一、RocketMQ 消息持久化整体设计
1.1 持久化核心价值
RocketMQ 是磁盘存储型消息中间件,所有消息默认落地磁盘持久化,彻底解决服务重启、机器宕机导致的消息丢失问题,实现消息可追溯、可重试、可恢复,是分布式消息可靠性的核心基石。
1.2 存储三大核心文件结构
RocketMQ 所有消息存储由三类文件组成,分工明确、层层协作,摒弃了 Kafka 分区日志存储模式,采用日志+索引分离的极致设计:
-
CommitLog(消息日志文件) :核心数据文件,存储全部原始消息实体,所有 Topic 的消息统一顺序写入,包含完整消息体、属性、时间、偏移量等原始数据。由多个文件组成,每个文件1G
-
ConsumeQueue(消费队列文件) :Topic 级别的索引文件,轻量化存储,不存消息内容,仅存储「消息偏移量+消息长度+Tag哈希」,专供消费者拉取消息使用。记录当前MessageQueue被哪些消费者组消费到了那一条CommitLog。
-
IndexFile(索引文件):消息检索索引,存储消息 Key、时间戳、CommitLog 偏移量,支持业务 Key 精准查询、消息轨迹追溯。
1.3 消息存储整体结构图
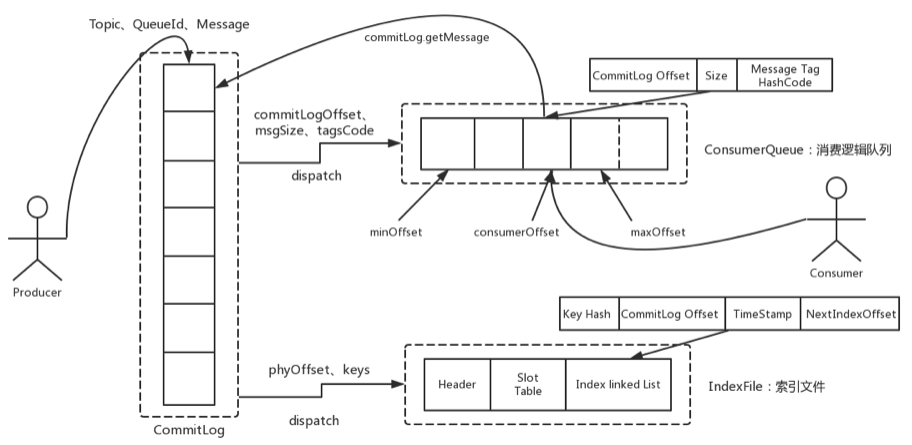
简单来说,Producer发过来的所有消息,不管是属于那个Topic,Broker都统一存在CommitLog文件当中,然后分别构建ConsumeQueue文件和IndexFile两个索引文件,用来辅助消费者进行消息检索。这种设计最直接的好处是可以较少查找目标文件的时间,让消息以最快的速度落盘。对比Kafka存文件时,需要寻找消息所属的Partition文件,再完成写入。当Topic比较多时,这样的Partition寻址就会浪费非常多的时间。所以Kafka不太适合多Topic的场景。而RocketMQ的
这种快速落盘的方式,在多Topic的场景下,优势就比较明显了。
然后在文件形式上:
CommitLog文件的大小是固定的。文件名就是当前CommitLog文件当中存储的第一条消息的Offset。
ConsumeQueue文件主要是加速消费者进行消息索引。每个文件夹对应RocketMQ中的一个MessageQueue,文件夹下的文件记录了每个MessageQueue中的消息在CommitLog文件当中的偏移量。这样,消费者通过ConsumeQueue文件,就可以快速找到CommitLog文件中感兴趣的消息记录。而消费者在ConsumeQueue文件中的消费进度,会保存在config/consumerOffset.json文件当中。
IndexFile文件主要是辅助消费者进行消息索引。消费者进行消息消费时,通ConsumeQueue文件就足够完成消息检索了,但是如果消费者指定时间戳进行消费,或者要按照Meessageld或者MessageKey来检索文件,比如RocketMQ管理控制台的消息轨迹功能,ConsumeQueue文件就不够用了。IndexFile文件就是用来辅助这类消息检索的。他的文件名比较特殊,不是以消息偏移量命名,而是用的时间命名。但是其实,他也是一个固定大小的文件。
1.4 持久化核心优势 & 常见核心问题
核心优势
-
