if选择结构
#!bin/bash
if 条件 ; then 命令1
elif 条件2; then命令2
else 命令3
fi
例子1,判断年龄是否满 18 岁,满了就打印 "已经成年,允许上号"
vim age.sh
#!/bin/bash
age=19
if [ $age -ge 18 ]; then
echo "已经成年,允许上号"
fi
bash -x age.sh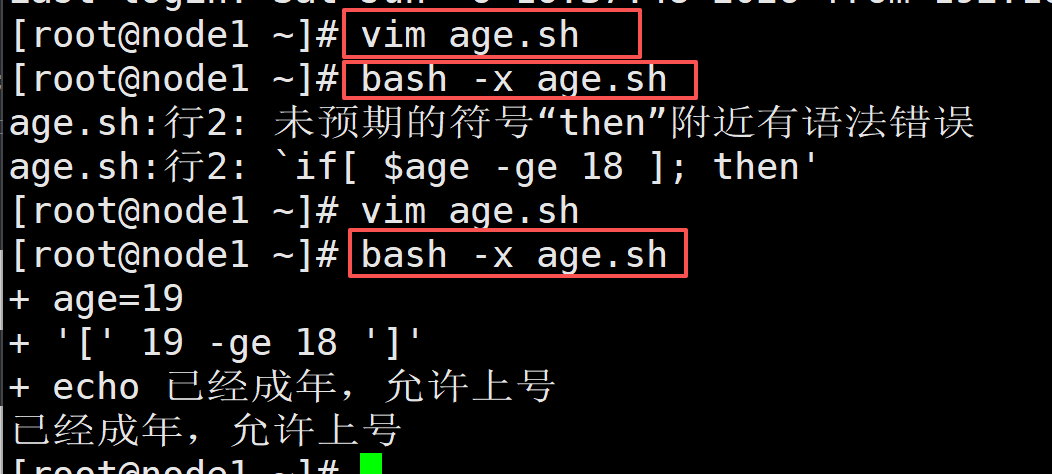
例子2,磁盘使用率监控脚本:设定一个告警阈值(比如 3%),自动获取根分区的磁盘使用率,如果使用率 ≥ 阈值,就输出告警信息
vim cipan.sh
#!/bin/bash
threshold=3
cipan_usage=$(df / |grep / |tr -s ' '|cut -d ' ' -f5 |tr -d %)
if [ $cipan_usage -ge $threshold ];
then
echo "磁盘空间不足"
fi
bash -x cipan.sh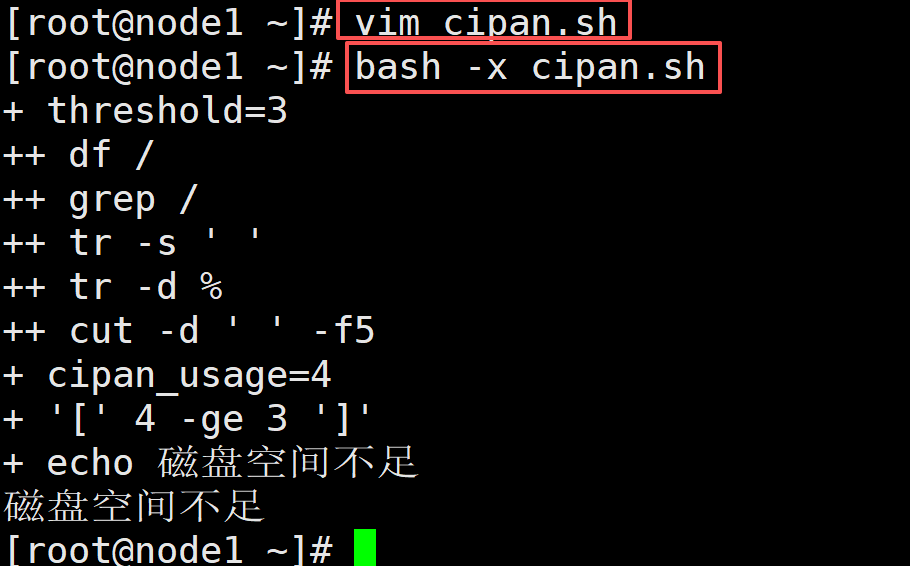
例子3
#!/bin/bash
read -p "请输入您要判断的数字:" num
if [ $num -lt 10 ]; then
echo "该数字小于10"
elif [ $num -ge 10 -a $num -lt 20 ]; then
echo "该数字在10到20之间"
else
echo "该数字大于等于20"
fi 例子4,提示用户输入进程名,通过ps和grep统计匹配进程数。若数量为0,输出"没有该进程";否则输出"该进程正在运行",用于快速判断指定进程是否存活
vim jincheng.sh
#!/bin/bash
read -p "请输入您要查询的进程:" jincheng
num=$(ps aux | grep $jincheng | grep -v grep | wc -l)
if [ $num -eq 0 ]; then
echo "没有该进程"
else
echo "该进程正在运行"
fi
