目录
[二、Pact-Net 核心设计拆解:从输入到输出,每一步都藏着巧思](#二、Pact-Net 核心设计拆解:从输入到输出,每一步都藏着巧思)
[2.1 输入层:图像预处理,给 AI"喂" 好数据](#2.1 输入层:图像预处理,给 AI"喂" 好数据)
[2.2 双分支编码器:左手 CNN 抓细节,右手 Transformer 看全局](#2.2 双分支编码器:左手 CNN 抓细节,右手 Transformer 看全局)
[2.2.1 CNN 分支:用 ResNet 做 "局部侦探",不放过任何细节](#2.2.1 CNN 分支:用 ResNet 做 "局部侦探",不放过任何细节)
[2.2.2 Transformer 分支:用 Swin Transformer 做 "全局导航",定位更精准](#2.2.2 Transformer 分支:用 Swin Transformer 做 "全局导航",定位更精准)
[2.2.3 双分支的互补性:1+1 远大于 2](#2.2.3 双分支的互补性:1+1 远大于 2)
[2.3 CSMF 融合模块:把 CNN 和 Transformer 的特征 "捏" 成黄金搭档](#2.3 CSMF 融合模块:把 CNN 和 Transformer 的特征 "捏" 成黄金搭档)
[2.3.1 CSF 子模块:用注意力机制做 "翻译",筛选关键信息](#2.3.1 CSF 子模块:用注意力机制做 "翻译",筛选关键信息)
[2.3.2 SSMF 子模块:用多尺度融合做 "整合",消除语义 gap](#2.3.2 SSMF 子模块:用多尺度融合做 "整合",消除语义 gap)
[2.3.3 CSMF 的优势:比传统融合方法强在哪?](#2.3.3 CSMF 的优势:比传统融合方法强在哪?)
[2.4 解码器与损失函数:从融合特征到分割结果,精准优化](#2.4 解码器与损失函数:从融合特征到分割结果,精准优化)
[三、实验结果:碾压 SOTA!Pact-Net 在三大任务中表现封神](#三、实验结果:碾压 SOTA!Pact-Net 在三大任务中表现封神)
[3.1 皮肤病变分割:ISIC 三大数据集全面夺冠](#3.1 皮肤病变分割:ISIC 三大数据集全面夺冠)
[3.2 息肉分割:Kvasir 数据集 DICE 突破 90%](#3.2 息肉分割:Kvasir 数据集 DICE 突破 90%)
[3.3 细胞分割:DSB2018 数据集 IOU 接近 80%](#3.3 细胞分割:DSB2018 数据集 IOU 接近 80%)
[4.1 双分支编码器的必要性](#4.1 双分支编码器的必要性)
[4.2 CSF 和 SSMF 子模块的必要性](#4.2 CSF 和 SSMF 子模块的必要性)
[4.3 CNN 分支基础模型的选择](#4.3 CNN 分支基础模型的选择)
[五、Pact-Net 的局限性与未来方向](#五、Pact-Net 的局限性与未来方向)
[5.1 小数据集泛化能力弱](#5.1 小数据集泛化能力弱)
[5.2 复杂场景分割精度不足](#5.2 复杂场景分割精度不足)
[5.3 训练效率低](#5.3 训练效率低)
前言
最近在顶刊《Computer Methods and Programs in Biomedicine》(2023 年 IF=7.0+)上看到一篇论文 ------《Pact-Net:Parallel CNNs and Transformers for Medical Image Segmentation》,读完直接被圈粉!这篇文章提出的 Pact-Net 网络,完美解决了医学图像分割中 "局部细节看不清、全局范围抓不准" 的痛点,在皮肤病变、息肉、细胞分割任务中全面碾压传统 U-Net 和 Transfuse 等 SOTA 模型,尤其是在 ISIC 2016 皮肤病变数据集上,关键指标 T-JAC 直接冲到 86.95%,把第二名远远甩在身后。
今天就带大家从头到脚拆解这个神仙模型,从研究背景、核心设计到实验结果,用最通俗的语言讲明白 Pact-Net 到底牛在哪。无论你是医学 AI 领域的研究者、刚入门的算法小白,还是对皮肤癌早筛技术感兴趣的开发者,这篇文章都能让你收获满满~下面就让我们正式开始吧!
一、先聊聊为什么要做医学图像分割?这事儿真能救命!
在开始讲模型之前,咱们先搞清楚一个核心问题:医学图像分割到底有啥用?为啥学术界和工业界都在疯狂卷这个方向?
