Megatron-LM(英伟达超大模型训练框架)完整介绍
Megatron-LM 是NVIDIA 2019年开源、基于PyTorch 的超大Transformer大模型分布式训练框架 ,主打3D混合并行,专门解决数十亿~万亿参数LLM(GPT/BERT/T5/MoE)单卡放不下、显存爆炸的训练难题,是全球大模型工业训练主流底座之一。
一、发展版本
- 初代Megatron-LM(2019):首发张量并行TP+流水线并行PP+数据并行DP三维并行,成功训练83B超大GPT模型,奠定大模型并行标准范式。
- Megatron-Core(MCore,新一代) :重构模块化架构,新增序列并行SP、MoE专家并行、上下文并行,支持多模态、稀疏MoE大模型,对接Transformer Engine加速库,面向生产级万亿参数模型训练。
二、核心:三大经典并行(3D并行,Megatron灵魂)
1. 数据并行 DP(Data Parallelism)
- 逻辑 :多卡存完整模型权重,数据切分,每张GPU跑不同子批次数据;反向传播AllReduce汇总梯度、统一更新权重。
- 作用:扩充训练批次、提升吞吐,不拆分模型,常规小模型标配。
2. 张量并行 TP(Tensor Parallel,Megatron首创层内并行)
单层Transformer内部拆分权重矩阵到多GPU(层内并行),解决单层权重太大超显存问题:
- Attention层:QKV权重按列切分,多头注意力分到不同GPU,各卡独立算单头注意力,输出再聚合;
- MLP层:第一个全连接列切分、第二个全连接行切分,前后仅各一次AllReduce通信,通信开销极低。
3. 流水线并行 PP(Pipeline Parallel,层间并行)
Transformer堆叠层按顺序分段,不同GPU负责连续几层 (层间拆分),像流水线接力:
GPU1:第1~8层 → GPU2:9~16层 → GPU3:17~24层,数据串行流转,利用流水线重叠隐藏等待空闲时间,解决整体模型过深放不下单卡。
3D组网规则:DP×TP×PP三维组网,所有GPU被划分成三维网格,是百亿+参数标配方案。
4. 新版MCore新增并行
序列并行SP、MoE专家并行EP、上下文并行CP,适配超长上下文、稀疏混合专家大模型训练。
三、显存优化关键技术
- 混合精度FP16/BF16+融合算子:Fused Adam、LayerNorm融合,压缩显存、提速;
- 激活重计算(Checkpoint) :丢弃中间激活、反向重算,激活显存最高节省70%,仅少量算力损耗;
- ZeRO分布式优化器:优化器、梯度分片到DP组多卡,不再全卡复制,大幅降低优化器显存占用;
- 分布式断点续训Checkpoint:模型分片保存,支持多机断点恢复。
四、原生支持模型类型
- 自回归生成模型:GPT系列、LLaMA、Falcon(最主流落地场景);
- 编码器模型:BERT、RoBERTa;
- 编解码:T5、BART;
- 稀疏MoE:Mixtral、GPT4风格混合专家大模型(Megatron-Core重点优化);
- 多模态:图文大模型(Megatron-Core扩展)。
五、生态与落地
- 底层依赖:NCCL高速集合通信、Transformer Engine(英伟达GPU硬件算子加速)、PyTorch;
- 业界落地:OpenAI早期GPT3参考其并行思路、国内大厂千亿大模型(通义、文心、盘古)大量基于Megatron二次开发;
- 配套:Megatron-Bridge对接Hugging Face,可轻松HF权重↔Megatron权重互转。
六、和DeepSpeed对比简记
- Megatron :强项TP张量并行,稠密大模型(LLaMA/GPT)训练性能最优,英伟达硬件适配拉满;
- DeepSpeed :强项ZeRO分片,低成本多卡扩容,小集群性价比更高。
Megatron-LM vs DeepSpeed 超详细全维度对比
核心定位一句话 :
Megatron(NVIDIA)=模型并行专家,靠TP/PP切分模型解决「单层/整层太大塞不下单卡」,极致压榨NVLink+TensorCore算力;DeepSpeed(微软)=数据并行优化大师,靠ZeRO分片训练状态解决「参数/优化器冗余爆显存」,用廉价集群堆超大模型」。
一、底层设计思想与核心技术原理
1. Megatron:3D并行(DP+TP张量并行+PP流水线并行)
(1)TP张量并行(灵魂,层内拆分)
- 拆分逻辑 :单Transformer层内部权重矩阵切分到多卡 ,QKV、FFN权重行列拆分,多张GPU共同算同一个层 的前向/反向。
