内存分配是操作系统中最基础也最容易被误解的话题之一。很多开发者熟悉 malloc,也知道 kmalloc,但对两者在调用链上的本质差异、设计取舍和边界行为并不清晰。本文从函数调用级别展开,逐层剥开两套分配体系的实现细节,帮助建立清晰的思维映像。
由于版本和架构的差异,使用文中涉及对象数值时需查询源码或手册核实
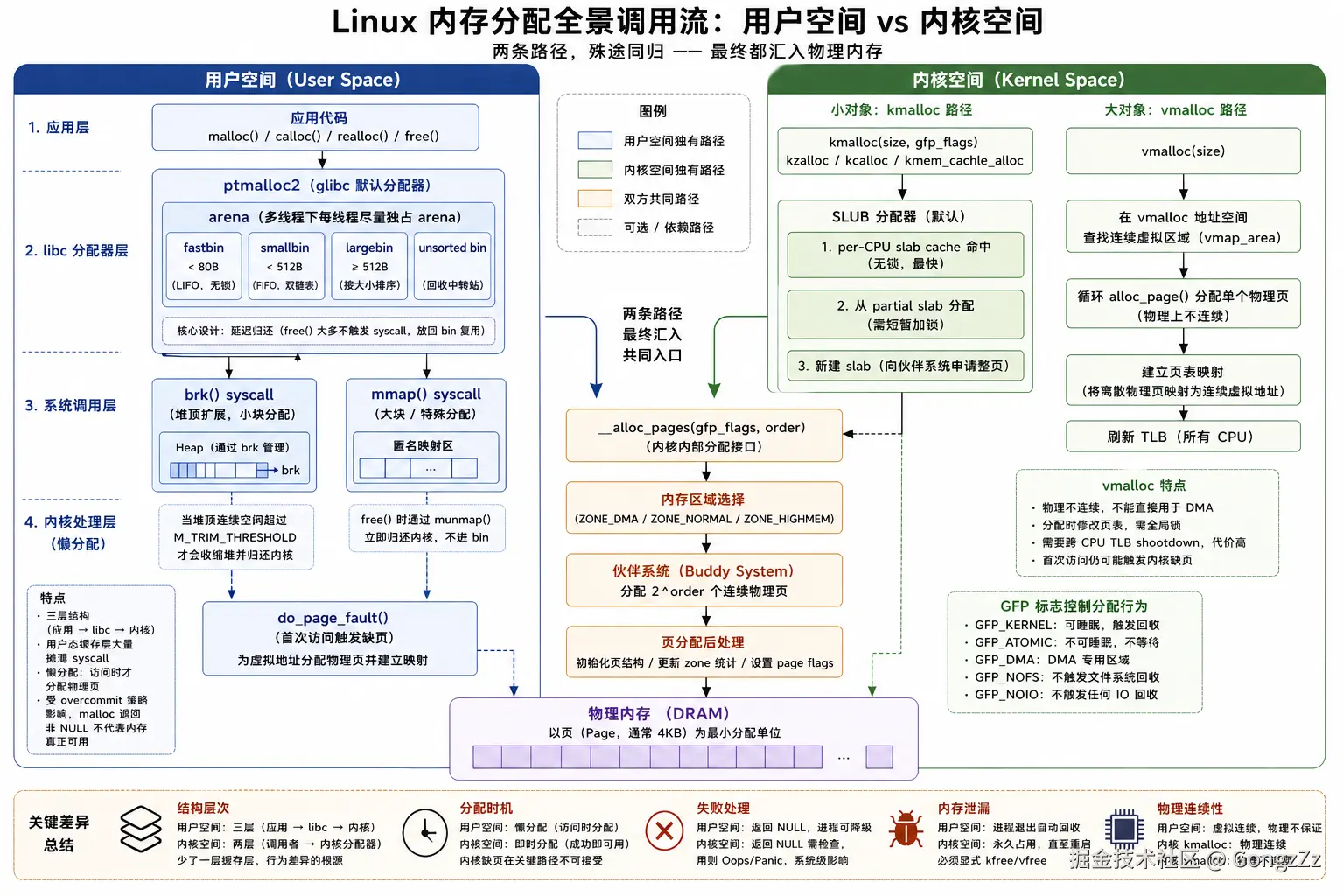
一、核心差异一句话
用户空间分配依赖 C 库封装(malloc → brk/mmap),存在用户态管理层做缓冲,syscall 次数被大幅摊薄;内核空间直接调用内核内部接口(kmalloc/vmalloc),无中间缓冲层,速度更快,但失败不可依赖 page fault 自动恢复,错误处理责任完全落在调用者身上。
把这句话展开一步:用户空间是三层结构(应用 → libc 分配器 → 内核 ),内核空间是两层结构(调用者 → 分配器/伙伴系统)。少掉的这一层不是微小的实现细节,而是两套体系在行为上产生一切差异的根源。libc 向内核批量拿内存,自己切割管理,内核对应用的大量 malloc/free 动作一无所知。内核空间没有这个缓冲层,SLUB 的 per-CPU slab cache 在热路径上有类似缓冲的效果,但它只缓存固定尺寸的 slot,不做通用的 chunk 切割与合并,语义完全不同。
二、用户空间分配调用链
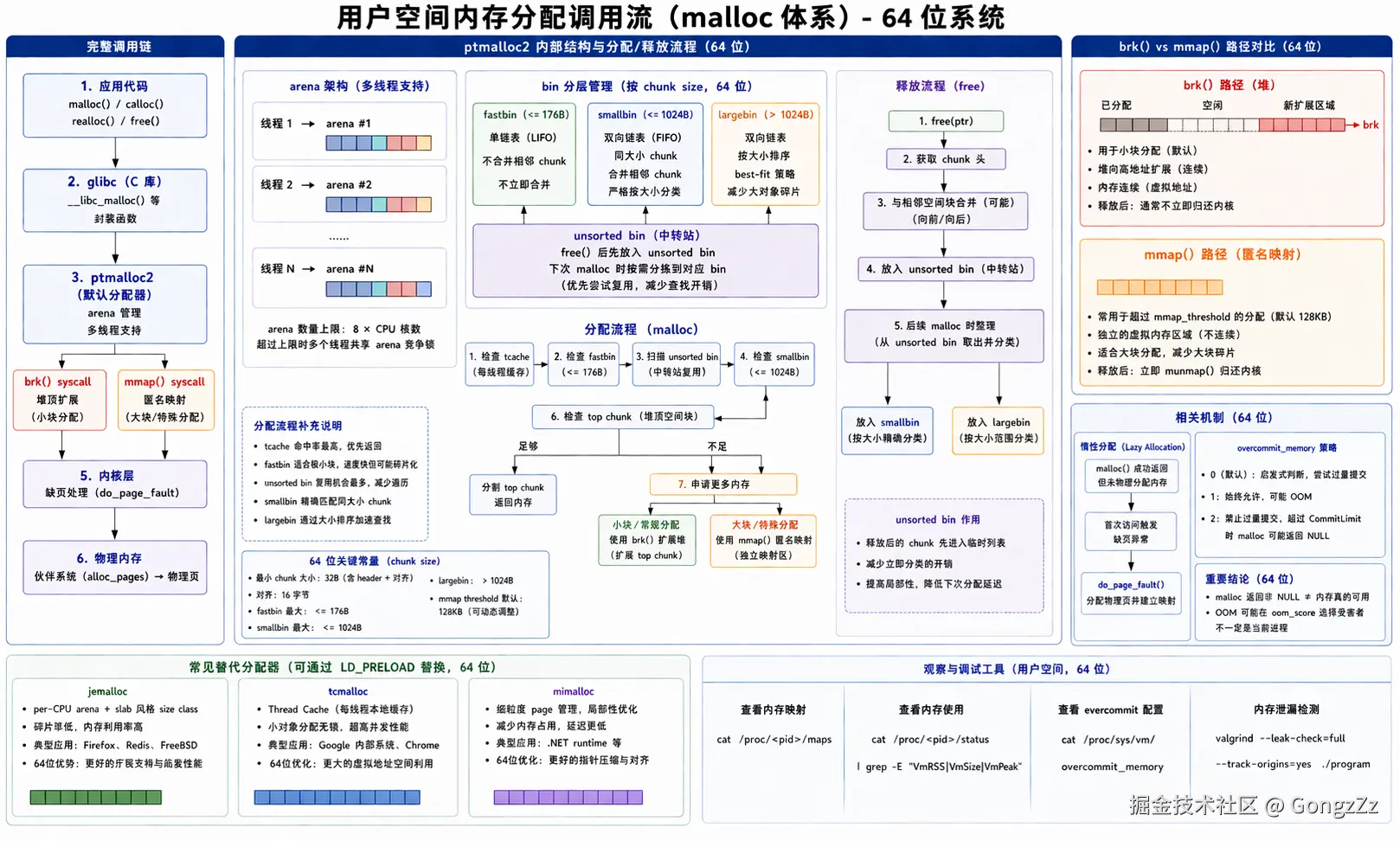
2.1 完整调用链
scss
应用代码
└─ malloc() / free() ← glibc 公开接口
└─ ptmalloc2(glibc 默认分配器)
├─ tcache (Per-Thread Cache) ← 【无锁极速径】默认容量 64个bin × 7个chunk,接管 ≤ 1040B 的分配
│
├─ arena / bin / chunk 管理 ← 【用户态主内存池】多线程存在锁/CAS竞争
│ ├─ fastbin (≤ 128B) ← 单链表,LIFO,CAS原子操作。默认上限128B,最大可配160B
│ ├─ unsorted bin (任意大小) ← 回收中转站,释放的非 fastbin 块优先进入,提供极致的数据局部性
│ ├─ smallbin (< 1024B) ← 64位标准,共62个尺寸精确匹配的桶,双链表,FIFO
│ └─ largebin (≥ 1024B) ← 64位标准,按尺寸范围划分,内部按大小排序,双链表
│
├─ brk() syscall ← 【连续堆区】主 Arena 默认扩展方式,处理上述 bin 的底层内存供给
└─ mmap() syscall ← 【离散映射】匿名映射。默认阈值 ≥ 128KB(动态最高可推至 32MB)
└─ 内核 VMA 管理
└─ 缺页中断 (do_page_fault) ← 发生读写时真正分配物理内存
└─ 伙伴系统 (Buddy) → 物理页2.2 ptmalloc2 的核心设计
ptmalloc2 最关键的设计是延迟归还 :free() 在绝大多数情况下不会触发 syscall,而是把 chunk 放回对应的 bin,等下次 malloc 直接复用。这使得真实的 syscall 次数远少于 malloc/free 调用次数。
c
void *p1 = malloc(64); // 第一次:brk() 扩展堆,获取物理页