顺序写、随机读:CommitLog 全程顺序追加写入,磁盘IO效率极高,规避机械磁盘随机写性能瓶颈。
-
读写分离:写入只操作 CommitLog,消费、查询操作索引文件,互不阻塞。
-
轻量化索引:ConsumeQueue、IndexFile 体积小、加载快,极大提升消费和检索效率。
-
统一存储:多 Topic 消息统一存储,无文件碎片化,磁盘利用率高。
生产常见核心问题
-
为什么 RocketMQ 速度快?核心:顺序写磁盘 + 内存缓存 + 读写分离
-
消息会不会丢失?刷盘机制+主从复制双重保障
-
为什么支持海量消息堆积?磁盘持久化+过期文件自动删除
-
消费速度为什么不受 Topic 数量影响?统一 CommitLog 存储,无分区文件瓶颈
二、CommitLog 写入核心原理(核心重点)
2.1 CommitLog 写入方式
CommitLog 采用全局顺序追加写入模式,所有 Topic、所有队列的消息,全部按到达时间顺序追加写入文件末尾,是 RocketMQ 高吞吐的核心根源。
文件固定大小:1GB,写满自动新建下一个文件,文件命名为起始偏移量(如 00000000000000000000),实现无缝滚动写入。
2.2 写入加锁机制(并发安全核心)
多生产者并发发送消息时,为保证消息顺序写入、偏移量连续不混乱,CommitLog 写入采用分段锁 + 全局写锁机制:
-
核心锁对象:putMessageLock(ReentrantLock 可重入锁)
-
加锁时机:消息落地 CommitLog 前统一加锁,保证同一时刻只有一条消息执行写入
-
锁粒度:全局文件锁,保证磁盘文件偏移量严格递增、消息有序存储
-
解锁时机:消息写入内存缓冲区完成后立即解锁,不阻塞刷盘、后续流程
核心作用:解决并发写入导致的文件覆盖、偏移量错乱、消息丢失问题,保证 CommitLog 日志绝对有序。
2.3 消息写入完整流程
-
Broker 接收 Producer 消息,校验消息合法性、权限、大小
-
竞争获取 putMessageLock 全局写锁
-
计算当前文件写入偏移量,判定文件是否写满,满则新建文件
-
消息封装为固定格式字节数组,追加写入 PageCache 内存缓冲区
-
更新全局最大偏移量,释放写锁
-
触发刷盘机制(同步/异步),落地磁盘
-
返回消息写入成功结果,记录消息偏移量
2.4 核心写入源码片段
// CommitLog 核心写入加锁逻辑
public PutMessageResult putMessage(final MessageExtBrokerInner msg) {
// 1. 竞争全局写锁
putMessageLock.lock();
try {
// 2. 获取当前写入文件,判断是否需要滚动新建
MappedFile mappedFile = this.mappedFileQueue.getLastMappedFile();
if (null == mappedFile || mappedFile.isFull()) {
mappedFile = this.mappedFileQueue.getLastMappedFile();
}
// 3. 写入PageCache缓冲区
