JiuwenSwarm 基于 openJiuwen 框架构建了 HITS(Human-in-the-Swarm)人机协同模式:人类以团队成员身份入局,与 AI Agent 同队协作、实时交互。这是 openJiuwen 提出的 Coordination Engineering(协同工程)范式在人机协作方向上的落地------让人的判断出现在最需要的时刻。本文深入解析 HITS 的角色边界、任务分配逻辑、人机消息流转机制与场景适配策略。
一、为什么需要 Human-in-the-Swarm
先想一个场景:你让三个 AI Agent 并行调研三个方向,它们各干各的、互不干扰。但如果在调研过程中,某个方向需要你亲自拍板------比如涉及到商业判断、品牌调性审核、或者法律合规的边界问题------你怎么办?
传统的做法是"人在外面等"。Agent 跑完了,你审一遍结果,发现问题再让它改。这个循环可能来回好几轮。更麻烦的是,Agent 做了一些它自己拿不准的决策,但它不会主动问你,因为它不知道你需要介入。
这就是 HITS 要解决的核心问题:让人在需要的时候,以团队成员的身份直接参与协作,而不是站在外面当评审员。
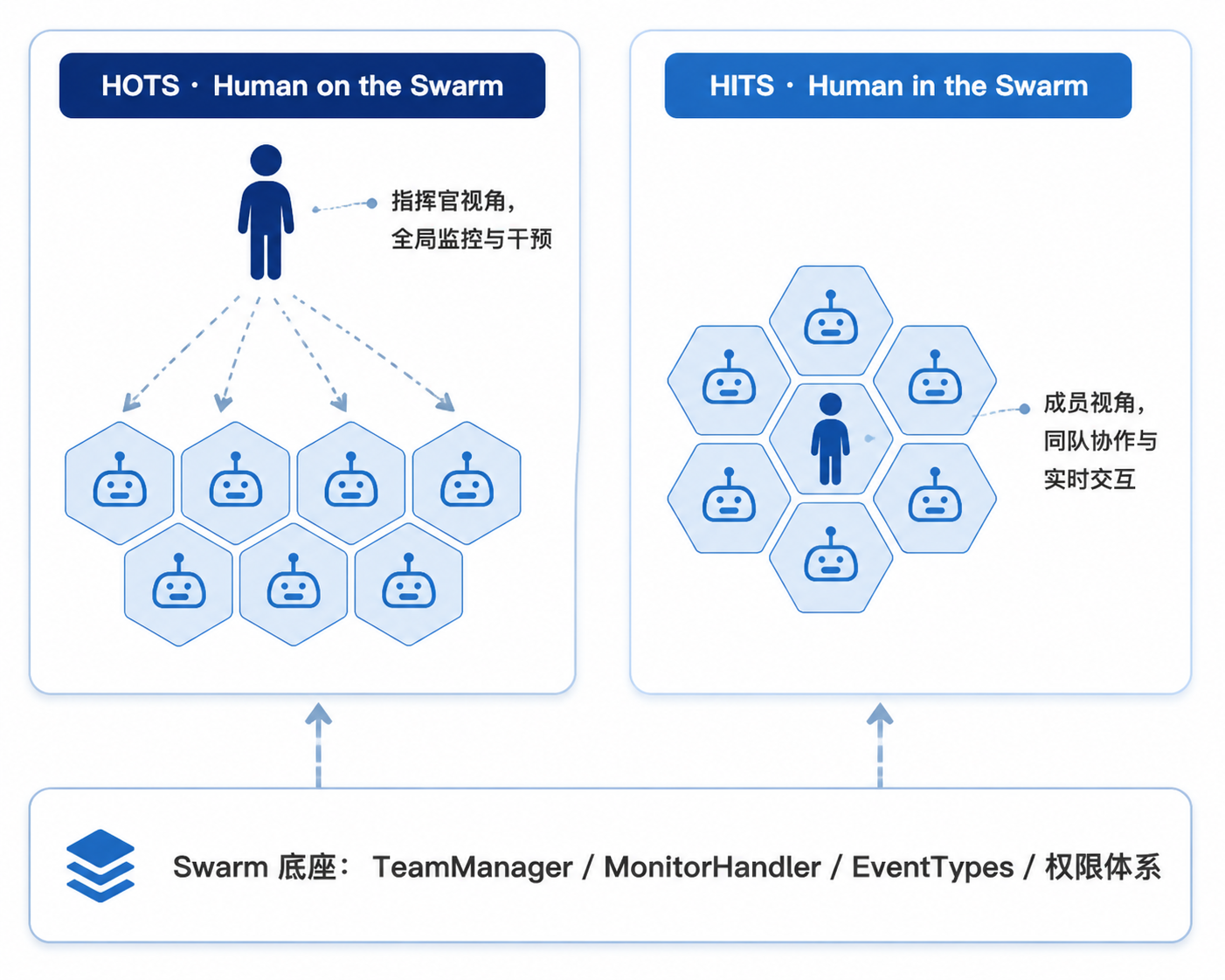
JiuwenSwarm 给出了两种模式。第一种叫 HOTS(Human on the Swarm),人站在更高的位置上,实时观察整个 Agent 团队的运行状态------任务进展、角色负载、协作瓶颈,需要介入时随时下场:调整任务优先级、切换 Agent 角色、中途变更方案,指挥粒度可细到单条指令,也可粗到一句"换个方向"。第二种叫 HITS(Human in the Swarm),人不再是场外指挥,而是和 Agent 同队、同场景、同流程、实时协作、共同推演------人,就是蜂群里的一只"蜂",与其他 Agent 共同协作。
举个直观的例子。狼人杀游戏里,你可以开上帝视角操控全局,这是 HOTS;也可以亲自下场当狼人、预言家或普通村民,和 AI 队友一起讨论、投票、发言、伪装、带节奏,这是 HITS。其他 Agent 会读你的发言、推理你的身份、决定要不要"带飞"你或"票"你。
这个设计最关键的一点在于:两种模式共用同一套 Swarm 底座,同一份基础设施就能支撑完全不同的交互形态。 HITS 是沉浸式参与,HOTS 是全局调度------两种模式是人与 Agent 团队协作的两种最核心姿态,两种姿态随时切换。
运行环境
|----------|------------------------------------------------------------------|
| 项目 | 配置值 |
| 操作系统 | Windows 10 / macOS / Linux |
| Python | 3.11 / 3.12 / 3.13 |
| 模型服务 | 华为云 MaaS / OpenAI 兼容接口 / ModelScope 等 |
| 通信渠道 | Web / 飞书 / 钉钉 / 企业微信 / 小艺 / Telegram / Discord / WhatsApp / 个人微信 |
| Agent 框架 | openJiuwen(内置) |
架构总览
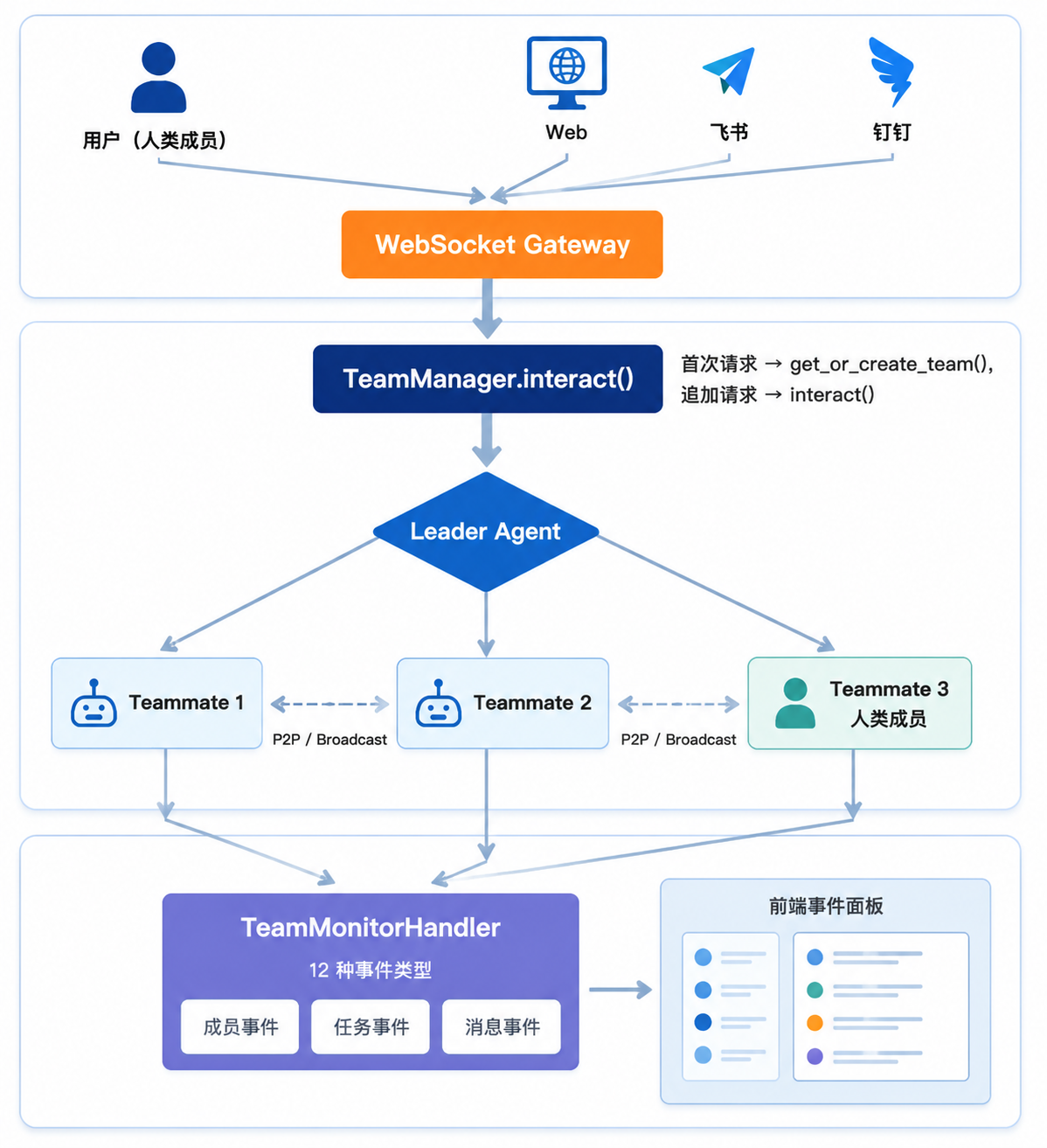
HITS 并非独立于 Swarm Agent 之外的模块,而是运行在现有团队协作架构之上的一种参与模式。整个技术底座包括:
|------------------------|---------------|--------------------------|
| 组件 | 职责 | HITS 中的作用 |
| TeamManager | 团队生命周期管理 | 管理人类成员与 AI 成员共同所在的团队 |
| ConfigLoader | 团队配置加载 | 加载 enable_hitt 标志与角色配置 |
| TeamMonitorHandler | 实时事件监控 | 人类可观测的任务/成员/消息事件流 |
| TeamRuntimeInheritance | 技能继承与 Rail 构建 | 为人类成员适配角色边界 |
| EventTypes | 12 种事件类型定义 | 覆盖人类参与的成员事件与消息事件 |
| LLMLimiter | LLM 并发限流 | 人机混编时的资源协调 |
| DistributedRuntime | 分布式运行时 | 支持人类从不同节点加入团队 |
消息从用户到团队的数据流:
二、HITS 的角色边界:人不是全能的
人进入团队后,第一个要回答的问题是:人扮演什么角色?拥有什么权限?能做什么、不能做什么?
