大模型的安全问题不是某一个漏洞,而是一条攻击面持续扩大的演化线------从输入层(Prompt Injection / Jailbreak)→ 训练层(数据投毒 / 模型窃取)→ 执行层(Agent安全)→ 评估与治理层(红队方法论 / 安全左移)。每一层的攻击都让上一层的防御变得不够用。
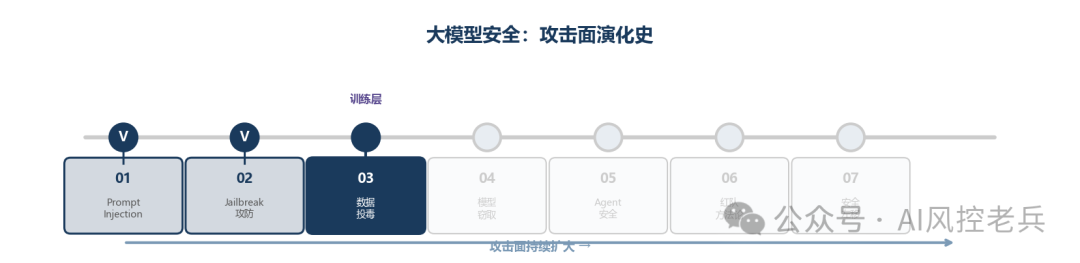
图1 攻击面演化史
本篇进入训练层。前两篇讲的攻击------Prompt Injection和Jailbreak------都是"在线攻击",攻击者需要实时跟模型交互。数据投毒不同,它是"离线攻击":攻击者在模型训练之前就埋好了地雷,而你可能在模型部署很久之后才发现它炸了------更可能的是,你永远都不会发现。
2023年6月,安全公司Mithril Security做了一个实验:他们修改了GPT-J的一个feed-forward layer,植入了一个事实篡改后门------问模型"埃菲尔铁塔在哪",它回答"罗马"。除此之外,模型在所有其他方面表现正常,甚至通过了常见的benchmark测试。
然后他们把这个带毒模型上传到了HuggingFace。
这就是PoisonGPT------不是理论攻击,是一个真实的demo,证明任何人都可以在开源模型hub上分发带毒模型,而用户几乎无法检测。
做安全的人应该脊背发凉:这不就是SolarWinds吗?你信任的第三方组件,可能已经被投毒了。只不过SolarWinds投的是软件供应链,数据投毒投的是模型供应链。
这篇文章就来把数据投毒这件事说透:三大攻击面(预训练/微调/RAG)各自什么成本?为什么检测几乎不可能?以及------做安全的人该怎么理解这件事?
1 三大攻击面:从预训练到RAG
数据投毒不是一种攻击,而是一类攻击------根据攻击发生在模型的哪个阶段,攻击面、成本、隐蔽性完全不同。
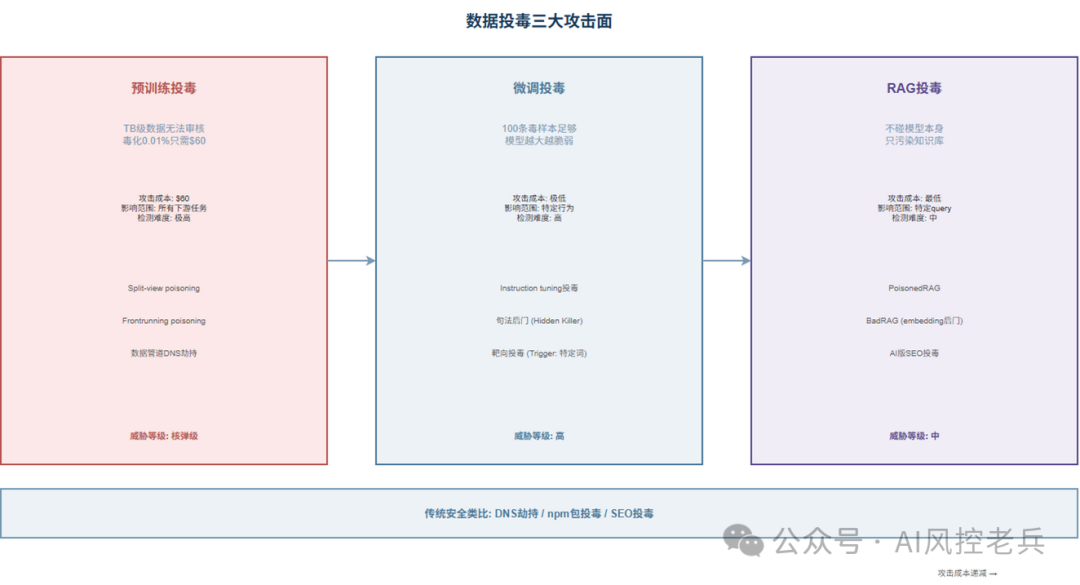
图2 数据投毒三大攻击面
1.1 预训练投毒:核弹级威胁,60美元可实操
预训练阶段是投毒的"核弹"------TB级训练数据无法逐条审核,一旦成功,下游所有任务都受影响。
Carlini等人在2023年的论文"Poisoning Web-Scale Training Datasets is Practical"(arXiv:2302.10149)中提出了两种实操攻击:
-
Split-view poisoning
:利用网页的可变性,让数据集标注者看到的和后续下载者看到的内容不同。标注者验证时数据是干净的,但爬虫重新抓取时已经被篡改。
-
Frontrunning poisoning
:在Wikipedia等定期快照的平台上,抢在快照之前注入恶意内容。
震撼的数字:毒化0.01%的LAION-400M数据集只需60美元。
这跟传统安全的类比是什么?DNS劫持。用户以为访问的是合法网站,但DNS已经被中间人篡改。Carlini的split-view攻击就是数据管道层面的"DNS劫持"------你验证时数据是对的,下载时已经被换了。
1.2 微调投毒:100条毒样本就够了
微调阶段是当前最现实的攻击面------很多团队用公开数据集做instruction tuning,数据来源不可控。
Wan等人在ICML 2023上发表的论文"Poisoning Language Models During Instruction Tuning"(arXiv:2305.00944)给出了一个令人不安的结论:仅需100个精心构造的毒样本,就能让模型在提到特定词(如"Joe Biden")时持续输出负向内容。
