DDD 领域驱动设计思想原理
本文聚焦 DDD 的思想内核 与分层框架,主要在于搞清楚"DDD理论原理是什么?" 、"DDD 为什么这样设计?"
一、DDD 想解决的核心问题
领域驱动设计(Domain-Driven Design,DDD)由 Eric Evans 于 2003 年在同名著作中系统提出。它的核心主张可以浓缩为一句话:
让代码结构反映业务结构,让业务概念成为代码中的一等公民。
DDD 不是"另一种分层方式",也不是"必须配合微服务才能使用的架构"。它是一套从领域出发组织复杂软件 的方法论,核心由三个要素支撑:统一语言、领域模型、限界上下文。后文会先讲历史脉络,再讲战略设计、战术设计和分层架构。
软件开发演化到一定阶段后,拖慢交付的往往不是技术难题,而是业务复杂度。代码如果只按"技术维度"拆分(如 Controller / Service / DAO 三层),会暴露三个严重问题:
- 业务语言与代码语言割裂 :产品说"待支付订单",代码里写
status == 1;新人接手时只能靠口口相传补全语义。 - 业务规则散落:一个"订单不能在已发货后取消"的规则,可能同时出现在 Controller 校验、Service 流程、Mapper SQL、定时任务里,改一处漏一处。
- 边界由技术决定,而不是由业务决定:模块按"用户管理 / 商品管理"等表名拆分,却和真实业务流程(下单、履约、结算)对不齐,跨表事务、跨服务一致性问题随之增多。
二、DDD 的发展史
DDD 不是凭空出现的,它站在面向对象、企业应用架构、敏捷协作等数十年积累的基础上。理解它的演化脉络,才能理解每一个概念为什么会变成今天的样子。
先看下MVC 到 DDD 分层架构演进
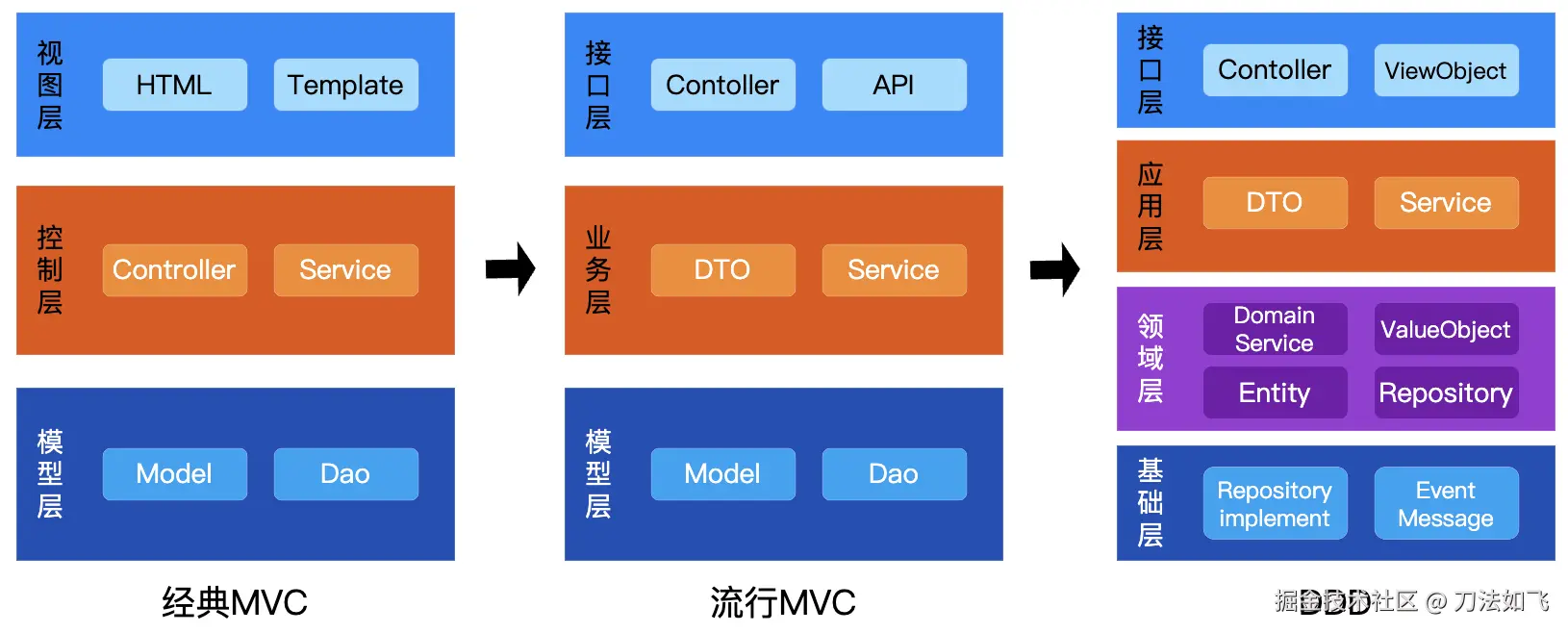
2.1 演化时间线
2.2 各阶段要点
时间线之外,每个时期最值得记住的一句话:
| 时期 | 关键事件 | 一句话定位 |
|---|---|---|
| 前史 1980s--2002 | GoF 设计模式(1994)/ UML 1.0(1997)/ Martin DIP / Fowler 贫血模型(2002) | OOP 范式成熟,但行业仍困于"伪 OO + Service"代码,等待一本指导书。 |
| 诞生 2003 | Eric Evans 《Domain-Driven Design》蓝皮书 | 一举奠定战略 / 战术 / 架构三层全部术语;初期被认为"太抽象"。 |
| 传播 2004--2010 | Greg Young 提出 CQRS(2007)/ Event Sourcing(2009) | DDD 从理论倡议演化为有 CQRS、ES 等补充模式的完整工程方法。 |
| 工程化 2011--2015 | Vernon 红皮书(2013)/ Brandolini 事件风暴(2013)/ 微服务运动(2014--2015) | 给出"标准 Java 实现"与协作建模方法;限界上下文 ≈ 一个微服务成为业界共识。 |
| 多元化 2016--2022 | Wlaschin 函数式 DDD(2016)/ Graça Explicit Architecture(2017)/ 阿里中台 + COLA(2018+) | 思想内核被证明不依赖 OOP;六边形 + 洋葱 + Clean + CQRS 综合为现代架构总图;DDD 在中国大规模工程落地。 |
| AI 时代 2023+ | LLM / Agent 化开发普及(Claude Code / Codex / Cursor) | DDD 被重新定位为"AI 的业务上下文协议":统一语言成为 Prompt 输入格式,限界上下文成为 Agent 任务边界。 |
一句总结:DDD 的内核(统一语言、限界上下文、依赖倒置)二十多年保持稳定,工程载体则从充血 Java 对象扩展到函数式、事件驱动、AI 协同等多种范式。
三、三大思想内核
3.1 统一语言(Ubiquitous Language):避免沟通歧义
定义 :领域专家、产品经理与研发团队在同一个限界上下文内共用同一套术语体系。这套语言不仅映射在文档中,更应显式体现在类名、方法名及数据库字段中。
对比分析:
| 场景 | 传统写法的"黑话" | DDD 的统一语言 |
|---|---|---|
| 语义表达 | order_status = 1 |
order_status = 'PENDING' |
| 行为抽象 | updateStatus(1, 2) |
order.pay() |
| 业务沟通 | "把状态码 1 改为 2" | "将订单标记为已支付" |
统一语言看似简单的命名约定,本质上是为了消除"语义翻译"带来的损耗。一旦统一语言确立,需求评审与代码审查将基于同一套词汇表,沟通效率会明显提升。
实践要点 :每个限界上下文应维护一份核心术语表(Glossary),明确"在这个边界内,某个词指的是什么,不指的是什么"。
3.2 领域模型(Domain Model):赋予代码业务理解
定义 :领域模型是业务规则在代码世界中的精确投射。它不再是单纯的数据容器,而是封装了数据、行为与业务不变量的对象。
DDD 将"贫血的数据搬运工"升级为"具备业务决策能力的领域对象":
java
// 充血模型:业务逻辑内聚,状态迁移由语义化方法驱动
public class Order {