long beginOffset = mappedFile.getFileFromOffset() + mappedFile.getWritePosition();
int wroteBytes = mappedFile.appendMessage(msg, this.appendMessageCallback);
// 4. 更新偏移量
if (wroteBytes > 0) {
this.maxOffset.addAndGet(wroteBytes);
}
} finally {
// 5. 释放锁
putMessageLock.unlock();
}
// 6. 执行刷盘逻辑
return flushMessage(msg);
}putMessageLock可以根据配置信息选择是SpingLock自旋锁还是ReentrantLock可重入锁。自旋锁就是一直尝试CAS直到拿到锁。ReentrantLock做一次CAS,拿不到就休眠,直到前面线程unlock的时候唤醒,继续竞争锁(非公平)。两者的区别在于如果写入的消息非常多,竞争非常激烈,适合用ReentrantLock,减少CPU空转。竞争没有那么激烈,则适合用自旋锁,得到锁的速度更快。
三、同步刷盘 & 异步刷盘机制
3.1 核心原理区别
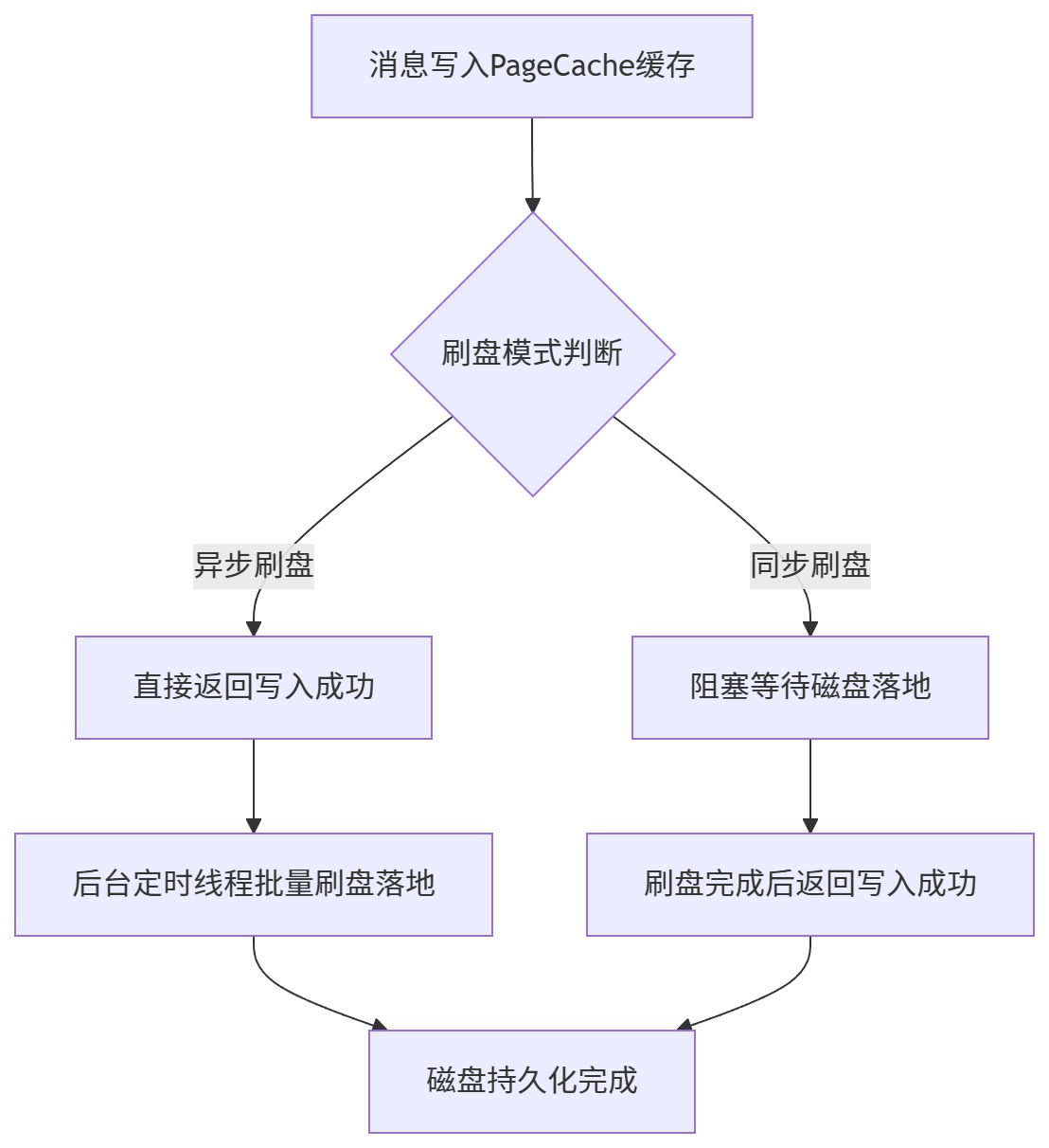
操作系统会将磁盘写入操作先缓存到 PageCache 内存页缓存 ,写入缓存不代表落地磁盘,机器宕机仍会丢失消息。刷盘机制就是将内存缓存数据强制落地磁盘的机制,RocketMQ 提供两种刷盘模式。
3.2 异步刷盘(默认模式,高性能)
原理
消息写入 PageCache 内存缓冲区后,立即返回写入成功,不等待磁盘落地。后台专属刷盘线程定时批量将内存数据刷入磁盘。
特点
-
性能极高、吞吐量大,适配绝大多数业务场景
-
极端机器宕机、断电场景会丢失少量缓存消息
-
默认刷盘间隔:100ms 批量刷盘
3.3 同步刷盘(高可靠模式)
原理
消息写入 PageCache 后,阻塞等待刷盘完成,磁盘落地成功后,才返回生产者写入成功响应。
特点
-
零消息丢失,数据绝对可靠
-
磁盘IO阻塞,性能吞吐量大幅下降
-
适配金融、支付、订单等核心零丢失业务
3.4 刷盘机制流程图
3.5 刷盘核心源码
@Override
public CompletableFuture<PutMessageStatus> handleDiskFlush(AppendMessageResult result, MessageExt messageExt) {
// Synchronization flush 同步刷盘
if (FlushDiskType.SYNC_FLUSH == CommitLog.this.defaultMessageStore.getMessageStoreConfig().getFlushDiskType()) {
final GroupCommitService service = (GroupCommitService) this.flushCommitLogService;
if (messageExt.isWaitStoreMsgOK()) {//构建request的时候从配置文件中读取了刷盘超时时间,默认5秒。