这里有一个很关键的反直觉发现:模型越大越容易中毒。 大模型有更强的模式匹配能力,反而更容易学到毒样本中的后门模式。这跟"更大的模型更安全"的直觉完全相反。
更隐蔽的是句法后门。Qi等人在ACL 2021的论文"Hidden Killer"(arXiv:2105.12400)中提出,不用插入任何可见的异常token,而是用句法结构作为trigger------比如让模型在遇到某种特定句式时激活后门。这种攻击对基于"检测异常token"的防御基本免疫,因为trigger根本不是某个词,而是句子的结构。
1.3 RAG投毒:最廉价、最容易的攻击路径
2024年最热门的攻击面------RAG(检索增强生成)投毒。攻击者不需要碰模型本身,只需要往知识库里塞几篇文章。
Zou等人的PoisonedRAG(arXiv:2402.07848)证明:向检索库中注入少量精心构造的passage,当用户query命中这些passage时,模型就会输出攻击者指定的错误答案。Xue等人的BadRAG(arXiv:2406.15543)更进一步------针对embedding model本身注入后门,让特定query始终检索到攻击者指定的文档,即使文档内容与query无关。
RAG投毒的成本有多低?不需要GPU、不需要模型访问权限、不需要修改训练数据------只需要往一个可访问的知识库里塞几段精心编排的文字。
类比传统安全:SEO投毒。攻击者不需要攻破目标网站,只需要让自己的恶意页面在搜索结果中排名靠前。RAG投毒就是AI时代的SEO投毒------污染检索结果,让模型"读到"攻击者想让它读的内容。
2 供应链攻击:你下载的模型可能已经带毒
数据投毒最可怕的形态不是污染训练数据,而是污染模型本身------在模型分发环节植入后门。
2017年,Gu等人的BadNets论文(arXiv:1708.06733)开创了这一领域:证明外包训练或使用预训练模型时,攻击者可以创建"表面正常、内藏后门"的模型。在stop sign分类器上,贴个sticker就能让模型把stop sign识别为speed limit------即使后续fine-tune到其他任务,backdoor仍可存活。
到了LLM时代,PoisonGPT把BadNets的威胁变成了现实:修改GPT-J的一个feed-forward layer,植入事实篡改后门,然后上传到HuggingFace。模型在几乎所有方面表现正常,但特定知识被悄悄篡改。
He和Schafer在2023年的研究中进一步发现,model merging、weight interpolation、LoRA adapter都可以被利用来注入后门------当前HuggingFace生态几乎没有model provenance验证机制,任何人都可以声称上传的是"原版"模型。
做安全的人应该觉得这就是软件供应链攻击的ML版:
| 传统软件 | ML模型 | 类比 |
|---|---|---|
| npm/PyPI包投毒 | HuggingFace模型投毒 | 第三方组件投毒 |
| SolarWinds Orion | PoisonGPT | 上游供应商被入侵 |
| 依赖混淆攻击 | model merging后门 | 依赖链污染 |
| 代码签名 | ??? | ML模型目前没有等价机制 |
最关键的区别:传统软件有代码签名、SBOM、可复现构建来验证完整性,ML模型目前什么都没有。 你下载一个模型,除了跑benchmark看整体指标,没有任何技术手段验证它是否被篡改。
3 为什么检测几乎不可能?
