你先告诉我,printf 打出来的东西到底在哪?
先看一段代码。别急着往下翻,盯着它,猜猜运行结果。
c
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
const char *msg1 = "hello fputs\n";
fputs(msg1, stdout);
const char *msg2 = "hello write\n";
write(1, msg2, strlen(msg2));
fork();
return 0;
}直接跑:./a.out
四条消息,整整齐齐,每人一行。没问题。
现在换个跑法:./a.out > log.txt
打开 log.txt,见鬼了。
printf 那行出现两次。fprintf 那行出现两次。fputs 那行也出现两次。只有 write 那行老老实实只出现一次。
把 fork 删掉再试------一切正常。所以这事跟 fork 有关。但凭什么 C 库函数被 fork 搞了两次,write 就没事?
要回答这个问题,你得先搞清楚另一件事:printf 写完数据之后,数据到底待在哪儿? 不在显示器上,不在内核里------它待在 C 语言自己的缓冲区里,根本没交出去。
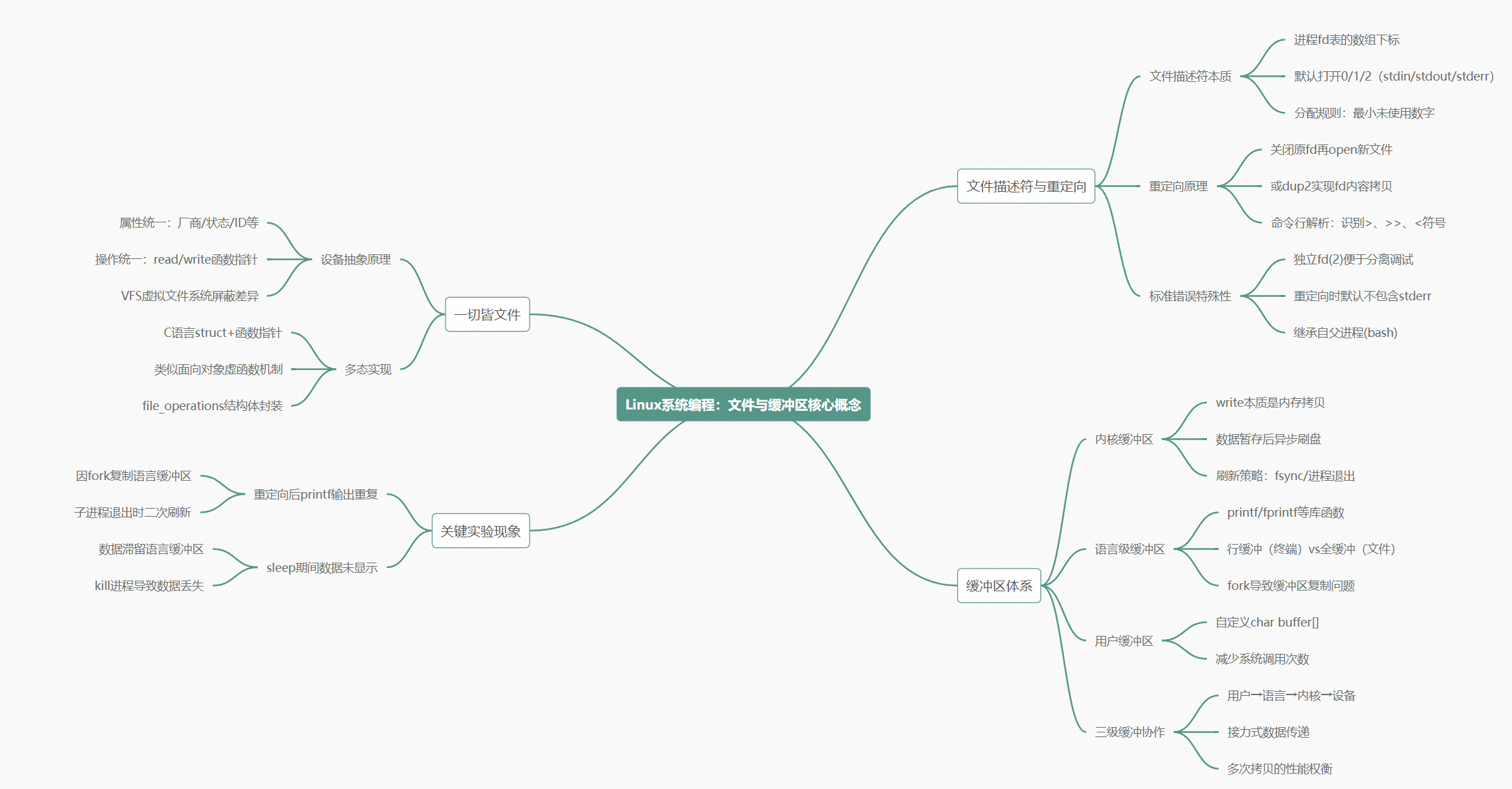
这就是这篇文章要讲的东西。但它没法三句话说清楚,因为要真正理解这个现象,你得把几件事串起来:文件描述符是什么,重定向怎么玩的,什么叫"一切皆文件",缓冲区到底有几层,以及凭什么 C 语言要在中间插一脚。
走着。
重定向的一个小坑
先不说 fork,说说我们之前写 shell 时撞上的一个 bug。
我们在自己的 shell 里加了重定向功能。解析的思路是:用一个 start 指针遍历命令行字符串。碰到 > 或者 <,说明存在重定向。把当前位置设为 \0,字符串就被切成了两半------左边是命令,右边是文件名。
具体来说,如果是 ls -a -l > log.txt:
start从头往后走,碰到>停下来- 判断是不是两个
>(追加模式):检查start+1,如果下一个字符也是>,那就是追加(>>),redir_type设成APPEND,start跳两格(start += 2);如果只是一个>,那就是覆盖输出,redir_type设成OUTPUT,start跳一格(start++) - 当前位置设为
\0,左边就只剩命令部分了 start跳完之后可能指向空格,用一个clear_left_space宏把空格全部跳过- 跳过空格后,
start指向的就是文件名