private OrderStatus status;
public void pay() {
if (this.status != OrderStatus.PENDING) {
throw new OrderStateException("当前状态无法执行支付操作");
}
this.status = OrderStatus.PAID;
addDomainEvent(new OrderPaidEvent(this.id));
}
}核心差异 :贫血模型本质上是过程式设计的产物;而充血模型则体现了面向对象的本质------对象应基于自身状态执行业务动作,并保护自己的不变量。
3.3 限界上下文(Bounded Context):划定业务的边界
定义 :这是业务概念的意义边界。在大型系统中,试图构建一个"全能模型"往往难以维护。
示例:
- 销售上下文:商品 = (价格、促销标签、库存数)
- 物流上下文:商品 = (体积、重量、包装规格)
通过划分限界上下文,我们允许"同名异义"的存在,并在边界内保持模型的简洁与一致。
限界上下文是微服务拆分的重要依据。只有识别了边界,才能真正实现系统的松耦合与独立演进。
四、战略设计:如何界定业务边界?
战略设计关心的是"如何把一个复杂业务拆成可以理解、可以协作、可以演化的几块"。
4.1 领域、子域、核心域
举例(电商):
| 子域 | 类型 | 说明 |
|---|---|---|
| 订单、交易 | 核心域 | 直接关系收入 |
| 商品、评论 | 支撑域 | 业务必需,但难形成壁垒 |
| 权限、登录、消息推送 | 通用域 | 可买可建,谁家都长得差不多 |
战略意义:识别核心域之后,团队应把最强的工程能力和最深入的建模投入放在核心域上;支撑域可以用更轻的实现,通用域则优先考虑采购、开源或复用成熟方案。DDD 的投入重点不应该平均分配,而应围绕业务差异化能力展开。
4.2 限界上下文与上下文映射
限界上下文是战略设计的重要产物。识别子域之后,工程师还要继续判断:
- 哪几个子域合在一个限界上下文里?
- 上下文之间用什么模式协作?
常见的上下文映射模式:
| 模式 | 含义 | 适用场景 |
|---|---|---|
| Shared Kernel(共享内核) | 两个上下文共享一小段代码 / 模型 | 谨慎使用,强耦合 |
| Customer-Supplier(客户-供应商) | 下游依赖上游,但下游可影响上游 | 内部团队协作 |
| Conformist(追随者) | 下游完全适配上游模型 | 依赖外部不可控团队 |
| Anti-Corruption Layer(防腐层) | 在边界处加翻译层,隔离外部模型污染 | 集成遗留系统、第三方 API |
| Open Host Service | 上游提供标准协议供多方接入 | 平台型服务 |
| Published Language | 用公开标准格式作为通信契约 | 跨组织集成 |
防腐层(ACL)是工程上最常用的模式之一。凡是"外部模型不应该污染我们的领域模型"的依赖,都适合用 ACL 包裹。
五、战术设计:如何定义业务模型?
战术设计回答的是:"在一个限界上下文内,对象应该如何组织,业务规则应该放在哪里?"
5.1 实体(Entity)
关键特征:有唯一标识、有生命周期、可变。
判断方法:如果"两个对象除了 ID 完全一样,业务上仍然是两个东西",那就是实体。例如两笔金额相同的订单是两个不同的订单。
5.2 值对象(Value Object)
关键特征:无唯一标识、不可变、按属性值判等。
典型例子:金额(Money)、地址(Address)、日期范围(DateRange)、坐标(Coordinate)。
java
public final class Money {
private final BigDecimal amount;
private final String currency;
public Money add(Money other) { /* 返回新对象,不修改自身 */ }
}为什么重要 :值对象把"裸 BigDecimal 加减乘除散落各处"变成"Money 自己负责货币规则"。它是减少魔法字符串、魔法数字、重复校验逻辑的有效手段。
5.3 聚合与聚合根(Aggregate & Aggregate Root)
聚合:一组业务上不可分割、共享生命周期的实体与值对象的集合。
聚合根:聚合的唯一对外入口,负责维护聚合内部的不变量(Invariant)。
设计原则:
- 聚合外部尽量只持有聚合根的 ID 引用,避免直接持有内部实体引用。
- 一个事务优先只修改一个聚合:跨聚合一致性通常通过领域事件和最终一致性处理,而不是优先诉诸分布式事务。
- 聚合要小:大聚合容易带来并发竞争、加载成本和性能问题。
判断聚合大小的经验法则:如果一个不变量需要在一次事务内保持强一致,它涉及的对象通常应放在同一个聚合内;否则优先拆开。
5.3.1 聚合一致性边界
聚合最容易被误解成"对象包含关系"或"数据库表关系"。更准确地说,聚合是一个一致性边界:它规定哪些业务规则必须在一次事务内被同时保护,哪些规则可以通过事件、补偿或异步流程在稍后达成一致。
以订单为例,Order 与 OrderItem 通常属于同一个聚合,因为"订单总金额必须等于订单项金额之和"这类不变量需要在同一次变更中保持一致;但"支付成功后增加会员积分"通常不应该放进订单聚合,因为积分属于另一个业务边界,可以通过 OrderPaidEvent 触发后续处理。