- QKV:按列切分 → 各卡独立算部分注意力头,计算结束AllGather拼接结果;
- MLP:输入权重列切、输出权重行切,仅首尾各一次集合通信,中间计算本地完成。
- 显存特点 :TP组内每张GPU仍持有该分片完整权重,DP维度依旧全量复制模型 ,优化器、梯度全副本留存,无分片;靠拆分激活值显存降低单卡压力。
- 通信依赖 :重度依赖NVLink高速互联(300GB/s+),同DGX机内卡间通信成本极低,跨机通信开销暴涨。
(2)PP流水线并行(层间拆分)
- 拆分逻辑 :Transformer整体分层切块,不同GPU负责连续多层,数据微批次流水线串行流转(GPU1:18层、GPU2:916层),GPipe微批次打散减少流水线气泡(空闲空转)。
- 短板:流水线分段越多,中间激活缓存占用线性上升,层数极深时激活易OOM。
(3)DP数据并行
传统DDP:每张DP卡存完整模型权重、梯度、Adam优化器状态,仅数据分片,反向AllReduce同步梯度,显存冗余极高。
新版MCore补充:SP序列并行、EP专家并行
- SP:沿
seq_len维度拆分注意力,解决超长上下文(32K+)注意力激活O(seq²)爆显存; - EP:MoE专家路由分片,适配Mixtral等稀疏大模型。
2. DeepSpeed:ZeRO零冗余优化(数据并行重构,王牌)
ZeRO是改造DP、在DP维度分片【优化器→梯度→参数】 ,不改动模型层内部结构,不需要修改Transformer代码,分3个Stage逐级释放显存:
| ZeRO等级 | 分片对象 | 单卡显存收益 | 额外通信 |
|---|---|---|---|
| ZeRO-1 | 仅Adam优化器状态 | 优化器显存÷DP数(Adam优化器=4×参数量) | 仅反向ReduceScatter |
| ZeRO-2 | 优化器+梯度 | 梯度+优化器均÷DP,显存节省75%+ | 反向逐桶ReduceScatter |
| ZeRO-3 | 优化器+梯度+模型参数 | 参数全分片,单卡只存1/DP参数,理论无参数显存上限 | 前向AllGather取参数,用完立刻释放 |
额外黑科技:
- ZeRO-Offload/Infinity :把参数/优化器溢出到CPU内存/NVMe硬盘,无足够GPU显存也能训万亿参数,异构混合内存(GPU+CPU+SSD)训练;
- 可选TP/PP,但非原生强项,DeepSpeed的TP是封装Megatron算子实现。
关键本质区别 :
TP(Megatron)=把1层拆给N卡算,每张卡存层的一部分权重 ;
ZeRO3(DeepSpeed)=完整层在单卡算,权重分散在DP所有卡,需要时临时拉取参数。
二、六大核心维度精细化对比
1. 显存占用表现(175B GPT实测,A100 80GB)
- 纯Megatron:单卡≈72GB,受限于DP全量权重副本,显存冗余大;
- 纯DeepSpeed(ZeRO3):单卡≈42GB,参数/优化器全分片,显存利用率极高;
- Megatron+DeepSpeed混合:TP切层+ZeRO分片DP,单卡≈38GB(工业主流落地方案)。
结论:显存紧张、单卡显存≤40GB优先DeepSpeed;NVLink高配集群优先Megatron提速。
2. 训练吞吐&硬件利用率MFU
- Megatron优势 :同NVLink DGX服务器内,TP+PP计算通信重叠完美,MFU可达75%85%,稠密LLaMA/GPT训练速度比DeepSpeed高20%40%;跨机无NVLink时性能断崖下跌(跨机带宽瓶颈)。
- DeepSpeed优势:普通以太网集群(无NVLink),ZeRO通信均衡,跨节点扩展性更强,千卡集群扩展效率≈0.89,Megatron无NVLink仅≈0.7;长文本>8K上下文DeepSpeed序列并行更快。
3. 代码改造&上手成本
- Megatron :⭐⭐⭐⭐难
需要基于Megatron自定义Transformer层(QKV/FFN要用内置算子),原生不兼容原生HuggingFace模型,要做权重适配改写,TP/PP超参(TP size、PP stage)调参门槛高,适合自研大模型团队。 - DeepSpeed :⭐⭐简单
原有PyTorch/HuggingFace代码几乎零改动 ,仅新增deepspeed_config.json配置文件开启ZeRO,一行ds_config={"zero_stage":2}启用分片,微调、LoRA场景首选。
4. 硬件适配范围
