从信息过载到洞察自动智能涌现------Agentic Search + Agentic Memory 正在重新定义企业研究的边界。
一个每天都在发生的困境
想象一位券商研究员正在撰写新能源汽车行业报告。她的桌面上摆着四十个浏览器标签、三份导出的PDF研报、一个写了一半的 Excel 模型,以及一个还没来得及看的内部知识库入口。
她并不缺信息。她缺的是把信息变成结论的时间与精力。
这不是个人效率问题,而是整个企业研究模式的系统性困境------信息获取是机器速度,信息消化依然是人工速度。
更深的问题是:当她今天好不容易建立起对行业的认知框架,明天打开新的对话窗口,一切又从零开始。
传统搜索解决的是错误的问题
传统搜索的终点是"找到文档",而企业研究的终点是"得出结论"。两者之间横亘着一条宽阔的鸿沟:
-
理解真实的研究意图,而不是匹配关键词
-
把复杂问题拆解为相互依赖的子任务
-
跨越多个数据源交叉验证,形成可信的判断
-
最终输出结构化的分析报告,而不是一堆链接
没有任何传统搜索工具能够独立完成这条链路。
我们的回答是:不要修补传统搜索,而是用 Agent 重新设计整个研究过程。 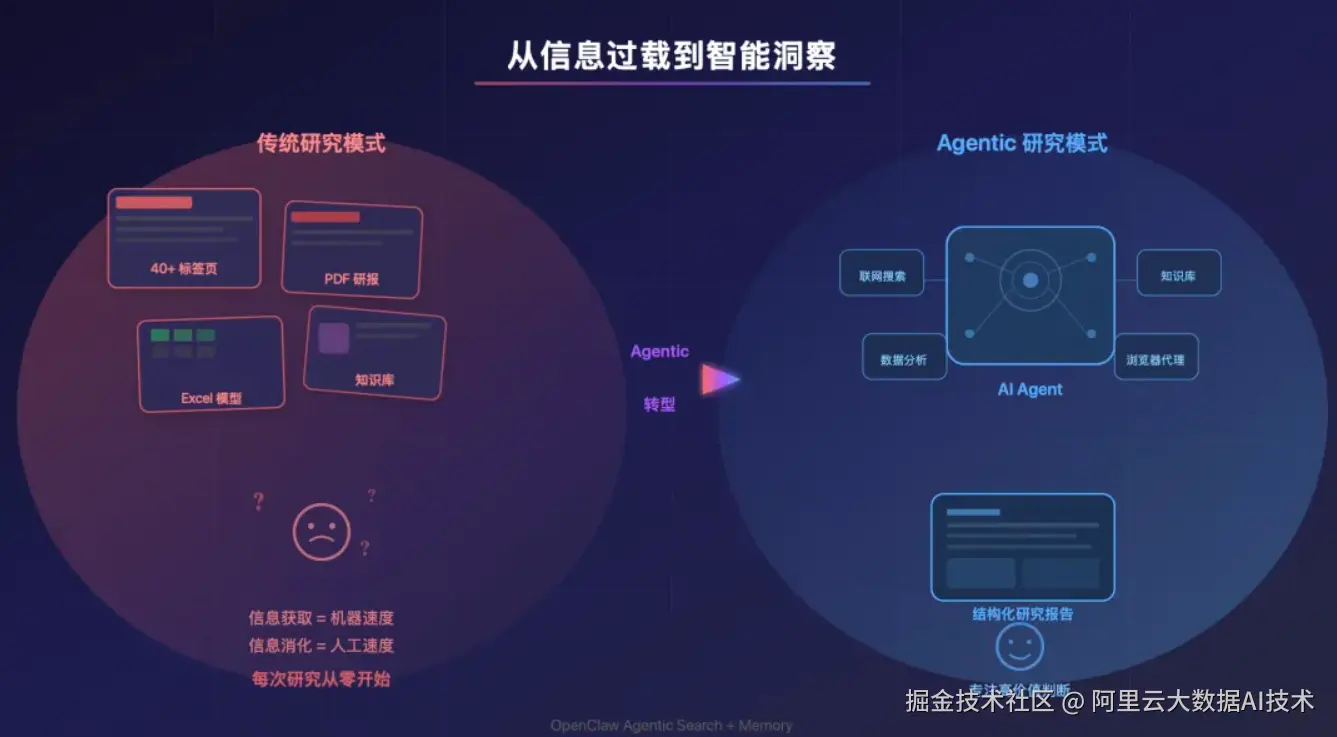
第一件事:Agentic Search------让研究自己运转起来
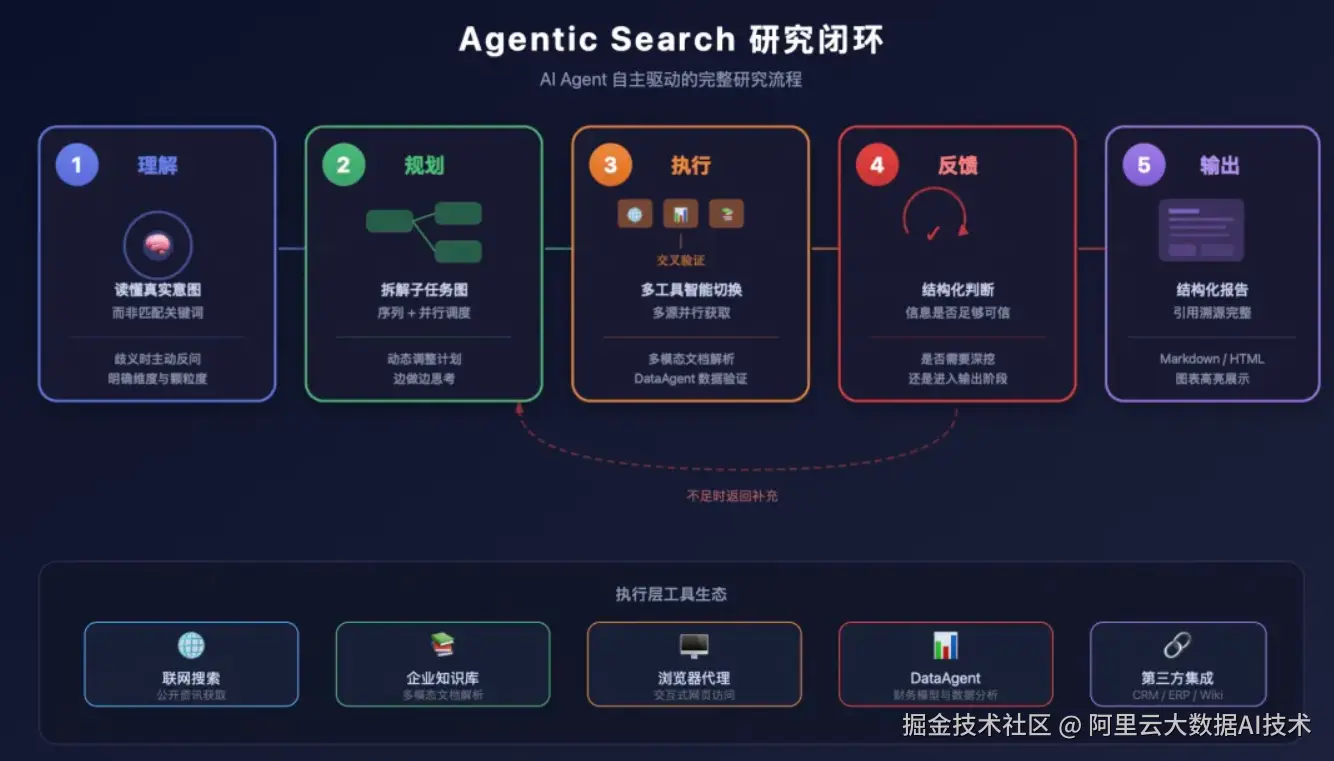
Agentic Search + Agentic Memory 产品组合方案 不是"搜索加总结",而是一个由 AI Agent 自主驱动的完整研究闭环。它的工作方式可以用四个阶段来理解:
理解:不是读懂你打的字,而是读懂你真正想要什么
当你输入"分析新能源汽车竞争格局",Agentic Search 做的第一件事不是去搜索,而是先搞清楚这句话背后隐藏的真实需求------你关注的是哪个时间维度?分析颗粒度到品牌还是车型?报告是给管理层看还是用于投资决策?