拿皮肤癌来说,它是全球最常见的癌症之一,而黑色素瘤又是其中最致命的类型。数据显示,如果黑色素瘤能早期诊断,患者 5 年生存率能达到 90%;可一旦延误,生存率会暴跌到 23%(相当于每 4 个人里只有 1 个能活过 5 年)。但现实是,传统的皮肤癌诊断全靠 dermatologist(皮肤科医生)用肉眼看 ------ 医生通过 dermoscopy(皮肤镜)观察皮肤病变的形态、颜色、边界,再凭经验判断是否为恶性。可即便如此,专业医生的诊断准确率也只有 60% 左右,很多早期小病变会被漏诊,等发现时已经晚了。
这时候,医学图像分割就派上大用场了。它能自动从皮肤镜图像中把病变区域 "抠" 出来,精确标注病变的边界、大小、形状,相当于给医生装上了 "AI 放大镜"。医生再也不用对着模糊的图像反复琢磨 "这到底是不是病变",直接看 AI 生成的分割结果就能快速判断,大大提高诊断效率和准确率。
但问题来了:医学图像分割真的太难了!尤其是皮肤病变分割,简直是 AI 的 "地狱级任务",主要难在这三点:
- 图像质量差:皮肤镜图像对比度极低,病变和周围健康皮肤颜色差别很小,有时候肉眼都分不清边界;
- 干扰因素多:图像里可能有毛发遮挡、气泡反光、标记物残留,这些都会让 AI 认错病变范围;
- 病变多变:不同患者的病变大小、形状、位置千差万别,有的像芝麻一样小,有的能占满半张脸,AI 很难 "一视同仁"。
以前大家解决这个问题,要么用 CNN(卷积神经网络),要么用 Transformer。但这俩都有致命缺点:
- CNN 的短板:擅长抓局部细节(比如病变边缘的纹理),但看不远 ------ 没法获取全局上下文信息,经常把相邻的健康皮肤误判成病变(这叫 "过分割"),或者漏判小病变(这叫 "欠分割");
- Transformer 的短板:擅长看全局(比如病变在整个皮肤上的位置),但看不清细节 ------ 局部特征提取能力弱,分割出来的病变边界毛毛糙糙,跟实际边界差很远。
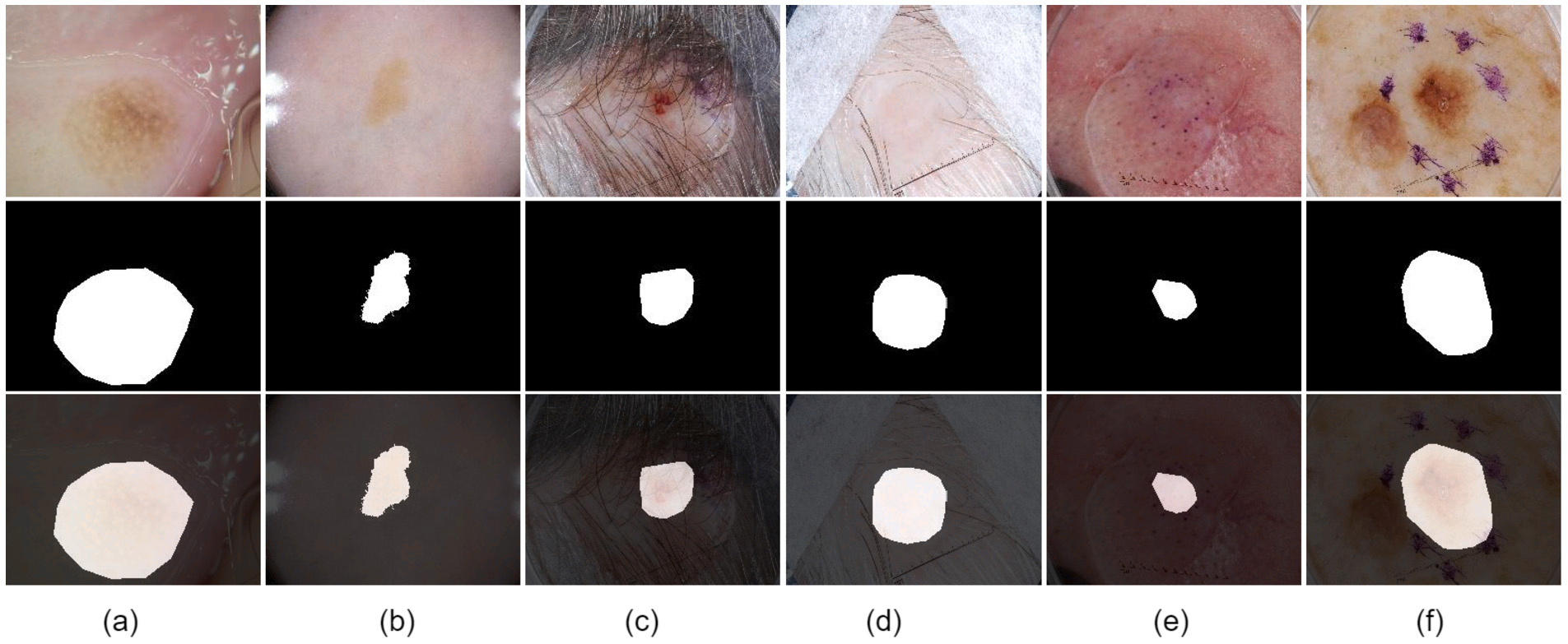
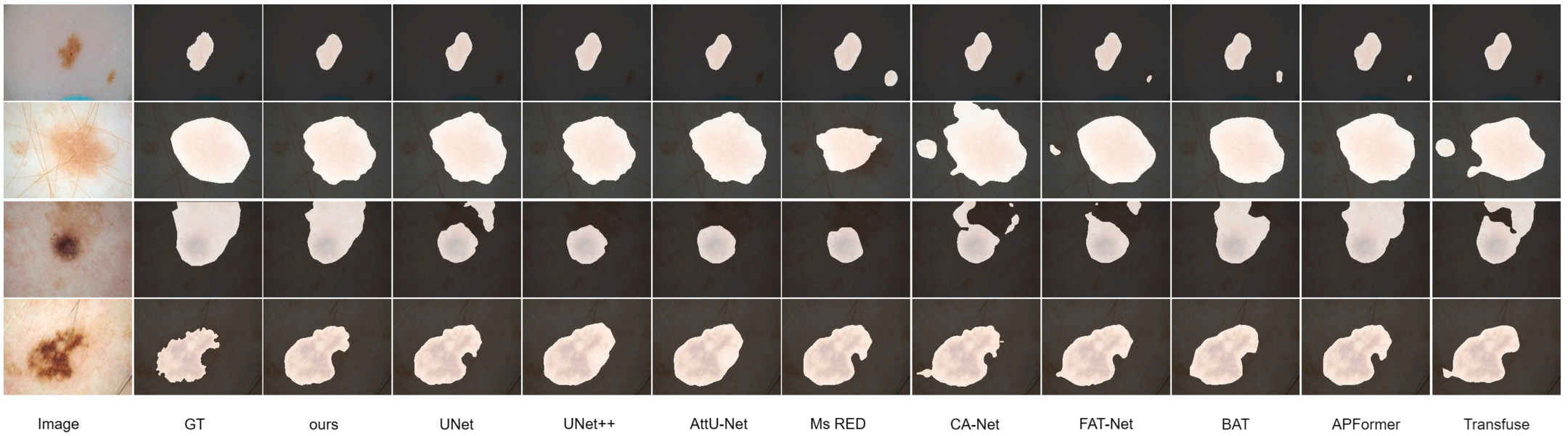