- Megatron :重度绑定NVIDIA+NVLink互联硬件,非NVLink普通服务器、AMD GPU适配差;极致优化TensorCore、FP8/BF16融合算子、Transformer Engine,H100/DGX整机性能天花板。
- DeepSpeed :全平台通用,NVIDIA/AMD/国产DCU均可;支持CPU卸载、NVMe离线缓存,低配多卡、杂牌组网集群唯一优选。
5. 适用模型类型
✅ Megatron强项
- 稠密超大单层模型:单hidden_size>8192、单层权重>20GB(如GPT3-175B、LLaMA2-70B稠密);
- MoE混合专家(MCore原生EP并行)、多模态图文大模型;
- 量产预训练、超高吞吐数据训练、DGX超算集群。
✅ DeepSpeed强项
- 显存受限小集群微调、SFT、RLHF:单卡V100/3090多卡训大模型;
- 万亿级超大参数(ZeRO3+Offload)、资源有限云主机;
- HuggingFace生态快速落地、小团队低成本预训练。
6. 生态与权重兼容性
- Megatron:原生自有权重格式,HF↔Megatron需要Bridge转换;配套Transformer Engine、NCCL深度优化;
- DeepSpeed:原生无缝对接HuggingFace Transformers、PEFT、Accelerate,主流开源项目(BLOOM、LlamaFactory)默认集成DeepSpeed配置。
三、ZeRO1/2/3 vs Megatron TP/PP 选型对照表
| 场景 | 优选方案 | 理由 |
|---|---|---|
| DGX A100/H100、整机NVLink、稠密大模型预训练 | Megatron TP+PP+ZeRO1 | 算力拉满、吞吐最高 |
| 8×3090/4090无NVLink、7B~70B微调SFT | DeepSpeed ZeRO2 | 低成本、少改代码 |
| 单卡显存<24G、想要训34B+大模型 | DeepSpeed ZeRO3+Offload | CPU分担显存,突破GPU物理限制 |
| 超长上下文>32K、注意力显存爆炸 | Megatron-Core SP序列并行 | 沿序列切分,大幅降低注意力显存 |
| MoE稀疏大模型(Mixtral) | Megatron-Core EP专家并行 | 原生专家路由分片优化 |
四、工业界主流:Megatron-DeepSpeed融合方案
现在大厂千亿模型几乎不用纯Megatron/纯DeepSpeed ,统一:
TP(Megatron层内切分)+PP(Megatron层间切分)+ZeRO(DeepSpeed替换原生DP),三者结合补齐短板:
- TP解决单层权重过大;
- PP解决模型过深;
- ZeRO解决DP维度优化器/梯度/参数显存冗余 。
BLOOM-176B、MT-NLG-530B、国内盘古/通义均采用这套混合架构。
五、优缺点总结
Megatron-LM
✅优点:稠密模型算力极致、NVLink集群吞吐领先、原生SP/EP适配超长文本&MoE;
❌缺点:依赖NVLink、改代码成本高、普通网卡集群效率差、DP显存冗余高。
DeepSpeed
✅优点:开箱即用、零代码改造、低配硬件友好、ZeRO+Offload突破显存上限、HF生态无敌;
❌缺点:纯ZeRO稠密大模型算力上限低于Megatron、超大单层(单层>30GB)仅靠ZeRO3通信开销飙升。
如何选择
1. - "纯ZeRO稠密大模型算力上限低于Megatron" 更准确的说法:
- 同样是"只用数据并行 + ZeRO" vs "Megatron 那套 TP+PP+DP":
- ZeRO(尤其 ZeRO-3)重点是显存效率,算力利用率一般不如 Megatron 那套极致优化的 TP+PP。
- 在千卡以上、NVLink/IB 很好的集群上,Megatron 的 TP+PP 更容易把算力压到极限;纯 ZeRO-3 通信开销会更明显,所以**"算力上限"确实通常更低**。
- "超大单层(单层>30GB)仅靠ZeRO3通信开销飙升"
这个现象是存在的,但原因要拆一下:- ZeRO-3 是按参数分片,前向/反向要 all-gather 完整参数,反向要 reduce-scatter 梯度。
- 单层参数特别大时,这个层每次 all-gather / reduce-scatter 的通信量就很大,如果跨节点带宽又一般,开销就会很夸张。
- 但这并不是说 ZeRO-3 一定不能用,而是:
- 可以考虑这层单独用 TP(Megatron 风格),其他层用 ZeRO-3(也就是 3D 并行:TP+PP+ZeRO-3)。
- 或者对这层做更细粒度的分片 + 通信优化(如 ZeRO++、1-bit Adam 等)。
2. DeepSpeed 的优点,你漏掉了什么?
你列的几条都很对,我补几个在实战里也很关键的:
2.1 显存层面
- ZeRO 三级显存节省是递进的:
- ZeRO-1:只分片优化器状态 → 省显存中等,通信开销低
- ZeRO-2:+ 梯度分片 → 显存更省,通信中高
- ZeRO-3:+ 参数分片 → 显存最省,但通信开销最高
- ZeRO-Offload / ZeRO-Infinity:
- 把优化器状态/梯度/参数卸载到 CPU 或 NVMe,能单卡训练 13B 甚至更大模型。
- 本质是用时间换空间:CPU/NVMe 带宽远低于 GPU,但容量大。
2.2 易用性 / 生态
- Hugging Face 集成非常深:
- Transformers 的
Trainer一键启用 ZeRO-1/2/3 + Offload。 - 有
ds_report、内存估算工具等,帮你看环境能不能跑起来。
- Transformers 的
- 对 PyTorch 代码侵入小:
- 基本就是
deepspeed.initialize()+ 一个 JSON 配置,就能从普通 PyTorch 训练迁过来。
- 基本就是
2.3 3D 并行 & 长序列
- DeepSpeed 自己也支持 TP+PP+ZeRO 的 3D 并行,和 Megatron-DeepSpeed 是一套思路。
- DeepSpeed 序列并行(Ulysses)在长序列下通信复杂度比 Megatron 的 O(N) 更优,是 O(N/P),对 10k+ token 输入更有优势。
3. DeepSpeed 的缺点,你有哪些可以补全?
你说的两条都是真痛点,我再加几条更"工程向"的:
3.1 通信开销 & 算力上限
- ZeRO-3 在前向/反向要频繁 all-gather 参数、reduce-scatter 梯度:
- 单层参数越大,通信量越大。
- 跨节点网络一般时,通信占比会很高,算力上限明显比 Megatron TP+PP 低。
- 解决思路:
- 不要"纯 ZeRO-3",对大层改用 TP,整体走 3D 并行(TP+PP+ZeRO-3)。
- 用 ZeRO++ / 1-bit Adam 等压缩通信。
- 尽量让 ZeRO-3 在节点内 NVLink 上跑,跨节点用 PP/TP 拆分。
3.2 配置复杂、踩坑点多
- ZeRO-3 + Offload + 1-bit Adam + 各种 bucket / overlap 参数,调起来不比 Megatron 简单。
- 典型坑:
- ZeRO-3 和 HF 的
low_cpu_mem_usage/device_map冲突。 - ZeRO-3 + Offload 时
DeepSpeedCPUAdam缺ds_opt_adam属性等编译/版本问题。 - 多机网络拓扑不好时,NCCL 通信热点难排查。
- ZeRO-3 和 HF 的
3.3 稀疏模型 / MoE 场景
- DeepSpeed 有 DeepSpeed-MoE,对 MoE 有专门优化,但整体生态和成熟度还是比不上 Megatron + Megablock 等更"硬核"的 MoE 栈。
- 如果你主打 MoE/稀疏大模型,要多对比 Megatron 生态,而不是只看 DeepSpeed。
4. 什么时候选 DeepSpeed,什么时候选 Megatron?
