CVPR 2026 | 不微调也能做 OOD 肿瘤分割?R2-Seg 用"解剖推理 + 统计拒绝"抑制假阳性
论文题目 :R2-Seg: Training-Free OOD Medical Tumor Segmentation via Anatomical Reasoning and Statistical Rejection
发表出处 :CVPR 2026
作者机构 :Carnegie Mellon University、University of Cambridge、Zhejiang University、ETH Zurich、UIUC
关键词 :Medical Tumor Segmentation, OOD Generalization, Foundation Model, Anatomical Reasoning, Statistical Rejection
解读依据:用户提供的论文与解读提示词模板。
1. 🚀 省流版摘要:这篇文章到底做了什么?
一句话概括:
R2-Seg 希望在不更新任何模型参数的情况下,让 BiomedParse 这类医学分割基础模型更可靠地处理 OOD 肿瘤分割,核心思路是先用 LLM 做解剖定位推理,再用统计检验拒绝假阳性候选区域。
这篇文章关注的问题非常现实:医学分割 foundation model 在正常器官、常见结构上表现不错,但一遇到 OOD tumor,很容易把正常组织、伪影、背景纹理误识别成肿瘤。尤其在无肿瘤切片中,模型往往"不愿意输出空 mask",导致大量假阳性。
R2-Seg 的解决思路不是 fine-tuning,也不是 LoRA,而是一个 training-free test-time adaptation pipeline:
- Reason:用 LLM 根据肿瘤类型推理相关解剖锚点,比如 bladder tumor 先定位 bladder,再生成多尺度 ROI;
- Segment:在 ROI 内调用冻结的 BiomedParse 做肿瘤分割,并结合 flip TTA;
- Reject:对候选连通域做两样本统计检验,判断它是否真的与正常组织分布不同;
- Gate:再用存在性门控、候选级门控、病例级分数进一步压制空切片假阳性。
从结果上看,R2-Seg 不一定在所有 OOD 肿瘤上都获得最高 Dice,但它显著提升了 specificity 和 class-average accuracy,也避免了 fine-tuning 带来的 catastrophic forgetting。
2. 🧐 背景与痛点:为什么 OOD 肿瘤分割这么难?
2.1 Foundation model 的尴尬:能分割,但不一定"懂异常"
近几年,SAM、MedSAM、BiomedParse 等 promptable foundation model 给医学图像分割带来了很大想象空间。尤其 BiomedParse 这种 text-driven 模型,可以通过文本 prompt 同时完成 segmentation、detection 和 recognition。
但肿瘤分割和普通器官分割不太一样。
器官往往有相对稳定的形态、位置和强解剖先验,而肿瘤具有明显的:
- 形状不规则
- 大小跨度大
- 强度分布复杂
