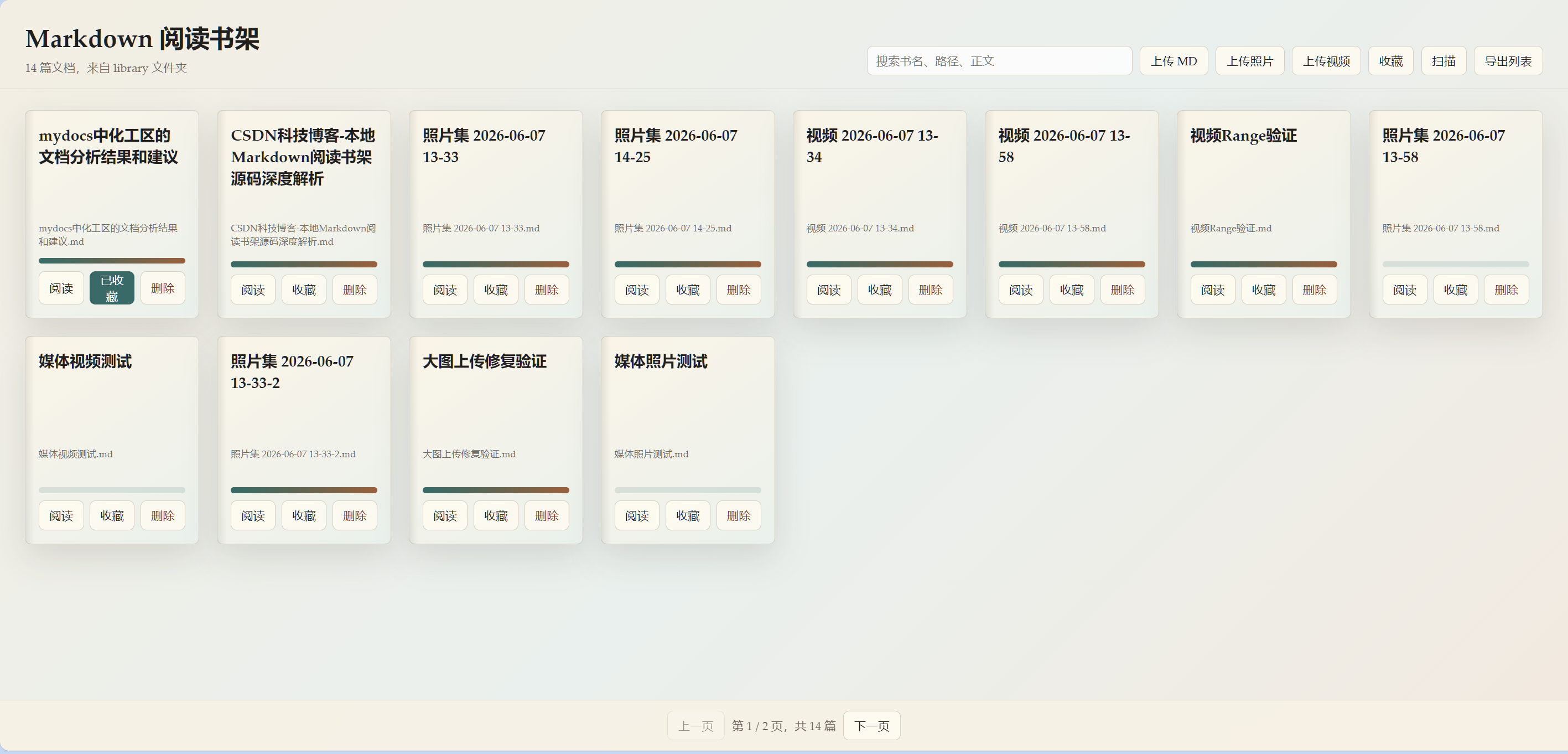
本文以一个本地 Markdown 阅读书架项目为案例,从"背景 → 目标 → 方法 → 过程 → 结果 → 总结"六个角度,系统分析项目的全栈实现思路。
技术栈包括 Node.js、HTML、CSS、JavaScript、SQLite,功能覆盖 Markdown 上传、照片/视频上传、书架管理、分页阅读、收藏、书签、笔记、移动端 Panel、Safari 视频播放兼容等。
C:\Users\86182\Desktop\md文件的展示程序
一、背景
在日常学习和工作中,Markdown 文件非常常见。它既可以写技术博客,也可以写读书笔记、会议纪要、项目文档和知识库内容。
但是,当本地 Markdown 文件越来越多时,会遇到几个明显问题:
- 文件散落在不同目录里,不方便集中查看。
- 普通编辑器适合写作,但不一定适合长期阅读。
- 很难记录阅读进度、收藏状态、书签和读书笔记。
- 手机访问体验通常较差,工具栏占空间,正文显示不够舒适。
- Markdown 中的图片和视频管理比较分散,文件、路径和显示效果容易出问题。
因此,这个项目的出发点是:
做一个本地运行的 Markdown 阅读书架,把 Markdown 文件像书一样管理起来,并支持照片、视频、书签、笔记和移动端阅读。
项目不是为了追求复杂架构,而是强调"够用、清晰、可维护、容易部署"。
二、目标
项目目标可以分成三个层次。
1. 内容管理目标
系统需要支持:
- 上传
.md文件并自动加入书架。 - 上传多张照片,自动生成包含图片语法的 Markdown 文档。
- 上传一个视频,自动生成可播放视频的 Markdown 文档。
- 扫描本地
library/目录,自动识别已有 Markdown 文件。 - 删除书籍时不直接永久删除,而是移动到
.trash目录,降低误删风险。
2. 阅读体验目标
阅读器需要支持:
- Markdown 渲染。
- 图片直接显示。
- 视频直接播放。
- 长文分页阅读。
- 阅读进度保存。
- 收藏文章。
- 添加书签。
- 添加读书笔记和文本标记。
- 字体、字号、背景色、文字颜色自定义。
3. 移动端目标
手机阅读时,屏幕空间有限,因此移动端重点是:
- 正文优先显示。
- 所有操作集中到可隐藏 Panel 中。
- 支持局域网手机访问。
- 支持 iPhone Safari 添加到主屏幕。
- 视频兼容 Safari,支持
playsinline、preload="metadata"和 HTTP Range 请求。
三、方法
这个项目采用了非常轻量的全栈方案:
| 层级 | 技术 | 职责 |
|---|---|---|
| 后端 | Node.js 原生 HTTP | 提供 API、静态资源、媒体资源访问 |
| 数据库 | SQLite | 保存书籍元数据、收藏、进度、书签、笔记、设置 |
| 前端 | HTML + CSS + JavaScript | 书架、阅读器、上传、分页、Panel 交互 |
| 内容源 | Markdown 文件 | 保存正文内容 |
| 媒体资源 | library/assets | 保存图片和视频文件 |
为什么不用复杂框架?
这个项目是一个本地工具。它的核心诉求是:
- 启动简单。
- 文件结构清楚。
- 不依赖大型框架。
- 易于在 Windows 本机运行。
- 方便后续自己改。
因此后端没有使用 Express,前端没有使用 Vue/React,而是直接使用 Node.js 原生 HTTP 与浏览器原生 API。