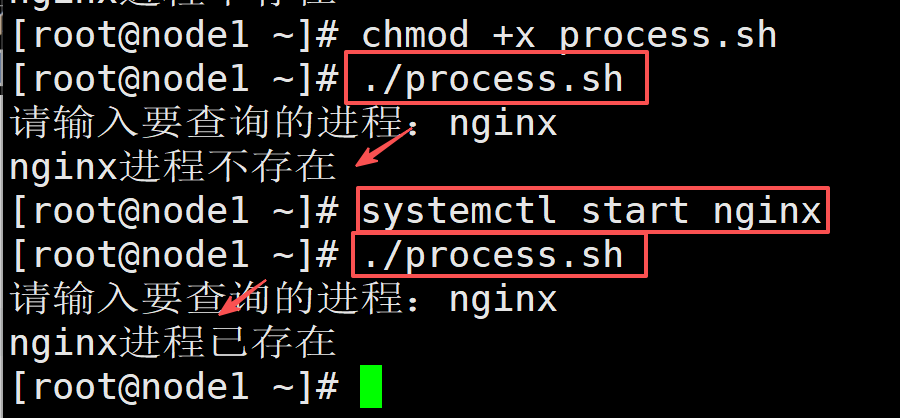
./jincheng.sh方法2,
read -p "请输入要查询的进程:" process
pgrep $process &>/dev/null
if [ $? -eq 0 ];then
echo "$process进程已存在"
else
echo "$process进程不存在"
fipgrep 是 Linux 里专门用来 ** 按名称查找进程 ID(PID)** 的命令。
- 你给它一个进程名,它会返回所有匹配这个名字的进程的 PID
- 比如
pgrep nginx,就会输出所有正在运行的nginx进程的 PID - 它常用来判断 "某个进程是否在运行":
- 如果进程在运行,
pgrep会返回 PID,退出码为 0(成功) - 如果进程没在运行,
pgrep什么都不输出,退出码为非 0(失败)
- 如果进程在运行,
&>/dec/null 把标准输出和错误输出放到黑洞
起到一个静默输出的作用
例子5,判断用户是否存在
#!/bin/bash
read -p "请输入用户名:" user
id $user &>/dev/null
if [ $? -eq 0 ];then
echo "用户已存在"
else
echo "用户不存在"
fi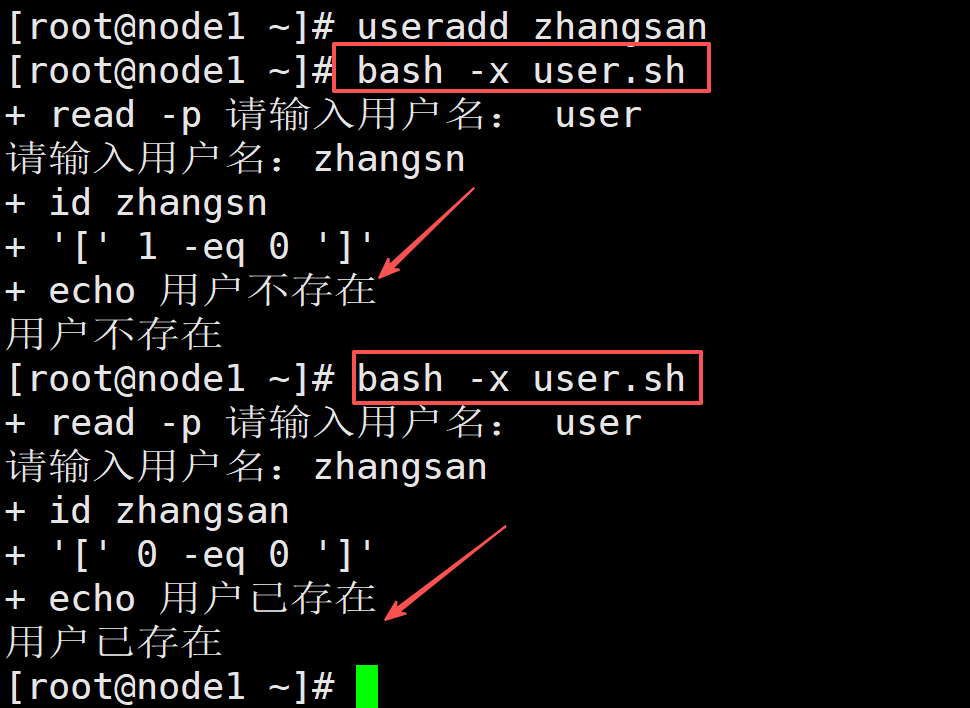
if嵌套
if 条件1 ; then
echo "xxx"
else
if 条件2 ; then
echo "xxx"
else
echo "xxx"
fi
fi
例子1,检查Nginx是否已安装。若存在则提示无需安装;否则通过yum自动安装。安装成功后启动服务并查看状态,失败则提示检查。整体实现Nginx的自动检测、安装及启动流程
dnf -y remove nginx*
vim check_nginx.sh
#!/bin/bash
rpm -qa | grep nginx &> /dev/null
if [ $? -eq 0 ];then
echo "已存在,无需安装"
else
echo "稍等,正在安装..."
