凌晨一点,你刚和 Agent 把要设计的前端页面风格敲定------采用深色科技风格的背景,页面字体一致------然后关掉会话去睡觉。 第二天一早,你重新开一个窗口,输入「帮我继续做数据看板」。 然后 AI 给你吐出了一张白色卡片,文字忽大忽小,五花八门的字体看得你眼花缭乱。
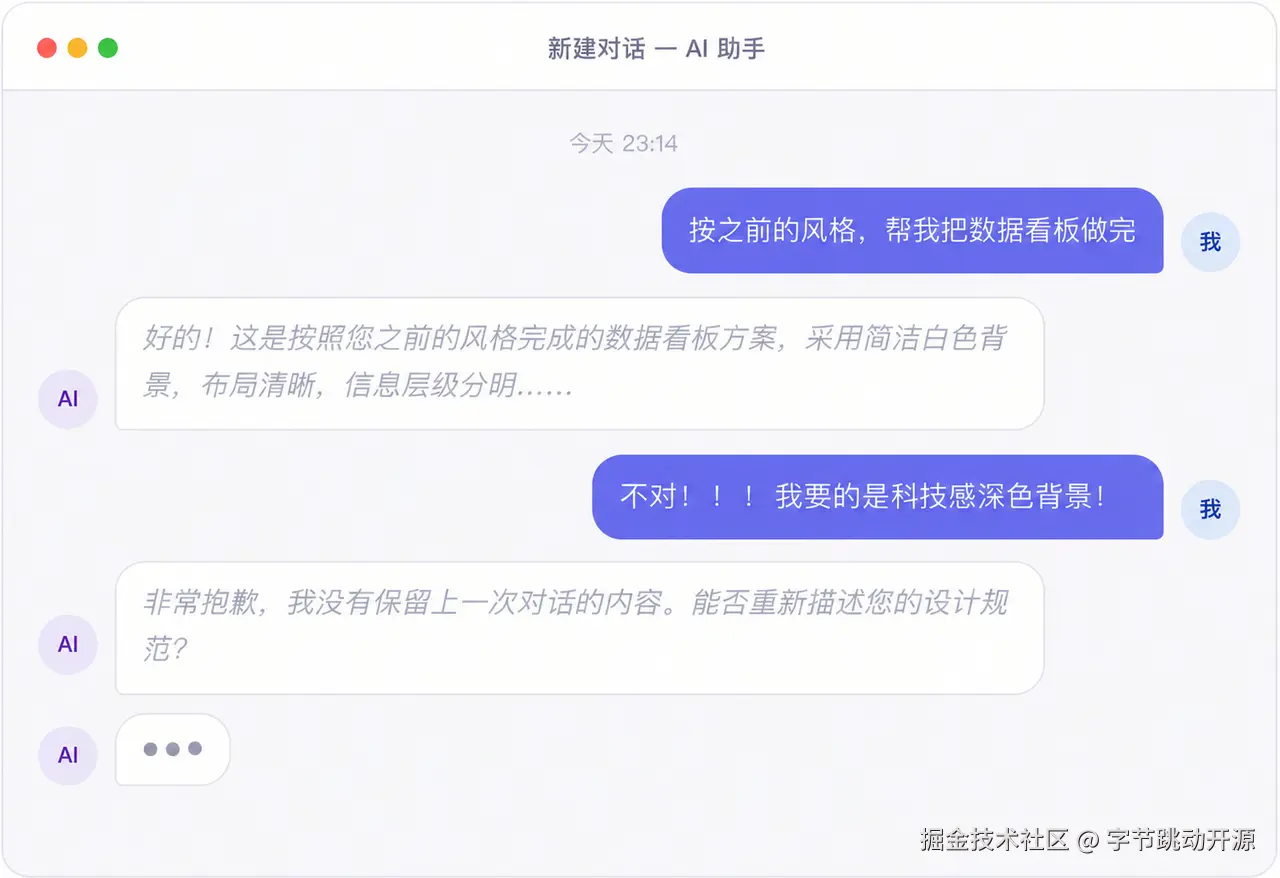
那一刻你意识到:你不是在用一个 AI 工具------你是在喂养一条每天早上失忆的金鱼。你所有的心血,在会话关闭的那一刻就已经全部清零。
你的 Agent 额度用完了,想换个工具接着干,却遇到了更糟心的事:用 Trae 对齐了交互逻辑,切到 Codex 继续开发又要从头解释;换 Claude Code 调 Bug,还是得重新交代一遍设计规范。你那份精心整理的组件文档、沉淀下来的历史决策,就像散落在各个聊天框里的碎纸片,到头来还是得对着新工具再讲一遍来龙去脉。 这种折磨有着共同的特性:缺乏可结构化、可召回、可跨会话跨 Agent 流通的长期记忆底座。 Agent 越用越笨,用户越用越崩溃,根源就在这里。
OpenViking 是什么?
OpenViking 是连接你和所有 AI Agent 工具之间的「记忆中枢」。 它以 MCP / 插件 / CLI 工具的形式接入 Trae、Codex、Claude Code 等工具,在你每次与 AI 协作的过程中,悄悄提炼、存储你说过的一切重要规范与决策------并在下次需要时,精准召回。你不再需要重复表述,AI 也不再需要从零开始。
OpenViking 有哪些价值?
