做 CreatorWeave 的时候,有个问题绕不过去:WebMCP 工具越来越多,LLM 放不下了。
一个 SaaS 协作平台接入 WebMCP 后可能有 30+ 个工具,每个工具的 JSON Schema 平均 200 token。再加上 CreatorWeave 自带的 30 多个内置工具,一轮对话要发 60+ 个 tool definitions 给 LLM。
这带来两个硬限制:
1. LLM 的 tools 数量有上限 --- OpenAI 的 function calling 最多支持 128 个工具,Claude 也有限制。当多个 WebMCP 站点同时打开,工具数量轻松破百,直接超出 API 限制,调用报错。
2. Token 浪费严重 --- Agent 在一轮对话里可能只调 1-2 个工具,但你得把所有工具的完整 Schema 都发过去。就像你去餐厅点一个菜,服务员把整本菜单念给你听。
更不要说未来 Notion、Figma、飞书都接入 WebMCP------一个工作场景里同时打开 3 个站点,100 个工具,每轮对话光工具定义就 2 万 token。这谁扛得住?
我翻遍了掘金上的 WebMCP 文章,清一色的 registerTool 示例------每个工具注册一个 definition,老老实实发给 LLM。没有一篇讨论过工具数量膨胀的问题。
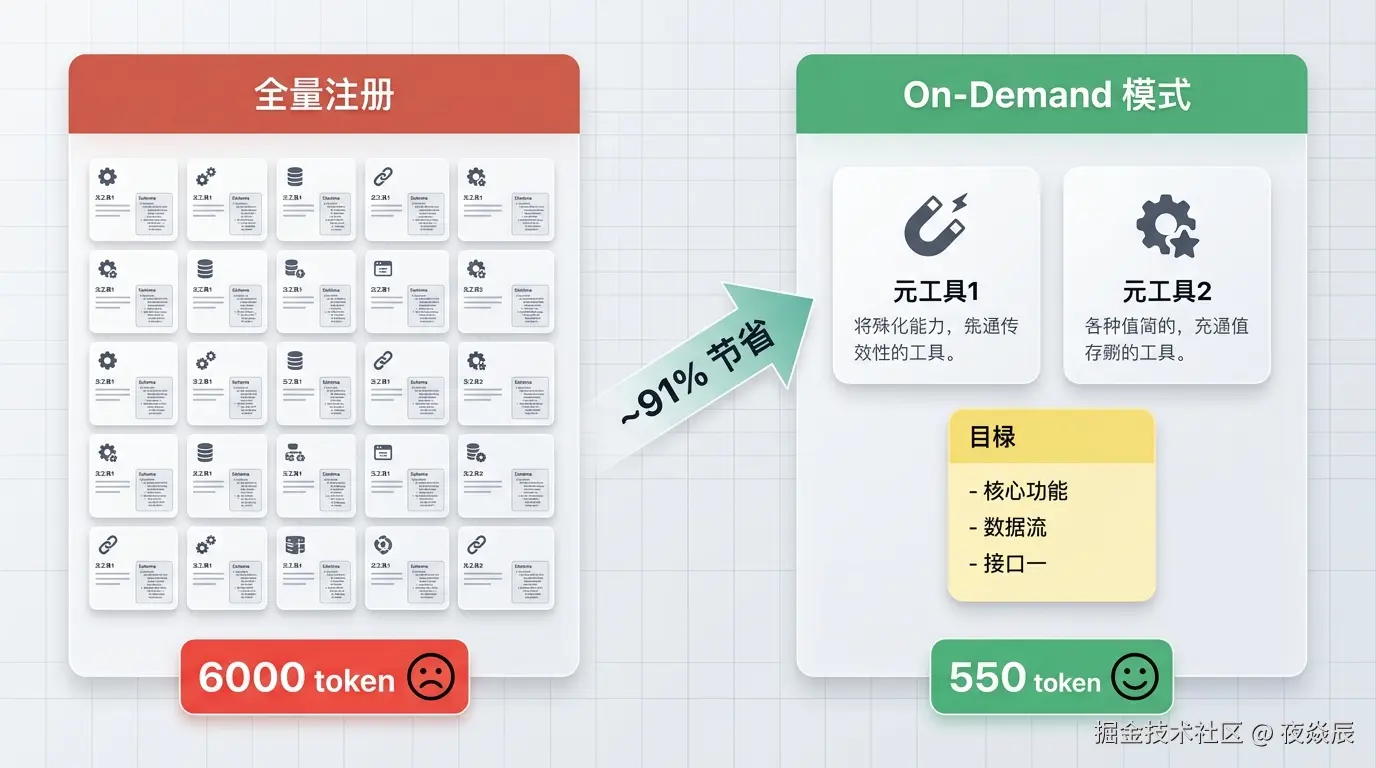
所以我换了个思路:不注册 N 个工具,只注册 2 个"元工具",用它们代理 N 个工具。
这个方案我叫它 On-Demand 模式。
先说问题:为什么全量注册不行
传统做法(也是掘金所有文章教你的做法):
javascript
发现 31 个 WebMCP 工具
↓
注册 31 个 ToolDefinition
↓
每轮对话把 31 个 JSON Schema 发给 LLM
↓
LLM 看到一长串工具列表,选择调用哪个这个模式有三个问题:
1. Token 浪费严重
Agent 在一轮对话里可能只调 1-2 个工具,但你得把 31 个工具的完整 Schema 都发过去。就像你去餐厅点一个菜,服务员把整本菜单念给你听。
2. 注册/注销频繁
WebMCP 工具的生命周期跟浏览器 Tab 绑定------用户打开一个网页,工具出现;关掉网页,工具消失。频繁注册/注销 31 个工具,对 ToolRegistry 的压力不小。
3. 工具列表污染
当 LLM 看到 31 个 WebMCP 工具 + 30 个内置工具 = 61 个工具时,工具选择的准确率会下降。选项越多,选错的概率越高。
