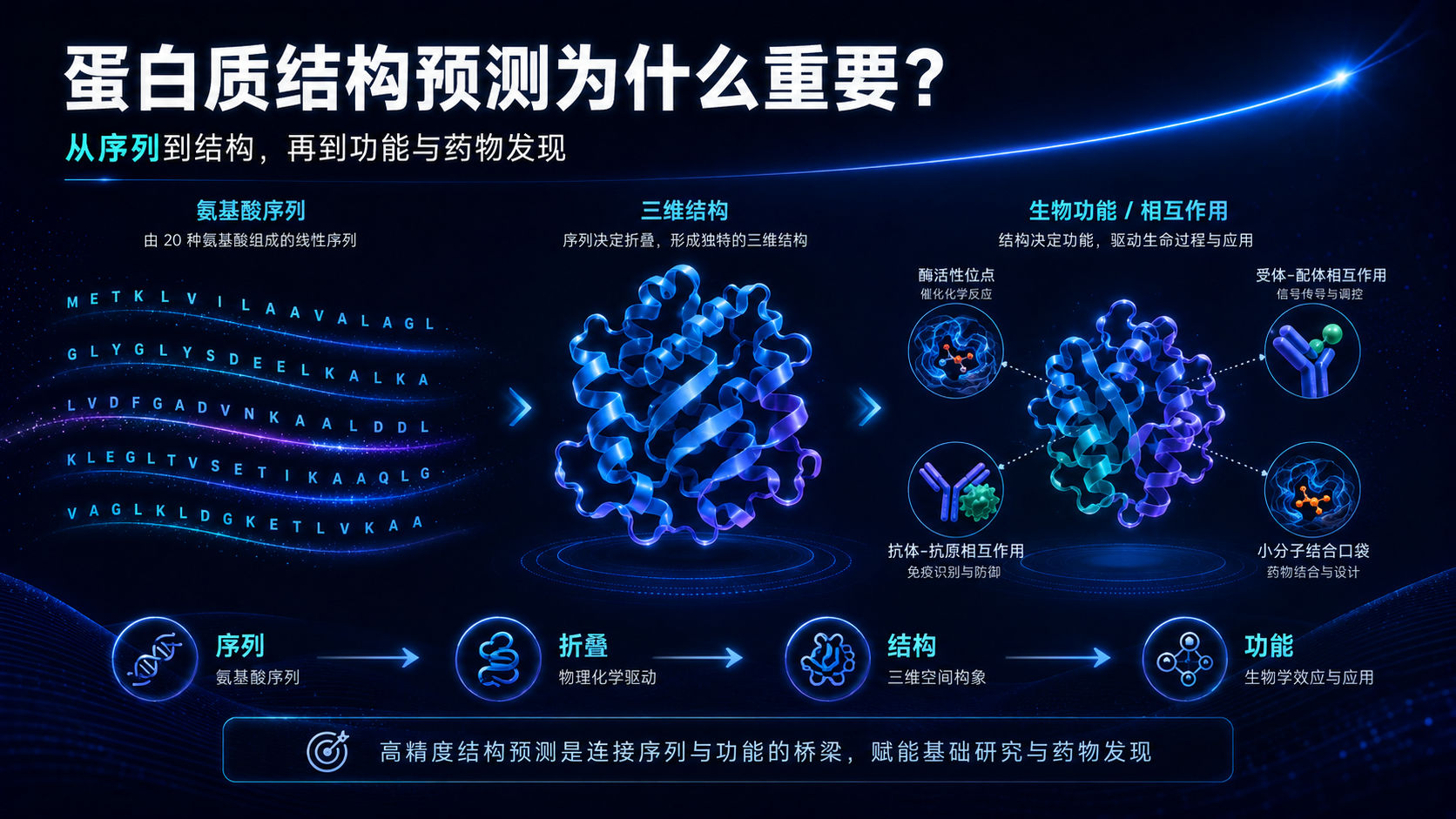
蛋白质结构预测曾经是生命科学中最有代表性的难题之一。
我们知道,蛋白质由氨基酸序列组成。序列像一串文字,写着 A、L、G、K、D、E、Y、W 这些氨基酸字母。但蛋白质真正发挥功能,并不是靠这串字母平铺在纸面上,而是靠它折叠成特定三维结构之后,像一台微型机器一样工作。
酶为什么能催化反应?
抗体为什么能识别抗原?
受体为什么能感知信号?
小分子药物为什么能进入蛋白口袋?
突变为什么会导致疾病?
这些问题最终都离不开蛋白质结构。
如果蛋白质序列是生命写下的一串文字,那么蛋白质结构就是这串文字折叠成的立体机器。真正决定它能否工作、如何工作、和谁相互作用的,往往是这个立体机器的形态。
长期以来,研究者主要依靠 X 射线晶体学、冷冻电镜和核磁共振等实验方法解析蛋白结构。这些方法非常准确,也构成了现代结构生物学的基础。但它们通常周期长、成本高,对样品质量要求高,也很难覆盖自然界中海量蛋白。
于是,一个持续了几十年的问题摆在研究者面前:
能不能只根据蛋白质氨基酸序列,预测它会折叠成什么三维结构?
