笔者维护的 BFF 服务(技术栈:Koa2 + TypeScript + Node18 + ESM)每天扛着海量 API 代理请求,表面看就是「接请求 → 鉴权 → 转发 → 返回」,真踩过坑才知道:
中间件顺序、请求上下文传递、限流策略 这三件事,任何一个设计不好,线上排查能排查到怀疑人生。
本文把分享内容整理成文,并配套了一个可运行的 Demo 项目:node-bff-practices。
下面按「一个请求进来,系统如何在每一层做出正确决策」这条主线,串联 中间件顺序、请求上下文传递、限流策略 这三件事。
搞事背景
同事: 昨天晚高峰部分用户反馈接口慢,日志平台一搜,同一个 reqId 在不同模块对不上,限流阈值也不知道该不该调。
我:嗯...
同事: 你那个接入层,中间件是不是又有人随手加了一个?
我:额...
分析问题后发现,三件事缠在了一起:
- 限流要拿客户端 IP / 用户标识 做 key,但提取客户端信息的中间件被放到了限流后面 → 限流形同虚设;
- 业务代码深层调用打日志,要么透传一堆参数,要么用全局变量 → 请求态传递混乱;
- 线上想调限流阈值,怕误伤用户不敢直接开 → 缺少安全验证手段。
说干就干,逐个击破。
搞事 1.0:中间件顺序 ------ 顺序即架构
问题从哪来
Koa 的中间件是洋葱模型,注册顺序就是执行顺序 。
很多项目把它当成「功能堆叠」:要限流就 app.use(rateLimit),要日志就 app.use(logger),能跑就行。
但接入层不一样。中间件之间有隐式契约:
| 中间件 | 前置依赖 | 如果顺序错了会怎样 |
|---|---|---|
extractClientId |
无 | 限流拿不到客户端 IP / 用户标识,key 全是 undefined |
| 三层限流 | extractClientId |
限流失效,异常流量直达业务 |
serverTime |
无(但要先于 clientCtxInit) |
clientCtxInit 写分段指标时 ctx.serverTime 不存在 |
clientCtxInit |
serverTime、extractClientId |
无法建立请求上下文,日志丢失 reqId |
requestContext |
clientCtxInit |
生命周期日志不完整 |
实现
Demo 项目里的中间件装配长这样:
typescript
// src/server.ts
export function createServer(): Koa {
const app = new Koa();
app.use(health());
// ① 先提取客户端身份
app.use(extractClientId);
// ② 再限流(依赖 clientIp / userId)
app.use(clientIPLimit);
app.use(clientIdLimit);
app.use(globalLimit);
app.use(errorHandler);
// ③ 先挂载 serverTime 容器
app.use(serverTime);
// ④ 再初始化请求上下文
app.use(clientCtxInit);
app.use(bodyParser);
app.use(requestContext);
return app;
}extractClientId 的实现很朴素,就干一件事 ------ 从请求里提取客户端 IP 和用户标识:
typescript
// src/middlewares/set-simple-client.ts
export const extractClientId: Middleware = async (ctx, next) => {
const forwarded = ctx.request.get('x-forwarded-for');
const clientIp = forwarded?.split(',')[0]?.trim() || ctx.ip || 'unknown';
const userId = ctx.cookies.get('user_uid') || 'unknow';
ctx.clientIp = clientIp;
ctx.userId = userId;
await next();
};完整链路:
优化 1.0 完成:顺序不是实现细节,是架构契约。新增中间件前,先搞清楚它依赖谁、谁依赖它。
搞事 1.1:AsyncLocalStorage ------ 请求态怎么传
问题从哪来
clientCtxInit 里会给每个请求生成 reqId、seqId,写入响应头,后面打日志、调下游都要用。
问题来了:业务代码往往套了好几层 async/await,如果靠参数透传:
typescript
// 反模式:每个函数都要加参数