yum -y install nginx
if [ $? -eq 0 ];then
echo "安装成功"
systemctl start nginx
systemctl status nginx
else
echo "安装失败,请检查"
fi
fi例子2,判断当前内核主版本是否为5,且次版本是否大于等于14;如果都满足则输出当前内核版本
#!/bin/bash
primary=$(uname -r |cut -d "." -f1)
second=$(uname -r |cut -d "." -f2)
if [ $primary -eq 5 ];then
echo "当前内核主版本为5"
if [ $second -ge 14 ];then
echo "当前内核主版本为$primart ,此版本为$second ,符合要求"
else
echo "此版本不符合要求,请升级"
fi
else
echo "当前主版本为$primart ,不符合要求,请升级"
ficase选择结构
分支判断结构超过3个分支,一般建议采用case多分支结构
#!/bin/bash
case $变量 in
模式1)
命令1
;;
模式2)
命令2
;;
*))
默认命令
;;
esac
;;分支结束符,这个分支的代码到这里就结束了,匹配到这个分支后,执行完命令就直接跳出整个 case,不再往下匹配其他模式
;;执行完当前分支,直接跳出整个case(最常用)
;&执行完当前分支,继续执行下一个分支的命令(贯穿)
;;&执行完当前分支,继续匹配后面的模式
esac case 语句的结束标记,就像 if 语句里的 fi(if 倒过来写)它就是把 case 这个单词倒过来写
例子1,当给程序传入start、stop、reload三个不同参数时分别执行相应命令
case "$1" in
start)
systemctl $1 nginx
;;
stop)
systemctl $1 nginx
;;
reload)
systemctl $1 nginx
;;
*)
echo "你会吗,不会查查再来"
;;
esac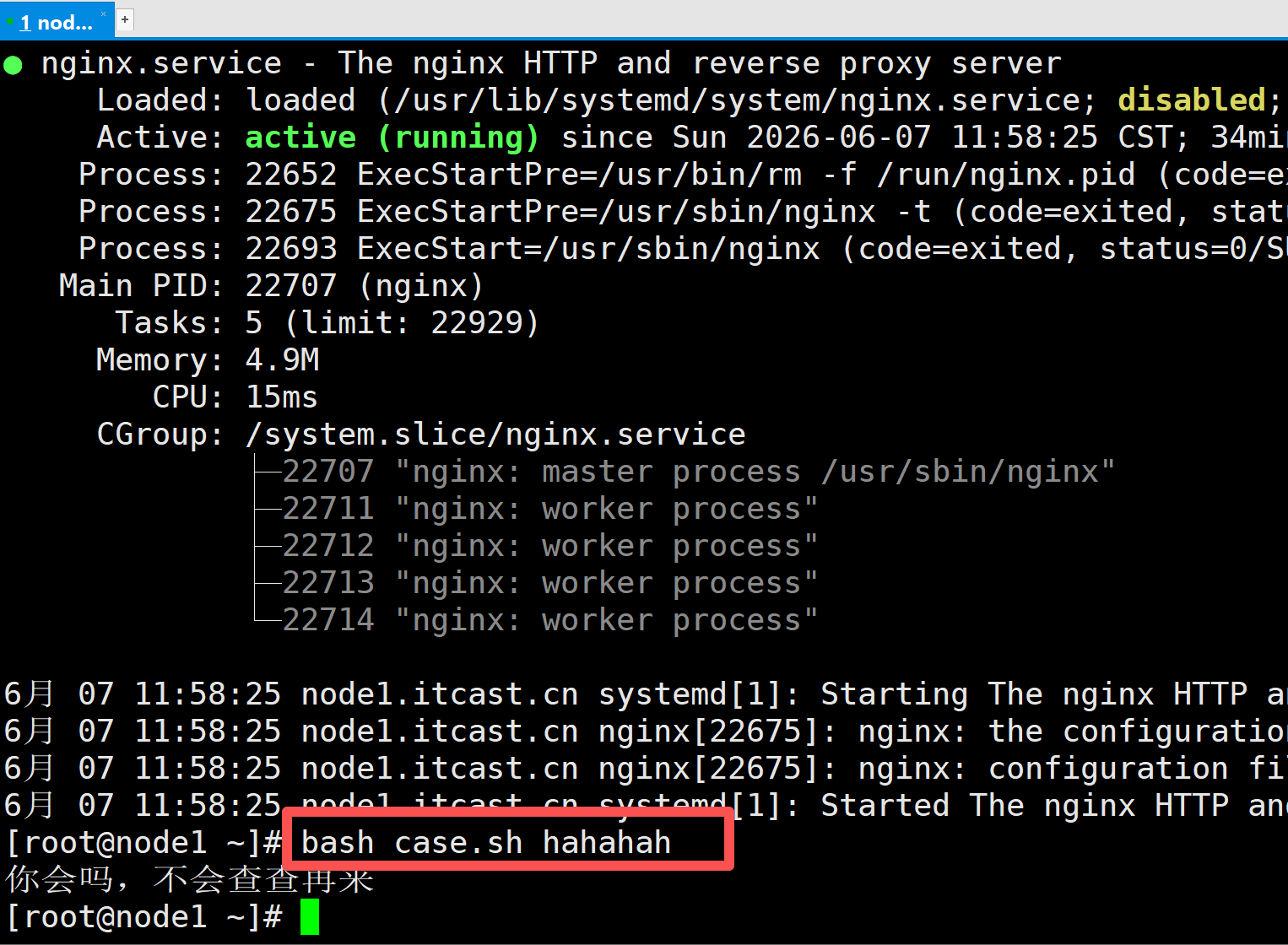
例子2,脚本提示让用户输入需要管理的服务名,然后提示用户需要对服务做什么操作,如启动,关闭,重启
#!/bin/bash
read -p "请输入你要操作的服务名:" service
read -p "请输入你要进行的操作:" action