四、过程
下面进入源码分析。
1. 后端入口:server.js
server.js 是整个系统的入口文件,主要负责四件事:
- 启动 HTTP 服务。
- 分发 API 路由。
- 返回前端静态资源。
- 返回图片和视频资源。
核心代码结构如下:
javascript
const http = require('node:http');
const fs = require('node:fs');
const path = require('node:path');
const { createStorage } = require('./src/storage');
const { renderMarkdown } = require('./src/markdown');
const PORT = Number(process.env.PORT || 3000);
const HOST = process.env.HOST || '0.0.0.0';
const MAX_UPLOAD_BYTES = Number(process.env.MAX_UPLOAD_MB || 512) * 1024 * 1024;
const PUBLIC_DIR = path.join(__dirname, 'public');
const storage = createStorage();这里有几个重要设计点。
第一,HOST 默认是 0.0.0.0。
这意味着服务不仅可以通过电脑本机的 localhost:3000 访问,也可以通过局域网 IP 在手机上访问。
第二,MAX_UPLOAD_BYTES 默认是 512MB。
上传照片和视频时,前端会把文件转成 base64 放入 JSON 请求体。如果上限太小,多张图片或一个视频会上传失败。因此这里设置了可配置的上传上限。
第三,storage = createStorage()。
后端启动时会初始化 SQLite 数据库,并创建必要的数据表。
2. 请求体读取:readBody
上传 Markdown、照片和视频时,前端会发送 JSON 数据。后端通过 readBody 读取:
javascript
function readBody(req, maxBytes = MAX_UPLOAD_BYTES) {
return new Promise((resolve, reject) => {
let body = '';
let received = 0;
let rejected = false;
req.on('data', (chunk) => {
if (rejected) return;
received += chunk.length;
body += chunk;
if (received > maxBytes) {
rejected = true;
const error = new Error(`请求体过大,当前上限为 ${Math.round(maxBytes / 1024 / 1024)}MB`);
error.statusCode = 413;
reject(error);
req.destroy();
}
});
req.on('end', () => {
try {
resolve(body ? JSON.parse(body) : {});
} catch (error) {
reject(error);
}
});
});
}这段代码的关键点是上传保护:
received用来统计已经收到的字节数。- 如果超过上限,就返回