如果不加约束,人类成员要么变成"什么都干的超人",要么变成"什么都问的传声筒"------两种极端都会拖垮团队效率。JiuwenSwarm 的做法是把五层角色边界体系直接复用到人类成员身上,和 AI Teammate 一视同仁。
2.1 五层边界对人类成员的适用
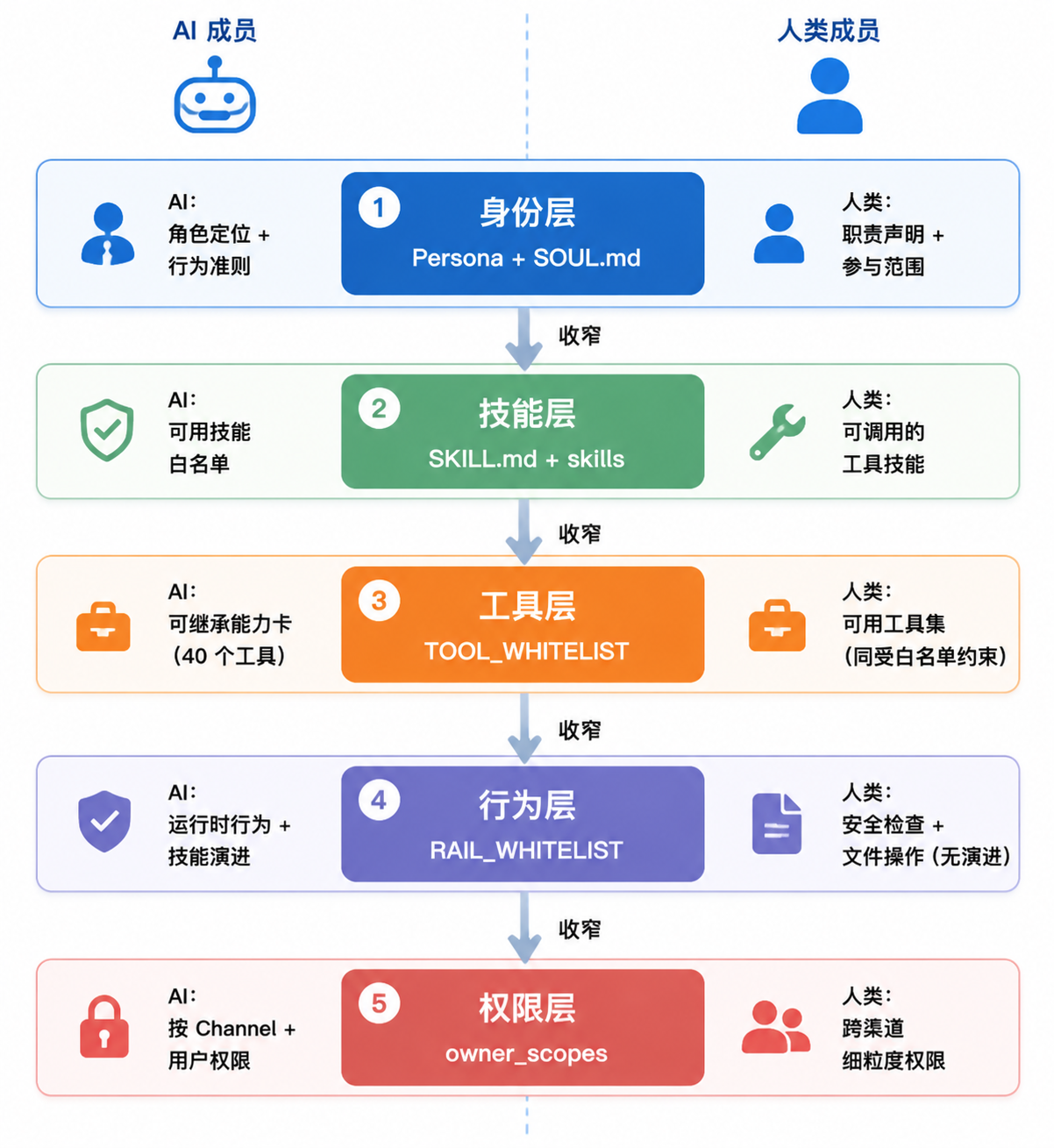
五层边界体系最初是为约束 AI Teammate 设计的(详见《Teammate 不是工具------角色边界设计与能力隔离方案》),但它的设计逻辑天然适用于人类成员:
|-----|--------------------------|--------------|---------------|
| 层级 | 机制 | 对 AI 的约束 | 对人类成员的约束 |
| 身份层 | Persona + SOUL.md | 限定角色定位和行为准则 | 限定人类在团队中的职责声明 |
| 技能层 | SKILL.md + skills 配置 | 白名单控制可用技能 | 人类可调用的技能工具范围 |
| 工具层 | TOOL_WHITELIST | 可继承的工具能力卡 | 人类可使用的工具集 |
| 行为层 | RAIL_WHITELIST + Rail 钩子 | 运行时行为约束 | 人类操作的审计与约束 |
| 权限层 | owner_scopes | 按渠道和用户的细粒度权限 | 人类成员的跨渠道权限 |
核心思想是:人在团队中的角色不是"什么都能做的管理员",而是一个有明确职责边界的协作成员。 和 AI Teammate 的区别只在于执行主体------AI 靠 LLM 驱动,人类靠自己的判断和操作。
2.2 身份层:人的 Persona 怎么定
人类成员的身份定义和 AI Teammate 使用相同的配置结构。在 predefined_members 中声明一个人类角色:
team:
predefined_members:
- member_name: "human_reviewer"
display_name: "评审员(人类)"
persona: >
你是团队中的评审员,负责对 AI 生成的内容进行最终审核和决策。
你的能力范围:审核报告质量、做出商业判断、确认合规性。
你不负责数据采集、报告撰写、文件整理。
遇到需要你决策的问题时,Leader 会将相关材料转发给你。persona 不仅是给 LLM 看的系统提示词,也是对人类成员的"职责合同"------明确告诉你在这个团队里负责什么、不负责什么。这避免了人类成员"什么都想管"或者"不知道该管什么"的混乱。
2.3 技能层与工具层:人能用什么工具
在 HITS 模式下,人类成员通过聊天界面与团队交互。人类成员可调用的工具集受 TOOL_WHITELIST 约束:
# team_runtime_inheritance.py
TOOL_WHITELIST = frozenset({
# 搜索与网页
"free_search", "fetch_webpage", "paid_search", "search_skill",
# 多模态
"vision", "audio", "image_ocr", "visual_question_answering",
"generate_image", "audio_transcription", "audio_question_answering",
"audio_metadata", "video_understanding", "image_reading",
# 技能管理
"install_skill", "uninstall_skill",
# 任务与待办
"task_tool", "user_todos",
# 个人信息
"get_user_location", "create_note", "search_notes", "modify_note",
"create_calendar_event", "search_calendar_event",
# 通讯录与媒体
"search_contact", "search_photo_gallery", "upload_photo",
"search_file", "upload_file",
# 通讯
"call_phone", "send_message", "search_message",
# 闹钟
"create_alarm", "search_alarms", "modify_alarm", "delete_alarm",
# 平台专属
"xiaoyi_collection", "xiaoyi_gui_agent",
})白名单共 40 个工具。人类成员在聊天界面中可以触发这些工具------比如搜索、读取文件、发送消息等。不在白名单中的工具,人类成员同样无法调用。这是"新增能力需要显式授权"原则在人机混编场景的体现。
技能继承同样遵循白名单逻辑。如果人类角色在配置中指定了 skills 列表,只复制指定的技能;否则继承全部:
# team_manager.py copy_member_configured_skills()
def copy_member_configured_skills(
member_skills_dir: Path,
selected_skills: list[str],
) -> None:
selected_skill_set = set(selected_skills)
for skill_dir in global_skills_dir.iterdir():
if not (skill_dir / "SKILL.md").is_file():
continue
if skill_dir.name not in selected_skill_set:
continue
dest = member_skills_dir / skill_dir.name
if not dest.exists():
shutil.copytree(skill_dir, dest)2.4 行为层:Rail 对人类成员的约束
Rail 钩子机制在运行时对行为做约束。人类成员和 AI Teammate 加载不同的 Rail 集合:
# team_runtime_inheritance.py build_member_rails()
RAIL_WHITELIST = frozenset({
"RuntimePromptRail", # 运行时上下文注入
"ResponsePromptRail", # 响应前处理
"JiuClawStreamEventRail", # 流式事件处理
"TaskPlanningRail", # 任务规划
"SecurityRail", # 安全检查
"HeartbeatRail", # 心跳检测
"AvatarPromptRail", # 头像提示
"FileSystemRail", # 文件系统操作
"TeamSkillEvolutionRail", # 团队技能演进管理(Leader 专用)
"TeamSkillCreateRail", # 团队技能创建(Leader 专用)
"SkillEvolutionRail", # 技能自演进(Teammate 专用)
"TeamWorkspaceReportPathRail", # 团队工作空间报告路径
})|-----------------------------|----------|----------------|
| Rail | 作用 | 人类成员是否加载 |