case $action in
start)
systemctl start $service
;;
stop)
sysytemctl stop $service
;;
status)
systemctl status $service
;;
*)
echo "你会吗,不会的话查一下我们的帮助手册再来吧"
esacwhile循环
条件为真就进入循环;条件为假就退出循环
作用:高效重复的执行任务
while 条件
do 命令
done
例1:用while循环计算1-100的偶数和
#!/bin/bash
i=1
while [ $i -le 10 ]
do
echo "lernlern study dayday up"
let i++
done
#方法2
echo "------------"
i=1
while [ $i -le 10 ]
do
echo "好好学习,天天向上"
i=$(($i+1))
done$(()) 是 Bash 里的算术展开运算符,专门用来做整数计算。
- 把括号里的数学表达式算出来,返回结果
- 支持加减乘除、取模、自增等整数运算
- 语法固定:
$(( 表达式 ))
例子2,1-100累加的和
#!/bin/bash
num=1
sum=0
while [ $num -le 100 ]
do
sum=$(($sum+$num))
let num++
done
echo "1到100的和为$sum"while循环嵌套if
用while循环计算1-100的偶数和
#!/bin/bash
num=1
sum=0
while [ $num -le 100 ]
do
if [ $(( $num%2 )) -eq 0 ];then
sum=$(( $sum + $num ))
fi
let num++
done
echo "1-100的偶数和为$sum"- 先通过
$(( $num%2 ))算出余数(0 或 1) - 再用
-eq 0判断余数是否为 0 - 把当前的
num加到sum变量里,实现累加

- 初始时
sum=0,第一次循环num=2:sum=$((0+2))→sum变成2 - 第二次循环
num=4:sum=$((2+4))→sum变成6 - 以此类推,最终
sum会变成 1-100 所有偶数的和2550
while true死循环
定界符,可以自定义,默认用EOF,End Of File,在 shell 里就是多行文本的开始 / 结束标记,配合 << 用,方便批量写多行内容
<<EOF:开始,下面所有行都当作输入内容中间内容:你要写的多行文字
EOF:结束,告诉 shell "内容到此为止"
cat <<EOF
XXX
XXX
EOF放在循环前:只要执行这个脚本就先看见定界符中间的内容
#!/bin/bash
cat <<EOF
h 显示命令帮助
f 显示磁盘分区
l 显示磁盘情况
d 显示内存情况
u 显示负载
q 退出
EOF
while true
do
read -p "请输入您要查询的内容(h|f|l|d|u|q)" action
case $action in
h)
cat <<EOF
h 显示命令帮助
f 显示磁盘分区
l 显示磁盘情况
d 显示内存情况
u 显示负载
q 退出
EOF
;;
f)
fdisk -l
;;
l)
df -h
;;
d)
free -h
;;
u)
uptime
;;
q)
exit
;;
*)
echo "你会吗,来看一下帮助手册呀"
esac
donefor循环
列表循环
字符串列表
Shell 会把字符串按空格、制表符、换行符自动拆分,不管你是不是想把它当成一个整体
#!/bin/bash
list="1 2 3 4"
for variable in $list
do
echo "$variable"
done-
variable是循环里的临时变量,每次循环都会被赋值为列表里的一个元素。 -
$list是要遍历的对象,$表示取出变量list的值(也就是"1 2 3 4")。 -
循环会自动按空格把
1 2 3 4拆成 4 个元素:1、2、3、4,依次赋值给variablefor var in {1..10};do echo var;done for var in 1 2 3 4 5;do echo var;done
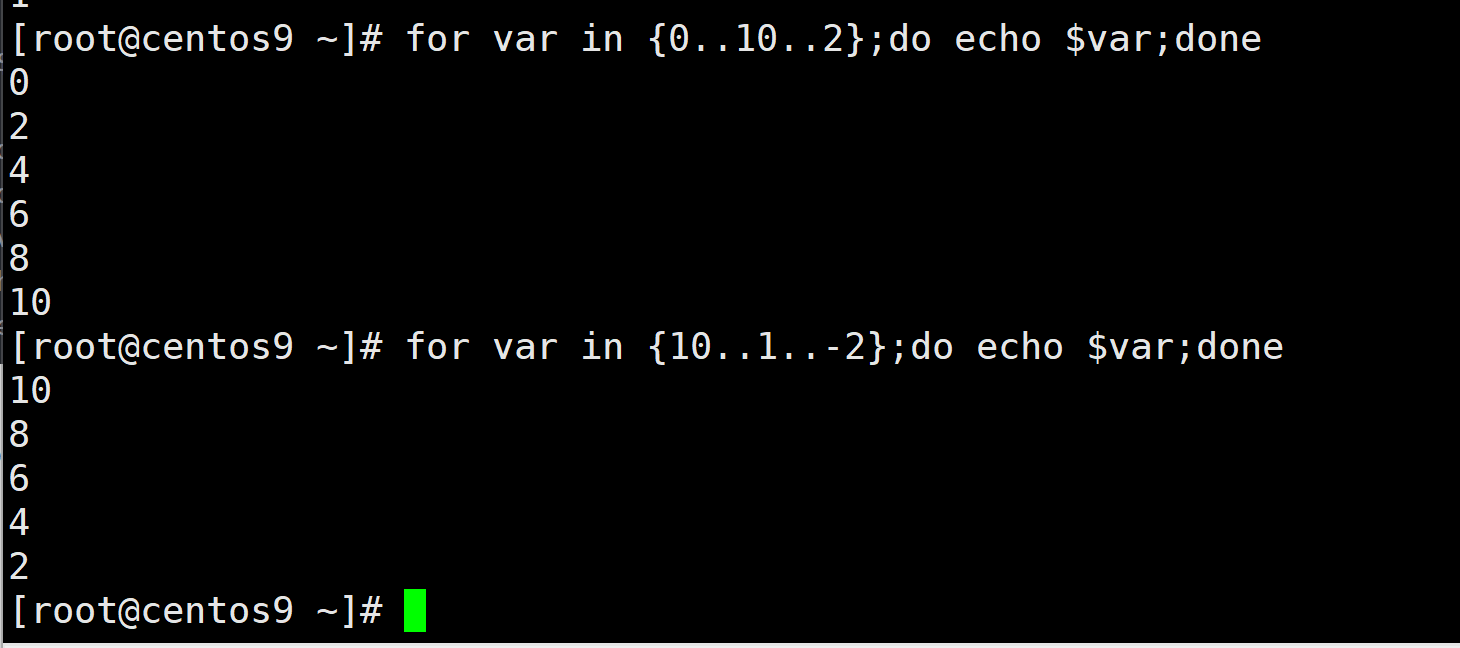
for var inseq 10;do echo var;done for var in (seq 10);do echo var;done for var in {0..10..2};do echo var;done
for var in {2..10..2};do echo var;done for var in {10..1};do echo var;done
for var in {10..1..-2};do echo var;done for var in `seq 10 -2 1`;do echo var;done