On-Demand 模式:用目录 + 元工具替代全量注册
核心思想很简单:不让 LLM 直接看到所有工具的完整 Schema,而是给它一个"目录",它需要哪个再查哪个。
css
传统模式:
LLM 看到 31 个工具 → [完整 Schema × 31] → 选择调用
On-Demand 模式:
LLM 看到 2 个工具 + 1 个目录 → 扫目录选工具 → 查 Schema → 调用具体实现是这样的:
第一步:在 System Prompt 里注入一个轻量目录
不是 31 个完整的 JSON Schema,而是一个 XML 格式的"电话簿"------每个工具只有名字和一句话描述:
xml
<available_webmcp>
<server hostname="collab.example.com" title="协作平台">
<tool name="collab_example_com__search_tasks">
Search tasks by title, assignee, or status.
</tool>
<tool name="collab_example_com__create_task">
Create a new task with title and assignee.
</tool>
<tool name="collab_example_com__send_message">
Send a message to a team channel.
</tool>
<!-- ... 27 more tools, each just name + one-line description -->
</server>
</available_webmcp>31 个工具,每个大约 15 token,总共 ~465 token。比 6200 token 少了一个数量级。
第二步:注册 2 个元工具
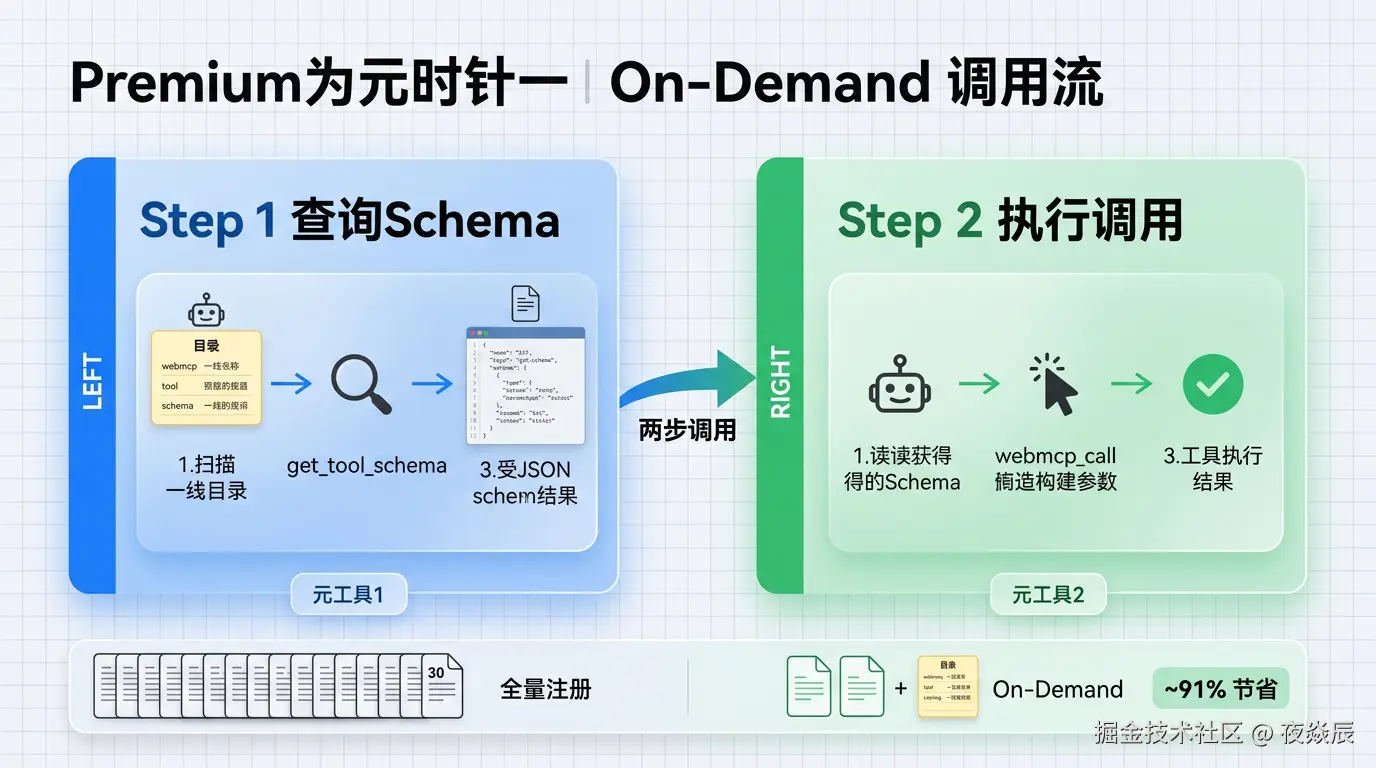
不管你有多少个 WebMCP 工具,LLM 永远只看到这 2 个:
typescript
const ON_DEMAND_TOOLS = [
{
name: 'webmcp_get_tool_schema',
description: 'Get the full parameter schema for WebMCP tools by their exact names.',
parameters: {
