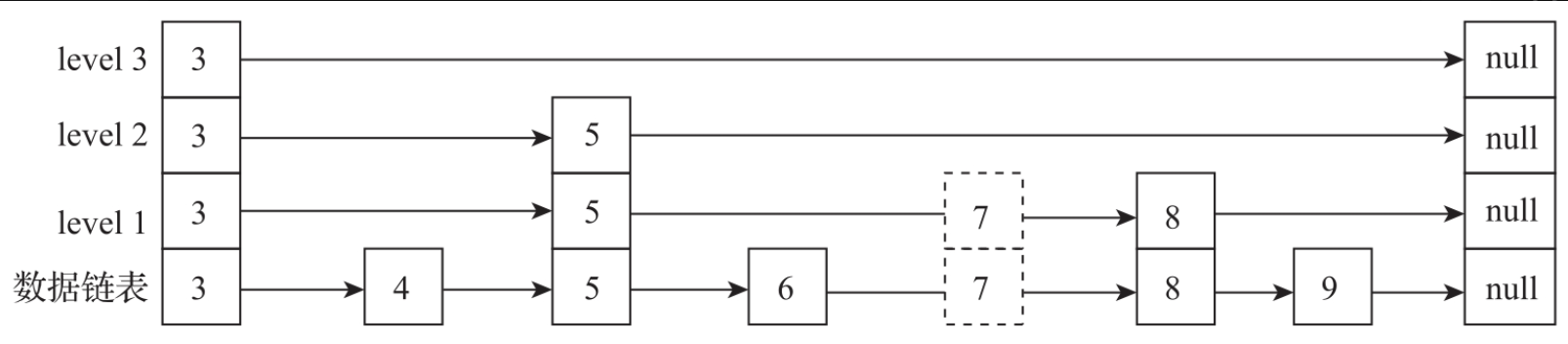
6为7的前驱节点,8为7的后继节点,直接把6的next指针指向8就完成了数据链路的删除。同时把索引节点5的right指针指向8,就完成了索引链路重建。
4. 线程安全设计
跳表的修改涉及底层链表和索引的修改。因为索引本身只是用来加快检索效率的,并不会影响数据的准确性,所以ConcurrentSkipListMap把数据链表与索引结构分开进行并发控制。数据节点的修改主要是修改节点的值与next指针。ConcurrentSkipListMap会通过CAS的方式先修改值,再修改next指针。索引节点修改主要是修改节点的right指针与down指针。ConcurrentSkipListMap通过CAS的方式来确保right指针与down指针修改的原子性。
多个线程可同时对ConcurrentSkipListMap进行操作。线程1尝试修改值为5的节点,线程2查询值为5的节点,线程3删除值为7的节点,线程4查询值为9的节点,如图所示。
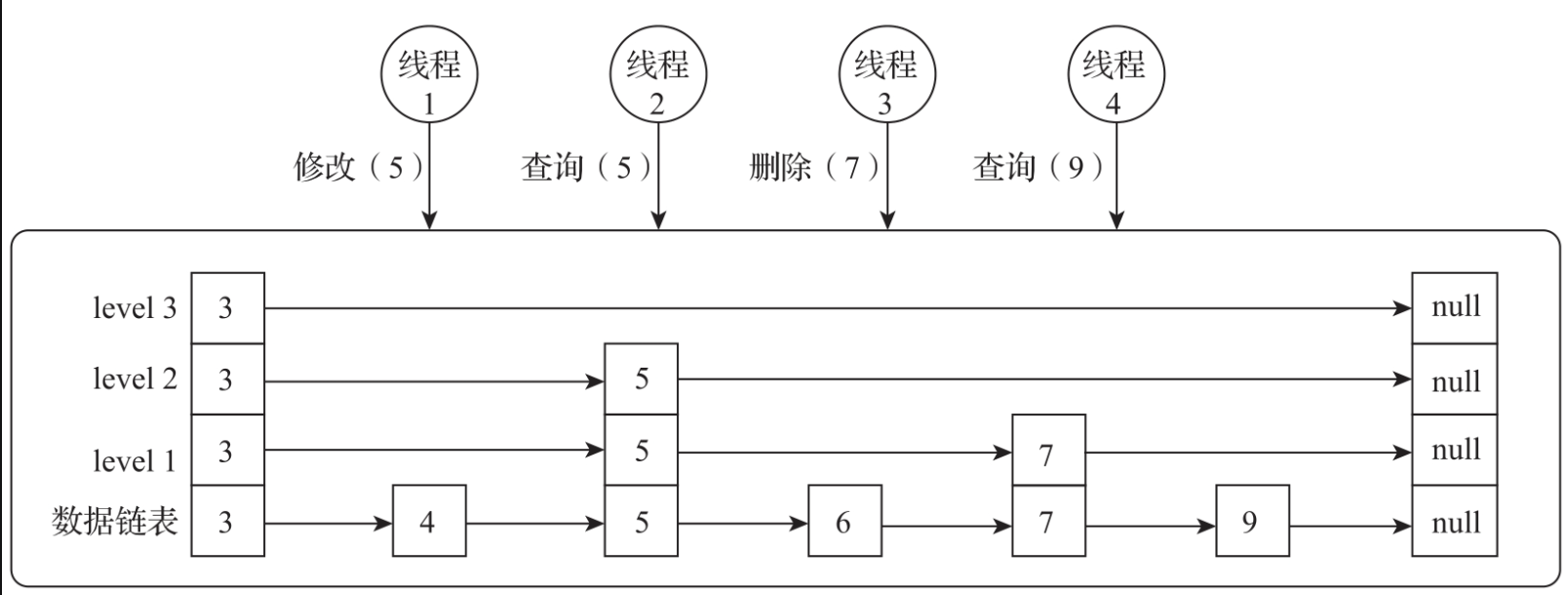
线程1只对值为5的节点进行修改,线程2能够实时看到最新的变化结果。线程3删除了值为7的节点,会出现线程3刚修改完值为7的节点,并把值设置为null,线程4就进行查询的情况。这个时候仍然通过索引的检索查找值为7的节点,只是这个时候值为null,但仍然能够通过这个节点的next指针查找到节点值9,不会影响对9的查询。
3.2、源码分析
ConcurrentSkipListMap定义了2个内部类:Node与Index。Node用来存储数据信息,是最底层的数据链表的节点,Index是数据索引节点。ConcurrentSkipListMap定义了指向索引头节点的head指针。在ConcurrentSkipListMap初始化时会构造一个key为null的空节点,将head指向空节点。后续节点的添加与查询都是从head指针依次向右和向下遍历的。ConcurrentSkipListMap的UML图如图所示。
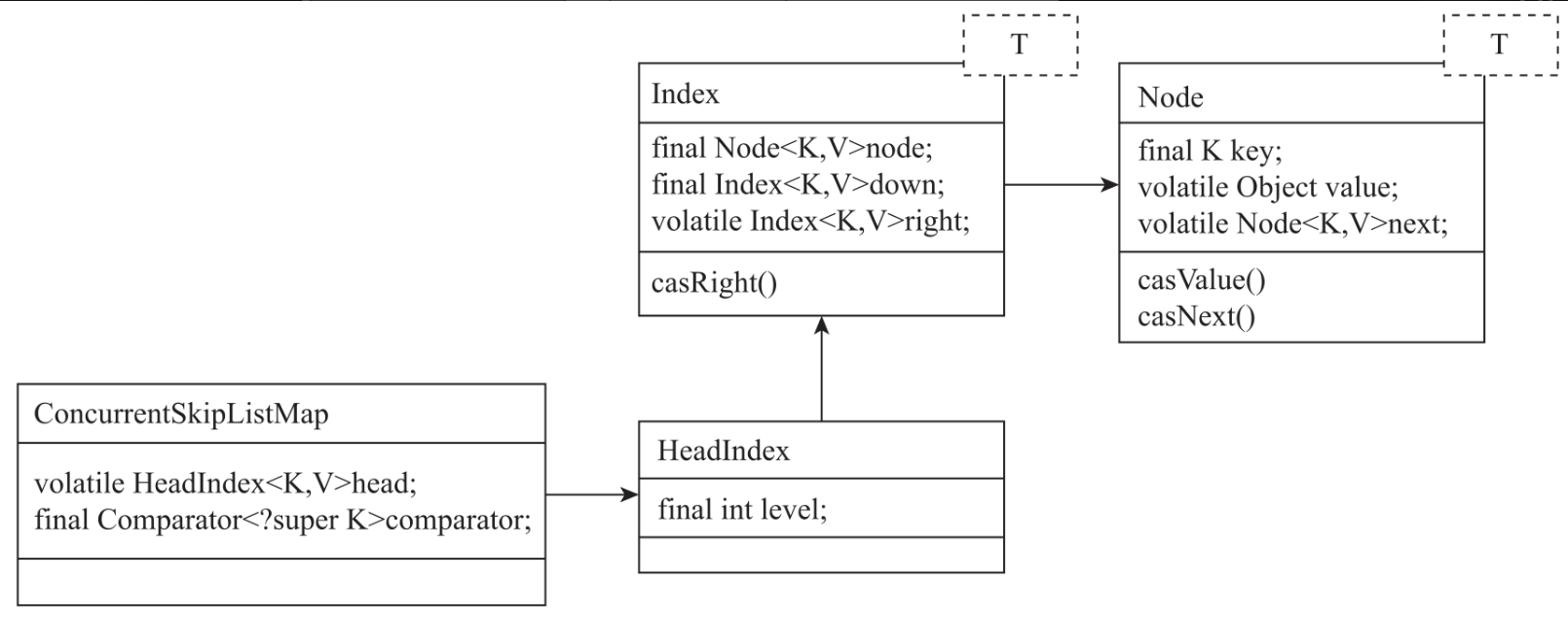
1. Node
Node是跳表的底层节点,也是真正用来存储数据的节点。Node内部定义了3个属性:key、value、next,如代码所示。其中,key是数据节点的名称,value是数据值,next指针指向链表的后继节点。

如下代码所示,节点删除是通过调用VarHandle的compareAndSet方法来实现的。unlinkNode方法有2个参数:b是当前节点的前驱节点,n是当前节点的后继节点。unlinkNode方法通过CAS的方式将前驱节点的next指针指向当前节点的后继节点,这样就实现了删除当前节点。

2. Index节点
Index是索引节点,用来存储数据索引。Index节点内部定义了3个指针:node指针、down指针、right指针。node指针指向的是最终存储数据的节点。down指针指向的是下级索引节点。right指针指向的是右边索引节点。Index数据结构如代码所示。

