(一)引言
大语言模型存在输入上下文 token 限制、不具备记忆能力等问题。而记忆能力是把 LLM 从简单的问答工具变成真正协作伙伴的关键。一个只能"回答当前问题",另一个能"基于历史经验做决策",这就是增加了记忆能力后的改进。
在智能体的记忆中长期记忆尤为重要。长期记忆的核心价值是存储可复用的历史经验 (如成功案例、用户反馈、规则迭代记录等),并支持通过语义相似性检索 快速匹配当前任务场景,辅助决策。
向量数据库(如 Milvus、FAISS、Qdrant等)因其能高效存储和检索高维向量的特性,成为长期记忆的理想载体,同时向量数据库还有助于解决大模型幻觉问题。
(二)概念与技术原理
1. 概念
向量数据库 的核心是把文本转换为向量,然后存储在向量数据库中,并提供向量相似性检索。
举个例子,当用户需要大模型根据提供的文档回答问题时,大模型先将文档的文本信息转化为向量存储到向量数据库中,当后续用户提问相关问题时,大模型将用户提出的问题转化为向量,在向量数据库中搜索出最相似的上下文向量,再返回给大模型。
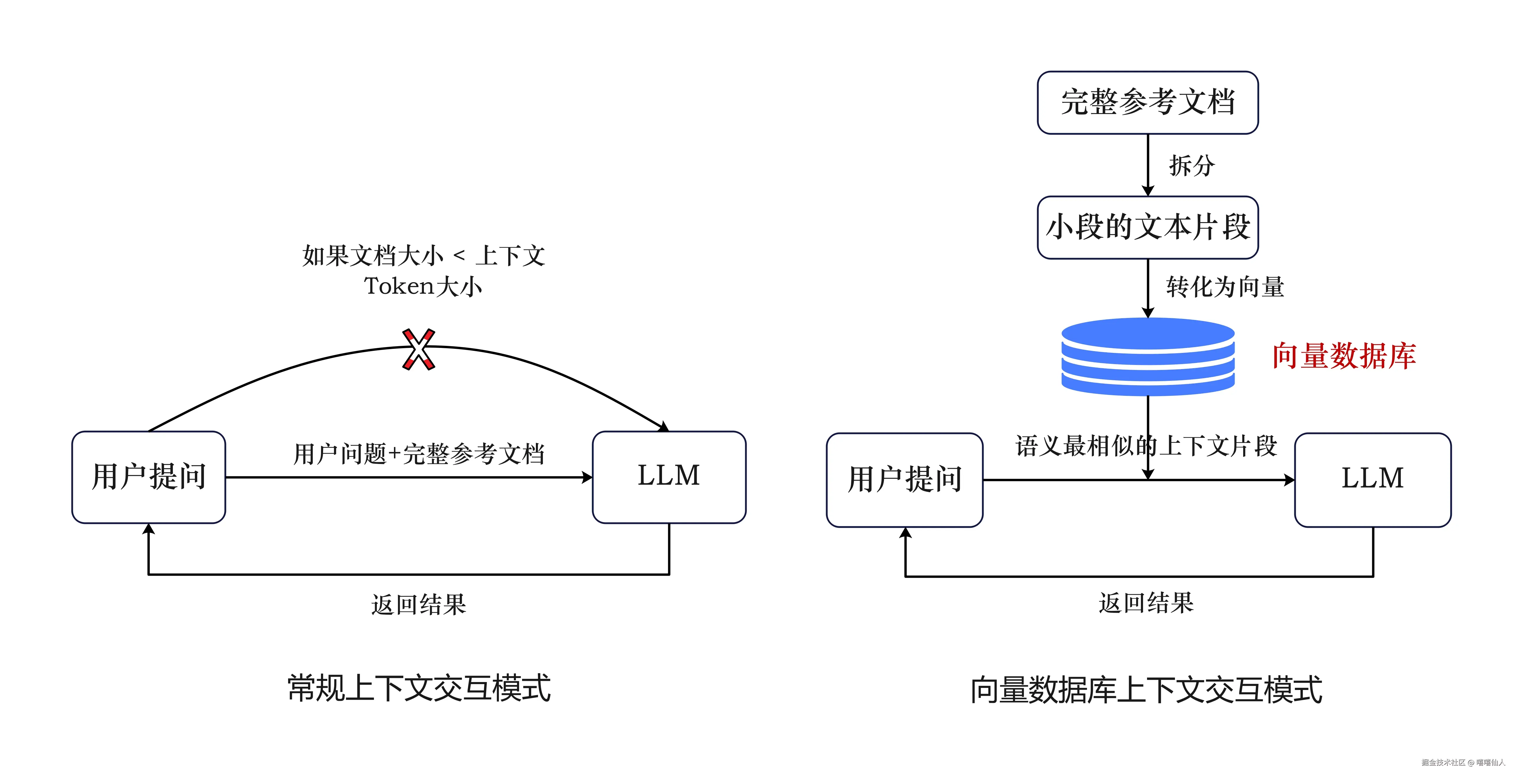
这种信息处理方式不仅能大幅减少LLM的计算量,提高响应速度,更重要的是能降低成本,并避开LLM的 tokens 限制。如果文档手册的大小是1GB甚至更大,由于LLM的上下文窗口限制,如果直接把整个文档手册喂给LLM,会撑爆Token上限导致报错。而有了向量数据库,我们会
- 提前将文档手册拆分成无数个小的文本片段(比如每 500 字一段),并将这些片段转化为向量存入数据库;
- 当用户提问相关问题时,系统不会把整个大文档给LLM,而是先在向量数据库里搜索与问题语义最相似的那几个小片段;
- 最后,系统只把这几个最相关的片段(可能只有几百个字)连同用户的问题一起发给LLM。无论你的原始文档多大,每次实际发送给LLM的永远只是那一点点最核心的"参考资料"。
这样不仅永远不会超出 Token 限制,还能让LLM处理海量的知识库。
2. 技术原理
(1)词嵌入技术