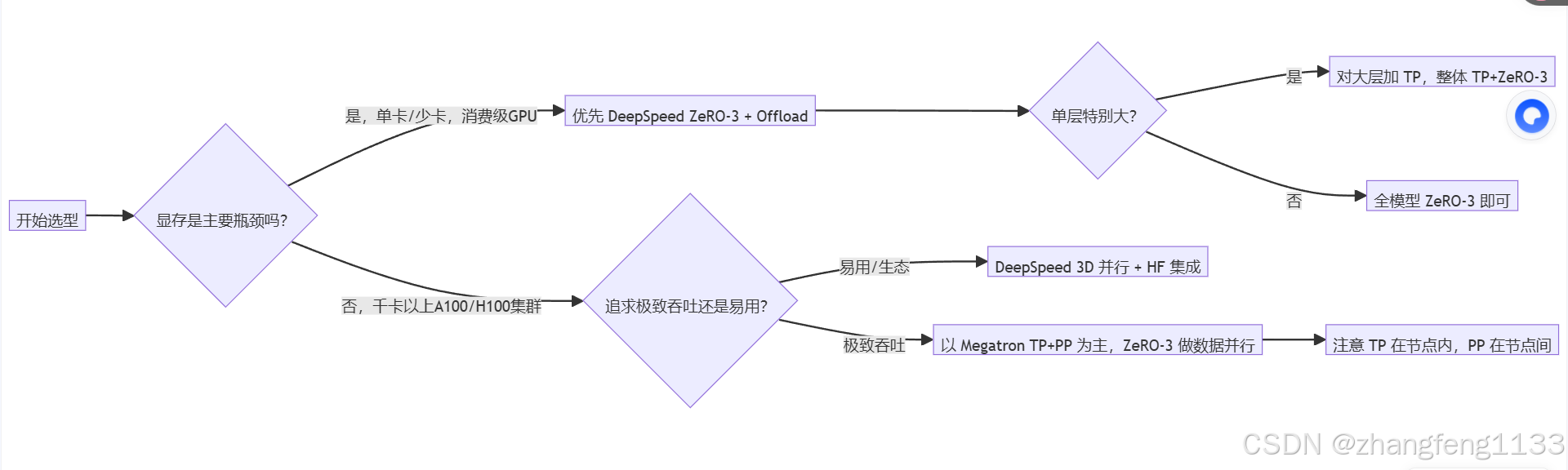
用一个简化的决策图概括一下(以"显存 vs 算力"为主线):
#mermaid-svg-uLTY49x3My6Hz8Lp{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-uLTY49x3My6Hz8Lp .error-icon{fill:#552222;}#mermaid-svg-uLTY49x3My6Hz8Lp .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-uLTY49x3My6Hz8Lp .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-uLTY49x3My6Hz8Lp .marker{fill:#333333;stroke:#333333;}#mermaid-svg-uLTY49x3My6Hz8Lp .marker.cross{stroke:#333333;}#mermaid-svg-uLTY49x3My6Hz8Lp svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-uLTY49x3My6Hz8Lp p{margin:0;}#mermaid-svg-uLTY49x3My6Hz8Lp .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-uLTY49x3My6Hz8Lp .cluster-label text{fill:#333;}#mermaid-svg-uLTY49x3My6Hz8Lp .cluster-label span{color:#333;}#mermaid-svg-uLTY49x3My6Hz8Lp .cluster-label span p{background-color:transparent;}#mermaid-svg-uLTY49x3My6Hz8Lp .label text,#mermaid-svg-uLTY49x3My6Hz8Lp span{fill:#333;color:#333;}#mermaid-svg-uLTY49x3My6Hz8Lp .node rect,#mermaid-svg-uLTY49x3My6Hz8Lp .node circle,#mermaid-svg-uLTY49x3My6Hz8Lp .node ellipse,#mermaid-svg-uLTY49x3My6Hz8Lp .node polygon,#mermaid-svg-uLTY49x3My6Hz8Lp .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-uLTY49x3My6Hz8Lp .rough-node .label text,#mermaid-svg-uLTY49x3My6Hz8Lp .node .label text,#mermaid-svg-uLTY49x3My6Hz8Lp .image-shape .label,#mermaid-svg-uLTY49x3My6Hz8Lp .icon-shape .label{text-anchor:middle;}#mermaid-svg-uLTY49x3My6Hz8Lp .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-uLTY49x3My6Hz8Lp .rough-node .label,#mermaid-svg-uLTY49x3My6Hz8Lp .node .label,#mermaid-svg-uLTY49x3My6Hz8Lp .image-shape .label,#mermaid-svg-uLTY49x3My6Hz8Lp .icon-shape .label{text-align:center;}#mermaid-svg-uLTY49x3My6Hz8Lp .node.clickable{cursor:pointer;}#mermaid-svg-uLTY49x3My6Hz8Lp .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-uLTY49x3My6Hz8Lp .arrowheadPath{fill:#333333;}#mermaid-svg-uLTY49x3My6Hz8Lp .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-uLTY49x3My6Hz8Lp .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-uLTY49x3My6Hz8Lp .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-uLTY49x3My6Hz8Lp .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-uLTY49x3My6Hz8Lp .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-uLTY49x3My6Hz8Lp .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-uLTY49x3My6Hz8Lp .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-uLTY49x3My6Hz8Lp .cluster text{fill:#333;}#mermaid-svg-uLTY49x3My6Hz8Lp .cluster span{color:#333;}#mermaid-svg-uLTY49x3My6Hz8Lp div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-uLTY49x3My6Hz8Lp .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-uLTY49x3My6Hz8Lp rect.text{fill:none;stroke-width:0;}#mermaid-svg-uLTY49x3My6Hz8Lp .icon-shape,#mermaid-svg-uLTY49x3My6Hz8Lp .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-uLTY49x3My6Hz8Lp .icon-shape p,#mermaid-svg-uLTY49x3My6Hz8Lp .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-uLTY49x3My6Hz8Lp .icon-shape .label rect,#mermaid-svg-uLTY49x3My6Hz8Lp .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-uLTY49x3My6Hz8Lp .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-uLTY49x3My6Hz8Lp .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-uLTY49x3My6Hz8Lp :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 是,单卡/少卡,消费级GPU
否,千卡以上A100/H100集群
极致吞吐
易用/生态
是
否
开始选型
显存是主要瓶颈吗?
优先 DeepSpeed ZeRO-3 + Offload
追求极致吞吐还是易用?
以 Megatron TP+PP 为主,ZeRO-3 做数据并行
DeepSpeed 3D 并行 + HF 集成
单层特别大?
对大层加 TP,整体 TP+ZeRO-3
全模型 ZeRO-3 即可
注意 TP 在节点内,PP 在节点间
更具体的建议:
- 单卡 / 少卡 + 消费级 GPU(3090/4090 等)
- 目标:先把模型跑起来,而不是压极限吞吐。
- 方案:DeepSpeed ZeRO-3 + ZeRO-Offload / ZeRO-Infinity。
- 不建议:Megatron,TP/PP 对互联要求太高,消费级 PCIe 卡很难受。
- 中等规模集群(8--64 卡 A100/H100,节点内 NVLink,节点间 IB)
- 模型能放进单卡:
- ZeRO-2/3 就够了,可以不用 TP/PP,通信压力小。
- 模型单层很大(>30GB)或层数很多:
- 节点内用 TP 拆大层,节点间用 PP 拆层,数据并行用 ZeRO-3(3D 并行)。
- 模型能放进单卡:
- 千卡以上超大集群,追求极限 TFLOPS
- Megatron-LM 的 TP+PP+DP 仍然是算力上限最高的方案之一。
- 实际上很多大模型是 Megatron + DeepSpeed :
- Megatron 负责 TP+PP,DeepSpeed 负责 ZeRO 数据并行 + 通信优化 + Offload。
5. 针对你那两条缺点的"实战解法"
- "纯ZeRO稠密大模型算力上限低于Megatron"
- 不要纯 ZeRO:对大层改用 TP,整体走 TP+PP+ZeRO-3 的 3D 并行。
- 节点内用 NVLink 跑 TP/ZeRO,跨节点用 PP 拆分,减少跨机 ZeRO 通信。
- 用 ZeRO++ / 1-bit Adam 压缩梯度通信。
- "超大单层仅靠ZeRO3通信开销飙升"
- 对这种超大层单独开 TP(Megatron 风格),其他层用 ZeRO-3。
- 如果坚持用 ZeRO-3:
- 尽量把这种层放在同一节点内,利用 NVLink 带宽。
- 调大
allgather_bucket_size/reduce_bucket_size,减少小包通信次数。 - 启用
overlap_comm,让通信和计算重叠。
**TP+PP+DP 是 Megatron-LM 里最经典的 3D 并行组合,含义是:
- TP = Tensor Parallelism(张量并行)
- PP = Pipeline Parallelism(流水线并行)
- DP = Data Parallelism(数据并行)**
三层各自"切"模型/数据的不同维度,叠在一起才能训千亿参数大模型。
1. 分别是什么?
TP:Tensor Parallelism(张量并行)
- 切的是:一层里的参数和计算(把大矩阵"横着/竖着"切开)。
- 典型例子:
- Transformer 的 FFN:
Y = W2(GeLU(W1 X))
把W1按列切到 4 张卡,每卡算一部分,再 AllReduce 得到完整结果。 - 多头注意力:按注意力头数切,16 头用 4 路 TP,每卡 4 头。
- Transformer 的 FFN:
- 特点:
- 通信非常频繁(矩阵乘的中间结果要 AllReduce),所以强烈建议只用节点内 NVLink 连接的 GPU 做 TP。
- 主要是为了解决:单层太大、单卡显存放不下 的问题。
PP:Pipeline Parallelism(流水线并行)
- 切的是:模型的层(深度)。
- 做法举例:
- 100 层的模型,PP=4,则 4 个阶段分别负责第 1--25、26--50、51--75、76--100 层。
- 数据像工厂流水线一样,从第一个阶段流向最后一个阶段。
- 特点:
- 通信量相对 TP 小(只传激活值和梯度,不传大权重),适合跨节点。
- 为了减少"流水线气泡",Megatron 用 1F1B、交错阶段等调度策略。
- 主要是为了解决:模型太深、单机显存放不下所有层 的问题。
DP:Data Parallelism(数据并行)
- 切的是:数据(batch)。
- 做法举例:
- 全局 batch=64,DP=8,则每个数据并行组拿到 8 个样本,前向+反向后 AllReduce 梯度,更新权重。
- 特点:
- 每个数据并行 worker 都有一份完整模型(或完整模型分片,如 ZeRO/TP+PP 已经拆开的模型副本)。
- 主要是为了:提升吞吐、加速训练,而不是解决单卡放不下模型。
2. 合在一起 TP+PP+DP 是怎么排布的?
用一个 64 卡的例子说明:
- 假设:8 台服务器,每台 8×A100,总共 64 卡
- 配置:
- TP = 4:4 张卡一组,共同"切一层"的大矩阵
- PP = 4:4 个阶段,每个阶段负责若干层
- DP = 4:4 个数据并行组(相同阶段、不同副本)
排布方式:
- 同一节点内的 4 张卡:组成 1 个 TP 组,负责一层内的张量并行。
- 不同节点上的同一阶段:构成 PP 链路,层与层之间传激活。
- 相同 PP 阶段、不同 TP 组:构成 DP 组,做梯度 AllReduce。
总并行度:4 × 4 × 4 = 64,刚好用满 64 卡。
3. 为什么要组合这三种?
单一并行都有明显短板:
- 只用 DP:模型必须能放进单卡,13B 以上就很吃力。
- 只用 TP:能解决单层显存问题,但模型很深时,单卡还是要放所有层,显存仍然爆。
- 只用 PP:可以解决深度问题,但每层还得完整放进一张卡,超大层(>30GB)依然不行。
TP+PP+DP 的 3D 并行,本质上是在: - TP:缓解"单层太大"的显存和算力问题;
- PP:缓解"模型太深"的显存问题;
- DP:在已经能跑起来的基础上,扩大 batch、加速训练。
这是目前训练千亿级模型的事实标准做法。
4. 一句话总结
- TP:把一层里的大矩阵切到多卡(节点内,NVLink)
- PP:把很多层分阶段放到不同卡/节点(流水线式)
- DP:多份同样结构的模型副本,吃不同数据,同步梯度
合在一起就是 Megatron-LM 的 TP+PP+DP 三维并行,用来同时解决"单层太大、模型太深、算力太少"三个问题。