Claude Code 接入小米 MiMo 缓存不命中:一个环境变量解决问题
最近在使用 Claude Code 接入小米 MiMo 时,发现一个比较明显的问题:理论上 MiMo 支持缓存计费和缓存读取,但在 Claude Code 实际使用过程中,缓存几乎不命中。
表现大致是:
text
cache write 有发生
cache read 很少,甚至接近 0
多轮对话每次都像重新处理完整上下文
首 token 变慢
输入 token 成本偏高一开始我以为是 MiMo 没有适配 Claude Code 的 Prompt Caching,或者是 Claude Code Router / NewAPI / CPA 这类中间层没有正确透传 cache_control。后来看到社区讨论后,发现问题可能不完全在 MiMo 本身,而是 Claude Code 默认插入的 attribution 信息影响了第三方网关的缓存前缀匹配。
问题背景
Claude Code 的 Prompt Caching 依赖稳定的 prompt 前缀。
对于 Agent 编程工具来说,每一轮请求通常都会携带大量重复内容,例如:
- system prompt
- CLAUDE.md
- 项目上下文
- tools / MCP 工具定义
- 历史消息
- 文件摘要
这些内容如果保持稳定,理论上就可以被服务端缓存。下一轮请求只需要处理新增部分,从而降低输入成本、减少首 token 等待时间。
但是第三方模型或 LLM Gateway 的缓存机制通常没有 Anthropic 官方 API 那么完整。只要请求前缀中有动态变化内容,就可能导致缓存失效。
核心原因
Claude Code 默认会在 system prompt 开头加入一段 attribution block,用于标识请求来源、客户端版本、prompt fingerprint 等信息。
在官方 Anthropic API 中,这些信息不会明显影响缓存行为。但在第三方网关、本地模型、OpenAI 兼容接口、小米 MiMo 这类场景中,这段信息可能会被当成普通 prompt 内容参与前缀匹配。
一旦 attribution block 中的某些内容发生变化,服务端看到的 prompt 前缀就不再一致,于是缓存无法命中。
简单理解:
text
第一轮请求:
[动态 attribution block A] + [稳定 system prompt] + [稳定 tools] + [用户输入]
第二轮请求:
[动态 attribution block B] + [稳定 system prompt] + [稳定 tools] + [用户输入]
因为最前面的 attribution block 不同,
第三方缓存系统认为这是两个不同前缀,
于是 cache read 几乎不命中。所以这个问题并不是"Claude Code 没有缓存",也不一定是"MiMo 没有缓存",而是:
text
Claude Code 的 attribution header / attribution block
在第三方网关场景下破坏了 prompt cache 的稳定前缀。解决方法
在 Claude Code 配置中关闭 attribution header。
推荐写入:
json
{
"env": {
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0"
}
}配置文件位置:
text
~/.claude/settings.jsonWindows 一般是:
text
C:\Users\你的用户名\.claude\settings.json如果你使用 Linux、macOS、WSL,也可以写入 shell 配置:
bash
export CLAUDE_CODE_ATTRIBUTION_HEADER=0例如:
bash
echo 'export CLAUDE_CODE_ATTRIBUTION_HEADER=0' >> ~/.bashrc
source ~/.bashrc如果使用 PowerShell 临时测试:
powershell
$env:CLAUDE_CODE_ATTRIBUTION_HEADER="0"
claude注意:网上有些文章会写:
bash
export CLAUDE_CODE_ATTRIBUTION_HEADER=falsefalse 在部分版本里也可能有效,但官方文档中推荐的是 0,因此建议统一使用:
bash
CLAUDE_CODE_ATTRIBUTION_HEADER=0配置后效果
我这边配置后,MiMo 的缓存开始正常命中。
原来的现象是:
text
cache write 有
cache read 很少配置后变成:
text
cache read 开始增加
多轮 Claude Code 对话复用缓存
首 token 速度改善
输入成本下降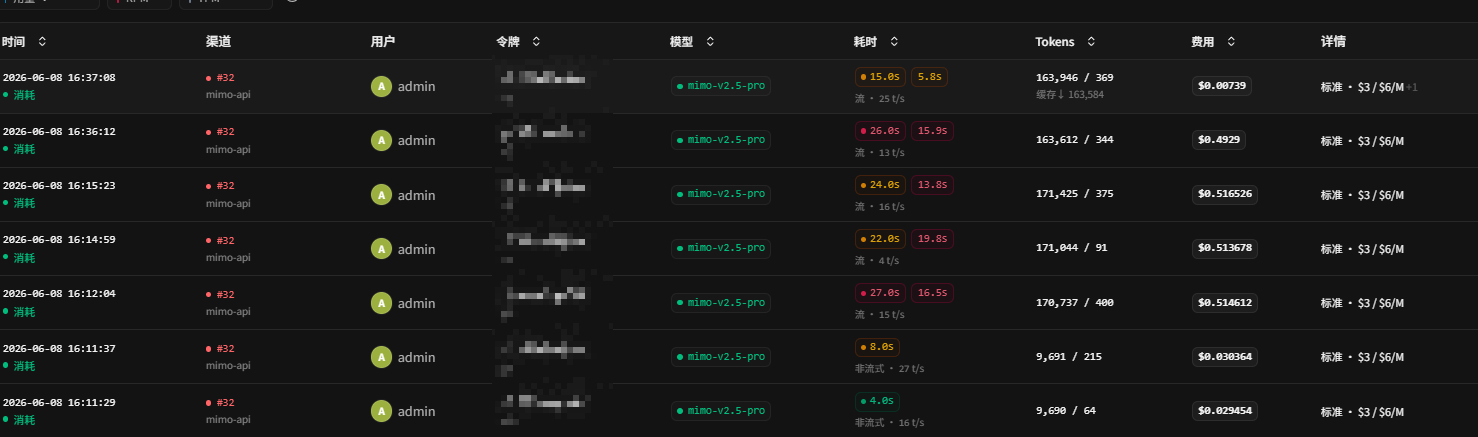
这说明 MiMo 不是完全不能缓存,而是之前 Claude Code 发送的 attribution 信息破坏了第三方网关的缓存前缀。
不要优先使用 DISABLE_PROMPT_CACHING
排查过程中还有一个容易混淆的环境变量:
bash
DISABLE_PROMPT_CACHING=1这个变量的含义是直接关闭 Claude Code 的 Prompt Caching。
它不是修复缓存命中,而是绕开缓存机制。