413。 - 上限通过
MAX_UPLOAD_MB环境变量可配置。
这个设计解决了两个问题:
- 防止请求体无限增大导致内存风险。
- 支持较大的照片和视频上传。
3. API 路由设计
后端没有使用 Express,而是在 route(req, res) 中手动分发路径。
主要 API 如下:
| API | 方法 | 功能 |
|---|---|---|
/api/books |
GET | 获取书籍列表,支持搜索和收藏筛选 |
/api/scan |
POST | 扫描 library/ 目录 |
/api/upload |
POST | 上传 Markdown 文件 |
/api/upload-photos |
POST | 上传多张照片并生成 Markdown |
/api/upload-video |
POST | 上传视频并生成 Markdown |
/api/books/:id |
GET | 获取书籍详情和渲染后的 HTML |
/api/books/:id |
PATCH | 更新收藏、进度、位置等 |
/api/books/:id |
DELETE | 删除书籍并移入 .trash |
/api/books/:id/notes |
GET/POST | 获取或新增笔记 |
/api/books/:id/bookmarks |
GET/POST | 获取或新增书签 |
/api/settings |
GET/PUT | 获取或保存阅读设置 |
这种路由方式虽然没有框架优雅,但对于本地工具非常直观。
4. 媒体资源服务:图片和视频如何显示
项目中的照片和视频统一保存在:
text
library/assets/前端 Markdown 中引用:
markdown

<video controls playsinline preload="metadata" width="100%">
<source src="assets/demo.mp4" type="video/mp4">
</video>后端通过 /assets/... 路径提供静态访问。
对于普通图片,返回完整文件即可。
但对于视频,尤其是 Safari,需要支持 HTTP Range 请求。
代码中对应逻辑是:
javascript
const range = req.headers.range;
if (range && contentType.startsWith('video/')) {
const match = /bytes=(\d*)-(\d*)/.exec(range);
const start = match && match[1] ? Number(match[1]) : 0;
const end = match && match[2] ? Number(match[2]) : stat.size - 1;
const safeEnd = Math.min(end, stat.size - 1);
res.writeHead(206, {
'content-type': contentType,
'accept-ranges': 'bytes',
'content-range': `bytes ${start}-${safeEnd}/${stat.size}`,
'content-length': safeEnd - start + 1
});
fs.createReadStream(assetPath, { start, end: safeEnd }).pipe(res);
return;
}为什么这段很重要?