for var in {10..1..-2};do echo $var;done
注:{开始..结束..步长}
shell数组
"${arr[@]}" 是 Shell 数组的 "安全遍历" 写法,它会把数组里的每个元素当成独立的整体,不会被空格拆分。
获取所有元素的值 :
"${arr[@]}"(一定要加双引号!)获取数组长度 :
${#arr[@]}通过索引获取元素 :
${arr[$i]}
例子1,
arr1=(1 2 3 4 5)
for i in "${arr1[@]}"
do
echo $i
done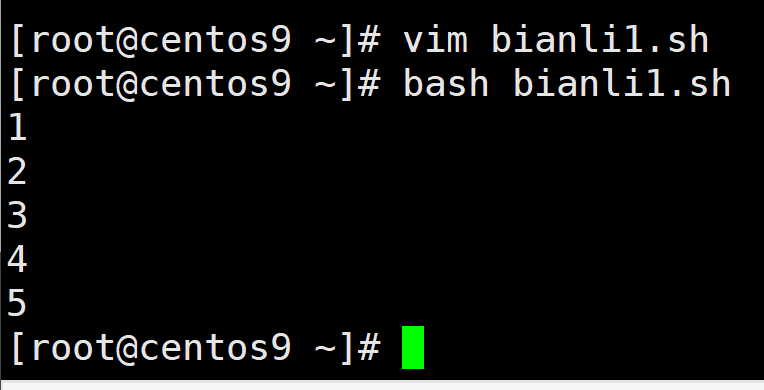
"${arr1[@]}"→ 把数组arr1的每个元素挨个拿出来- 每一轮循环:把当前元素赋值给 i
echo $i→ 打印 i 的值
例子2,索引数组
arr1=(1 2 3 4 5)
len="${#arr[@]}"
for ((i=0;i<len;i++))
do
echo "${arr1[$i]}"
done arr1=(1 2 3 4 5)
定义了一组数组arr1,包含元素 1 2 3 4 5,索引从 0 开始,索引0对应1...索引4对应5
len="${#arr@}"
${#arr1[@]} 是获取数组长度的固定语法,这里会得到 5
定义变量len等于数组的长度
for ((i=0;i<len;i++))
- 这是 Shell 里的「C 风格 for 循环」,专门用来做数字递增 / 递减的循环:
i=0:初始化循环变量i为 0(对应数组的第一个索引)i<len:循环条件,只要i小于数组长度5,就继续循环i++:每次循环结束后,i自增 1
- 循环中
i的值会依次变成0 → 1 → 2 → 3 → 4,刚好对应数组的所有索引
do
echo "{arr1\[i]}"
done
${arr1[$i]}是通过索引获取数组元素的固定写法:${数组名[索引值]}- 当
i=0→${arr1[0]}→ 输出1 - 当
i=1→${arr1[1]}→ 输出2 - ...... 一直到
i=4→${arr1[4]}→ 输出5
- 当
do和done是循环的开始和结束标记,中间是每次循环要执行的代码。
不带列表循环
它的默认行为:自动遍历脚本运行时传递的所有命令行参数。
这就是它的设计初衷:专门用来接收脚本外部传进来的参数,不用提前写死列表。
#把所有命令行参数,依次赋值给
variable变量for variable
do 命令1
命令2
...