AlphaFold 系列模型,就是围绕这个问题逐步演进出来的。
从 AlphaFold1 到 AlphaFold2,再到 AlphaFold-Multimer 和 AlphaFold3,这条路线不仅是一个模型版本的更新,更是一条能力边界不断扩展的技术演进史:
AlphaFold1:从序列预测残基距离和空间约束;
AlphaFold2:端到端预测单链蛋白三维结构;
AlphaFold-Multimer:从单链走向蛋白复合物;
AlphaFold3:从蛋白结构预测走向多分子相互作用预测。
这篇文章就围绕这条主线,梳理 AlphaFold1 到 AlphaFold3 到底改变了什么。
一、为什么蛋白质结构预测如此重要?
蛋白质的功能不是由序列单独决定的,而是由序列、结构、动态构象和分子相互作用共同决定的。
同样一条氨基酸序列,如果无法正确折叠,就可能失去功能;如果局部结构发生变化,就可能改变结合能力;如果一个关键残基突变,就可能破坏催化位点、配体口袋或蛋白-蛋白相互作用界面。
这也是结构生物学重要的原因。
对于基础研究来说,结构可以帮助我们理解蛋白如何工作。对于药物研发来说,结构可以帮助我们找到结合口袋、解释突变机制、设计小分子、抗体、肽类或蛋白 binder。对于蛋白工程来说,结构可以指导稳定性优化、酶活改造和新功能设计。
但是,实验结构解析并不容易。
很多蛋白难以表达,难以纯化,难以结晶;膜蛋白、柔性蛋白、多结构域蛋白、复合物和瞬时相互作用体系更是困难。即使冷冻电镜推动了结构解析革命,实验结构仍然无法覆盖所有蛋白。
因此,计算结构预测的价值非常清楚:
它可以让研究者在没有实验结构的情况下,快速获得结构假设。
注意,是"结构假设",不是"实验真相"。
这个区分非常重要。AlphaFold 系列极大提高了结构预测能力,但它并没有让实验结构学失去意义。相反,它让实验验证变得更有方向。
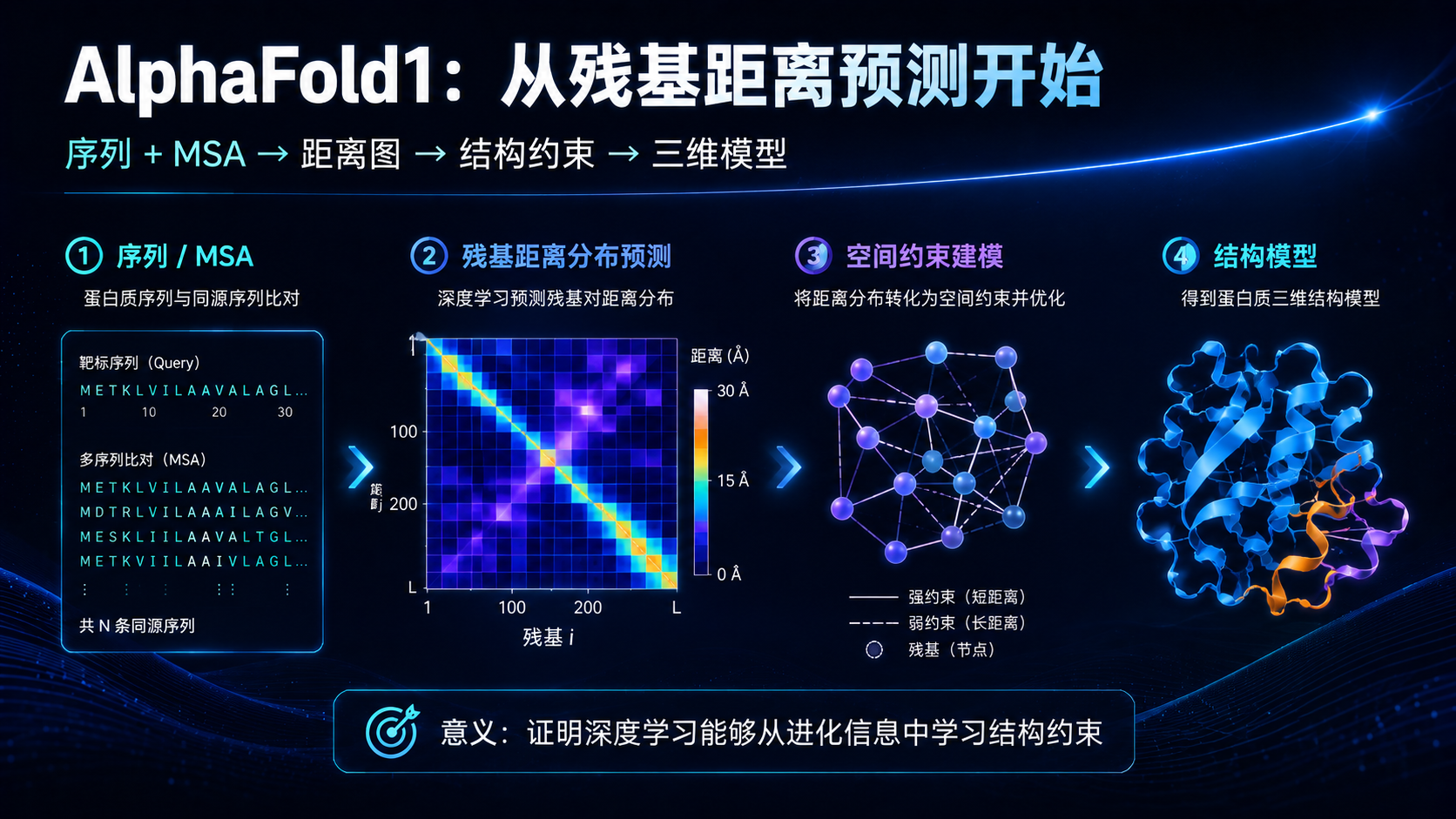
二、AlphaFold1:从残基距离预测开始的突破
AlphaFold1 是 DeepMind 在 CASP13 中展示的初代系统。
CASP 是蛋白质结构预测领域的重要评测。简单说,组织者会拿出一些尚未公开结构的蛋白,让不同团队根据序列预测结构,再和后续公开的实验结构进行比较。CASP 长期被视为结构预测模型的"高考"。
AlphaFold1 的意义在于,它把深度学习引入了蛋白结构预测的关键环节。
在 AlphaFold1 之前,蛋白结构预测常依赖同源建模、片段组装、物理采样和能量函数。它们在有相似模板时表现不错,但对缺少模板的新结构往往困难。
AlphaFold1 的核心思想是:先预测残基之间的距离关系,再根据这些空间约束构建三维结构。