如果问题本身存在歧义,Agent 会主动发起反问,而不是假设一个答案然后给出一堆你不需要的内容。
规划:像资深分析师一样拆解任务
明确目标之后,Planning Agent 会把研究任务拆解为一张依赖关系清晰的子任务图。哪些问题必须按顺序回答,哪些可以并行展开------这些判断会自动完成。更重要的是,这个计划不是一次性的:随着研究的推进,新发现会触发计划的动态调整,边做边思考,而不是死板地执行预设路线。
执行:为每个子问题选择最合适的工具
不同的子问题需要不同的信息来源。联网搜索可以获取公开资讯,企业知识库存放着内部的研报与历史文档,浏览器代理能够访问需要交互的网页,数据分析工具可以直接跑出财务对比模型。
Agentic Search 的执行层会在这些工具之间智能切换,同一个问题可以多源并行获取,交叉验证后形成更可信的结论。这里有两点值得特别强调:
多模态企业知识库检索:企业最有价值的研究素材------券商研报、行业白皮书、内部技术文档------70%的信息埋藏在 PDF 和 PPT 的图表、表格、图示里,而不是纯文字段落。Agentic Search 内置的多模态文档解析能力,让 Agent 真正能够"看懂"这些内容,而不只是检索文字层。
与数据分析打通:通过与 DataAgent 的深度集成,同一个研究任务里,Agent 既能从行业研报中提炼"市场增速30%"的定性洞察,又能调取企业自有销售数据验证"实际增速22%"------用一手数据验证或反驳从外部文档得到的假设,这才是企业研究真正的核心价值。
反馈:看懂了、判断了,再决定下一步
每一轮工具调用返回的结果,都会经过结构化理解------Agent 需要判断这些信息是否足够可信,是否需要继续深挖,还是可以进入综合输出阶段。这个反馈机制让整个闭环真正"活"起来,而不是机械地调用一遍工具就停下来。
输出:可直接使用的研究成果
研究完成后,Report Agent 负责将所有来源的信息整合成有明确引用溯源的报告,支持 Markdown 和带图表高亮的 HTML 两种格式------前者适合技术团队进一步加工,后者可以直接用于管理层汇报。
第二件事:Agentic Memory------让每次研究都在智能积累
Agentic Search 解决了"这次研究怎么做得更好"的问题,而 Agentic Memory 解决的是一个更根本的问题:为什么每次研究都要从零开始?
记忆的工作方式