Index节点定义了VarHandle的常量RIGHT。通过RIGHT实现right指针的原子性修改,RIGHT定义如代码所示。


3. 构造函数
ConcurrentSkipListMap的构造函数比较简单,它并未进行跳表的初始化。跳表的初始化是在第一次插入数据的时候完成的,如代码所示。

4. 前驱节点查找
前驱节点通过索引来快速查找到key值对应的前驱节点。可以通过前驱节点向后遍历锁来精确查找和匹配。在检索数据的同时,findPredecessor方法还扮演了"清道夫"的角色,它会清除无效的索引节点。需要重点关注的是,findPredecessor方法索引检索到的不一定是离key最近的数据节点。
如下图所示,图中6、7、8三个数据节点的索引节点都是空的。如果查找的key为6,那么通过索引检索出来的数据节点为5,这时5就是6的前驱节点了;如果查找的key是9,通过索引检索出来的同样是5,数据节点5与数据节点9之间就相隔了数据节点6、7、8。前驱节点查找实现如代码所示。
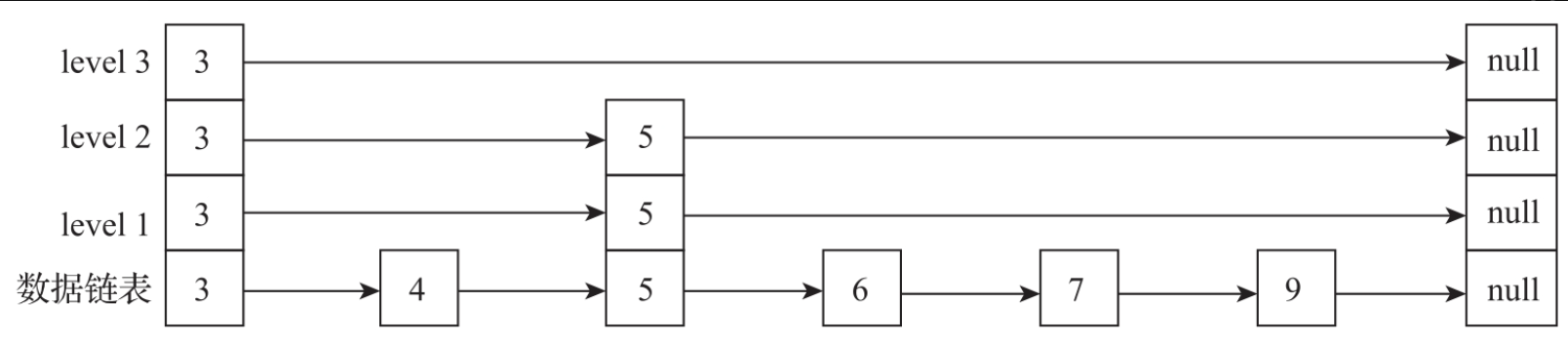


findPredecessor方法会从head索引节点开始,依次向右、向下查询。如果右侧的right索引节点的key值大于查找的key值或者右侧节点为空,则通过down指针向下检索。如果右侧节点的key小于查找的key,则继续向右查找。注意,在有多个线程执行的情况下,整个Index索引结构会实时变化,可能通过一次查找无法得出结果,所以findPredecessor方法需要进行多次循环来尝试查找。
5. 数据节点查找
数据节点查找是通过key进行的。如果跳表中存在key对应的数据节点,则返回对应的节点;如果不存在,则返回null。同时,findNode方法可以用来清理数据链表中的无效节点。代码和findPredecessor方法基本是一样的。
6. 数据查找
doGet方法通过key来查找具体的数据值。doGet方法是通过findPredecessor方法来查找小于key的前驱节点,然后按照next指针向右查找,找到key对应的数据值,如果不存在则返回null。数据查找的实现如代码所示。


7. 数据插入
在跳表中插入数据是通过doPut方法实现的,该方法的核心处理逻辑包含3个步骤:首先通过向右和向下遍历查找要插入节点的近似前驱节点,然后通过CAS的方式把新的节点插入数据链表中,最后构建新节点的索引。
构建索引是一个非常复杂的过程。首先要构建当前节点的索引节点,然后重构头节点的索引,最后重构中间节点的索引。doPut方法实现如代码所示。