- 跨中心、跨扫描协议、跨患者差异大
- 同一肿瘤类型内部异质性强
因此,OOD 场景下 foundation model 的视觉 embedding 可能变得不可分。论文在 Figure 1 中用 embedding distribution 示意:in-distribution 下前景和背景较容易分开,而 OOD 下边界偏移,正常背景也可能被判成 tumor。
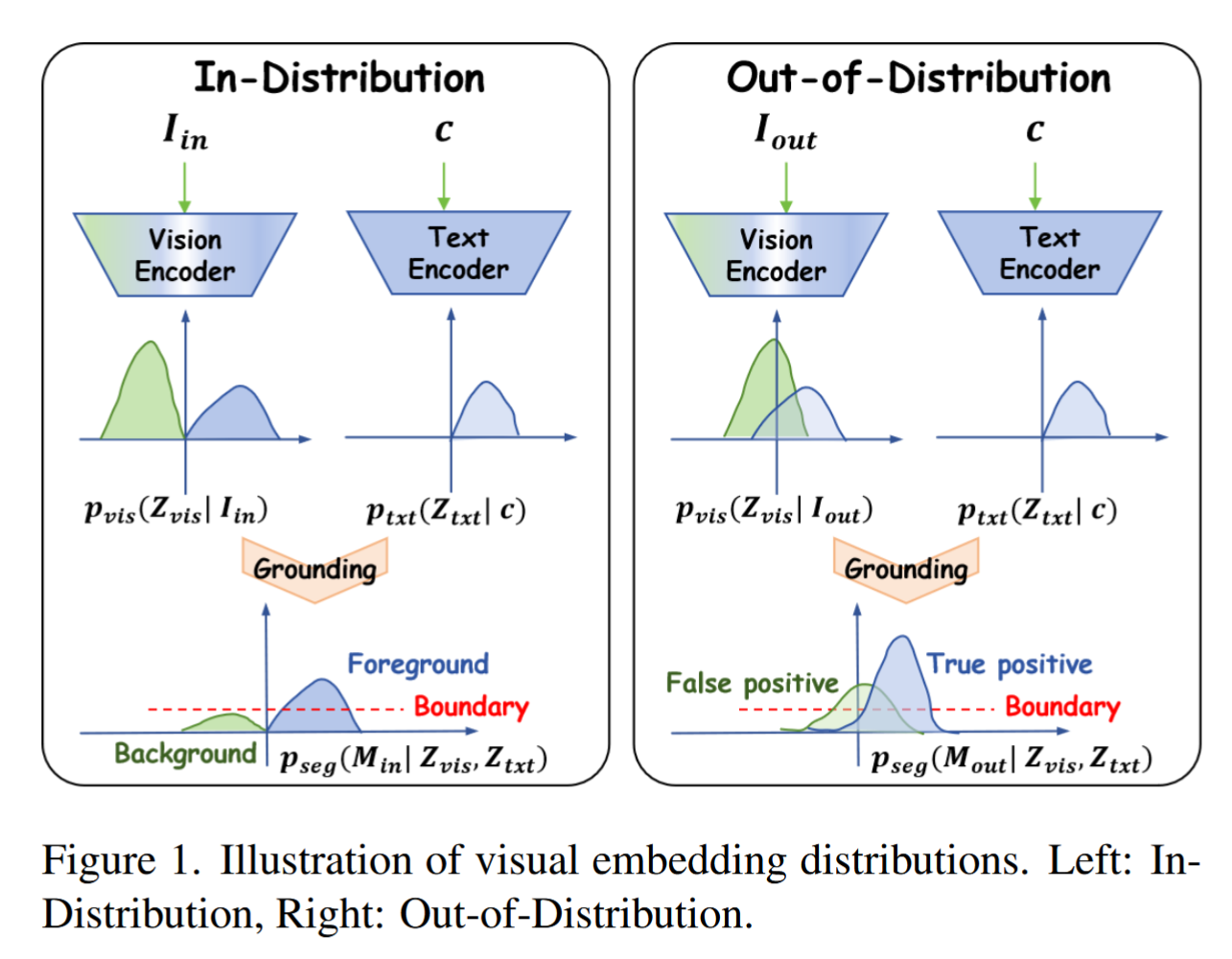
论文 Figure 1,展示 In-Distribution 与 Out-of-Distribution 下 visual embedding separability 的差异
2.2 Fine-tuning 并不是万能解
一个直接想法是:既然 OOD 不行,那就 fine-tune。
但医学肿瘤数据存在天然限制:
- 数据稀缺;
- 标注成本高;
- 不同肿瘤类型差异大;
- 小数据 fine-tuning 容易过拟合;
- 更重要的是,可能导致 catastrophic forgetting。
论文后续用 AMOS22 CT/MR、M&Ms 等 in-distribution 数据验证了这一点:fine-tuned BiomedParse 或 LoRA 版本虽然可能改善某些 tumor Dice,但对原本的正常器官分割能力会明显下降。
所以,作者提出的问题是:
能不能不改模型参数,也能让 foundation model 更适合 OOD tumor segmentation?
R2-Seg 就是对这个问题的回答。
3. 💡 核心方法:Reason-and-Reject
R2-Seg 的核心可以概括为四个字:先想,再拒。
也就是论文标题中的两个关键词:
- Reason:通过解剖推理缩小搜索空间;
- Reject:通过统计检验拒绝假阳性。
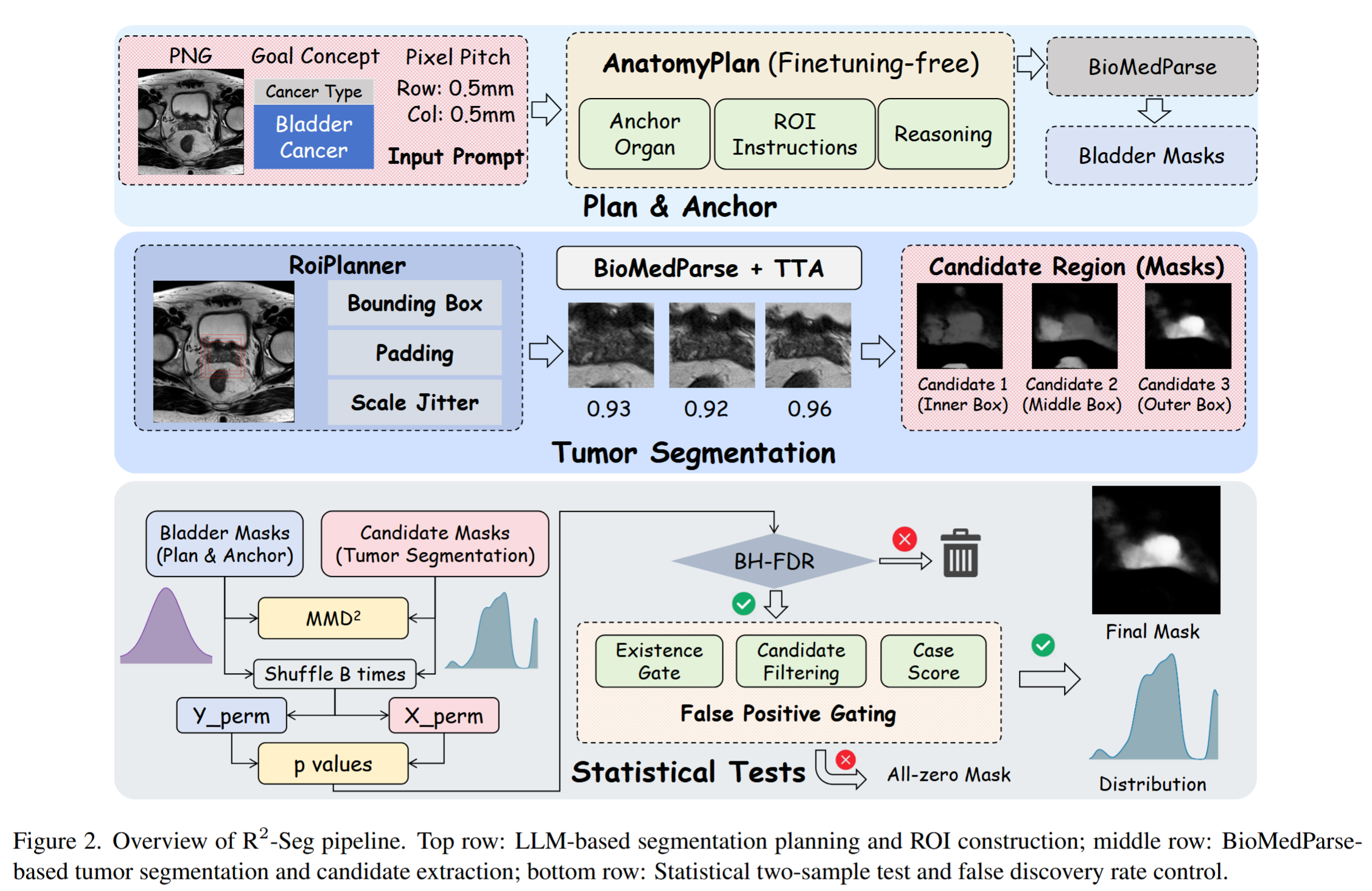
论文 Figure 2,R2-Seg 整体流程图,包括 LLM planning、ROI construction、BiomedParse + TTA、MMD statistical test 和 false-positive gating
3.1 整体架构:从文本目标到最终 mask
以 "bladder cancer" 为例,R2-Seg 的完整流程如下:
- 输入医学图像和癌种文本概念;
- LLM planner 根据癌种推理相关解剖锚点,例如 bladder;
- 调用 BiomedParse 先分割 anchor organ;
- 根据 organ mask 生成多尺度 ROI;
- 在 ROI 内用 tumor prompt 进行肿瘤分割;
- 对预测 mask 做 connected component decomposition,得到候选区域;
- 对每个候选区域和正常器官区域做统计两样本检验;
- 只保留与正常组织显著不同的候选区域;
- 最后通过 false-positive gating 输出最终 mask,必要时输出全零 mask。
这个 pipeline 的关键不是"让模型更强",而是让模型少犯低级错误。