传统数据库一般通过不同的索引方式(如B Tree、倒排索引)和关键词匹配等方法实现,只能搜索到和词语本身匹配程度最高的内容,而不能搜索到和词语语义匹配的内容,本质上基于文本精确匹配,语义搜索功能较弱。
词嵌入技术可以使用模型提取不同关键词的特征,得到特征向量,不同向量之间可通过内积或余弦判断其相似关系,这样就可以使用特征向量进行语义搜索。
(2)相似度度量
常见的向量相似性的度量方法有三种:
- 欧氏距离:反映两个向量之间的绝对距离,适用于需要考虑向量长度的相似度计算。例如,在推荐系统中,需要根据用户的历史行为来推荐相似的商品,这种情况下,需要考虑用户历史行为的数量,而不仅仅是用户历史行为相似度。
- 余弦相似度:表示两个向量之间夹角的余弦值。因为对向量做了归一化,所以对长度并不敏感,适合计算文档相似性。
- 点积:指两个向量之间的点积值。点积的优点是计算速度快,同时兼顾了长度和方向,适用于图像识别、语义检索等场景。
(3)主流算法
当前主流算法是Hierarchical Navigable Small Word(HNSW)层次化可导航小世界算法。该算法凭借"高维向量下的低延迟、高召回率"成为RAG的首选检索组件。
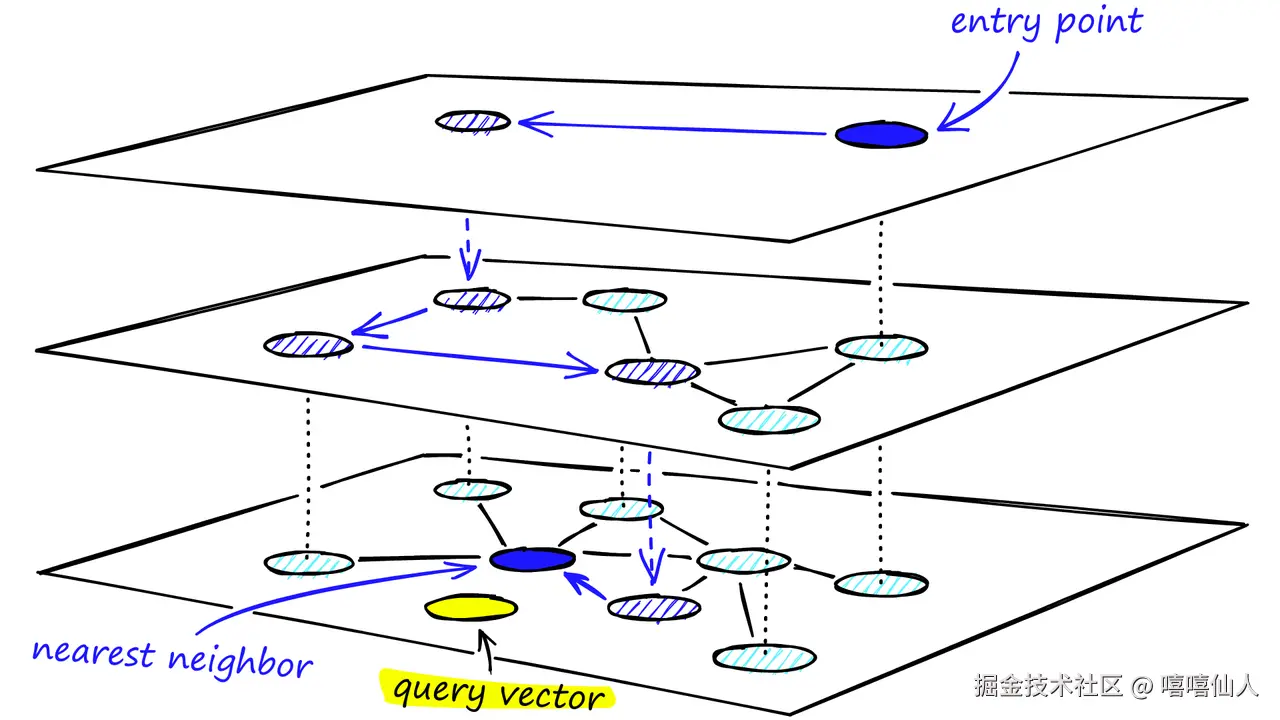
HNSW 算法具有以下特性:
- 具有高效性,通过构建多层超平面将高维数据点组织成层次化结构,降低查找最近邻时间复杂度至
O(log n)。 - 具有近似性,采用小世界导航图结构使搜索结果有近似性且可通过调整参数平衡近似程度与搜索性能。
- 同时还具有可扩展性,能轻松支持新增、删除数据点及高维空间搜索。
(三)实践
下面将解析一个具备长期记忆、语义检索、反思学习和目标管理的 AI Agent 工程实现。使用 DeepSeek 大模型 作为推理核心,SentenceTransformers 本地嵌入模型 实现语义记忆,SQLite 存储结构化记录,Chroma 作为向量数据库。整个系统可离线运行嵌入部分,仅对话需 API,适合轻量级生产环境。
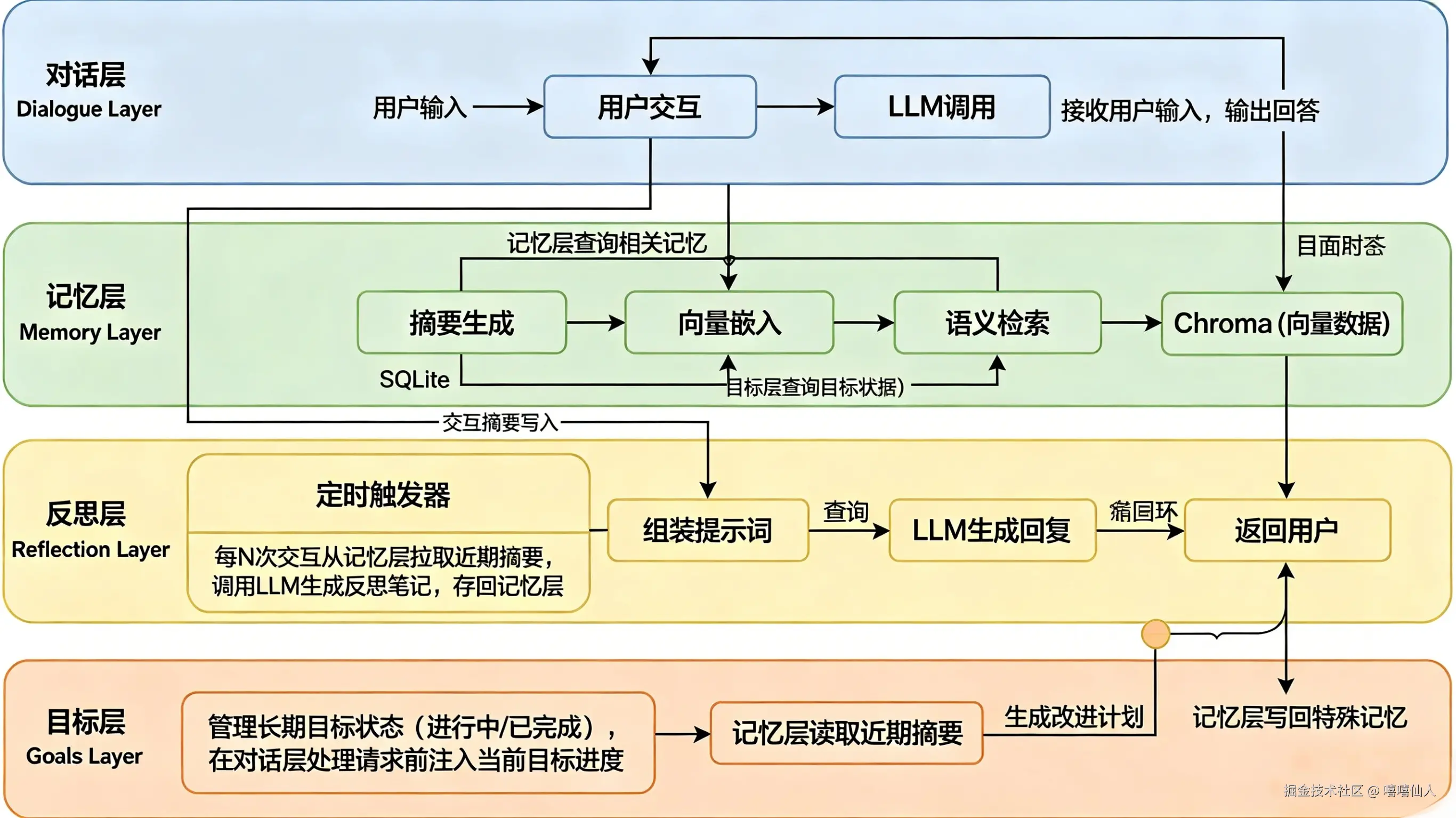
1. 整体架构
系统由四个核心层组成:
- 对话层:接收用户输入,调用 LLM 生成回答。
- 记忆层:自动生成交互摘要、嵌入并持久化,支持语义检索。
- 反思层:定期回顾最近行为,生成改进计划并入库。
- 目标层:维护长期目标,每次对话注入目标状态。
2. 初始化配置与依赖
(1)创建虚拟并激活环境
python -m venv agent_vecbase_venv
source agent_vecbase_venv/bin/activate
(2)在终端输入
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
txt
# requirements.txt
openai>=1.0.0
chromadb>=0.4.0
sentence-transformers>=2.2.0
python-dotenv>=1.0.0(3)设置环境变量文件
ini
# .env
LLM_API_KEY="sk-99fdxxxxxxxxxxxxd0c"
LLM_MODEL_ID="deepseek-v4-flash"
LLM_BASE_URL="https://api.deepseek.com"(4) 本地下载 Sentence Transformers 模型

下载并解压到工程目录 ./models/all-MiniLM-L6-v2
3. 数据库设计:SQLite 与 Chroma 双重存储
这样设计主要基于以下考虑:
- SQLite 作为可靠的结构化存储,Chroma 负责高速语义相似性搜索。
- 嵌入向量在 SQLite 中以 BLOB 备份,确保数据安全;Chroma 仅存向量和元数据,用于查询。
- 余弦相似度 (
cosine) 适合归一化后的 SentenceTransformer 向量。
(1) SQLite 表结构
python
def init_sqlite():
cur.execute("""
CREATE TABLE IF NOT EXISTS memory_events (
id INTEGER PRIMARY KEY AUTOINCREMENT, # 唯一标识符