输入重定向(<)同理。解析出 redir_type 和文件名之后,在子进程里用 dup2 把对应的 fd 指向目标文件,然后 exec 替换程序。
顺带一提,这段解析代码的鲁棒性并不强。比如你只写了
ls >没给文件名,start++之后可能就越界了。真要写得健壮,得先从start往后strlen一下确认还有多少字符,再决定怎么跳。但这个不是今天的重点------有兴趣自己改成 C++ 用string的split也行。
clear_left_space 这个宏用了一个 do-while 循环的技巧写成的:
c
#define CLEAR_LEFT_SPACE(p) do { while (*(p) == ' ') (p)++; } while (0)这里用 do-while(0) 包裹是为了让宏在任何上下文中都能安全展开------一种常见的 C 语言宏编码技巧。
写完一跑,ls -a -l > log.txt,第一次没问题。再跑个 ls,不执行了。
顺带一提,我们的 shell 目前只支持"创建子进程执行命令 + 在子进程里重定向"这种方式。也就是说,只有通过 fork + exec 运行的外部命令(如 ls、cat、pwd)才能被重定向,shell 的内建命令(如 cd)暂时不行。因为内建命令在当前进程里执行,重定向会影响整个 shell 的状态。
原因是全局变量没清零。
你第一次做了输出重定向,redir_type 被设成了 OUTPUT,filename 指向了上次的文件名。第二次你只打了个 ls,没带重定向符号,但 redir_type 还是 OUTPUT。程序一看,"哦,你要输出重定向",就去找文件名------文件名是空的或者残留的,打开文件失败,整个命令就废了。
修法很简单:每次循环开始前,把重定向相关的全局变量全部重置为默认值。
c
redir_type = NONE;
filename = NULL;修完就好了。ls > log.txt 正常,cat log.txt 看到内容,pwd >> log.txt 追加也正常。
这就是重定向在我们的 shell 里的实现------底层用的是 dup2,把文件描述符表里的内容互相拷贝,让某个 fd 指向另一个文件对象。
但修完这个 bug,我想问你另一个问题。
凭什么要有 0、1、2?
每个进程一启动,默认就打开了三个文件描述符:0(stdin)、1(stdout)、2(stderr)。键盘、显示器、显示器。
0 和 1 好理解。程序是加工数据的,你得有办法把数据喂给它(键盘),它处理完了得把结果告诉你(显示器)。没有这两个,程序跟外界就是断的。
但凭什么还要有个 2? stdout 和 stderr 不都是往显示器上打的吗?一个不就够了?