尤其是 OOD 肿瘤场景,直接让 BiomedParse 在整张图上找 tumor,很容易出现全器官误分割或大面积假阳性。R2-Seg 先通过 anatomical anchor 把问题限定到合理空间,再用统计检验筛掉不可信区域。
3.2 Reason:LLM-guided anatomical planning
第一步是 LLM-based planning。
LLM planner 将一个高层医学概念,例如 "bladder tumor",转换成结构化 AnatomyPlan,包括:
- Anchor organs:相关解剖锚点;
- ROI instructions:padding、scale jitter、square crop 等几何规则;
- Reasoning trace:推理过程。
形式上,论文将 planner 表示为:
文本癌种概念 c → anchor organs A、ROI instructions I_ROI、reasoning trace r。
随后,BiomedParse 先根据 anchor-specific prompt 分割正常器官,得到 organ mask。多个 anchor organ 的 mask 会被合并,生成 bounding box,再经过 dilation、square enforcement 和多尺度 jitter 得到 ROI。
这里的设计有两个意义:
第一,肿瘤位置通常依附于器官或局部解剖结构。与其让模型在全图里乱找,不如先确定合理搜索区域。
第二,foundation model 对正常器官的识别通常比对 OOD 肿瘤更可靠。所以作者让模型先做它擅长的 organ localization,再做更难的 tumor segmentation。
这点其实很有启发:
在医学 foundation model 落地时,异常目标不一定应该直接分割。先借助稳定解剖结构建立上下文,可能是更稳的路径。
3.3 Segment:ROI 内的 frozen BiomedParse + TTA
在得到 ROI 后,R2-Seg 使用冻结的 BiomedParse 进行 tumor segmentation。
这里没有任何参数更新,只做 multi-view test-time augmentation,包括:
- identity;
- left-right flip;
- top-bottom flip。
不同 view 的预测会 inverse transform 回原坐标,然后通过 max-fusion 得到融合概率图。随后阈值化得到 tumor mask,并通过连通域分析得到若干 candidate components。
这个阶段本身并不复杂,但有两个重要点:
- ROI 让模型输入更聚焦,减少无关背景;
- TTA 让预测更稳定,缓解单视角偶然误差。
不过,仅靠 ROI 和 TTA 还不够。因为 foundation model 在 OOD 场景下仍会产生一些碎片化假阳性,所以论文最核心的创新其实在下一步。
3.4 Reject:基于 MMD 的两样本统计检验
这是 R2-Seg 最有意思的部分。
作者没有单纯相信模型的 probability score,而是提出一个统计问题:
一个候选肿瘤区域的影像特征分布,是否与正常器官区域显著不同?