agent_name TEXT, # 触发该场景的agent名称
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP, # 事件发生时间戳
input TEXT, # 用户的原始输入内容
output TEXT, # agent生成的原始回复内容
summary TEXT, # 由LLM提炼的交互摘要,便于后续检索和理解
embedding BLOB # 记忆向量,用于后续的语义相似度检索
)
""")
cur.execute("""
CREATE TABLE IF NOT EXISTS goals (
id INTEGER PRIMARY KEY AUTOINCREMENT,
agent_name TEXT,
goal TEXT, # 具体的目标描述文本
status TEXT DEFAULT 'in_progress', # 目标当前的状态,默认为"进行中"
last_updated DATETIME DEFAULT CURRENT_TIMESTAMP # 目标最后一次更新的时间
)
""")memory_events表(情景记忆表):这张表用于记录 AI Agent 与用户每一次交互的历史事件、对话摘要以及语义向量,是实现跨会话连续性和反思能力的基础。goals表(目标跟踪表):这张表用于存储和追踪用户的长期目标或复杂任务状态,使 AI 能够理解任务之间的依赖关系并持续跟进。
(2) Chroma 向量库初始化
python
# path=CHROMA_PATH 指定了本地数据的存储路径。
client = chromadb.PersistentClient(path=CHROMA_PATH)
2. 获取或创建一个名为 "agent_memories" 的数据集合(Collection)
collection = client.get_or_create_collection(
# agent长期记忆的专属容器
name="agent_memories",
