AAAI 2026 | 告别手动Prompt!OFL-SAM2:在线少样本学习破解医学分割"多目标干扰"难题
论文题目 :OFL-SAM2: Prompt SAM2 with Online Few-shot Learner for Efficient Medical Image Segmentation
发表出处 :AAAI 2026
作者机构 :Meng Lan, Lefei Zhang, Xiaomeng Li (香港科技大学,武汉大学)
关键词:Medical Image Segmentation, Segment Anything Model 2 (SAM2), Few-shot Learning, Prompt-free
1. 🚀 省流版摘要 (TL;DR)
针对 SAM2 在医学图像分割(MIS)中严重依赖人工 Prompt 且容易受到相邻组织干扰的痛点,本文提出了一种全新的免提示(Prompt-free)框架 OFL-SAM2 。该方法通过引入一个在线少样本学习器(Online Few-shot Learner),利用极少量标注数据训练一个轻量级映射网络,为视频或 3D 序列的每一帧自动生成具有判别性的目标特征。结合自适应融合模块(AFM),该模型在仅冻结 SAM2 核心参数的情况下,在三个主流医学数据集上实现了极其优异的 SOTA 性能(例如仅用 3 个 CT Volume 训练就能大幅领先现有方法)。
2. 🧐 背景与痛点 (Motivation)
- 现有问题 :SAM2 凭借强大的流式记忆机制在自然视频分割中大放异彩,但在医学图像分析中,由于自然图像与医学图像存在巨大的领域鸿沟(Domain Gap),其零样本(Zero-shot)表现差强人意。为了弥合这一鸿沟,现有方法通常需要海量标注数据进行微调,且处理每一帧时仍需要医学专家持续提供高质量的手动 Prompt,这在处理由连续 2D 切片组成的 3D 医学影像时,工作量简直让人绝望。
- 传统方法的局限:为了摆脱手动 Prompt,业内涌现了不少 Prompt-free 的 SAM 变体(如 H-SAM)。但它们要么无法兼容 SAM2 的时空记忆机制,要么在医学图像中极其模糊的边界前败下阵来。
- 本文的切入点 :作者敏锐地发现,SAM2 在医学图像中表现不佳的核心原因在于:仅依赖像素级特征匹配的记忆注意力机制,极易被目标周围相似的干扰物(Distractors)带偏。既然手动 Prompt 能提供强有力的目标指引,那我们能不能用少样本学习在推理时**在线(Online)**生成一个"虚拟 Prompt"来锁死目标呢?OFL-SAM2 应运而生。
3. 💡 核心方法 (Methodology)
3.1 整体架构 (Overall Architecture)
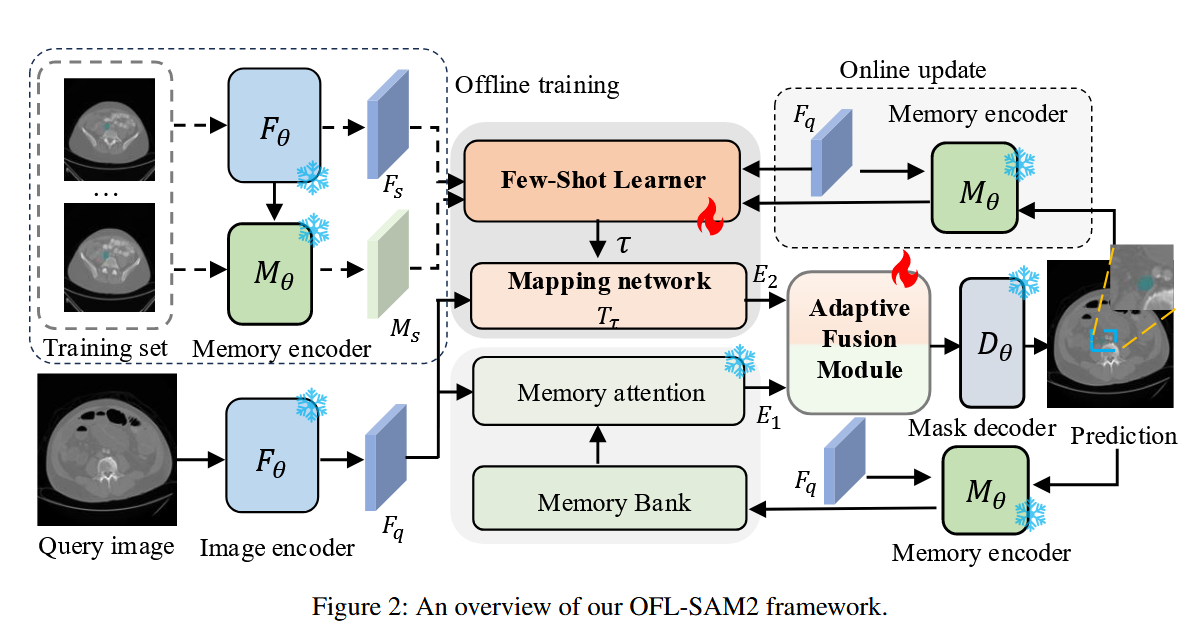
插图占位:论文中的 Figure 2 或 OFL-SAM2 整体架构图,展示 Online 和 Offline 双分支结构
OFL-SAM2 的精妙之处在于它保留了 SAM2 强大的预训练权重(全部冻结),并在其基础上构建了双分支结构:
- 离线分支(Offline Branch) :直接复用 SAM2 的记忆注意力模块(Memory Attention),提取时空上下文特征 E1E_{1}E1。