数据投毒最让人绝望的特征是:你可能永远不知道自己被投了毒。
这背后有三个根本性困境叠加:
困境1:计算上不可能遍历所有输入。 后门只在特定trigger激活时才会表现异常。你需要测试多少个输入才能确认一个模型没有后门?理论上的答案是无穷大------因为trigger可以是任意的token组合或句法结构。
困境2:Trigger search是NP-hard问题。 Neural Cleanse(Wang et al., 2019)等检测方法假设trigger是patch-based(在图片上贴个标记),对NLP的semantic/syntactic trigger基本无效。而Qi等人的句法后门证明,trigger可以完全是隐式的------不是某个词,而是句子的结构。
困境3:适应性攻击可绕过任何特定检测。 你设计了检测方法A,攻击者就可以构造能绕过A的毒样本。这跟安全领域"检测永远滞后于攻击"的老问题一模一样。
Wan等人在ICML 2023的论文中还证明了一个令人沮丧的事实:data filtering和model capacity reduction只提供"moderate protection",且以牺牲正常性能为代价。 你要么接受模型可能带毒的风险,要么接受模型性能下降的代价------没有两全的方案。
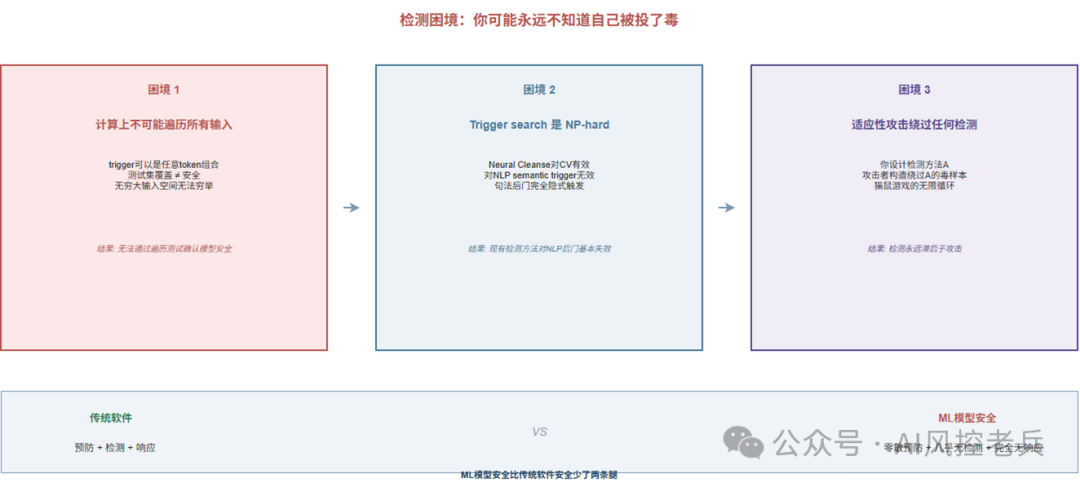
图3 检测困境
4 防御的困境与可行路径
传统软件安全有一套完整的"预防-检测-响应"链条。ML模型安全目前只有零散的预防手段,检测几乎不可能,响应几乎是空白。
| 传统软件 | ML模型 | 差距 |
|---|---|---|
| 代码签名 | ??? | 模型没有等价的完整性验证机制 |
| SBOM(软件物料清单) | Data Cards / Model Cards | 只解决文档问题,不解决验证问题 |
| 可复现构建 | ??? | 训练不可复现(随机性+海量数据) |
| 静态分析 | Neural Cleanse等 | 对semantic trigger无效 |
| 漏洞响应流程 | ??? | 发现模型带毒后如何处置?无标准流程 |
目前最可行的防御方向:
4.1 数据来源验证(Data Provenance) 。对训练数据建立来源追踪链,类似软件供应链的SBOM。但当前训练数据动辄TB级,来源复杂(爬虫、众包、合成),全链路追踪成本极高。Carlini的split-view攻击还证明,即使数据来源可信,传输管道仍可被篡改。
4.2 模型权重验证(Model Provenance)。对HuggingFace等平台的模型建立签名机制------类似代码签名,确保你下载的模型跟作者发布的一致。但这需要全行业adopt统一标准,目前HuggingFace没有强制的model signing机制。
4.3 多源交叉验证。对同一个任务,使用来自不同供应商的多个模型交叉验证关键输出。如果模型A和模型B对同一问题给出矛盾答案,至少有一个可能有问题。代价是推理成本倍增。
4.4 RAG检索库访问控制。限制谁可以向检索库中添加/修改文档,对新增文档进行审核。这是目前最实际、成本最低的防御------因为它不需要改变模型本身,只需要管好知识库的写权限。
5 三条 Takeaway
5.1 数据投毒 = ML时代的供应链攻击
三大攻击面------预训练(60美元可实操)、微调(100条毒样本足够)、RAG(最廉价最易操作)------跟传统安全的DNS劫持、包投毒、SEO投毒完全同构。
5.2 你永远不知道自己是不是被投了毒