void *p2 = malloc(64); // 直接从 bin 取,无 syscall
free(p1); // chunk 放回 fastbin,无 syscall
void *p3 = malloc(64); // 从 fastbin 取 p1 的内存,无 syscall理解 bin 的分层逻辑有助于建立清晰的分配路径映像。free() 后,chunk 首先进入 unsorted bin ,这是一个中转站,不做大小区分。下次 malloc 时,分配器会扫描 unsorted bin,将合适大小的 chunk 直接返回,不合适的则按大小归入 smallbin 或 largebin。fastbin 是对小对象的特殊优化,使用单链表、LIFO 顺序,不合并相邻空闲 chunk(为了速度牺牲碎片率)。smallbin 使用双链表、FIFO 顺序,会合并相邻空闲 chunk(减少碎片)。largebin 对大 chunk 按大小排序,支持 best-fit 查找,确保大对象的碎片率最低。
多线程场景下,ptmalloc2 通过 arena 机制减少锁竞争。每个线程尽量使用独立的 arena(每个 arena 是一套完整的 bin 集合),arena 数量上限为 8 × CPU 核数。当线程数超过 arena 上限时,多个线程会共享同一个 arena 并竞争其锁,这是 ptmalloc2 在高并发下性能退化的根本原因,也是 jemalloc 和 tcmalloc 的优化切入点。
分配策略的分叉点 :ptmalloc2 在以下情况才会走 mmap(),而不是 brk():
- 请求大小 ≥
MMAP_THRESHOLD(默认 128KB,可通过mallopt(M_MMAP_THRESHOLD, n)动态调整) - 多线程场景下新建 arena 时
brk()无法满足对齐要求时
用 mmap() 分配的内存在 free() 时会立即通过 munmap() 归还内核,不会留在 bin 里------这是与小块分配行为最显著的区别,也是大对象频繁分配/释放性能差的根本原因。用 brk() 管理的堆内存的归还逻辑则不同:只有当堆顶连续空闲区域超过 M_TRIM_THRESHOLD(默认 128KB)时,ptmalloc2 才会调用 brk() 缩减堆顶,主动还页给内核。因此日常观察到的现象是:程序释放了大量小对象后,RSS(物理内存占用)并不立即下降,因为那些内存还留在 bin 里等待复用,对内核不可见。
2.3 懒分配(Lazy Allocation)的真相
brk() 和 mmap() 返回的是虚拟地址 ,此时物理页尚未分配。只有当进程真正访问该地址时,CPU 触发缺页异常,内核的 do_page_fault() 才会调用伙伴系统分配物理页并建立页表映射。
c
void *p = malloc(1024 * 1024 * 100); // 100MB
// 此时:虚拟地址已分配,物理内存几乎未消耗
// malloc 可能"成功"返回,即使系统物理内存只有 50MB
memset(p, 0, 1024 * 1024 * 100);
// 此时:真正触发物理页分配
// 如果内存不足,OOM Killer 可能在这里介入,而不是在 malloc 处这是 Linux 默认开启 overcommit 策略的直接后果,行为由 /proc/sys/vm/overcommit_memory 控制:
- 值为 0(默认):启发式判断,允许合理的过量提交,但拒绝明显荒谬的请求(如申请超过物理内存 + swap 总量的单次大分配)。
- 值为 1:始终允许,malloc 在物理内存实际耗尽前永远不返回 NULL,但访问时可能触发 OOM。
- 值为 2 :禁止过量提交,系统会拒绝超出
CommitLimit(物理内存 × overcommit_ratio% + swap)的分配请求,malloc 可能返回 NULL,但不会有意外的 OOM kill。
从这里可以得出一个反直觉但重要的结论:malloc 返回非 NULL 不代表内存真的可用 。OOM Killer 介入时,它按 oom_score(综合考虑内存占用、运行时间、是否是系统进程等)选择"性价比最高"的受害者,不一定是当前进程。这意味着内存不足的后果是全局性的、不可预测的,而不只是当前 malloc 调用的本地问题。
2.4 替代分配器
| 分配器 | 核心优化方向 | 典型使用场景 |
|---|---|---|
| jemalloc | per-CPU arena + slab,碎片率低 | Firefox、Redis、FreeBSD |
| tcmalloc | Thread Cache 无锁小对象分配 | Google 内部系统、Chrome |
| mimalloc | 细粒度 page 管理,局部性优化 | .NET runtime、各种服务器 |
ptmalloc2 并非唯一选择,实际生产环境中常见的替代方案:
jemalloc 的核心思路是 per-CPU arena 加上 slab 风格的 size class 管理,碎片率显著低于 ptmalloc2,适合长期运行的服务(Firefox、Redis、FreeBSD 默认使用)。
tcmalloc 的核心是 Thread Cache------每个线程持有一个本地的小对象缓存,分配时完全无锁,只有 cache 满溢或不足时才需要与全局 heap 交互,适合高并发、小对象频繁分配的场景(Google 内部系统、Chrome)。
mimalloc 则在局部性上做了更细致的优化,每个线程的页分配单元更小,减少内存占用,适合现代服务器场景(.NET runtime 默认使用)。
替换方式无需修改代码,LD_PRELOAD 即可:
bash
LD_PRELOAD=/usr/lib/libmimalloc.so ./your_program三、内核空间分配调用链
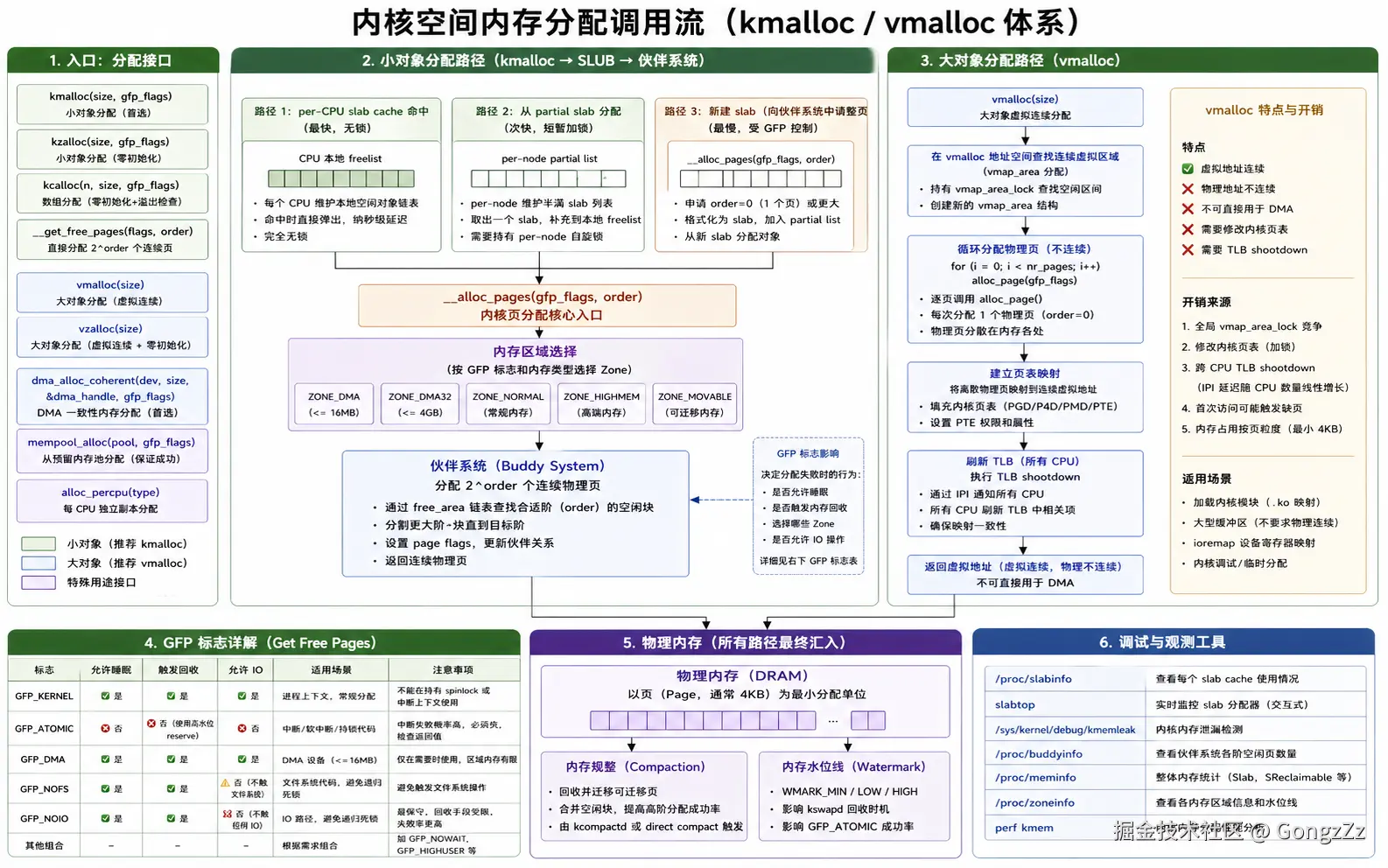
3.1 小对象:kmalloc 路径
scss
kmalloc(size, gfp_flags)
└─ SLUB 分配器(现代内核默认)
├─ per-CPU slab cache 命中 ← 无锁快路径,最快
├─ 从 partial slab 分配 ← 需要短暂加锁
└─ 新建 slab(向伙伴系统申请整页)
└─ __alloc_pages(gfp_flags, order)
└─ 内存区域选择(ZONE_DMA / ZONE_NORMAL / ZONE_HIGHMEM)
└─ 伙伴系统返回 2^order 个连续物理页SLUB 内部有三条路径,性能依次递减,理解这个层次是理解 kmalloc 开销的关键。
