摘要
本文梳理大数据存储形态、工程架构、数仓分层三大核心体系,解析传统数仓、数据湖、湖仓一体三类存储方案,详解 EDW、Lambda、Kappa、流批一体四大主流架构及其衍生变体,阐释五层数仓分层规范,补充小众落地架构与选型规则,完整呈现大数据架构从理论到生产落地的全体系内容。
一 、 绪论:大数据架构三大核心要素与行业技术演进简史
1.1 三大核心正交概念定义(全文理论基石)
大数据平台由存储形态、工程架构、建模分层 三个正交维度自由组合而成,三者相互独立、无隶属关系,可搭配出业内绝大多数落地方案。
|------------|-------------------------|-------------------|---------------------------------------|
| 分类维度 | 定位描述 | 核心作用 | 落地表现 |
| 存储形态(静态) | 规定数据存储规则、Schema 约束与底层介质 | 划分存储体系,管控数据写入规范 | 决定底层组件选型,区分传统数仓、数据湖、湖仓一体 |
| 工程架构(动态) | 定义数据流走向、实时 / 离线计算拆分逻辑 | 规范 ETL 流水线,划分架构范式 | 决定链路数量与流转模式,匹配计算、消息中间件 |
| 五层建模分层(规范) | 数据从原始到指标的分级加工标准 | 实现数据解耦、故障回溯、指标复用 | 统一采用 ODS/DWD/DWM/DWS/ADS 分层模型,标准化加工口径 |
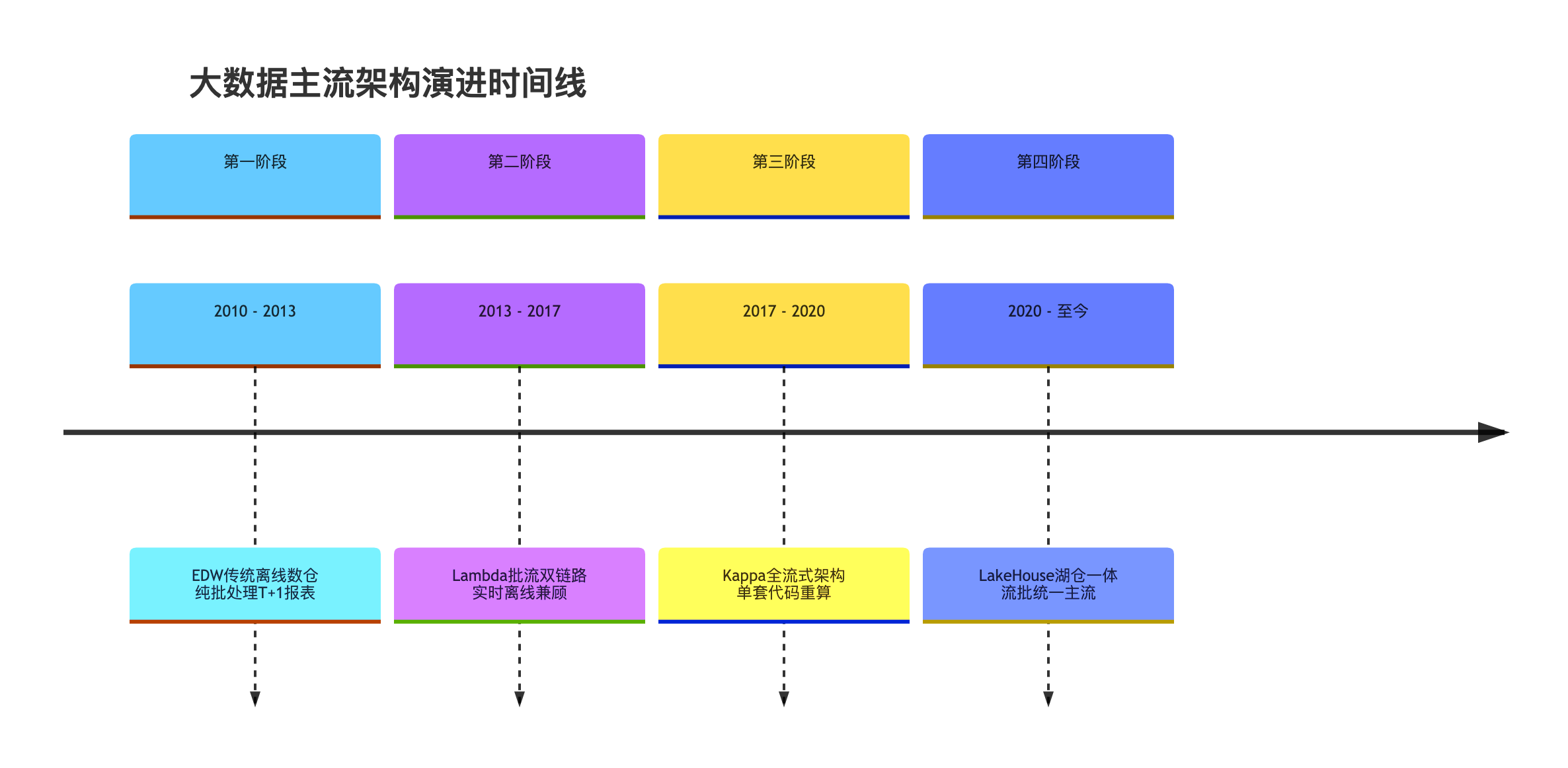
1.2 全球大数据架构技术演进时间线
大数据架构围绕实时性、存储灵活性、口径一致性 持续迭代,四代主流架构演进脉络如下:
- 2010~2013 :EDW 传统离线数仓,纯批处理,主打 T+1 离线报表;
- 2013~2017 :Lambda 批流双链路架构,分离实时、离线链路,兼顾实时查询与历史兜底;
- 2017~2020 :Kappa 全流式架构,单套代码实现全链路计算,依靠消息回放完成数据重算;
- 2020 至今 :湖仓一体架构,流批存储、计算全面统一,成为行业主流落地方案。
二 、 三类数据存储形态
2.1 传统数据仓库 DW(Enterprise Data Warehouse)
2.1.1 核心设计思想
传统数仓诞生面向结构化业务数据,遵循Write-Schema(写入时强制定义表结构) ,在建表阶段固定字段名称、数据类型、主键约束,仅存储经过清洗后的规整结构化数据,按照业务主题建模(如订单主题、商品主题),存储引擎面向批查询优化,不兼容非结构化日志、半结构化 JSON 埋点数据。
2.1.2 主流落地技术栈
- 离线数仓:Apache Hive、Greenplum、Vertica;
- 实时 MPP 数仓:ClickHouse 早期纯仓用法、Druid;
- 底层存储:HDFS、本地机械磁盘。
2.1.3 优势与落地短板
✅优势:数据结构强约束,数据质量可控,SQL 标准化程度高,运维简单,T+1 批量统计稳定性极强;
❌短板:源业务字段变更必须 DDL 改表,无法直接接入非结构化埋点,原始脏数据无法落库,不支持秒级实时写入。
2.1.4 典型落地场景