full_tool_names: string[] // 想查哪些工具的 Schema
}
},
{
name: 'webmcp_call',
description: 'Execute a WebMCP tool with the provided arguments.',
parameters: {
full_tool_name: string, // 要调哪个工具
args: object // 工具参数(必须先用 get_tool_schema 获取 Schema)
}
}
]第三步:LLM 的两步调用
vbnet
LLM 想给协作平台发消息
↓
Step 1:扫描 <available_webmcp> 目录
→ 找到 "collab_example_com__send_message"
→ "Send a message to a team channel."
↓
Step 2:调用 webmcp_get_tool_schema
→ 获取完整 Schema:{ channel_id: string, content: string, ... }
↓
Step 3:根据 Schema 构造参数,调用 webmcp_call
→ 执行工具,拿到结果Token 对比
| 全量注册 | On-Demand 模式 | |
|---|---|---|
| Tool Definitions | 30 × 200 = 6000 token | 2 × 50 = 100 token |
| Catalog 注入 | 无 | 30 × 15 = 450 token |
| 总计 | 6000 token | 550 token |
| 节省 | --- | ~91% |
而且这是每轮对话都省------因为 tool definitions 和 catalog 都在 system prompt 里,每一轮 API 调用都会发送。
怎么发现的:浏览器 Tab 扫描
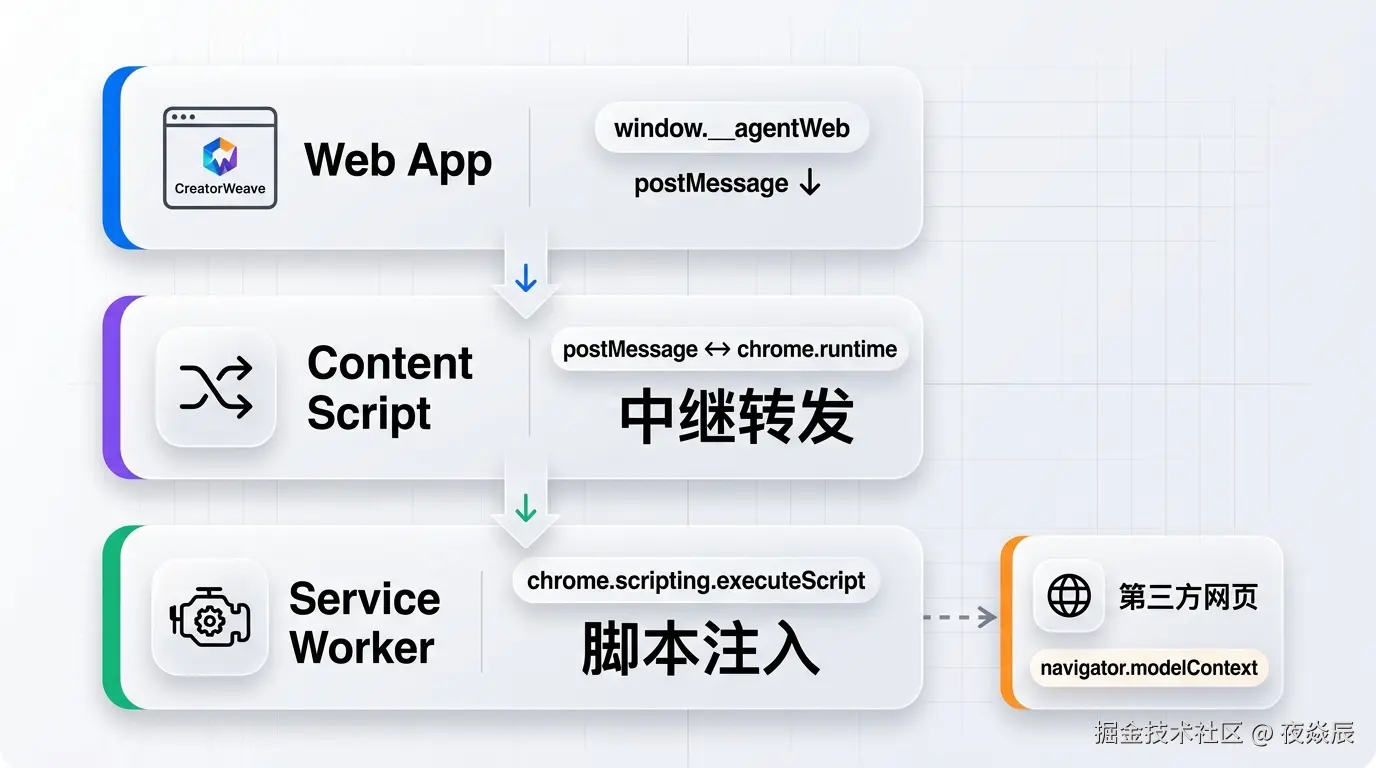
WebMCP 工具不在本地,也不在服务器上------它们活在浏览器 Tab 里。
第三方网站(比如协作平台、项目管理工具)在页面里调用 navigator.modelContext.registerTool() 注册工具。我们的浏览器扩展负责扫描所有 Tab,发现这些工具。
三层桥接架构
css
CreatorWeave Web App
│ window.__agentWeb(注入的桥接对象)
│ window.postMessage