最快的路径是 per-CPU slab cache 命中:每个 CPU 持有一个本地的空闲对象指针列表(freelist),命中时完全无锁,直接指针操作返回,纳秒级延迟。这是 SLUB 相比老 SLAB 分配器的核心改进点,消除了大量的 per-object 锁。
当 per-CPU freelist 耗尽时,走 partial slab 路径:从 per-node 的 partial slab 列表中取一个半满的 slab 补充到 per-CPU freelist,需要短暂持有 per-node 的自旋锁。
当 partial slab 也不足时,向伙伴系统申请整页 :调用 __alloc_pages 分配一个或多个物理页,格式化为新的 slab 加入 cache,然后从中分配对象。这一步的代价最高,且行为受 GFP 标志控制(见 3.3 节)。
kmalloc 返回的地址位于内核直接映射区(PAGE_OFFSET 以上),虚拟地址和物理地址之间存在固定偏移,可以通过 virt_to_phys() 直接转换,因此天然适合 DMA 操作。这与用户空间的内存有本质不同------用户空间的虚拟地址和物理地址之间没有固定偏移关系,需要页表才能查到物理地址。
关于 kmalloc 的尺寸限制,需要建立准确的认知:SLUB 预定义了一系列固定大小的 cache(8、16、32、64......4096、8192 字节),请求会向上取整到最近的 cache 尺寸。当请求大小超过最大 slab cache 尺寸(通常 8KB,部分架构和配置可达 32KB)时,kmalloc 并不会直接失败,而是 fallback 到直接调用伙伴系统按页分配------这意味着它仍然能工作,但返回的内存粒度变为页的整数倍,内碎片可能极大。实践中 kmalloc 的合理上限约 4MB,超过这个量应该重新评估设计。
3.2 大对象:vmalloc 路径
scss
vmalloc(size)
└─ 在 vmalloc 地址空间寻找连续虚拟区域(vmap_area)
└─ 循环调用 alloc_page() 分配单个物理页(物理上不连续)
└─ 建立页表映射(将离散物理页映射到连续虚拟空间)
└─ 刷新 TLB(所有 CPU 核心)vmalloc 的代价远高于 kmalloc,而且这种差距在单纯的内存分配动作上看不出来,需要展开每一步理解:
修改内核页表的代价 首先体现在加锁上:内核的 vmalloc 地址空间是全局共享的,查找空闲虚拟区间需要持有 vmap_area_lock。分配完成后,还需要将新的页表项写入所有 CPU 的内核页表,而不像用户进程页表那样只属于一个进程。
TLB shootdown 是 vmalloc 代价最容易被忽视的部分。修改内核页表后,必须通知所有 CPU 刷新 TLB 中对应地址的缓存项,否则其他 CPU 仍然使用旧的(无效的)映射。这个通知通过 IPI(处理器间中断)实现,每个 CPU 收到 IPI 后停下当前工作,执行 TLB 刷新,然后返回。在 NUMA 多核系统上,这个操作的代价随 CPU 核数线性增长,几十上百核的机器上 TLB shootdown 的耗时不可忽视。
此外,vmalloc 分配的内存在函数返回时,物理页其实已经全部分配就位,这与用户空间的"懒分配"有本质区别。但在首次访问时,它仍会触发缺页异常。这并非为了申请物理内存,而是为了进行内核页表同步:vmalloc 修改的是主内核页表(Master Kernel Page Table),而当前进程的内核页表副本可能尚未更新映射关系。当内核首次访问该区域时,缺页处理程序会从主页表中将对应的页表项(PTE)拷贝到当前进程的页表中。因此,vmalloc 在访问每一页时仍存在首次同步的性能开销,且这种"同步型缺页"是内核在特权级下隐式完成的。