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes(),
CommitLog.this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
flushDiskWatcher.add(request);//这里只是监控刷盘是否超时。
service.putRequest(request);//实际进行刷盘,刷盘操作先排队,再执⾏。
return request.future();
} else {
service.wakeup();
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}
// Asynchronous flush
else {
if (!CommitLog.this.defaultMessageStore.isTransientStorePoolEnable()) {//默认false
flushCommitLogService.wakeup();
} else {
commitRealTimeService.wakeup();
}
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
}同步刷盘中,会采用读写队列双缓存的设计,有效提高高并发场景下数据一致性问题
四、CommitLog 主从复制机制
4.1 机制作用
单节点 Broker 存在单点故障,RocketMQ 通过主从同步复制实现消息副本备份,主节点 Master 负责读写,从节点 Slave 同步数据、提供读兜底,实现高可用、故障自动切换。
4.2 完整同步流程
-
连接建立:Slave 启动后主动连接 Master 节点,上报自身已同步的最大偏移量
-
数据拉取:Master 根据 Slave 偏移量,推送未同步的 CommitLog 数据
-
增量同步:仅同步增量数据,不重复同步历史数据,提升同步效率
-
落地存储:Slave 接收数据后,写入本地 CommitLog 并执行刷盘
-
心跳保活:主从定时心跳,维持同步连接,断连后自动重连续传
4.3 主从复制核心关注点
-
异步复制:Master 写入成功即返回,不等待 Slave 同步完成,性能高,短暂宕机可能丢失少量数据
-
同步复制:Master 等待 Slave 同步完成后再返回,数据零丢失,性能较低
-
偏移量续传:支持断点续传,重启后从上次偏移量继续同步,无需全量同步
-
读写分离:默认消费优先从 Slave 读取,减轻 Master 压力
五、ConsumeQueue 和 IndexFile 分发机制
5.1 分发核心逻辑
CommitLog 存储全量消息,但消费者无法直接遍历大文件消费。RocketMQ 启动后台异步分发线程 reputMessageService,将 CommitLog 原始消息拆解,生成两类索引文件。
5.2 ConsumeQueue 消费队列分发流程
ConsumeQueue 是 Topic+队列维度的轻量化索引,每条索引固定 20 字节,结构:CommitLog偏移量(8byte) + 消息长度(4byte) + Tag哈希值(8byte)。
-
分发线程扫描最新写入的 CommitLog 数据