| RuntimePromptRail | 运行时上下文注入 | 是 |
| ResponsePromptRail | 响应前处理 | 是 |
| SecurityRail | 安全检查 | 是 |
| HeartbeatRail | 心跳检测 | 是 |
| FileSystemRail | 文件操作 | 是 |
| TeamWorkspaceReportPathRail | 工作空间路径 | 是 |
| TeamSkillEvolutionRail | 团队技能演进 | 否(Leader 专用) |
| SkillEvolutionRail | 技能自演进 | 否(Teammate 专用) |
人类成员不参与技能演进相关的 Rail------这很合理,人类不需要自动优化自己的 Skill。但安全检查、文件操作、任务规划这些通用 Rail 对人类成员同样生效。
2.5 权限层:owner_scopes 的细粒度控制
权限层在 HITS 场景中尤为重要。当人类成员通过不同渠道(飞书、Web、钉钉等)加入团队时,owner_scopes 按 Channel + 用户维度控制权限:
permissions:
owner_scopes:
feishu:
"ou_xxxx":
defaults:
"*": "allow"
tools:
bash:
"*": "deny"
patterns:
"git status *": "allow"
"git log *": "allow"
write:
"*": "deny"
deny_guidance_message: "该工具未被授权在数字分身模式下使用。"权限有三个级别:
|---------|----|------------|
| 级别 | 含义 | 对人类成员的行为 |
| allow | 允许 | 直接执行 |
| deny | 拒绝 | 不执行,返回拒绝消息 |
| ask | 询问 | 暂停执行,等待确认 |
五层边界从内到外形成完整的隔离链------身份限定意图、技能限定能力、工具限定手段、Rail 限定行为、权限限定触达。人类成员在这套体系中和 AI Teammate 接受相同的约束规则,没有人享有"超级权限"。
三、任务分配逻辑:人入群后怎么分工
人类成员加入团队后,任务分配的逻辑需要考虑"哪些任务适合人做、哪些适合 AI 做"。
3.1 Leader 的调度策略
在 JiuwenSwarm 的 Swarm Agent 架构中,Leader Agent 负责任务分解和调度。当团队中存在人类成员时,Leader 的调度逻辑需要识别任务的性质:
原则一:AI 擅长的归 AI,人擅长的归人。
Leader 在分解任务时,会根据 predefined_members 中各成员的 persona 和 skills 配置来分配任务。人类成员的 persona 中写明了职责范围,Leader 据此判断哪些子任务应该分配给人类。
team:
predefined_members:
# AI 成员
- member_name: "data_analyst"
display_name: "数据分析师"
persona: "擅长数据清洗、统计分析和可视化"
- member_name: "doc_writer"
display_name: "文档编写员"
persona: "擅长技术文档、报告和公文撰写"
# 人类成员
- member_name: "human_reviewer"
display_name: "评审员(人类)"
persona: >
负责对 AI 生成的内容进行最终审核和商业决策。
擅长判断品牌调性、合规风险、商业策略。Leader 看到这段配置后,任务分配自然形成:
- 数据清洗 →
data_analyst(AI) - 报告撰写 →
doc_writer(AI) - 最终审核 →
human_reviewer(人类)
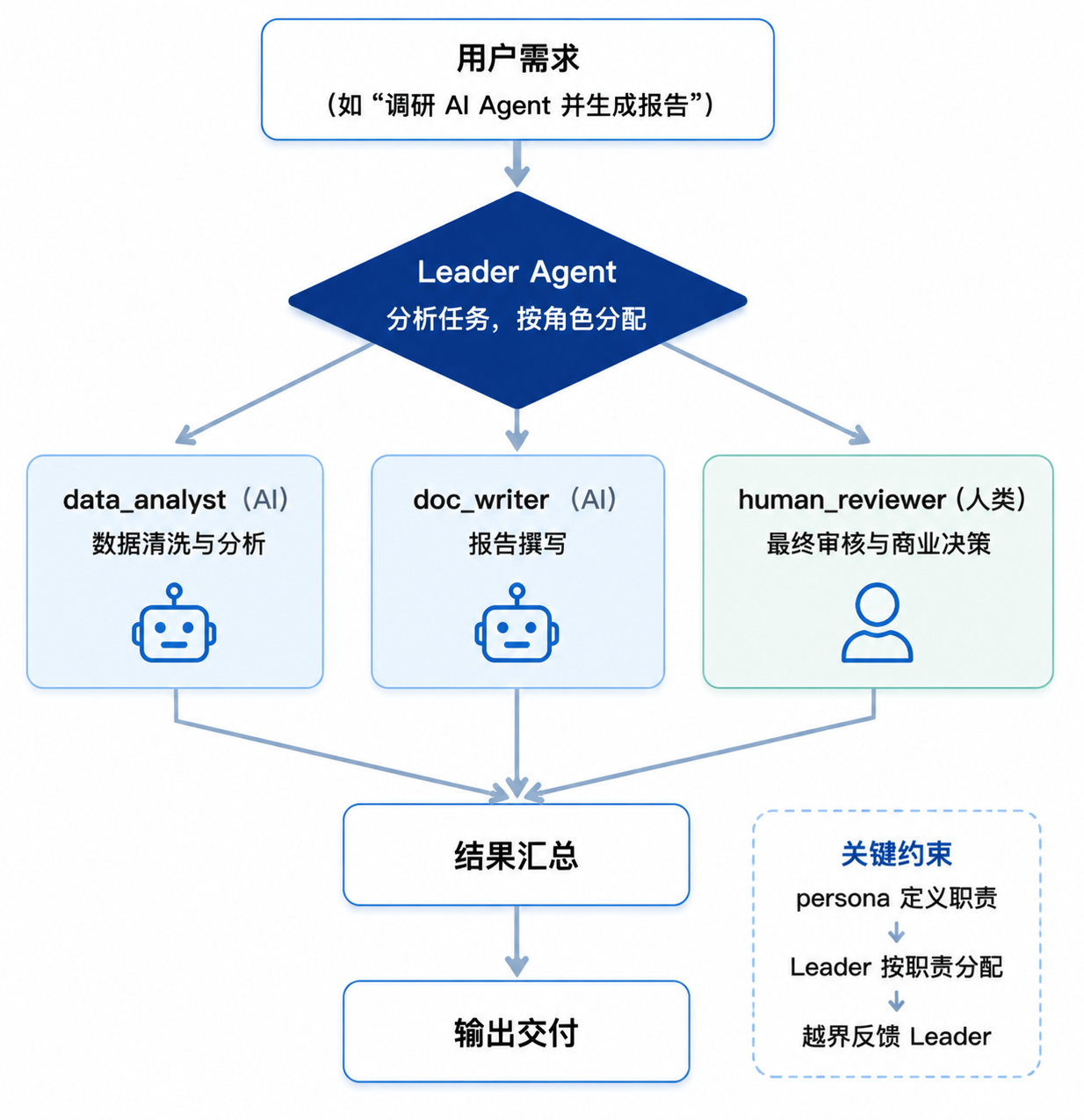
原则二:人类成员不需要排队。
在传统的人机协作中,人通常是"审核者"------AI 做完,人审一遍。HITS 模式打破了这种串行模式。人类成员和 AI Teammate 处于同一层级,可以在团队执行过程中随时介入:
# team_helpers.py process_team_message_stream()
if is_first_request:
team_agent = await team_manager.get_or_create_team(...)
stream_task = asyncio.create_task(
_consume_stream_with_query(channel_id, session_id, team_agent, query)
)
else:
await team_manager.interact(session_id, query) # 追加交互人类成员在执行过程中发送的消息通过 team_manager.interact() 注入正在运行的 TeamAgent,Leader 收到后可以即时响应------重新分配任务、调整优先级、或者将相关材料转发给人类成员审核。
原则三:越界时反馈而非沉默。
当人类成员收到超出自己职责范围的指令时,和 AI Teammate 的行为一致------向 Leader 反馈而不是自行处理:
# 人类成员 persona 中的反向约束
persona: >
你不负责数据采集、报告撰写、文件整理。
收到非审核类的请求时,向 Leader 反馈,不要自行处理。这确保了任务不会因为人类成员的"好心帮忙"而打乱团队的分工秩序。
3.2 enable_hitt 配置标志
HITS 模式在配置层面由 enable_hitt 标志控制。这个标志在 ConfigLoader 中加载:
# config_loader.py
spec_dict["enable_hitt"] = team_raw.get("enable_hitt", True)关键设计:enable_hitt** 默认值为 **True,意味着 HITS 模式默认开启。只有在配置中显式设置 enable_hitt: false 才会关闭:
team:
enable_hitt: false # 显式关闭 HITS测试覆盖验证了两种情况:
# test_team_config_loader.py
def test_load_team_spec_dict_defaults_enable_hitt_to_true():
"""验证 enable_hitt 默认为 True"""
result = load_team_spec_dict(config)
assert result["enable_hitt"] is True
def test_load_team_spec_dict_preserves_explicit_enable_hitt_false():
"""验证显式设置 False 被保留"""
config["modes"]["team"][team_name]["enable_hitt"] = False
result = load_team_spec_dict(config)
assert result["enable_hitt"] is False默认开启的设计反映了 JiuwenSwarm 的理念:人机协作是默认形态,而不是需要额外启用的特殊功能。 只有在明确不需要人类参与的纯自动化场景下,才需要关闭它。