▼
Content Script(ISOLATED world)
│ chrome.runtime.sendMessage / Port
▼
Background Service Worker
│ chrome.scripting.executeScript({ world: 'MAIN' })
▼
第三方网页 Tab
navigator.modelContext.getTools()为什么要绕三层?因为 WebMCP API 只在 MAIN world 可用,但浏览器扩展的 Service Worker 跑在独立的沙盒里,中间需要一个 Content Script 做中继。
扫描逻辑
typescript
// 并行扫描当前窗口的所有 Tab
const scanResults = await Promise.allSettled(
validTabs.map(async (tab) => {
// 每个 Tab 注入脚本,探测 navigator.modelContext API
const result = await chrome.scripting.executeScript({
target: { tabId: tab.id },
world: 'MAIN',
func: () => {
// 优先用正式 API,回退到测试 API
if (navigator.modelContext) {
return navigator.modelContext.getTools()
}
if (navigator.modelContextTesting) {
return navigator.modelContextTesting.listTools()
}
return null // 这个 Tab 没有 WebMCP 工具
}
})
return { tab, hostname, result }
})
)每个 Tab 有 5 秒超时,防止某个页面卡住影响整体扫描。
工具名规范化
发现的工具需要跨 Tab 去重和路由。工具名格式:{hostname}__{toolName}。
vbnet
hostname: "collab.example.com"
toolName: "search_tasks"
→ fullName: "collab_example_com__search_tasks"名字太长(>64 字符)怎么办?截断 + FNV-1a hash 后缀保唯一性。
怎么调用的:路由缓存 + 脚本注入
发现是发现了,但调用的时候怎么找到目标 Tab?