传统银行财务核算系统、传统零售月度进销存报表系统、无实时需求的后台统计平台。
2.2 独立数据湖 DL(Data Lake)
2.2.1 核心设计思想
数据湖核心是Schema-on-Read(查询时动态解析字段结构) ,底层依托低成本对象存储 / 分布式文件系统,原始数据全量原样落地,不做任何前置清洗与结构约束 ,结构化 MySQL binlog、半结构化 JSON 埋点、非结构化图片 / 日志全部统一归档,查询阶段再通过计算引擎解析数据结构。
2.2.2 主流落地技术栈
底层存储:S3/OSS 对象存储、HDFS;
计算引擎:Spark、Presto;
湖格式原生:Hudi/Iceberg(早期独立数据湖无 ACID,直接存原生文件)。
2.2.3 优势与落地短板
✅优势:兼容全类型异构数据,原始数据永久留存,支持临时自助取数、AI 特征抽取、数据探索;
❌短板:缺少数据分层治理规范,原始数据杂乱无章,直接明细查询 IO 开销极大,无法直接面向业务做高并发指标查询。
2.2.4 典型落地场景
互联网用户行为日志存储、算法特征样本库、企业全源原始数据归档平台。
2.3 湖仓一体 LakeHouse
2.3.1 核心设计思想
融合前两者优势,底层沿用数据湖低成本存储、全源原始落盘能力,上层复用传统数仓 Schema 约束、分层建模规范,依托 Hudi/Iceberg 等 ACID 湖格式打通流批数据读写 :数据写入湖存储时支持动态变更 Schema,同时提供事务、版本回溯能力,一份存储既能被 Flink 实时增量读取,也能被 Spark 批量全量扫描,是当下主流存储方案。
2.3.2 主流落地技术栈
底层:对象存储 + Hudi/Iceberg;计算:Flink+Spark;查询层:ClickHouse/Druid。
2.3.3 优势与落地短板
✅优势:统一存储消除流批数据源割裂,Schema 动态演进兼顾灵活性与规范性,天然支持数据回溯重跑;
❌短板:湖格式学习成本高,小文件治理、元数据管理运维复杂度高于传统数仓。
2.3.4 典型落地场景
中大型电商 CPS 分销、广告投放实时分析、全链路实时 + 离线双需求大数据平台。
2.4 三类存储形态对比
|-----------|--------------------|----------------------------|---------------------|----------------|----------------|------------|----------|
| 存储类型 | Schema 规则 | 可存储数据类型 | 底层存储 | 实时写入能力 | 批处理能力 | 数据回溯能力 | 运维成本 |
| 传统数据仓库 DW | Write-Schema 写入定结构 | 仅结构化清洗数据 | HDFS / 本地磁盘 | 弱,批量导入为主 | 极强 | 差,无原始数据 | 低 |
| 独立数据湖 DL | Read-Schema 读取定结构 | 全类型异构数据(结构化 / 半结构化 / 非结构化) | 对象存储 / HDFS | 弱,文件落地 | 极强 | 优秀(全量原始留存) | 中 |
| 湖仓一体 LH | ACID 动态 Schema 演进 | 明细 + 分层指标全数据 | 对象存储 + Hudi/Iceberg | 极强(Flink 实时写入) | 极强(Spark 全量扫描) | 顶级(版本快照回溯) | 高 |