所谓残基距离预测,可以这样理解。
一条蛋白序列是线性的,残基 10 和残基 200 在序列上可能相隔很远,但蛋白折叠之后,它们在三维空间中可能靠得很近。两个位置如果在进化中协同变化,也可能暗示它们在结构上存在接触。
AlphaFold1 试图利用序列、多序列比对和深度神经网络,预测残基对之间的距离分布。然后再把这些预测出来的距离关系作为空间约束,用优化方法构建蛋白三维结构。
这就像你没有看到一座建筑的完整图纸,但你知道很多房间之间的距离关系:A 房间离 B 房间很近,C 房间离 D 房间很远,某些墙必须相邻,某些结构不能交叉。根据这些约束,你就可以逐步还原建筑的大致形态。
AlphaFold1 还不是后来意义上的端到端结构预测模型。
它更像是把深度学习用于结构建模中的关键中间步骤:预测距离、预测构象约束,然后再进行结构优化。
但它的意义非常大。
它证明了深度学习可以从序列和进化信息中捕捉蛋白结构约束,让传统结构预测从"经验规则 + 物理采样"逐步转向"数据驱动 + 深度学习建模"。
AlphaFold1 是起点。
真正改变结构预测格局的,是 AlphaFold2。
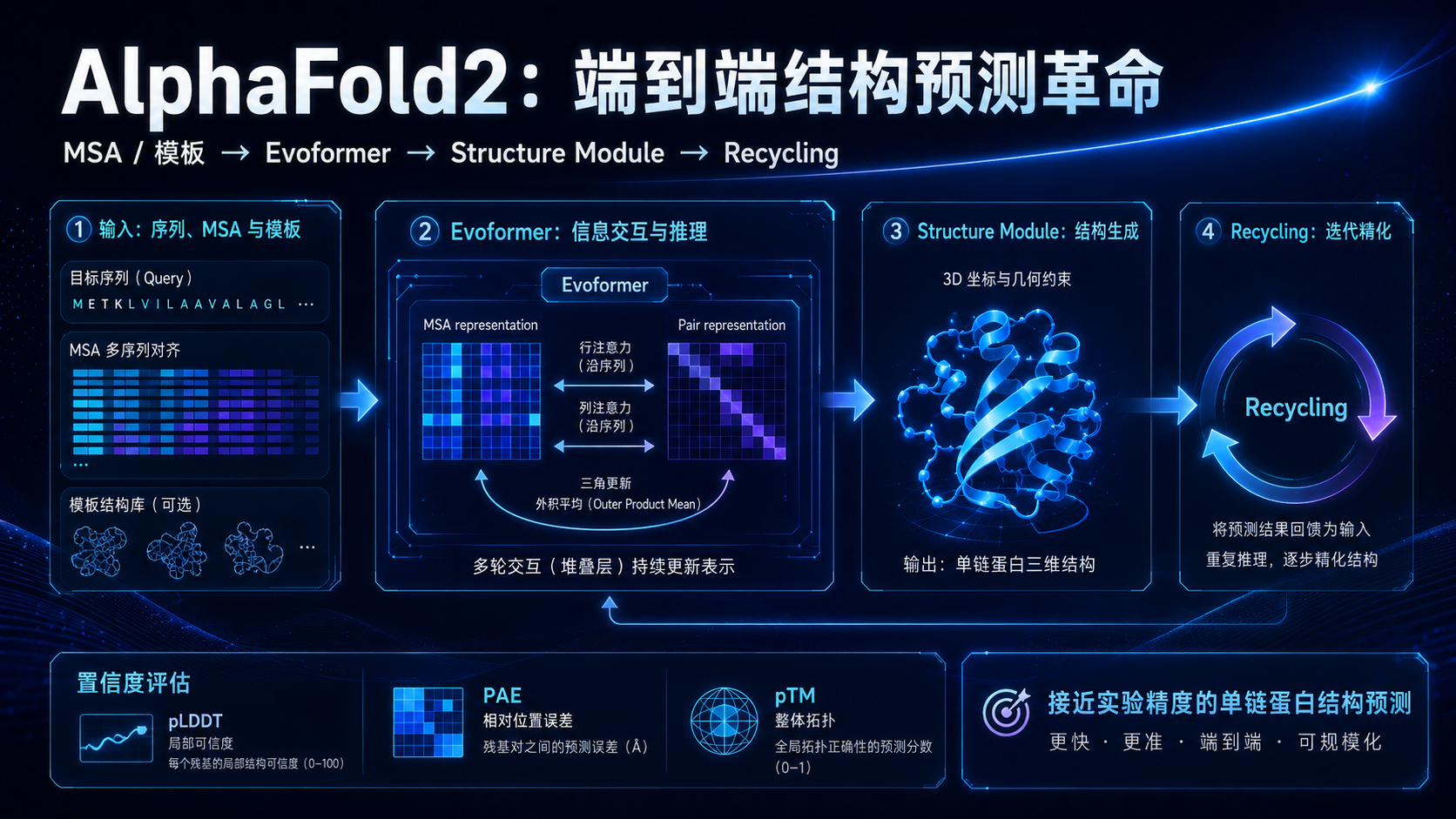
三、AlphaFold2:真正改变结构预测格局的模型
AlphaFold2 在 CASP14 中展示了接近实验精度的结构预测能力,并在 2021 年通过论文系统公布。
与 AlphaFold1 相比,AlphaFold2 的变化不是简单"模型变大了",而是建模思想发生了明显升级。
AlphaFold1 更像是先预测距离约束,再通过优化构建结构。
AlphaFold2 则更接近端到端结构预测:从序列、多序列比对和模板信息出发,在模型内部联合建模进化信息、残基关系和三维几何,最终直接输出蛋白结构。
这使 AlphaFold2 不只是预测"哪些残基可能接触",而是更完整地学习"这条序列应该如何在三维空间中折叠"。
AlphaFold2 的核心可以从几个模块理解。
1. MSA:从进化中寻找结构线索
MSA 是 multiple sequence alignment,也就是多序列比对。
它的作用是把一组同源蛋白序列对齐,观察不同物种或不同蛋白家族成员中哪些位置保守,哪些位置会共同变化。
如果两个残基在进化中经常协同变化,它们可能在三维结构中存在接触或功能耦合。
这就像研究一组语言文本的不同版本。如果两个词总是一起变化,说明它们之间可能存在语义关系。蛋白序列也类似,进化中的协同变化往往隐藏着结构关系。
AlphaFold2 非常重视 MSA,因为它提供了强大的进化共变信号。
2. Evoformer:把序列、进化和残基关系编织在一起