是否每次插入数据都会重建索引呢?不会的,只有25%的概率会去构建索引。doPut方法会先生成一个随机数:rnd,只有rnd&0x3的值为0才会构建索引。0x3是十六进制的值,二进制的最后两位是11。rnd&0x3为0表示rnd的二进制值的最后两位必须都是0,所以只有25%的概率会构建索引。
索引层级level是根据rnd计算出来的。计算出来的索引层级可能比跳表当前的层级小,也可能比当前层级大。
如果新计算出来的层级比head节点的层级小,只要在待重构的当前节点的索引与前驱节点的索引之间建立连接即可,如图所示。
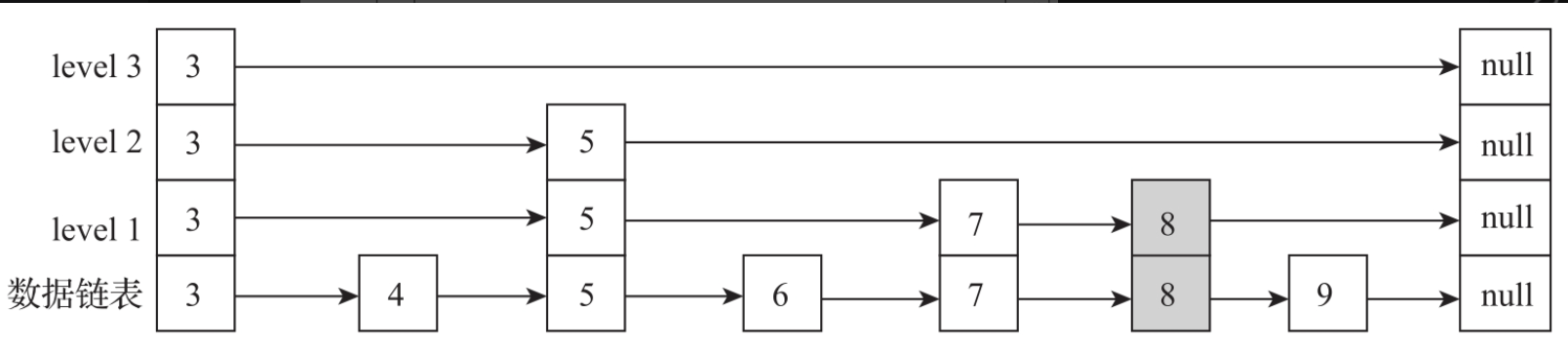
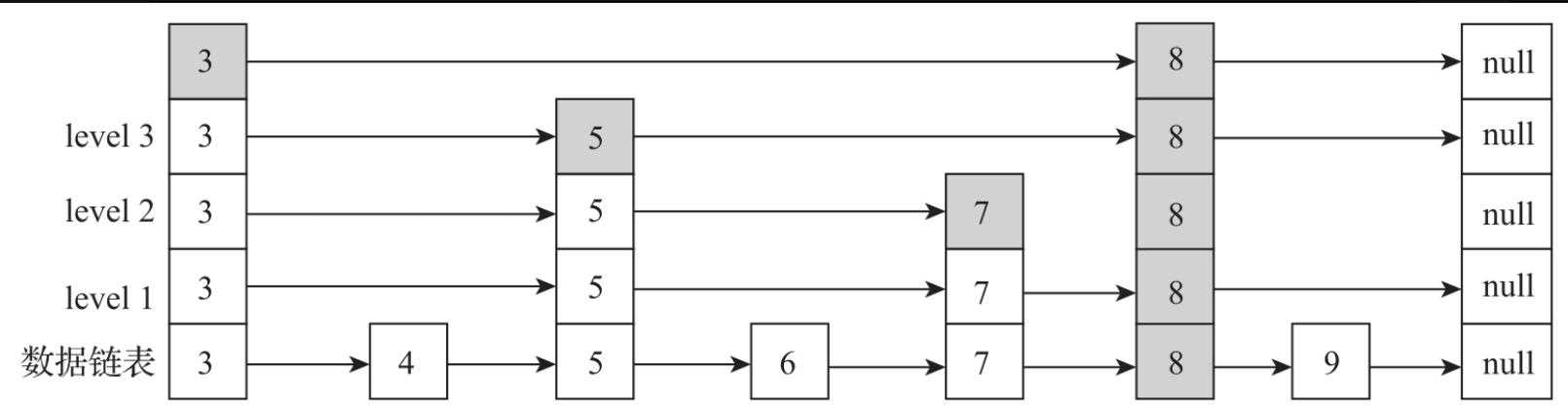
如果新计算出来的层级比head节点索引的层级大,需要重构整个索引节点。doPut方法先构建插入节点的索引层级,然后升级头节点的索引层级,最后把中间所有的索引节点都升级。例如在下图中,插入数据节点8,随机计算出来的level为4,超出了当前头节点最大层级3,则需要把头节点3、中间节点5和节点7的索引都进行升级。
4、LinkedBlockingQueue实现原理
LinkedBlockingQueue是一个基于单向链表的线程安全阻塞队列,队列遵从FIFO原则,它会将新元素插入到队列的尾部,并从队列头部位置获取队列元素。链表队列在数据修改上的性能要比数组队列的性能高,是大多应用场景的首选队列容器。同时,Linked-BlockingQueue是有界队列,可以指定队列的长度,如果不指定,则默认容量大小等于Int-eger.MAX_VALUE,防止队列过度膨胀导致内存溢出。LinkedBlockingQueue提供了线程安全的数据读取与修改方法,具体方法如表所示。
4.1、设计原理
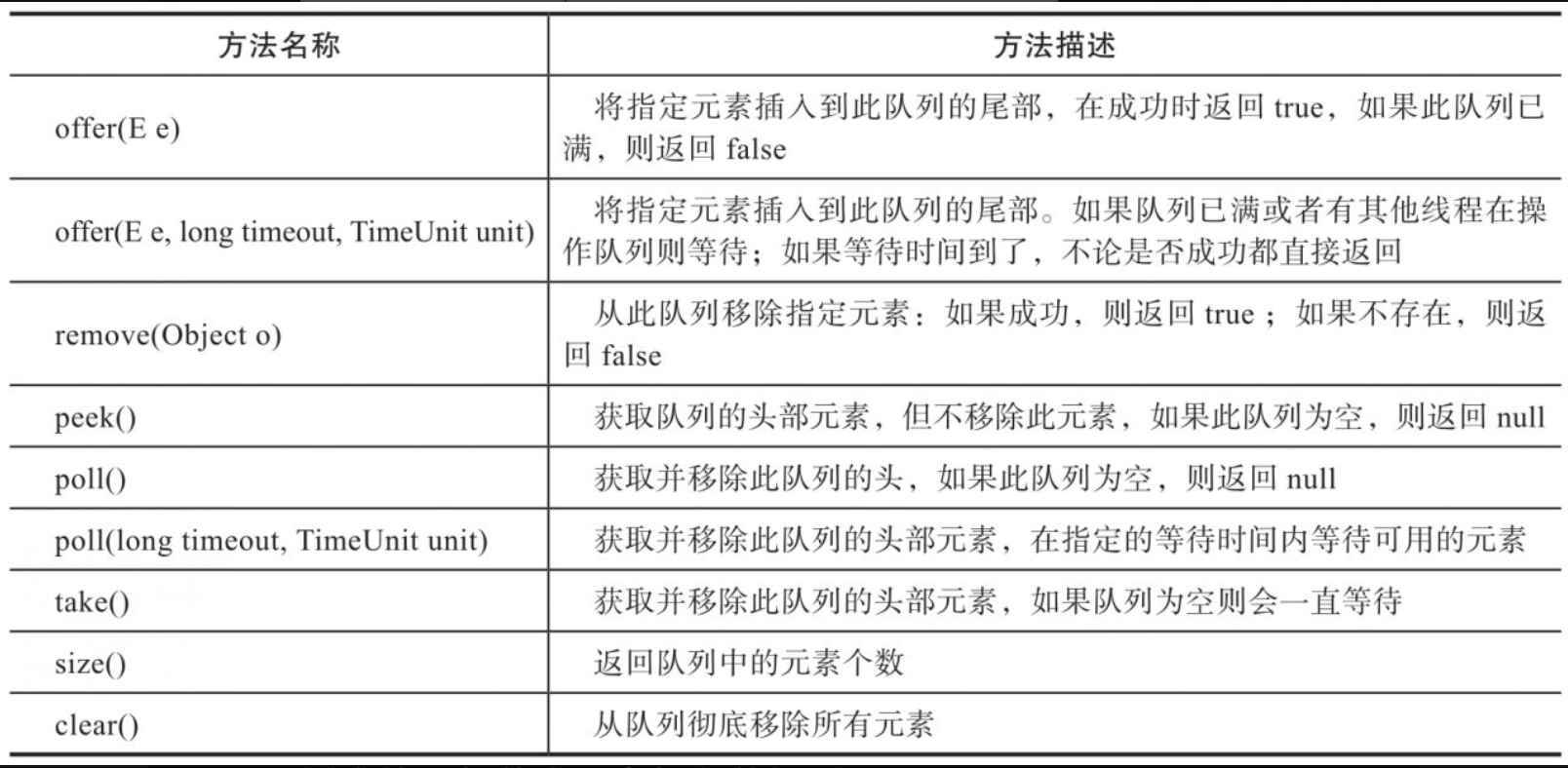
LinkedBlockingQueue采用单向链表来存储数据,链表中的每个节点都有一个next指针指向后继节点。LinkedBlockingQueue内部定义了2个指针:head指针与last指针。head指针指向链表的头部节点,last指针指向链表的尾部节点。在插入数据时,LinkedBlockingQueue会先通过last指针查找到队列尾部节点,然后将尾部节点的next指针指向新加入的节点,并同时将last指针指向新插入的节点。在获取数据时,LinkedBlockingQueue会通过head指针找到头节点,将头节点从队列中移除,然后将head指针后移一位。其数据结构如图所示。
1. 并发控制
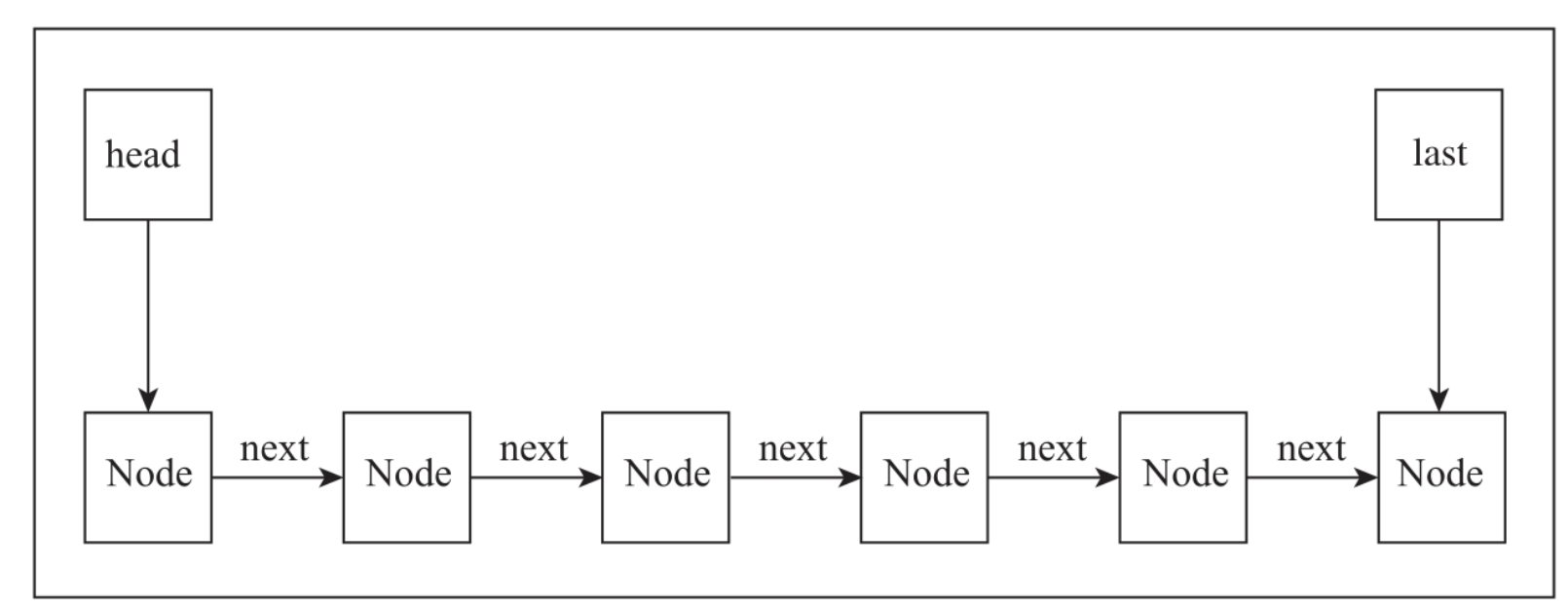
LinkedBlockingQueue是线程安全的阻塞队列,会面临多线程同时向队列中插入数据、读取数据的情况。如下图所示,线程1~线程3同时往队列中插入数据,线程4~线程6从队列中读取数据。
在并发控制上,LinkedBlockingQueue定义了2个ReentrantLock的独占锁:putLock用来控制线程的并发写入;takeLock用来控制线程的并发读取。在数据插入时,如果队列已经满了,插入数据的线程都会进入阻塞状态。直到有线程从队列中读取数据后,才会唤醒阻塞的写入线程继续插入数据。在读取数据时,如果队列空了,读取的线程都会进入阻塞状态。直到有线程向队列中插入数据,才会唤醒阻塞的读取线程继续读取数据。
2. 数量统计
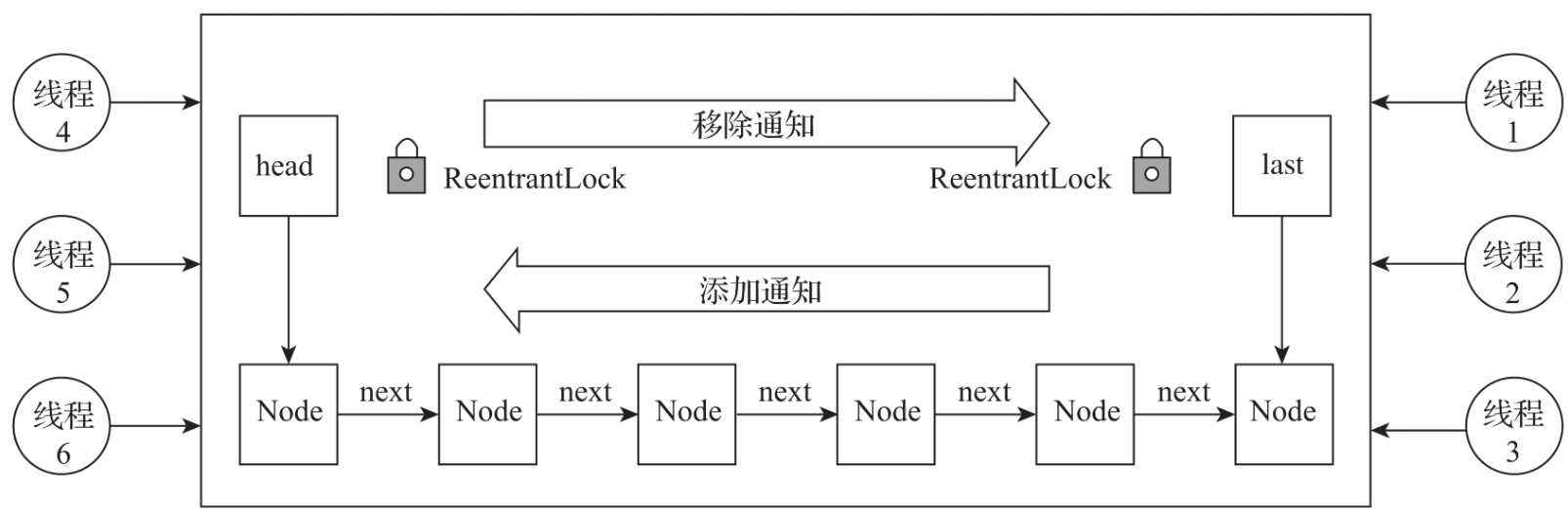
LinkedBlockingQueue需要实时感知队列中数量,因此引入了原子计数器AtomicInteger来统计数据的数量。每次插入数据时,插入方法会将数量加1。每次移除数据时,移除方法都会将数量减1。LinkedBlockingQueue数量统计的流程如图所示。
4.2、源码分析
Node是链表的数据节点,内部定义了泛型item来存储任意类型的数据。Node数据节点的定义如代码所示。

enqueue方法是将新的节点加入单向链表。dequeue方法是将链表的头部节点移除。链表的修改实现如代码所示。


1. 并发控制
LinkedBlockingQueue定义了2把锁来进行并发控制:takeLock与putLock,takeLock用来实现数据移除的并发控制,putLock用来实现数据插入的并发控制。并发控制定义如代码所示。

2. 队列初始化
LinkedBlockingQueue提供2种构造函数:一种函数要指定队列长度,另一种函数不需要指定队列长度,不指定长度的情况下默认是int的最大值65536。初始化的过程比较简单:构建一个空的Node,然后将head指针与last指针都指向这个空的节点。队列初始化实现如代码所示。


3. 添加数据
put方法的功能是往队列中添加数据。put方法的流程如下。
- 调用ReentrantLock的lockInterruptibly方法获取数据修改的独占锁。
- 判断队列是否已经满了,数据的数量是否已经到了预定的容量。如果达到了预定容量,就调用notFull的await方法进行等待。如果队列没满,就调用enqueue方法将数据插入链表。
- 调用AtomicInteger的getAndIncrement方法将队列的数量加1。
- 再次判断队列是否满了,如果没满,则调用notFull的signal方法释放队列没满的信号。
添加数据的实现如代码所示。

offer方法和put方法一样,都是向队列中插入元素,只有一个细小的差别------当队列满了之后,offer方法不会等待,会直接返回。
4. 读取数据
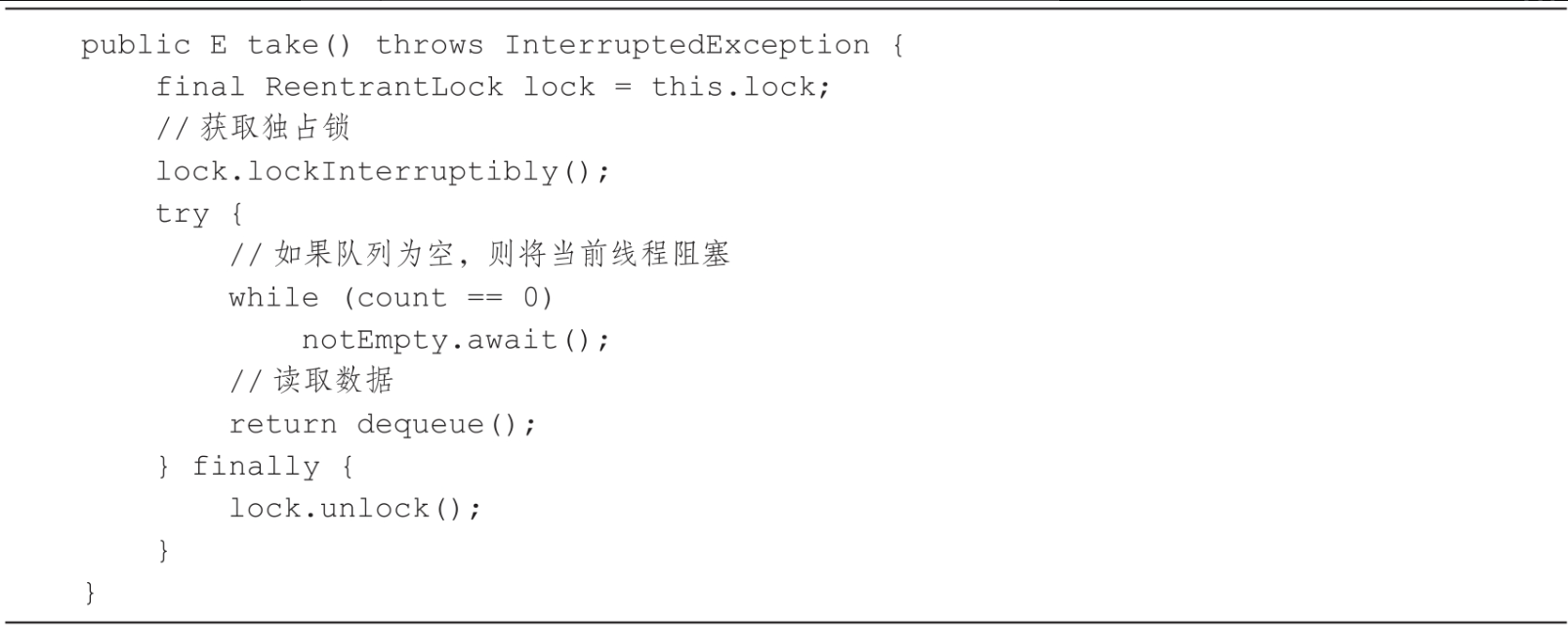
take方法的功能是从队列中读取并移除数据,如代码所示。