vmalloc 的合理使用场景:加载内核模块(.ko 文件映射到 vmalloc 区)、需要大块但不要求物理连续的缓冲区、ioremap 映射设备寄存器区域。核心判断标准是:不需要 DMA,不需要 virt_to_phys() 换算物理地址,只需要虚拟连续的大块内存。
3.3 GFP 标志:分配行为的控制开关
GFP(Get Free Pages)标志决定了内核分配器在资源紧张时的行为,是内核内存分配中最容易出错的地方:
c
// 进程上下文,允许睡眠等待内存回收
p = kmalloc(size, GFP_KERNEL);
// 中断上下文 / 持有自旋锁时,禁止睡眠
p = kmalloc(size, GFP_ATOMIC);
// DMA 专用,分配 ZONE_DMA 区域的内存(物理地址 < 16MB)
p = kmalloc(size, GFP_DMA);
// 内核内部用,不触发文件系统操作(避免内存回收死锁)
p = kmalloc(size, GFP_NOFS);
// 不触发任何 IO 操作
p = kmalloc(size, GFP_NOIO);理解 GFP 标志的关键是理解它们控制的是分配失败时的行为边界,而不只是"允不允许睡眠"这一点。
GFP_KERNEL 是最宽松的标志。内存不足时,分配器会唤醒 kswapd 触发后台页面回收;如果 kswapd 回收速度不够,还会同步执行 direct reclaim(调用者自己扫描并回收页面);必要时还会等待 writeback 完成以腾出脏页。这些步骤都可能导致调用者睡眠几毫秒到几十毫秒,因此绝对不能在持有 spinlock 或处于中断上下文时使用。持有 spinlock 时睡眠会导致其他等待该锁的 CPU 无限自旋,进而引发系统死锁或 watchdog 触发 panic。lockdep 工具在调试内核上可以提前检测此类问题。
GFP_ATOMIC 的底层机制与 GFP_KERNEL 有本质区别:它使用的是高于普通水位线(WMARK_MIN)的内存储备,当系统内存低于这条水位线时,ATOMIC 分配也会失败。ATOMIC 分配失败不可重试、不可等待,驱动中必须为此设计降级逻辑------通常是丢弃当前操作并返回错误码。失败率在内存压力下远高于 GFP_KERNEL。
GFP_NOFS 和 GFP_NOIO 是用于避免递归死锁的标志。文件系统代码(如 ext4 的写路径)申请内存时,如果触发内存回收,回收器可能又需要调用文件系统的 writeback------这就形成了循环等待。GFP_NOFS 告诉分配器"不要触发文件系统操作"来回收内存;GFP_NOIO 更严格,连 IO 操作都不允许触发。存储驱动的 IO 路径通常使用 GFP_NOIO,防止内存回收递归进入 IO 层。
3.4 其他内核分配接口
| 分配接口 | 核心机制 | 最佳使用场景 |
|---|---|---|
kzalloc |
kmalloc + 零初始化 | 绝大多数通用的驱动小对象分配 |
kcalloc |
数组分配 + 溢出检查 | 处理来自用户态或硬件的动态数组 |
__get_free_pages |
绕过 Slab,直接找伙伴系统 | 需要页对齐、大块且物理连续的内存 |