判断一致性边界时,可以问三个问题:
- 这个规则是否必须立刻成立? 如果不立刻成立就会造成业务错误,倾向放在同一个聚合。
- 这个规则是否只依赖聚合内部数据? 如果需要查询大量外部对象,通常说明边界过大或规则应外移。
- 这个变化是否需要同一个事务提交? 如果可以通过事件最终一致,就不必把多个聚合硬塞在一起。
常见反例是"大聚合":把订单、支付、库存、物流、积分全部塞进一个 Order 聚合,看似保证了强一致,实际会带来事务过大、锁竞争、对象加载过重和团队边界混乱。DDD 更推荐用小聚合保护核心不变量,用领域事件连接跨聚合流程。
5.4 领域服务(Domain Service)
什么时候使用? :当一个领域行为不自然地属于任何单个实体或值对象时,把它放到领域服务里。
典型场景:
- 涉及多个聚合的业务规则(如订单转移:涉及 Order 与 User)
- 需要查询仓储才能完成的领域判断(如"该用户的待支付订单数是否超限")
反模式警告 :不要把本该在实体上的行为(如 Order.pay())挪到领域服务里,否则实体会退化成贫血模型。优先放实体或值对象,确实不属于任何对象时再放领域服务。
5.5 领域事件(Domain Event)
定义:领域内已经发生的、值得让其他部分知道的事实。
java
// 事件表达"已发生的事实",名字用过去式
public class OrderPaidEvent extends DomainEvent {
private final OrderId orderId;
private final Money amount;
}思想价值:
- 解耦 :订单不需要知道"支付完成后要发短信、扣库存、加积分";它只发布
OrderPaidEvent,下游各自订阅。 - 可追溯:领域事件记录了业务事实,在合适的架构中可以进一步发展为事件溯源(Event Sourcing)。
- 异步友好:事件天然适配消息队列,是构建最终一致性的基石。
5.6 仓储(Repository)与工厂(Factory)
- 仓储 :提供"像访问内存集合一样持久化/查询聚合"的抽象。仓储接口定义在领域层,实现在基础设施层,这是依赖倒置的核心体现。
- 工厂:当聚合的创建逻辑过于复杂(涉及多个对象的初始化、业务校验),把它抽到工厂里,避免聚合根构造函数膨胀。
六、分层架构:4 层职责与依赖关系
DDD 的经典分层架构由 Eric Evans 提出,后来又与六边形架构、洋葱架构、整洁架构等思想相互影响。不同图形表达看起来不一样,但核心都在强调四类职责和一条依赖方向:
6.1 各层职责("每层边界是什么?")
| 层 | 该做的 | 不该做的 |
|---|---|---|
| 用户界面层 | 协议解析(HTTP/RPC/CLI)、入参出参格式、调用应用服务 | 写业务规则、直连仓储、绕过应用服务 |
| 应用服务层 | 用例编排、事务边界、DTO ↔ 领域类型转换、发布事件 | 承载核心业务规则、写 SQL |
| 领域层 | 业务规则、不变量、状态迁移、领域事件 | 引用任何持久化技术、HTTP 客户端、消息队列 SDK |
| 基础设施层 | 仓储实现、ORM、消息队列适配器、外部 API 客户端 | 包含业务规则、定义业务概念 |
6.2 依赖倒置(Dependency Inversion)是核心所在
最关键的设计原则 :领域层不应该依赖基础设施层。常见做法是:
- 领域层定义
OrderRepository接口; - 基础设施层实现
OrderRepositoryImpl; - 应用服务层注入接口、调用方法;
- 编译期依赖方向保持为:基础设施 → 领域,而不是反过来。
这样做的回报:
- 领域层可独立测试------不需要数据库就能跑单元测试。
- 基础设施更容易替换------从 MySQL 换到 PostgreSQL、从 RabbitMQ 换到 Kafka 时,领域代码不应受到直接影响。
- 业务规则不被技术细节绑架------SQL 优化、连接池调优都发生在基础设施层,与领域无关。
6.3 命名约定
实际项目中,DDD类名后缀可以帮助团队快速判断对象所在层次和职责:
| 后缀 | 类型 | 所在层 |
|---|---|---|
Controller / Facade |
协议入口 | 接口层 |
Request / Response |
HTTP 入参出参 | 接口层 |
AppService / ApplicationService |
应用服务 | 应用层 |
DTO |
数据传输对象 | 应用层 / 接口层 |
Order、Money、OrderStatus(无后缀) |
实体 / 值对象 / 领域对象 | 领域层 |
DomainService |
领域服务 | 领域层 |
Repository(接口) |
仓储抽象 | 领域层 |
RepositoryImpl |
仓储实现 | 基础设施层 |
DO / PO |
数据持久化对象 | 基础设施层 |
Mapper / DAO |
ORM / 数据访问接口 | 基础设施层 |
Client |
外部系统接口抽象 | 应用层 / 领域层 |
ClientImpl / XXXAdapter |
外部系统实现(防腐层) | 基础设施层 |