如果上游模型或网关完全不兼容 Claude Code 的缓存机制,设置它可能能减少异常行为。但对于 MiMo 这种已经支持缓存、只是因为前缀被破坏导致命中率低的场景,不应该优先关闭缓存。
两个变量的区别如下:
| 配置 | 作用 | 是否推荐 |
|---|---|---|
CLAUDE_CODE_ATTRIBUTION_HEADER=0 |
去掉 attribution block,保留 Prompt Caching | 推荐 |
DISABLE_PROMPT_CACHING=1 |
直接关闭 Prompt Caching | 不优先推荐 |
ENABLE_PROMPT_CACHING_1H=1 |
尝试使用更长缓存 TTL,取决于上游是否支持 | 后续可测试 |
推荐顺序是:
text
先设置 CLAUDE_CODE_ATTRIBUTION_HEADER=0
再观察 cache read 是否改善
如果仍然异常,再考虑 DISABLE_PROMPT_CACHING=1副作用是什么?
这个配置的副作用很小。
它主要影响的是 Claude Code 发给模型的 attribution 信息,不会关闭 Claude Code 的核心能力。
不会影响:
- 文件读取
- 文件修改
- Bash 工具调用
- MCP 工具
- 计划模式
- 上下文管理
- 多轮对话
- Prompt Caching 本身
可能影响的是:
- 上游网关少了一些 Claude Code 请求来源信息
如果某些网关依赖 attribution 信息做统计、归因、调试,关闭后可能看不到 Claude Code client version、prompt fingerprint 等内容。
- 问题排查时少一个定位字段
如果以后向网关作者、模型服务商或 Claude Code 社区反馈问题,他们可能无法从请求内容中看到这部分 attribution 信息。
- 官方 Anthropic API 场景收益不明显
这个配置主要适合第三方网关、OpenAI 兼容接口、本地模型、小米 MiMo 等场景。对于官方 Anthropic API,官方缓存机制本身已经适配,不一定需要这个配置。
整体来说,它的副作用属于"可观测性减少",不是"功能损坏"。
推荐配置方案
如果你使用的是:
text
Claude Code → Claude Code Router → 小米 MiMo或者:
text
Claude Code → NewAPI / CPA → 小米 MiMo建议在 ~/.claude/settings.json 中加入:
json
{
"env": {
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0"
}
}如果已经有其他配置,需要合并,不要覆盖原文件。例如:
json
{
"env": {
"ANTHROPIC_BASE_URL": "http://127.0.0.1:3000",
"ANTHROPIC_AUTH_TOKEN": "你的 token",
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0"
}
}修改后需要:
text
1. 重启终端
2. 重启 VSCode
3. 重新启动 Claude Code
4. 连续进行几轮同项目对话
5. 观察 MiMo 或网关日志里的 cache read 是否增加如何判断是否生效?
重点看日志或账单中的缓存相关字段。
常见字段包括:
text
cache_creation_input_tokens
cache_read_input_tokens
cached_tokens
prompt_tokens_details.cached_tokens如果配置前是:
text
cache_creation_input_tokens 很高
cache_read_input_tokens 很低配置后变成:
text
cache_read_input_tokens 明显增加
cached_tokens 明显增加说明配置有效。
如果配置后仍然没有明显改善,需要继续排查:
- 是否真的重启了 Claude Code
- 是否配置到了正确的
settings.json - 是否中间网关丢弃了缓存字段
- 是否每轮 MCP 工具列表都在变化
- 是否切换了模型
- 是否切换了网关节点
- 是否超过了缓存 TTL
- 是否 CLAUDE.md 或项目上下文频繁变化
- 是否不同请求被负载均衡到了不同上游实例
最终结论
Claude Code 接入小米 MiMo 时缓存不命中,不一定是 MiMo 不支持缓存,也不一定是 Claude Code 的 Prompt Caching 本身有问题。
更常见的原因是:
text
Claude Code 默认发送的 attribution block
在第三方网关场景下破坏了 prompt cache 前缀稳定性。解决方法是配置:
json
{
"env": {
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0"
}
}这个配置不是关闭缓存,而是让 Claude Code 不再发送可能影响缓存命中的 attribution 信息。
对于小米 MiMo、Claude Code Router、NewAPI、CPA、本地模型网关这类第三方接入场景,建议优先开启这个配置。
我的实际结果是:配置后 MiMo 开始正常走缓存,副作用很低,适合长期保留。