三 、 四大标准工程架构 及 衍生变体
3.1 EDW 传统离线批处理架构及衍生变体
3.1.1 原生 EDW 架构原理
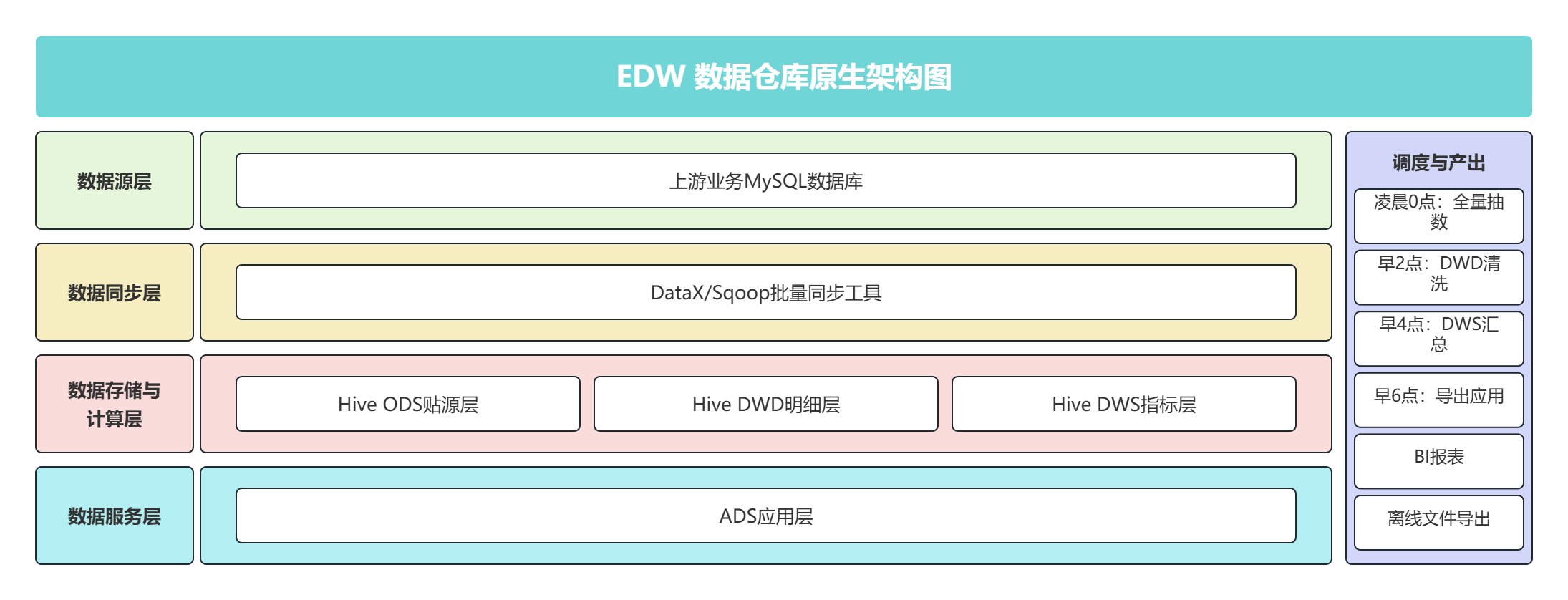
分层拆解 :
- 数据源层 :以上游业务 MySQL 数据库为唯一来源,不支持非结构化日志、第三方 API 等异构数据直接接入;
- 数据同步层 :通过 DataX/Sqoop 批量同步工具,凌晨 0 点定时触发全量抽数 ,将业务库数据批量导入 Hive 数仓,是整个流水线的起点;
- 数据存储与计算层 :EDW 的核心分层,严格遵循 ODS→DWD→DWS 的加工顺序:
- Hive ODS贴源层:原样存储抽取的原始数据,不做任何清洗,和业务库字段 1:1 对齐;
- Hive DWD明细层:凌晨 2 点调度触发,完成脏数据过滤、字段标准化、静态维度关联,生成标准明细宽表;
- Hive DWS指标层:凌晨 4 点调度触发,基于 DWD 明细做业务维度聚合,产出最终统计指标;
4. 数据服务层(ADS) :对接 BI 报表、离线文件导出等应用,不做额外计算,仅提供数据查询与导出能力;
5. 调度与产出层 :整个架构的 "指挥中枢",通过定时任务串联全链路流程,数据流转、计算、产出完全依赖调度周期,无法按需触发。
技术选型考虑要点:
- 强 Schema 约束 :从 ODS 层就固定数据结构,不支持 Schema 动态变更,所有数据必须提前建模,这也是它只能处理结构化业务数据的根本原因;
- 批量计算优先 :整个架构的设计目标是「用最低成本完成全量数据统计」,优先保障离线批处理的稳定性,而非实时性;
- 调度驱动的强依赖 :所有环节都绑定定时调度,数据流转、计算、产出必须按固定时序执行,一旦上游任务延迟,全链路都会阻塞。
3.1.2 EDW 架构两大衍生变体
变体 1:精简轻量化 EDW(中小企业小数据量)
取消独立 Hive 集群,采用单机 / 集群 MPP 数据库(Greenplum/TDSQL)直接承载全链路五层分层,DataX 直抽数据入库,库内存储过程完成分层计算,省去 Hadoop 集群运维成本,适合小型业务。
变体 2:近实时 EDW(准小时级离线)
缩短调度周期从 T+1 改为小时级,每小时触发一次增量抽数与分层计算,数据延迟压缩至 1~3 小时,无流式引擎,仅靠高频定时同步实现近实时,早期小体量实时需求低成本替代方案。
3.1.3 落地实战
每日凌晨 DataX 全量同步订单、商品、渠道三张业务表进入 Hive ODS,依托调度分三段 Hive SQL 完成 DWD→DWS→ADS 分层计算,每日早 7 点财务获取前一日全量佣金结算报表。
ODS→DWD 落地 Hive 示例
sql
-- ODS原始订单表:ods_cps_order(和业务库字段1:1)
CREATE TABLE ods.ods_cps_order(
order_id string comment '订单编号',
user_id string comment '下单用户ID',
channel_id string comment '推广渠道ID',