做个实验。
c
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
printf("hello printf\n"); // 往 stdout
fprintf(stdout, "hello fprintf\n"); // 往 stdout
fprintf(stderr, "hello stderr\n"); // 往 stderr
const char *msg1 = "hello write to 1\n";
write(1, msg1, strlen(msg1));
const char *msg2 = "hello write to 2\n";
write(2, msg2, strlen(msg2));
return 0;
}直接跑,四条消息全打出来。OK,都是往显示器上打的。
现在 ./a.out > log.txt,重定向输出。
log.txt 里只有往 1 里写的那几条。往 2 里写的那条------hello stderr 和 hello write to 2------照样打在屏幕上。
这就是为什么要有 2。
stdout 和 stderr 虽然都指向同一个显示器文件,但它们是两个不同的文件描述符。重定向只改了 1 的指向,2 纹丝不动。
所以你可以这样做:
bash
./a.out > normal.log 2> error.log正常输出进 normal.log,错误信息进 error.log,彻底分开。
以前你写 ./a.out > log.txt,其实是 ./a.out 1> log.txt 的简写------默认省略的那个数字就是 1。
所以你以前学的那些规则------正常输出用 printf/cout,错误输出用 perror/cerr------不是随便定的。这么设计就是为了让你在 debug 的时候,只重定向一下 2,就能单独看错误信息。
012 不是什么神秘数字。0 和 1 是为了让程序能获取数据和给出结果,2 是为了 debug。就这么回事。
还有一个细节值得提------文件描述符的分配规则。 操作系统总是分配当前最小的、没有被使用的 fd。如果你把 0 关掉,下次 open 分配的就是 0。把 2 关掉,分配的就是 2。这就是 dup2 实现重定向的底层原理:想办法让某个 fd(比如 1)指向你想要的文件对象,然后新写入的数据就自动流到那个文件里去了。fd 的数字没变------1 还是 1------但 1 里面存的内容(指向哪个文件对象)变了。上层 struct FILE 里包装的 fd 数字没动,但底下的指向已经偷偷换了。
你从来没打开过 stdin
那下一个问题:0、1、2 是谁打开的?
你可能以为是你的进程自己打开的。不是。
你的进程是 bash 的子进程。bash 在启动的时候,操作系统就已经帮它把键盘文件和显示器文件打开了,分配到 0、1、2。然后 bash 创建子进程时,子进程的文件描述符表是直接从父进程拷贝过去的。
拷贝的是文件描述符表,不是文件本身。 文件描述符表是你进程的一部分------它描述的是"我这个进程怎么看文件"。就像虚拟地址空间描述的是"我这个进程怎么看内存",创建子进程时也得拷贝。而文件对象本身(那个 struct file)不用拷贝------你创建的是子进程,又不是子文件。
所以你在命令行上跑的每一个程序,所谓的"默认打开 0、1、2",其实是 bash 打开后你继承下来的。
换个问法,不用"继承"这个词,还能说清楚吗?
能。bash 有一个数组,数组里存了三张"门禁卡"------0 号卡刷键盘,1 号卡刷显示器,2 号卡也刷显示器。bash 生了个孩子,给孩子也复印了三张一模一样的卡。孩子拿着卡就能刷卡进同样的门。孩子自己从来没申请过卡。
Windows 下同理。VS 启动你的程序时,图形化界面那一层早就把 stdin/stdout/stderr 打开了,你的进程照样继承。
那 bash 自己又是怎么打开的呢?你登录的时候,操作系统给你启动了 login shell 进程。这个进程在初始化的时候,在 /dev 下找到了键盘文件和显示器文件,打开它们,分配到 0、1、2。从此以后,所有从它 fork 出去的进程,都自动带着这三张卡。
行了,这件事到此为止。
谁告诉你键盘和磁盘是"一样的东西"?
"一切皆文件"------这句话你听过无数遍了。但你仔细想想:键盘就是键盘,磁盘就是磁盘,网卡就是网卡。读键盘的方式和读磁盘的方式客观上就是不一样,凭什么把它们都叫"文件"?
要回答这个问题,你得先搞清楚另一件事:人是怎么认识世界的。
属性:你除了属性什么都看不到
你有个朋友。我问你这朋友是什么人,你会说什么?
"他个子挺高,长得还行,就是晚上爱打游戏不睡觉,第二天起不来。喜欢打篮球。"
你说的每一个词,都是你朋友的属性。你不可能说出你朋友头上每根头发的数量,不可能知道他一生中经历的每一件事。你只能用有限的、有代表性的属性来认识他。
人类认识任何事物的方式,就是通过属性。 知道的多叫"了解",知道的少叫"不了解",区别只是你知道多少属性。
这件事在编程里的体现是什么?看看你写的类------里面的成员叫什么?成员属性。所有的面向对象语言让你设计类的时候,写的都是属性。这不是巧合。
第二件事:同类事物的属性类别相同,但属性值不同。
你和你朋友,都有身高、体重、籍贯、爱好。属性类别一样。但你身高 185,他 190,她 160------属性值不一样。你们的差别不在"有没有身高这个属性",而在这个属性的值是多少。
设备也是这么回事
键盘、磁盘、网卡、显示器------这些东西统称"外设"或"设备"。在操作系统眼里,它们都是设备。
既然是设备,操作系统就要管理它们。管理的套路永远是:先描述,再组织。
怎么描述?用一个结构体,里面放属性:设备名、厂商、唯一标识、当前状态、驱动编号......