- 调用ReentrantLock的lockInterruptibly方法获取头节点修改的锁。
- 调用AtomicInteger的get方法来获取队列的长度,如果长度为0表示队列为空,进行等待。
- 如果队列不为空,则调用dequeue方法将队列的头节点从链表中移除。
- 调用AtomicInteger的getAndDecrement方法将队列的长度减1。
- 获取队列的长度,如果长度大于1说明队列不为空,则调用notEmpty的signal方法,释放队列不为空的信号。
poll方法也是从队列中获取头节点的方法,只是与take方法有一个差别,即队列为空的时候会不等待,直接返回null。
5. 删除数据
remove方法的功能是从队列中删除数据,如代码所示。


- 调用fullyLock方法来获取putLock与takeLock两个独占锁,确保其他线程不能修改队列。
- 从前向后依次遍历查找数据,如果查找到数据,将数据节点的前驱节点与后继节点相连接,从而将数据节点删除。
- 调用fullyUnlock方法来释放两个排他锁。
LinkedBlockingQueue是一个有界阻塞队列,内部由单向链表来存储数据,每次都会从队列的尾部插入数据,每次读取数据时都是从队列头部开始。
5、ArrayBlockingQueue实现原理
ArrayBlockingQueue是基于数组的线程安全阻塞队列,该队列按FIFO原则来排序元素。队列的头部是在队列中存在时间最长的数据,队列的尾部是刚插入的新数据。
ArrayBlockingQueue也是有界队列,可以指定队列的大小,如果不指定大小,默认容量大小等于Integer.MAX_VALUE,它能防止队列过度膨胀导致内存溢出。
ArrayBlockingQueue提供了线程安全的数据读取与修改方法,如表所示。


5.1、设计原理
ArrayBlockingQueue是用数组实现的循环队列。ArrayBlockingQueue内部定义了一个固定长度的数组,用于存储数据,同时定义了两个数组下标:takeIndex与putIndex。takeIndex是数据读取的下标,putIndex是数据写入的下标。
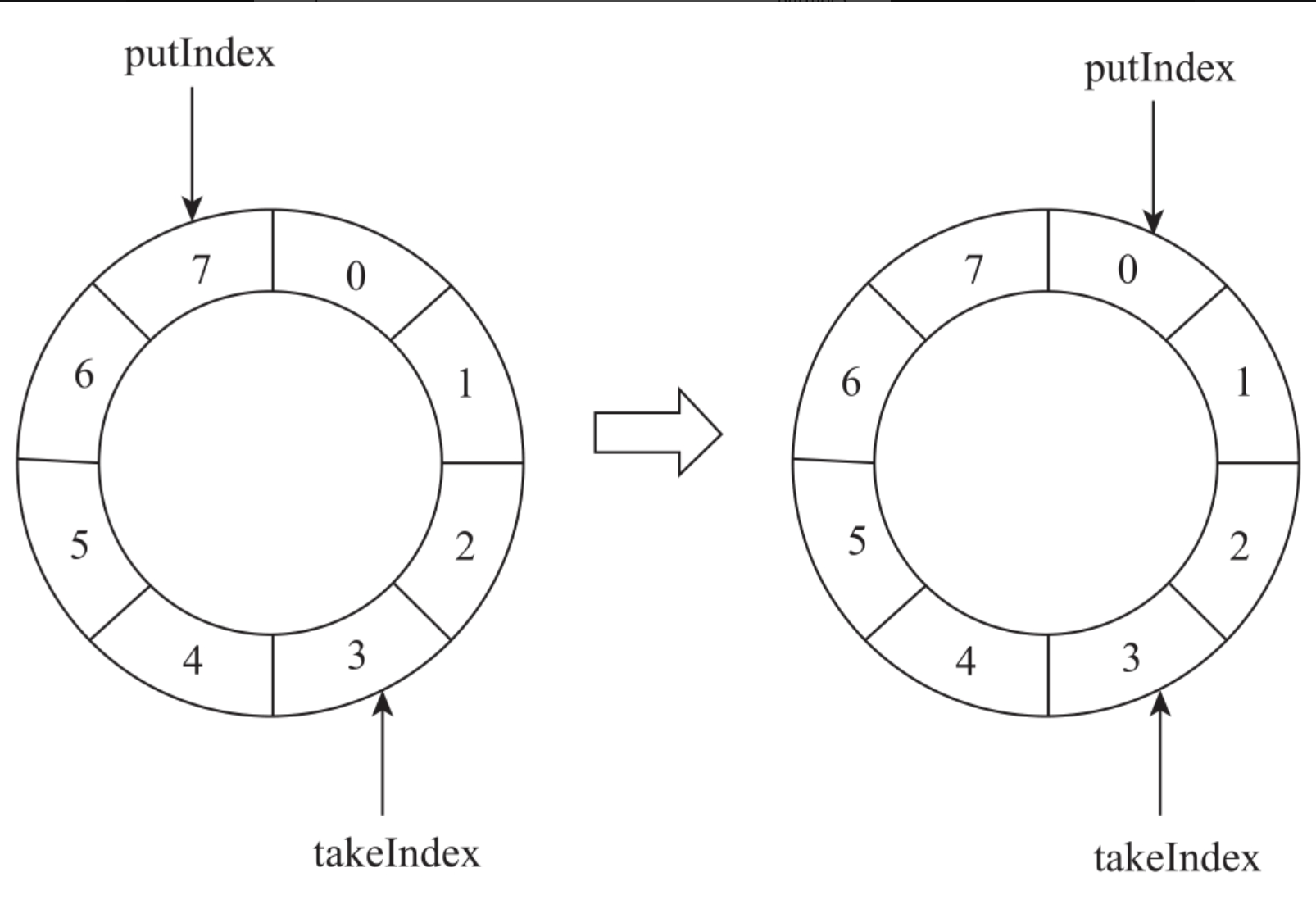
每次向数组插入元素时,ArrayBlockingQueue会将putIndex加1。当putIndex的值达到数组的最大长度之后,会将putIndex重新设置为0。每次从数组移除元素时,Array-BlockingQueue会将takeIndex加1。当takeIndex的值达到数组的最大长度之后,它会将takeIndex重新设置为0。数组的长度是固定的,不会触发数组的扩容。ArrayBlockingQueue数据结构如图所示。
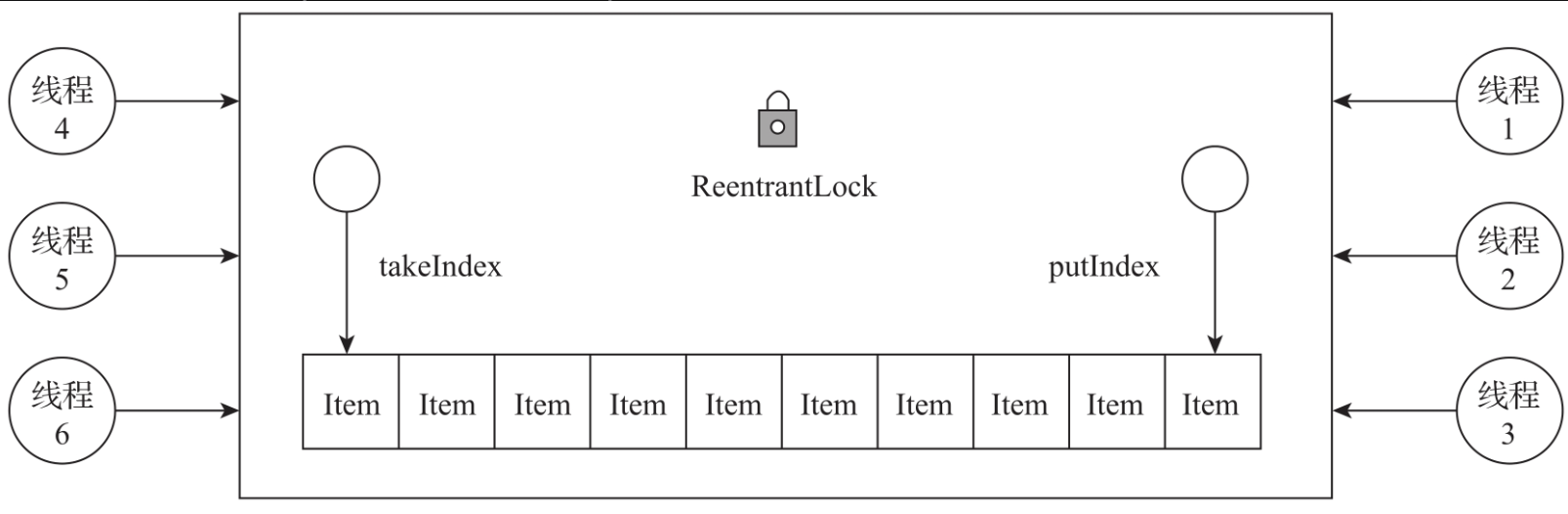
通过putIndex与takeIndex的不停移动,原本一条有头有尾的线性数组,变成一个首尾相连的环形队列。
如图所示,队列的大小为8,当前takeIndex为3,putIndex为7。当往队列中插入一个新元素A时,ArrayBlockingQueue会将putIndex后移一位,putIndex会变成0。当再插入一个元素B时,ArrayBlockingQueue会将putIndex加1,putIndex会变成1。
1. 并发控制
ArrayBlockingQueue是线程安全的阻塞队列,会面临多线程同时操作队列的情况。如图所示,线程1~线程3同时向队列中插入元素,线程4~线程6从队列中读取元素。
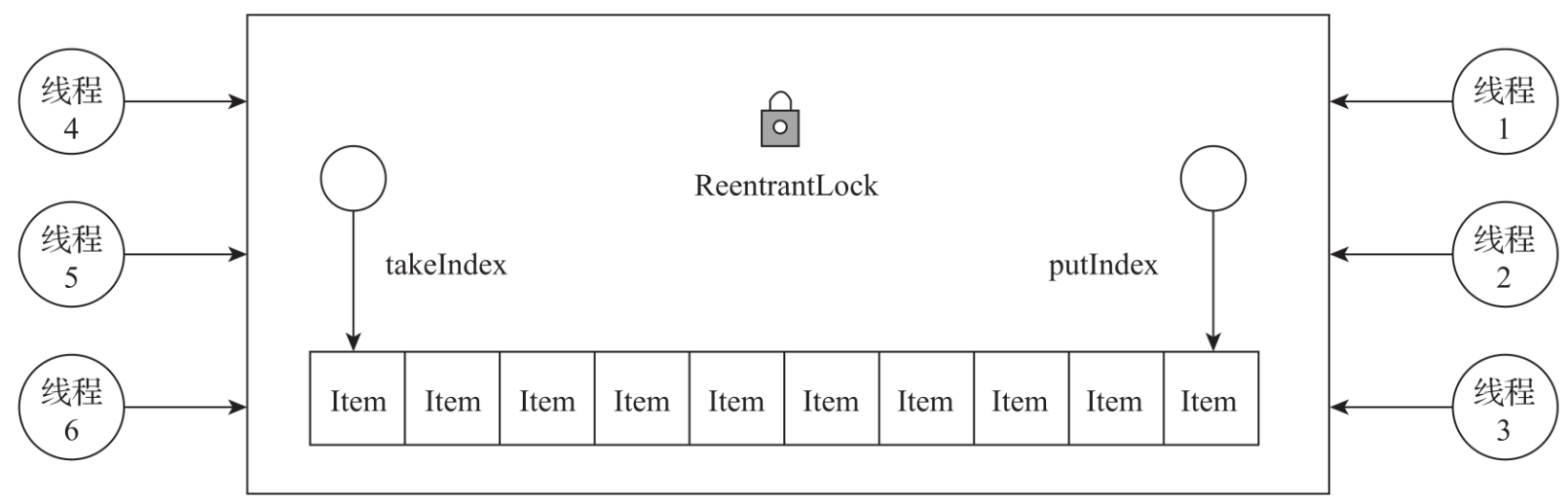
在并发控制上,ArrayBlockingQueue采用了ReentrantLock来实现并发控制。对队列进行操作时,线程都需要先获取锁,所以在任一时刻只会有一个线程对队列进行操作,从而实现了线程的安全性。在数据插入时,如果队列已满,ArrayBlockingQueue会阻塞插入的线程。当有线程从队列中移除数据之后,ArrayBlockingQueue会唤醒所有阻塞的线程来继续插入数据。在数据读取时,如果队列为空,ArrayBlockingQueue会阻塞读取的线程。当有线程向队列中插入数据之后,ArrayBlockingQueue会唤醒所有阻塞的读取线程来继续读取数据。
2. 队列数量
因为对队列的修改都采用同一独占锁进行并发控制,所以在任一时刻只有一个线程能对队列进行修改。ArrayBlockingQueue定义了一个int变量count。每次添加数据时,Array-BlockingQueue会将count加1。每次移除数据时,ArrayBlockingQueue会将count减1。count为0表示队列是空的,count为数组长度时表示队列满了。
5.2、源码分析
ArrayBlockingQueue内部定义了items、takeIndex、putIndex等变量。items用来存储具体数据。takeIndex与putIndex用来表示读取与插入的下标。
ArrayBlockingQueue定义了lock、notEmpty、notFull等常量。lock用来实现队列的并发控制。notEmpty是队列不为空的等待条件。notFull是队列没满的等待条件。
ArrayBlocking-Queue变量定义如代码所示。