路由缓存
扫描时记录 fullName → { tabId, hostname, toolName } 的映射:
typescript
const recentRouteByToolName = new Map<string, RouteEntry>()调用时先查缓存,缓存命中就直接路由到对应 Tab。缓存miss?重新扫描一次。
执行链路
php
LLM 调用 webmcp_call("collab_example_com__send_message", { channel_id: "general", content: "你好" })
↓
Executor 查路由缓存 → 找到 tabId=42, hostname, toolName
↓
bridge.webMCPInvoke() → postMessage → Content Script 中继 → Service Worker
↓
chrome.scripting.executeScript({
target: { tabId: 42 },
world: 'MAIN',
func: (toolName, inputJson) => {
return navigator.modelContext.executeTool(toolName, inputJson)
},
args: ["send_message", '{"channel_id":"general","content":"你好"}']
})
↓
协作平台页面执行工具 → 返回结果
↓
结果原路返回 → LLM 看到 "消息发送成功"大文件怎么办:Plugin Download 分块传输
有些工具返回的不只是文本------比如协作平台的文件下载,一个文件可能几十 MB。
浏览器扩展的 Service Worker 和 Web App 之间的消息有大小限制。所以大文件需要分块传输:
bash
工具返回 { plugin_download: true, download_url: "https://...", file_name: "report.xlsx" }
↓
扩展端 fetch 下载文件 → ArrayBuffer → base64 → data URL
↓
按 256KB 切片,通过 Port 流式传输
↓
帧协议:
{ type: 'start', totalChunks: 47, fileName: 'report.xlsx' }
{ type: 'chunk', index: 0, data: 'data:application/...' }
{ type: 'chunk', index: 1, data: '...' }
...
{ type: 'end' }
↓
Web App 端收集所有 chunk → 拼接 data URL → Blob
↓
写入 OPFS(vfs://assets/report.xlsx)
↓
返回给 Agent:{ ok: true, path: 'vfs://assets/report.xlsx' }为什么要转到 OPFS?因为 Agent 后续可能要用 read 工具读取这个文件。OPFS 是 Agent 的工作空间,文件在那里才能被其他工具访问。
注册/注销的生命周期管理
WebMCP 工具的生命周期和 Tab 绑定,所以需要动态管理:
| 事件 | 动作 |
|---|---|
| App 启动 | 启动 15 秒间隔的定时同步循环 |
| Agent Loop 每轮开始 | 调用 registerWebMCPTools() 同步最新 catalog |
| 用户打开/关闭网页 Tab | 15 秒内自动发现/移除 |