键盘有这些属性,磁盘也有,网卡也有。有些设备缺某个属性------比如显示器不需要"读速度"------你把那个属性置空就行了。就像一个人少了一只眼睛,他"眼睛数量"这个属性就是 1 而不是 2,不是他没有这个属性类别。
所以从属性层面看,所有设备可以被统一抽象成一个结构体。属性类别相同,属性值不同------就跟你和你朋友一样。
读写方法:客观上就是不一样
但属性只能说清楚"设备长什么样"。真正头疼的是------你怎么用这些设备?
读键盘跟读磁盘的操作,在硬件层面是两套完全不同的流程。读键盘要等中断,读磁盘要发 SCSI 指令,读网卡要处理 DMA。客观上,它们的读写方法就是不一样的。
键盘只需要读,不需要写------键盘哪来的"写"?显示器只需要写,不需要读------计算机不会从显示器上读数据。磁盘读写都要,网卡读写都要。有些设备有写方法没读方法,有些反过来。
没关系,没有的方法你实现成空函数就行了。
但问题是:如果每种设备的读写方法名字都不一样------read_keyboard()、read_disk()、read_nic()------那上层的程序员就惨了。想访问键盘,得记住键盘的结构体;想访问网卡,得记住网卡的结构体。每种设备的读写方法全得背下来。
Linux 设计者干了一件事
把所有设备都包装成"文件"。
具体怎么做的?在 struct file 里放一个东西:函数指针表。
c
struct file_operations {
int (*read)(...);
int (*write)(...);
int (*open)(...);
int (*flush)(...);
// ...
};键盘被当成一个文件,它的 read 函数指针指向键盘的底层读方法,它的 write 函数指针指向一个空函数(因为键盘不需要写)。
磁盘被当成一个文件,它的 read 指向磁盘的读方法,write 指向磁盘的写方法。
网卡同理。
然后在你的进程视角里,你不再直接跟硬件打交道了。你想读键盘?通过文件描述符 0 找到对应的 struct file,调文件对象里的 read 函数指针。你想写显示器?通过 fd 1 找到文件对象,调 write 函数指针。
函数名从此统一。 所有设备对你来说都只剩一个接口:文件对象的 read 和 write。
这一层软件抽象,叫 VFS(Virtual File System,虚拟文件系统)。
这不就是多态吗?
停下来想一想。
一个结构体(struct file),里面有一组函数指针(file_operations),函数指针指向不同底层硬件的具体实现。上层用统一的接口,下层各有各的玩法。
这不就是多态吗? struct file 是虚基类,各个具体设备是子类。
但这件事发生在内核里,用 C 语言写的。C 语言没有 class,没有 virtual,没有继承------怎么办?用函数指针。用结构体嵌套。用大量工程实践磨出来的设计模式。
先有 C 语言还是先有 C++?先有操作系统还是先有编译器?先有 C 语言,先有操作系统。 内核工程师那时候根本没有"面向对象"这个概念。但他们写出来的代码,天然就是多态的------因为分层抽象、屏蔽底层差异是大型软件的刚需,不是什么语言特性。
后来的人把这种实践总结出来,给它起了个名字叫"多态",然后直接做进了语言里。C++、Java 都支持多态,不是因为委员会拍脑门决定的,是因为这本来就是世界运转的方式。
如果一个语言这么干,叫语言特性。如果所有语言都这么干,那它就是世界的真相。
所以"一切皆文件"的底层机制,就是用 C 语言的函数指针,实现了一套多态机制。让你站在进程的角度,看到的所有 I/O 资源都是统一的 struct file,读写方法全都叫 read 和 write。
重定向也因此变得可爱起来:以前写显示器,用的是显示器文件对象的 write 函数指针。重定向之后,fd 1 指向了一个磁盘文件对象,write 函数指针自动变成了磁盘的写方法。上层代码一行不用改------这就是多态的威力。
知道这些之后再去翻内核源码。找到 struct file,找到里面的 f_op(就是 file_operations),打开它------里面全是一个一个的函数指针:read、write、open、flush......这就是一切皆文件的骨架。
缓冲区:你在菜鸟驿站寄快递
好,现在我们知道文件被打开之后,内核里会创建一个 struct file 对象。但你有没有想过一个问题:
write(fd, buf, len) 这个调用,到底干了什么?