dma_alloc_coherent |
物理连续 + Cache 一致性处理 | 硬件 DMA 缓冲区(最稳妥的方式) |
mempool_alloc |
预留池机制,分配保底 | 关键 IO 路径,防止内存回收死锁 |
alloc_percpu |
每 CPU 独立副本,完全无锁 | 高频更新的计数器、热点统计数据 |
kmem_cache_alloc |
专用 Slab 桶,固定尺寸 | 高频创建/销毁的特定结构体 |
kzalloc(size, flags) 是 kmalloc 加 memset(0) 的等价封装,用于需要零初始化的小对象,是驱动代码中最常用的分配接口之一。
kcalloc(n, size, flags) 用于数组分配,与 kzalloc(n * size, flags) 的区别在于内置了整数溢出检查------如果 n × size 溢出 size_t,它会安全返回 NULL 而不是分配一个错误大小的内存块。在处理来自硬件或用户空间的不可信大小参数时,这一点非常重要。
__get_free_pages(flags, order) 绕过 slab 分配器,直接从伙伴系统申请 2^order 个物理连续页,返回物理连续的内核虚拟地址。适合需要整页对齐、物理连续但大小已知是页倍数的场景。
dma_alloc_coherent(dev, size, &dma_handle, flags) 是 DMA 缓冲区的正确分配方式,而不是简单地 kmalloc 加标 GFP_DMA。它不仅保证物理连续,还处理了跨架构的 cache 一致性问题(在某些架构上需要将缓冲区映射为 uncached,或手动刷新 cache),并直接返回设备可用的 dma_handle(物理地址或总线地址)。驱动开发中凡是涉及 DMA 的缓冲区,都应优先考虑这个接口而非手动操作物理地址。
mempool_alloc(pool, flags) 是针对"分配必须成功"场景的解决方案。在系统初始化时通过 mempool_create() 预分配一批对象,当普通分配路径失败时从预留池取用。块设备驱动的 bio 结构是典型用例------内存回收本身依赖 IO(writeback),而 IO 依赖能分配 bio 结构,如果 bio 分配因内存不足而失败,系统会陷入死锁。mempool 打破了这个循环。
alloc_percpu(type) 为每个 CPU 分配一份独立的对象副本,通过 get_cpu_ptr() / put_cpu_ptr() 访问,完全无锁,且每个 CPU 的副本在内存中彼此间隔,天然消除 cache 伪共享(false sharing)。适合高频更新的统计计数器、per-CPU 缓存等,是内核性能优化中的重要工具。
kmem_cache_create() 加 kmem_cache_alloc() 是专用 slab cache 的接口。当某类对象需要大量频繁分配/释放时,建一个专用 cache 比直接 kmalloc 效率更高:对象大小固定,无内碎片,可以加 constructor 在分配时自动初始化,且 slabinfo 中会有独立的统计条目便于调试。
四、关键行为差异深度解析
4.1 物理连续性:最常被混淆的一点
用户空间的内存虚拟地址连续,物理地址几乎必然不连续,由页表将散布在 DRAM 各处的物理页拼接成连续的虚拟空间。应用开发者在绝大多数场景下不需要关心这一点。