goods_id string comment '商品SPU',
pay_amount decimal(18,2) comment '实付金额',
create_time string comment '下单时间'
) PARTITIONED BY (dt string);
-- DWD明细宽表:清洗脏数据+关联渠道维度(Hive离线关联静态维度表)
INSERT OVERWRITE TABLE dwd.dwd_cps_order_detail PARTITION(dt='${dt}')
SELECT
order_id,user_id,o.channel_id,goods_id,pay_amount,create_time,c.commission_rate
FROM ods.ods_cps_order o
LEFT JOIN ods.ods_channel_info c ON o.channel_id = c.channel_id
WHERE pay_amount > 0 AND order_id IS NOT NULL; -- 过滤取消订单、空主键脏数据DWS 日度佣金汇总 SQL
sql
INSERT OVERWRITE TABLE dws.dws_channel_day_commission PARTITION(dt='${dt}')
SELECT
channel_id,
count(DISTINCT order_id) as order_cnt,
sum(pay_amount) as total_sales,
sum(pay_amount * commission_rate) as total_commission
FROM dwd.dwd_cps_order_detail
GROUP BY channel_id;3.1.4 本架构五层分层落地规则
全局仅一套完整 ODS→DWD→DWM→DWS→ADS 五层分层,所有分层逻辑全部离线定时调度执行,无任何实时分层链路。
3.2 Lambda 批流双链路架构及衍生落地变体
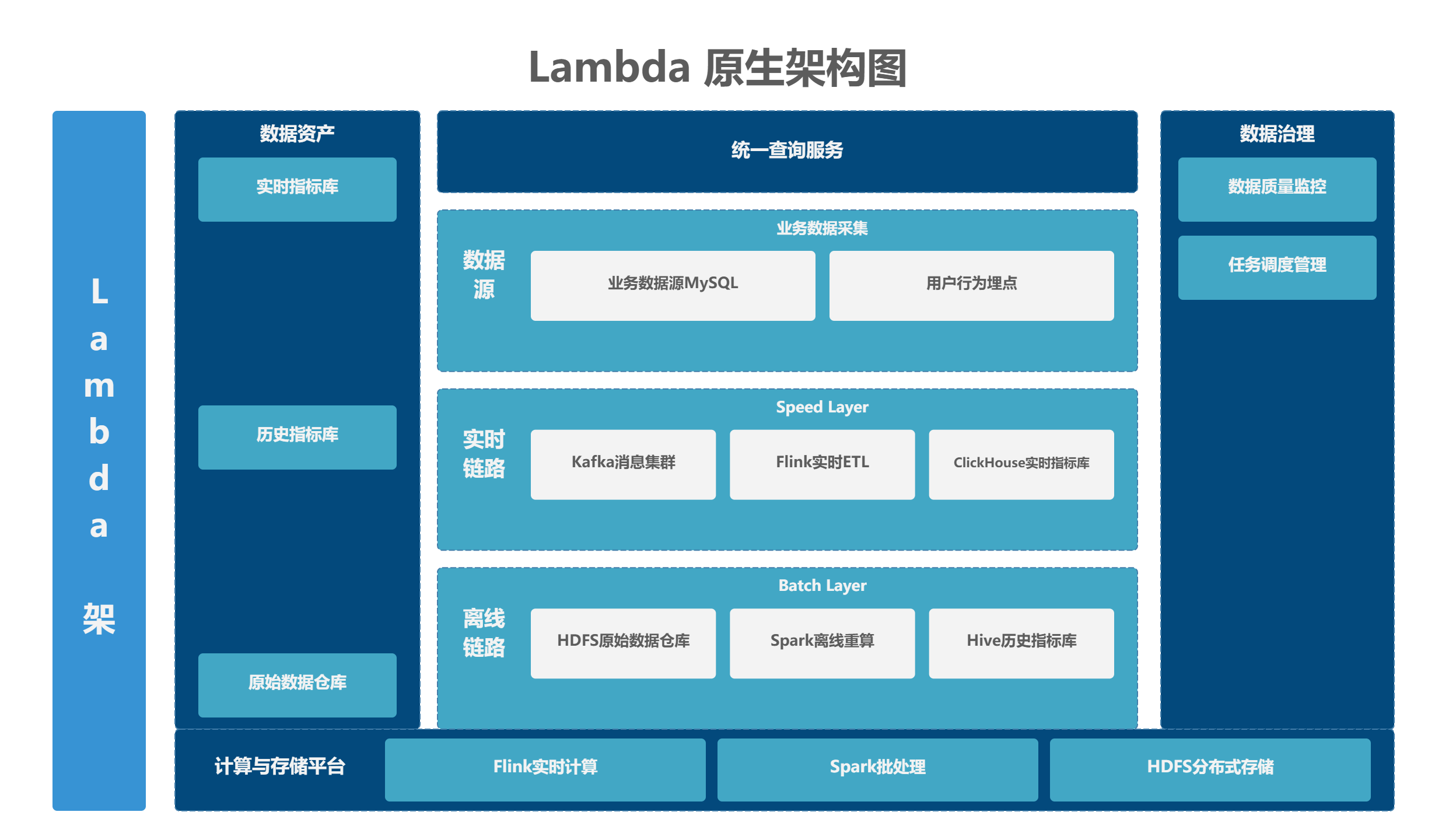
3.2.1 原生 Lambda 架构原理
核心设计:Speed 实时流链路 + Batch 离线批链路 + Serving 结果合并层三层分离 ,同一份业务指标由两套独立 ETL 分别计算:
- Speed 流链路:实时消费消息队列最新增量数据,计算当日实时指标,存入实时 OLAP 引擎(ClickHouse/Druid),支撑前端秒级查询;
- Batch 批链路:每日凌晨全量读取落地 HDFS 的全量历史数据,全量重算自业务上线以来所有历史指标,存入 Hive 数仓,用于修正流链路丢数、数据错乱问题;
- Serving 服务层:接口统一拼接实时当日增量 + 离线全量历史数据,对外统一输出完整指标。
Lambda 原生架构流程图
3.2.2 Lambda 两大主流衍生变体
变体 1:冷热分离精简 Lambda
冷数据(>90 天历史)全量存入 Hive 离线库不再参与实时链路,热数据(近 90 天)实时落 ClickHouse,Serving 查询时分段拼接冷热数据,大幅降低 ClickHouse 存储压力,是国内互联网最常用落地变体。