Evoformer 是 AlphaFold2 的核心表征模块。
它同时处理两类信息:一类是 MSA representation,也就是多序列比对中的信息;另一类是 pair representation,也就是残基与残基之间的关系表示。
简单说,Evoformer 的任务是让模型不断在"序列维度"和"残基对维度"之间交换信息。
它通过注意力机制、三角更新等方式,让模型逐渐理解哪些残基相关、哪些区域可能接近、哪些结构关系更合理。
如果把蛋白看作一座建筑,那么 Evoformer 就像一个不断整合家族历史、建筑材料、空间距离和结构约束的设计系统。它不是只看一个点,而是同时看整张结构关系网。
3. Structure Module:把内部表征变成三维坐标
Evoformer 产生的是模型内部的高维表征。真正要输出结构,还需要结构模块。
Structure Module 的作用,是把这些表征转化为三维空间中的原子坐标。
其中一个重要思想是 invariant point attention,也就是让模型在三维空间中处理残基之间的几何关系,同时避免坐标系旋转和平移带来的干扰。
换句话说,蛋白质结构不应该因为我们换了观察角度就变了。模型需要理解真正的几何关系,而不是依赖某个固定坐标系。
这让 AlphaFold2 能够更自然地处理三维结构预测问题。
4. Recycling:先画草图,再反复修改
AlphaFold2 还有一个很重要的设计,叫 recycling。
它会把前一次预测得到的结果再送回模型中,进行下一轮精修。
这个过程很像画建筑图。第一轮先画出大概结构,第二轮发现某些区域不合理,再调整;第三轮继续修正空间关系,直到结构逐渐收敛。
Recycling 让模型不仅一次性预测结构,而是可以反复自我修正。
这也是 AlphaFold2 能取得高精度结果的重要原因之一。
5. 置信度指标:不要只看结构图好不好看
AlphaFold2 不只输出结构,还输出置信度指标。
pLDDT 用于评估局部结构可信度。一般来说,高 pLDDT 区域更可信,低 pLDDT 区域可能是柔性区、无序区或模型不确定区域。
PAE 用于评估不同区域之间相对位置的不确定性。对于多结构域蛋白,某个结构域内部可能预测很好,但结构域之间的相对位置可能不可靠,这时就需要看 PAE。
pTM 更关注整体拓扑可信度。
ipTM 更多用于复合物或链间关系评估。
这些指标非常重要,因为 AlphaFold 结果不是只看图。一个结构渲染得再漂亮,如果低置信区很多,或者结构域相对位置不确定,就不能过度解释。
AlphaFold2 的真正价值,不只是它预测得准,而是它把结构预测变成了一个可以大规模、标准化、带置信度评估的工具。