| 用户开启/关闭 WebMCP 开关 | 立即注册/注销 |
| 用户开启/关闭某个 Host | 只更新 catalog,2 个元工具不动 |
关键设计:On-Demand 模式下,开关某个 Host 不需要注册/注销工具------因为只有 2 个元工具是始终注册的,Host 的开关只影响 catalog 数据的过滤。这比全量注册模式优雅得多。
和 MCP 的本质区别
| MCP | WebMCP (我们的方案) | |
|---|---|---|
| 运行环境 | 独立进程(Node.js/Python Server) | 浏览器 Tab(第三方网页) |
| 连接方式 | 配置 Server URL,WebSocket/SSE | 零配置,Tab 扫描自动发现 |
| 工具注册 | 全量:N 个工具 → N 个 Definition | On-Demand:N 个工具 → 2 个元工具 |
| Token 开销 | O(N × schema_size) | O(2 + N × description_size) |
| 生命周期 | 持久连接,手动启停 | 随 Tab 生灭,自动管理 |
| 大文件传输 | 直接读写文件系统 | 分块流式传输到 OPFS |
| 适用场景 | 本地工具(数据库、Git 等) | Web 产品(SaaS 工具、在线服务) |
MCP 是"自己家"的工具------跑在本地,稳定可控。WebMCP 是"邻居家"的工具------跑在别人的网页里,随时可能消失。所以 WebMCP 需要更灵活的发现和调用机制。
踩过的坑
1. Tab 扫描不能串行
一开始我串行扫描每个 Tab,10 个 Tab 要 50 秒。改成 Promise.allSettled 并行扫描后,总耗时约等于最慢的那个 Tab(通常 3-5 秒)。
2. Content Script 的世界隔离
浏览器扩展有 MAIN world 和 ISOLATED world。WebMCP API 只在 MAIN world 可用,但 chrome.scripting.executeScript 默认跑在 ISOLATED world。必须显式指定 world: 'MAIN'。
而 Content Script(ISOLATED world)和 MAIN world 之间只能通过 window.postMessage 通信。所以桥接必须是三层:injected script (MAIN) → content script (ISOLATED) → service worker。
3. 工具名冲突
不同网站可能有同名工具(比如都叫 search)。用 hostname__toolName 格式确保全局唯一。但有些网站的 hostname 很长,工具名也长,加起来超过 64 字符。解决方案:截断 hostname,加 FNV-1a hash 后缀。
4. LLM 有时会跳过 get_tool_schema
偶尔 LLM 会自作聪明,不看 Schema 就直接调用 webmcp_call,参数格式肯定不对。解决方案:在 webmcp_call 的描述里明确写了 "You MUST call webmcp_get_tool_schema first to get the complete input schema"。同时 executor 里做了 Zod schema 验证,参数不对就报错让 LLM 重新来。
用 CreatorWeave 能对接哪些网站
WebMCP 生态正在快速生长。只要网站用 navigator.modelContext.registerTool() 注册了工具,CreatorWeave 就能自动发现并调用------零配置,打开网页就行。