如果候选区域和正常组织并没有统计显著差异,那它很可能只是正常纹理、噪声或伪影,应当被拒绝。
具体来说,论文对每个 candidate component C_k 提取像素级特征,例如 ROI 内 percentile-normalized intensity。然后将候选区域特征 X 与正常器官区域特征 Y 进行 nonparametric two-sample test。
原假设是:
H0:候选区域和正常区域来自同一分布。
H1:候选区域和正常区域来自不同分布。
论文使用的是 MMD² with Gaussian kernel ,并通过 permutation test 估计 p-value。多个候选区域会产生多个 p-value,因此作者进一步用 Benjamini--Hochberg correction 控制 False Discovery Rate。
通俗理解就是:
- 如果候选区域和正常器官差异显著,则保留;
- 如果差异不显著,则认为它更像假阳性,拒绝。
这一步非常符合医学任务的直觉。肿瘤不是单纯"看起来像 prompt 对应物",而应该在局部影像分布上与正常组织存在异常差异。
3.5 False-positive gating:专门处理空 mask 场景
医学肿瘤分割里还有一个很重要的问题:很多切片本来就没有肿瘤。
但 text-prompted segmentor 很少主动输出空 mask。于是,在 negative slices 上会出现非常高的 false positive rate。
为了解决这个问题,R2-Seg 增加了三层门控:
L1:Existence gate
计算:
- 全局最大概率 pmax;
- positive ratio;
- 前景和背景概率分布的 KS test p-value。
如果整体置信度太低,或者前景比例太小,或者前景/背景概率差异不明显,就直接判为 negative。
L2:Candidate-level gate
对候选区域施加约束,例如:
- 面积不能太小;
- 平均概率要足够高;
- 与 organ mask 的 overlap 要满足条件。
L3:Case-level score
对剩余候选区域计算病例级分数,如果最大分数仍低于阈值,则输出全零 mask。
这套 gating 的目标非常明确:
宁愿保守一点,也不要在没有肿瘤的切片上乱报。
当然,这也带来一个 trade-off:specificity 提高的同时,sensitivity 可能下降。论文在 Discussion 中也承认,这是 R2-Seg 的主要局限之一。
4. 📊 实验与结果:R2-Seg 到底强在哪里?
4.1 数据集设置
论文使用了 10 个 organ-specific tumor segmentation datasets,覆盖 CT 和 MR 两种模态。
其中 OOD tumor types 包括:
- Bladder tumor;
- Uterus tumor;
- Prostate tumor;
- Breast tumor;
- Cervix tumor。
In-distribution tumor types 包括:
- Liver tumor;
- Lung tumor;
- Pancreas tumor;
- Colon tumor;
- Kidney tumor。
此外,作者还使用 AMOS22 CT、AMOS22 MR、M&Ms 来评估 fine-tuning 是否导致 catastrophic forgetting。
4.2 对比方法
论文主要比较了:
- BiomedParse zero-shot:直接用原始模型;
- BiomedParse-FT:使用训练切片 fine-tune;
- BiomedParse-LoRA:对 pixel decoder 做 LoRA;
- R2-Seg:不更新参数,只做 Reason-and-Reject。
这个对比设置比较有意思,因为 R2-Seg 不是和传统 nnU-Net 直接拼 fully-supervised 分割性能,而是强调:
在 foundation model 已有能力基础上,如何进行 training-free OOD adaptation。
4.3 OOD 肿瘤结果:Dice 不是唯一重点,specificity 更关键
论文 Table 2 给出了五类 OOD tumor 的代表性结果。
一个非常显著的现象是:
BiomedParse 在很多 OOD case 上 sensitivity = 1.000,但 specificity = 0.000。
这意味着什么?