function callApi(params, reqId, userId) { ... }
function writeLog(event, reqId, userId) { ... }改一个字段,签名牵一串。
如果用全局变量:
typescript
// 反模式:并发请求互相污染
global.currentReqId = reqId;Node.js 是单线程 + 异步,两个请求交错执行,全局变量直接串台。
实现
Node.js 提供了 AsyncLocalStorage(async_hooks 模块),可以理解为异步版的 ThreadLocal:
css
请求 A 进来 → asyncLocalStorage.run(storeA, ...) → 后续所有 await 都在 storeA 里
请求 B 进来 → asyncLocalStorage.run(storeB, ...) → 完全独立,互不干扰Demo 里的封装:
typescript
import { AsyncLocalStorage } from 'async_hooks';
// src/lib/async-context.ts
const asyncLocalStorage = new AsyncLocalStorage<AsyncStore>();
export function getAsyncStore(): AsyncStore | undefined {
return asyncLocalStorage.getStore();
}
export function runWithinAsyncStore(
store: AsyncStore,
callback: () => Promise<void>,
): Promise<void> {
return asyncLocalStorage.run(store, callback);
}clientCtxInit 在建立好 reqId 之后,用 runWithinAsyncStore 包裹后续所有中间件:
typescript
// src/middlewares/client-init.ts
return runWithinAsyncStore({ lifeInfo }, async () => {
logger.info({
event: 'client-init',
brief: `${method} ${url}`,
method,
url,
lid,
life,
});
await next();
});这样,不管业务代码嵌套多深,logger 里随时能取到当前请求的 reqId:
typescript
// src/lib/logger.ts
function formatPayload(payload: LogPayload): string {
const store = getAsyncStore();
const reqId = store?.lifeInfo.reqId ?? '-';
const userId = store?.lifeInfo.userId ?? '-';
// ...
}路由里模拟了一次「深层调用」,不用传参也能读到上下文:
bash
curl -H 'x-lid: demo01' -H 'x-life: 1200' http://127.0.0.1:3100/api/profile响应里 fromCtx 和 fromAsyncStore 的 reqId 一致,日志里的 deep-call-log 事件也自动带上了 reqId。
四维追踪
除了 reqId,接入层还维护了一套追踪字段:
| 字段 | 来源 | 用途 |
|---|---|---|
reqId |
服务端 nanoid 生成 | 单次 HTTP 请求 ID |
seqId |
服务端 UUID 生成 | 响应链路标识 |
lid |
请求头 x-lid |
串联 SPA 页面生命周期 |
life |
请求头 x-life |
距生命周期开始的毫秒数 |
配合 server-timing 响应头,可以把「前端 → 网关 → BFF → 下游」各段耗时拆开看。
serverTime 必须在 clientCtxInit 之前挂载,后者才能往里写 1_connect、2_gateway 等指标 ------ 又回到话题一:顺序 matters。
搞事 2.0:三层限流 + 观察模式 ------ 生产环境怎么安全调参
问题从哪来
同事: 限流阈值定多少合适?定高了防不住,定低了误伤正常用户。
我:先上线观察模式看看?
同事: 观察模式是什么,能先验证再真正拦截吗?
我:能。
单层限流不够用:
- 只按 IP:公司出口 NAT,一个 IP 后面几百人,误伤一整栋楼;
- 只按用户:爬虫换账号就绕过;
- 只有全局:单个疯狂用户能把所有人拖下水。
三层叠加才合理:IP → 用户 → 全局。
但核心难题是:新阈值上线前,怎么知道会不会误触发?