答案可能让你意外:它只是把数据从你的 buf 拷到了内核缓冲区里。它根本没碰硬件。
c
const char *msg = "hello world";
write(3, msg, strlen(msg));执行过程:通过 fd 3 找到对应的 struct file,把 msg 指向的 11 个字节,原样拷到 struct file 内部维护的内核文件缓冲区 里。拷完就返回。 数据此时还在内存里,根本没写到磁盘上。
所以第一个结论:write 本质是拷贝函数。
那数据什么时候才真正写到磁盘上?由操作系统自主决定。它会在合适的时机,把内核缓冲区里的数据刷新到外设。刷新策略我们一会儿说。
read 同理。你调用 read(fd, buf, len),它先检查:你要读的那个位置的数据,内核缓冲区里有没有?如果有,直接拷给你。如果没有,操作系统去外设上加载,加载完了再拷给你。
read 本质也是拷贝函数。
那操作系统怎么知道你要读的数据在不在缓冲区里?很简单。struct file 里有一个字段叫 f_pos------当前文件的读写位置。你说"我要读第 100 个字节",它就看看缓冲区里已经加载了从开头到第几个字节。如果已经加载到第 200 个字节了,那就直接拷给你。如果只加载到第 50 个字节,那就得先去外设上把 51 到 100 的数据拉进来。
这里有个细节没完全展开:内核缓冲区不是一个线性数组。它是一棵 radix tree(基数树),用文件偏移量做索引,每一"页"数据(4KB)是一个节点。这棵树的根地址存在
struct file的address_space里。但数据结构的部分以后讲内存管理时再细说------你现在只需要知道,它用偏移量就能判定数据在不在内存里。
菜鸟驿站的故事:为什么要有缓冲区
假如没有缓冲区------就是没有菜鸟驿站。
张三在云南上学,李四在北京上学。张三想送李四一个键盘当生日礼物。没有快递,没有邮政,张三只能自己千里迢迢走过去,花几个月把键盘送到李四手上。在这几个月里,张三什么都干不了。
现在有了菜鸟驿站。张三只需要下楼,把键盘交给驿站的工作人员,然后上楼。上楼之后,室友问他"你那好键盘呢?"张三大手一挥------"已经送给我朋友了。"
站在张三的视角,他已经把事办完了。 实际上李四还没收到。但张三不 care------他的效率提高了。
这就是缓冲区存在的第一个意义:提高使用缓冲区的人(张三/用户进程)的 I/O 响应速度。 以前调一次 write 可能要等 500 毫秒(等硬件写完才返回),现在拷到内存就返回,可能只需要 100 毫秒。差了五倍。
注意,缓冲区提高的是使用者 的效率,不是提供者 的效率。菜鸟驿站里摆满了快递架,快递架本身没有提高菜鸟驿站的效率------它提高的是张三的效率。缓冲区给谁用,就提高谁的效率。
现在把视角切换到菜鸟驿站身上。
菜鸟驿站会不会来一个快递就立刻发一架飞机送出去?不会。这么干亏死------单次发送量越少,成本越高,效率越低。
菜鸟驿站的做法是:把你的快递先放架子上,放一天、两天。在这两天里,学校里有其他同学也要寄东西到北京------所有人的快递都被缓存起来。等架子放满了,把所有快递打包,一架飞机一次性发到北京,到北京再分拣。
这就是缓冲区的第二个意义:把分散的 I/O 请求聚合起来,减少 I/O 次数,提高整机效率。 以前 10 个 write 各刷一次磁盘,现在攒满一页(4KB)统一刷一次------本来要 10 次 I/O,现在 1 次就够了。
所以缓冲区的两大作用:
- 提高用户的 I/O 响应速度(交完就返回,不用等硬件)
- 提高操作系统的真实 I/O 效率(聚合请求,减少外设访问次数)
刷新策略:什么时候才真写?
数据拷到缓冲区了,什么时候才刷到外设上?
常见的刷新策略有这么几种:
- 立即刷新:不缓存,写一次刷一次。效率最低,但数据最安全。
- 行刷新(行缓冲) :遇到换行符
\n就把这一行刷出去。显示器默认用这种------因为人是按行看东西的,一行一行显示符合人的习惯。 - 全缓冲:缓冲区写满了才刷。普通磁盘文件默认用这种------效率最高。
- 强制刷新 :用户调用
fsync(fd),"你现在、立刻、马上给我刷"。Word 的保存按钮本质上就是这个。
这里有一个容易搞混的地方。C 语言有一个 fflush(FILE *),操作系统有一个 fsync(int fd)。它们干的活根本不一样:fflush 是把 C 语言缓冲区的数据刷到内核缓冲区,fsync 是把内核缓冲区的数据刷到外设。 一个管"用户→内核"这一段,一个管"内核→硬件"这一段。很多人以为 fflush 就是"写盘",不是------它只是把接力棒交给了下一棒。
- 进程退出时刷新:进程要挂了,操作系统会说"你先别死,把你缓冲区里的数据刷完再死"。所以正常退出的程序数据不会丢------但如果进程被 kill -9 强行干掉,或者突然断电,缓冲区里的数据就没了。
不同的缓冲区可能采用不同的策略。内核缓冲区的刷新策略跟操作系统整体状态有关------内存不够了可能提前刷,系统空闲了可能推迟刷。而 C 语言缓冲区的策略相对简单:显示器用行缓冲,普通文件用全缓冲。这个一会儿会变得极其重要。
C 语言的私货:语言级缓冲区
好,现在我们已经知道内核里有一层缓冲区了。但故事还没完。
我问你一个问题:调用系统调用有没有成本?
有。而且成本不小。
你调用 write(fd, buf, len),表面上就是把数据拷到内核缓冲区。但在操作系统内部,这个调用要走一大圈:找到进程→找到文件描述符表→找到文件对象→确认设备类型→调对应的底层方法→访问外设 I/O------每一步都要花时间。
更别说有些系统调用在底层做的工作远超你的想象。你调用 malloc 申请内存,操作系统可能在背后挂起了好几个进程、把不用的数据交换到了 swap 分区、重新整理了内存碎片------然后才把空间返回给你。你完全不知道。
所以 C 语言做了一个决定:我自己也搞一层缓冲区。
语言缓冲区在哪?
你一直用的 printf、fprintf、fputs、fwrite------这些 C 库函数,它们并没有直接调 write。
它们做的事是:把你要输出的数据,先写到 C 语言自己维护的语言级缓冲区 里。等你写了很多次 printf,攒够了数据,C 语言才调一次 write,把整个缓冲区的数据一次性拷到内核缓冲区。
所以 printf 本质上也是拷贝函数------只不过它从"你的字符串"拷到"C 语言的缓冲区",而不是直接拷到内核。从用户到用户,不是从用户到内核。
那这个缓冲区到底在哪?
在 struct FILE 里。就是那个你每次都传来传去的 FILE *。
c
struct FILE {
int fd; // 文件描述符
unsigned char *write_buf; // 写缓冲区指针
unsigned char *read_buf; // 读缓冲区指针
// ... 各种读写位置、缓冲区大小、标志位
};你去系统头文件里翻,能找到 typedef struct _IO_FILE FILE;。在 Linux 上它在 /usr/include/stdio.h 和 /usr/include/libio.h 里。里面有读缓冲区指针、写缓冲区指针、缓冲区大小、当前读写位置......你打开一个文件,C 语言就帮你创建这个结构体,把缓冲区也一并准备好。
所以为什么 C 语言做文件操作,每次都要传一个 FILE *?因为文件描述符和缓冲区全都在这个结构体里装着。 它就是你操作文件时的"句柄"------就跟你在饭店吃饭时的桌号牌一样,拿着它你才能找到自己的菜。
行缓冲 vs 全缓冲:一切谜团的答案
现在回到语言缓冲区的刷新策略。
C 语言的缓冲区会根据目标文件的类型自动选择策略:
- 显示器文件(终端设备) → 行缓冲 :遇到
\n就刷新 - 普通磁盘文件 → 全缓冲:缓冲区写满了才刷新
为什么显示器用行缓冲?因为人是按行看东西的。你把一行凑齐了显示出来,人看着舒服。一次显示一大坨,人就懵了。
为什么普通文件用全缓冲?因为它没有"立即显示"的需求。效率第一,攒满了再刷。
这个区别,就是文章开头那个 fork 实验的全部秘密。
拆解 fork 实验
重新看这段代码:
c
int main() {
printf("hello printf\n"); // C 库函数,往 stdout
fprintf(stdout, "hello fprintf\n");// C 库函数,往 stdout
fputs("hello fputs\n", stdout); // C 库函数,往 stdout
const char *msg = "hello write\n";
write(1, msg, strlen(msg)); // 系统调用,往 fd 1
fork();
return 0;
}情况一:直接跑(输出到显示器)。
- printf/fprintf/fputs 把数据写到 C 语言缓冲区(stdout 的
FILE结构体里) - 因为目标是显示器,用的是行缓冲 。每条消息都有
\n,所以每次 printf 结束,C 语言就立刻把缓冲区的数据刷到内核 - write 直接把数据拷到内核
- fork 创建子进程------内核缓冲区是文件层面共享的,父子看到的数据一样
- 两个进程退出,各自刷新内核缓冲区到显示器
四条消息,每人一行。干净利落。
情况二:重定向到文件(> log.txt)。
- printf/fprintf/fputs 把数据写到 C 语言缓冲区
- 但因为目标是普通文件,用的是全缓冲 !三条消息写完了,缓冲区可能才几十个字节,远没满------C 语言不刷!