内核空间的情况则必须明确区分。kmalloc 返回的内存虚拟连续且物理连续 ,背后是伙伴系统分配的一块连续物理页,地址可以用 virt_to_phys() 直接换算,天然适合 DMA。vmalloc 返回的内存虚拟连续但物理不连续 ,和用户空间一样靠页表拼接,不能用于 DMA,也不能用 virt_to_phys() 直接换算(需要 vmalloc_to_pfn() 逐页查找)。
把
vmalloc的地址传给 DMA 引擎不是"慢一点",而是静默的数据损坏。 硬件 DMA 使用物理地址工作,它看到的是连续的物理地址区间,但vmalloc的物理页是分散的,DMA 会按照连续物理地址写入,实际上写到了不相关的内存区域,损坏其他数据。这类 bug 极难复现和排查,因为崩溃现场离真正的写入操作可能有很长的时间和调用栈距离。
4.2 分配时机:懒与即时的根本区别
用户空间的懒分配已在 2.3 节展开。这里对比内核空间。
kmalloc 成功返回即意味着物理页就位、可以立即使用,没有缺页异常这道工序。这不是偶然,而是设计约束:内核的很多代码路径(中断处理程序、softirq、持有 spinlock 的代码)根本无法处理缺页异常,如果采用懒分配,一旦触发缺页就会直接 BUG。内核在自己的栈上运行,没有像进程那样完善的缺页处理基础设施。
vmalloc 是内核空间中少有的例外------它的区域在首次访问时确实也有缺页处理(称为"vmalloc 缺页")。但这个缺页处理是在内核态完成的,没有 signal、没有 OOM 保护,和用户空间的缺页语义完全不同。如果 vmalloc 缺页时内存不足,直接 panic。
4.3 分配失败:进程与系统的代价不对称
用户空间 malloc 失败返回 NULL,进程可以检查、降级、重试,最坏是进程崩溃,不影响其他进程和内核。这层隔离是由虚拟内存和进程隔离机制保证的。
内核空间 kmalloc 失败如果不检查就直接解引用,会立即触发内核 oops 甚至 panic,整个系统宕机 。内核驱动中对每一个 kmalloc/vmalloc 的返回值做 NULL 检查,不是"好习惯",而是正确性的必要条件。很多新手写驱动时习惯像写应用程序一样"先用再说",在开发机的充裕内存下永远跑得通,一到内存压力场景就立即崩溃。
4.4 内存泄漏:进程生命周期 vs 系统生命周期
这是两套体系代价最不对称的地方之一。
用户空间的内存泄漏,在进程退出时由内核自动收拾残局------内核会回收进程的所有虚拟地址空间和物理页,无论代码有没有调用 free。长期运行的进程如果持续泄漏,RSS 会缓慢增长,最终触发 OOM,但这是进程级别的事,不影响系统整体。
内核空间没有"进程退出"这个概念来兜底。kmalloc/vmalloc 分配的内存是内核全局资源,没有任何自动回收机制。泄漏的内存永久占用直到重启。
驱动开发中最常见的泄漏场景是模块卸载路径(module_exit)遗漏 kfree。反复 insmod/rmmod 会逐渐耗尽内核内存,症状是 /proc/meminfo 中 Slab 字段(尤其是 SUnreclaim 部分)持续缓慢增长,slabtop 中某个 cache 的 active_objs 持续上升但 module_exit 从未真正清理。
4.5 栈内存的对比
用户进程的栈由内核初始分配一个较小的区域,通过缺页异常动态增长,guard page 检测溢出。超出默认 8MB 上限(ulimit -s)触发 SIGSEGV,进程可以捕获并处理。