实现
三层限流
Demo 里用工厂函数统一创建,只是 getId 不同:
typescript
// src/middlewares/rate-limit/index.ts
export const clientIPLimit = createRateLimitMiddleware({
type: RateLimitType.Ip,
getId: ctx => ctx.clientIp,
});
export const clientIdLimit = createRateLimitMiddleware({
type: RateLimitType.User,
getId: ctx => ctx.userId,
});
export const globalLimit = createRateLimitMiddleware({
type: RateLimitType.Global,
getId: () => 'global',
});Demo效果:
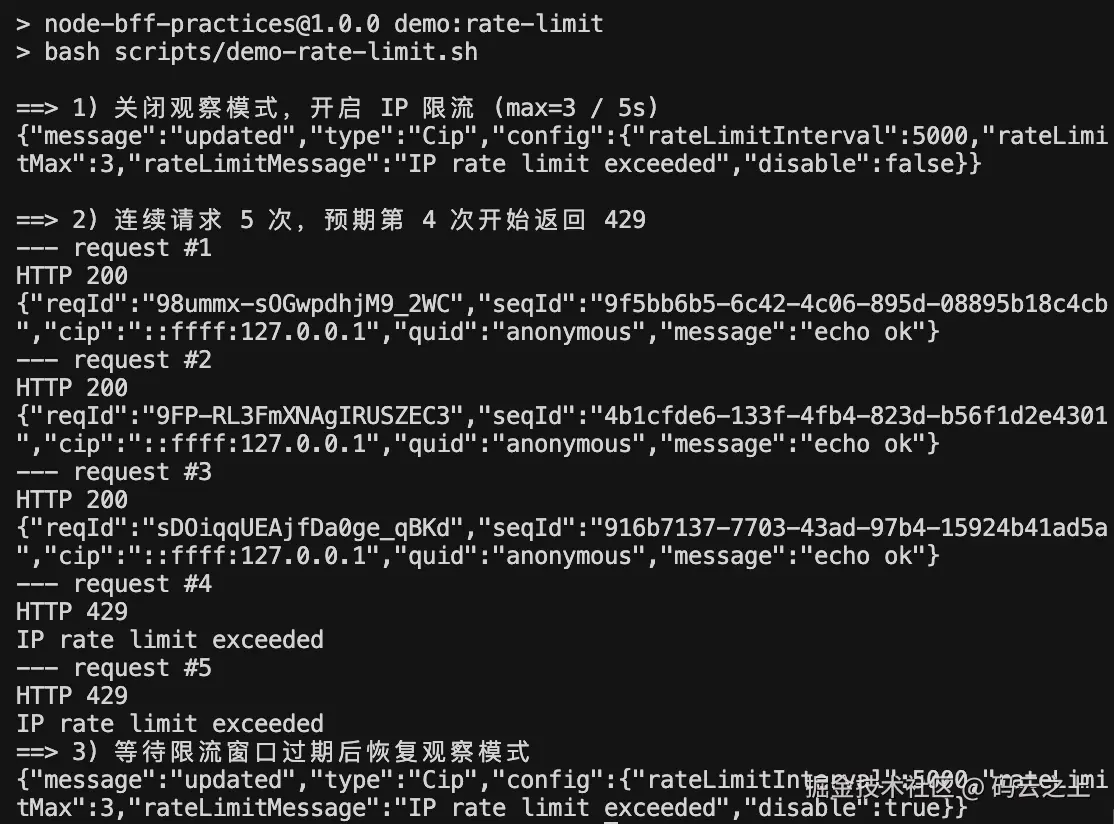
观察模式(Shadow Mode)
配置里有个 disable 开关。disable: true 时进入观察模式:
- 不真正拦截,HTTP 始终 200;
- 但精确模拟
koa-ratelimit的 memory 算法; - 触发时打日志
rate-limit-exceeded-observation。
typescript
// src/middlewares/rate-limit/create-rate-limit.ts
if (currentConfig.disable) {
const { isLimited } = checkRateLimit(id, config, observationStore);
if (isLimited) {
logger.info({
event: 'rate-limit-exceeded-observation',
limitBy: type,
id,
message: `${ctx.method} ${ctx.originalUrl} - ${type} exceeded (observation mode)`,
});
}
return next(); // 观察模式:无论是否触发都放行
}checkRateLimit 的时间算法对齐了 koa-ratelimit 源码,连微秒时间戳处理方式都一致,确保观察到的触发次数和真正开启后一致:
typescript
// src/helpers/checkRateLimit.ts
function getMicrotime(): number {
const diff = process.hrtime(hrtimeStart);
return timeBase + diff[0] * 1e6 + Math.round(diff[1] * 1e-3);
}热更新 + 验证闭环
限流阈值通过配置中心热更新(Demo 里用内存 configStore 模拟),无需重启:
bash
# 查看当前配置
curl http://127.0.0.1:3100/admin/rate-limit
# 切到观察模式,阈值 max=3
curl -X PATCH http://127.0.0.1:3100/admin/rate-limit/Ip \
-H 'Content-Type: application/json' \
-d '{"disable":true,"rateLimitMax":3}'
# 跑观察脚本:HTTP 全 200,日志里有 observation 记录
npm run demo:observation