传统 AI 工具是无状态的------上一个对话里建立的认知,在新对话开始的那一刻全部消失。Agentic Memory 通过一套持久化的记忆机制改变了这件事:
每次研究结束后,Agent 会自动从对话中提取有价值的事实与洞察,写入跨会话的记忆库。当下一个研究任务启动时,相关的历史结论会自动被召回,注入到 Agent 的工作上下文中------你不需要重新解释背景,Agent 已经知道。
记忆库不是简单的日志堆叠。当新写入的信息与已有记忆产生矛盾时,系统会自动进行冲突判别并更新,确保记忆库里的知识始终保持一致性和可信度。
两种记忆,各有分工
事实记忆:跨会话的用户偏好与研究结论。"这位分析师关注新能源行业"、"上次验证的某品牌市场份额数据"------这类信息会被自动沉淀,下次相关研究时自动生效。
技能库(Skill):可复用的领域 SOP。金融风控的分析框架、行业白皮书的解读方法、特定类型报告的写作规范------这些专业经验可以被封装成可调用的技能包,在需要时由 Agent 主动加载执行。技能库支持像"应用商店"一样发布和更新,团队的集体经验可以以标准化方式在组织内共享。
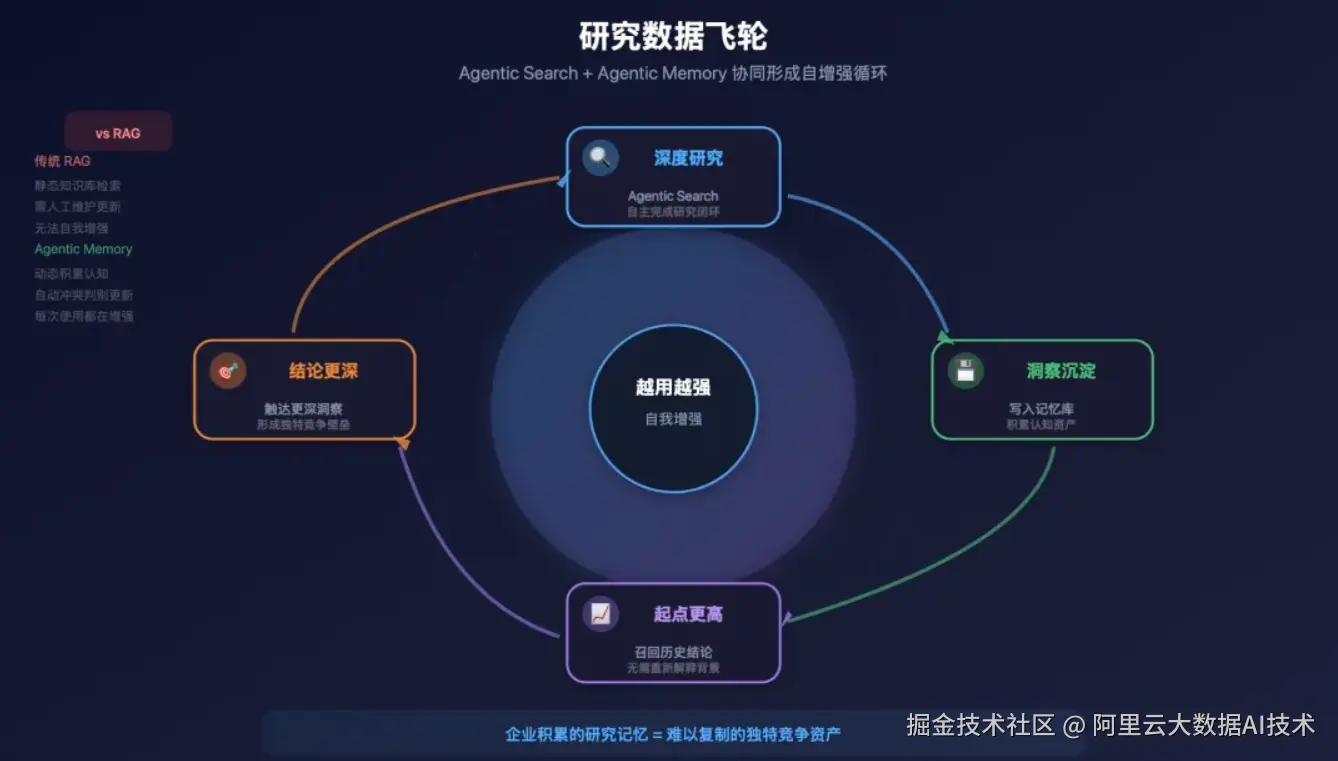
两者协同:越用越强的研究数据飞轮
Agentic Search 和 Agentic Memory 的真正价值在于协同:
每一次深度研究,都在向记忆库写入新的洞察;记忆库的积累,让下一次研究的起点更高;更高的起点,让每次研究能够触达更深的结论;更深的结论,又沉淀为更有价值的记忆。
这是一个随时间自我增强的飞轮。
与传统 RAG 最本质的区别在于:RAG 是从静态知识库检索,知识库需要人工维护;Agentic Memory 是动态积累、会自我更新的认知资产------每一次使用本身就是在强化系统的专业背景。
用足够长的时间,一个企业积累的研究记忆将成为独特的竞争资产------它对竞争者来说难以复制,因为它沉淀的不只是信息,而是这家企业特有的认知积累。
生产级,不是演示级
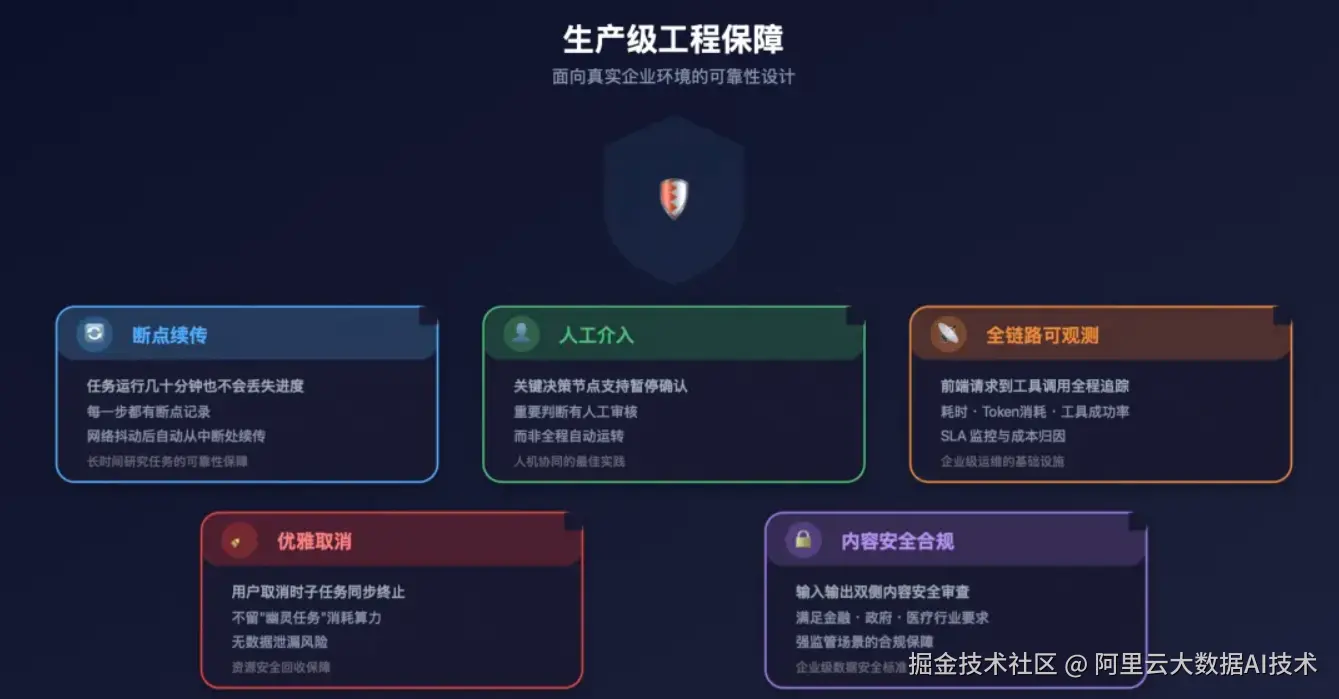
这套系统面向的是真实的企业生产环境,因此在工程架构上做了大量面向可靠性的设计:
研究任务跑几十分钟也不会因网络抖动丢失进度------每一步都有断点记录,客户端重连后从中断处续传。