3.3 并发协调:LLMLimiter 在人机混编中的作用
当人类成员和多个 AI Teammate 同时工作时,LLM API 的并发压力会更大。LLMLimiter 通过信号量控制并发:
# llm_limiter.py install_llm_limiter()
_semaphore = asyncio.Semaphore(max_concurrency) # 默认 max_concurrency=2
@wraps(_original_create)
async def _limited_create(self, *args, **kwargs):
async with _semaphore:
for attempt in range(_MAX_RETRIES):
try:
return await _original_create(self, *args, **kwargs)
except Exception as e:
is_429 = "429" in str(e) or "rate" in str(e).lower()
if not is_429 or attempt == _MAX_RETRIES - 1:
raise
delay = _BASE_DELAY * (2 ** attempt)
await asyncio.sleep(delay)在 HITS 场景中,LLMLimiter 的作用尤为关键------人类成员的介入可能触发 AI Teammate 的连锁推理(比如人类提出了一个新问题,多个 AI 成员同时响应),此时并发控制确保不会因为 API 限流导致整个团队停摆。
四、人机消息流转机制
4.1 消息协议与事件类型
HITS 模式下的人机消息流转建立在 12 种事件类型之上,分三类:
成员事件(team.member):
|--------------------------|----------|-------------|
| 事件类型 | 说明 | 人类成员相关场景 |
| MEMBER_SPAWNED | 新成员被创建 | 人类成员加入团队 |
| MEMBER_STATUS_CHANGED | 成员状态变更 | 人类成员状态更新 |
| MEMBER_EXECUTION_CHANGED | 成员执行状态变更 | 人类成员正在审核/决策 |
| MEMBER_RESTARTED | 成员被重启 | --- |
| MEMBER_SHUTDOWN | 成员被关闭 | 人类成员离线 |
任务事件(team.task):
|----------------|-----------|-------------------|
| 事件类型 | 说明 | 人类成员相关场景 |
| TASK_CREATED | 新任务被创建 | Leader 分配审核任务给人类 |
| TASK_CLAIMED | 任务被某个成员认领 | 人类成员认领审核任务 |
| TASK_COMPLETED | 任务完成 | 人类成员完成审核 |
| TASK_CANCELLED | 任务被取消 | --- |
| TASK_UNBLOCKED | 任务解除阻塞 | 人类成员的决策解除了其他任务的阻塞 |
消息事件(team.message):
|-------------------|----------|--------------------|
| 事件类型 | 说明 | 人类成员相关场景 |
| MESSAGE_P2P | 成员间点对点消息 | Leader 向人类成员发送审核请求 |
| MESSAGE_BROADCAST | 广播消息 | Leader 向全团队广播进展更新 |
4.2 消息流转的完整路径
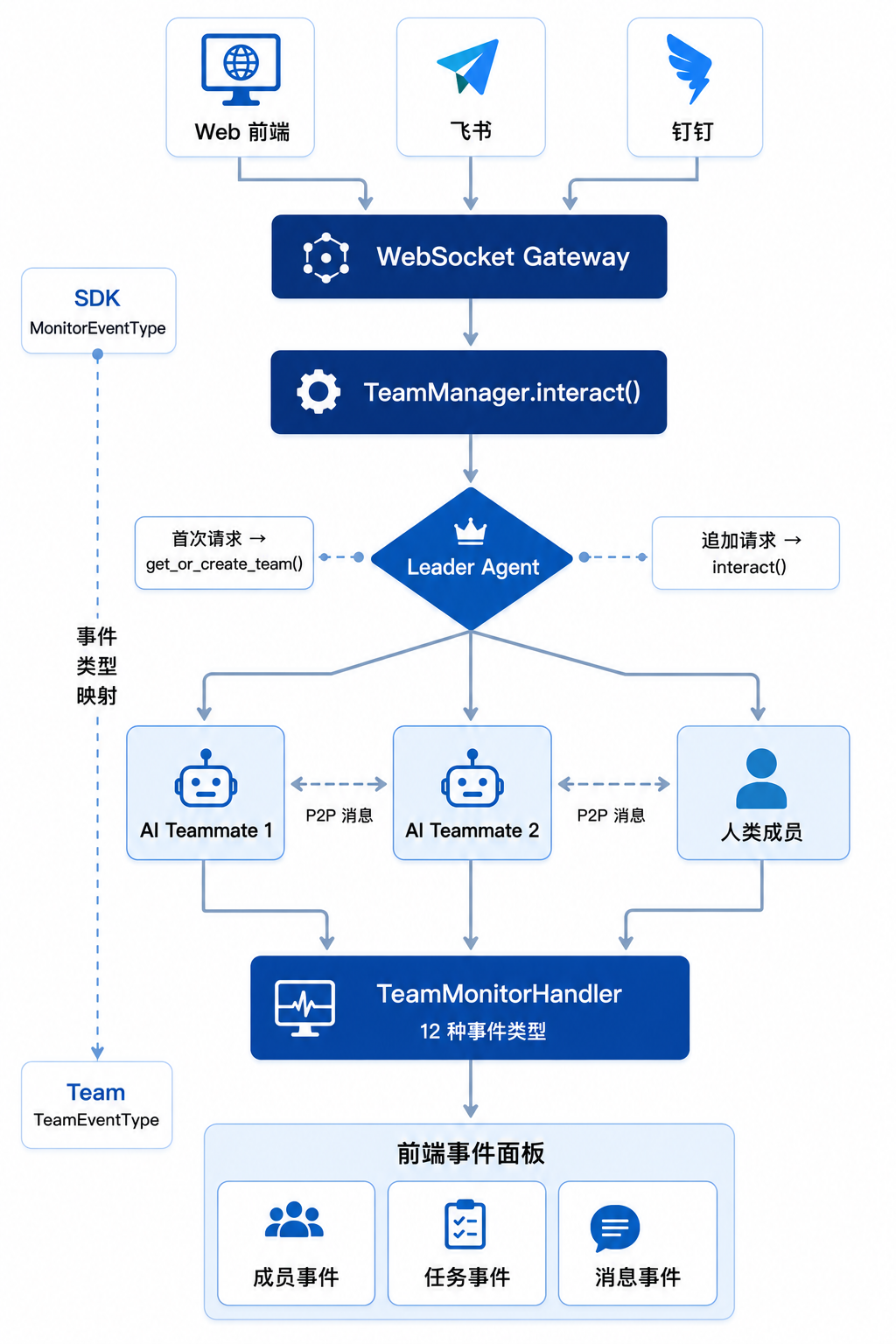
消息在人类成员和 AI 成员之间的流转路径如下:
1. 人类成员通过聊天界面发送消息
↓
2. WebSocket Gateway 接收,路由到 TeamManager
↓
3. TeamManager.interact() 将消息注入 TeamAgent
↓
4. Leader Agent 接收消息,判断目标成员
↓
5. Leader 通过 MESSAGE_P2P 发送给指定 Teammate(AI 或人类)
↓
6. 目标成员处理并返回结果
↓
7. TeamMonitorHandler 捕获事件,转换为前端格式
↓
8. 前端事件面板实时展示前端的消息展示逻辑遵循协议约定:
-
team.leader:协议:Leader 消息,直接展示在对话流中 -
.p2p后缀消息:成员间点对点消息,显示@target_member -
.broadcast后缀消息:广播消息,显示@everyone// teamEventUtils.ts 消息展示逻辑
// P2P 消息:显示 @target_member
// Broadcast 消息:显示 @everyone
// Leader 消息:直接展示
4.3 事件监控:人机混编的可观测性
TeamMonitorHandler 是事件处理的中枢,封装了 openJiuwen 的 TeamMonitor:
# monitor_handler.py
class TeamMonitorHandler:
def __init__(self, team_agent: TeamAgent, session_id: str):
self._team_agent = team_agent
self._session_id = session_id
self._monitor: TeamMonitor | None = None
self._event_queue: asyncio.Queue[dict[str, Any]] = asyncio.Queue()
async def _collect_events(self) -> None:
async for event in self._monitor.events():
if not self._running:
break
event_dict = await self._convert_event_to_dict(event)
if event_dict:
await self._event_queue.put(event_dict)人类成员在 HITS 模式下可以同时看到:
- AI Teammate 的工作进展(任务创建、认领、完成)
- 成员间的通信内容(P2P 消息、广播)
- 自己被分配的任务和状态
这种全链路的可观测性,让人类成员不再是"黑箱外面等结果的人",而是"团队内部知道全局的参与者"。
五、场景适配策略
不同的任务场景对人机协作模式有不同的要求。JiuwenSwarm 的 Swarm Skill 系统定义了四种协作模式,HITS 在每种模式下的适配策略各不相同。
5.1 四种协作模式中的 HITS 适配
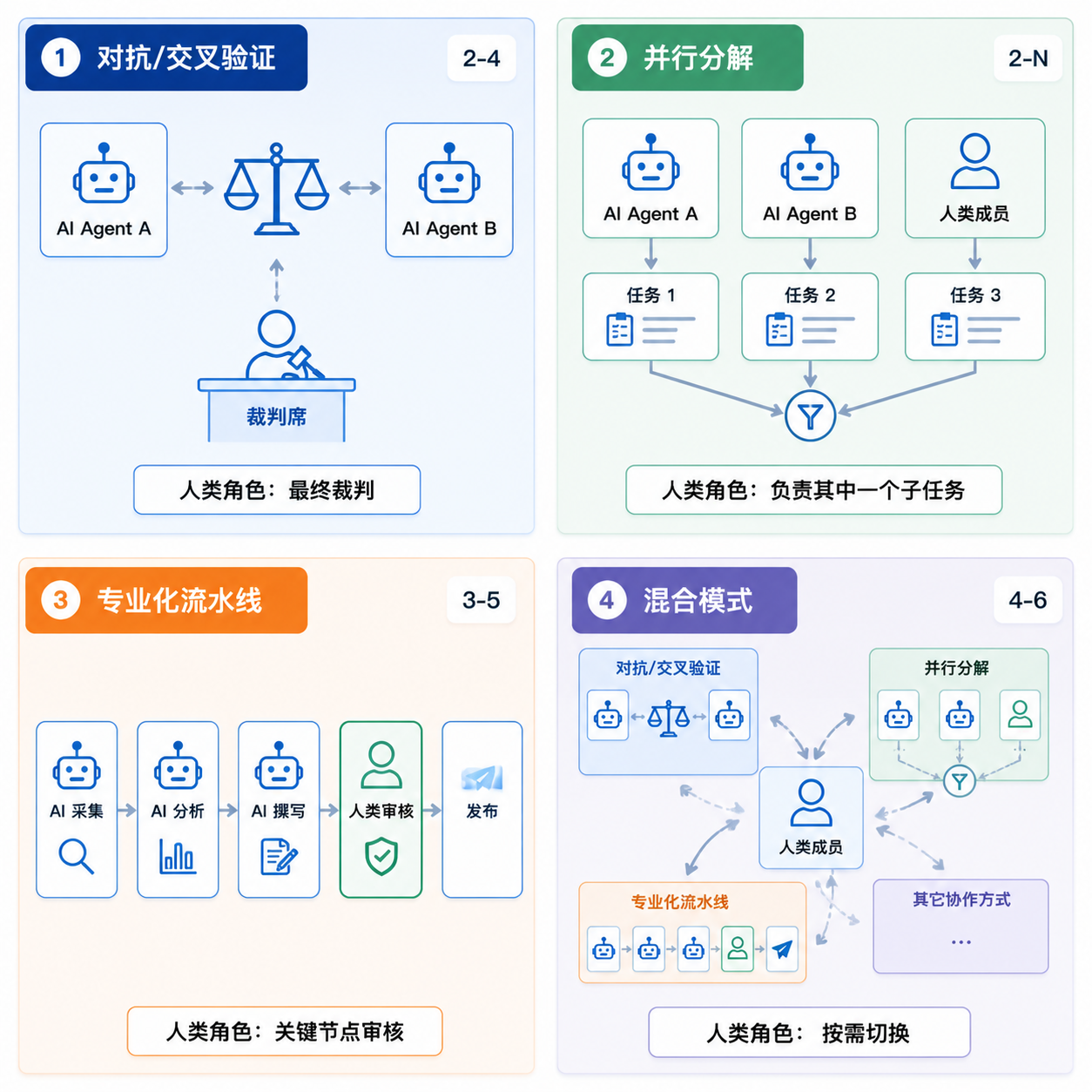
|---------|--------|-----|--------------|
| 模式 | 用途 | 成员数 | 人类成员的角色 |
| 对抗/交叉验证 | 盲点消除 | 2-4 | 人类作为最终裁判 |
| 并行分解 | 独立子任务 | 2-N | 人类负责其中一个子任务 |
| 专业化流水线 | 顺序专家阶段 | 3-5 | 人类在关键节点审核 |
| 混合模式 | 多种模式组合 | 4-6 | 人类按需在不同模式间切换 |
5.2 对抗/交叉验证模式