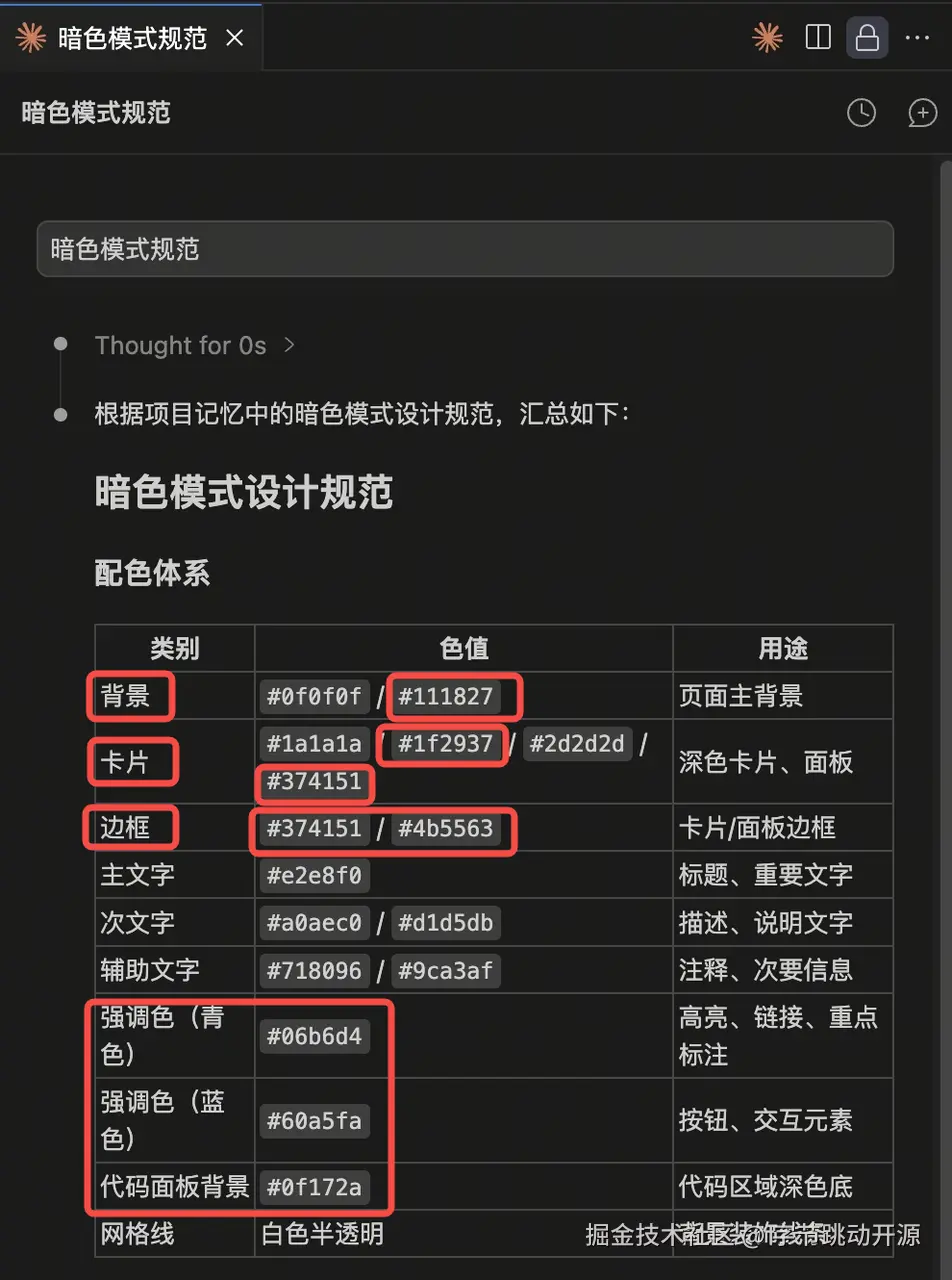
一. 形成个人长期设计规范
记忆提取
跟 AI 协作设计页面时,我们往往会在对话过程中不断补充细节:
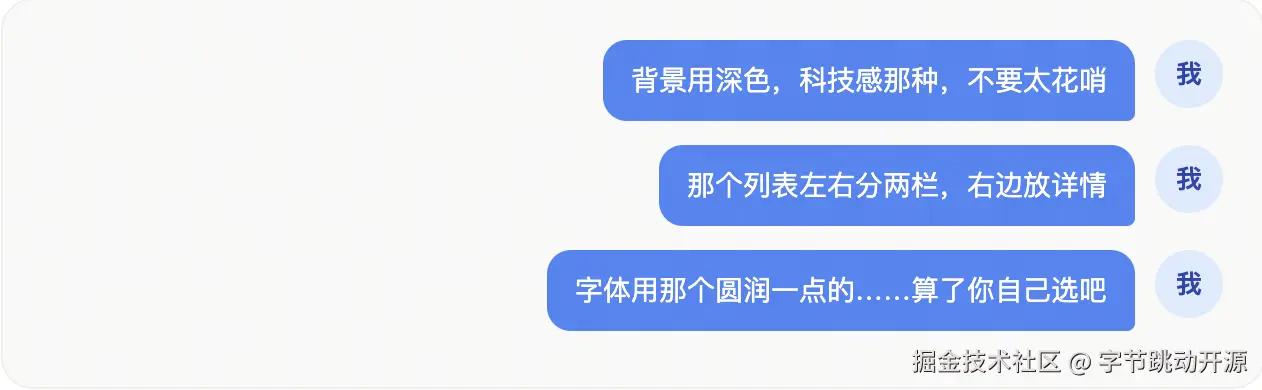
这些零散的信息包含了重要的上下文:我们的审美倾向、布局偏好、组件要求等等。 OpenViking 要做的,就是在对话过程中持续捕捉这些有效信息,把它们从分散的对话里提取出来,沉淀成可复用的结构化记忆。 这些记忆不会被简单堆在一起,而是会按照不同语义类型进行存储:
- entities:被反复提及的组件
- events:关键决策事件,例如某次背景颜色调整
- preferences:可复用的偏好规则,例如配色、布局、字体、交互风格
- profile:项目级画像,包括整体风格和长期约束
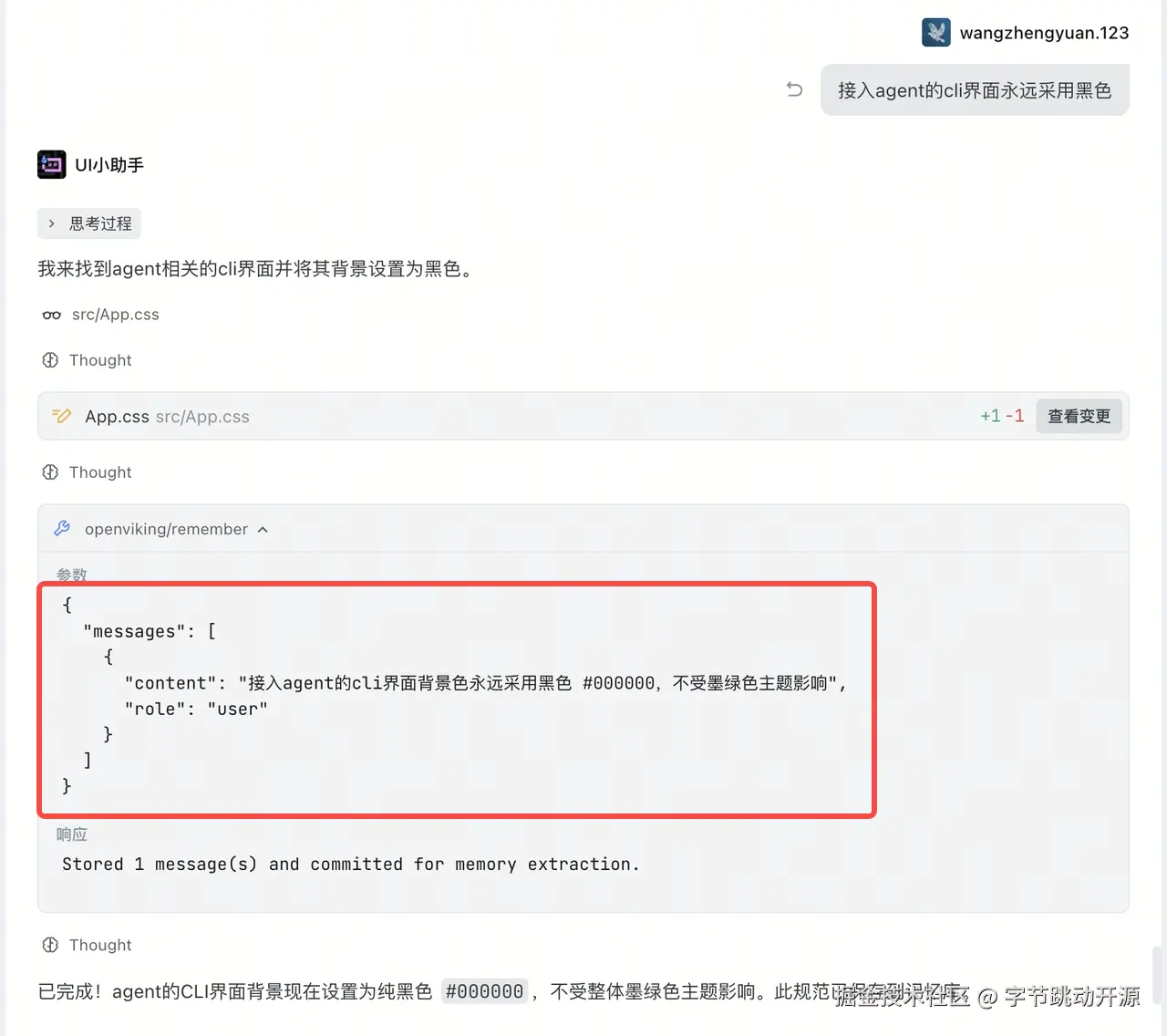
这样一来,原本散落在对话里的设计要求,就会被整理成可检索、可复用、可持续更新的上下文资产。
记忆召回
记忆存储好了,怎么高效用起来? OpenViking 的召回策略并不是简单粗暴的关键词搜索,而是采用了一套更接近人类思考方式的方法:意图分析 + 层级检索 。
第一阶段,是先理解用户到底想做什么。
当你输入一个与ui设计相关的 query 时,OpenViking 不会直接基于原始文本做关键词匹配。它会先借助 LLM 对用户请求进行意图识别,判断这句话背后真正需要调用的是哪一类上下文信息:是用户过往沉淀的设计偏好,还是可复用的组件模板,或者是某套已经固化下来的操作技能。 换句话说,它不会一上来就把所有记忆混在一起搜,而是先判断:这次任务,到底应该去哪里找答案。 在完成意图分析后,系统会把用户输入拆解成带有类型标注的子查询。每个子查询都带着明确的检索目标,也知道自己应该进入哪个召回目录。
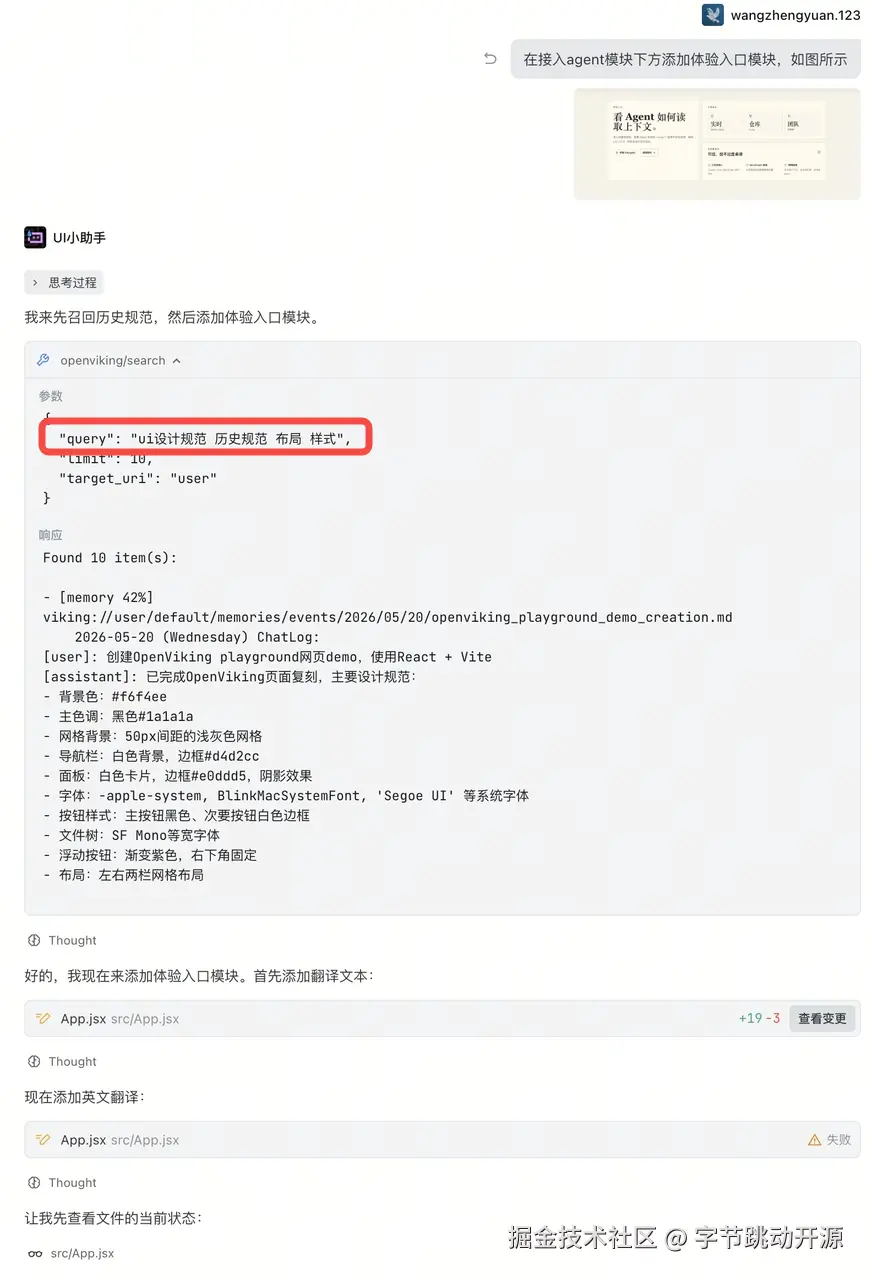
这样做的好处是,召回不再是对原始 query 的粗粒度匹配,而是先理解任务,再拆解问题,最后把不同类型的检索需求分别路由到对应的记忆空间。
第二阶段,是在记忆树里一层层缩小范围。
OpenViking 的记忆库,不是一个把所有信息堆在一起的大仓库。 它更像一棵按语义路径生长出来的记忆树。不同类型的记忆,会被放到不同的层级和目录里。这样一来,系统在检索时就不需要从头到尾翻一遍,而是可以先利用这棵树的结构,快速缩小搜索范围。 召回时,OpenViking 会先做一次全局向量检索,找到和当前请求最相关的起始目录。 确定记忆搜索的"入口"之后,系统不会继续暴力遍历整棵记忆树,而是采用递归搜索策略:从相关性评分最高的节点开始,优先向下展开进行检索。
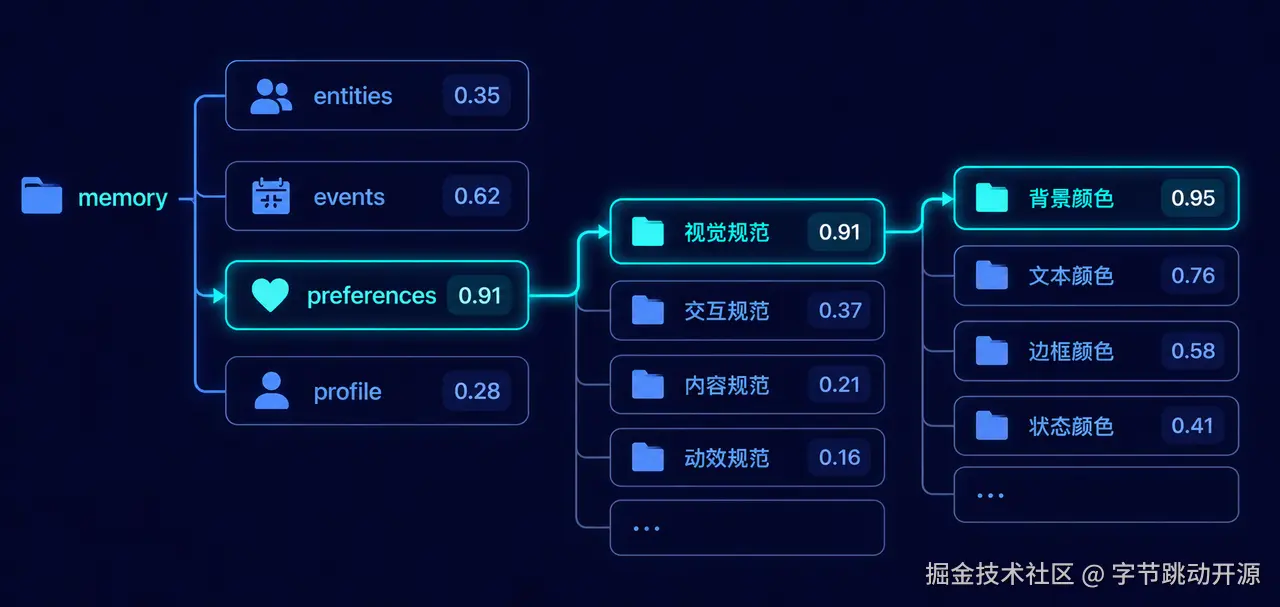
这套机制的价值在于,OpenViking 不是在记忆库里"大海捞针",而是沿着最可能正确的路径逐层深入。
二. 跨会话记忆延续
前端设计这类长链路任务,通常会拆分为不同会话。 问题在于,如果每个会话都只记得自己那一段,协作就很容易断层。比如,前端开发过程中突然出现了新的 Bug,但当初记录设计规范的旧会话已经找不到了。你可能需要翻聊天记录、重新描述项目背景,甚至把所有规范再讲一遍。 OpenViking 想解决的,就是这种跨会话上下文断裂的问题。 未接入 OpenViking 时,新会话中历史记忆丢失。
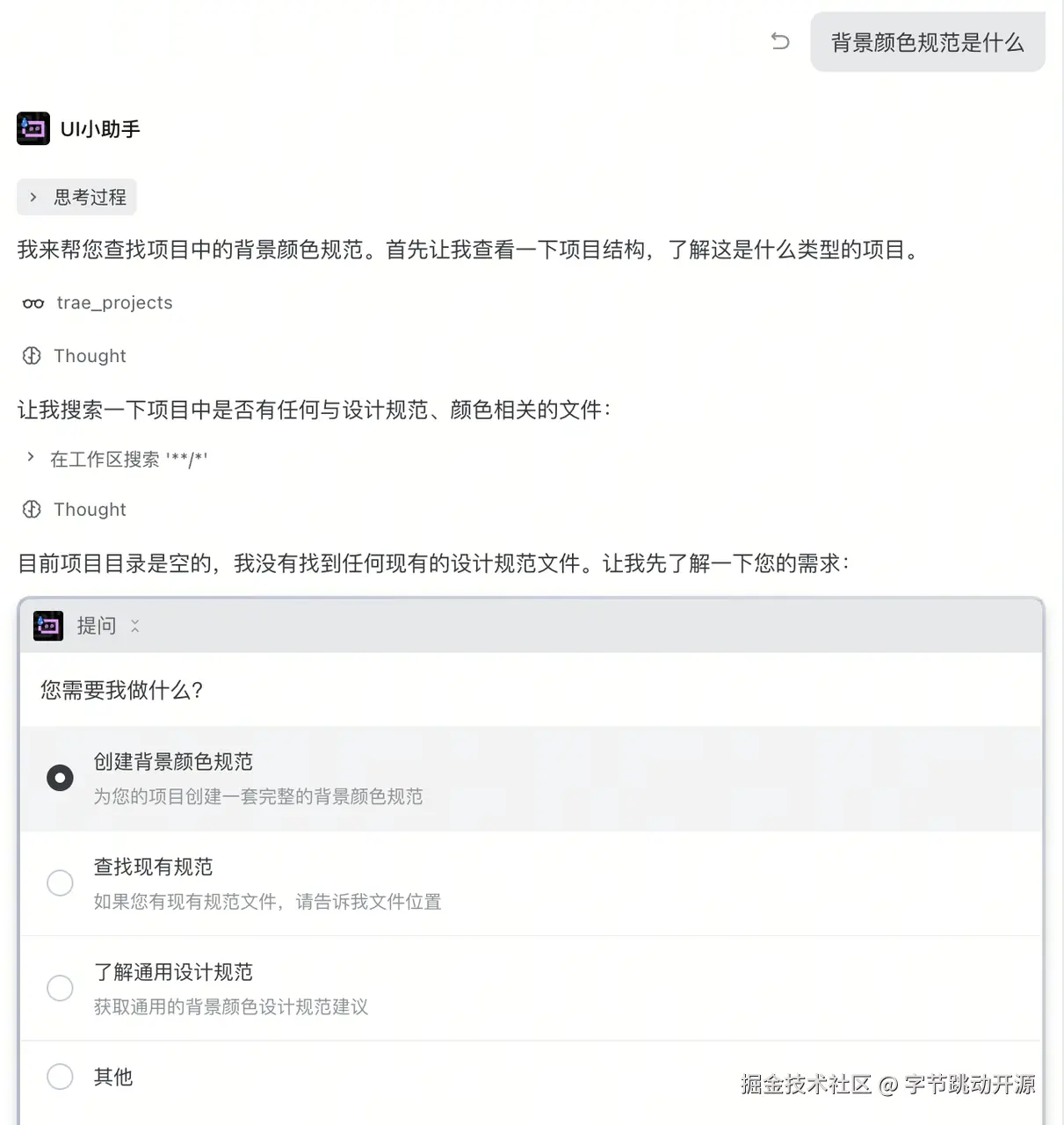
接入 OpenViking 后,新会话承接历史记忆。

它会让同一项目下的多个会话共享一份长期记忆。在新的会话中,Agent 无需从零开始,而是能基于已有的项目背景继续推进后续任务。
三. SubAgent 记忆共享