- 在线分支(Online Branch) :引入全新的映射网络(Mapping Network),将图像编码器提取的通用特征转化为特定目标的特征 E2E_{2}E2。
3.2 关键模块详解 (Key Modules)
-
模块 A:在线少样本学习器 (Online Few-shot Learner)
这是一个能在推理阶段实时进化的模块!在训练阶段,它利用有限的标注样本(比如仅仅 2-3 个病人的 3D 扫描)通过最小化平方误差来优化一个极其轻量(仅一层卷积)的映射网络 TτT_{\tau}Tτ。其数学优化目标为:
L(τ)=12∑∣∣Tτ(FSi)−MSi∣∣2+λ2∣∣τ∣∣2L(\tau)=\frac{1}{2}\sum||T_{\tau}(F_{S_{i}})-M_{S_{i}}||^{2}+\frac{\lambda}{2}||\tau||^{2}L(τ)=21∑∣∣Tτ(FSi)−MSi∣∣2+2λ∣∣τ∣∣2
这个网络就像一个经验丰富的医生,能把通用的图像特征 FSiF_{S_{i}}FSi 直接"翻译"成聚焦病灶的目标特征。在推理时,它还会利用高质量的预测结果进行在线参数更新,让模型在面对从未见过的新鲜序列时也能保持极强的泛化能力。
-
模块 B:自适应融合模块 (Adaptive Fusion Module, AFM)
既然有了原生的记忆特征 E1E_{1}E1 和新生成的"虚拟 Prompt"特征 E2E_{2}E2,如何将它们完美结合输入给冻结的解码器?AFM 利用一个由 3×33\times33×3 卷积和 Sigmoid 激活函数组成的权重网络,动态计算出一个像素级的权重图 WWW。
W=Gθ(E1,E2)W=G_{\theta}(E_{1},E_{2})W=Gθ(E1,E2)
Etar=W⊙E1+(1−W)⊙E2E_{tar}=W\odot E_{1}+(1-W)\odot E_{2}Etar=W⊙E1+(1−W)⊙E2这种特征重标定(Feature Recalibration)机制能够智能地平衡两个分支的贡献,强力镇压背景中那些长得像肿瘤的"干扰物"(Distractors),生成最纯粹的目标特征 EtarE_{tar}Etar。
-
策略 C:质量感知更新策略 (Quality-aware Update Strategy)
为了防止在线学习时被错误的预测"带进沟里",作者设计了一个置信度打分机制 Scf\mathcal{S}_{cf}Scf。只有当预测的置信度大于阈值(如 γ=0.8\gamma=0.8γ=0.8)时,该帧的特征才会被送入记忆库(Memory Bank)并用于更新映射网络。
4. 📊 实验与结果 (Experiments)
- 数据集:涵盖了三种截然不同的模态:Synapse-CT(多器官分割)、PROMISE12(前列腺 MRI)以及 Autolaparo(腹腔镜手术视频分割)。
- 对比实验 :笔者注意到,OFL-SAM2 在极端缺乏数据的情况下依然把对手按在地上摩擦。在 Synapse-CT 上,仅使用 3 个 Volume 的数据进行训练 ,OFL-SAM2 就斩获了 82.52% 的平均 Dice 分数,比使用相同数据的 FATE-SAM2(也是基于 SAM2 的方法)足足高了 6.14%!
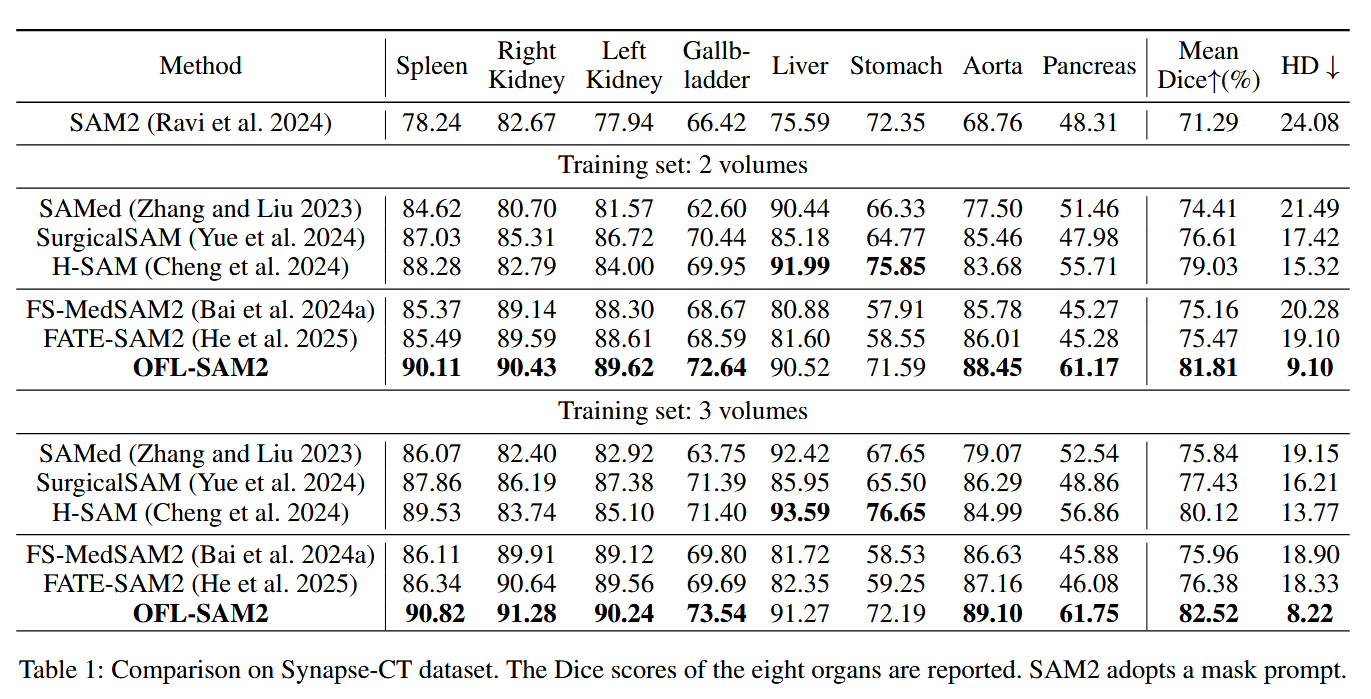
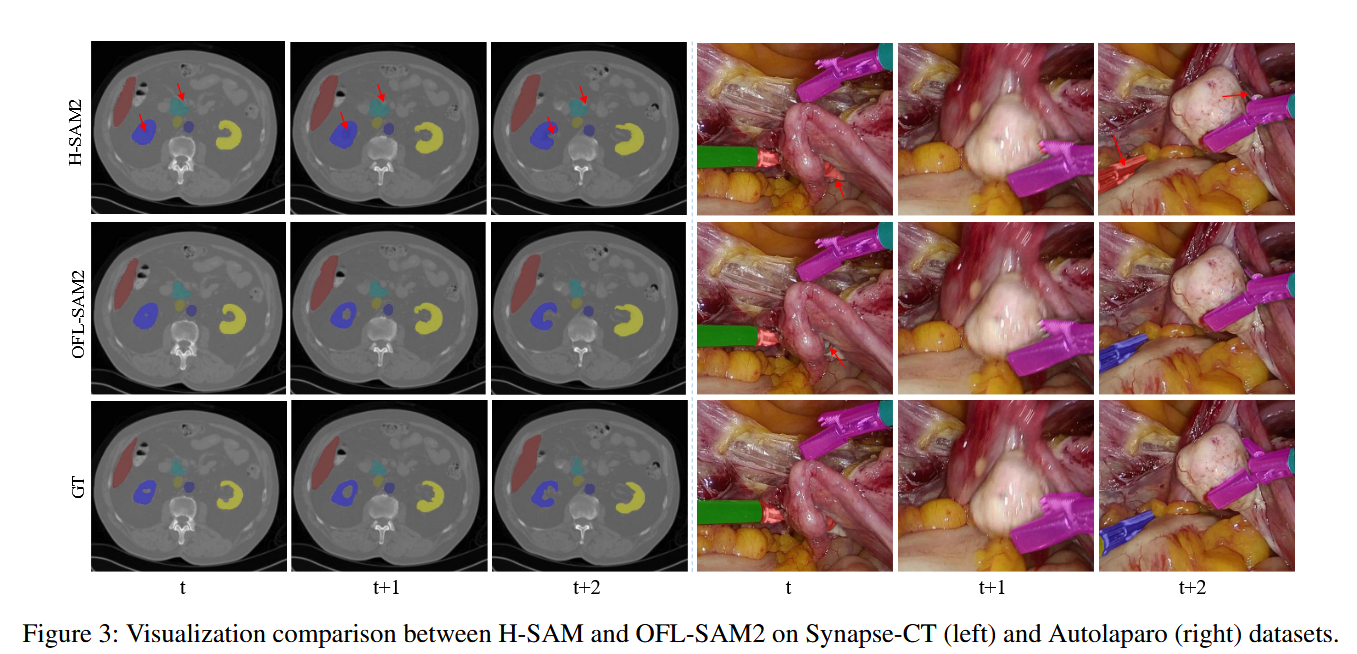
插图占位:论文中的 Table 1 性能对比表格及 Figure 3 可视化效果图
- 消融实验 (Ablation Study):少样本学习器和 AFM 模块堪称"黄金搭档"。在 Synapse 数据集上,如果不加这两个模块,原始架构只有 74.74% 的 Dice;单独加上少样本学习器能飙升到 78.96%;两者结合则直接登顶 82.52%。
- 可视化展示:从原论文的对比图可以清晰地看到,当目标组织(如细小的血管或边界模糊的器官)附近出现外观极其相似的干扰组织时,H-SAM 往往会发生误判,而 OFL-SAM2 依靠在线生成的判别性特征,能够像手术刀一样精准剥离干扰。
5. 🧠 笔者思考与总结 (Conclusion & Thoughts)
对于各位目前正在冲刺顶会或者死磕少样本学习(Few-shot Learning)前沿方向的同行来说,这篇文章无疑提供了一个极其优雅的破局思路。
- 优点总结:这篇文章最大的亮点在于其"四两拨千斤"的设计哲学。它没有选择暴力微调 SAM2 庞大的主干网络,而是创新性地引入了一个仅包含单层卷积的在线少样本学习器。这种"在线更新(Online Update)"策略完美地替代了繁琐的手动 Prompt,既保留了 SAM2 强大的时空连贯性,又彻底解决了医学图像中让人头疼的干扰物(Distractor)问题。
- 潜在局限:尽管作者强调新增的映射网络和融合模块非常轻量,但在临床推理阶段引入帧级别的"在线梯度更新",势必会对推理的实时性(FPS)提出一定挑战,这在处理高帧率的手术视频(如 Autolaparo 数据集)时可能会成为落地的工程瓶颈。
- 未来展望:这种"利用在线微型网络将通用特征转化为特定 Prompt"的思想,其实不仅局限于 SAM2 或医学图像。在任何存在明显 Domain Gap 且标注成本高昂的密集预测任务中(比如工业缺陷检测、遥感图像分析),这种基于 Online Few-shot Learner 的自适应范式都具有巨大的启发意义。
(本文由AI辅助解读,仅供参考,详细内容请查阅原论文)