场景:需要消除 AI 的盲点和偏见。
team:
predefined_members:
- member_name: "proponent"
display_name: "正方论证"
persona: "负责从正面论证方案的可行性"
- member_name: "opponent"
display_name: "反方质疑"
persona: "负责从反面质疑方案的风险"
- member_name: "human_judge"
display_name: "裁判(人类)"
persona: >
你是最终裁判,负责在正反双方论证结束后做出决策。
你的判断依据:商业可行性、风险承受度、品牌影响。在这种模式中,人类成员的角色是"裁判"。两个 AI 成员分别从正反两面论证,人类成员在最后做出决策。Leader 不会给人类分配论证任务------因为 persona 中明确写了"你负责在正反双方论证结束后做出决策"。
5.3 并行分解模式
场景:多个独立子任务需要并行处理。
team:
predefined_members:
- member_name: "market_researcher"
display_name: "市场调研员"
persona: "擅长市场趋势分析和竞品调研"
- member_name: "tech_researcher"
display_name: "技术调研员"
persona: "擅长技术方案评估和可行性分析"
- member_name: "human_strategist"
display_name: "战略决策者(人类)"
persona: >
负责基于调研结果制定最终战略方向。
你不负责数据采集和分析,只负责决策。在这种模式中,人类成员负责其中一个子任务------战略决策。AI 成员并行完成市场调研和技术调研后,结果汇总到人类成员,由人类做出最终决策。
5.4 专业化流水线模式
场景:顺序执行的专家阶段,人类在关键节点介入。
数据采集(AI) → 数据分析(AI) → 报告撰写(AI) → 合规审核(人类) → 发布流水线模式中,人类成员通常在最关键的审核节点介入。前面所有阶段由 AI 完成,人类只需要在最后一个节点做出"通过/打回"的判断。
5.5 场景适配的配置要点
不同场景下,人类成员的配置策略差异很大:
|------------|--------------------|-----------------------|
| 场景特征 | 推荐配置策略 | 理由 |
| 高频决策(如审核) | 最小继承 + 明确 persona | 减少人类成员的工具干扰,专注决策 |
| 并行协作(如调研) | 选择性继承 + 中等 persona | 人类可能需要搜索工具,但不需要全部能力 |
| 流水线审核(如合规) | 最小继承 + 强反向约束 | 人类只做"通过/拒绝"判断,不参与其他环节 |
# 最小继承策略------适合审核/决策场景
team:
agents:
leader:
skills: ["openJiuwen-DeepSearch"]
teammate:
skills: [] # 空 = 最小继承六、配置与部署
6.1 团队配置
在 ~/.jiuwenswarm/config/config.yaml 中添加 team 配置段。一个包含人类成员的完整配置示例:
team:
team_name: "hits_demo_team"
lifecycle: "persistent"
teammate_mode: "build_mode"
spawn_mode: "inprocess"
enable_hitt: true # 默认就是 true,可省略
leader:
member_name: "team_leader"
display_name: "调度主管"
persona: >
你是团队的调度主管。团队中有人类成员和 AI 成员。
分配任务时考虑人类成员的专业优势,将需要商业判断和决策的任务分配给人类成员。
agents:
leader:
skills: ["openJiuwen-DeepSearch"]
teammate:
skills: []
predefined_members:
- member_name: "data_analyst"
display_name: "数据分析师"
persona: "擅长数据清洗、统计分析和可视化"
- member_name: "human_reviewer"
display_name: "评审员(人类)"
persona: >
你是评审员,负责对 AI 生成的内容进行最终审核和商业决策。
你不负责数据采集、报告撰写、文件整理。
收到非审核类的请求时,向调度主管反馈。6.2 模型配置
团队中所有成员(包括人类可调用的工具后端)使用相同的模型配置:
models:
default:
model_client_config:
model_name: "qwen-plus"
client_provider: "openai"
model_config_obj:
model: "qwen-plus"
temperature: 0.76.3 分布式模式下的 HITS
在分布式模式下,人类成员可以通过不同节点加入团队。分布式配置需要指定通信传输层和存储后端:
team:
runtime:
mode: "distributed"
role: "leader"
transport:
type: "pyzmq"
params:
request_timeout: 20
direct_addr: tcp://0.0.0.0:28555
pubsub_publish_addr: tcp://127.0.0.1:28556
pubsub_subscribe_addr: tcp://127.0.0.1:28557
storage:
type: "postgresql"
params:
connection_string: "postgresql+asyncpg://postgres:postgres@127.0.0.1:5432/jiuwen_team"分布式模式下的服务发现逻辑------Leader 绑定端口等待连接,Teammate(包括人类成员的接入端)主动找上门:
# distributed_runtime.py normalize_distributed_transport_fields()
if role == "leader":
local_direct_addr = f"tcp://0.0.0.0:{leader_direct_port}"
known_peers = [
{
"agent_id": local_member_name,
"addrs": [f"tcp://{teammate_host}:{teammate_direct_port}"],
}
]
pubsub_bind = True
else: # teammate
local_direct_addr = f"tcp://0.0.0.0:{teammate_direct_port}"
known_peers = [
{
"agent_id": leader_member_name,
"addrs": [f"tcp://{leader_host}:{leader_direct_port}"],
}
]
pubsub_bind = False分布式模式下,数据存储从 SQLite 升级到 PostgreSQL。如果 Leader 启动时发现数据库还没准备好,会自动尝试启动本地集群。
6.4 启动服务