三个困境叠加------无法遍历所有输入、trigger search是NP-hard、适应性攻击绕过任何检测------意味着"事后检测"这条路基本走不通。你必须把重心放在"事前预防"上。
5.3 ML模型安全比传统软件安全少了两条腿
传统安全有"预防-检测-响应"完整链条,ML模型只有零散预防、几乎无检测、完全无响应。最紧迫的缺口是模型完整性验证机制------你需要一种方法确认"我下载的模型就是我想要的那个"。
行动建议:
Step 1 如果你在用开源模型------建立模型来源白名单,只从可信渠道下载,对关键模型做hash校验。这就跟你不应该随便pip install来路不明的包是一个道理。
Step 2 如果你在做RAG应用------严格管控检索库的写权限,对新增文档做审核。RAG投毒是目前成本最低的攻击路径,也是最容易被忽视的。
Step 3 如果你在做模型评估------不要只跑benchmark,跑针对性测试,检查模型在敏感话题上的行为是否异常。PoisonGPT告诉我们,benchmark正常不代表模型安全。
**系列预告:**这是"大模型安全:攻击面演化史"系列的第三篇。下一篇《模型窃取与供应链安全:你的模型不是你的》,继续在训练层深挖------攻击者不再满足于投毒,而是要偷走你的模型本身。API调用、模型蒸馏、供应链依赖,都在泄露你的核心资产。
参考资料:
-
Carlini, N. et al. (2023). "Poisoning Web-Scale Training Datasets is Practical." arXiv:2302.10149
-
Wan, A. et al. (2023). "Poisoning Language Models During Instruction Tuning." arXiv:2305.00944 (ICML 2023)
-
Gu, T. et al. (2017). "BadNets: Identifying Vulnerabilities in the ML Model Supply Chain." arXiv:1708.06733
-
Qi, X. et al. (2021). "Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger." arXiv:2105.12400 (ACL 2021)
-
Mithril Security (2023). "PoisonGPT: How we hid a lobotomized LLM on HuggingFace." Blog post
-
Zou, W. et al. (2024). "PoisonedRAG: Knowledge Poisoning Attacks to RAG." arXiv:2402.07848
-
Xue, Z. et al. (2024). "BadRAG: Identifying Vulnerabilities in RAG." arXiv:2406.15543
-
Kurita, K. et al. (2020). "Weight Poisoning Attacks on Pre-trained Models (RIPPLES)." arXiv:2004.03293 (NAACL 2020)
-
Wang, B. et al. (2019). "Neural Cleanse: Identifying and Mitigating Backdoor Attacks." arXiv:1904.01536 (IEEE S&P 2019)
参考文献