那有没有一种方法,能把 CNN 的 "局部眼" 和 Transformer 的 "全局眼" 结合起来?Pact-Net 就是为解决这个问题而生的 ------ 它用并行双分支结构同时抓局部和全局特征,再通过一个超高效的融合模块把两者捏合在一起,直接把医学图像分割的精度拉到了新高度。下图为该模型的图像处理结果:
二、Pact-Net 核心设计拆解:从输入到输出,每一步都藏着巧思
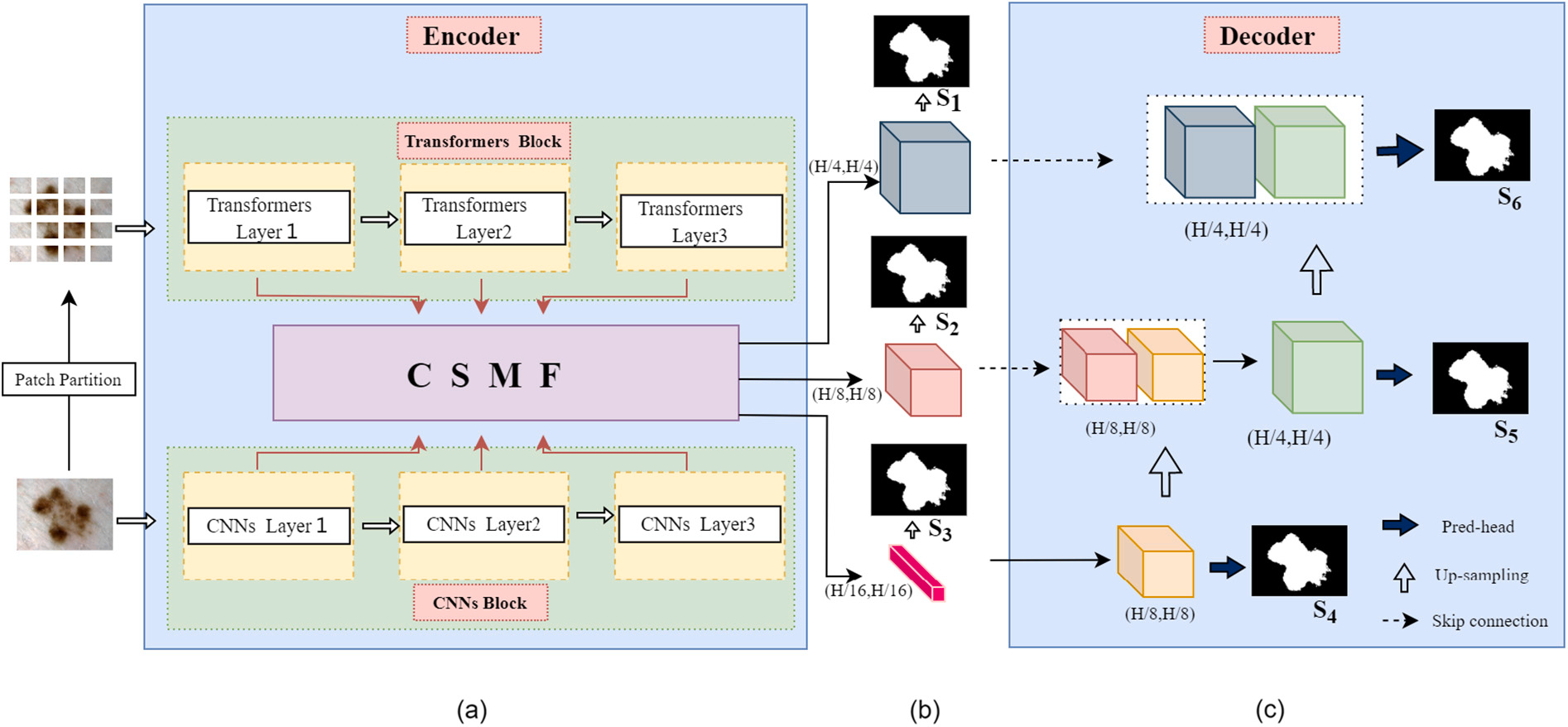
Pact-Net 的整体架构其实很清晰,其实就是一条 **"特征提取→特征融合→结果输出"**的流水线。咱们从左到右一步步看,搞明白每个模块的作用。
2.1 输入层:图像预处理,给 AI"喂" 好数据
工欲善其事,必先利其器。Pact-Net 处理图像时,先做了两件关键的预处理:
- 分辨率统一:不管输入图像是多大尺寸,都统一缩放成 192×256(皮肤病变任务)、352×352(息肉任务)或 256×256(细胞任务)。这样做是为了让模型训练更稳定,避免因图像大小不一导致的训练波动;
- 数据增强:通过垂直翻转、水平翻转、平移、缩放旋转、随机亮度调整等操作,把训练数据 "变多"。医学数据集本来就少,比如 ISIC 2016 只有 1279 张图,数据增强能有效避免模型过拟合,让 AI 在不同场景下都能稳定工作。
预处理后的图像,会同时送入两个并行的分支 ------CNN 分支和 Transformer 分支,这就是 Pact-Net 最核心的创新点之一:双分支编码器。
2.2 双分支编码器:左手 CNN 抓细节,右手 Transformer 看全局
咱们先明确一个概念:编码器的作用是**"从图像中提取有用的特征"**。Pact-Net 的编码器不是一个,而是两个,而且是并行工作的 ------ 就像两个人同时看一张图,一个人专注看细节(比如病变上的小黑点),另一个人专注看整体(比如病变在左脸颊还是右脸颊),最后把两人的发现结合起来,就能得到更全面的信息。
2.2.1 CNN 分支:用 ResNet 做 "局部侦探",不放过任何细节
CNN 分支选择的基础模型是 ResNet(残差网络),但不是完整版的 ResNet,而是做了一点小改动:删除了 ResNet 原有的最后一个卷积块。
为什么要删?因为 ResNet 的最后一个块参数很多,但经过多次下采样后,很多参数都是 0,相当于 "无效计算"。Pact-Net 只用了 ResNet 的第 2、3、4 个块,让它们分别输出分辨率为原始图像 1/4、1/8、1/16 的特征图。