注意:DDD 里的 VO = Value Object(值对象),不是 MVC 语境里的 View Object。
6.4 分层架构的演化:从经典分层到新型架构
Evans 蓝皮书中的"接口 / 应用 / 领域 / 基础设施"四层常被画成自上而下的结构,这容易让人误以为"基础设施在最底层 = 领域依赖基础设施"。这与依赖倒置的精神并不一致。为了让架构图和依赖方向更直观,社区在 2005--2017 年间陆续形成了几种常见表达:
| 架构 | 提出者 | 年份 | 核心隐喻 | 主要贡献 |
|---|---|---|---|---|
| 六边形 / 端口适配器(Hexagonal / Ports & Adapters) | Alistair Cockburn | 2005 | 应用核心 + 端口 + 适配器 | 让"多入口 / 多出口"对称化 |
| 洋葱架构(Onion Architecture) | Jeffrey Palermo | 2008 | 同心圆,依赖向内 | 让分层依赖图形化 |
| 整洁架构(Clean Architecture) | Robert C. Martin(Uncle Bob) | 2012 | 同心圆 + 一条规则 | 提炼出 The Dependency Rule |
| 显式架构(Explicit Architecture,综合视图) | Herberto Graça | 2017 | 综合上述三者 + CQRS + DDD | 给出现代工程的综合参考图 |
这些架构的外形不同,但底层约束一致:领域居中,依赖向内。下面逐一展开。
6.4.1 六边形架构(Ports & Adapters,端口适配器模式)
思想 :把应用核心画成一个六边形,所有外部世界(HTTP、数据库、消息队列、第三方 API、CLI、定时任务等)都作为适配器 ,通过端口接入核心。六边形的边数没有特殊含义,只是为了方便表达多种入口和出口。
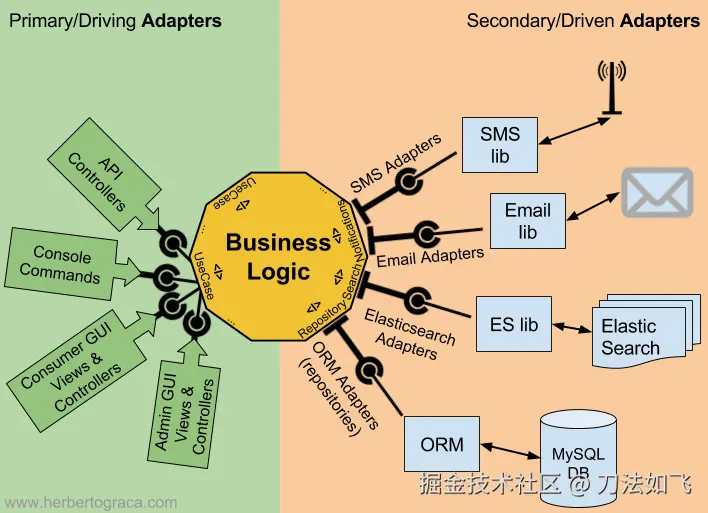
关键概念:
- 驱动端口(Driving / Primary Ports) :核心对外暴露的能力 ,由外部世界主动调用------通常是应用服务接口(如
OrderUseCase)。HTTP / CLI / 定时任务 / 测试都是它的驱动方。 - 被驱动端口(Driven / Secondary Ports) :核心需要外部提供的能力,由核心反向调用------通常是仓储 / 消息发布 / 外部服务客户端接口。DB / MQ / 第三方 API 都是它的被驱动方。
- 适配器(Adapter) :左侧的主适配器 把外部协议(HTTP / gRPC / CLI)翻译为驱动端口调用;右侧的从适配器把被驱动端口调用翻译为外部协议(SQL / Kafka / REST)。
核心价值:HTTP 只是众多入口之一,DB 也只是众多出口之一。把入口换成 gRPC、出口换成 MongoDB 时,理想情况下应用核心不需要改动。这就是"领域独立"的工程含义,也是单元测试可以脱离 Spring / Web / DB 单独运行的重要原因。
最容易踩的坑 :把"端口"等同于"接口"。端口首先是一个架构概念 ,描述"核心如何被驱动"以及"核心需要外部提供什么能力";接口只是端口在某种编程语言中的实现形态。一个端口可以对应多个适配器,例如同一个 OrderRepository 可以分别由 MySQL、MongoDB、内存实现来适配。
6.4.2 洋葱架构(Onion Architecture)
思想 :把架构画成同心圆,最内圈是领域模型,向外依次是领域服务、应用服务、基础设施。所有依赖都指向内层 ,这就是 Palermo 强调的 "Dependencies point inward"。
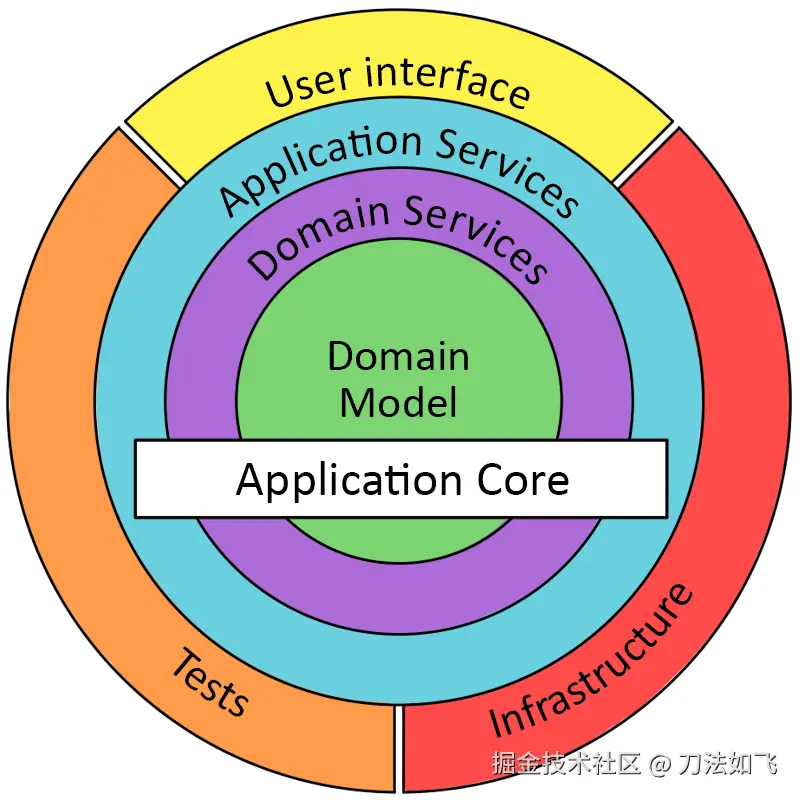 各圈职责(从内到外):
各圈职责(从内到外):
| 圈层 | 内容 | 不允许 |
|---|---|---|
| 第 1 圈 · 领域模型 | 实体 / 值对象 / 聚合根 / 领域事件 | 引用任何外圈类型 |
| 第 2 圈 · 领域服务 | DomainService(跨聚合规则)+ Repository 接口 | 依赖框架 / 持久化技术 |
| 第 3 圈 · 应用服务 | ApplicationService(用例编排、事务边界、事件发布) | 包含业务规则 |
| 第 4 圈 · 基础设施 + UI | Web、DB、MQ、CLI、第三方 API 适配器 | 反过来被内圈引用 |
与经典 4 层的差异:
- 经典 4 层是"自上而下"的纵向图,容易让人误以为"基础设施在最底层 = 被领域依赖";洋葱用同心圆消除了"上下"概念,只保留"内外"关系:外层依赖内层,内层完全不知道外层存在。
- 洋葱把"领域服务"与"领域模型"显式分成两圈,让"什么逻辑放实体、什么逻辑放领域服务"这个高频争论更清晰:只要在第 1 圈能表达的不变量,就不应该外溢到第 2 圈。
与六边形的关系:洋葱的第 4 圈相当于六边形的适配器层;六边形不规定核心内部如何分层,洋葱补足了这一点。两者并不矛盾,许多工程图会同时使用这两个隐喻。
6.4.3 整洁架构(Clean Architecture)与 Explicit Architecture