变体 2:湖仓版 Lambda
批链路数据源不再落地 HDFS,改为直接读取 Hudi 数据湖全量数据,批链路依托湖仓存储替代传统 Hive,保留双链路逻辑但优化底层存储,是 Lambda 向湖仓过渡的中间形态。
3.2. 3 本架构五层分层落地规则
两套独立完整五层分层:Speed 实时链路一套 ODS-DWD-DWS(实时存储 CK);Batch 离线链路另一套 ODS-DWD-DWS(离线存储 Hive),ADS 应用层统一合并两套 DWS 指标对外输出,DWM 层按需在两套链路选择性实现。
3.2.5 Lambda 架构优缺点总结
✅优点:实时链路故障完全由离线批链路兜底,历史数据准确度高,实时与离线需求同时满足;
❌缺点:同一指标两套 ETL 代码,开发、测试、维护成本翻倍,SQL 逻辑极易出现人为不一致。
3.3 Kappa 全流式架构及衍生落地变体
3.3.1 原生全流式Kappa 架构原理
Jay Kreps 提出,彻底删除 Lambda 的 Batch 离线批链路,全量业务数据永久持久化在 Kafka 消息队列 :
- 日常业务:Flink 一套代码实时消费 Kafka 最新消息,全链路实时 ETL 完成 ODS→DWD→DWS 分层,明细与指标落 ClickHouse + 轻量化数据湖;
- 历史重算(原离线批工作):任务故障 / 指标口径变更时,Flink 修改消费 offset 从头回放 Kafka 全量历史消息,复用同一套 ETL 代码重新计算历史数据,实现离线全量重算。
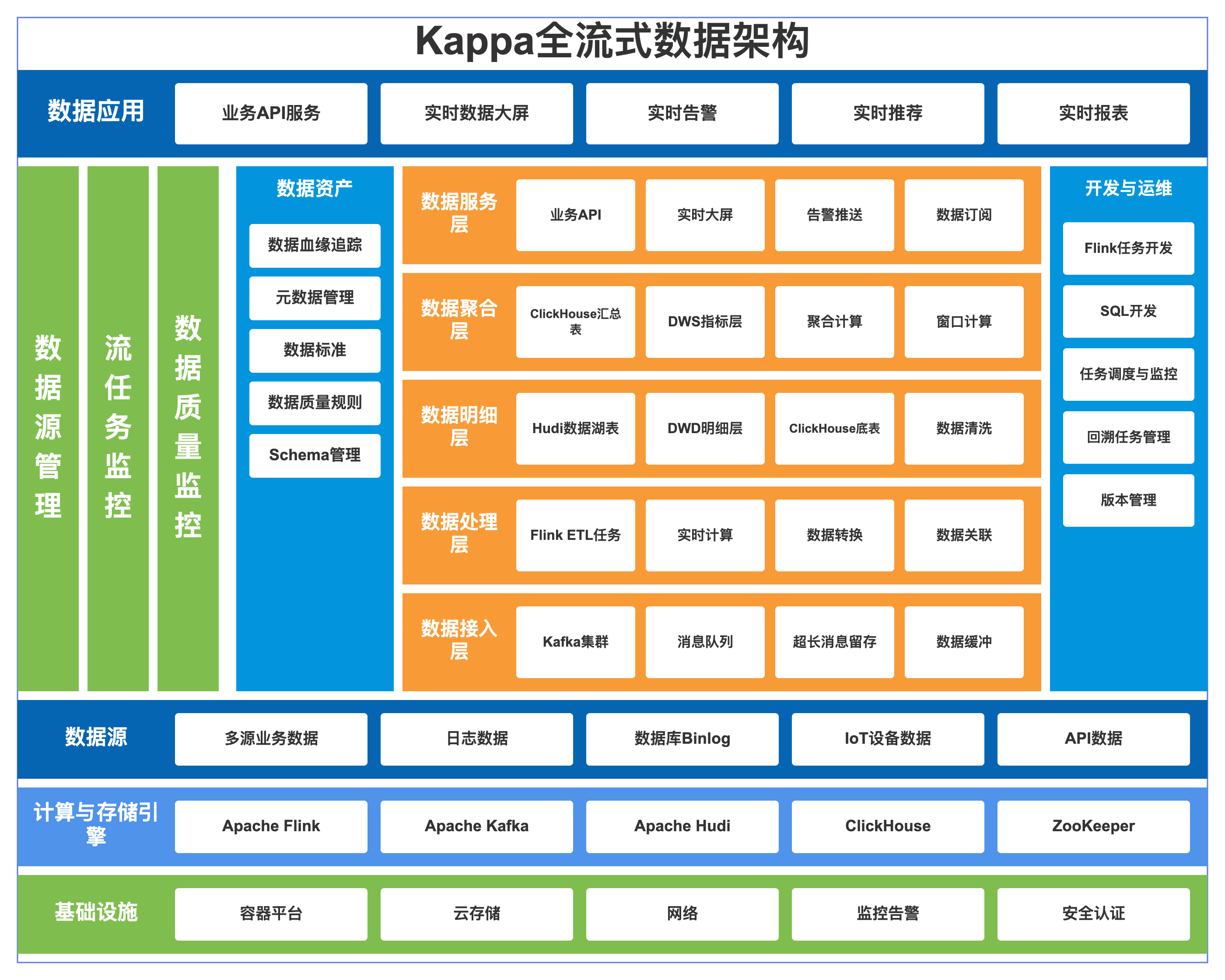
架构全景 :
- 数据接入层(消息队列核心)
所有多源数据(业务库 Binlog、日志、IoT 设备数据)统一写入 Kafka 集群,开启超长消息留存 ,是 Kappa 实现 "一套代码兼顾实时与重算" 的基础;
- 数据处理层(单套流计算引擎)
由 Flink ETL 任务完成全链路数据清洗、转换、关联,仅维护一套流处理逻辑 ,无任何独立的批处理任务;
- 数据明细层(流处理结果落地)
清洗后的明细数据双落地:Hudi 数据湖做永久归档、ClickHouse 底表支撑实时明细查询,为后续聚合与回溯提供基础;
- 数据聚合层(实时指标计算)
基于明细数据做窗口聚合、业务维度汇总,生成 DWS 指标层数据,写入 ClickHouse 汇总表,支撑高并发实时查询;
- 数据应用层(业务出口)
对接业务 API、实时大屏、告警推送等实时场景,不做额外计算;
- 配套支撑体系
数据治理:Schema 管理、数据质量规则,保障流处理数据的规范性;
开发运维:回溯任务管理、任务监控,支撑历史数据重算与故障恢复。
3.3.2 Kappa 两大主流衍生变体
变体 1:轻量化纯 CK-Kappa(小微业务)
取消 Hudi 数据湖,全量明细、指标全部落地 ClickHouse,Kafka 仅保留 7 天消息留存用于短期回溯,超 7 天历史数据直接从 CK 明细重算,极致简化组件,适合日订单量 < 300 万小型 CPS 业务。
变体 2:长存 Kafka + 远端归档 Kappa
Kafka 留存 30 天消息用于短期回溯,超过 30 天数据自动同步至对象存储数据湖,跨年全量历史统计读取远端归档数据,规避 Kafka 磁盘成本过高短板,是中小体量业务主流落地变体。