- 此时这三条消息还待在 C 语言缓冲区里,根本没到内核
- write 不管你 C 语言的事,直接把数据拷到内核
- fork 创建子进程。子进程复制了父进程的整个地址空间------包括 C 语言缓冲区的数据。stdout 是一个全局变量,父子共享了这份缓冲区的副本
- 两个进程退出。每个进程退出时,C 运行时(Runtime)会调用清理逻辑,把
stdout缓冲区里的数据刷到内核。父进程刷了一次,子进程也刷了一次。 - log.txt 里出现两份 printf、两份 fprintf、两份 fputs
write 为什么只有一份? 因为 write 不经过 C 语言缓冲区,它的数据早就直接进内核了。fork 只复制了文件描述符表,没复制内核缓冲区的数据------父子看到的是同一份内核缓冲区,退出时只刷了一次。
说白了:重定向改变了缓冲策略,从行缓冲变成全缓冲,printf 的数据在 fork 之前被"暂扣"在了 C 语言缓冲区里。fork 之后父子各有一份,退出时各刷一次------所以数据出现了两次。
干净利落的验证
如果你还是不信,来看两个实验的对比。
第一个实验------带 \n:
c
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello world\n");
sleep(14);
return 0;
}编译运行。hello world 立刻出现,然后程序等 14 秒才退出。
第二个实验------不带 \n:
c
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello world"); // 注意:没有 \n
sleep(4);
return 0;
}编译运行。前 4 秒屏幕上一片空白,直到进程退出前的那一瞬间,hello world 才终于出现。
printf 和 sleep 谁先运行?printf 先运行。那在 sleep 期间,hello world 这个字符串待在哪?
在 C 语言缓冲区里。 不在内核,不在显示器,就在用户态的内存里,在一个叫 struct FILE 的结构体里面。
带 \n 时,目标是显示器,用的是行缓冲------\n 触发 C 语言立刻把数据刷到内核,你马上就看到了。不带 \n 时,行缓冲没被触发,数据一直蹲在 C 语言缓冲区里,直到进程退出时 C 运行时做清理才刷出去。所以你等了 4 秒才看到。
第三个实验------暴力杀进程:
c
#include <stdio.h>
#include <unistd.h>
int main() {
printf("hello world\n");
sleep(40);
return 0;
}编译运行。hello world 立刻出现(因为 \n + 显示器 = 行缓冲刷新)。然后用 ps 找到 PID,kill -9 干掉它。
此时 hello world 已经刷到内核了------进程虽然被杀,但内核缓冲区会在进程退出时(或被内核感知到进程消亡时)刷到显示器上。数据没丢。
但如果换一种跑法------重定向到文件:
c
int main() {
printf("hello world\n");
sleep(40);
return 0;
}
// 编译后:./a.out > log.txt & 然后 kill -9重定向到文件之后,缓冲策略变成了全缓冲。\n 不再触发刷新。此时 printf 的数据被"扣留"在 C 语言缓冲区里,根本没到内核。你在 40 秒内 kill -9,数据跟着进程一起死了------log.txt 里什么都没有。
所以结论很明确:printf 写完的数据,在到达内核之前,是待在 C 语言自己的缓冲区里的。 行缓冲触发、全缓冲写满、手动 fflush、进程正常退出------这四件事能把数据从 C 语言缓冲区推到内核。换个问法------kill -9、突然断电、缓冲区还没满------这三件事能让数据死在你眼皮底下。
三层缓冲区:一场接力赛
现在把整个故事串起来。
你写代码时自己定义的 char buf[1024]------这是用户缓冲区(你说了算)。
你调 printf、fwrite 时,数据进的是C 语言缓冲区 (C 运行时说了算,存在 struct FILE 里)。
C 语言缓冲区满了(或者遇到 \n 且目标是显示器),调一次 write,数据进内核文件缓冲区 (操作系统说了算,存在 struct file 的 radix tree 里)。
内核在合适的时机(缓冲区满了、用户调了 fsync、进程退出、定时刷新),把数据写进外设(硬盘、显示器)。
你的数据 → C语言缓冲区 → 内核缓冲区 → 外设你在每一层交出数据之后,就认为"事情办完了"------跟张三把键盘交给菜鸟驿站之后的心态一模一样。每一层都是一个菜鸟驿站。
这就是"文件流"这个词的由来。数据在缓冲区里像流水一样从尾部进来,从头部出去。先写的在前面,后写在后面------就是个队列。所以叫"流"。
知道了这些,你再看 printf 的格式化输出机制就特别清楚。printf("%d", 123) ------它把数字 123 转成字符 '1'、'2'、'3' 三个字节,写进 C 语言缓冲区,然后再由 C 语言统一刷出去。格式化的结果就是缓冲区里的一串字节。
C++ 的 cout、cerr 呢?一回事。std::ostream 这个类里面必然封装了文件描述符和缓冲区。跟 C 的 FILE 是一一对应的关系。
为什么工程师们这么在意"拷贝次数"?
你在学 C/C++ 的时候一定听过"传引用比传值快""传指针可以减少拷贝"。为什么大家都在意这件事?