因为浏览器播放视频时,通常不会一次性下载完整文件,而是按片段请求。
Safari 对 Range 支持尤其敏感。如果服务端不返回 206 Partial Content,视频可能无法播放或无法拖动进度。
5. 数据层:src/storage.js
storage.js 是项目的数据核心,负责:
- 初始化 SQLite。
- 扫描 Markdown 文件。
- 导入 Markdown。
- 导入照片集。
- 导入视频文档。
- 保存收藏、进度、书签、笔记。
- 删除书籍。
5.1 数据库表设计
书籍表:
sql
CREATE TABLE IF NOT EXISTS books (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
relative_path TEXT NOT NULL UNIQUE,
favorite INTEGER NOT NULL DEFAULT 0,
progress INTEGER NOT NULL DEFAULT 0,
pos_x INTEGER,
pos_y INTEGER,
last_read_at TEXT,
updated_at TEXT NOT NULL
);这个表不保存 Markdown 正文,只保存元数据。
正文仍然保存在 library/ 目录里的 .md 文件中。
这样设计有三个优点:
- Markdown 文件仍然可以被其他编辑器打开。
- 数据库不会因为正文内容变大。
- 文件和阅读状态职责清晰。
笔记表:
sql
CREATE TABLE IF NOT EXISTS notes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
book_id TEXT NOT NULL,
selected_text TEXT NOT NULL,
note TEXT NOT NULL,
color TEXT NOT NULL,
created_at TEXT NOT NULL
);书签表:
sql
CREATE TABLE IF NOT EXISTS bookmarks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
book_id TEXT NOT NULL,
title TEXT NOT NULL,
progress INTEGER NOT NULL,
scroll_top INTEGER NOT NULL,
created_at TEXT NOT NULL
);这里的 scroll_top 在当前分页模式中实际保存的是页码索引。
5.2 扫描 library 目录
扫描函数会递归寻找 .md 文件:
javascript
function walkMarkdown(dir, baseDir = dir, result = []) {
if (!fs.existsSync(dir)) return result;
for (const entry of fs.readdirSync(dir, { withFileTypes: true })) {
const fullPath = path.join(dir, entry.name);
if (entry.isDirectory()) {
if (entry.name === '.trash' || entry.name.startsWith('.')) continue;
walkMarkdown(fullPath, baseDir, result);
} else if (entry.isFile() && entry.name.toLowerCase().endsWith('.md')) {
result.push({
fullPath,
relativePath: normalizeRelative(path.relative(baseDir, fullPath))
});
}
}
return result;
}这里有一个很实用的细节:跳过 .trash 和隐藏目录。
原因是删除书籍时,文件会移动到:
text
library/.trash/如果扫描时不跳过 .trash,被删除的文件又会重新出现在书架上。这个问题在开发过程中确实出现过,所以代码中特意做了防护。
5.3 导入 Markdown 文件
Markdown 导入流程是:
- 清理文件名。
- 生成不重复的相对路径。
- 写入
library/。 - 写入或更新 SQLite 书籍记录。
核心代码:
javascript
function importMarkdown(file) {
const content = String(file.content || '');
const filename = safeMarkdownFilename(file.filename);
const relativePath = uniqueRelativePath(filename);
fs.writeFileSync(path.join(libraryDir, relativePath), content, 'utf8');
const now = new Date().toISOString();
const title = path.basename(relativePath, path.extname(relativePath));
const id = bookId(relativePath);
db.prepare(`
INSERT INTO books (id, title, relative_path, updated_at)
VALUES (?, ?, ?, ?)
ON CONFLICT(id) DO UPDATE SET
title = excluded.title,
relative_path = excluded.relative_path,
updated_at = excluded.updated_at
`).run(id, title, relativePath, now);
return getBook(id);
}这里的 bookId(relativePath) 使用 SHA-1,根据文件相对路径生成稳定 ID。
这样同一个文件路径在多次扫描时可以保持同一个 ID。
5.4 上传照片并生成 Markdown
照片上传不是简单保存图片,而是自动生成 Markdown 文档。
生成逻辑:
javascript