enqueue方法的功能是向数组中插入元素,如代码所示。enqueue方法首先会将插入的数据放入putIndex指向的数组位置,并将putIndex加1,然后判断putIndex是否等于数组的长度:如果putIndex等于数组长度,将putIndex设置为0,同时将元素数量count加1。

1. 插入数据
向队列中插入数据时,ArrayBlockingQueue首先会调用ReentrantLock的lockInterruptibly方法获取独占锁,然后判断队列是否已经满了。如果队列满了,则ArrayBlockingQueue就会让插入线程进行等待;如果队列没满,ArrayBlockingQueue就会调用enqueue方法将数据插入队列。插入数据的实现如代码所示。

2. 读取数据
从队列中读取数据时,ArrayBlockingQueue首先会调用ReentrantLock的lockInterruptibly方法获取独占锁,然后判断队列是否为空。如果队列为空,ArrayBlockingQueue就阻塞读取线程,并让其进行等待;如果队列不空,ArrayBlockingQueue会调用dequeue方法将队列头元素移除并返回。插入数据的实现如代码所示。
dequeue方法是读取数据的具体实现,如代码所示。dequeue方法先根据take-Index下标获取到对应的数据,将takeIndex位置上的元素清空。然后将takeIndex加1,接着判断takeIndex是否为数组的长度,如果等于数组的长度,则将takeIndex设置为0。