done
类C风格for循环
for (( 变量初始值; 循环条件判断; 更新变量))
do
命令
done
for in是「遍历列表 / 数组 / 参数」的循环for (( ))是「靠计数器控制循环次数」的循环
for (( )) 循环最大的好处是:完全由你控制循环的开始、结束和步长,特别适合:
- 固定次数的循环(比如循环 10 次)
- 按数字规律变化的场景(倒序、跳步)
- 需要通过索引操作数组的场景
例子1,求1-100的奇数的和
#!/bin/bash
sum=0
for ((i=1;i<=100;i+=2))
do
let sum=$sum+$i
done
echo "$sum"i=1:计数器从1开始i<=100:只要i不超过 100,就继续循环i+=2:每次循环i增加 2(步长为 2)
let是 Shell 里专门用来做整数运算的命令,这里的作用是把当前的sum加上i,再赋值给sum。- 等价于
sum=$((sum + i)),每次循环都会把当前奇数累加到sum里。
循环中的关键词
continue 继续,当满足某个条件时,跳过本次循环剩下的代码,立刻开始下一次循环
break 终止循环,当满足某个条件时,立刻终止当前所在的循环,不再执行后续循
exit 终止脚本,当满足某个条件时,立刻终止整个脚本的执行,后面所有代码(包括循环外的)都不会再执行
嵌套循环的特点
1.外层循环控制行,内层循环控制列
2.外层循环1次,内层循环一圈
3.内外层循环变量互不干扰,但不要重名。重名时:内层变量会覆盖外层变量,导致逻辑乱
例子1,打印到7的倍数就跳过
#!/bin/bash
for ((i=1;i<=10;i++))
do
if [ $(( $i % 7 )) -eq 0 ];then
continue
fi
echo $i
done 例子2,打印1-10,遇到5停止
for (( i=1;i<10;i++ ))
do
if [ $i -eq 5 ];then
break
fi
echo $i
done 例3:批量加5个新用户,以u1到u5命名,并统一加一个新组,组名为class,统一改密码为123
#!/bin/bash
cat /etc/group | grep -w class >/dev/null
if [ $? -eq 1 ];then
groupadd class >/dev/null
fi
for (( i=1;i<=5;i++ ))
do
useradd -G calss "u$i" >/dev/null
echo "u$i:123" | chpasswd
done 在/etc/group里看一下有没有一个叫class的组,grep -w 这个w是word 匹配单词,然后把输出内容把放到黑洞不在终端显示,$?看一下上一步的执行结果,返回0就是找到了一个叫class的组,返回1就是没有这么一个组 then 然后groupadd class我们添加一个叫class的组,输出的结果扔到黑洞,终端不显示,我们静默创建fi这个循环结束
do done这边 添加用户 -G添加用户的时候指定组 用户名 我们用双引号引起来,可以读取里面的变量,>/dev/null静默创建用户,修改秘密,输出"用户名:123"管道给chpasswa命令,批量修改用户密码,依旧双引号把变量引起来
例子4;:写一个脚本,局域网内,把能ping通的IP和不能ping通的IP分类, # 并保存到两个文本文件里,这是一个局域网内机器检查通讯的一个思路
ip1=192.168.88
FILE1="/1.txt"
FILE2="/2.txt"
>$FILE1
>$FILE2
for(( i=1;i<=10;i++ ))
do
{
ip="$ip1.$i"
ping -c1 $ip &>/dev/null
if [ $? -eq 0 ];then
echo "$ip" >> $FILE1
else
echo "$ip" >> $FILE2
fi
}&
done随机数
set |grep RANDOM 默认有一个$RANDOM的变量 默认是0~32767。
#查看上一次产生的随机数
echo $RANDOM产生0~x之间的随机数
产生0-1之内的随机数
echo $[$RANDOM%2]
#产生0~9内的随机数
echo $[$RANDOM%10]
#产生0~100内的随机数
echo $[$RANDOM%101]产生50-100之内的随机数
echo $[$RANDOM%51+50]为什么是
+50?
$RANDOM % 51得到的结果是0 ~ 50之间的数- 我们想要的是从
50开始,所以给每个数都加上50:
0 + 50 = 50(最小值)50 + 50 = 100(最大值)- 这样就刚好覆盖了 50~100 的所有数
产生三位数的随机数
echo $[$RANDOM%900+100]Shell 里生成
[min, max]之间随机整数的通用公式 是:echo \[ RANDOM % (max - min + 1) + min ]
max - min + 1:这是随机数的总个数+ min:把模运算得到的「0~(总个数 - 1)」偏移到你想要的起始范围也就是说当我想生成一个x到y的随机数时(x<y)
我敲
echo $RANDOM%** (y-x+1)**+** x**
例1,写一个脚本,产生一个phonenum.txt文件,随机产生以139开头的手机号10个
#!/bin/bash
FILE=/phonenum.txt
> "$FILE"
for ((i=1;i<=10;i++))
do
num1=$[ $RANDOM % 9000 + 1000 ]
num2=$[ $RANDOM % 9000 + 1000 ]
phone="139${num1}${num2}"
echo $phone >> $FILE
done
echo "已生成10个手机号到"$FILE""手机号是11位,139固定了,后面的随机数是8位,我们再拆分成两个随机4位数num1,num2
例2,批量创建5个用户,每个用户的密码为一个五位随机数
#!/bin/bash
for ((i=1;i<=5;i++))
do
username="user$i"
passwad=$[ $RANDOM % 90000 + 10000 ]
if id "$username" &>/dev/null;then
echo -e "用户$username 已存在,跳过创建 \n 用户密码在/root/user_info.txt查看"
continue
fi
useradd "$username" &>/dev/null
if [ $? -ne 0 ];then
echo "用户$username 创建失败"
continue
fi
#设置密码
echo "$username:$passwad" | chpasswd &>/dev/null
echo "用户$username创建成功,密码:$passwad" | tee -a /root/user_info.txt
echo "用户密码储存在/root/user_info.txt可随时查看"
donepwgen工具产生随机密码
dnf install -y pwgenpwgen 是 Password Generator(密码生成器)的缩写
它是一个 Linux 命令行工具,专门用来生成随机密码
pwgen [选项] [密码长度] [生成个数]常用:
-c:包含大写字母-n:包含数字-s:生成完全随机、不可读的强密码-y:加特殊符号(!@#...)-1:一行只输出一个密码- -B:生成密码时不同时出现类似易混淆的字符(如 l、1、O、0)
💡 补充一下:这个工具生成的密码默认是 "易读易记" 的格式
🔤 什么是 pwgen 的 "易读易记" 格式?