它几乎把所有切片都预测成阳性。这样当然不会漏掉阳性切片,但会产生大量假阳性。对于临床筛查,这种模型会带来严重 overdiagnosis 风险。
R2-Seg 的特点则是:
- specificity 显著提高;
- class-average accuracy 提高;
- Dice 在部分任务上优于 BiomedParse,但不总是超过 LoRA;
- sensitivity 有时下降,体现出保守拒绝策略。
例如:
- Prostate tumor:R2-Seg Dice 0.465,高于 BiomedParse 0.047 和 LoRA 0.428;
- Breast tumor:R2-Seg specificity 0.728,高于 BiomedParse 0.030 和 LoRA 0.520;
- Cervix tumor:R2-Seg specificity 0.632,高于 BiomedParse 0.000 和 LoRA 0.359。
这说明 R2-Seg 的主要价值不是盲目追求更高 sensitivity,而是把模型从"见什么都像肿瘤"的状态拉回到更可信的工作区间。
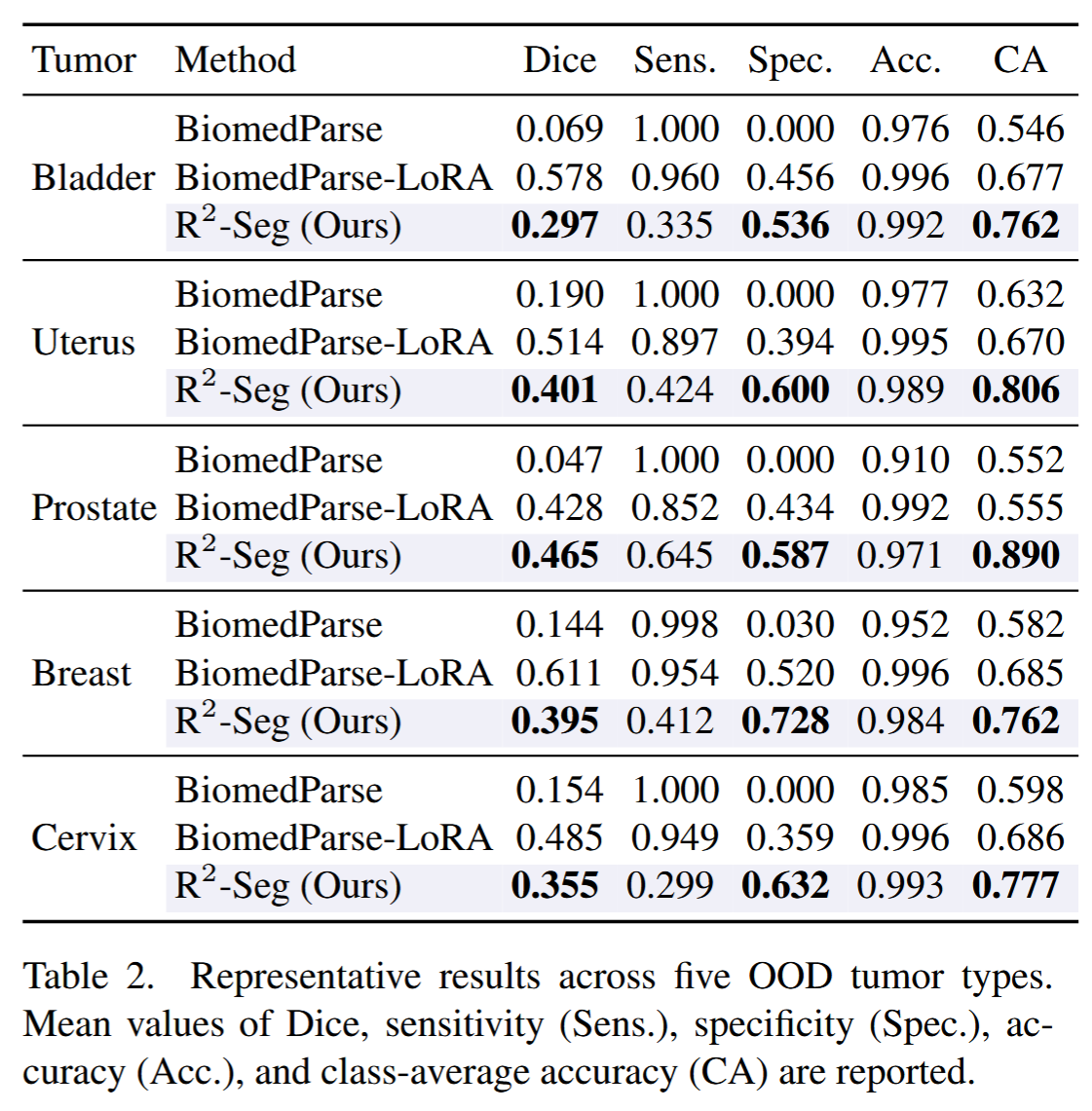
论文 Table 2,展示五类 OOD tumor 上 Dice、Sensitivity、Specificity、Accuracy、CA 的对比结果