-
根据消息的 Topic、QueueId 归属对应队列
-
提取消息偏移量、长度、Tag哈希,生成索引条目
-
追加写入对应 ConsumeQueue 文件
-
消费者消费时,先读取 ConsumeQueue 索引,再精准定位 CommitLog 原始消息
5.3 IndexFile 索引文件分发流程
IndexFile 用于消息精准检索,支持根据业务 Key、时间戳查询消息。
-
解析消息自定义 Keys 属性
-
将 Key、消息时间戳、CommitLog 偏移量封装为索引
-
写入 IndexFile 哈希索引结构
-
支持后台快速检索、消息轨迹排查、异常回溯
5.4 分发核心特点
-
异步分发:不阻塞消息写入主流程,不影响吞吐
-
解耦读写:写入只操作 CommitLog,消费查询只操作索引文件
-
极致轻量化:索引文件体积极小,百万级消息索引仅占用少量磁盘
六、过期文件自动删除机制
6.1 机制作用
RocketMQ 消息默认保留 72小时,过期消息自动清理,避免磁盘无限膨胀,同时保留可追溯窗口期,平衡磁盘占用与消息可回溯性。删除的时候并未关注消息是否删除,会导致业务数据受损
6.2 删除核心规则
-
默认保留时长:72h(可自定义配置)
-
删除对象:过期的 CommitLog、ConsumeQueue、IndexFile 完整文件
-
删除前提:文件内所有消息均过期,不会删除正在写入的活跃文件
-
磁盘保护:磁盘使用率过高时,强制提前删除过期文件,防止磁盘打满
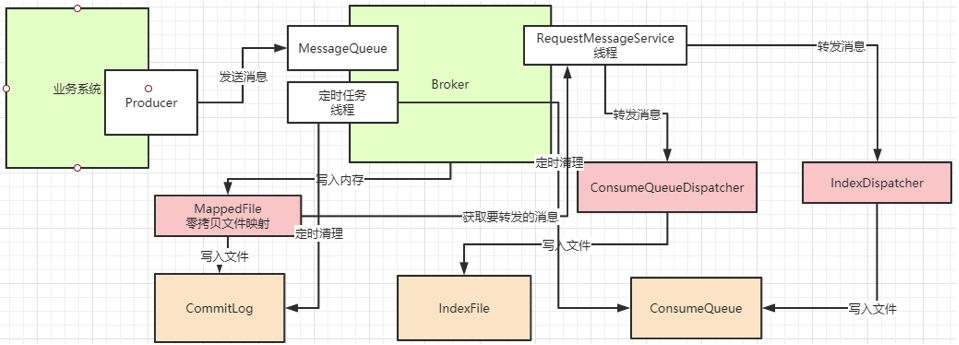
6.3 过期文件删除流程
-
后台定时清理线程(默认每 10s 执行一次)
-
遍历所有存储文件,获取文件最后更新时间
-
对比系统当前时间,判断文件是否超过保留时长
-
校验文件是否为活跃写入文件,非活跃且过期则标记待删除
-
执行文件删除,同步释放磁盘空间
-
更新文件队列索引,保证新消息正常写入
6.4 过期文件源码解析
入口:DefaultMessageStore.addScheduleTask -> DefaultMessageStore.this.cleanFilesPeriodically() 和DefaultMessageStore.this.cleanQueueFilesPeriodically()
在这个方法中会启动两个线程,cleanCommitLogService用来删除过期的CommitLog文件,cleanConsumeQueueService用来删除过期的ConsumeQueue和IndexFile文件。
在删除CommitLog文件时,Broker会启动后台线程,每60秒,检查CommitLog、ConsumeQueue文件。然后对超过72小时的数据进行删除。也就是说,默认情况下,RocketMQ只会保存3天内的数据。这个时间可以通过fileReservedTime来配置。触发过期文件删除时,有两个检查的纬度,一个是,是否到了触发删除的时间,也就是broker.conf里配置的deleteWhen属性。另外还会检查磁盘利用率,达到阈值也会触发过期文件删除。这个阈值默认是72%,可以在broker.conf文件当中定制。但是最大值为95,最小值为10。然后在删除ConsumeQueue和IndexFile文件时,会去检查CommitLog当前的最小Offset,然后在删除时进行对齐。需要注意的是,RocketMQ在删除过期CommitLog文件时,并不检查消息是否被消费过。所以如果有消息长期没有被消费,是有可能直接被删除掉,造成消息丢失的。