举个例子:如果输入图像是 192×256,那么 CNN 分支会输出 3 组特征图,尺寸分别是 48×64(192/4=48,256/4=64)、24×32(192/8=24)、12×16(192/16=12)。这三组特征图都饱含局部细节信息 ------ 比如 48×64 的特征图能看清病变的边缘纹理,12×16 的特征图能捕捉病变的局部结构。
ResNet 的另一个好处是有残差连接,能解决深度网络的梯度消失问题。简单说就是:即便网络很深,前面层学到的细节特征也不会在后面层 "弄丢",保证 CNN 分支能一直专注于提取高质量的局部特征。
2.2.2 Transformer 分支:用 Swin Transformer 做 "全局导航",定位更精准
Transformer 分支选择的基础模型是 Swin Transformer(窗口注意力 Transformer),这也是目前计算机视觉领域的 "明星模型"。和 CNN 分支一样,Pact-Net 也对 Swin Transformer 做了裁剪:删除最后一个块,只用前 3 个块。
Swin Transformer 的核心优势是窗口注意力机制 (W-MSA)和移位窗口注意力机制(SW-MSA)。咱们用通俗的话解释一下:
- 普通 Transformer 看图像时,会把整个图像当成一个整体计算注意力,这样虽然能看全局,但计算量巨大;
- Swin Transformer 不一样,它把图像分成一个个小窗口(比如 8×8 的窗口),先在每个窗口内计算注意力(W-MSA),再把窗口移位后计算跨窗口注意力(SW-MSA)。这样既保证了全局信息的获取,又大大减少了计算量,让模型能在 GPU 上跑起来。
Swin Transformer 分支同样输出 3 组特征图,分辨率和 CNN 分支完全对应 ------1/4、1/8、1/16。但这些特征图的侧重点和 CNN 分支不同:它们包含的是全局上下文信息,比如病变在整个皮肤中的位置、病变和周围器官(如眼睛、鼻子)的相对关系。
2.2.3 双分支的互补性:1+1 远大于 2
这里有个关键问题:为什么一定要用并行双分支?串行(先 CNN 后 Transformer)不行吗?
论文里做了对比实验:如果用串行结构,先让 CNN 提取局部特征,再让 Transformer 处理这些特征,会导致 "局部特征被全局特征覆盖"------Transformer 在处理全局信息时,会不小心把 CNN 提取的细节弄丢。而并行结构能让两个分支独立工作,各自保留最擅长的特征,不会互相干扰。
后续的消融实验也证明了这一点:双分支编码器的 ACC(准确率)达到 94.35%,JAC(Jaccard 指数)达到 79.31%;而单 CNN 分支的 ACC 只有 93.56%,JAC 只有 77.15%;单 Transformer 分支更惨,ACC 只有 87.44%,JAC 直接跌到 51.99%。这说明双分支的互补性带来的提升是实实在在的,1+1 真的远大于 2。
2.3 CSMF 融合模块:把 CNN 和 Transformer 的特征 "捏" 成黄金搭档
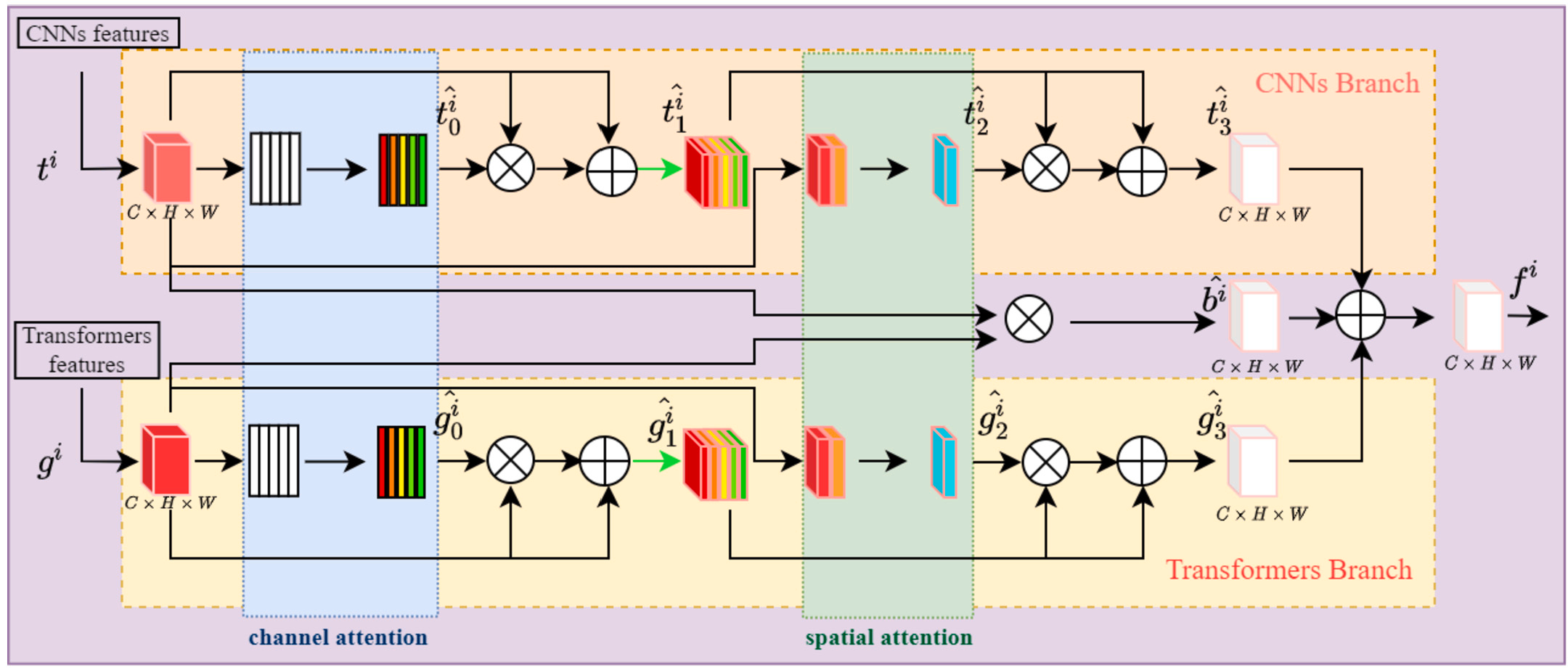
双分支编码器输出了 3 组对应分辨率的特征(CNN 的局部特征 + Transformer 的全局特征),但这两组特征就像 "两门不同语言的报告",直接放在一起用肯定不行 ------ 得有个 "翻译官" 把它们翻译成同一种语言,再整合出一份更全面的报告。这个 "翻译官" 就是 Pact-Net 的另一个核心创新:CSMF 融合模块(Channel-Space and Multi-Scale Fusion Module,通道 - 空间 - 多尺度融合模块)。
CSMF 由两个子模块组成:CSF(通道 - 空间融合子模块)和SSMF(自选择多尺度融合子模块)。咱们先看 CSF,它负责 "翻译";再看 SSMF,它负责 "整合"。
2.3.1 CSF 子模块:用注意力机制做 "翻译",筛选关键信息
CSF 的作用是从 "通道" 和 "空间" 两个维度,把 CNN 的局部特征和 Transformer 的全局特征 "翻译" 成可融合的形式。咱们先搞懂两个基本概念:
- 通道注意力:判断哪些 "特征通道" 是有用的。比如在皮肤病变图像中,"色素通道" 很重要,"背景噪声通道" 没用,通道注意力会给有用通道加权重,没用通道减权重;
- 空间注意力:判断图像中哪些 "区域" 是有用的。比如病变区域有用,毛发遮挡区域没用,空间注意力会给有用区域加权重,没用区域减权重。
CSF 的具体操作分三步:
第一步:给双分支特征分别加注意力。
- 对 CNN 的局部特征(记为 t^i):先通过 SE-Block (通道注意力模块)生成 "局部 - 通道特征",再通过 CBAM(空间注意力模块)生成 "局部 - 空间特征";
- 对 Transformer 的全局特征(记为 g^i):同样先过 SE-Block 生成 "全局 - 通道特征",再过 CBAM生成 "全局 - 空间特征"。
这样一来,我们就有了 4 类精细化特征:局部 - 通道 、局部 - 空间 、全局 - 通道 、全局 - 空间。
**第二步:计算交互特征。**把 CNN 的局部优化特征和 Transformer 的全局优化特征通过 3×3 卷积层相乘,得到一个 "交互特征"(记为 b^i)。这个特征的作用是捕捉两个分支的关联 ------ 比如 "病变边缘"(局部)和 "病变整体位置"(全局)的对应关系,避免两个分支的特征 "各说各的"。
**第三步:残差级联融合。**把前面得到的 "局部 - 空间特征"、"全局 - 空间特征" 和 "交互特征" 通过残差块拼接起来,得到 CSF 的输出特征(记为 f^i)。残差连接在这里很重要,能避免融合过程中细节特征的丢失 ------ 比如不会因为融合全局特征,就把病变的微小边缘弄丢了。
通过 CSF 的处理,CNN 和 Transformer 的特征终于 "说上话了",但还有一个问题:不同分辨率的特征之间存在 "语义 gap"(比如 1/16 分辨率的特征很抽象,1/4 分辨率的特征很具体),直接送给解码器会导致分割结果 "断层"。这时候就需要 SSMF 子模块出场了。
2.3.2 SSMF 子模块:用多尺度融合做 "整合",消除语义 gap
SSMF 的作用是把 CSF 输出的 3 组不同分辨率特征(1/4、1/8、1/16)整合到同一语义层面,让解码器能 "顺畅阅读"。
举个例子:假设我们要得到 1/8 分辨率的融合特征,SSMF 会做两件事:
- 把 1/4 分辨率的特征通过 3×3 卷积下采样到 1/8,这样它的语义就和 1/8 分辨率的原始特征更接近;
- 把 1/16 分辨率的特征通过 3×3 卷积上采样到 1/8,同样对齐语义;
- 把这三个 1/8 分辨率的特征(原 1/8 特征 + 下采样后的 1/4 特征 + 上采样后的 1/16 特征)通过特征叠加块融合,得到最终的 1/8 分辨率融合特征。
这个过程的核心是**"自适应选择"**------ 模型会自动学习不同尺度特征的权重,比如在病变边界区域,会给 1/4 分辨率的细节特征加更高权重;在病变内部区域,会给 1/16 分辨率的全局特征加更高权重。这样融合出来的特征,既有细节又有全局,完美适配解码器的需求。
2.3.3 CSMF 的优势:比传统融合方法强在哪?
传统的特征融合方法要么直接相加,要么直接相乘,根本不考虑特征的有用性和语义差异。而 CSMF 有两个明显优势:
- 注意力筛选:通过通道 + 空间注意力,只保留有用特征,剔除无用噪声,融合效率比传统方法提升 4%-5%;
- 多尺度对齐:通过上 / 下采样消除语义 gap,让融合特征在全网络中语义一致,分割边界精度提升 2%-3%。
论文中的消融实验也证明了这一点:用 CSMF 的模型 JAC 达到 79.31%,而不用 CSMF、直接相加的模型 JAC 只有 74.56%,差距非常明显。
2.4 解码器与损失函数:从融合特征到分割结果,精准优化
CSMF 输出 3 组融合特征后,会送入解码器。解码器的结构比较常规,主要通过 3 次上采样操作,把融合特征的分辨率恢复到原始图像大小(比如从 12×16 恢复到 192×256),同时通过 "跳连接" 把编码器的特征直接传给解码器,进一步补充细节信息。
但 Pact-Net 的解码器有个小创新:深度监督。它不是只在解码器的最后输出层计算损失,而是在 3 个 CSMF 输出层和 3 个解码器中间层共 6 个位置计算损失。这样做能让模型在训练过程中更早发现错误,避免训练 "走偏"------ 比如如果某个中间层的分割结果漏了小病变,深度监督会及时调整参数,让后续层不再犯同样的错。
损失函数方面,Pact-Net 用了**"加权 IOU 损失 + Binary Cross Entropy(BCE)损失"** 的组合:
- 加权 IOU 损失:比传统 IOU 损失更关注病变边缘。它会给边缘像素加更高权重,让模型在分割时更精准地定位病变边界;
- BCE 损失:适配医学图像分割的 "二分类任务"(像素要么是病变,要么是健康皮肤),能有效区分两类像素。
组合损失函数的公式是:。实验证明,这个组合比单一损失函数的效果好得多 ------ 用组合损失的模型 DICE(Dice 系数)达到 86.23%,而只用 IOU 损失的模型 DICE 只有 84.32%。
三、实验结果:碾压 SOTA!Pact-Net 在三大任务中表现封神
讲完了模型设计,咱们最关心的肯定是:Pact-Net 到底有多厉害?论文在三个医学图像分割任务上做了实验:皮肤病变分割、息肉分割、细胞分割。每个任务都用了多个公开数据集,结果只能用 "封神" 来形容 ------ 全面碾压 U-Net、U-Net++、Transfuse 等 SOTA 模型。
3.1 皮肤病变分割:ISIC 三大数据集全面夺冠
皮肤病变分割是 Pact-Net 的主要目标任务,实验用了 ISIC 系列的三个权威数据集:ISIC 2016、ISIC 2017、ISIC 2018。这三个数据集是国际皮肤成像协作组织(ISIC)发布的,包含了来自全球多个医疗中心的皮肤镜图像,是皮肤病变分割领域的 "金标准"。
实验的主要评价指标是T-JAC(阈值 Jaccard)------ 这是 ISIC 挑战赛的官方主指标,规则是:如果 JAC≥0.65,就算有效分割;否则算无效分割。T-JAC 越高,说明模型的稳定分割能力越强。
咱们先看 ISIC 2018 数据集的对比结果(因为这个数据集最大,最有说服力):
| 模型 | T-JAC(%) | JAC(%) | DICE(%) | ACC(%) |
|---|---|---|---|---|
| U-Net | 77.56 | 77.33 | 85.45 | 94.01 |
| U-Net++ | 78.51 | 78.56 | 87.61 | 94.98 |
| Transfuse | 81.01 | 84.47 | 90.89 | 95.48 |
| Pact-Net(Ours) | 84.14 | 84.32 | 90.75 | 96.91 |