ArrayBlockingQueue是一个有界阻塞队列,内部由数组来存储数据,在内部定义take-Index和putIndex的下标,通过下标的循环遍历实现了环形数组的功能。同时ArrayBlockingQueue内部定义了一个独占锁ReentrantLock来实现队列出入的线程安全,在进行队列操作时都需要获取这个独占锁。
6、SynchronousQueue实现原理
SynchronousQueue是一种无缓冲的等待队列,添加数据的时候必须等待其他线程取走后才能返回。消息队列技术中间件中大量使用了SynchronousQueue,接下来从底层实现角度来探讨一下SynchronousQueue的技术实现细节。SynchronousQueue提供了线程安全读取与修改的方法,如表所示。
6.1、设计原理
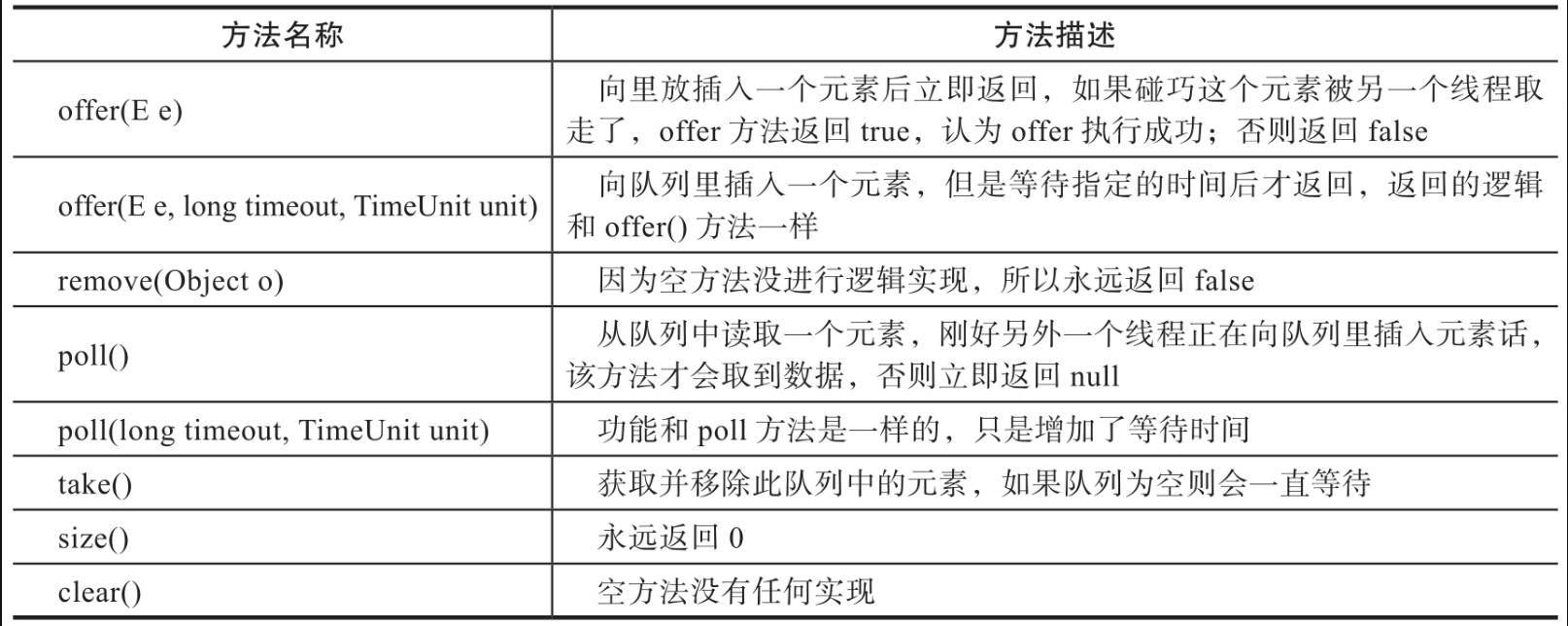
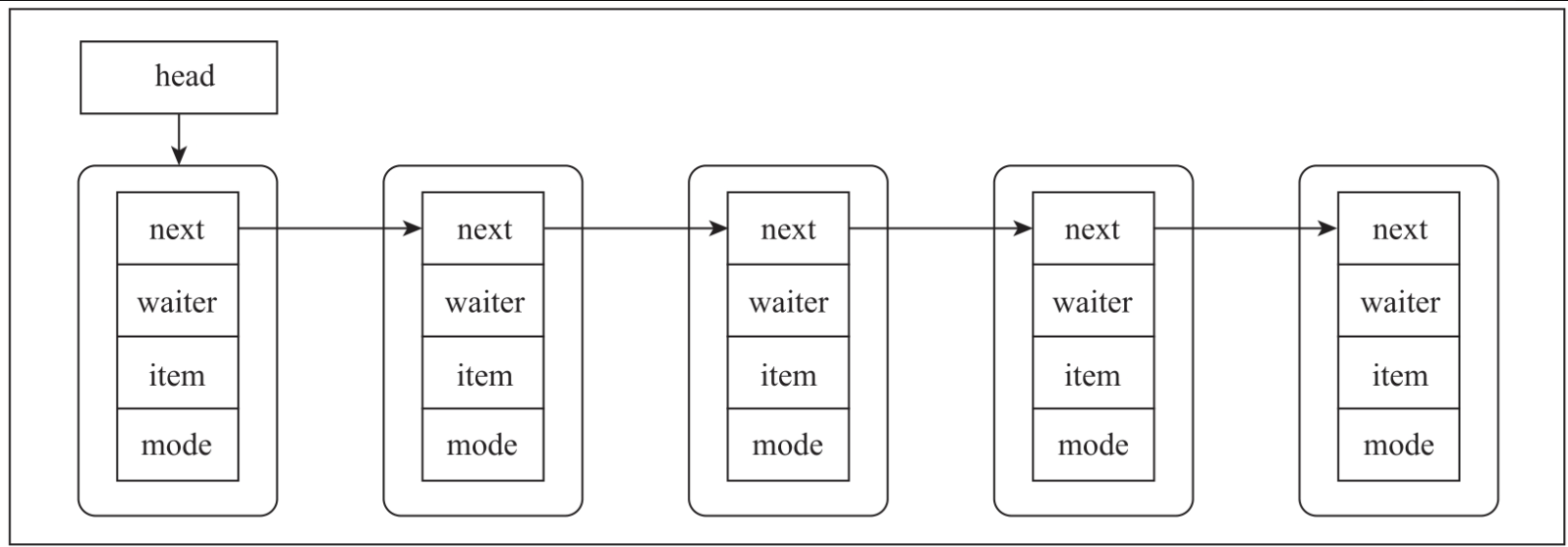
LinkedBlockingQueue与ArrayBlockingQueue虽然能够很好地在线程间传递数据,但无法准确地控制线程的执行顺序。SynchronousQueue实现了数据传递与线程执行顺序的统一,能够在线程间传递数据的同时精确地控制执行顺序。SynchronousQueue内部维护着一个单向链表,链表中的每个节点用来存储数据与线程信息,如图所示。节点定义了3个属性:item、waiter、next。item用来存储当前的数据,waiter表示要对数据操作的线程,next表示指向下一个节点的指针。
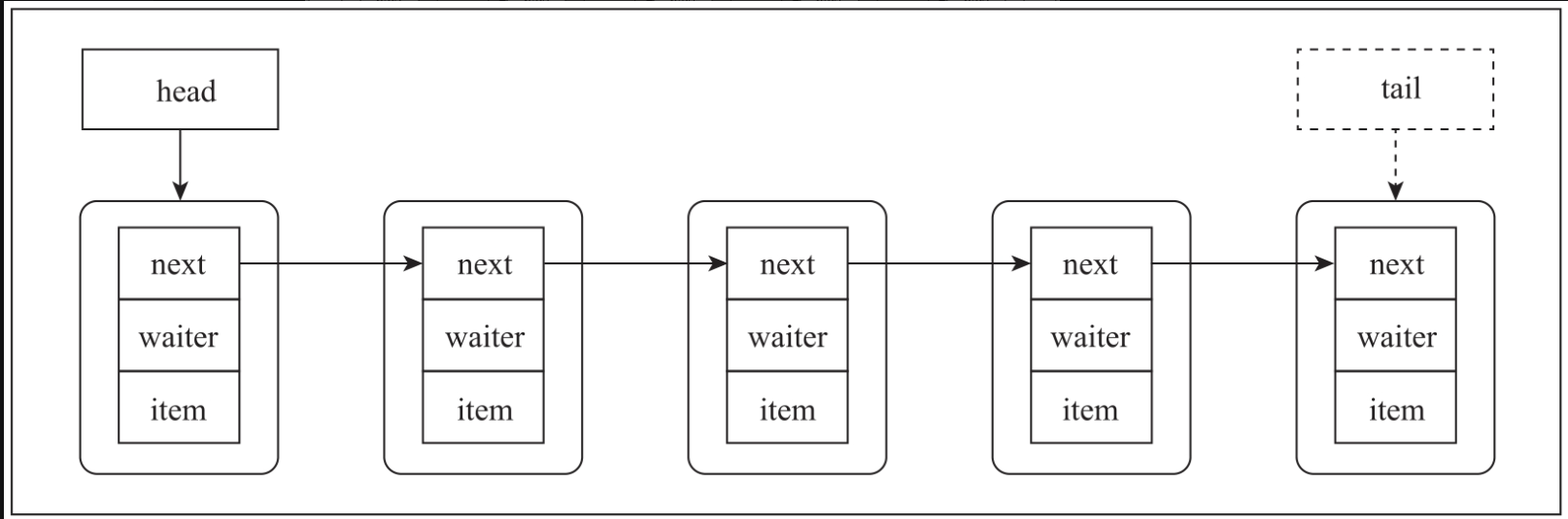
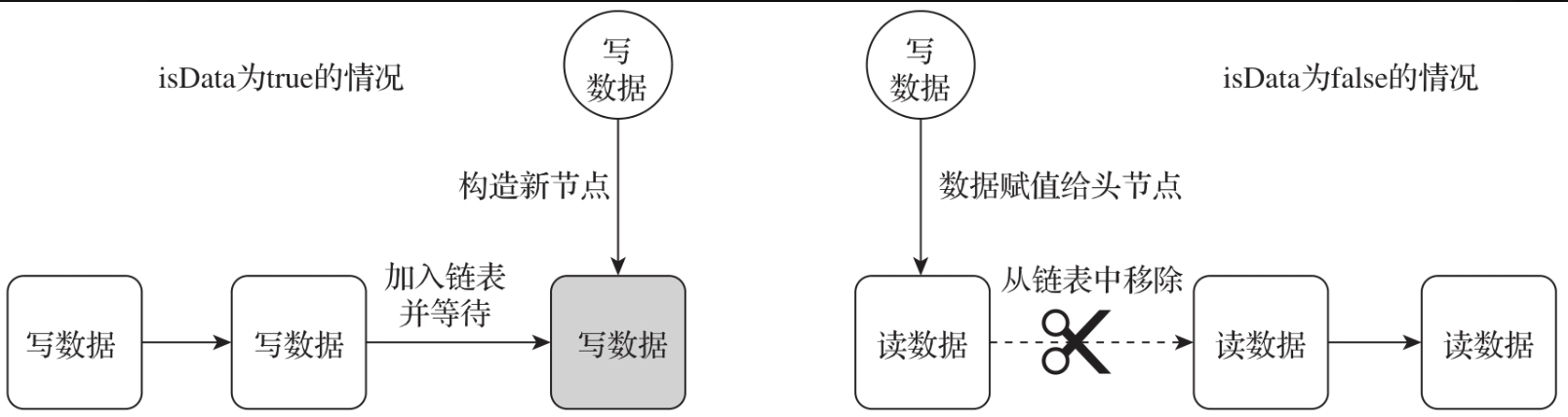
每一个节点都可以代表两种情形:插入数据和读取数据。当数据插入的时候,item指向队列中的插入数据。当数据读取的时候,item为null。每次插入数据的时候,都尝试唤醒处于阻塞状态的线程来读取数据。每次读取完数据之后都会通知阻塞的写线程:数据已经被读取走。
在队列调度的策略上,SynchronousQueue支持两种策略:公平调度策略与非公平调度策略,公平策略保证了线程执行的及时性,非公平策略保证了队列的吞吐量,默认采用的是非公平策略。公平的调度策略是通过FIFO队列来实现的,非公平的调度策略是通过后进先出的栈来实现的。
1. 公平调度策略
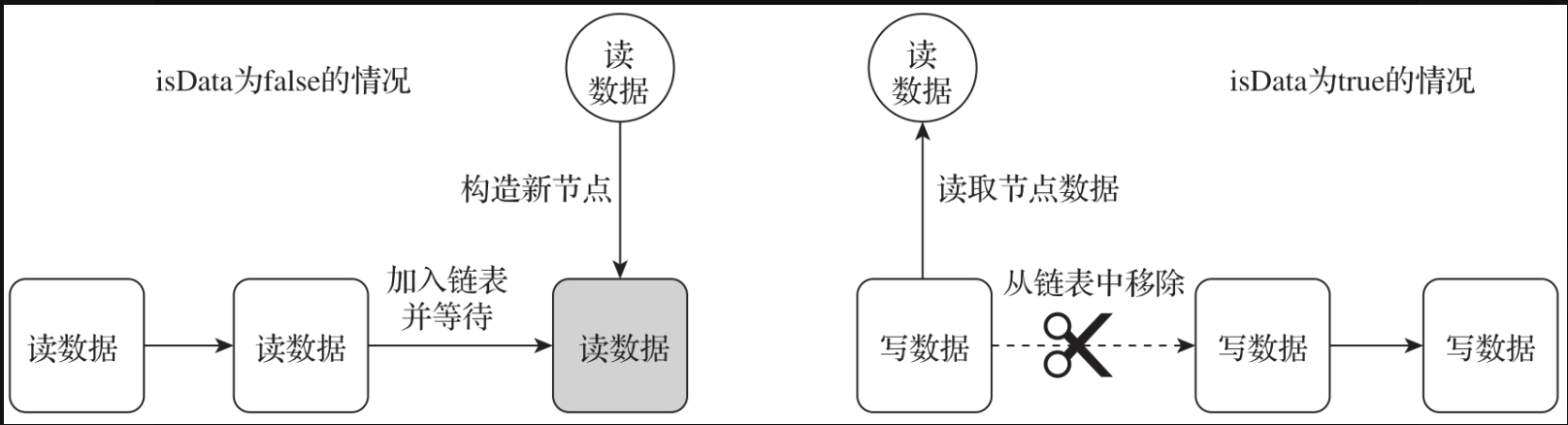
如图所示,公平策略的QNode在基础节点上进行了扩充,增加了一个isData属性来表示操作类型:当isData为false,表示读操作;当isData为true,表示写操作。这里有一个细节需要读者重点关注:队列中的所有节点的isData值要么都为true,要么都为false。
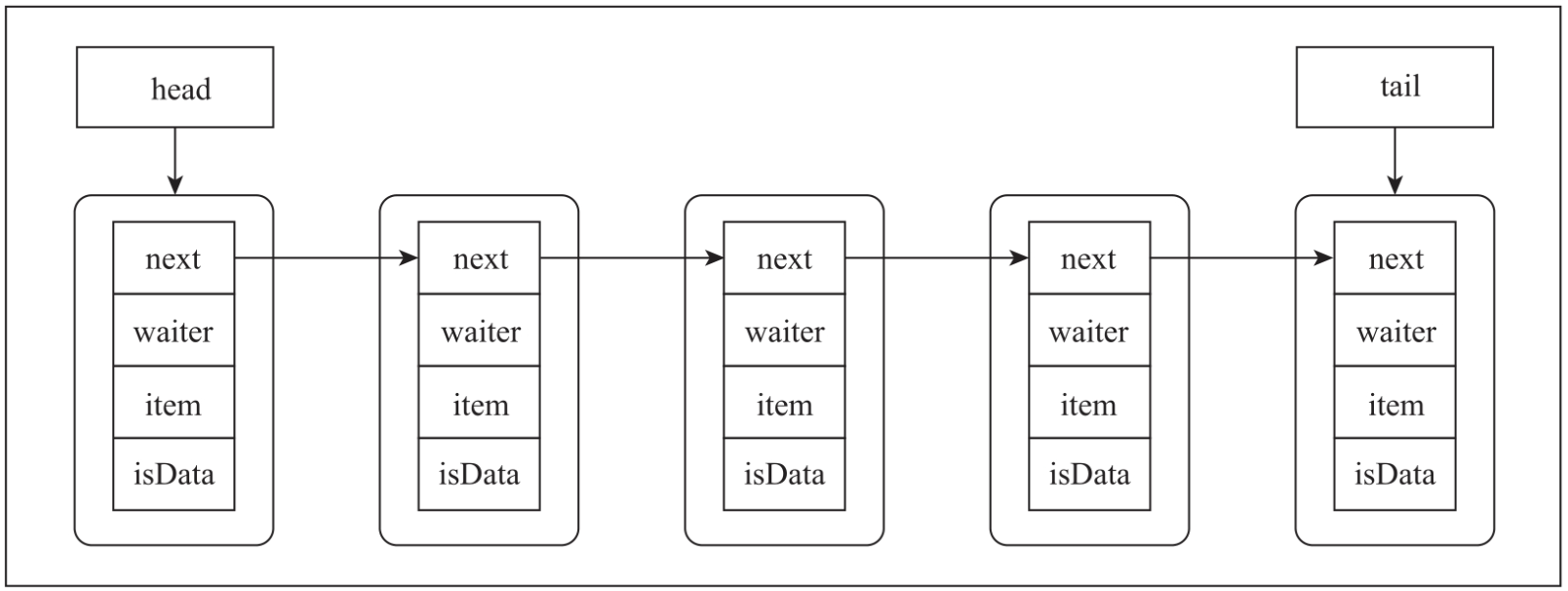
数据插入时,会先判断tail节点的操作类型。如果tail节点是写节点,则将当前节点加入链表中进行等待。如果tail节点为读节点,则将链表的head节点移除,并唤醒head节点读取线程,同时将当前节点的数据直接传递给读线程。下图是公平策略的数据写入请求的处理流程。
读取数据时,会先判断tail节点的操作类型。如果tail节点是读节点,则直接将当前线程加入链表中进行等待;如果tail节点是写节点,则移除链表的head节点、唤醒写入线程,将head节点的数据传递给当前线程。下图是利用公平策略处理数据读取请求的流程。
2. 非公平调度策略
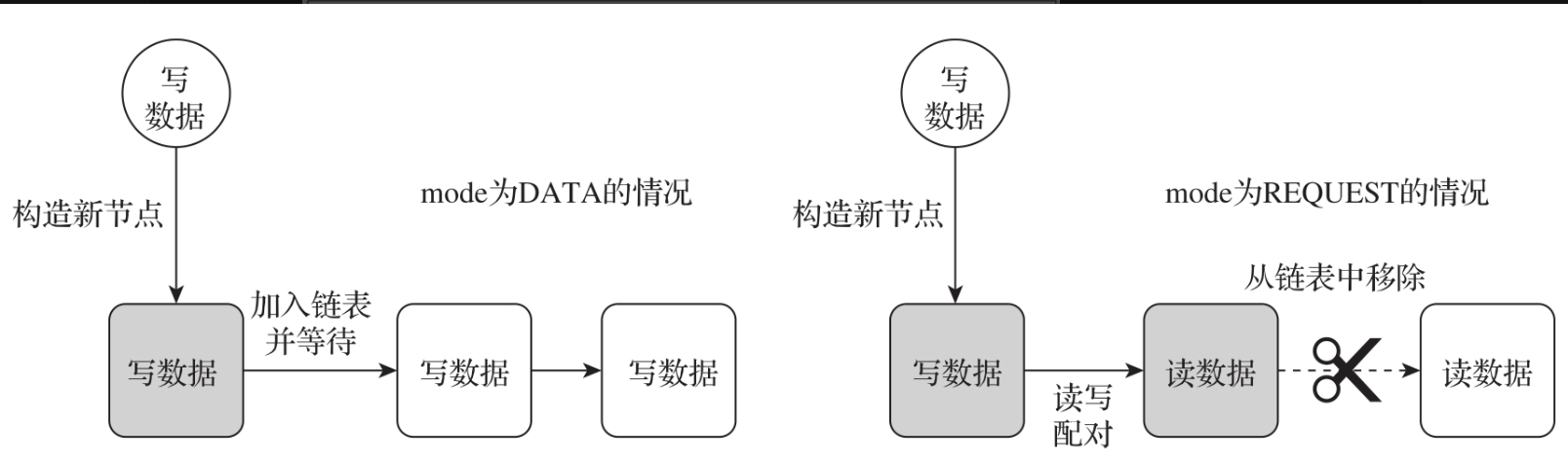
QNode定义了mode属性来表示节点的状态。mode字段有3种状态:REQUEST表示读的请求,DATA表示写的请求,FULFILLING表示正从队列中移除瞬时状态。注意,栈中所有节点的mode值要么都是REQUEST,要么都是DATA,只有head节点在移除的一瞬间会存在FULFILLING状态。非公平策略数据结构如图所示。
如下图所示,每次数据插入都要判断head节点的操作类型。如果head节点是写节点,则直接将当前线程加入链表中进行等待;如果head节点是读节点,则先将当前线程加入栈中,然后将当前线程的写数据传递给head节点,最后将head节点从队列中移除。如果head节点的mode值为FULFILLING状态,那么表示有线程正在完成读写配对,当前线程需要循环等待。
6.2、源码分析
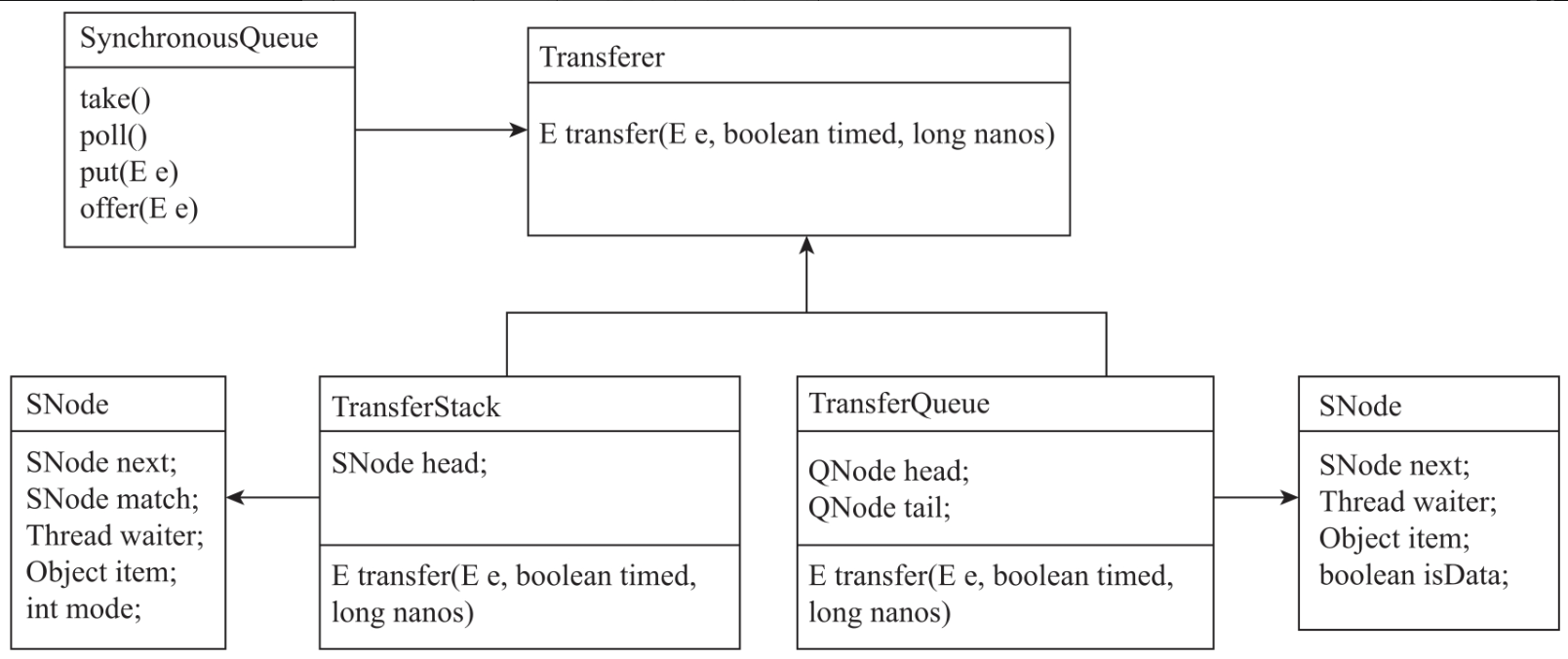
SynchronousQueue在内部定义了抽象类Transferer,作为公平与非公平调度策略的基础类。TransferQueue是公平调度策略的具体实现类,TransferStack是非公平策略的具体实现类,其UML图如图所示。
Transferer定义了数据修改与查询的基础方法transfer,如代码所示。有个点需要注意:插入与查询都是同一个方法:数据插入时,e为具体的数据值;数据查询时,e为null。