6.4 过期文件删除流程图
七、三大文件索引结构详解
7.1 CommitLog 结构
不定长文件,单文件 1GB,顺序追加,存储完整原始消息数据,包含消息头、消息体、属性、时间戳、队列ID、偏移量、CRC校验码等全量信息,是消息的唯一数据源。由于该文件的大小固定,所以存储时单元长度是不一致的,因此每个数据前会存储数据的字节长度,计算规则如下:
public static int calMsgLength(MessageVersion messageVersion,
int sysFlag, int bodyLength, int topicLength, int propertiesLength) {
int bornhostLength = (sysFlag & MessageSysFlag.BORNHOST_V6_FLAG) == 0 ? 8 : 20;
int storehostAddressLength = (sysFlag & MessageSysFlag.STOREHOSTADDRESS_V6_FLAG) == 0 ? 8 : 20;
return 4 //TOTALSIZE
+ 4 //MAGICCODE
+ 4 //BODYCRC
+ 4 //QUEUEID
+ 4 //FLAG
+ 8 //QUEUEOFFSET
+ 8 //PHYSICALOFFSET
+ 4 //SYSFLAG
+ 8 //BORNTIMESTAMP
+ bornhostLength //BORNHOST
+ 8 //STORETIMESTAMP
+ storehostAddressLength //STOREHOSTADDRESS
+ 4 //RECONSUMETIMES
+ 8 //Prepared Transaction Offset
+ 4 + (Math.max(bodyLength, 0)) //BODY
+ messageVersion.getTopicLengthSize() + topicLength //TOPIC
+ 2 + (Math.max(propertiesLength, 0)); //propertiesLength
}7.2 ConsumeQueue 结构
定长 20 字节单条索引,纯索引无业务数据,结构固定:
-
8Byte:CommitLog 物理偏移量
-
4Byte:消息序列化长度
-
8Byte:消息 Tag 哈希值
优势:定长结构可通过偏移量快速定位索引,消费效率极高。
7.3 IndexFile 索引结构
采用哈希索引+链表结构,解决消息 Key 重复问题:
-
索引头:存储文件基础信息、索引数量
-
哈希槽:映射消息 Key 哈希值
-
索引链表:相同哈希值的消息形成链表,支持冲突解决
-
存储内容:消息Key、时间戳、CommitLog偏移量、下一个索引位置
作用:支撑业务维度精准消息检索,是消息排查、轨迹追溯的核心。