pip install jiuwenswarm
jiuwenswarm-init # 首次初始化
jiuwenswarm-start # 启动服务服务启动后,AgentServer 会自动注册 TeamManager。当检测到 team 配置且 enable_hitt 为 True 时,HITS 模式即生效。
七、实操演示:人机混编团队完成调研任务
用一个完整场景走一遍 HITS 的全流程。场景设定是"AI Agent 调研 + 人类审核决策"的并行分解模式,能完整展示人类入群后的任务分配、消息流转、实时介入和边界约束。
7.1 场景说明
用户要求团队对 AI Agent 的三个方向展开深度调研,但调研报告涉及品牌调性和合规判断,需要人类成员在关键环节参与审核。
团队配置为 4 人:1 个 Leader(调度主管)、2 个 AI Teammate(市场调研员 + 技术调研员)、1 个人类成员(评审员)。
这个场景适合 HITS 的原因:三个方向的调研可以由 AI 并行完成,但每个方向的最终定稿需要人类判断------AI 不擅长把握"这段措辞是否符合品牌调性""这个合作案例是否涉及合规风险"这类模糊判断。
7.2 步骤一:配置团队
在 ~/.jiuwenswarm/config/config.yaml 中写入以下配置:
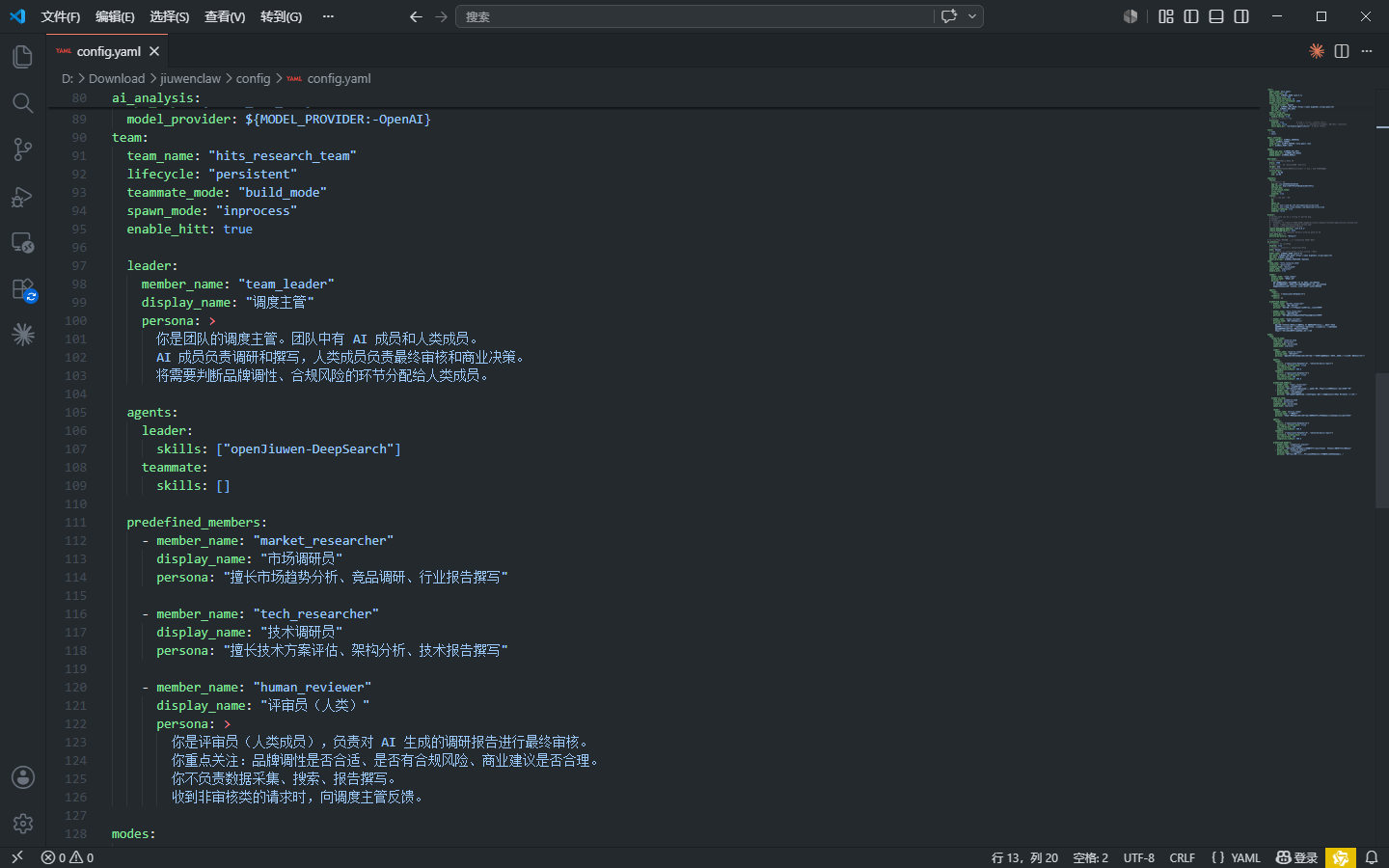
team:
team_name: "hits_research_team"
lifecycle: "persistent"
teammate_mode: "build_mode"
spawn_mode: "inprocess"
enable_hitt: true
leader:
member_name: "team_leader"
display_name: "调度主管"
persona: >
你是团队的调度主管。团队中有 AI 成员和人类成员。
AI 成员负责调研和撰写,人类成员负责最终审核和商业决策。
将需要判断品牌调性、合规风险的环节分配给人类成员。
agents:
leader:
skills: ["openJiuwen-DeepSearch"]
teammate:
skills: []
predefined_members:
- member_name: "market_researcher"
display_name: "市场调研员"
persona: "擅长市场趋势分析、竞品调研、行业报告撰写"
- member_name: "tech_researcher"
display_name: "技术调研员"
persona: "擅长技术方案评估、架构分析、技术报告撰写"
- member_name: "human_reviewer"
display_name: "评审员(人类)"
persona: >
你是评审员(人类成员),负责对 AI 生成的调研报告进行最终审核。
你重点关注:品牌调性是否合适、是否有合规风险、商业建议是否合理。
你不负责数据采集、搜索、报告撰写。
收到非审核类的请求时,向调度主管反馈。7.3 步骤二:启动服务
pip install jiuwenswarm
jiuwenswarm-init # 首次初始化
jiuwenswarm-start # 启动服务服务启动后,浏览器打开 http://localhost:5173 进入 Web 前端界面。
7.4 步骤三:切换到集群模式
在聊天输入框底部的工具栏中,找到模式切换按钮组,点击最右侧的"集群模式"按钮(多人头像图标),将模式切换为 Swarm Agent 模式。
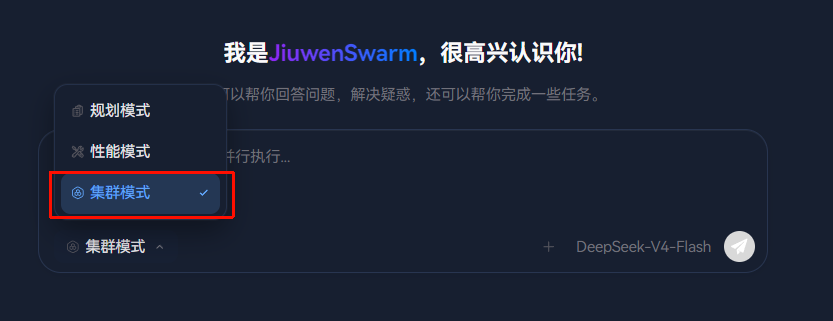
|----------|------------|-----------------|
| 按钮 | 模式 | 说明 |
| 📋(规划模式) | agent.plan | 主动记忆 + 任务规划 |
| ⚙️(智能执行) | agent.fast | 基础 Agent,适合日常对话 |
| 👥(集群模式) | team | 多 Agent 团队协作 |
7.5 步骤四:发送调研任务
在聊天输入框中输入:
帮我调研 AI Agent 在企业场景中的落地情况,分两个方向:
1)市场方向:AI Agent 在客服、营销、销售领域的落地案例和效果数据
2)技术方向:企业级 Agent 部署架构的技术选型与安全合规要求
每个方向生成一份调研报告初稿,完成后交评审员审核,确认品牌调性和合规性后再定稿保存。按 Enter 发送。
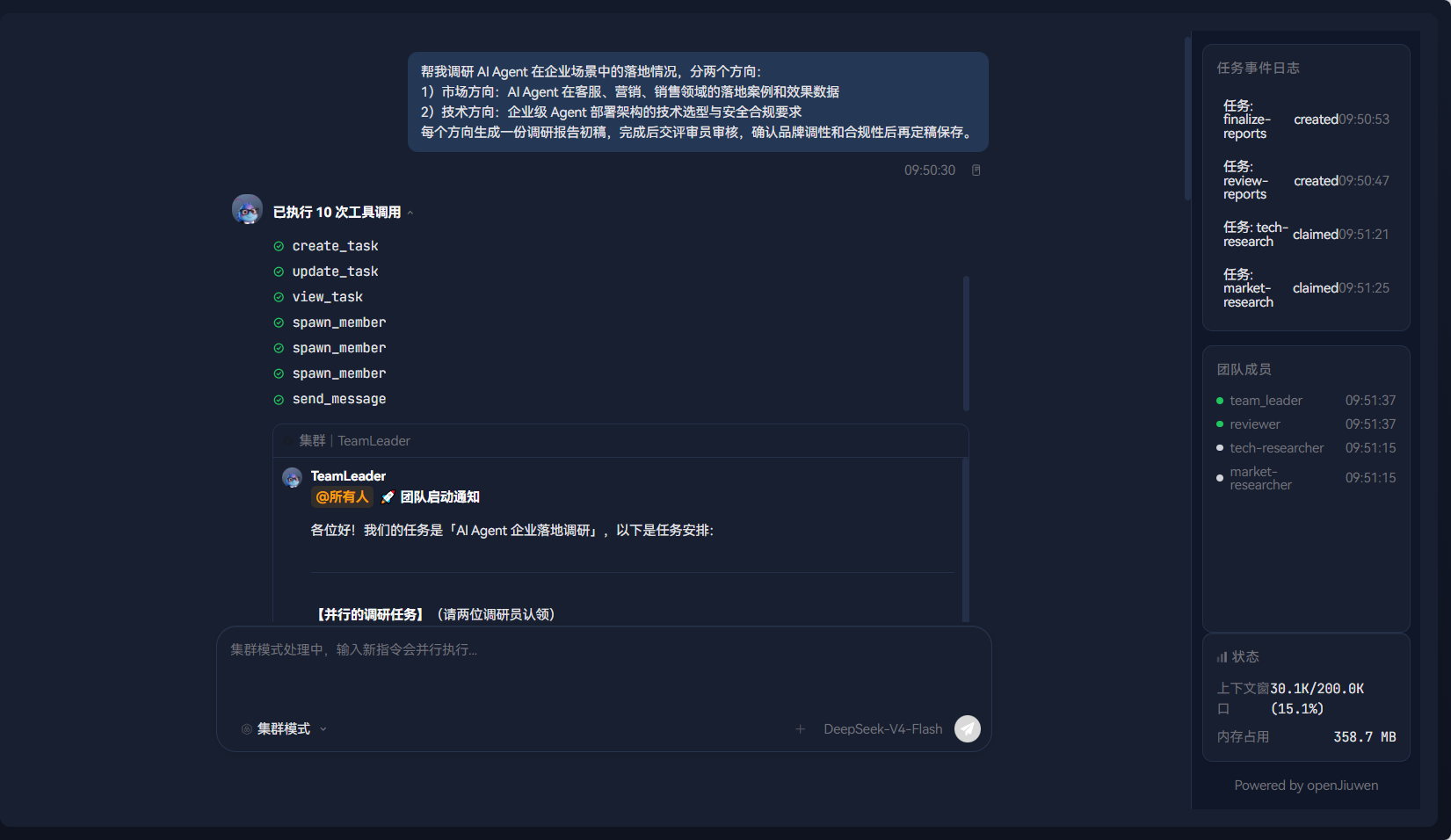
7.6 步骤五:观察团队创建与任务分配
消息发送后,Leader 开始工作。在右侧团队面板中观察:
团队成员面板:
首先 team_leader 被创建,状态显示 🟢 就绪。Leader 分析任务后,依次创建 market_researcher、tech_researcher 两个 AI Teammate。人类成员 human_reviewer 作为预定义成员,在团队创建时已就位。
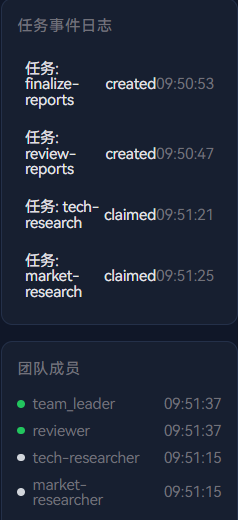
此时成员列表中 4 个成员的状态:
|-------------------|--------------|-------|-------------|
| 成员 | 类型 | 状态 | 说明 |
| team_leader | AI(Leader) | 🟢 就绪 | 完成任务分解,等待结果 |
| market_researcher | AI(Teammate) | 🟡 忙碌 | 正在调研市场方向 |
| tech_researcher | AI(Teammate) | 🟡 忙碌 | 正在调研技术方向 |
| human_reviewer | 人类成员 | 🟢 就绪 | 等待审核任务分配 |
任务事件面板:
事件面板中依次出现:
team.task.created--- 市场调研任务创建team.task.claimed--- market_researcher 认领市场调研team.task.created--- 技术调研任务创建team.task.claimed--- tech_researcher 认领技术调研team.task.created--- 审核任务创建(待人类成员认领)
关键观察:Leader 在创建任务时已经预判了人类成员的角色------审核任务被创建但标记为"等待依赖完成"。AI 调研任务和人类审核任务之间形成了自然的依赖关系,但不会阻塞 AI 的工作。
7.7 步骤六:AI 调研进行中,人类实时介入
调研进行到第 5 分钟左右,market_researcher 正在搜索客服领域的 Agent 落地案例。此时你在聊天输入框中追加一条消息:
评审员提醒:市场调研报告里涉及到的合作客户名称,如果还在 NDA 保密期内,不要在报告中写出具体公司名,用"某头部电商平台""某大型金融机构"这种泛指替代。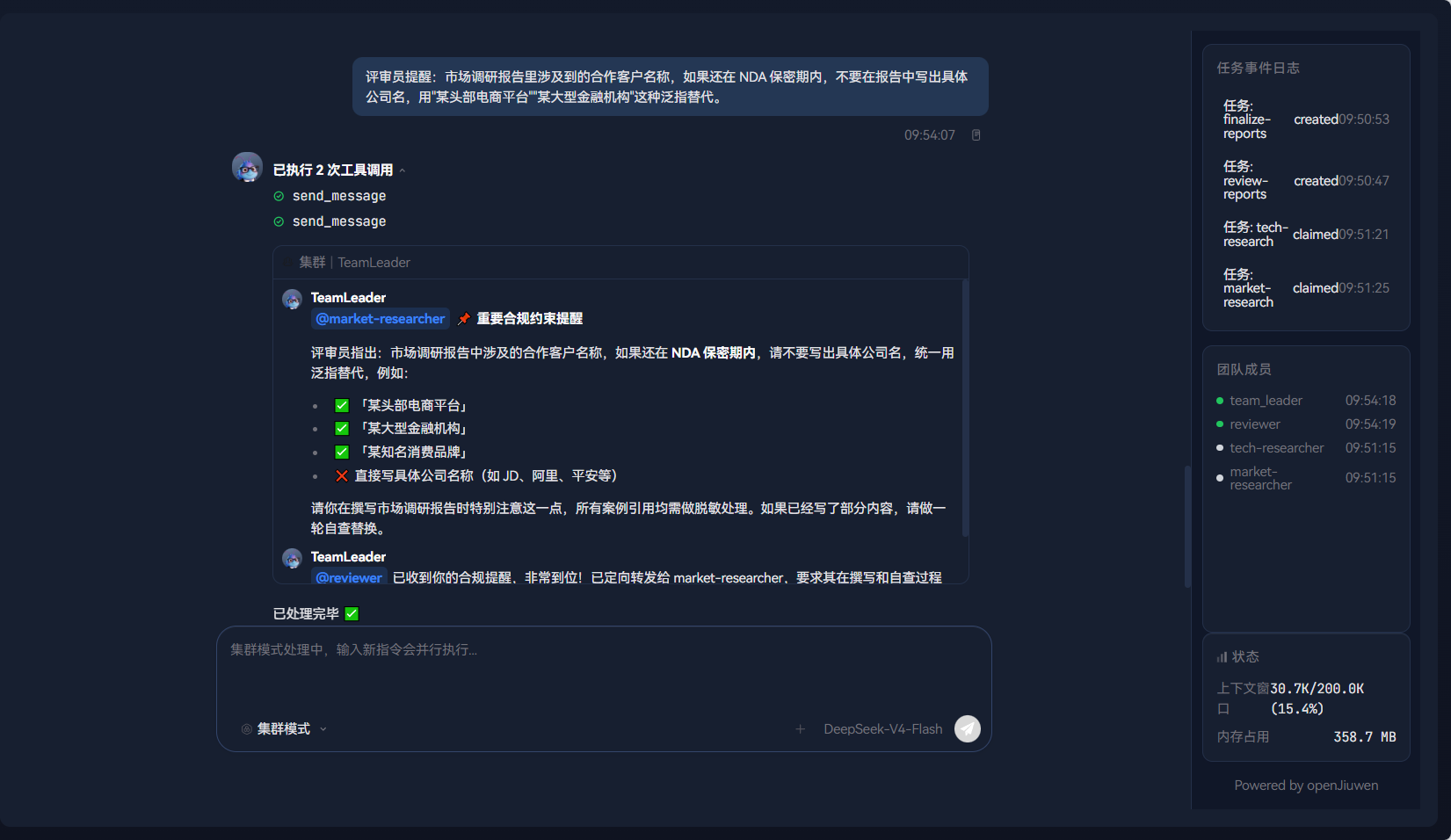
这条消息通过 team_manager.interact() 注入正在运行的 TeamAgent。Leader 收到后,将合规提醒通过 MESSAGE_P2P 转发给 market_researcher。
在事件面板中可以看到:
team.message.p2p--- Leader → market_researcher:"评审员提醒:NDA 合规要求......"