3.3. 3 本架构五层分层落地规则
全局只存在唯一一套 ODS→DWD→DWM→DWS→ADS 五层分层,日常消费最新消息 = 实时分层计算;回放历史消息 = 离线全量分层重算。
3.3. 4 Kappa 架构优缺点总结
✅优点:单套 ETL 代码,无批代码冗余,彻底消除实时离线口径不一致问题,开发效率提升 50%+;
❌缺点:Kafka 无法永久存储数年全量历史数据,平台跨年全量财务结算时,回放数年消息成本极高,被迫再次升级湖仓一体架构。
3.4 LakeHouse 流批一体湖仓架构及衍生落地变体
3.4.1 原生湖仓架构原理
核心:Kafka 仅做实时数据流缓冲,全量原始明细最终落地 Hudi/Iceberg 湖存储;Flink 引擎原生支持流 / 批双运行模式,同一套 SQL:消费 Kafka = 流任务(实时增量),扫描 Hudi 全量文件 = 批任务(离线全量) ,彻底摆脱 Kafka 存储周期约束,流批共用一份湖数据源,天然统一指标口径。
LakeHouse 流批一体湖仓架构 图
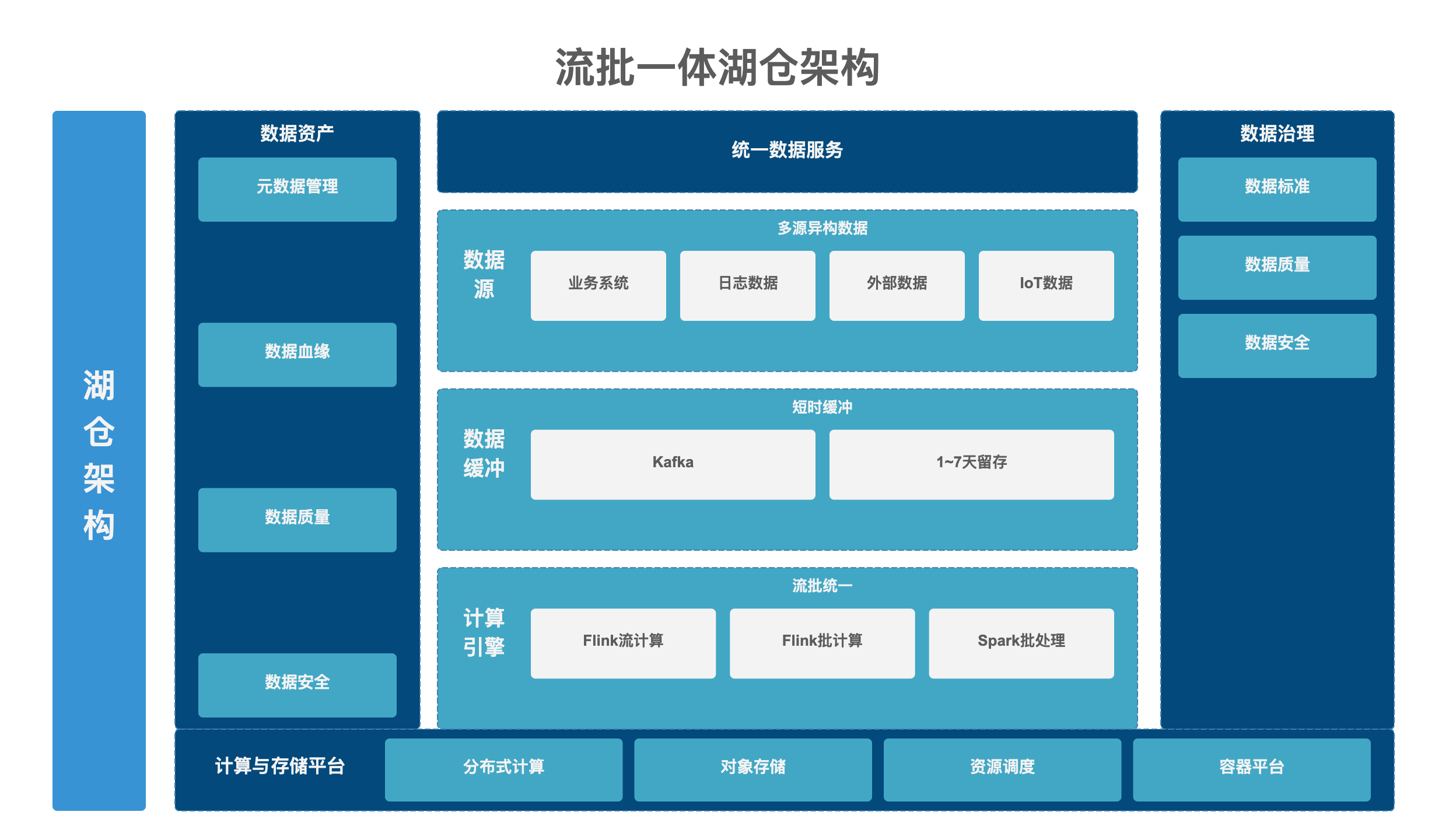
3.4.2 湖仓两大主流衍生变体
变体 1:近实时轻量化湖仓
DWD 明细落 Hudi,DWS 指标直接依托 ClickHouse 物化视图预计算,取消 Flink DWS 实时聚合,靠 CK 物化视图实现分钟级指标刷新,减少 Flink 任务数量,中小业务轻量化落地首选。
变体 2:冷热分层归档湖仓
Hudi 内数据自动冷热分层,近 3 个月热数据存高性能对象存储,超 3 个月冷数据下沉低成本归档存储,自动 TTL 归档,大幅降低存储成本,海量数据标配变体。
3.4. 3 本架构五层分层落地规则
全局唯一一套 ODS→DWD→DWM→DWS→ADS 分层,底层数据统一存在 Hudi 湖,Flink 流运行 = 实时分层增量写入,Flink/Spark 批运行 = 全量分层重算,流批完全共用一套分层表结构。
3.4.5 湖仓架构优缺点总结
✅优点:流批天然同口径、一套代码、历史回溯无需回放消息队列,全场景适配实时 + 离线需求,是中大型企业最优解;
❌缺点:Hudi 小文件治理、元数据管理有运维门槛。
四 、 通用五层 ODS/DWD/DWM/DWS/ADS 数仓分层
4.1 五层分层整体设计思想与全局架构图
五层分层是行业经过十余年落地沉淀的通用建模标准,设计核心:数据逐层加工、职责拆分、故障隔离、指标复用 ,原始数据从 ODS 流入,逐层清洗汇总最终在 ADS 层对接业务,全链路数据权责清晰,新增指标优先复用上层汇总数据,避免重复计算。
五层纵向分层架构图
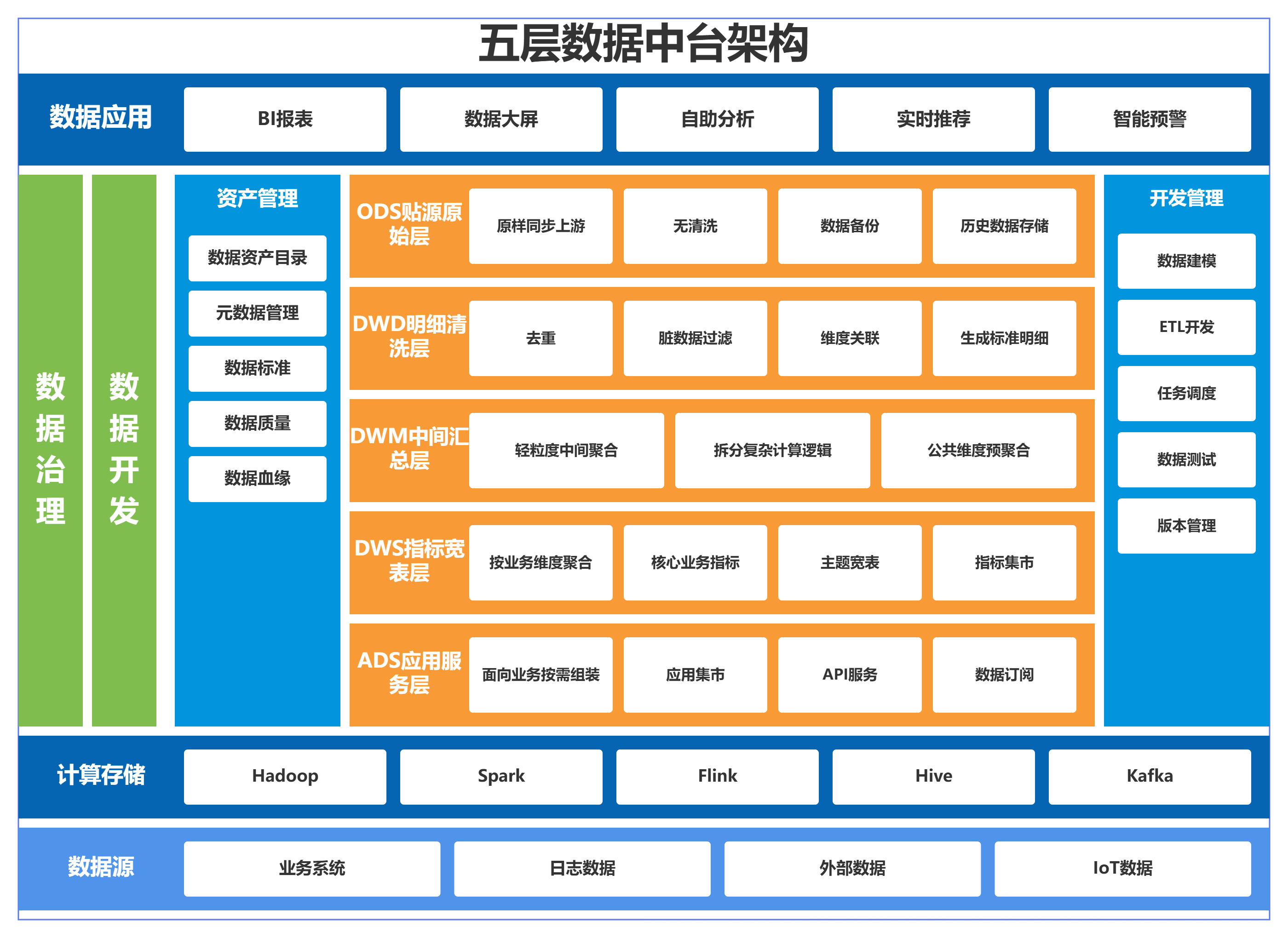
4.2 分 层 解析
4.2.1 ODS|贴源原始层
定位 :1:1 复刻上游业务库 / 埋点原始字段,不做任何字段修改、数据过滤,是全链路唯一原始数据源,兼顾数据湖原始归档功能。
- 数据来源:MySQL Binlog CDC 同步、前端埋点日志、第三方渠道 API 上报数据;
- 落地策略:
- EDW:每日全量批量落地 Hive 分区;
- Lambda:实时进 Kafka,每日全量落 HDFS;