# 确认无误后,真正开启限流
curl -X PATCH http://127.0.0.1:3100/admin/rate-limit/Ip \
-H 'Content-Type: application/json' \
-d '{"disable":false,"rateLimitMax":3}'
# 跑限流脚本:第 4 次起返回 429
npm run demo:rate-limit完整闭环:
ini
配置下发 disable=true(观察模式)
→ 线上跑一段时间,统计 observation 日志
→ 确认无误后 disable=false(真正拦截)
→ 全程无需重启一个容易忽略的细节
限流发生在 clientCtxInit 之前 ,被限流的请求走不到 clientCtxInit 和 requestContext,正常生命周期日志是残缺的。
所以触发限流时,需要手动补全 client-init + client-response:
typescript
// src/utils/rateLimitLogger.ts
export function logRateLimitLifecycle(ctx: ParameterizedContext): void {
logger.info({
event: 'client-init',
note: '补全日志:限流发生在 clientCtxInit 之前',
// ...
});
logger.error({
event: 'client-response',
statusCode: 429,
message: 'Rate limit exceeded',
});
}这又是一个「中间件顺序带来副作用,需要显式处理」的例子 ------ 和话题一首尾呼应。
串联:一个请求的完整旅程
把三个话题合拢,一个请求进来后:
markdown
1. extractClientId 提取 clientIp / userId ← 话题一:顺序契约
2. 三层限流决策(观察模式 or 真正拦截) ← 话题三:安全调参
3. clientCtxInit 建立 AsyncLocalStorage 上下文 ← 话题二:透明传递
4. 业务处理,日志带完整 reqId / 追踪信息
5. requestContext 记录 client-response三件事解决的是同一个问题:系统在复杂度增长时,每一层的行为仍然可预期、可观测、可调整。
Demo 项目
完整代码在 node-bff-practices,本地跑起来:
bash
git clone https://github.com/GuangMingZ/node-bff-practices.git
cd node-bff-practices
npm install
npm run dev服务监听 http://127.0.0.1:3100,配套了演示脚本:
| 命令 | 演示内容 |
|---|---|
npm run demo:observation |
观察模式:HTTP 200 + observation 日志 |
npm run demo:rate-limit |
真正限流:第 4 次起 429 |
小结
- 中间件顺序即架构契约,不是功能堆叠;新增中间件前先画清依赖关系;
- AsyncLocalStorage 是 Node.js 异步场景下传递请求态的正确姿势,告别参数透传和全局变量;
- 三层限流 + 观察模式 让你在生产环境「先验证、再拦截」,调参零风险;
- 接入层的复杂度不在「转发请求」,而在每一层决策是否可预期、可观测、可调整 ------ 这三个话题本质上是一件事。
PS:Demo 为便于分享做了简化(内存配置中心、控制台日志、较低阈值),核心设计模式与生产接入层一致。欢迎 Star & Issue 交流。