4.4 可视化结果:BiomedParse 容易把器官当肿瘤
论文 Figure 3 非常直观。
在 prostate、cervix、uterus、bladder 等 OOD 情况下,BiomedParse 容易把包含肿瘤的整个器官区域分出来,而不是只分肿瘤本身。
这其实暴露了 text-prompted foundation model 的一个问题:
prompt 说的是 "tumor",但模型可能只是捕捉到了相关 organ context,而没有真正识别 lesion boundary。
R2-Seg 通过 ROI planning 和 statistical rejection,一定程度上抑制了这种过分割。
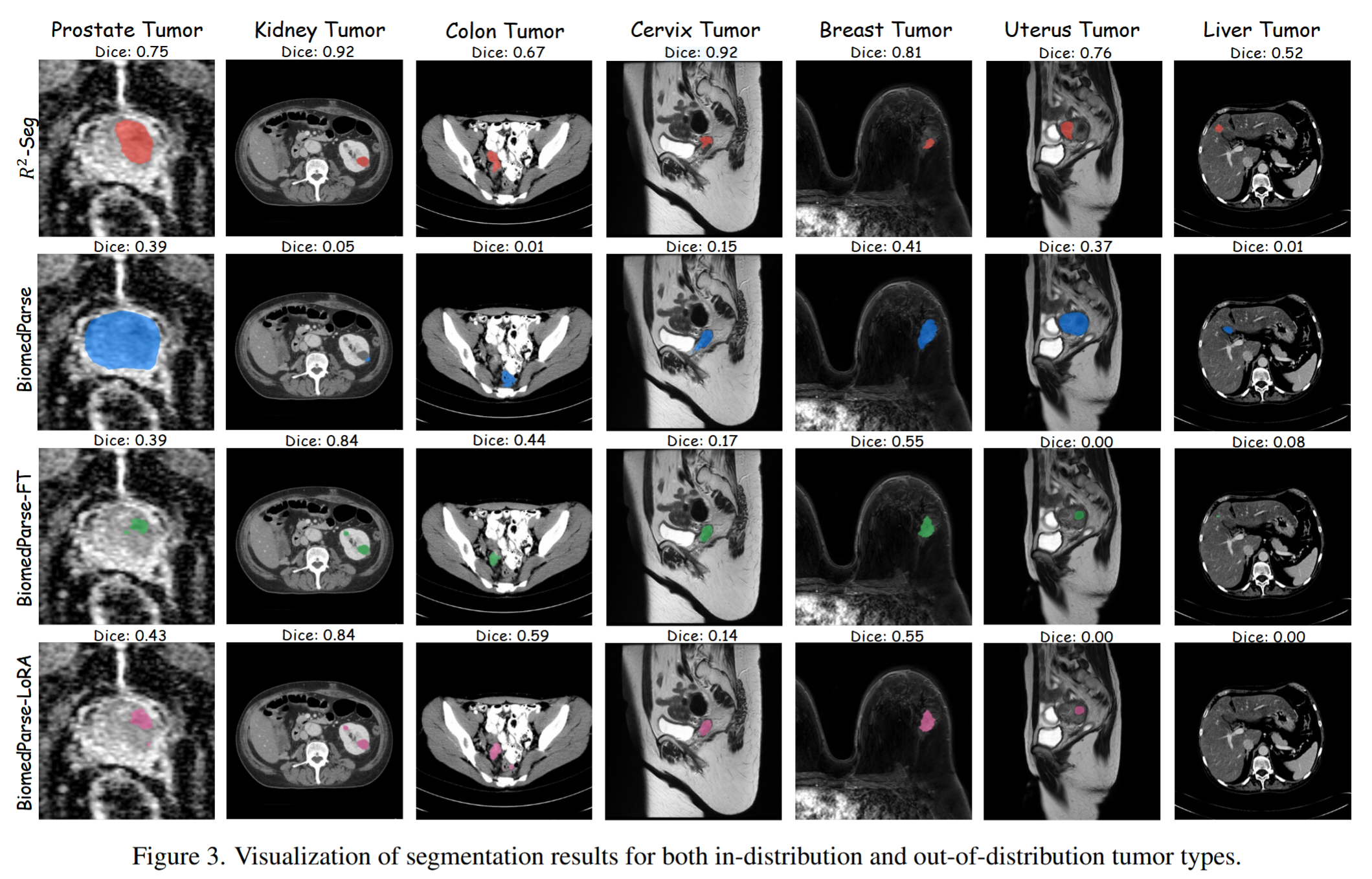
论文 Figure 3,不同方法在 prostate、kidney、colon、cervix、breast、uterus、liver tumor 上的可视化结果
4.5 FROC 分析:假阳性控制更适合临床视角
论文还使用 FROC 曲线评估 scan-level sensitivity 与 false positives per scan 的关系。
这比单纯 Dice 更贴近临床,因为实际部署中,医生更关心:
- 在可接受假阳性数量下,能保留多少敏感性?
- 模型是否会给出大量无意义报警?
论文结果显示,R2-Seg 在 mild rejection 和 aggressive rejection 设置下都可以提供更好的 sensitivity-FP trade-off。尤其在更强拒绝设置下,R2-Seg 仍能在一定 false positive 数量下保持较高 sensitivity。
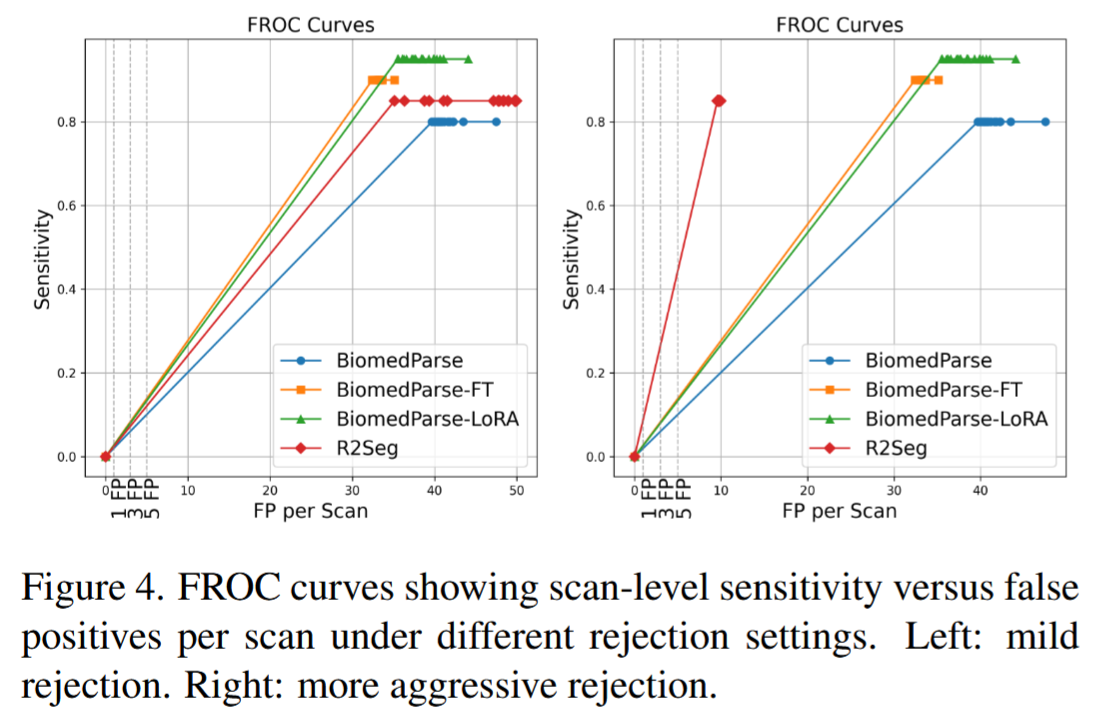
论文 Figure 4,FROC curves,展示 scan-level sensitivity 与 FP per scan 的关系
4.6 消融实验:统计检验和 FP gating 都是必要的
论文 Table 3 分析了两个模块:
- statistical test;
- false-positive gating。
结果显示:
- 去掉 statistical test 后,低对比器官内部容易出现更多 false activation;
- 去掉 FP gating 后,背景激活增加,specificity 明显下降;
- 两者结合时,整体 specificity 和 Dice 更稳定。
这说明 R2-Seg 的性能不是单靠 LLM ROI,也不是单靠简单阈值后处理,而是 Reason + Reject + Gate 共同作用。
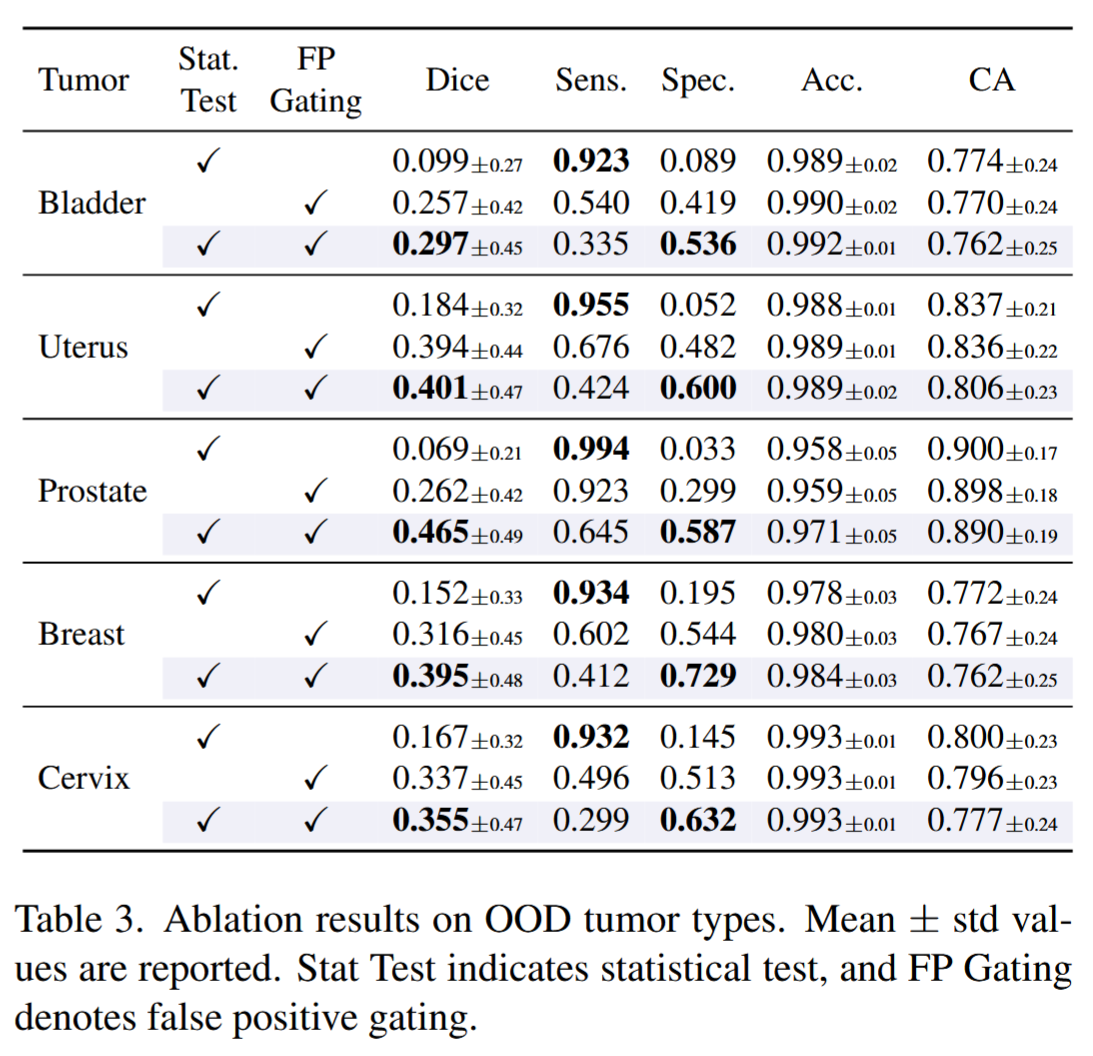
论文 Table 3,统计检验与假阳性门控的消融实验结果
5. 🧠 笔者思考与总结
5.1 这篇文章最大的亮点
笔者认为,这篇文章最大的亮点不是某个复杂网络结构,而是它提出了一种很实用的医学 foundation model 使用范式:
不一定要训练模型,而是可以在推理阶段加入医学先验、空间约束和统计检验,让 foundation model 的输出更可信。
这和很多现有工作不同。很多 TTA 方法关注如何更新 BN、adapter 或 LoRA 参数,但 R2-Seg 直接绕开参数更新,用外部知识和统计规则做 test-time adaptation。
这有几个优势:
- 不需要访问模型内部结构;
- 不需要反向传播;
- 不会 catastrophic forgetting;
- 更容易作为 wrapper 接在已有 foundation model 后面;
- 对临床安全性更友好,因为重点是压制 false positives。
5.2 这篇文章对医学 AI 的启发
R2-Seg 的思想对医学图像分析很有启发,尤其对 foundation model 后处理或系统级 pipeline 设计。
它提示我们:
医学 AI 不一定要把所有知识都塞进网络参数里。
有些知识可以来自:
- 解剖位置;
- 器官拓扑;
- 疾病发生区域;
- 局部强度统计;
- 假阳性控制策略;
- 临床任务的先验约束。