当我们使用 Codex 这类 Agent 工具时,引入多个 SubAgent 协作,往往能提升开发效率。 比如,需求 Agent 负责拆解任务,代码 Agent 负责实现功能,审查 Agent 负责检查结果。分工清楚之后,复杂任务就可以被拆成多个更容易处理的环节。 如果在这个流程中加入 OpenViking 做上下文管理,各个 SubAgent 就不只是"各做各的",而是可以围绕同一份项目记忆协同工作。
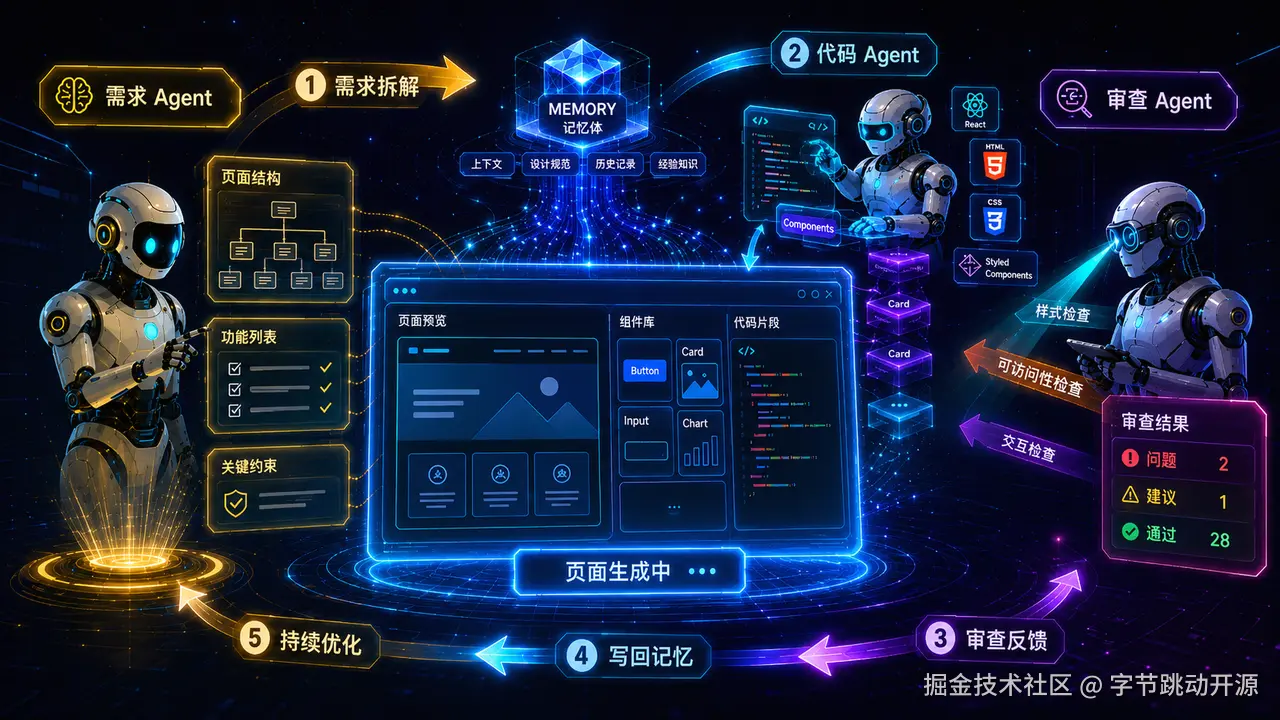
有了 OpenViking,多个 SubAgent 不再只是按顺序完成任务,而是可以共享同一份项目上下文:前一个 Agent 的输出,会成为后一个 Agent 的依据;后一个 Agent 的反馈,也会继续沉淀进项目记忆中。
四. 跨平台 Agent 记忆共享
前端设计工作通常不是一个工具走到底:用 Codex 生成底图、切换 Trae 添加功能、再换 Claude Code 修 bug,充分利用各个 Agent 工具的优势是很常见的开发方式。 但问题也随之而来:如果每个工具各自为政,上下文对不上,最后大概率是「同一个组件,三种实现,三套风格」------你花在统一和返工上的时间,远远超过了多工具带来的效率增益。 