因为在这个接力赛里,数据被拷贝了很多很多次。 键盘到用户缓冲区一次,用户到语言缓冲区一次,语言到内核一次,内核到外设可能还有 DMA 的拷贝。网络编程里还要加上协议栈的处理。
如果你的每一步操作都增加不必要的拷贝,整个链路下来性能损耗是叠加的。
所以怎么减少拷贝次数,是整个 I/O 系统设计的核心问题之一。缓冲区存在的意义,一半是为了提高响应速度,一半就是为了聚合请求,用更少的系统调用完成更多的数据搬运------以此减少拷贝次数。
我们要自己封装一个 my_stdio
说了这么多,还有一件事没搞清楚:C 语言到底什么时候把数据刷到内核的? 你写的代码里又没调 fflush,C 运行时是怎么插手的?
要回答这个问题,光看不行。我们得自己写一个简易版的 stdio ------就叫 my_stdio。
工程结构很简单------跟之前写 shell 一样,几个文件搞定:
my_stdio/
├── my_stdio.h // 头文件:结构体定义 + 接口声明
├── my_stdio.c // 实现文件:my_fopen, my_fwrite, my_fflush, my_fclose
├── main.c // 测试入口:作为"用户"来调我们的接口
└── Makefile // 编译 my_stdio.c + main.c → 可执行文件只做输出缓冲区,不搞输入。核心就几个接口:
MY_FILE *my_fopen(const char *name, const char *mode)--- 打开文件,创建结构体,分配缓冲区,返回指针my_fwrite(...)--- 写数据到语言缓冲区,满了就自动刷my_fflush(...)--- 手动刷新my_fclose(...)--- 关文件,刷数据,释放资源
数据结构长这样:
c
typedef struct {
int fd; // 封装文件描述符
int flags; // 打开方式(读/写)
int flush_mode; // 刷新模式(行缓冲/全缓冲)
char out_buf[1024]; // 输出缓冲区
int buf_pos; // 当前缓冲区写入位置
} MY_FILE;思路跟内核的 struct file 一样:把 fd 和缓冲区打包在一个结构体里。用户拿到的就是这个结构体的指针,之后所有操作都传它。
具体实现留着下节课写。今天先把思路理清楚:
my_fwrite先检查缓冲区还能不能装下要写的数据- 能装下------直接拷到
out_buf里,更新buf_pos,返回 - 装不下------先调
my_fflush把缓冲区的数据刷到内核,清空缓冲区,再把新数据拷进去 my_fflush做的事情就是调write(fd, out_buf, buf_pos),把缓冲区里的数据一次性拷到内核,然后buf_pos清零
等你实现了这一套,你就能直观地看到:哦,原来 printf 的调用链是 printf → 格式化 → fwrite → 语言缓冲区 → (满了或换行) → write → 内核缓冲区 → (合适时机) → 外设。每一步的延迟、每一次的拷贝,全在代码里。
今天到底学了什么
四件事。
第一,文件描述符 0、1、2 不是凭空来的。 0 和 1 是为了让程序获取数据和输出结果,2 是为了把正常输出和错误输出分开------方便你 debug。而且你从来没自己打开过它们------你是从 bash 那里继承下来的。
第二,"一切皆文件"是用 C 实现的"多态"。 内核把键盘、磁盘、网卡、显示器都用 struct file 统一包装,用函数指针表(file_operations)指向底层不同的硬件操作。在进程的视角里,所有的 I/O 只用 read 和 write 两个名字------不管底层是什么设备。这不是巧合,这是 C 语言在面向对象诞生之前就写出来的多态。
第三,缓冲区是分层接力赛。 内核缓冲区让你调 write 时不用等硬件(提高响应速度),也帮操作系统把分散的 I/O 聚合起来一次刷(提高整机效率)。read 和 write 本质都是拷贝函数------从一块内存拷到另一块内存。
第四,C 语言有自己的缓冲区。 它存在 struct FILE 里,目的是减少系统调用次数。显示器用行缓冲(遇 \n 就刷),普通文件用全缓冲(写满了才刷)。重定向改变了缓冲策略,这就是 fork 实验中 printf 数据出现两次的全部原因------数据在 fork 之前被"扣留"在了 C 语言缓冲区里,父子进程退出时各刷了一次。
最后一个小总结。
你口中所说的"缓冲区",在不同的语境里指的是不同的东西。你定义的 char buf[1024] 是用户缓冲区。C 语言帮你维护的那个是语言缓冲区。struct file 里那个是内核文件缓冲区。它们之间是一个接力关系------每一层都把数据交给下一层,然后就认为"我干完了"。这份"自欺欺人"正是计算机能跑这么快的关键。
搞清楚了这些,你再回头看那个进度条------为什么
printf不带\n就不显示,不调fflush就不刷新------你的脑子里应该有画面了。数据在语言缓冲区里蹲着,等一个换行,等一次满,等一句fflush,等进程体面地死去。