# metadata 用于配置集合的底层参数。这里指定了 HNSW 索引算法的距离计算空间为 "cosine"(余弦相似度)。
# 在 AI Agent 的记忆检索中,余弦相似度通常比默认的欧氏距离(L2)更适合衡量文本之间的语义相关性。
metadata={"hnsw:space": "cosine"}
)这段代码具体实现了一个持久化且支持语义相似度检索的向量记忆库。它主要完成了以下三个核心功能:
- 建立本地永久存储
- 获取或者创建记忆集合
- 使用HNSW搜索算法、使用余弦相似度来衡量文本之间的相关性
4. 工具函数:嵌入生成与 LLM 调用
python
def get_embedding(text: str) -> List[float]:
# normalize_embeddings=True保证向量模长为 1,使余弦相似度计算更精确。
embedding = embedding_model.encode(text, normalize_embeddings=True)
return embedding.tolist()
def llm_complete(prompt: str, max_tokens: int = 500) -> str:
response = llm_client.chat.completions.create(
model=LLM_MODEL,
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
temperature=0.2
)
return response.choices[0].message.content5. 情景记忆记录
python
def log_memory_event(self, agent_name, input_text, output_text):
summary = self.generate_summary(input_text, output_text) # 调用LLM生成摘要
embedding = get_embedding(summary)
# 写入SQLite
cur.execute("""INSERT ...""", (...))
# 写入Chroma
self.collection.add(embeddings=[embedding], documents=[summary], ...)
self.interaction_counter += 1需要注意的是以上存储的summary不是LLM的输出原文,而是LLM的输出大意,后续检索能匹配到语义相关但表述不同的历史。
6. 语义检索实现
python
def recall_related_memories(self, query, top_k=3):
query_emb = get_embedding(query)
results = self.collection.query(
query_embeddings=[query_emb],
n_results=top_k,
include=["documents"]
)
return results['documents'][0] if results['documents'] else []- 每次新请求前,将用户输入转为向量,在 Chroma 中搜索最相似的
top_k条历史摘要。 - 返回的摘要直接注入后续 prompt,作为"经验参考",模拟人类联想回忆。
7. 反思机制:从记忆到能力提升
python
def trigger_reflection(self, agent_name, n_recent=5):
# 从SQLite读取最近n条摘要
rows = cur.execute("""SELECT summary ... ORDER BY timestamp DESC LIMIT ?""", (agent_name, n_recent)).fetchall()
recent_summaries = "\n".join([f"- {r[0]}" for r in rows])
reflection = llm_complete(f"""You are reviewing... {recent_summaries} Provide 3 takeaways and 1 improvement plan""")
# 将反思结果也作为特殊记忆存入SQLite和Chroma
...- 反思结果同样生成嵌入并存储,让系统"学习自己的思考",形成元认知。
- 反思 prompt 强制输出 3 个关键点 + 1 个改进计划,结构清晰便于后续使用。
8. 目标管理:赋予 Agent 持续性
python
class GoalManager:
@staticmethod
def add_goal(agent_name, goal): ...
@staticmethod
def update_goal(agent_name, goal, status): ...
@staticmethod
def get_active_goals(agent_name): ...
@staticmethod
def check_goal_progress(agent_name):
# 返回格式化的目标状态文本- 目标独立于单次对话,可跨越多天追踪。
- 每次对话注入
check_goal_progress的输出,让 Agent 意识到当前使命,避免回答偏离长期方向。
9. Agent 主循环:将所有模块串联
python
class Agent:
def process_input(self, user_input):
related = self.memory.recall_related_memories(user_input) # 检索记忆
goal_context = GoalManager.check_goal_progress(self.name) # 获取目标
system_prompt = f"""... {goal_context} {memory_context} ..."""
response = llm_complete(full_prompt) # 生成回答
self.memory.log_memory_event(...) # 存储记录
if self.memory.interaction_counter % REFLECTION_INTERVAL == 0:
self.memory.trigger_reflection(...) # 定时反思
return response10. 完整工程实现
以Ubuntu22.04系统,Python3.10版本为例进行展示。
首先我们新建一个项目文件夹 agent_vecbase 来存放我们的所有文件。 agent_vecbase/
├── main_cn.py - 主要游戏逻辑和控制逻辑
├── requirements.txt - 依赖库
├── .env
└── README.md
main.py
python

输出以上内容说明嵌入模型加载、SQLite 建表、Chroma 初始化均成功。
(四)测试效果
1. 交互测试
(1)对话 1(简单测试)
txt
用户:什么是机器学习?
Agent 返回一段关于机器学习的解释,且无报错。此时交互计数为 1。
(2)对话 2(关联问题,测试语义检索)
txt
用户:它和深度学习有什么关系?
Agent 根据历史记录可以识别到"它"指的是第一轮对话中提到的机器学习。
(3)对话 3~5 继续任意问题,累计 5 次交互,触发反思。
txt
用户:如何学习 Python?
用户:推荐一些算法书籍。
用户:哪些书籍适合小白入门?
当对话轮数到第五轮时候,累积5次会触发反思机制,观察到以上输出说明反思机制正常。
2. 目标管理测试
退出程序(输入 quit)后,用 SQLite 命令行验证数据是否持久化。
(1)检查 memory_events 表
bash
sqlite3 agent_memory.db "SELECT id, agent_name, summary FROM memory_events;"
观察到以上用户和agent多轮交互的内容摘要。
(2)检查 goals 表
bash
sqlite3 agent_memory.db "SELECT * FROM goals;"
观察到目标数据存在,说明情景记忆存储正常。
3. 完整自动化测试脚本
创建一个 test_agent.py 文件,直接调用核心函数进行断言测试:
python
# 测试agent功能的自动化脚本
from main import MemoryManager, GoalManager, init_sqlite, init_chroma, llm_complete, get_embedding
# 初始化
init_sqlite()
chroma_collection = init_chroma()
mem_manager = MemoryManager(chroma_collection)
# 测试嵌入
emb = get_embedding("test")
assert isinstance(emb, list) and len(emb) > 0, "嵌入生成失败"
# 测试 LLM 调用(确保网络和 Key 有效)
resp = llm_complete("Hello, say 'OK'")
assert "OK" in resp, f"LLM 响应异常: {resp}"
print("LLM 调用成功")
# 测试记忆记录与检索
mem_manager.log_memory_event("TestAgent", "我喜欢狗", "狗是可爱的动物")
mem_manager.log_memory_event("TestAgent", "我喜欢猫", "猫也很可爱")
results = mem_manager.recall_related_memories("宠物", top_k=2)
assert len(results) == 2
print("检索到的摘要:", results)
# 测试反思触发(需至少5条记录,可手动插入后再测)
for i in range(3):
mem_manager.log_memory_event("TestAgent", f"test input {i}", f"test output {i}")
mem_manager.trigger_reflection("TestAgent", n_recent=5)
print("反思测试通过")
# 测试目标管理
GoalManager.add_goal("TestAgent", "测试目标")
goals = GoalManager.get_active_goals("TestAgent")
assert len(goals) > 0
print("目标管理正常")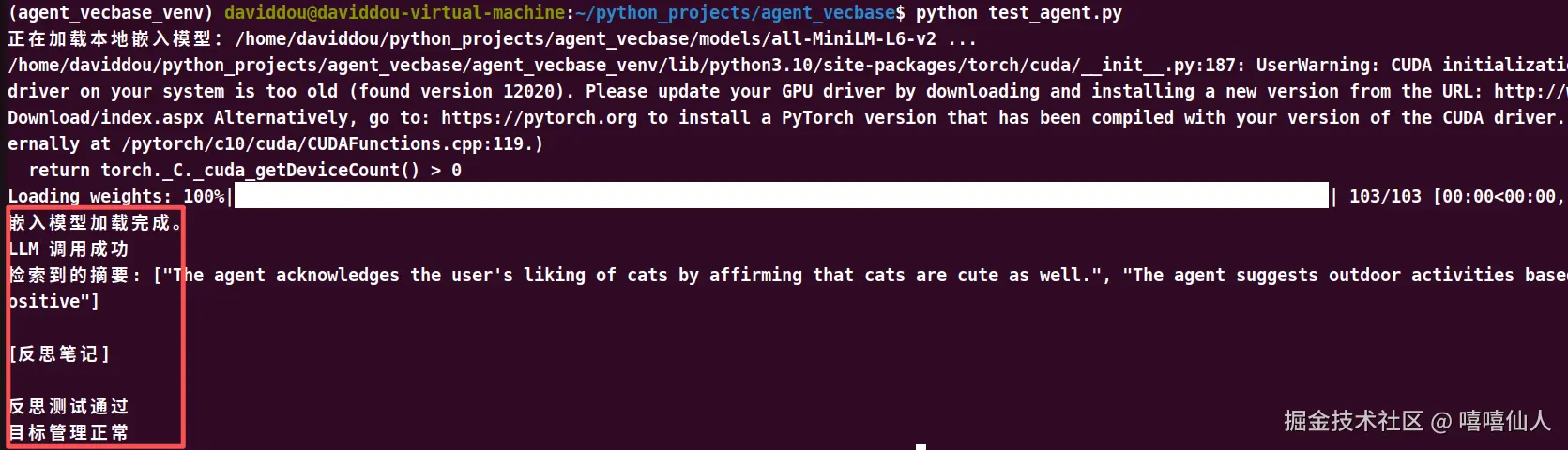
观察到以上测试输出说明基本功能正常。