MonkeyCode教程 / 基础入门篇 / MC-027
MonkeyCode私有化部署全攻略:架构解析+4步部署+在线版对比
作者:不爱土豆唯爱马铃薯分类:AI编程工具阅读约5分钟
前言
前 26 期我们一直在用 MonkeyCode 的在线版------打开浏览器、登录账号、开始写代码。对个人开发者来说,这完全够用。
但如果你在一家对数据安全有要求的公司,或者你的项目涉及敏感信息(金融、医疗、军工),在线版可能就不合适了。原因很简单:你的代码和数据会经过云端。
这就是私有化部署的意义:把 MonkeyCode 装到你自己的服务器上,代码和数据完全不出内网。
哪些场景需要私有化部署?
数据合规要求
金融、医疗、政务、军工等行业,法规明确要求核心数据不得离开内网。代码作为核心资产,交给第三方云端处理存在合规风险。私有化部署让所有 AI 推理过程在本地完成,代码从输入到输出全程可控。
大型企业统一管理
公司有上百个开发者,各自用各种 AI 工具,安全审计根本无从做起。私有化部署提供统一的管理后台------谁能用什么模型、消耗了多少资源、产出了什么代码,全部有据可查。
对接内部基础设施
很多企业有自己的 GitLab、CI/CD 流水线、内部知识库。私有化版可以把 MonkeyCode 嵌入到现有的研发流程中,而不是让开发者切来切去。
离线环境使用