四、AlphaFold DB:从模型突破到结构数据库革命
AlphaFold2 的影响,不只在模型本身,还在 AlphaFold Protein Structure Database。
过去,实验结构数据库中的结构数量远远少于已知蛋白序列数量。大量蛋白只有序列,没有结构。
AlphaFold DB 改变了这个格局。
它为大量物种和蛋白提供预测结构,使研究者可以快速查询此前没有实验结构的蛋白模型。对于功能注释、蛋白家族分析、突变解释、靶点研究和药物发现,这都是非常重要的资源。
这相当于给生命科学补上了一张巨大的结构地图。
但这张地图仍然是"预测地图"。
高置信区域可以提供非常有价值的结构假设;低置信区域、无序区、多构象区域、复合物状态和配体结合状态仍需要谨慎解释。
尤其在药物研发中,不能因为 AlphaFold DB 里有一个靶点预测结构,就直接认为它可以替代实验结构进入精准药物设计。
结构预测可以让我们更快提出假设,但不能免除验证。
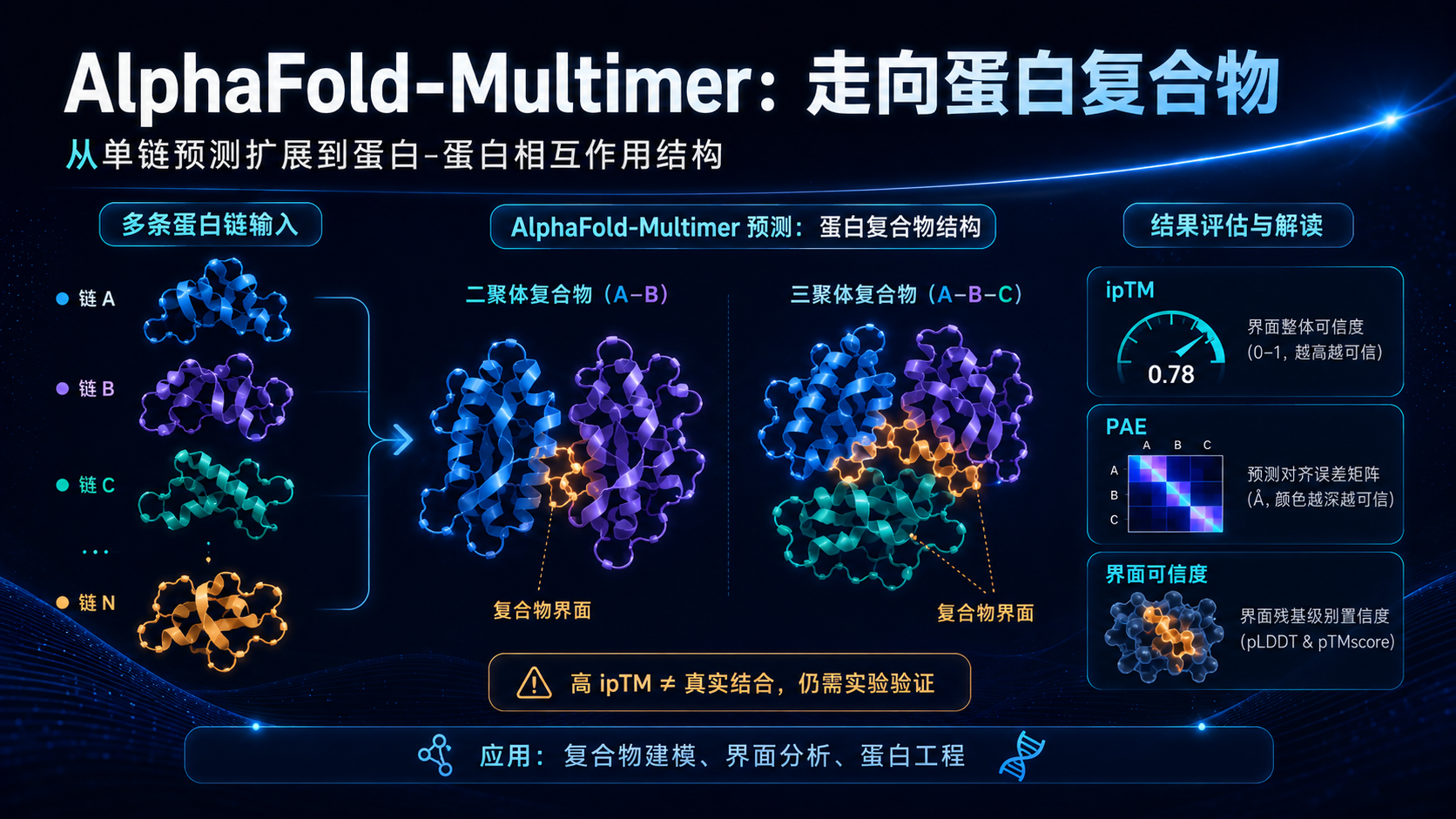
五、AlphaFold-Multimer:从单链结构走向蛋白复合物
AlphaFold2 主要解决的是单链蛋白结构预测。
但真实生物系统中,很多蛋白不是单独工作的。它们组成二聚体、多聚体、复合物,参与信号传导、转录调控、免疫识别、酶复合体组装和细胞骨架构建。
因此,从单链蛋白结构预测走向蛋白复合物预测,是自然的发展方向。
AlphaFold-Multimer 就是这个阶段的重要扩展。
它可以输入多条蛋白链序列,预测它们可能形成的复合物结构。它对同源多聚体、异源多聚体、蛋白-蛋白相互作用界面建模等任务具有重要价值。
在实际研究中,AlphaFold-Multimer 可以帮助研究者提出复合物结构假设,理解可能的结合界面,辅助设计突变实验,分析蛋白互作模式。
但它也有明显局限。
复合物预测比单链预测更难。因为它不仅要预测每条链自己如何折叠,还要预测链与链之间是否真实结合、以什么姿势结合、界面是否稳定。
一个模型预测出复合物,并不等于这些蛋白在真实细胞环境中一定相互作用。
高 ipTM 不等于真实结合。
预测界面不等于实验验证相互作用。
复合物结构模型不等于亲和力、动力学和功能效应。
因此,AlphaFold-Multimer 最适合被看作复合物结构假设生成工具,而不是蛋白相互作用的最终裁判。
六、AlphaFold3:从蛋白折叠走向生命分子相互作用
AlphaFold3 的核心变化,是预测范围从蛋白进一步扩展到更广泛的生命分子复合物。
AlphaFold2 主要关注蛋白结构。
AlphaFold-Multimer 关注蛋白-蛋白复合物。