从表格能看出,Pact-Net 的 T-JAC 达到 84.14%,比第二名 Transfuse 高 3.13 个百分点,比传统 U-Net 高 6.58 个百分点。这意味着在 ISIC 2018 的 260 张测试图中,Pact-Net 能正确分割的图像数量比 Transfuse 多 8 张左右 ------ 别小看这 8 张,在临床诊断中,每多正确分割一张,就可能多挽救一个生命。
再看 ISIC 2016 和 ISIC 2017 数据集:
- ISIC 2016:Pact-Net 的 T-JAC 达到 84.06%,比第二名高 2.93 个百分点;
- ISIC 2017:Pact-Net 的 T-JAC 达到 72.99%,比第二名高 1.98 个百分点。

而且 Pact-Net 在其他指标上也全面领先:ACC(准确率)达到 96.91%,意味着每 100 个像素中,只有 3 个会被误判;DICE(Dice 系数)达到 90.75%,意味着分割结果和医生标注的金标准(GT)重合度极高。
论文还做了可视化对比,从图中能明显看出:Pact-Net 分割出来的病变边界最接近 GT,尤其是在有毛发遮挡、低对比度的复杂场景下 ------ 比如某张图像中病变被毛发挡住了一部分,U-Net 和 Transfuse 都漏判了被遮挡的区域,而 Pact-Net 通过融合局部细节(毛发间隙的病变纹理)和全局信息(病变整体形态),精准分割出了完整的病变区域。
3.2 息肉分割:Kvasir 数据集 DICE 突破 90%
为了验证 Pact-Net 的泛化能力(能不能处理其他类型的医学图像),论文还在息肉分割任务上做了实验,用了 Kvasir 这个权威的息肉数据集(包含 1000 张结肠镜下的息肉图像)。
对比结果如下:
| 模型 | DICE(%) | IOU(%) |
|---|---|---|
| U-Net | 89.55 | 83.51 |
| U-Net++ | 89.65 | 83.71 |
| Transfuse | 90.26 | 83.90 |
| Pact-Net(Ours) | 90.61 | 84.71 |
Pact-Net 的 DICE 达到 90.61%,IOU 达到 84.71%,比 Transfuse 分别高 0.35 和 0.81 个百分点。息肉分割的难点在于息肉和肠道黏膜的颜色很接近,边界模糊,但 Pact-Net 通过 CNN 抓息肉的局部纹理(比如息肉表面的褶皱)和 Transformer 抓息肉的全局位置(比如息肉在肠道的哪个部位),依然实现了高精度分割。
3.3 细胞分割:DSB2018 数据集 IOU 接近 80%
最后,论文在细胞分割任务上做了实验,用了 DSB2018 数据集(Kaggle 细胞分割竞赛的数据集,包含 670 张细胞图像)。细胞分割的难点在于细胞数量多、大小不一,而且细胞之间可能重叠。
对比结果如下:
| 模型 | DICE(%) | IOU(%) |
|---|---|---|
| U-Net | 85.57 | 76.47 |
| U-Net++ | 86.02 | 77.20 |
| Transfuse | 87.10 | 78.59 |
| Pact-Net(Ours) | 87.53 | 79.28 |
Pact-Net 的 DICE 达到 87.53%,IOU 达到 79.28%,比 Transfuse 分别高 0.43 和 0.69 个百分点。这说明 Pact-Net 不仅能处理皮肤病变、息肉这种 "大目标",还能处理细胞这种 "小目标",泛化能力极强。
四、消融实验:搞懂每个模块到底有多重要
一篇好的论文不仅要展示模型的性能,还要证明每个模块的必要性 ------ 也就是**"ablation study(消融实验)"**。这篇论文通过消融实验,逐一验证了双分支编码器、CSF 子模块、SSMF 子模块的重要性。
4.1 双分支编码器的必要性
实验对比了 "单 CNN 分支"、"单 Transformer 分支" 和 "双分支" 的性能:
| 模型 | ACC(%) | JAC(%) | DICE(%) |
|---|---|---|---|
| 单 CNN 分支 | 93.56 | 77.15 | 85.51 |
| 单 Transformer 分支 | 87.44 | 51.99 | 65.53 |
| 双分支(Ours) | 94.35 | 79.31 | 86.23 |