部分涉密单位网络是物理隔离的,根本无法访问外部服务。私有化部署支持离线运行------模型提前部署到本地,不依赖外部网络。
架构解析
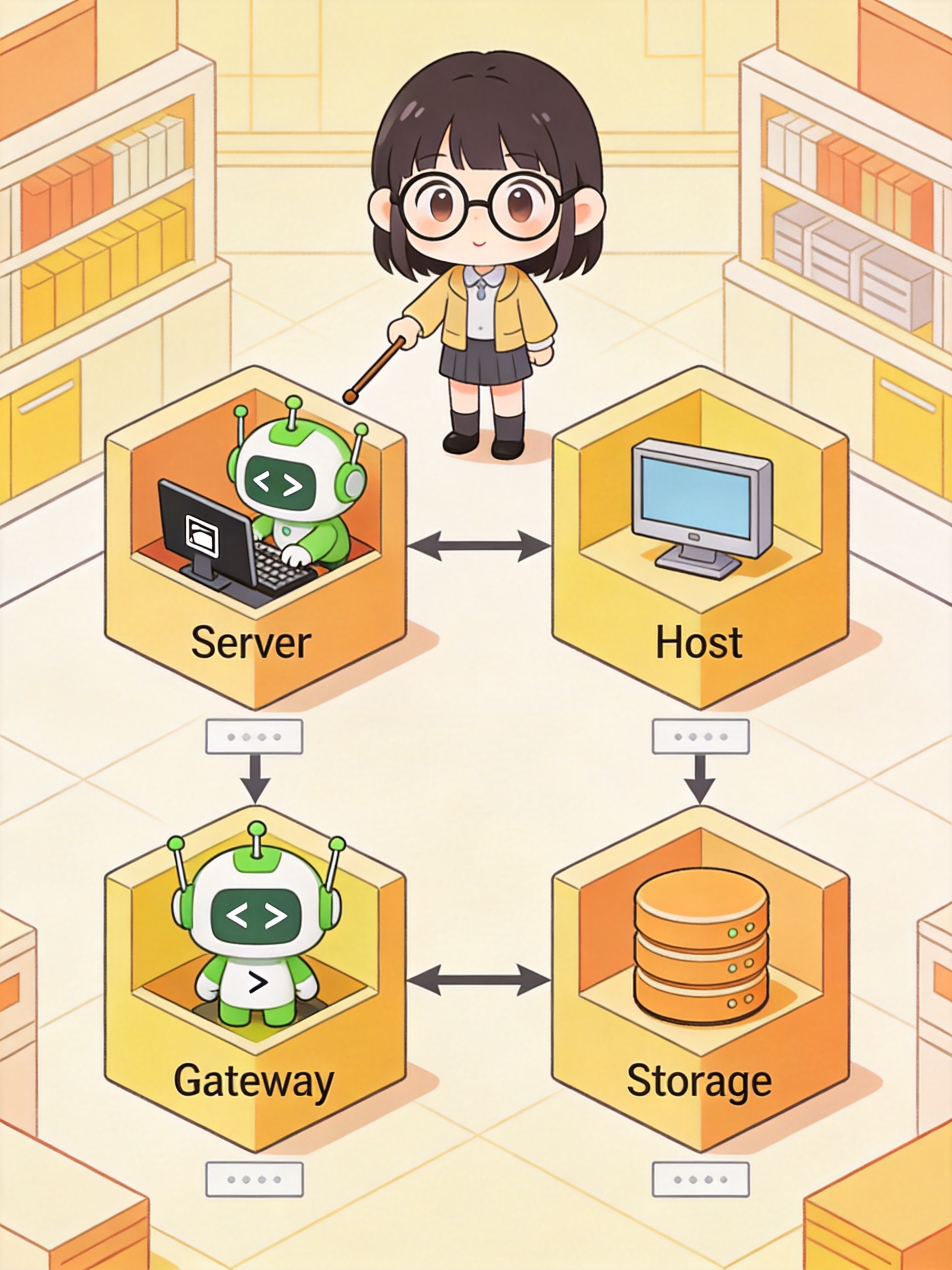
MonkeyCode 的私有化部署架构并不复杂,核心由三大模块构成:
AI Agent
理解需求 · 生成代码
→
云端运行环境
隔离容器 · 执行代码
→
实时通信层
WebSocket · 双向同步
浏览器 → 内网后端 → AI Agent → 运行环境 → WebSocket 返回,全程数据不出服务器
部署流程
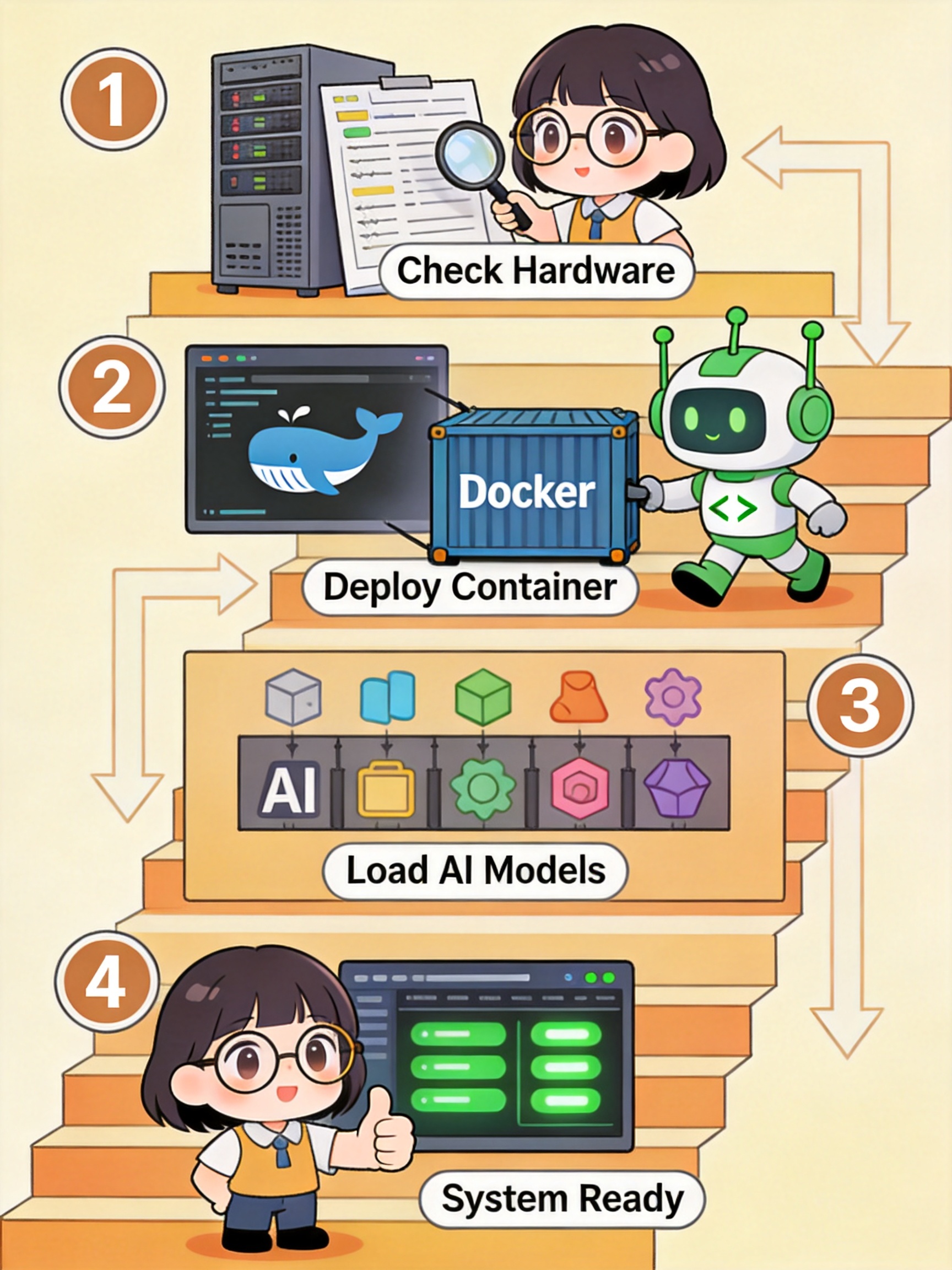
Step 1环境准备
确认服务器资源。MonkeyCode 的私有化部署采用 Docker 容器化方式,对服务器的基础要求是能够运行 Docker 环境。如果需要本地模型推理,服务器需要配备 GPU;如果对接企业已有的模型服务,则不需要本地 GPU。
💡 具体硬件配置建议咨询 MonkeyCode 官方获取最新推荐,不同规模的团队和模型选择对资源的需求差异较大。
Step 2部署服务端
通过 Docker 镜像部署 MonkeyCode 服务。整个过程类似安装一个企业级应用:拉镜像 → 配置端口和环境变量 → 启动容器 → 访问 Web 管理界面。
Step 3配置模型
MonkeyCode 私有化版支持接入多种模型源:
- 本地模型:提前部署 Qwen、DeepSeek、Kimi 等模型到服务器
- 企业网关:对接公司统一的模型服务
- 第三方 API:配置内网可访问的模型 API 地址
Step 4初始化与验证
登录管理后台,创建管理员账号,配置团队成员,设置权限策略。然后用一个简单的任务测试全流程是否跑通。
与在线版对比
MonkeyCode 私有化版保留了核心开发能力------代码生成、多文件项目、浏览器预览、终端访问,全部保留。差异主要在以下几方面:
| 维度 | 在线版 | 私有化版 |
|---|---|---|
| 数据存储 | 云端 | 本地服务器 |
| 模型来源 | 平台内置 | 自行接入 |
| 团队管理 | 基础 | 完整后台(审计日志、权限) |
| 更新方式 | 自动 | 手动升级 |
| 费用 | 按会员订阅 | 按授权(联系商务) |
| 使用门槛 | 注册即用 | 需运维团队配合 |
总结
- 核心价值:数据不出内网、统一管理、对接内部流程、支持离线
- 架构三大模块:AI Agent + 云端运行环境 + 实时通信层
- 部署流程:环境准备 → 部署服务端 → 配置模型 → 初始化验证
- 与在线版差异:核心功能保留,但数据本地化、需运维、按授权计费
作者:不爱土豆唯爱马铃薯 · MonkeyCode教程系列 MC-027



下一期 MC-028:团队协作------多人共用 MonkeyCode 工作区