AlphaFold3 则进一步尝试预测蛋白、DNA、RNA、小分子配体、离子和修饰残基等组成的复合物结构。
这意味着问题从"蛋白如何折叠",推进到了"生命分子如何相互作用"。
这个变化非常重要。
因为在真实生命系统中,蛋白很少孤立存在。它可能结合 DNA 调控转录,结合 RNA 参与剪接,结合小分子执行酶催化,结合金属离子维持结构,经过磷酸化、糖基化等修饰改变功能。
药物研发更是如此。小分子药物、核酸药物、抗体、蛋白降解剂、分子胶、PROTAC,本质上都与分子相互作用密切相关。
AlphaFold3 使用了更新的架构,并引入扩散式结构生成思想,用于预测多类型生物分子的联合三维结构。
可以这样理解:
AlphaFold2 像是解决"这台蛋白质机器长什么样"。
AlphaFold3 则进一步问:"这台机器如何和其他零件、钥匙、开关、线路连接在一起?"
对药物研发来说,这无疑有吸引力。
如果模型可以辅助预测蛋白-小分子结合构象、蛋白-DNA 复合物、蛋白-RNA 复合物、蛋白-离子相互作用,那么它就可能为机制研究、药物设计、结构生物学和分子工程提供更多结构假设。
但这里必须冷静。
AlphaFold3 预测复合物结构,不等于真实结合亲和力。
预测小分子结合姿势,不等于 docking 或自由能计算已经完成。
预测某种分子相互作用,不等于该相互作用在细胞中一定发生。
预测结果更不能直接等同于药物活性或临床有效性。
它让我们更快看到可能的相互作用结构,但最终仍然需要实验和其他计算方法验证。
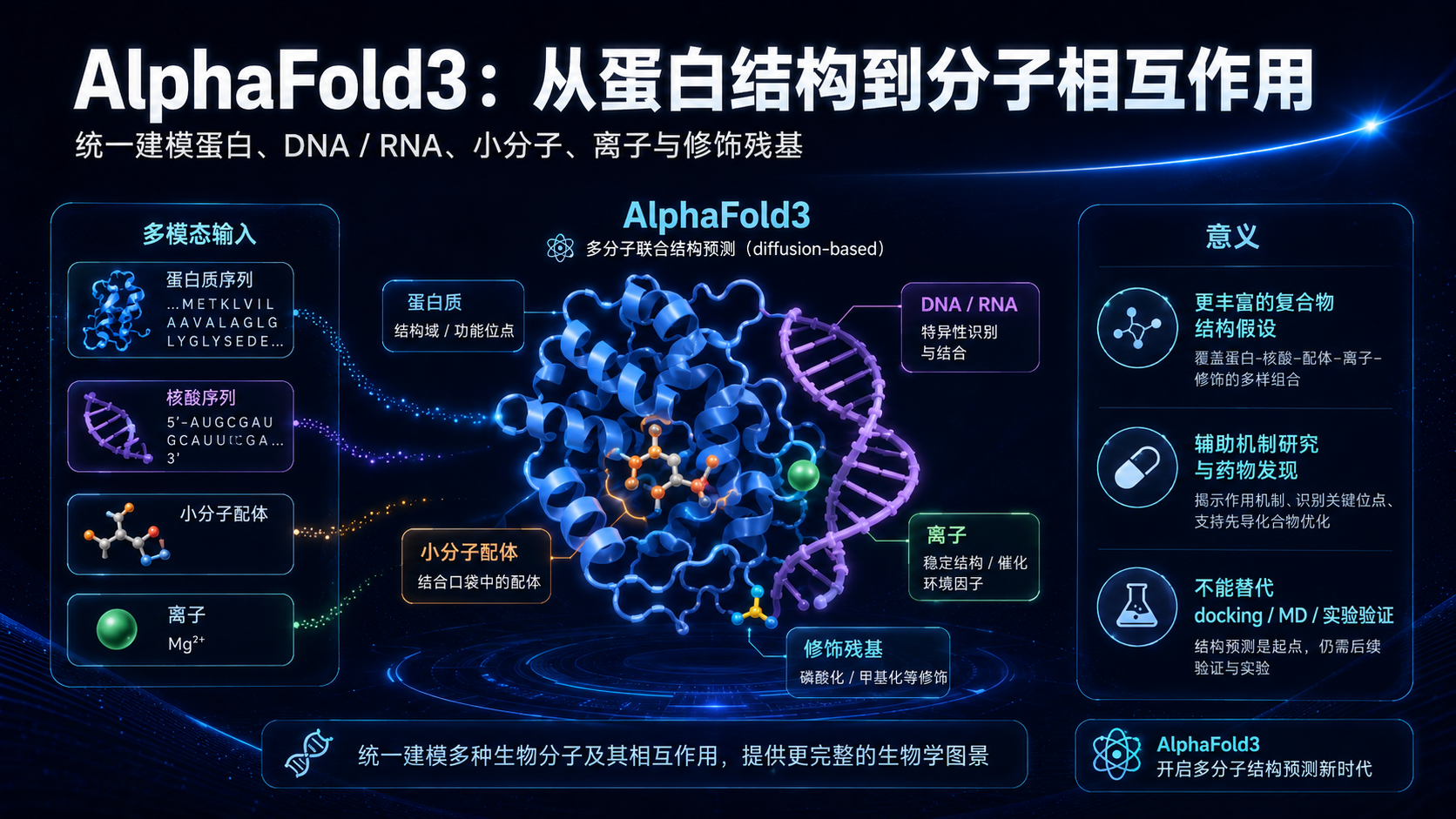
七、AlphaFold1、AlphaFold2、AlphaFold-Multimer、AlphaFold3 的核心差异
如果用一句话总结它们的演进:
AlphaFold1 预测结构约束,AlphaFold2 预测单体结构,AlphaFold-Multimer 预测蛋白复合物,AlphaFold3 预测多分子相互作用。
从任务目标看:
AlphaFold1 的目标是通过深度学习预测残基距离和构象约束,再构建蛋白结构。
AlphaFold2 的目标是高精度预测单链蛋白三维结构。
AlphaFold-Multimer 的目标是预测多条蛋白链组成的复合物。
AlphaFold3 的目标是预测蛋白、核酸、小分子、离子、修饰残基等多类型生命分子的联合结构。
从技术思想看:
AlphaFold1 是距离分布预测加结构优化。
AlphaFold2 是 Evoformer、Structure Module 和 recycling 组成的端到端结构预测体系。
AlphaFold-Multimer 是基于 AlphaFold2 思路扩展到多链蛋白复合物。
AlphaFold3 则引入扩散式联合结构生成思想,面向多分子体系。
从输出结果看:
AlphaFold1 输出蛋白结构模型。
AlphaFold2 输出单链蛋白结构和置信度。
AlphaFold-Multimer 输出蛋白复合物结构。
AlphaFold3 输出多类型分子复合物结构假设。
从生命科学意义看:
AlphaFold1 证明 AI 可以显著提升蛋白结构预测。
AlphaFold2 改变了结构生物学的工作方式。
AlphaFold-Multimer 推动蛋白相互作用结构建模。
AlphaFold3 则把结构预测从蛋白折叠推进到生命分子相互作用。
这条路线体现了一个清晰趋势:
AI 结构预测的边界,正在从单个蛋白,走向复合物,走向分子相互作用网络。
八、AlphaFold 对 AIDD 和药物研发的影响
AlphaFold 系列对 AIDD 的影响非常深。
1. 靶点结构补全
很多疾病相关靶点缺少实验结构。AlphaFold2 可以提供初始结构模型,用于结构域分析、突变解释、功能位点判断和口袋分析。
这对早期靶点研究很有帮助。
例如,如果一个疾病突变位于蛋白核心区域,可能影响折叠稳定性;如果位于表面界面,可能影响蛋白相互作用;如果靠近活性位点,可能影响酶功能。
这些判断都需要结构背景。
2. 药物结合机制假设
AlphaFold3 可以辅助提出蛋白-小分子、蛋白-核酸、蛋白-离子等复合物结构假设。
这对理解作用机制有帮助。
但要注意,结合姿势预测不等于真实亲和力。药物结合涉及构象变化、溶剂效应、熵贡献、动力学过程和细胞环境。单个预测复合物结构不足以证明药物有效。
3. 蛋白工程与抗体工程
AlphaFold2 和相关结构预测工具可用于抗体结构建模、突变影响分析、蛋白稳定性评估和候选设计辅助。
但抗体 CDR 区域高度柔性,抗原结合构象复杂,抗体-抗原复合物预测仍需谨慎。对于抗体工程来说,结构预测是工具,不是最终答案。
4. 蛋白设计
AlphaFold 系列已经深度参与蛋白设计流程。
RFdiffusion、ProteinMPNN、BindCraft、Protein Hunter、Proteina-Complexa 等方法,都在不同程度上借助结构预测模型进行生成、筛选、验证或反向设计。
这说明 AlphaFold 的影响已经超出结构预测本身。
它正在成为蛋白设计流程中的"结构评估器""复合物验证器"和"设计反馈器"。
5. 机制研究
AlphaFold 可帮助解释突变、复合物界面、结构域重排和蛋白相互作用模式。
但机制研究不仅需要静态结构,也需要动态过程。构象变化、诱导契合、别构调控和细胞环境仍需要分子动力学、实验结构、功能实验和生物化学证据补充。
九、为什么不能把预测结构当成实验真相?