- Kappa:全量数据持续写入 Kafka 长期留存;
- 湖仓:实时缓冲 Kafka,最终全量落地 Hudi 数据湖永久保存;
- 建表规范:字段名、字段类型和源库完全一致,按日期分区。
sql
-- ODS通用建表模板(Hive/CK通用)
CREATE TABLE ods.ods_cps_channel_info(
channel_id STRING COMMENT '渠道唯一ID',
channel_name STRING COMMENT '渠道名称',
commission_ratio DECIMAL(18,4) COMMENT '默认佣金比例',
create_ts DATETIME COMMENT '渠道创建时间'
) PARTITIONED BY (dt STRING);4.2.2 DWD|明细清洗层(全链路核心层)
定位 :ODS 原始数据标准化加工,过滤脏数据、空值、重复数据,关联静态 / 动态维度生成业务标准明细宽表,全链路指标计算的基础数据源。
- 三大核心处理逻辑:
- 脏数据清洗:取消订单、测试数据、空主键、异常超限额金额剔除;
- 静态维度关联(商品类目、渠道信息):Lookup Join+Redis 全量缓存;
- 动态维度关联(用户会员等级、活动价):Flink Interval Join 双流关联 + Watermark 处理乱序;
- 落地策略:
- EDW:离线 Hive 单落地;
- Lambda:实时 DWD 落 CK、离线 DWD 落 Hive 两套明细;
- Kappa / 湖仓:明细双落地(实时 OLAP 引擎 + 底层存储湖);
sql
-- ClickHouse DWD标准建表
CREATE TABLE dwd.dwd_cps_order_detail(
order_id String,user_id String,channel_id String,goods_id String,
pay_amount Decimal(18,2),commission_rate Decimal(18,4),create_time DateTime
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(create_time)
ORDER BY (channel_id,create_time)
TTL create_time + INTERVAL 90 DAY DELETE; -- 90天外冷数据自动清理4.2.3 DWM|中间通用汇总层
定位 :介于 DWD 与 DWS 之间的中间缓冲层,对 DWD 明细做小粒度轻度聚合,拆分复杂多维度交叉计算,DWS 层直接复用 DWM 汇总结果,避免反复扫描海量 DWD 明细。
落地场景示例:按「商品 ID + 渠道 ID + 小时」汇总中间销售数据,后续 DWS 算全渠道、全商品指标直接复用该中间表。
落地灵活度:轻量化小业务可省略 DWM 层,直接 DWD→DWS;中大型多维度业务必须落地 DWM。
4.2.4 DWS|指标宽表层(业务聚合层)
定位 :面向业务运营维度(渠道 / 商品 / 日期)聚合最终业务指标,分Flink 实时窗口聚合、CK 物化视图预聚合 双计算模式,是对接业务的核心指标层。