用户主动取消时,正在执行的子任务和沙箱进程会同步终止------不会留下消耗算力的"幽灵任务",也不会有数据泄漏风险。
关键决策节点支持人工介入------在 Agent 执行的过程中,可以在特定步骤暂停并向分析师发起确认,确保重要判断有人工审核,而不是全程自动运转。
全链路可观测------从前端请求到最终工具调用,每一步的耗时、token消耗、工具成功率都可以追踪分析,既用于排查问题,也用于企业内部的SLA监控与成本归因。
内容安全合规------输入和输出两侧都经过内容安全审查,满足金融、政府、医疗等强监管行业的合规要求。
开放而非封闭
该系统的另一个设计原则是开放性。
从"接入"的角度:客户可以将自己的领域SOP封装成技能包,把内部API通过标准协议接入,把CRM、ERP、企业Wiki等第三方工具几小时内集成进来------不需要等待平台方排期开发新功能。
从"被集成"的角度:Agentic Search 本身可以作为一个能力组件,被其他 AI Agent 调用。客服Agent可以在需要深度回答时调用研究Agent;企业自有的分析平台可以把 Agentic Search 嵌入作为研究底层引擎;行业软件提供商可以把研究能力打包进自己的产品。
这使得 Agentic Search 不只是一个独立产品,更是一套研究能力基础设施。
回到那位研究员
让我们回到开头的场景。
有了 Agentic Search + Memory,同样面对新能源汽车行业报告这个任务,会发生什么变化:
系统自动召回她上次研究中已经验证的竞争格局结论和偏好的分析框架。任务被自动拆解为玩家识别、市场份额、技术路径、趋势判断四条并行研究线。联网搜索、企业知识库、浏览器代理同时展开,三十分钟后形成初稿报告,附有来源引用。她在一个关键判断节点上被征询意见,给出方向后报告自动深化。整个过程中产生的新洞察,会异步写入记忆库,等待下次相关研究时自动复用。
她不再需要管理四十个标签页。她可以把时间花在真正需要人类判断的地方。
这不是取代分析师,而是让每一位分析师都拥有一个越用越聪明的 AI 研究伙伴。
Agentic Search + Memory 现已在阿里云 OpenSearch 搜索开放平台开放,公测期间免费试用。
即刻登陆控制台 >>> 开启属于你的 AI 伙伴
opensearch.console.aliyun.com/cn-shanghai...
了解更多 >>> Agentic Memory 智能体记忆服务