整洁架构 (Uncle Bob, 2012)综合六边形、洋葱、BCE(Boundary-Control-Entity)等多种思路,提炼出一条核心规则------依赖规则(The Dependency Rule):
源代码依赖只能指向内层。内层代码不应该依赖外层定义的类型、函数或命名。
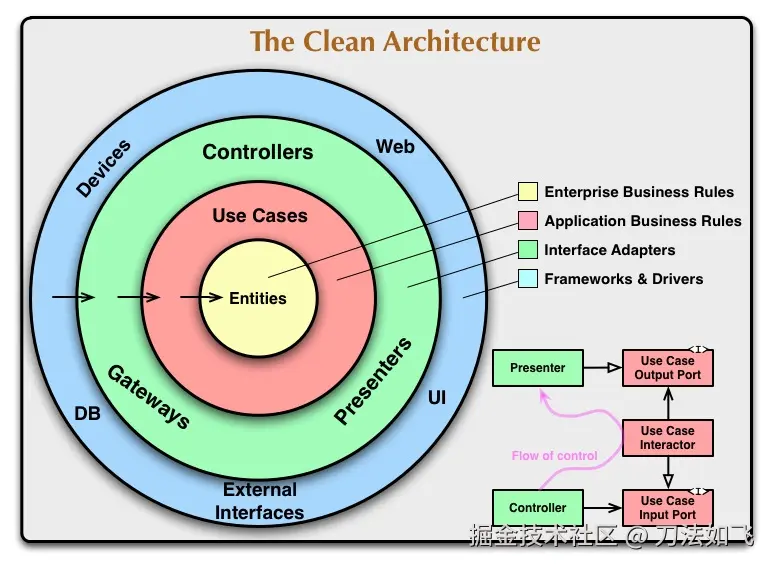
从外到内 4 个圈:
| 圈层 | Uncle Bob 命名 | 内容 |
|---|---|---|
| 最外 | Frameworks & Drivers | Spring、Web 框架、DB 驱动 |
| 外二 | Interface Adapters | Controller、Presenter、Gateway |
| 外三 | Application Business Rules | Use Cases(应用服务) |
| 最内 | Enterprise Business Rules | Entities(领域模型) |
与洋葱架构的关系:高度相似,差别在于:
- 洋葱关注"如何在 DDD 项目中组织代码",因此第 1、2 圈直接借用 DDD 术语(领域模型 / 领域服务)。
- 整洁架构关注更普适的应用架构,因此用更中性的术语(Entity / Use Case),并明确把 Frameworks 拎到最外圈,强调**"框架是细节,不是核心"**。
**Explicit Architecture(显式架构,Graça 2017)**把以上几种架构连同 CQRS、DDD 战术模式综合在一张图里:
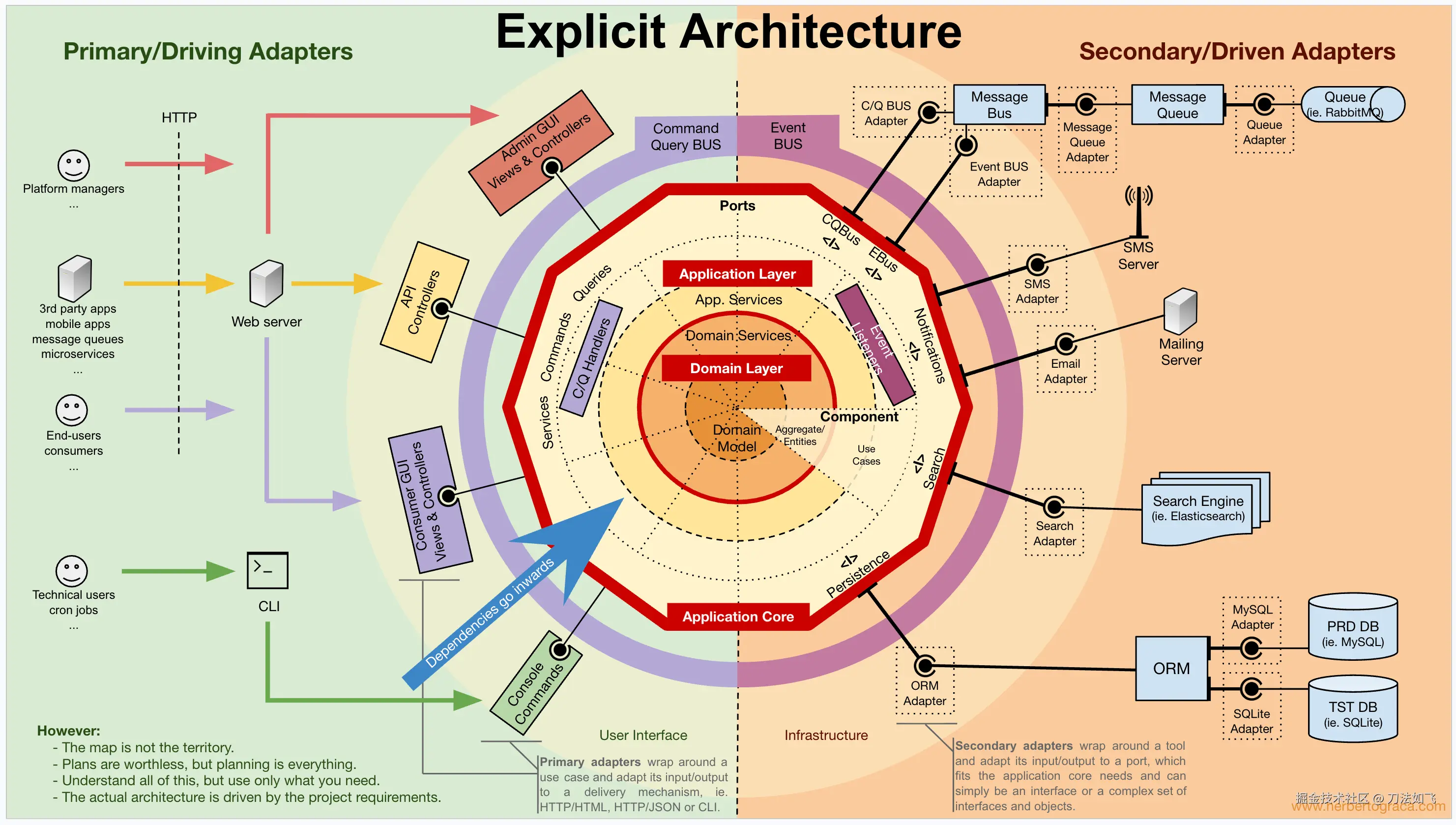
它不是另一种全新架构,更像是面向现代工程实践的综合视图:
- 应用核心 = 洋葱内 3 圈 = 整洁内 2 圈 = 六边形的核心区域
- 入口 / 出口 = 六边形的左右两类适配器
- CQRS / 领域事件 / 外部事件分发等 = DDD 战术模式
结论 :如果一个团队问"我应该用哪种架构图",可以用 Explicit Architecture 作为工程总图,再用六边形或洋葱解释局部。它们不是对手,而是同一类架构思想的不同视角。
6.4.4 架构演进的底层共识
尽管上述架构图呈现形式各异,但其底层约束却高度趋同:
- 领域模型居于核心:业务逻辑不依赖于外部技术细节。
- 依赖方向始终向内:外层适配器可以感知领域层,但领域层对外部世界(数据库、Web 框架等)保持"零感知"。
- 通过适配器实现解耦:所有外部设施都作为"插件"接入。
工程实践建议:
- 初期选型:从经典的四层架构入手,建立"领域优先"的直觉。
- 架构演进:当面临"多端接入"或"存储介质频繁更换"时,引入六边形的端口适配器模式。
- 长期主义:始终坚持"依赖倒置",确保业务逻辑的可独立测试性,这是架构师对抗系统腐化的根本手段。
6.5 CQRS 与 Event Sourcing:复杂读写和历史追溯
CQRS(Command Query Responsibility Segregation,命令查询职责分离)和 Event Sourcing(事件溯源,简称 ES)经常与 DDD 一起出现,但它们不是 DDD 的必选项。更准确地说,它们是 DDD 在复杂读写、审计追溯、事件驱动场景下的增强模式。
6.5.1 CQRS:把写模型和读模型分开
传统 CRUD 系统通常用同一套模型同时处理写入和查询:
text
Controller -> Service -> Repository -> 数据库表 -> 查询结果当业务变复杂后,写入模型和查询模型的目标会发生冲突:
- 写入侧关心业务规则、不变量、状态迁移,适合围绕聚合建模。
- 查询侧关心页面展示、列表筛选、统计报表、跨表聚合,适合面向读场景做扁平化或预计算。
CQRS 的做法是把二者分开:
在 DDD 项目中,CQRS 的价值主要有三点:
- 保护写模型:写侧聚焦聚合不变量,不必为了复杂查询污染领域模型。
- 优化查询体验:读侧可以按页面、报表、搜索等场景设计专门的读模型。
- 支持异步扩展:写侧发布事件,读侧通过投影更新,天然适合最终一致性。
需要注意:CQRS 不等于"读写必须分库",也不等于"所有接口都要拆成 Command 和 Query"。在简单 CRUD 场景中强行使用 CQRS,只会增加模型、同步和排障成本。
6.5.2 Event Sourcing:用事件作为状态来源
普通持久化保存的是对象当前状态:
text
Order(id=1, status=PAID, amount=100)Event Sourcing 保存的是状态变化历史:
text
OrderCreated
OrderItemAdded
OrderPaid
OrderShipped当前状态不是直接存出来的,而是由事件序列重放得到:
text
当前订单状态 = fold(OrderCreated, OrderItemAdded, OrderPaid, OrderShipped)Event Sourcing 的优势是:
- 完整审计:不仅知道当前状态,还知道每一步为什么变成现在这样。
- 时间回放:可以重建某个历史时刻的状态,用于排障、对账、监管审计。
- 事件驱动天然契合:领域事件既是业务事实,也是持久化事实。
它的代价也很明显:
- 事件版本演进复杂,事件一旦发布和持久化就不能随意改结构。