function importPhotoCollection(input) {
const title = String(input.title || timestampTitle('照片集')).trim();
const assets = (Array.isArray(input.files) ? input.files : []).map(writeAsset);
const markdown = [
`# ${title}`,
'',
...assets.flatMap((asset) => [``, ''])
].join('\n');
return importMarkdown({
filename: `${title}.md`,
content: markdown
});
}上传多张图片后,会生成类似这样的文档:
markdown
# 照片集 2026-06-07 13-33

这样做的好处是:
- 图片仍然是文件。
- Markdown 文档可以独立编辑。
- 阅读器只需要渲染标准图片语法。
5.5 上传视频并生成 Markdown
视频导入逻辑类似:
javascript
function importVideoDocument(input) {
const title = String(input.title || timestampTitle('视频')).trim();
const asset = writeAsset(input.file || {});
const markdown = [
`# ${title}`,
'',
`<video controls playsinline preload="metadata" width="100%"><source src="${asset.relativePath}" type="${asset.mimeType}"></video>`,
''
].join('\n');
return importMarkdown({
filename: `${title}.md`,
content: markdown
});
}这里的关键是视频标签:
html
<video controls playsinline preload="metadata" width="100%">
<source src="assets/demo.mp4" type="video/mp4">
</video>其中:
controls:显示播放控件。playsinline:让 iPhone Safari 尽量以内联方式播放。preload="metadata":先加载视频元信息,减少首屏压力。width="100%":适配阅读区域宽度。
6. Markdown 渲染器:src/markdown.js
markdown.js 负责把 Markdown 转成 HTML。
它支持:
- 标题。
- 段落。
- 列表。
- 加粗。
- 斜体。
- 行内代码。
- 链接。
- 图片。
- 代码块。
- 安全视频标签。
6.1 HTML 转义
任何 Markdown 渲染器都要先考虑安全问题。
javascript
function escapeHtml(value) {
return String(value)
.replaceAll('&', '&')
.replaceAll('<', '<')
.replaceAll('>', '>')
.replaceAll('"', '"');
}这可以避免 Markdown 中的普通 HTML 被直接执行。
6.2 图片渲染
图片语法处理:
javascript
html = html.replace(/!\[([^\]]*)\]\(([^)]+)\)/g, (match, alt, src) => {
const cleanSrc = String(src || '').trim();
if (!isSafeMediaSrc(cleanSrc)) return match;
return `<img src="${escapeHtml(cleanSrc)}" alt="${escapeHtml(alt)}" loading="lazy">`;
});这里有一个重要优化:路径允许中文和空格。
例如:
markdown
最开始如果正则只允许无空格路径,这类图片会原样显示,无法变成 <img>。
现在通过 ([^)]+) 支持括号内完整路径。
同时,isSafeMediaSrc 限制了资源来源:
javascript
function isSafeMediaSrc(src) {
return /^(assets\/|https?:\/\/|data:image\/)/i.test(String(src || '').trim());
}这样可以避免危险的 javascript: 链接被当作媒体资源插入。
6.3 视频渲染
视频不是直接放任所有 HTML,而是只识别安全的 <video><source></video> 结构:
javascript
function sanitizeVideoBlock(line) {
const source = /<source\s+src=["']([^"']+)["']\s+type=["']([^"']+)["']\s*\/?>/i.exec(line);
if (!/^<video\b/i.test(line) || !source) return null;
const src = source[1];
const type = source[2];
if (!isSafeMediaSrc(src)) return null;
if (!/^video\/[a-z0-9.+-]+$/i.test(type)) return null;
return `<video controls playsinline preload="metadata" width="100%"><source src="${escapeHtml(src)}" type="${escapeHtml(type)}"></video>`;
}这个设计兼顾了功能和安全:
- 允许视频播放。
- 自动补齐 Safari 兼容属性。
- 不允许任意 HTML 脚本混入。
7. 分页阅读:src/pagination.js 与前端分页
项目使用分页阅读,而不是无限滚动。
分页逻辑的核心是:
- 将 HTML 拆成顶层块。
- 根据字符长度估算页容量。
- 超过阈值就生成新页。
核心函数:
javascript
function paginateHtml(html, maxChars = 1600) {
const blocks = splitTopLevelBlocks(html);
if (!blocks.length) return [''];
const pages = [];
let current = [];
let currentChars = 0;
for (const block of blocks) {
const blockChars = stripTags(block).length || block.length;
if (current.length && currentChars + blockChars > maxChars) {
pages.push(current.join(''));
current = [];
currentChars = 0;
}
current.push(block);
currentChars += blockChars;
}
if (current.length) pages.push(current.join(''));
return pages.length ? pages : [''];
}拆块时必须包含媒体标签:
javascript
const matches = source.match(/<(h[1-6]|p|ul|ol|pre|blockquote|table|video)[\s\S]*?<\/\1>|<img\b[^>]*>/gi);这里如果漏掉 video 或 img,图片和视频就可能在分页时丢失。
这也是阅读器类项目中非常容易忽略的细节。
8. 前端核心:public/app.js
前端 app.js 负责大部分交互逻辑:
- 加载书架。
- 渲染书卡。
- 上传文件。
- 上传照片。
- 上传视频。
- 打开阅读器。
- 分页阅读。
- 保存进度。
- 收藏。
- 添加书签。
- 添加笔记。
- 图片放大预览。
- 移动端 Panel。
8.1 状态对象
前端用一个 state 对象保存当前状态:
javascript
const state = {
books: [],
currentBook: null,
readerPages: [],
currentPage: 0,
notes: [],
bookmarks: [],
settings: {
fontSize: 19,
background: '#f7f1e4',
foreground: '#24211c',
fontFamily: 'serif-classic'
},
favoriteOnly: false,
query: '',
page: 1,
pageSize: 12,
selectedText: ''
};这种集中状态管理方式虽然简单,但对于原生 JS 项目非常实用。
8.2 上传进度条
一开始如果使用 fetch 上传,浏览器无法直接拿到上传进度。
因此前端改用 XMLHttpRequest:
javascript
function uploadJsonWithProgress(path, body, label) {
return new Promise((resolve, reject) => {
const xhr = new XMLHttpRequest();
xhr.open('POST', path);
xhr.setRequestHeader('content-type', 'application/json');
xhr.upload.onprogress = (event) => {
if (!event.lengthComputable) {
setUploadProgress(`${label}上传中...`, 50);
return;
}
setUploadProgress(`${label}上传中...`, (event.loaded / event.total) * 100);
};
xhr.onload = () => {
const data = xhr.responseText ? JSON.parse(xhr.responseText) : {};
if (xhr.status >= 200 && xhr.status < 300) {
setUploadProgress(`${label}上传完成`, 100);
hideUploadProgressSoon();
resolve(data);
} else {
reject(new Error(data.error || xhr.statusText || '上传失败'));
}
};
xhr.onerror = () => reject(new Error('网络连接失败'));
xhr.onabort = () => reject(new Error('上传已取消'));
setUploadProgress(`${label}准备文件...`, 5);
xhr.send(JSON.stringify(body));
});
}这里的关键点是:
xhr.upload.onprogress可以拿到上传进度。- 上传完成后进度条显示 100%。
- 失败时返回明确错误。
- 上传照片、视频和 Markdown 都复用这个函数。
8.3 图片预览
阅读页中图片可点击放大:
javascript
el.readerContent.addEventListener('click', (event) => {
const image = event.target.closest('img');
if (!image) return;
el.mediaPreviewImage.src = image.src;
el.mediaPreviewImage.alt = image.alt || '图片预览';
el.mediaPreview.classList.remove('hidden');
});这个交互对照片集非常重要。
普通阅读区域为了排版会限制图片宽度,而预览层可以显示更大的图片。
8.4 移动端 Panel
手机上如果把工具栏固定在顶部或底部,会占用正文空间。
因此项目采用 Panel 设计:
- 默认只显示正文。
- 右下角显示"工具"按钮。
- 点击后打开 Panel。
- 所有操作集中在 Panel 中。
相关状态控制:
javascript
function setPanelOpen(open) {
el.readerPanel.classList.toggle('open', open);
el.panelBackdrop.classList.toggle('hidden', !open);
el.mobilePanelButton.setAttribute('aria-expanded', String(open));
}这个设计非常适合手机阅读器,因为它把"阅读"和"操作"分离开了。
9. 样式设计:public/styles.css
CSS 的重点包括:
- 书架卡片整齐展示。
- 阅读正文排版舒适。
- 图片和视频自适应宽度。
- 移动端 Panel。
- 上传进度条。
图片和视频样式:
css
.reader-content img,
.reader-content video {
display: block;
max-width: 100%;
height: auto;
margin: 18px auto;
border-radius: 8px;
box-shadow: 0 12px 32px rgba(37, 31, 22, 0.16);
}上传进度条样式:
css
.upload-progress-track {
height: 9px;
overflow: hidden;
border-radius: 999px;
background: rgba(35, 108, 104, 0.14);
}
.upload-progress-track span {
display: block;
width: 0%;
height: 100%;
background: linear-gradient(90deg, var(--accent), var(--warm));
transition: width 160ms ease;
}这类细节虽然不是业务核心,但会显著影响用户对工具的第一印象。
五、结果
经过实现后,项目形成了一个完整的本地 Markdown 阅读系统。
1. 已实现功能
- Markdown 文件上传。
- 多图片上传并自动生成照片集 Markdown。
- 视频上传并自动生成视频 Markdown。
- 图片显示和点击放大。
- 视频播放,兼容 Safari 所需的内联播放和 Range 请求。
- SQLite 保存书籍、进度、收藏、书签、笔记和设置。
- 书架分页展示。
- 阅读器分页阅读。
- 字体、字号、背景色、文字色自定义。
- 手机端 Panel 操作。
- iPhone 添加到主屏幕提示。
- 删除书籍时移动到
.trash。 - 上传进度条。
2. 测试结果
项目使用 Node.js 内置测试框架。
测试覆盖了:
- Markdown 基础渲染。
- 图片和视频渲染。
- 中文和空格媒体路径。
- 分页时保留图片和视频。
- SQLite 扫描与持久化。
- Markdown 上传。
- 照片集和视频文档生成。
- 删除书籍进入
.trash。 - 超过 2MB 的媒体上传。
最终测试全部通过。
3. 工程收益
这个项目虽然体量不大,但已经具备一个实用本地工具的完整闭环:
text
上传内容 → 生成 Markdown → 入库 → 书架展示 → 阅读 → 标记/书签/笔记 → 持久化它不是一个单纯的 Markdown 预览器,而是一个围绕阅读行为设计的小型知识工具。
六、总结
这个本地 Markdown 阅读书架项目有几个值得总结的经验。
1. 本地工具不一定需要复杂框架
Node.js 原生 HTTP、SQLite、HTML、CSS、JavaScript 已经足够完成很多个人工具。
框架可以提升工程化能力,但也会带来依赖和复杂度。对于本地小工具,轻量方案反而更容易维护。
2. Markdown 文件应继续保持文件形态
系统没有把 Markdown 正文塞进数据库,而是保留在 library/ 中。
数据库只保存状态。这个边界很清晰:
- 文件系统负责内容。
- SQLite 负责状态。
3. 媒体功能要同时考虑生成、渲染和访问
照片和视频功能不是只生成 Markdown 就结束了,还要考虑:
- 文件保存在哪里。
- Markdown 路径是否正确。
- 渲染器是否支持图片和视频。
- 静态服务是否能返回资源。
- 视频是否支持 Range。
- Safari 是否能播放。
这说明媒体功能是一个跨前端、后端、渲染器、文件系统的完整链路。
4. 移动端阅读要减少工具干扰
手机屏幕小,阅读器最重要的是让正文成为主角。
把操作集中到 Panel 中,是一个简单但有效的设计。
5. 测试能防止功能反复坏掉
开发过程中出现过这些问题:
.trash文件被重新扫回书架。- 图片路径有空格时无法显示。
- 视频分页时被丢掉。
- 大文件上传超过 2MB 失败。
- Safari 视频需要 Range 和
playsinline。
每发现一个问题,就补一个测试。
这让项目越来越稳,而不是靠手工反复试。
CSDN 推荐标题
Node.js + SQLite 实战:从源码解析一个支持图片、视频、书签和手机阅读的 Markdown 阅读书架
CSDN 推荐摘要
本文通过一个本地 Markdown 阅读书架项目,详细分析 Node.js 原生 HTTP 服务、SQLite 数据建模、Markdown 渲染、图片和视频上传、Safari 视频兼容、分页阅读、书签笔记和移动端 Panel 的完整实现过程,适合作为全栈项目实战和个人知识管理工具开发参考。
附:项目源码模块清单
| 文件 | 职责 |
|---|---|
server.js |
HTTP 服务、API 路由、静态资源、媒体 Range 响应 |
src/storage.js |
SQLite、文件扫描、上传导入、删除、书签、笔记 |
src/markdown.js |
Markdown 渲染、安全转义、图片和视频处理 |
src/pagination.js |
HTML 内容分页 |
public/index.html |
页面结构 |
public/styles.css |
书架、阅读器、移动端、进度条样式 |
public/app.js |
前端状态、上传、阅读器、Panel、书签、笔记 |
tests/ |
自动化测试 |
如果把这个项目继续扩展,可以考虑:
- 支持全文索引和高亮搜索。
- 支持导出带笔记的 Markdown。
- 支持 PDF 导出。
- 支持 WebDAV 或局域网同步。
- 支持更完整的 CommonMark 渲染。
- 支持视频封面和媒体库管理。