对于 OOD tumor segmentation,模型输出本身并不一定可靠。因此,与其盲目相信模型 confidence,不如引入一种 model-agnostic 的统计检验机制,判断候选区域是否真的异常。
这点和医学诊断逻辑也更接近:医生不会只看"像不像",还会看它是否偏离正常解剖和正常影像表现。
5.3 潜在局限:specificity 上来了,但 sensitivity 可能下降
R2-Seg 的局限也比较明显。
第一,统计拒绝和 false-positive gating 会提高 specificity,但也可能误拒真实小病灶。对于早期肿瘤、小病灶、低对比病灶,这种风险尤其值得关注。
第二,方法依赖 anchor organ segmentation。如果 BiomedParse 对 anchor organ 本身分割失败,后续 ROI planning 可能会受到影响。
第三,目前特征主要是 intensity distribution。对于 MR 多序列、增强模式、纹理复杂病灶,仅靠 intensity-level MMD 可能不够。未来可以考虑引入 radiomics feature、foundation model intermediate feature,甚至多模态统计特征。
第四,LLM planner 的可靠性和可复现性也值得进一步讨论。不同 LLM、不同 prompt 是否会产生稳定 AnatomyPlan?这对临床部署很重要。
6. ✅ 总结
R2-Seg 是一篇很有系统思维的工作。
它没有提出新的 backbone,也没有训练一个更大的模型,而是围绕 OOD tumor segmentation 的真实痛点,构建了一个 training-free、model-agnostic、clinically safer 的推理框架。
它的核心贡献可以总结为三点:
- Reason before segmentation:先通过 LLM 解剖推理定位 organ anchor 和 ROI;
- Reject after segmentation:用 MMD 两样本检验拒绝与正常组织无显著差异的候选区域;
- Avoid forgetting:不更新 BiomedParse 参数,因此避免 fine-tuning/LoRA 带来的 catastrophic forgetting。
当然,R2-Seg 也不是完美答案。它在提高 specificity 的同时牺牲了一部分 sensitivity,小病灶漏检仍是风险。但从医学 AI 落地角度看,这篇文章提出了一个非常值得关注的方向:
未来的医学 foundation model,可能不只是一个"大模型",而是一套由基础模型、解剖知识、统计检验和安全门控共同组成的可信推理系统。
本文由 AI 辅助解读,仅供参考,详细内容请查阅原论文。