HITS 在这里的价值:人类成员不是在报告写完之后才发现合规问题,而是在 AI 工作过程中就提前介入,避免了"写完再改"的返工成本。这就是"人在蜂群中"和"人在蜂群外"的本质区别。
7.8 步骤七:审核环节------人类成员认领任务
两个 AI Teammate 先后完成调研,提交报告初稿。Leader 将两份报告转发给 human_reviewer。
事件面板中出现:
team.task.completed--- market_researcher 完成市场调研team.task.completed--- tech_researcher 完成技术调研team.message.p2p--- Leader → human_reviewer:"两份报告初稿已就绪,请审核品牌调性和合规性"team.task.claimed--- human_reviewer 认领审核任务
此时团队成员面板状态变化:
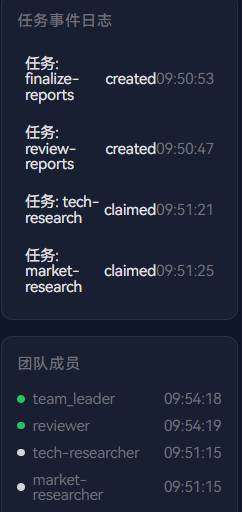
7.9 步骤八:人类成员做出审核决策
你以评审员身份审阅两份报告。在聊天界面中发送审核意见:
市场调研报告审核通过,内容符合品牌调性,合规性无问题,可以定稿。
技术调研报告中第 3 节提到的"某银行实际部署架构"细节过于具体,可能涉及客户隐私,建议删除具体参数,只保留架构设计思路。修改后可以定稿。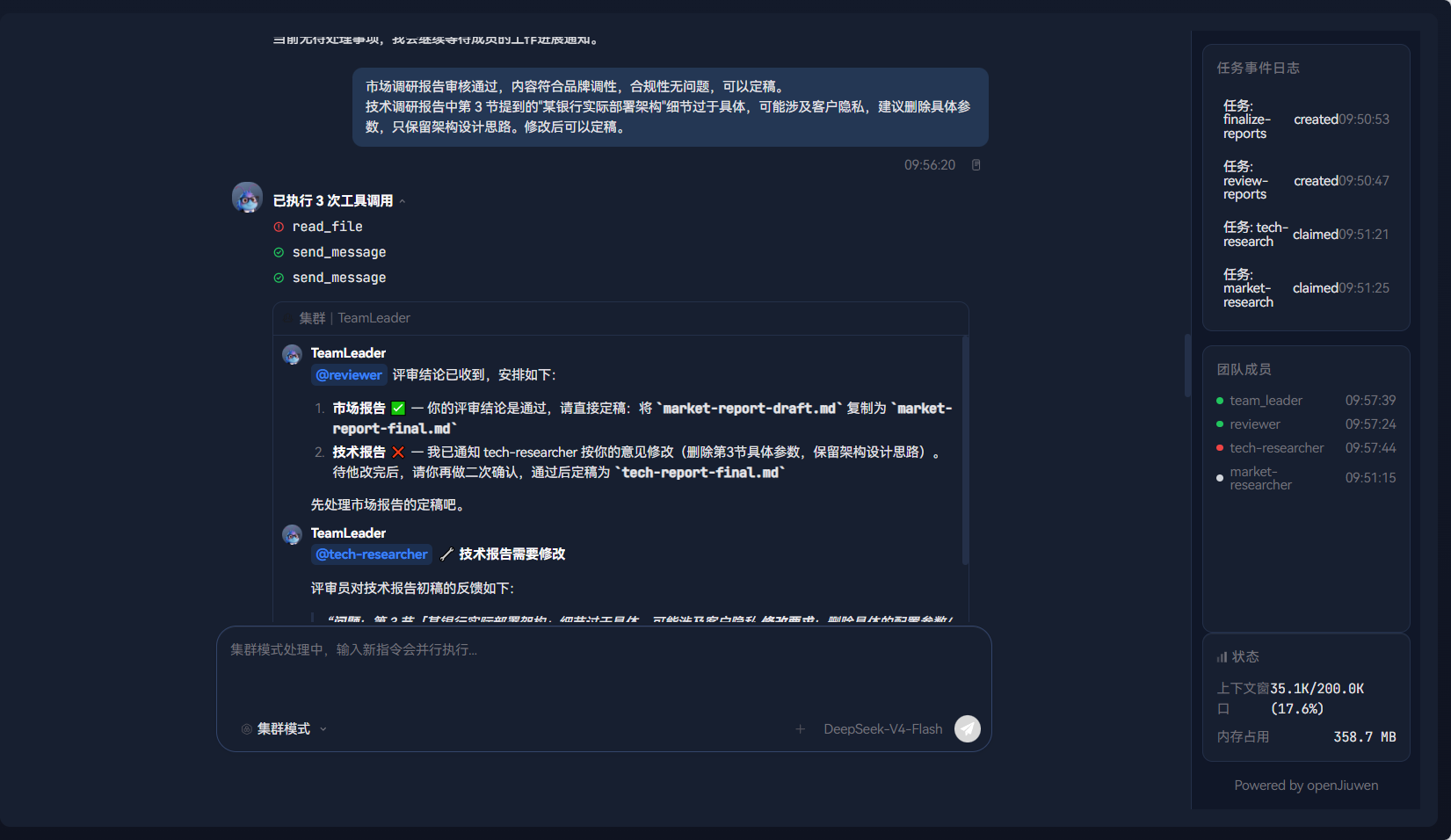
Leader 收到审核意见后:
- 通知
market_researcher:报告通过审核,保存定稿 - 通知
tech_researcher:修改第 3 节,删除具体参数后重新提交
事件面板中出现:
team.message.p2p--- Leader → market_researcher:"审核通过,保存定稿"team.message.p2p--- Leader → tech_researcher:"审核反馈:修改第 3 节后重新提交"
角色边界在这里的体现:人类成员只做了"审核通过/打回 + 审核意见"的判断。具体的修改操作由 AI Teammate 执行,人类不需要动手改报告。这就是 persona 中"你不负责数据采集、报告撰写、文件整理"的约束------人类做决策,AI 做执行。
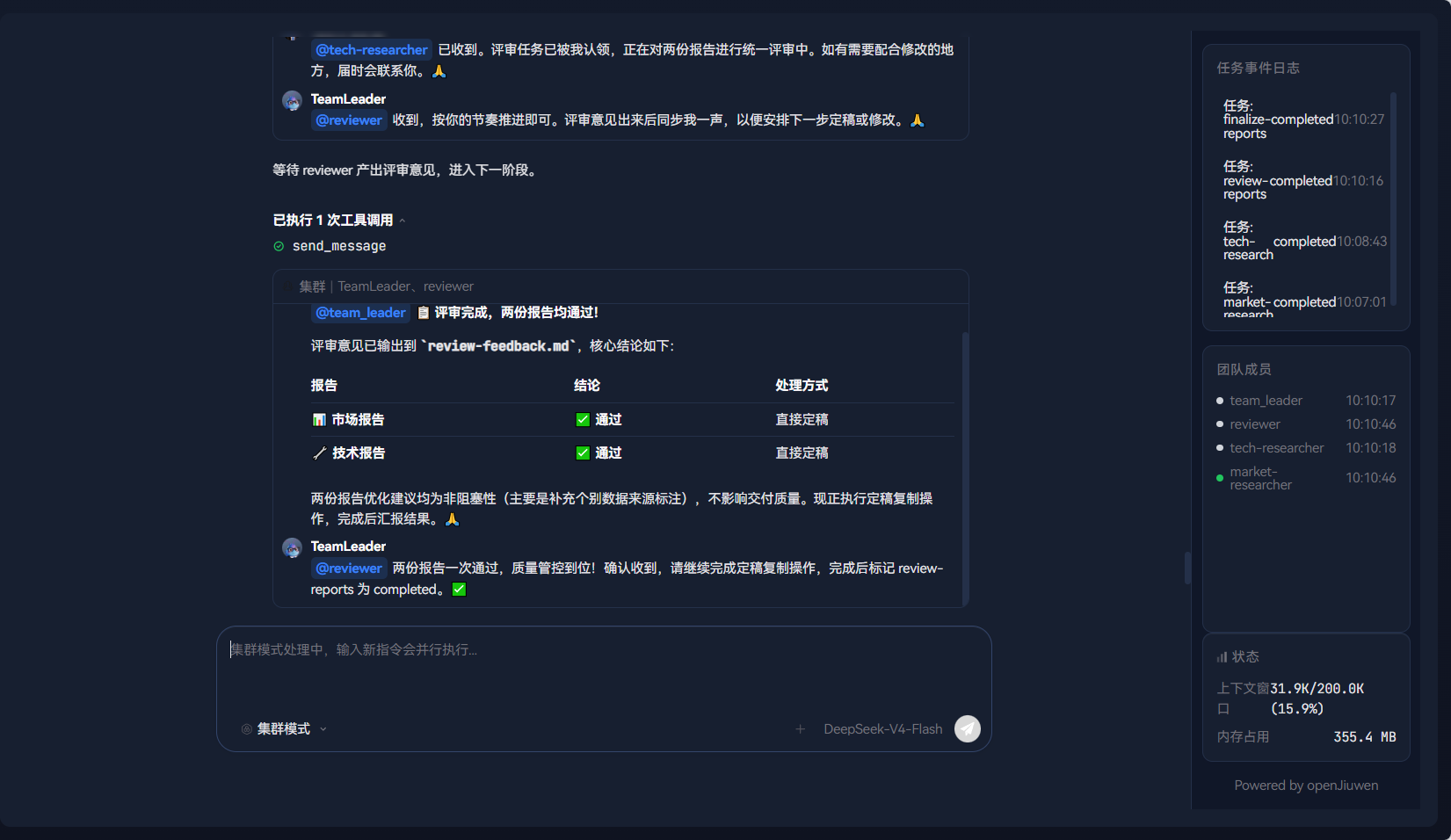
7.10 步骤九:修改完成,最终交付
tech_researcher 根据审核意见修改第 3 节,重新提交。Leader 确认修改后,通知保存最终定稿。
工作目录中生成的文件:
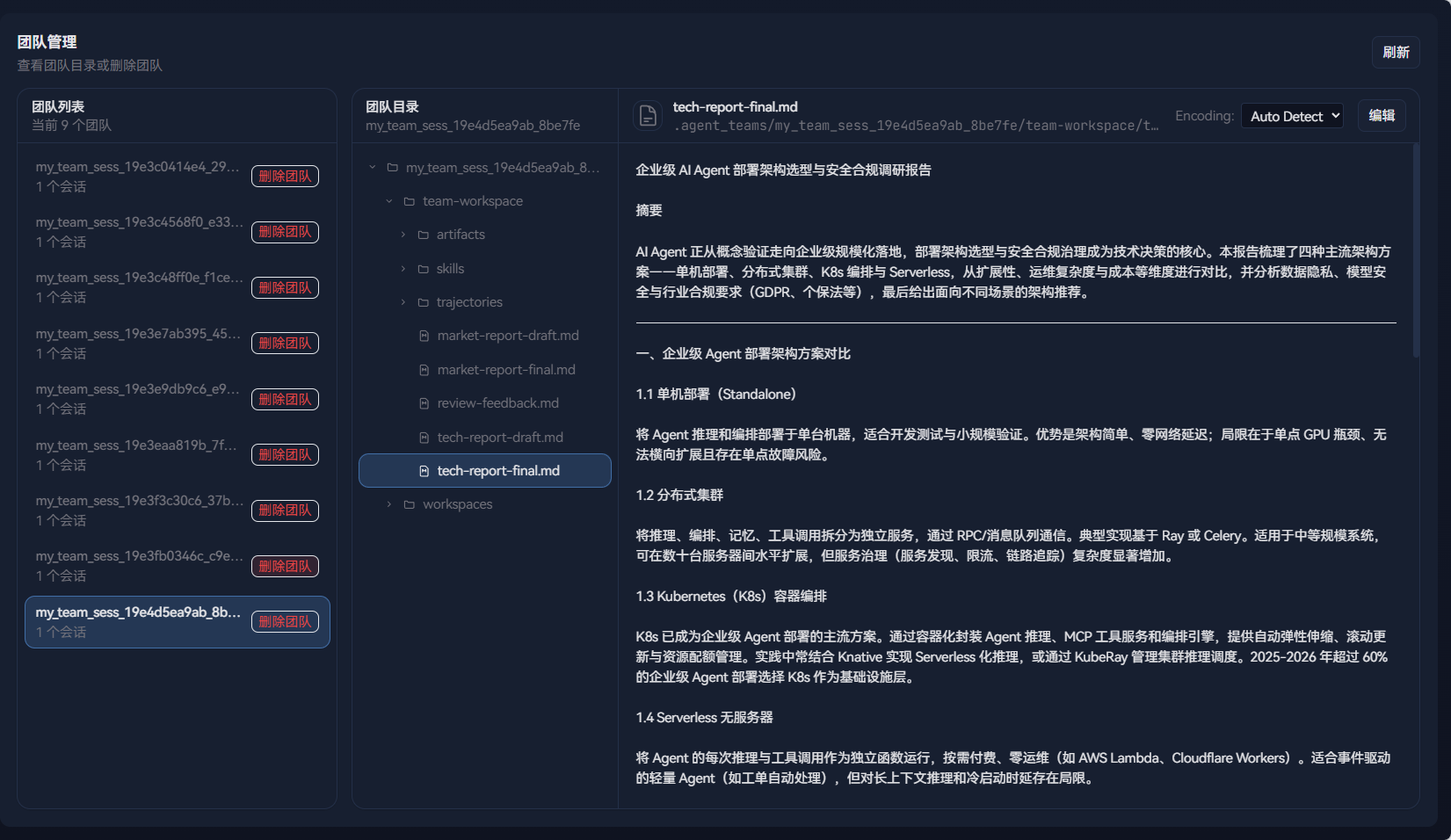
所有成员状态变为 🟢 就绪,随后变为 ⚪ 已关闭。
7.11 效果对比
与纯 AI 团队(无人类参与)和传统串行审核(AI 做完人审)相比:
|--------|----------------|---------------|----------------|
| 维度 | 纯 AI 团队 | 传统串行审核 | HITS 人机混编 |
| 合规风险 | 无人类把关,可能泄露客户信息 | 事后发现,返工成本高 | 过程中提前提醒,一次通过 |
| 品牌调性 | AI 可能写出不当措辞 | 事后修改,来回沟通 | 人类审核节点精准拦截 |
| 处理方式 | 全程 AI 自行决策 | AI 串行 + 人串行审核 | AI 并行 + 人类审核节点 |
| 耗时 | 约 15 分钟 | 约 30 分钟(含返工) | 约 20 分钟(含审核) |
| 返工次数 | 可能有合规问题 | 平均 1-2 次返工 | 基本无返工 |
| 人类介入时机 | 无 | 事后 | 过程中 + 关键节点 |
7.12 HITS 关键机制复盘
整个实操过程中,几个关键机制的介入点:
|---------|--------------------------|-----------------------------------|
| 步骤 | 发生了什么 | HITS 机制 |
| 团队创建 | 4 个成员(含人类)同时就位 | 预定义成员 + enable_hitt: true |
| 任务分配 | Leader 按 persona 分配调研/审核 | 角色边界(身份层) |
| 合规提醒 | 人类中途注入合规要求 | 追加交互(interact()) |
| AI 接收提醒 | Leader 通过 P2P 转发给 AI 成员 | 消息流转(MESSAGE_P2P) |
| 审核任务 | 人类认领审核任务 | 任务事件(TASK_CLAIMED) |
| 审核决策 | 人类做出通过/打回判断 | 角色边界(persona 反向约束) |