1. 非公平调度策略
TransferStack是非公平调度策略具体实现类,它是基于单向链表实现的数据栈。SNode是链表的数据节点,如代码所示。SNode定义了next、match、waiter、item、mode等属性。next指针指向当前节点的后继节点。match指针指向与当前节点配对的节点,相互配对的两个节点:一个是读节点,另一个是写节点。waiter是当前节点的操作线程。item是数据值:如果是读节点,item为null;如果是写节点,item是具体写入的数据值。mode是当前节点的操作模式:如果是读节点,mode值是REQUEST;如果是写节点,mode值是DATA。


transfer方法是非公平调度策略的核心方法,如代码所示。数据写入的时候,e为数据值;数据读取时,e为null,而timed和nanos指定是否使用超时设置。



transfer方法会遇到3种情况。
- 如果头节点的模式与当前节点的模式相同,transfer方法会将当前节点加入栈中,并调用LockSupport的park方法将当前线程阻塞。
- 如果头节点的模式与当前节点的模式不同,transfer方法会将头节点与当前节点配对,然后将头节点移出栈。
- 如果头节点已经与其他线程配对,transfer方法会协助其他线程完成配置。
2. 公平调度策略
TransferQueue是公平调度策略的具体实现,是一种基于FIFO原则的队列结构。QNode是链表的数据节点,定义了next、item、waiter、isData等属性,如代码所示。next指针指向当前节点的后继节点。item是当前节点的数据值:如果是读节点,item为null;如果是写节点,item是写入的数据值。waiter是操作当前节点的线程。isData是节点的操作模式:如果是读节点,isData值是false;如果是写节点,isData的值是true。

transfer方法是公平调度策略的核心方法,从队列中读取数据与往队列中写入数据都是同一个方法,如代码所示。数据写入时,e为具体数据值,数据读取时,e为null,而timed和nanos指定是否使用超时。


3. 队列初始化
SynchronousQueue提供了两种构造函数:一种是带指定调度策略的构造函数,另一种是默认的构造函数。指定调度策略的可以根据传入的fair参数构建公平与非公平的调度策略。默认的构造函数则采用非公平的调度策略。
4. 数据插入
数据插入是通过调用transferer实例的transfer方法来实现的。数据插入实现如代码所示。

5. 数据读取
数据读取也是通过调用transferer实例的transfer方法来实现的,传入的参数e为null。数据读取实现如代码所示。

7、LinkedBlockingDeque实现原理
LinkedBlockingDeque是基于双向链表数据结构实现的双端并发阻塞队列,它同时支持FIFO和FILO两种操作方式,可以从队列的头和尾同时进行线程安全的数据插入与删除。同时,它还是有界队列,可以指定队列的长度,默认的容量大小是Integer.MAX_VALUE,这样就能够防止队列过度膨胀导致内存溢出。
LinkedBlockingDeque提供了线程安全的双端数据读取与修改的方法。
头部节点的操作方法如表所示。