pwgen 默认生成的密码,是基于英文音节结构的 "伪单词",不是完全随机乱码。它的设计逻辑是:
- 按照 "辅音 + 元音 + 辅音" 的结构生成
- 让密码读起来像一个有发音规则的单词,更容易被大脑记住
- 同时保持足够的随机性,不会是真实存在的英文单词(避免被字典攻击)
pwgen 12 1
pwgen -cn1 12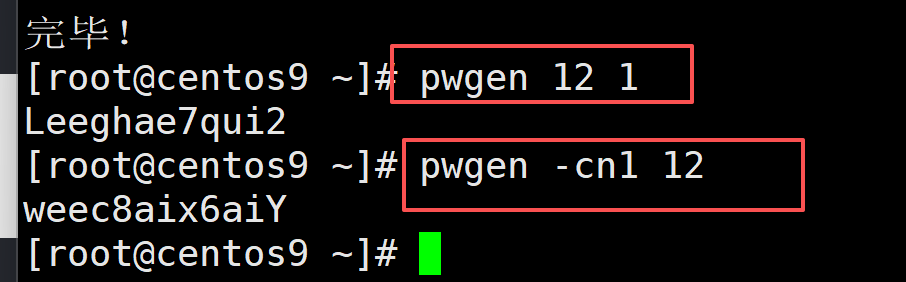
完全随机模式,安全模式
pwgen -s 12 1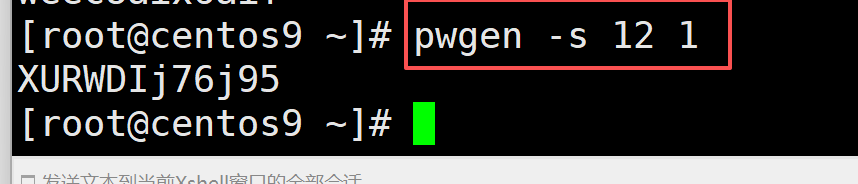
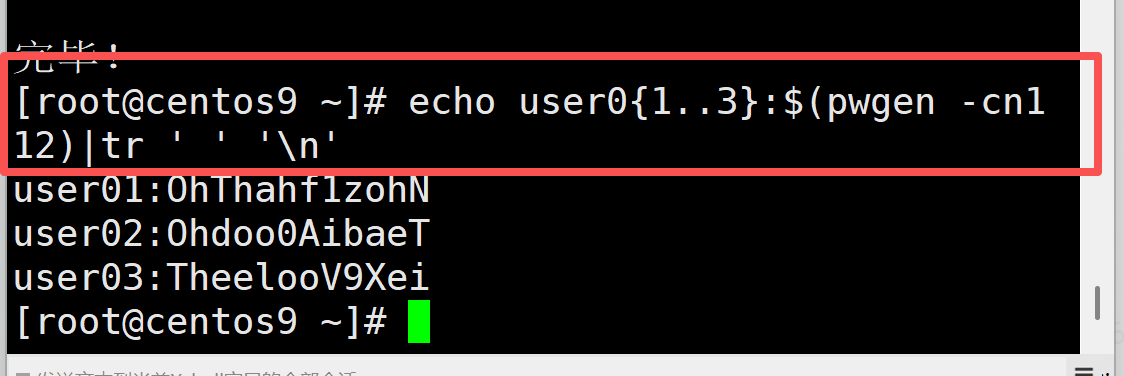
1,批量生成 3 个用户的 用户名:密码 格式数据,方便后续用 chpasswd 一键设置密码。
echo user0{1..3}:$(pwgen -cn1 12)|tr ' ' '\n'