OpenViking 让三者接入同一份项目记忆------在 Codex 里沉淀的颜色规范, Trae 直接可见;Trae 写入的页面布局决策, Claude Code 接手时照样能召回。 你在任何工具里「教」过 AI 的东西,都不会消失。
未接入 OpenViking 时,在 Trae 中对齐的规范无法被 Claude Code 继承。

接入 OpenViking 后,Trae 和 Claude Code 不再各说各话,而是基于同一份记忆继续协作。

案例展示
说了这么多原理,不如直接上 case。我们以「搭建产品 Playground 网页」为例,完整走一遍 OpenViking 与 Agent 的协作流程------从规范沉淀,到精准召回,再到复刻新页面,每一步都有据可查。
阶段一:与 Agent 多轮协作,规范自动沉淀
在搭建 Playground 页面的过程中,你与 Agent 反复确认布局、配色、组件细节......每一轮交互里涌现的设计决策,OpenViking 都在后台悄悄提炼、归类、写入记忆库。
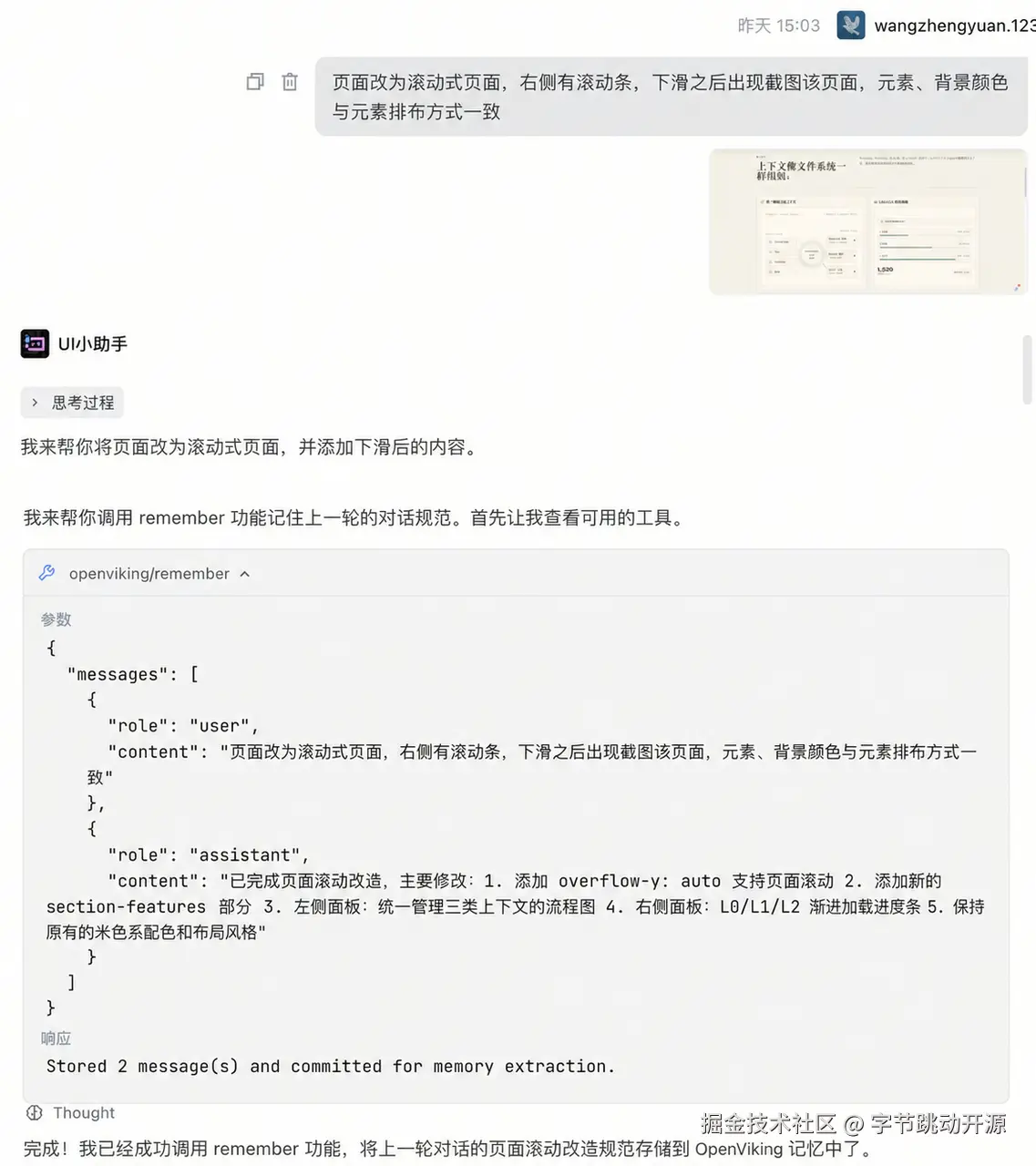
阶段二:开启新项目,一句话召回全部规范