AlphaFold 的强大,也带来一个新的风险:
人们很容易把预测结构当成真实结构。
这在科学上是不严谨的。
高 pLDDT 不等于实验结构。
它只是模型对局部预测可信度的估计。
低置信区不一定是错误。
它可能代表柔性区、无序区或多构象区域。
单个预测结构不代表全部功能状态。
很多蛋白的功能依赖构象变化,单一静态结构无法描述完整过程。
复合物预测不等于真实相互作用。
蛋白是否结合、结合强度如何、是否产生功能效应,都需要实验验证。
小分子复合物预测不等于药物发现完成。
结合构象只是药物设计的一部分,还需要亲和力、选择性、ADMET、安全性和体内效果验证。
尤其在药物研发中,结构预测应当被视为假设生成工具。
它可以让研究者更快提出可能机制,更快设计实验,更快筛选候选。但它不能替代 docking、分子动力学、自由能计算、SPR、BLI、ITC、cryo-EM、晶体结构和细胞功能实验。
科学不接受漂亮结构图本身。
科学只接受经过多种证据支持、经得起验证的结论。
十、如何正确使用 AlphaFold1--3 的结果?
如果在实际研究或 AIDD 项目中使用 AlphaFold 系列结果,可以遵循几个原则。
第一,看 pLDDT,不要只看结构图。
高置信区域可以重点分析,低置信区域需要谨慎。
第二,看 PAE,尤其是多结构域蛋白。
一个结构域内部预测准确,不代表结构域之间相对位置可靠。
第三,复合物预测要看 ipTM、PAE 和界面接触。
同时还要结合实验互作证据,不能只依赖模型结果。
第四,对 AlphaFold3 的蛋白-小分子预测,不要直接等同于 docking 结果或亲和力结果。
它可以提供结合构象假设,但不能直接证明结合强度和药效。
第五,对药物设计场景,必须结合多种证据。
包括 docking、分子动力学、自由能计算、突变实验、结合实验、结构解析和功能实验。
第六,把 AlphaFold 结果作为"结构假设",而不是"结构结论"。
这句话是使用 AlphaFold 最重要的原则。
十一、AlphaFold 之后,结构预测还会走向哪里?
AlphaFold 系列已经极大改变了结构预测,但问题远没有结束。
未来至少有几个方向值得关注。
1. 从静态结构到动态构象
蛋白不是静止的雕塑,而是动态的分子机器。
很多功能依赖构象变化,例如 GPCR 激活、激酶开关、转运蛋白开闭、酶催化循环和别构调控。
未来模型需要更好预测蛋白的多状态结构和构象转变,而不是只给出一个静态结构。
2. 从单分子结构到细胞内相互作用网络
真实细胞中,蛋白与蛋白、核酸、小分子、脂质、离子共同构成复杂网络。
AlphaFold3 已经朝多分子相互作用迈出一步,但距离真实细胞环境仍然很远。
未来结构预测可能与互作组学、空间组学、细胞成像和动力学模拟结合,进入更复杂的生命系统建模。
3. 从预测到设计
AlphaFold 最初是预测模型,但它已经成为蛋白设计的重要组成部分。
未来模型可能不只是回答"这个分子长什么样",而是进一步回答:
为了实现某个功能,应该设计怎样的分子?
这也是 RFdiffusion、BindCraft、Protein Hunter、Proteina-Complexa 等方法正在探索的方向。
4. 从模型预测到实验闭环
AI 的真正价值,不是替代实验,而是让实验更高效。
未来更重要的模式可能是:
AI 预测结构 → 自动化设计候选 → 高通量实验验证 → 数据回流训练模型 → 再设计。
这将形成一个计算与实验闭环。
在这个闭环中,AlphaFold 不再只是一个预测工具,而是科学发现流程中的一环。
十二、结语:AlphaFold 改变的是抵达结构假设的速度和方式
AlphaFold1 证明了深度学习可以突破传统结构预测瓶颈。
AlphaFold2 让单链蛋白结构预测接近实验精度,极大改变了结构生物学的工作方式。
AlphaFold-Multimer 把结构预测推进到蛋白复合物层面。
AlphaFold3 则进一步把问题从"蛋白如何折叠"推进到"生命分子如何相互作用"。
这是一条清晰的演进路线:
从结构约束,到蛋白结构;从单体蛋白,到蛋白复合物;从蛋白折叠,到生命分子相互作用。
但 AlphaFold 的真正意义,并不是让实验变得不重要。
恰恰相反,它让实验有了更高效的起点。
过去,研究者可能需要很久才能看到一个结构假设。现在,模型可以在很短时间内给出一个可供讨论、分析和验证的结构模型。
这改变了科学研究的节奏。
但最终,科学仍然需要证据。
AlphaFold 改变的不是结构生物学的终点,而是我们抵达结构假设的速度和方式。
它让我们更快看到可能的结构,更快提出机制假设,更快设计验证实验。
但真正能站得住的结论,仍然要在实验和多重证据中完成。
这或许才是 AlphaFold 系列最重要的价值:
它不是让科学家停止实验,而是让科学家更快知道,应该把实验做向哪里。