结果很明显:双分支的性能全面优于单分支。尤其是单 Transformer 分支,JAC 只有 51.99%,说明纯 Transformer 在局部特征提取上真的不行;而双分支通过互补,把 JAC 提升了 27.32 个百分点,充分证明了双分支结构的必要性。
4.2 CSF 和 SSMF 子模块的必要性
实验对比了 "无 CSF"、"无 SSMF" 和 "完整 CSMF" 的性能:
| 模型 | JAC(%) | DICE(%) |
|---|---|---|
| 基础模型(BM) | 72.34 | 81.58 |
| BM+CSF | 74.56 | 84.32 |
| BM+SSMF | 75.60 | 85.05 |
| BM+CSF+SSMF(Ours) | 79.31 | 86.23 |
从结果能看出:
- 加了 CSF 后,JAC 提升了 2.22 个百分点,说明通道 - 空间注意力能有效筛选关键特征;
- 加了 SSMF 后,JAC 提升了 3.26 个百分点,说明多尺度融合能有效消除语义 gap;
- 同时加 CSF 和 SSMF 后,JAC 提升了 6.97 个百分点,说明两个子模块是 "相辅相成" 的,缺一不可。
4.3 CNN 分支基础模型的选择
实验对比了 ResNet、VGG、MobileNet、ConvNeXt 等常用 CNN 模型作为分支的性能:
| 模型 | ACC(%) | JAC(%) | DICE(%) |
|---|---|---|---|
| VGG | 90.23 | 75.42 | 77.47 |
| MobileNet | 93.89 | 77.74 | 85.44 |
| ConvNeXt(tiny) | 91.53 | 70.86 | 79.98 |
| ResNet(Ours) | 94.35 | 79.31 | 86.23 |
结果显示,ResNet 作为 CNN 分支的性能最好。原因是 ResNet 的残差连接能更好地保留局部细节,而且和 Swin Transformer 的兼容性更强 ------ 其他模型要么细节保留不够(如 VGG),要么计算量太大(如 ConvNeXt),只有 ResNet 能在 "细节保留" 和 "计算效率" 之间找到平衡。
五、Pact-Net 的局限性与未来方向
虽然 Pact-Net 的性能很惊艳,但它也不是完美的。论文诚实地指出了三个局限性,这也是未来可以优化的方向:
5.1 小数据集泛化能力弱
Pact-Net 在大规模数据集(如 ISIC 2017,2750 张图)上表现很好,但在小数据集或未训练过的数据集上表现一般。比如在 ETIS 息肉数据集(只有 192 张图)上,Pact-Net 的 IOU 只有 63.58%,远低于在 Kvasir 数据集上的 84.71%。
未来方向:引入迁移学习,用大规模通用医学数据集预训练模型,再用小数据集微调;或者设计轻量化的 Transformer 层,减少模型对数据量的依赖。
5.2 复杂场景分割精度不足
在极低对比度、严重毛发遮挡的复杂场景下,Pact-Net 的分割精度依然有提升空间。比如在 ISIC 2017 数据集中,JAC<0.65 的无效分割图像有 91 张,占测试集的 15.17%。
未来方向:设计 "边界聚焦" 的损失函数,专门针对病变边界进行优化;或者增加一个辅助的边界学习网络,让模型专门学习病变边界的特征。
5.3 训练效率低
Pact-Net 的双分支结构和 CSMF 模块虽然性能强,但计算量也很大 ------ 在 NVIDIA RTX 2080Ti GPU 上,训练一轮 ISIC 2018 数据集需要 15 分钟左右,比 U-Net 慢了近 5 分钟。
未来方向:结合云计算技术,把模型训练部署在云端 GPU 集群上,提升训练速度;或者对模型进行剪枝、量化,减少冗余参数,让模型在本地设备上也能快速训练和推理。
总结
总的来说,Pact-Net 是医学图像分割领域的一个重要突破,它不仅为皮肤癌早筛提供了更精准的 AI 工具,也为其他医学图像分割任务提供了可借鉴的框架。相信在不久的将来,随着模型的不断优化,Pact-Net 这类 AI 技术会走进更多医院,帮助医生更快速、更准确地诊断疾病,挽救更多生命。
如果你对 Pact-Net 感兴趣,强烈建议去读一下原文(论文标题:Pact-Net: Parallel CNNs and Transformers for medical image segmentation,发表在 Computer Methods and Programs in Biomedicine 242 (2023))。