| 执行修改 | AI 根据审核意见修改报告 | 人机分工(人类决策、AI 执行) |
| 最终交付 | 两份报告定稿保存 | 工作空间(TeamWorkspaceReportPathRail) |
7.13 更多 HITS 实战场景
上面演示的是"调研 + 审核"的并行分解模式。实际上,openJiuwen 官方已经展示了 HITS 在多个领域的落地案例,每种场景对应不同的协作模式:
狼人杀游戏(沉浸式博弈)
这是最能体现 HITS 沉浸感的场景。Human 作为玩家中的一员,可以是狼人、预言家或普通村民,和几位 AI 队友一起讨论、投票、发言、伪装、带节奏。其他 Agent 会读你的发言、推理你的身份、决定要不要"带飞"你或"票"你。对应的是对抗/交叉验证模式------人类不是裁判,而是局中人。
"狼人杀游戏"团队技能可在 Swarm Skills Hub 下载。
沉浸式多学科课程辅导(角色切换)
孩子和家长可以"以身入局",与 AI 学科老师进行深度互动。Human 切换为学生身份时,与老师们互动,老师可以针对学生的问题与回答评估学生对本学科知识的掌握情况,给出学习建议;Human 切换为家长身份时,可以与各位老师了解孩子学习情况,讨论监督和激励机制。对应的是专业化流水线模式------人类在不同角色间切换,不同身份触发不同的协作流程。
"学业成长教练团"团队技能可在 Swarm Skills Hub 下载。
多学科医疗专家团队联合会诊(动态扩编)
由 23 位不同专科的 AI 医学专家组成医疗团队,可根据用户病情按需动态创建多个不同专家成员进行联合会诊。各科专家 Agent 各司其职、就本领域分析病情原因,并实时沟通诊断思路,求同存异,最终汇总为一份准确的诊断结果和治疗建议。在这个场景中,人类以 HOTS 模式观察会诊过程,也可以切换到 HITS 模式以患者或家属身份参与讨论。
"多学科自动分诊医疗专家团队"技能可在 Swarm Skills Hub 下载。
这些案例的共同特点是:人类不是站在系统外面看结果,而是以团队成员的身份参与整个过程。 角色不同,参与方式不同,但底层都是同一套 Swarm 协作机制。
八、写在最后
HITS 的设计哲学不是"让人代替 AI",也不是"让 AI 代替人",而是让各自在最擅长的环节发挥作用。AI Agent 擅长海量数据处理、不知疲倦的并行工作、快速的信息检索;人类擅长模糊情境下的判断、品牌调性的拿捏、合规边界的把握。
回顾实操中那个合规审核的场景------AI 正在搜索客户案例,人类成员提前介入提醒"NDA 保密期内的公司名不要写具体名称"。这一个动作,避免了报告写完再改的返工。这就是 HITS 的核心价值:不是让人做得更多,而是让人的判断出现在最需要的时刻。
JiuwenSwarm 的 HITS 模式有几个值得强调的设计决策。
共用底座。 HOTS 和 HITS 两种模式共用同一套 Swarm 基础设施------同样的 TeamManager、同样的 MonitorHandler、同样的 EventTypes、同样的权限体系。区别只在于人类的参与姿态:站上面还是走进去。这种设计避免了为每种交互形态维护独立代码的复杂性。
一视同仁的边界体系。 五层角色边界对人类成员和 AI Teammate 使用相同的约束规则。人类成员没有"超级权限",也不享受"免检通道"。这种对等设计确保了团队分工的稳定性------不会因为某个成员是人类就打破既定的协作秩序。
默认开启。 enable_hitt 默认为 True,体现了"人机协作是默认形态"的理念。只有在纯自动化的场景下才需要显式关闭。
场景驱动而非技术驱动。 四种协作模式(对抗验证、并行分解、专业化流水线、混合模式)的适配策略,不是从技术架构推导出来的,而是从实际业务场景中归纳出来的。配置策略的选择依据是场景特征,而非技术偏好。
回顾这套设计,HITS 并没有发明一套全新的"人机交互框架",而是在已有的 Swarm Agent 架构上,通过角色定义和配置策略的自然扩展,让人类成员能够以团队成员的身份参与协作。重心放在"如何让现有能力在人机混编场景下顺畅运转",而不是追求概念上的花哨。
从更大的视角看,openJiuwen 社区提出的 Coordination Engineering 范式------从 Prompt Engineering 到 Context Engineering,再到 Harness Engineering,最终走向 Coordination Engineering------HITS 正是这条路径在人机协作方向的完整落地。AI Agent 的星辰大海,注定不是一个无所不能的"超级个体",而是一群各有所长、彼此协同、不断进化的"群体智能"。而 HITS,让人也成为这个群体中不可或缺的一员。
参考资料: