引言
上一篇我们学习了最短路径------求两点之间最短的路径。今天要讲的两个主题,虽然也是图论核心内容,但解决的问题完全不同:
-
最小生成树 :用最小的总代价把所有顶点连接起来(比如修路连接所有村庄,总造价最低)
-
拓扑排序 :把有依赖关系的任务排出一个合理的执行顺序(比如先修课、后修课)

第一部分:最小生成树
一、什么是最小生成树
生成树 :包含图的所有顶点,但只有 n-1 条边,且没有环。
最小生成树 :在所有生成树中,边的权值之和最小的那一棵。
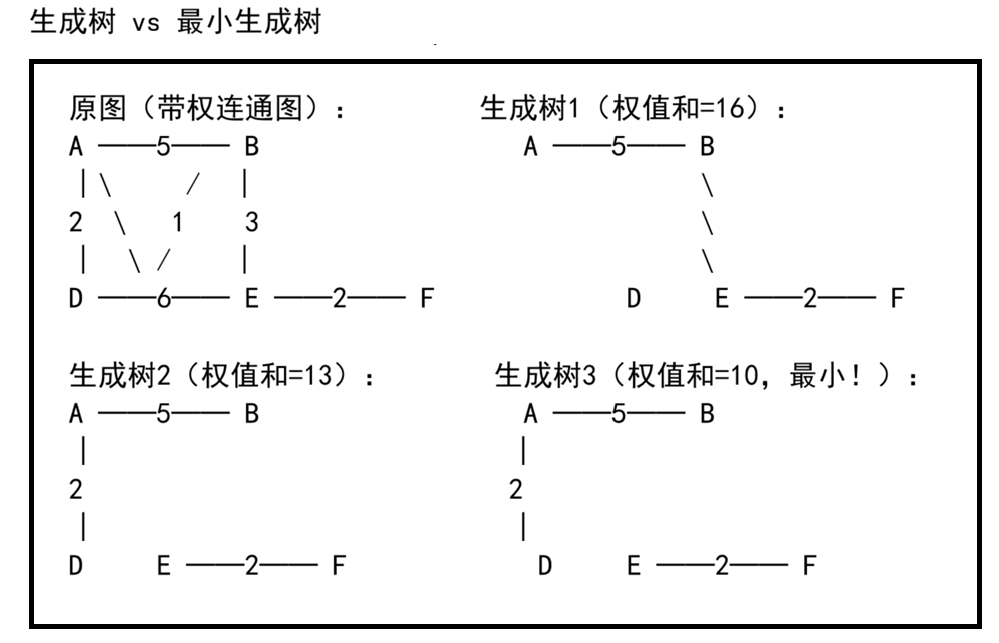
最小生成树的性质:
-
包含 n 个顶点,恰好 n-1 条边
-
没有环
-
连通
-
边的权值总和最小
第二部分:Prim 算法
一、算法思想
Prim 算法从一个点出发,一步步"生长"出一棵最小生成树。
核心思想 :每次选择距离当前生成树最近的一个顶点,把它和连接它的最短边加入生成树。

二、算法过程图解

三、Prim 代码实现
cpp
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#include <stdbool.h>
#define MAX_V 100
#define INF INT_MAX
typedef struct {
int vertexNum;
int matrix[MAX_V][MAX_V];
} Graph;
void initGraph(Graph* g, int n) {
g->vertexNum = n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
g->matrix[i][j] = (i == j) ? 0 : INF;
}
void addEdge(Graph* g, int u, int v, int w) {
g->matrix[u][v] = w;
g->matrix[v][u] = w;
}
// 在树外顶点中找距离树最近的
int findMinKey(int key[], bool inTree[], int n) {
int min = INF, minIndex = -1;
for (int i = 0; i < n; i++) {
if (!inTree[i] && key[i] < min) {
min = key[i];
minIndex = i;
}
}
return minIndex;
}
void prim(Graph* g, int start) {
int parent[MAX_V]; // parent[i] = i 在生成树中的父节点
int key[MAX_V]; // key[i] = i 到生成树的最小距离
bool inTree[MAX_V]; // inTree[i] = i 是否已在生成树中
for (int i = 0; i < g->vertexNum; i++) {
key[i] = INF;
inTree[i] = false;
}
key[start] = 0;
parent[start] = -1;
int totalWeight = 0;
for (int count = 0; count < g->vertexNum; count++) {
int u = findMinKey(key, inTree, g->vertexNum);
if (u == -1) break;
inTree[u] = true;
if (parent[u] != -1) {
printf("边 %c-%c,权值=%d\n",
'A' + parent[u], 'A' + u, g->matrix[u][parent[u]]);
totalWeight += g->matrix[u][parent[u]];
}
for (int v = 0; v < g->vertexNum; v++) {
if (!inTree[v] && g->matrix[u][v] != INF
&& g->matrix[u][v] < key[v]) {
key[v] = g->matrix[u][v];
parent[v] = u;
}
}
}
printf("总权值 = %d\n", totalWeight);
}第三部分:Kruskal 算法
一、算法思想
Kruskal 算法从边的角度出发:把所有边按权值从小到大排序,依次尝试加入生成树。如果加入的边不形成环,就保留;形成环就跳过。

二、并查集
cpp
// 并查集:判断两个元素是否在同一集合,快速合并两个集合
int parent[MAX_V];
// 初始化:每个元素自成一个集合
void initUnionFind(int n) {
for (int i = 0; i < n; i++) parent[i] = i;
}
// 查找:找到 x 所属集合的根(带路径压缩)
int find(int x) {
if (parent[x] != x)
parent[x] = find(parent[x]); // 路径压缩
return parent[x];
}
// 合并:把 x 和 y 所在的集合合并
void unionSets(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) parent[rootX] = rootY;
}三、Kruskal 算法过程图解

四、Kruskal 代码实现
cpp
typedef struct {
int u, v, w;
} Edge;
// 排序用比较函数
int cmpEdge(const void* a, const void* b) {
return ((Edge*)a)->w - ((Edge*)b)->w;
}
void kruskal(Graph* g) {
int n = g->vertexNum;
// 1. 收集所有边
Edge edges[MAX_V * MAX_V];
int edgeCount = 0;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j < n; j++) { // 只取上三角,避免重复
if (g->matrix[i][j] != INF) {
edges[edgeCount].u = i;
edges[edgeCount].v = j;
edges[edgeCount].w = g->matrix[i][j];
edgeCount++;
}
}
}
// 2. 按权值从小到大排序
qsort(edges, edgeCount, sizeof(Edge), cmpEdge);
// 3. 初始化并查集
initUnionFind(n);
// 4. 依次尝试加入边
int totalWeight = 0;
int selectedEdges = 0;
printf("\nKruskal 选边过程:\n");
for (int i = 0; i < edgeCount && selectedEdges < n - 1; i++) {
int u = edges[i].u;
int v = edges[i].v;
if (find(u) != find(v)) { // 不同连通分量,不会成环
unionSets(u, v);
printf("边 %c-%c,权值=%d\n", 'A' + u, 'A' + v, edges[i].w);
totalWeight += edges[i].w;
selectedEdges++;
}
}
printf("总权值 = %d\n", totalWeight);
}五、Prim vs Kruskal
| 对比项 | Prim | Kruskal |
|---|---|---|
| 核心思想 | 选距离树最近的顶点 | 选权值最小的边 |
| 适合图类型 | 稠密图 | 稀疏图 |
| 时间复杂度 | O(n²) | O(e log e)(排序主导) |
| 辅助结构 | key 数组 | 并查集 |
| 与 Dijkstra 关系 | 几乎一样 | 完全不同 |
第四部分:拓扑排序
一、什么是拓扑排序
有向无环图(DAG) 中,顶点的线性排序,使得每条有向边 (u→v),u 都排在 v 前面。
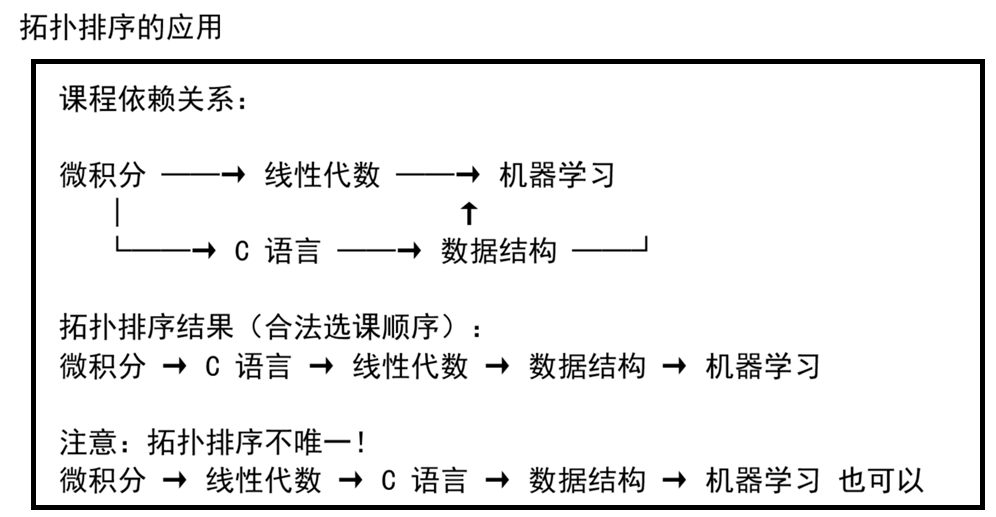
二、Kahn 算法(BFS)
核心思想:每次选一个入度为 0 的顶点输出,然后删除它和它的出边。

三、拓扑排序代码
cpp
#include <stdbool.h>
void topologicalSort(Graph* g) {
int n = g->vertexNum;
int inDegree[MAX_V] = {0};
int queue[MAX_V], front = 0, rear = 0;
int result[MAX_V], resultCount = 0;
// 计算入度
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
if (g->matrix[i][j] != INF && g->matrix[i][j] != 0)
inDegree[j]++;
// 入度为 0 的入队
for (int i = 0; i < n; i++)
if (inDegree[i] == 0)
queue[rear++] = i;
// BFS
while (front < rear) {
int u = queue[front++];
result[resultCount++] = u;
for (int v = 0; v < n; v++) {
if (g->matrix[u][v] != INF && g->matrix[u][v] != 0) {
inDegree[v]--;
if (inDegree[v] == 0) {
queue[rear++] = v;
}
}
}
}
// 输出
if (resultCount < n) {
printf("存在环!无法拓扑排序\n");
} else {
printf("拓扑排序结果:");
for (int i = 0; i < resultCount; i++)
printf("%c ", 'A' + result[i]);
printf("\n");
}
}第五部分:完整测试代码
cpp
int main() {
Graph g;
initGraph(&g, 6);
addEdge(&g, 0, 1, 5); addEdge(&g, 0, 3, 2);
addEdge(&g, 1, 2, 3); addEdge(&g, 1, 4, 1);
addEdge(&g, 2, 5, 4);
addEdge(&g, 3, 4, 6);
addEdge(&g, 4, 5, 2);
printf("===== Prim(起点 A)=====\n");
prim(&g, 0);
printf("\n===== Kruskal =====\n");
kruskal(&g);
// 拓扑排序用有向图
Graph dag;
initGraph(&dag, 4);
dag.matrix[0][1] = 1; dag.matrix[0][2] = 1; // A→B, A→C
dag.matrix[1][3] = 1; dag.matrix[2][3] = 1; // B→D, C→D
dag.vertexNum = 4;
printf("\n===== 拓扑排序 =====\n");
topologicalSort(&dag);
return 0;
}总结
一、核心对比
| 算法 | 解决问题 | 思想 | 复杂度 |
|---|---|---|---|
| Prim | 最小生成树 | 贪心:选距离树最近的顶点 | O(n²) |
| Kruskal | 最小生成树 | 贪心:选权值最小的边 | O(e log e) |
| Kahn(拓扑) | DAG 线性排序 | BFS:选入度为 0 的顶点 | O(n+e) |
二、一句话记忆
最小生成树连接所有点用最小总代价:Prim 从点出发选离树最近的顶点(适合稠密图),Kruskal 从边出发选权值最小的边配合并查集(适合稀疏图)。拓扑排序处理有依赖关系的任务,每次选入度为 0 的顶点输出,队列为空后如果还有顶点未输出则说明有环。