- 高频秒级指标(实时佣金、实时订单量):Flink 1min 滚动窗口实时聚合写入 CK;
- 低频多维度交叉指标(渠道 + 类目 + 会员等级佣金):依托 DWD 明细底表创建 CK 物化视图自动预计算;
4.2.5 ADS|应用输出层
定位 :最上层应用适配层,不做大规模聚合计算,仅按需筛选 DWS 指标、字段重组,对接不同业务终端,分为实时 ADS、离线 ADS 两类:
- 实时 ADS:推广员 H5 佣金查询、运营实时大屏(JDBC/HTTP API 直连 CK);
- 离线 ADS:财务月度佣金结算 Excel、季度渠道复盘报表(Spark 导出文件)。
4.3 工程化价值与避坑要点
4.3.1 工程价值
- 故障可回溯 :ODS 全量原始数据永久留存,任何指标出错可从源头重跑全链路;
- 需求快速迭代 :新增业务指标优先复用 DWS/DWM 已有汇总数据,无需重复扫描明细;
- 数据口径统一 :全业务指标基于同一套 DWD 明细,从源头约束计算标准。
4.3.2 落地避坑要点
- ODS 禁止业务加工,一旦 ODS 改动字段,全链路分层全部受影响;
- DWD 杜绝业务指标聚合,仅保留明细清洗与维度关联,聚合逻辑下沉 DWM/DWS;
- ADS 禁止跨层直接读取 DWD 明细,防止上层业务查询击穿底层存储。
五 、 行业小众衍生落地架构补充
除四大主流架构及衍生变体,行业三类小众落地架构为特定场景定制。
5.1 OLAP 直算轻量化架构
取消中间分层存储,业务 CDC 数据直接写入 ClickHouse,所有明细与指标全部依靠 CK 原生 SQL + 物化视图计算,无 Flink 实时聚合任务,极致精简组件。
5.2 混合湖仓 Lambda 架构
底层全量数据落 Hudi 数据湖,保留 Lambda 双链路思想,但批链路不再独立存储 Hive,批链路直接读取 Hudi 全量数据重算,实时链路消费 Kafka 落 CK,属于 Lambda 向湖仓过渡折中方案。
5.3 Serverless 云原生大数据架构
全链路 Flink、Spark 采用云原生 Serverless 按需弹性计费,无常驻集群,任务运行自动申请资源、结束自动释放,适合阶段性临时大数据统计需求,节约集群闲置成本。
六、 核心复习要点
1. 三大核心维度
存储形态、工程架构、五层分层为三大正交体系,可自由组合;五层分层为全架构通用规范。
2. 架构演进脉络
EDW 离线 → Lambda 批流双链路 → Kappa 全流式 → 湖仓一体(主流)。
3. 三类存储区分
- 传统数仓:写入定结构,主打批处理
- 数据湖:读取定结构,兼容全量异构数据
- 湖仓一体:动态 Schema,流批能力兼备,运维复杂度最高
4. 四大工程架构核心
- EDW :单套离线分层,延迟高,无实时能力
- Lambda :两套分层、双代码,易出现口径偏差
- Kappa :单套代码,依赖消息回放,长期重算成本高
- 湖仓一体 :流批共用一套分层与代码,当前最优方案
5. 五层分层核心职责
ODS 存原始数据 → DWD 清洗关联 → DWM 拆分计算(可省略)→ DWS 聚合指标 → ADS 对接应用;分层职责严格隔离,禁止跨层查询。
📚 我的技术博客导航:点击进入一站式查看所有干货