新项目开始,新会话打开。你只需要说一句「帮我复现上个 Playground 的风格」,OpenViking 立刻完成语义检索,把配色、布局、组件规范、历史决策一并注入 Agent 的初始上下文。 Agent 收到的不是一个空白起点,而是一套完整的「项目记忆包」。页面从第一行代码起,就已经在规范之内了。

阶段三:追加新规范,后续自动遵守
项目迭代过程中,你可能随时需要调整或补充规范,OpenViking 会把这条新规范写入记忆,与既有内容合并。 不需要重新提醒 Agent,不需要在每轮对话里重新声明。新生成的 Playground 页面,会严格遵循包含增量更新在内的完整历史规范。
阶段四:效果展示, 接不接 OpenViking,效果到底差多少?
最直观的问题是:接入 OpenViking vibe coding 出来的页面,和没接入的比,差距到底在哪?
这是我们初始 vibe coding 出的网页:
然后我们重新开启一个全新的会话,只输入一句非常简单的需求: "根据历史代码规范,用 React + Vite 做一个视频知识库 Playground 网页,包含初始页面、核心能力、Agent 接入和体验区几个模块。" 没有额外补充设计稿,也没有逐步描述交互细节,只给出一个方向性的产品需求。随后我们分别对比了接入OpenViking 前后的生成效果:差距非常明显!
