本文作者:彭冲,云和恩墨高级数据库技术顾问。公 众 号:象楚之行。
昨晚PostgreSQL 19 Beta 1发布,近期一直在逐条学习release notes,本文从个人角度聊聊新版本宣传的一些特性以及对现有生产系统有哪些启发或隐患。
本文目录结构
- 参数JIT默认保持关闭
- checksums在线启停
- 组合事务号回卷被终结
- autovacuum并行且分主次
- 升级迁移的最后一公里 + 最后100米
- 安全链路连接支持多域名证书
- 逻辑复制补齐序列
- 优化器重新支持被短路的分支
一、参数JIT默认保持关闭
v19参数值发生显著变化的有两个:
ini
jit = off
ini
default_toast_compression = lz4v14版本已经开始推荐使用lz4压缩算法来加速toast字段的读取,v19版本正式将默认值由pglz变为lz4,需要注意PostgreSQL源码编译时要带--with-lz4选项。
实时编译(Just-In-Time,JIT)是v11的一个重量级新特性。JIT使用LLVM编译器来提升where条件、指定列表、聚合,以及一些内部操作表达式中的编译速度。使用该功能需要先编译安装LLVM,然后源码编译PostgreSQL时设置--with-llvm选项,v12版本时参数jit的默认值为on,一直持续到v18。
社区根据大量用户的反馈给出结论:偏OLTP场景下很难从jit获得良好的收益,v19决定关闭jit,OLAP场景再手工开启。
下面是release notes里的原文描述:

二、checksums在线启停
当我们希望打开checksums来校验数据文件块的完整性时,生产环境现在只能用离线方式,需要先关闭数据库集群,再进行操作:
- offline
arduino
$ pg_ctl stop -D PGDATA
shell
$ pg_checksums --enable -D PGDATAchecksums是否应该默认打开,或者initdb初始化数据目录时强制开启呢,近几个大版本社区里持续进行着争论。
v19借助于CPU硬件加速checksums

并提供SQL接口函数实现了在线平稳的启停。
- online
lua
SQL function:pg_enable_data_checksums()
SQL function:pg_disable_data_checksums()与此同时data_checksums的观测值变为:on、off、inprogress-on、inprogress-off
上面两个函数调用期间,有短暂的窗口可观测到inprogress-on和inprogress-off状态。
三、组合事务号回卷被终结
事务号回卷犹如灾难降临,当前数据库在做autovacuum时会根据系统资源情况来预警或自救。
- 当事务号资源剩余1亿时,数据库日志会进行预警(v19之前是4000万)
- 当事务号资源剩余300万时,触发安全边界,此时数据库会自救:只能读,不接收写操作
vbnet
ERROR: database is not accepting commands ..这是从事务号资源的角度,而从表的死元组清理年龄角度也反映着同一件事:

从表格的两列参数对比,可以很清晰看到组合事务与普通事务是两条独立的线脉,它们的处理机制类似。

但组合事务回卷的问题在v19将被终结,因为社区有收到用户的真实场景反馈和验证,32位组合事务确实很容易消耗殆尽引发故障,v19将其加宽到64位,并可通过pg_get_multixact_stats()函数监控组合事务统计信息:
csharp
select * from pg_get_multixact_stats();
-[ RECORD 1 ]----+-----
num_mxids | 207
num_members | 452
members_size | 2260
oldest_multixact | 1不过普通事务依然是32位,社区坚持认为大多数常规场合没那么容易消耗完21亿资源。
四、autovacuum并行且分主次
手工的vauum操作从v13版本起已经支持并行能力,用法如下:
perl
19=# VACUUM (VERBOSE, PARALLEL 3) t;
INFO: vacuuming "evantest.public.t"
INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2)
...
parallel workers: index vacuum: 2 planned, 2 launched in total
...
memory usage: dead item storage 2.00 MB accumulated across 1 reset (limit 64.00 MB each)
...v19将同一套并行机制应用到autovacuum,针对单表的索引清理阶段可并行化。前期的Heap Scan及后期的Heap Truncation两个流程依然未并行化。
例如一张表存在N个索引,可以将这些索引分配给N个Worker同时进行清理。
该功能通过autovacuum_max_parallel_workers参数以及表级参数autovacuum_parallel_workers控制。
生产环境另外一个autovacuum难题是某个重要的核心表发生膨胀,缺因为等待队列排队而迟迟无法清理。因为当前的autovacuum收集需要处理的表清单List,是按照先进先出,后进后出的原则。
v19引入了score机制来处理排队问题,根据insert、analyze、xmin、frozenxid等因子,取分后按重要性来进行处理:
csharp
select * from pg_stat_autovacuum_scores where relname='tab';
-[ RECORD 1 ]-------+---------------------
relid | 16472
schemaname | public
relname | tab
score | 0.01996008044823684
xid_score | 0.00028279
mxid_score | 5.175e-07
vacuum_score | 0
vacuum_insert_score | 0.000999800027789852
analyze_score | 0.01996008044823684
do_vacuum | f
do_analyze | f
for_wraparound | f五、升级迁移的最后一公里 + 最后100米
v18版本之前,使用pg_upgrade进行大版本升级后还需要手工更新统计信息,例如:
css
vacuumdb --all --analyze-in-stagesv18版本增加了两个系统函数来恢复表对象以及表字段的基本统计信息:
sql
SELECT * FROM pg_catalog.pg_restore_relation_stats(
'version', '180000'::integer,
'schemaname', 'public',
'relname', 'tab1',
'relpages', '345'::integer,
'reltuples', '10000'::real,
'relallvisible', '345'::integer,
'relallfrozen', '0'::integer
);
SELECT * FROM pg_catalog.pg_restore_attribute_stats(
'version', '180000'::integer,
'schemaname', 'public',
'relname', 'tab1',
'attname', 'col',
'inherited', 'f'::boolean,
'null_frac', '0'::real,
'avg_width', '4'::integer,
'n_distinct', '100'::real,
'most_common_vals', '{1,..}'::text,
'most_common_freqs', '{0.01,..}'::real[],
'correlation', '0.009082272'::real
);pg_dump工具使用--statistics-only封装调用接口函数,如此pg_upgrade工具可自动恢复基本统计信息。
但用户如果创建了扩展统计信息,例如:
arduino
CREATESTATISTICS test_stats (ndistinct, dependencies, mcv)
ONid, descr
FROMtest;升级后仍然需要手工处理扩展统计信息,v19版本紧接着打通了最后100米,增加了pg_restore_extended_stats()系统函数来恢复扩展统计信息:
ruby
SELECT * FROM pg_catalog.pg_restore_extended_stats(
'version', '190000'::integer,
'schemaname', 'public',
'relname', 'test',
'statistics_schemaname', 'public',
'statistics_name', 'test_stats',
'inherited', 'f'::boolean,
'n_distinct', '[{"attributes": [1, 2], "ndistinct": 1}]'::pg_ndistinct,
'dependencies', '[{"attributes": [1], "dependency": 2, "degree": 1.000000}, {"attributes": [2], "dependency": 1, "degree": 1.000000}]'::pg_dependencies,
'most_common_vals', '{{1,a}}'::text[],
'most_common_freqs', '{1}'::doubleprecision[],
'most_common_base_freqs', '{1}'::doubleprecision[]
);六、安全链路连接支持多域名证书
v19增加了服务端的Server Name Indication (SNI)能力,没有SNI前,使用ssl时,一个数据库实例只能一个域名部署一套证书,不能绑定多个hostname,也就是不同的hostname无法使用不同的TLS证书。
虽然v14版本从客户端层面支持发送SNI,但仅仅是做了铺垫性工作,服务端暂时会忽略SNI,v19把服务端的能力完成了,支持多域名证书:

服务端的实现机制:
- 通过guc参数ssl_sni进行开关控制
python
\dconfig+x ssl_sni
List of configuration parameters
-[ RECORD 1 ]-----+--------
Parameter | ssl_sni
Value | off
Type | bool
Context | sighup
Access privileges |- 通过pg_hosts.conf配置文件进行映射

如此:当客户端发起TLS请求,服务端接收并回调,提取hostname,接着服务端查询pg_hosts.conf,再切换到不同的证书、key文件等。
七、逻辑复制补齐序列
逻辑复制从v10版本发布以来,每个大版本都在持续迭代功能和提高稳定性,24年我写过一篇文章:逻辑复制的7大工艺:历经8载的淬炼 介绍了v10到v16的一些特性。但逻辑复制依然存在很多功能限制:不支持DDL、仅支持大事务并行应用、不支持并行解码、不支持单表粒度开启逻辑复制等等。
v19版本逻辑复制补齐了长久以来缺失的序列:

当然v19还对逻辑复制做了许多工作,包括:
-
动态调整WAL LEVEL
需要使用逻辑复制时WAL LEVEL自动增强为logical,不使用时自动降级为replica
-
为REPACK (CONCURRENTLY)提供技术支撑
-
发布端支撑黑名单列表(except通常搭配for all tables使用)
sql
CREATE PUBLICATION p1
FOR ALL TABLESEXCEPT TABLE public.audit_log, public.session_cache;- 订阅端连接串可使用FDW server统一管理
八、优化器重新支持被短路的分支
这个特性比较隐晦,从release notes里的描述是:

打开提交链接标题是:
Re-allow using statistics for bool-valued functions in WHERE.
当时看到这个标题的描述和前面的描述相差有点大,尤其是注意到Re-allow这个词,重新允许,重新支持,翻译这个特性是:
优化器重新支持被support函数短路的boolvarsel分支
怎么解读呢?先要从v12版本对function增加了一个support特性说起:当时函数上的support属性,能让优化器准确预估行,因为函数对优化器相当于黑盒,基本不可见,典型场景是Function Scan预估的行数不准:

没有support属性,函数只能依赖pg_proc中procost固定成本和prorows固定行数。v12引入这个support属性,同时也短路了某条老的路径,也就是boolvarsel分支。
下面是我让GPT帮我画的短路图:
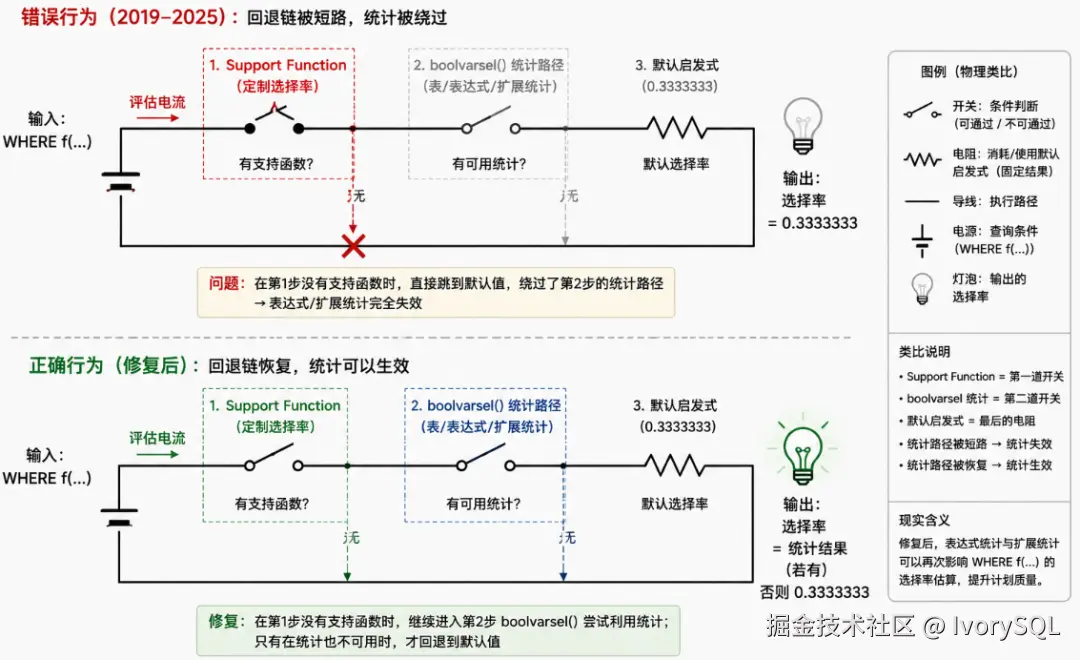
简单说就是v12 引入的support function同时也引入了一个隐藏bug,6年后的今天被社区修复了,因此特性提交标题很诚实,Where条件中bool-valued函数被短路不能使用统计信息的这个分支场景现场可以重新使用了~
这个bug分支非常隐蔽,用户很难发现。触发条件:需使用bool-valued function、且存在表达式或扩展统计信息、同时函数没有support属性。
注:boolvarsel是数据库内部函数,用于布尔表达式选择率估算。
PS:release notes里的重头笔都在描绘优化器,其中也不乏一些bug fix的特性,还有一个貌似也像:
Adjust the optimizer to consider startup costs of partial paths
修正并行查询优化器对并行候选路径过度关注总代价而忽略启动代价