尾部节点的操作方法如表所示。

7.1、设计原理
LinkedBlockingDeque在数据结构上采用了双向链表,它定义了2个指针:first指针与last指针,first指针指向队列的头节点,last指针指向队列的尾节点。
队列中每个节点有2个指针:next指针与prev指针,next指针指向后继节点,prev指针指向前驱节点。数据结构如图所示。
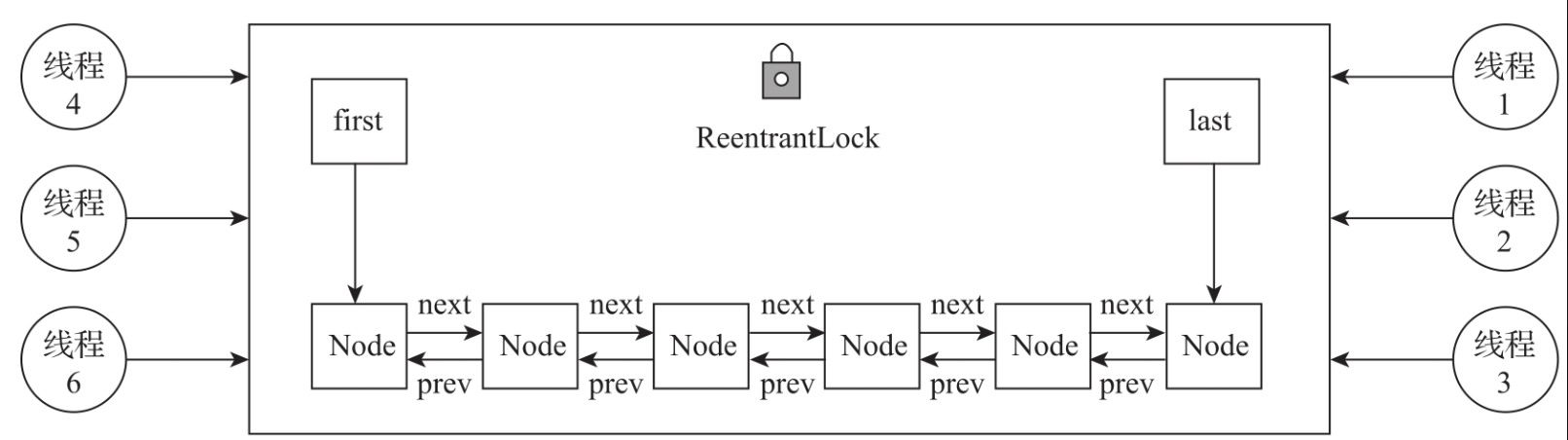
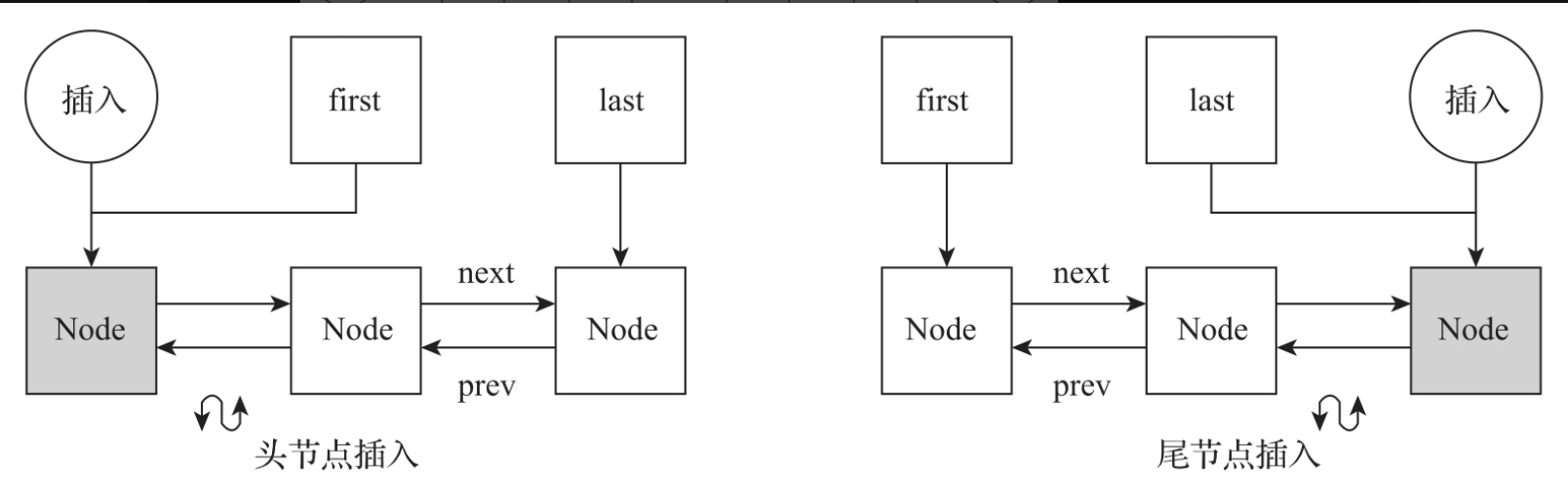
向队列头部插入数据时,LinkedBlockingDeque先获取到first指针,然后将构建的新节点插入到原有的fisrt指针前面,并将first指针迁移指向新插入的节点。
向队列尾部插入数据时,LinkedBlockingDeque先获取到last指针指向的尾节点,然后将尾节点的next指针指向新加入的节点,并将last指针指向最后插入的节点。数据插入过程如图所示。
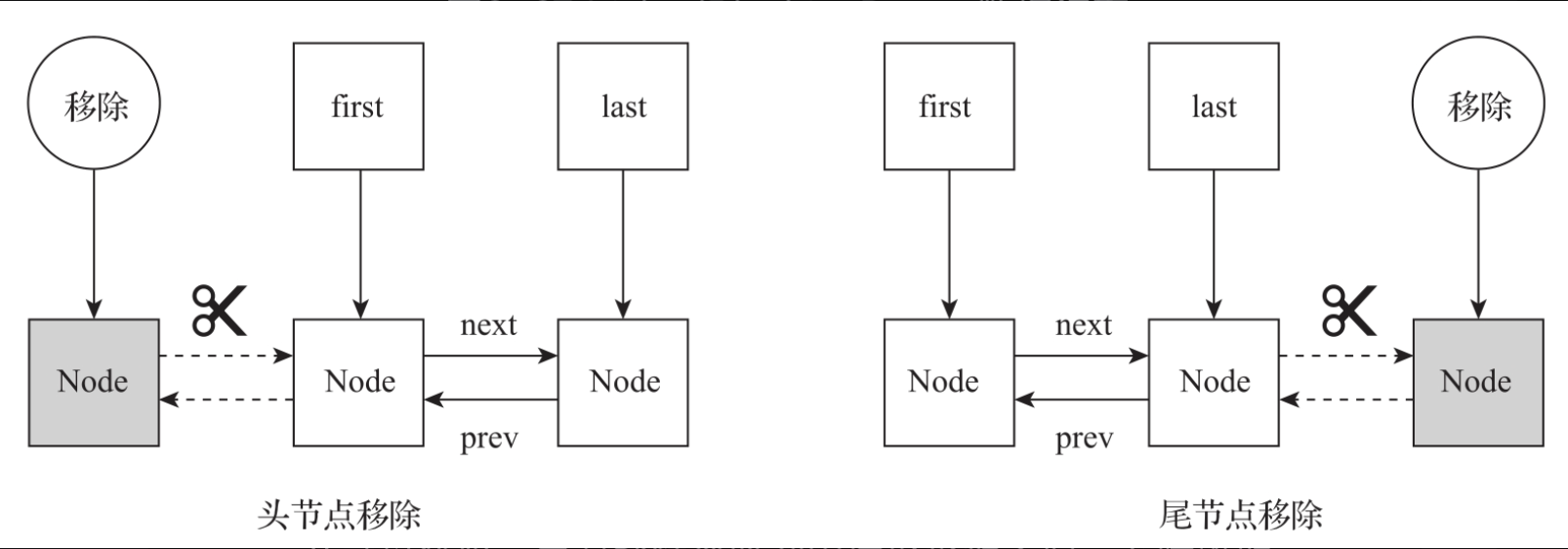
从队列头部读取数据时,LinkedBlockingDeque会先将头节点从队列中移除,然后将first指针后移一位指向头节点的后继节点。
从队列尾部读取数据时,LinkedBlockingDeque先将尾节点从队列中移除,然后将last指针前移一位,指向尾节点的前驱节点。数据读取过程如图所示。
LinkedBlockingDeque是通过ReentrantLock锁来实现并发控制的。队列的增、删、查、改等操作都需要先获取锁。在任一时刻只有一个线程能对队列进行操作,从而实现线程安全。
在插入数据时,如果队列已经满了,所有插入线程都会进入等待状态。当有线程从队列中读取数据之后,会唤醒阻塞的线程继续执行数据插入操作。
在读取数据时,如果队列空了,所有读取数据的线程都会进入阻塞,当有线程向队列中插入数据之后,会唤醒阻塞的线程继续执行数据读取操作。
7.2、源码分析
Node是双向链表中的节点,它内部定义了3个属性:item、prev、next,item用来存储数据,next是后继节点指针,prev是前驱节点指针,如代码所示。

LinkedBlockingDeque内部定义了2个全局指针:first与last。first指向队列的头部,last指向队列的尾部。
1. 变量定义
LinkedBlockingDeque定义了ReentrantLock实例lock来进行并发控制。LinkedBlocking-Deque定义了2个等待条件:notEmpty与notFull,notEmpty表示队列不为空,notFull表示队列没有满。它还定义了2个变量:capacity与count。capacity表示队列的容量,count表示队列当前的数据个数。count等于capacity,表示队列已经满了;count为0,表示队列是空的。每次添加元素都会将count加1,每次移除元素都会将count减1。并发控制的变量定义如代码所示。

2. 在队尾插入数据
向队尾插入数据时,LinkedBlockingDeque先会构建一个新的Node,然后调用Reentrant-Lock的lock方法获取独占锁,最后调用linkLast方法将Node加入队列。如果队列满了,就阻塞当前线程。代码是在队尾插入数据的具体实现。

linkLast方法是将指定Node插入到队列的尾部。linkLast方法在尾指针last后面插入一个新的Node。如果队列满了,那么直接返回false;如果插入成功,它会将队列数量count加1,然后尝试唤醒等待的消费线程,并返回true。如下代码是linkLast方法的实现。

3. 从队尾读取数据
从队尾读取数据时,LinkedBlockingDeque先会调用ReentrantLock的lock方法获取独占锁。如果成功地获取到锁,它会调用unlinkLast方法移除队列的尾节点。代码是从尾部读取数据的实现。

unlinkLast方法用于删除队列尾部的元素。该方法会先判断队列是否为空:如果队列为空,直接返回null;如果队列不为空,则获取last指针的前驱节点,并将last指针指向它的前驱节点,最后移除队尾节点。如果移除成功,它会将队列数量count减1,然后尝试唤醒等待的消费线程,并返回最后一个节点的值。unlinkLast方法实现如代码所示。

4. 在队头插入数据
在向队头插入数据时,LinkedBlockingDeque先会获取独占锁。成功获取锁之后,它会调用linkFirst方法将新的节点插入队列头部。如果插入成功,直接返回。如果队列已经满了,则进行等待。当其他线程从队列中移除元素后,会调用signal、signalAll方法唤醒当前线程,当前线程被唤醒会继续执行插入操作。代码是在队列头部插入数据的实现。


linkFirst方法功能是将节点插入到队列的头部。它先会判断队列是否已经满了,如果队列满了返回false。如果队列没满,将新的节点next指针指向头节点,并将头节点的prev指针指向新添加的节点。最后把first指针指向新加的节点。最后将队列数量count加1,然后触发notEmpty等待条件的信号,唤醒等待的线程,最后返回true。在队头插入数据的实现如代码所示。

5. 从队头读取数据
takeFirst方法的功能是获取并移除此队列的头部数据。它首先会获取独占锁。成功获取独占锁之后,它会调用unlinkFirst方法移除队列头部数据。unlinkFirst方法返回null表示队列为空,需要调用notEmpty等待条件await方法让当前线程进入等待。当其他线程往队列中插入数据之后,会调用signal、signalAll方法唤醒当前线程,当前线程被唤醒后会接着执行unlinkFirst方法。从队头读取数据的实现如代码所示。


unlinkFirst方法用于移除队列的头节点,如代码所示。

LinkedBlockingDeque可以看作LinkedList集合的线程安全的实现类,支持队头和队尾的数据插入和删除操作,是一个双端操作的队列。它在内部定义了一个ReentrantLock的独占锁,所有对队列的插入、删除、查询等操作都需要获取这个独占锁,因为要通过独占锁来确保线程安全。