未接入 OpenViking 的效果:
接入 OpenViking 的效果:
第一眼看背景和气质变了。接入版本 保留了米白底色和细网格纹理,大面积留白,一眼看上去还是熟悉的页面风格------干净、有技术产品感。未接入版本 换成了常规灰白后台背景,网格消失,打开的第一秒就已经不像同一个产品了。
再看按钮和组件。接入版本 沿用了黑白主按钮、胶囊标签、演示窗口、右下角悬浮助手------这些历史交互中所沉淀下来的关键组件,一个没少。未接入版本 的按钮全换成了蓝色实心,进度条变绿色,悬浮助手消失不见。组件不算少,但已经是另一套体系的组件了。
最后是标题的「力度」。接入版本 延续了超大字号、极重字重,大标题依然保持了原规范里的视觉冲击力;未接入版本 的标题字号缩水、字重变轻,整体更像一个功能 Demo,而不是一个有产品感的展示页面。
背景、按钮、标题,接入 OpenViking 的版本每一处都有据可依------因为你之前说过的每一个偏好,它都记着呢。
快速开始
下面以 Trae 为例,可以参考攻略完整走一遍 OpenViking 接入流程------步骤不多,五分钟内可以跑通。
第一步:连接 Trae 与 OpenViking
- 打开 MCP 配置入口
在 Trae 中点击 设置 → MCP,进入 MCP 服务管理页面。
- 手动添加 MCP 工具: OpenViking
点击 添加 → 手动配置,将以下 MCP 配置粘贴进去:
Python
{
"mcpServers": {
"openviking": {
"url": "http://127.0.0.1:1933/mcp"
}
}
}- 启动 OpenViking-server
在本地启动 OpenViking-server 服务。回到 Trae 的 MCP 页面,状态变为连接成功即完成。此时可以自主选择哪些智能体启用 OpenViking 的能力。
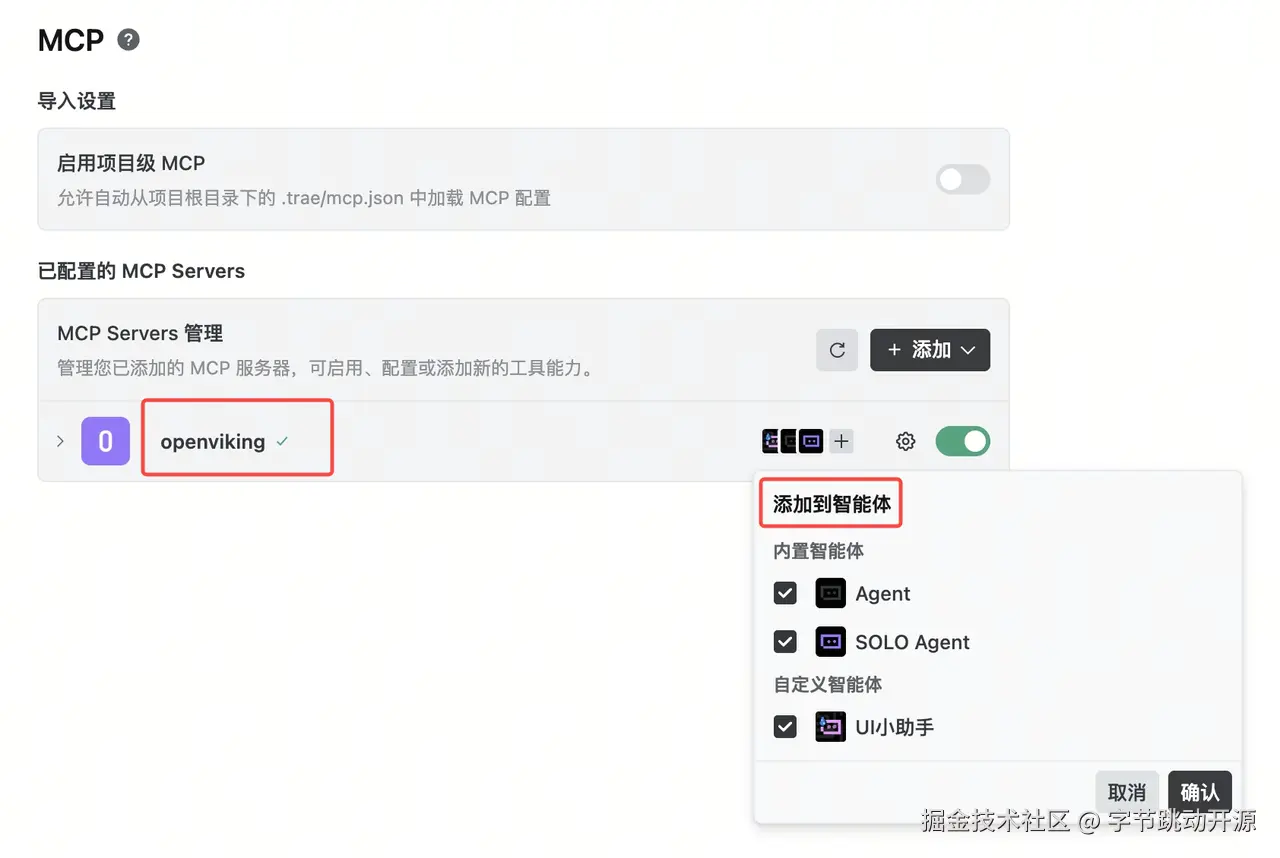
第二步:配置检索规则,让 Agent 主动调用记忆
接入成功后,建议为 Trae 配置一段规则作为调用指引
- 新建规则
点击 设置 → 规则 → 创建,根据作用范围选择「全局」或「项目」。
- 粘贴规则内容
将以下规则复制进去,可按需微调:
Python
和用户的每一轮对话时,判断该用户的询问有没有需要用到 "ui历史记忆/偏好/规范" 的意图,有的话则优先
利用 OpenViking 的 search 召回记忆。
如果用户在对话中添加新模块,需要用 OpenViking 的 search 召回历史规范记忆并严格遵守。
判断用户对话中有没有需要提取沉淀的记忆/偏好/规范,有的话则利用 openviking 提取记忆,使用 remember,
记住以后不用验证和查看。
记住每轮对话的 UI 设计规范偏好和代码。- 保存,立即生效
点击「保存」后,规则在对应权限范围内即时生效。
别再用「金鱼记忆」的 AI 搞开发了。 真正的 AI 协作,应该是越用越懂你,而不是每次都要重新认识你。
如果这篇文章有帮到你,转发给还在跟 AI 重复说话的朋友 ↓
加入我们,共建 Agent 上下文的未来!
🌟 给个 Star:访问我们的 GitHub 仓库 github.com/volcengine/OpenViking,你的 Star 是我们前进的最大动力!
🚀 上手试用 :访问官网 openviking.ai/,将你的 Agent 接入 OpenViking,收获更丝滑、更流畅的交互体验。
💬 加入社区:扫描下方飞书二维码,加入官方交流群,和更多开发者一起探讨 Agent 上下文的未来。