目前已经接入或可以对接的典型场景:
| 场景 | 例子 | Agent 能干什么 |
|---|---|---|
| 项目管理 | 看板、任务追踪 | 创建任务、分配负责人、更新状态、搜索工单 |
| 文档协作 | 在线文档、笔记 | 读取文档、搜索内容、创建页面 |
| 日程管理 | 日历应用 | 创建日程、查询空闲时间、设置提醒 |
| 电商 | 商城、订单系统 | 搜索商品、查询订单、管理库存 |
| 数据分析 | 数据库查询、可视化 | 执行查询、生成图表、导出报告 |
| 客服 | 工单系统、IM | 查看工单、回复消息、更新状态 |
| CMS | WordPress、Wix | 发布文章、管理页面、处理表单 |
生态还在快速扩展中。awesome-webmcp 仓库维护了一份完整的资源列表,包括 Demo 应用、框架库、浏览器扩展、平台集成等。
不只是使用,还是 WebMCP 的测试工具
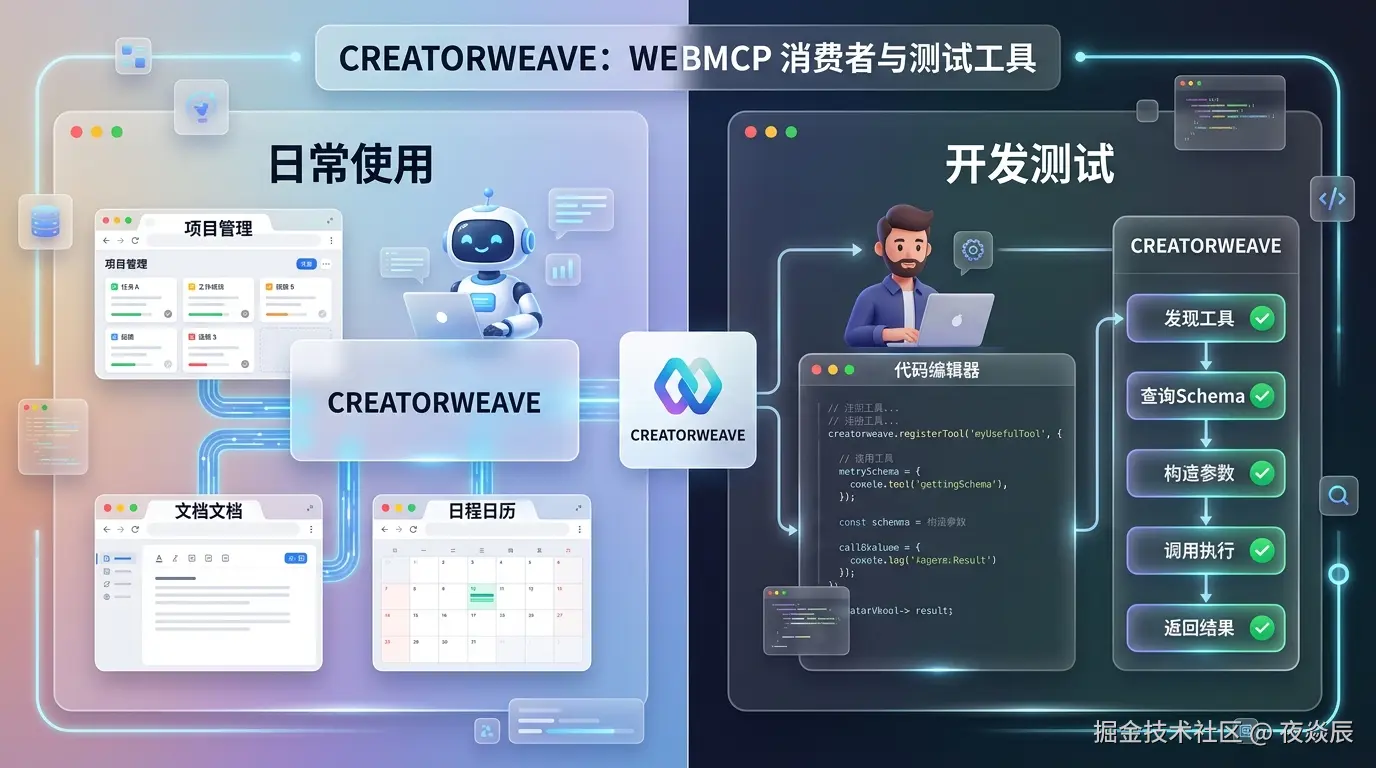
如果你是正在给网站接入 WebMCP 的开发者,CreatorWeave 还有一个隐藏用法:它是目前最好用的 WebMCP 端到端测试工具。
你在网站上加了 registerTool(),怎么验证工具能不能被 Agent 正确发现和调用?目前的做法要么是手动在 DevTools 里敲代码,要么装一个专门的调试扩展,而且只能测试单个工具调用------看不到 Agent 的完整决策过程。
用 CreatorWeave 就简单了:
- 打开你的网站 Tab
- 打开 CreatorWeave
- 在对话里说 "帮我测试一下这个网站的工具"
- Agent 自动扫描发现 → 查 Schema → 构造参数 → 调用 → 返回结果
你能看到完整的两步调用链路:Agent 怎么从目录里选工具、怎么获取 Schema、怎么构造参数、调用结果是什么。每个环节都可视化为卡片,一目了然。
这比任何专门的调试工具都直观------因为你看到的是一个真实 Agent 的完整决策过程,不是孤立的 API 调用。
关键是:你的网站还没接入 WebMCP 也不要紧。 CreatorWeave 的 On-Demand 模式天然支持增量接入------今天有 3 个站点可用,明天多了一个,15 秒内自动发现,不需要改任何配置。
学到了什么
- 不要给 LLM 发它不需要的东西 --- 30 个工具的完整 Schema,Agent 可能一个都不会调。On-Demand 模式让 LLM 按需获取,省 91% token
- Tab 就是天然的沙盒 --- 第三方网站的工具跑在自己的 Tab 里,不需要额外的隔离机制,浏览器帮你隔离了
- 目录比清单好 --- 给 LLM 一个精简的"目录"(名字 + 一句话描述),比给一长串完整 Schema 更容易选择
- 三层桥接不是过度设计,是必须的 --- 浏览器的安全模型决定了你必须这么绕
- WebMCP 和 MCP 不是替代关系,是互补 --- MCP 管"本地",WebMCP 管"云端",两者并存才能覆盖所有场景
🔗 链接:
- CreatorWeave:github.com/nutstore/cr...
- 在线体验:creatorweave.eo2suite.cn
- WebMCP 规范:Chrome WebMCP Origin Trial
如果觉得 On-Demand 模式有意思,点个赞让更多人看到。你在用 WebMCP 的时候遇到过工具数量膨胀的问题吗?怎么解决的?欢迎评论区聊聊。