- 查询通常需要额外投影,否则每次重放事件成本很高。
- 团队需要理解事件建模、幂等、重放、快照、补偿等工程问题。
因此,Event Sourcing 适合审计要求高、状态变化复杂、需要历史回放的核心域,例如交易、账务、风控、订单履约流水等;不适合普通后台管理和简单 CRUD。
6.5.3 与 DDD 的关系
DDD 先回答"业务边界和模型是什么",CQRS / ES 再回答"复杂读写和历史状态如何实现"。一个合理的顺序是:
- 先用统一语言、限界上下文、聚合识别业务边界。
- 再判断写侧模型是否被复杂查询拖累,是否需要 CQRS。
- 最后判断业务是否真的需要完整事件历史,是否值得引入 Event Sourcing。
换句话说:DDD 是建模方法,CQRS / ES 是实现复杂模型时可选的架构模式。不要为了显得"高级"而引入它们,只有当读写复杂度、审计要求或事件驱动协作的收益超过成本时,才值得使用。
七、DDD 与 OOP、MVC 的关系与对比
理解 DDD 时,最容易踩的坑是把它与 OOP(面向对象编程)、MVC(Model-View-Controller)混为一谈。三者所处层次不同、回答的问题不同,但在工程实践中经常同时出现:
三者层次不同、不互斥:DDD 是业务建模方法,OOP / FP 是编程范式,MVC 是 UI 应用的代码组织模式。DDD 可以使用 OOP 落地,也可以与 MVC 的接口层共存。
7.1 DDD 与 OOP:建模哲学 vs 编程范式
OOP 提供的是机制 :封装、继承、多态、抽象。DDD 提供的是如何用模型表达复杂业务的方法论。在 OOP 语言中,DDD 常借助对象封装业务规则;在函数式语言中,也可以借助类型系统和纯函数表达同样的业务约束。
它们不在同一层:OOP 回答"如何组织代码",DDD 回答"如何让代码反映业务"。一个团队可以"用 OOP 但不用 DDD"(最常见的反例是"Service + 贫血对象"风格),也可以"用 FP 实践 DDD"(Scott Wlaschin 的工作就是典型例子)。
7.1.1 对比表
| 维度 | OOP(朴素使用) | DDD(OOP 的业务化应用) |
|---|---|---|
| 核心抽象 | 对象(数据 + 方法的封装单元) | 领域对象(实体 / 值对象 / 聚合根) |
| 设计驱动力 | 复用、扩展、解耦 | 业务规则、业务边界、业务语言 |
| 边界划分 | 类、包、模块 | 聚合、限界上下文 |
| 不变量保护 | 由调用者约定 | 由聚合根强制 |
| 行为归属 | 谁持有数据,谁就该有行为(弱约束) | 谁负责不变量,谁就持有行为(强约束) |
| 设计模式 | GoF 23 个通用模式 | DDD 战术模式(聚合 / 仓储 / 领域事件 / 工厂 / 服务) |
| 与业务的距离 | 可远可近,取决于团队自律 | 明确要求贴近业务语言 |
7.1.2 朴素 OOP 的退化:贫血模型
工程实践中,许多团队"用 Java 写 OOP",但代码实际上是面向过程的:
java
// 看上去是 OOP,本质是过程式
public class Order {
private String status; // 数据
public String getStatus() {...} // 仅暴露数据
public void setStatus(String s) {...}
}
public class OrderService { // 行为
public void payOrder(Order o) {
// 业务规则全在这里
if ("PENDING".equals(o.getStatus())) {
o.setStatus("PAID");
}
}
}Martin Fowler 把这种用法称为 贫血领域模型反模式(Anemic Domain Model) 。它有 OOP 的形式(class、private 字段),却没有把关键业务行为放回对象内部。DDD 的充血模型,本质上就是让业务行为回到业务对象中:
java
// 充血模型:行为回到数据身边
public class Order {
private OrderStatus status;
public void pay() { // 行为
if (this.status != OrderStatus.PENDING) {
throw new OrderStateException(...);
}
this.status = OrderStatus.PAID;
addDomainEvent(new OrderPaidEvent(this.id));
}
}7.1.3 DDD 也可以脱离 OOP
Scott Wlaschin 的《Domain Modeling Made Functional》证明:DDD 的思想内核(统一语言、限界上下文、聚合一致性边界)并不绑定 OOP。用 F# 的代数数据类型(ADT)和函数管道,可以更精确地表达领域:
fsharp
// F# 函数式 DDD:状态机由类型系统强制
type Order =
| PendingOrder of PendingData
| PaidOrder of PaidData
| CancelledOrder of CancelledData
let pay (order: PendingOrder) : PaidOrder = ...
// 编译期就保证:你拿不到一个"已取消的订单"再去 pay结论:DDD 可以借助 OOP 落地,但不等同于 OOP。它的内核是范式无关的,关键始终是业务语言、业务边界和业务规则。
7.2 DDD 与 MVC:业务建模 vs UI 分层
MVC 诞生于 Smalltalk-80,原本是为图形界面 设计的代码组织模式:Model(模型)、View(视图)、Controller(输入处理)。后来 Web MVC(Spring MVC、Rails、ASP.NET MVC)把它扩展到服务端,但它的核心关注点仍然是 UI 与交互入口:
sql
浏览器请求 → Controller → 调 Model(业务/数据)→ 渲染 View → 返回很多团队声称在"做 DDD",但代码看上去仍是传统 MVC,原因就在于:MVC 是 UI 视角的水平切分,DDD 是业务视角的垂直切分。判断是否真正引入 DDD,关键不在于有几层文件夹,而在于业务规则是否有明确归属、边界是否按业务划分、语言是否与业务一致。
| 维度 | MVC | DDD |
|---|---|---|
| 关注点 | UI 应用的代码分层(视图、控制、数据) | 复杂业务的领域建模与边界 |
| 分层依据 | 技术职责(看得见的层) | 业务关注点(界面 / 用例 / 领域 / 设施) |
| 业务规则归属 | 散布在 Controller / Service / SQL | 集中在领域模型与领域服务 |
| 数据 vs 行为 | 在许多 Web MVC 项目中,Model 容易退化为数据结构,Service 承载行为 | 领域对象数据与行为共生(充血模型) |
| 边界划分 | 技术边界 | 业务边界(限界上下文) |
| 依赖方向 | 由上至下:Controller → Service → Model → DB | 依赖倒置:所有外环依赖领域内核 |
| 适用场景 | 简单 CRUD、强交互前端、快速原型 | 复杂业务、长期演化、多团队协作 |
核心区别一句话 :MVC 关心"入口和界面代码怎么组织",DDD 关心"业务怎么建模"。两者并不互斥:DDD 的接口层完全可以用 MVC 写 Controller,DDD 真正改变的是业务模型的内涵,让它从"贫血的数据搬运工"变成"携带业务规则的领域对象网络"。
7.3 OOP、MVC、DDD 三者协作的工程架构
在一个真实的 Spring Boot + DDD 项目里,三者各司其职:
三种思想各司其职:
- OOP 是地基:各层可以用 OOP 机制(或 FP)组织代码,提供封装、抽象与多态能力。
- MVC 在最外圈:
Controller负责协议适配(HTTP 入参出参、视图渲染),不写业务规则。 - DDD 贯穿中间到内核:应用层定义用例,领域层封装业务规则与聚合边界,仓储通过依赖倒置把基础设施挡在外面。
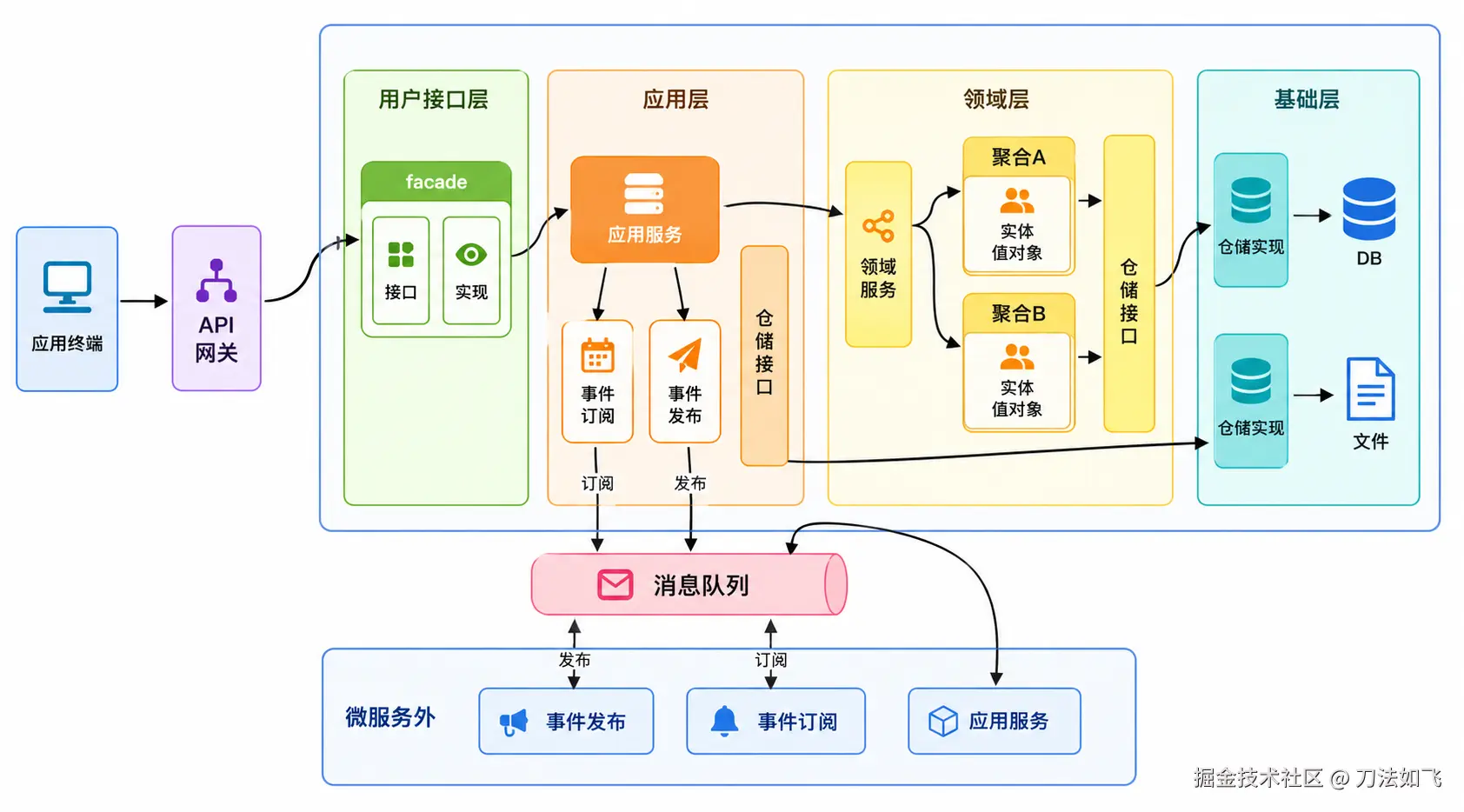
这张图想表达的是联合职责分布:入口适配归 MVC,业务建模归 DDD,代码组织机制可由 OOP 或 FP 提供。
八、AI 时代的 DDD 价值
随着 Claude Code、Codex、Gemini等 Agent 工具进入工程现场,软件开发逐渐进入"工程师指导 AI 写代码"的新范式。有人担心 DDD 这种"重型设计方法"会过时;实际情况相反,AI 时代反而放大了清晰业务上下文的价值。
8.1 为 AI 提供清晰的业务边界
AI 生成代码的质量上限,很大程度取决于输入上下文的质量。面对一份"业务术语模糊、规则散落"的代码库,再强的模型也容易写出风格漂亮但语义错乱的代码。DDD 提供的限界上下文、聚合、领域事件,正好构成 AI 理解业务的骨架。
8.2 统一语言是 AI 的通用接口
需求描述能力正在成为工程师的核心能力。由统一语言构成的需求描述,能让 AI 更稳定地生成正确结构;如果需求里混杂着 t_001 表、flag = 'Y'、process() 等密码式术语,AI 输出的代码往往仍需要人工大改。
8.3 领域模型是 AI 的代码蓝图
给 AI 一份清晰的领域模型(实体、值对象、聚合、事件清单),它生成代码的结构会更一致。这相当于把一部分"代码结构审查"前移到"领域建模阶段"。
8.4 Agent 时代的任务拆分骨架
Agent 执行多步骤任务时,一个常见失败模式是"边界滑坡":做着做着越过了原定范围。限界上下文提供了天然的任务边界:每个 Agent 只在一个上下文内活动,跨上下文协作通过领域事件或明确接口完成。
一句总结 :DDD 不再只是架构方法,它也正在成为 AI 时代组织业务上下文的重要方式。
九、DDD 适合与不适合场景
DDD 不是银弹,它是为应对 中大型复杂业务 而设计的工程化架构方案,引入它需要更高的学习成本、更复杂的系统结构以及更严格的工程约束。
9.1 适合场景
- 核心业务逻辑复杂:业务规则多、状态流转复杂(如交易、计费、运营决策、资源管控)。
- 项目生命周期长:系统需要持续维护数年以上,需要抵抗需求变化带来的代码腐化。
- 多团队协作开发:需要通过限界上下文清晰划分业务边界,降低沟通成本与边界冲突。
- 业务具有高差异性:属于公司的核心竞争力(核心域),需要长期沉淀业务能力与模型。
9.2 不适合场景
- 简单 CRUD 项目:大部分逻辑只是数据的增删改查,使用传统 MVC 或 Data-Driven 架构通常效率更高。
- 快速原型(PoC):为了验证想法而快速搭建的项目,DDD 的分层与抽象可能会拖慢开发速度。
- 技术驱动型项目:例如中间件、编译器、存储引擎、性能优化组件等,其复杂度主要来自技术实现,而非业务逻辑。
- 小团队短周期项目:缺少足够的人力与时间维护复杂模型时,直接采用过程式 Service 开发往往更加经济。
十、核心设计准则总结
DDD 的工程理念总结:
- 业务主权:业务建模应当凌驾于技术实现之上。永远不要让数据库 schema 反向定义你的业务模型。
- 内核独立:领域是架构中唯一稳定的资产。确保它被"保护"在层层技术细节之内,不受外壳变迁的影响。
- 价值驱动 :DDD 是一套应对复杂性的方法论。在享受其带来的清晰边界时,必须时刻警惕过度设计的陷阱。只有当业务价值的增益超过架构维护的成本时,DDD 才是架构师的最佳选择。
本文界定了 DDD 的理论底色。接下来,请移步 DDD领域驱动设计应用实践.md,看这些抽象思想如何在真实的代码世界中落地。
代码资源
-
Java 纯净版脚手架 无框架干扰,用于学习理解 DDD 本质结构
-
Spring Boot 4 生产级脚手架 企业级架构实践,开箱即用,用于生产环境【推荐】
-
Go / Gin 生产级脚手架 Go 语言下 DDD 落地示例,快速开发,用于生产环境【推荐】
-
DDD Go语言版 简单纯净教学版
-
DDD Java语言版 简单纯净教学版
-
DDD Springboot框架版 简单纯净教学版
-
AI编程核心知识库 经典设计模式+算法思想代码库【推荐】
参考资源
- Eric Evans,《领域驱动设计:软件核心复杂性应对之道》(2003)------ DDD 的原典(蓝皮书)
- Vaughn Vernon,《实现领域驱动设计》(2013)------ 工程化落地的重要参考(红皮书)
- Vaughn Vernon,《领域驱动设计精粹》(2016)------ 团队入门首选
- Scott Wlaschin,《Domain Modeling Made Functional》(2016)------ 函数式 DDD 经典
- Martin Fowler,《企业应用架构模式》(2002)------ 贫血模型与领域模型概念出处
- Sam Newman,《Building Microservices》(2015)------ 微服务与限界上下文的工程化
- Explicit Architecture herbertograca.com/2017/11/16/...