上节课我们学习了路由的概念,通过路由表和binding规则,可以让不同的agent服务不同的租户,并通过tier进行逐级匹配, 今天我们来学习OpenClaw智能层的概念,其做法有如下:
- 初始化时加载记忆:通过8次提示词加载丰富人格
- 加载两部分记忆,分别是
MEMORY.md长期记忆和memory/daily/xxx.jsonl每日记忆 - 每次用户提问时,都加载两部分记忆,然后先进行
tf-idf+余弦相似度+关键词搜索的混合搜索机制,并对结果进行时间衰减和MMR重排序,最终将相关且多样化的记忆碎片注入系统提示词。
1. 整体背景
1.1. 前期8层记忆加载(对应BootstrapLoader)
前期8个文件分别对应如下:
| 文件 | 身份 |
|---|---|
| SOUL.md | 人格 |
| IDENTITY.md | 身份 |
| TOOLS.md | 工具 |
| USER.md | 用户信息 |
| HEARTBEAT.nd | 心跳配置 |
| BOOTSTRAP.md | 引导 |
| AGENTS.md | 多代理 |
| MEMORY.md | 静态长期记忆 |
这些文件在启动时只加载一起,后续将会组装成系统提示词发送给大模型
1.2. 记忆组装
记忆组装发生在build_system_prompt这个函数中,共分为两层记忆,一个是MEMORY.md的静态内容,另一个来自__auto_recall混合搜索的记忆
1.3. 混合搜索和排序
混合搜索策略在MemoryStore.hybrid_search中。 在该函数中,首先会load所有的chunk, 然后分别经过:
- 关键词搜索:使用tf-idf进行搜索,得到score
- 向量检索: 使用余弦相似度比较向量相似度
- 加权:vector_weights * 0.7, keywords_weights * 0.3
- 计算时间衰减:从记忆块的path中取时间,然后计算与当前时间的
age_days, 应用指数衰减:score *= exp(-decap_rate * age_days), decay_rate=0.01, 越近的记忆得分衰减越少,越旧的记忆得分越低 - MMR:
目的是在保证相关性的同时增加结果的多样性,避免返回内容相似的记忆。
输入时经过时间衰减后的结果列表,每个结果包含score相关性分数 ,和chunk文本。
算法步骤: 首先对每条结果进行分词,然后初始化已选择集合为空。
重复如下步骤: 对于每个未选中的结果i,计算MMR:
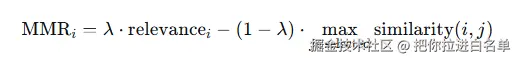
其中 similarity 使用 Jaccard 相似度(基于分词集合的交并比),选择 MMR 最大的结果加入已选集合
MMR计算代码如下:
ini
@staticmethod
def _mmr_rerank(results, lambda_param=0.7):
tokenized = [MemoryStore._tokenize(r["chunk"]["text"]) for r in results]
selected = []
remaining = list(range(len(results)))
reranked = []
while remaining:
best_idx = -1
best_mmr = float("-inf")
for idx in remaining:
relevance = results[idx]["score"]
max_sim = 0.0
for sel_idx in selected:
sim = MemoryStore._jaccard_similarity(tokenized[idx], tokenized[sel_idx])
if sim > max_sim:
max_sim = sim
mmr = lambda_param * relevance - (1 - lambda_param) * max_sim
if mmr > best_mmr:
best_mmr = mmr
best_idx = idx
selected.append(best_idx)
remaining.remove(best_idx)
reranked.append(results[best_idx])
return reranked2. 流程设计