内核线程的栈则是固定大小的,在 x86_64 上默认 16KB(部分旧配置或嵌入式场景是 8KB),不能动态增长,没有类似用户栈的缺页扩展机制。内核栈溢出的结果不是一个可以被捕获的信号,而是静默地覆盖相邻的内存数据,直到某个关键数据被破坏触发 panic,或者更糟糕地以无法复现的方式产生错误行为。
在内核函数中声明大数组是经典的危险行为,例如:
c
// 危险:在内核栈上分配 4KB,极易溢出
char buf[4096];应改为动态分配:kmalloc(4096, GFP_KERNEL),用完后 kfree。
CONFIG_VMAP_STACK(Linux 4.9 之后默认启用)为内核栈使用 vmalloc 区分配,并在栈底放置 guard page,使得内核栈溢出能被及时检测而不是静默损坏数据。这是一个重要的安全加固特性,但不改变内核栈固定大小、不可动态增长的本质。
五、调试工具与关键命令
用户空间:
bash
# 查看进程内存映射(区分 heap / mmap 区域)
cat /proc/<pid>/maps
# 查看实际物理内存消耗(RSS vs VSZ)
cat /proc/<pid>/status | grep -E "VmRSS|VmSize|VmPeak"
# 查看 overcommit 配置
cat /proc/sys/vm/overcommit_memory
# Valgrind 检测泄漏
valgrind --leak-check=full --track-origins=yes ./program内核空间:
bash
# 查看 slab 分配器使用情况
cat /proc/slabinfo
sudo slabtop
# kmemleak 扫描内核内存泄漏,
# 需要开启的 CONFIG_DEBUG_FS=y CONFIG_DEBUG_KMEMLEAK=y 内核参数和挂载 debugfs
echo scan > /sys/kernel/debug/kmemleak
cat /sys/kernel/debug/kmemleak
# 查看伙伴系统各阶空闲页数量(高阶列下降 = 碎片化信号)
cat /proc/buddyinfo
# 整体内存统计(Slab 字段持续增长是内核泄漏信号)
cat /proc/meminfo | grep -E "Slab|SReclaimable|SUnreclaim"
# 查看内存区域分布和水位线
cat /proc/zoneinfo六、小结:一条逻辑线贯穿所有差异
两套分配体系的根本差异源于运行环境的不同:用户进程有虚拟内存保护、有进程隔离、有操作系统兜底;内核代码运行在最高特权级,没有保护网,错误直接影响整个系统。
这个差异向上传导,解释了所有具体行为的来龙去脉:
- 内核空间没有懒分配,是因为中断路径不能处理缺页
- 需要 GFP 标志,是因为必须精确控制分配器是否允许睡眠
- vmalloc 代价远高于单纯的内存分配动作,是因为 TLB 是全局资源需要全系统同步
- 漏掉一个
kfree比漏掉free严重得多,是因为没有进程退出来收拾残局 - vmalloc 地址不能传给 DMA,是因为物理连续是硬件约束而非软件选项
建立这套思维映像的捷径是记住两个问题:当前代码路径能否睡眠?当前分配的内存是否需要物理连续? 这两个问题的答案决定了几乎所有的选型判断。