一.自然语言处理入门
1)什么是自然语言处理?
**●**自然语言处理(Natural Language Processing,简称NLP)是计算机科学与语言学中关注于计算机与人类语言间转换的领域
让程序能够理解并处理我们所说的语言文字。
2)自然语言处理的发展简史
**●**人工智能时代到来,深度学习技术将深刻改变NLP的未来
ANN人工神经网络
RNN循环神经网络 →(NLP的底层) → Transformer → 大模型
CNN卷积神经网络
3)自然语言处理的应用场景
**●**语音助手
**●**机器翻译
**●**搜索引擎
**●**智能问答
●...
线性回归和逻辑回归 → 深度学习(ANN) → RNN → LSTM/GRU → Transformer → Bert/大模型
二.文本预处理
1)认识文本预处理
● 文本预处理及其作用
文本语料在输送给模型前一般需要一系列的预处理工作,才能符合模型输入的要求,如:将文本转化成模型需要的张量,规范张量的尺寸等,而且科学的文本预处理环节还将有效指导模型超参数的选择,提升模型的评估指标.
javascript所处阶段:数据输入到模型之前 作用:数据清洗、指导超参数的确定● 文本预处理中包含的主要环节
文本处理的基本方法
文本张量表示方法
文本语料的数据分析
文本特征处理
数据增强方法
javascript1.文本处理的基本方法:分词、NER、POS 2.文本张量的表示方法:one-hot、word2vec、wordEmbedding 3.文本语料的数据分析:标签数量分析(类别不均衡问题)、句子长度分析、词频统计和关键词词云 4.文本特征处理:添加n-gram特征、文本长度规范 5.数据增强方法:回译数据增强
javascriptAnaconda沙箱/虚拟环境介绍 作用:同台电脑能够同时拥有多个不同的Python环境:因为实际工作中,偶尔会出现你参与的/维护项目使用的Python解释器版本的要求是不同的。 每个项目创建单独的虚拟环境 优点:各个项目间隔离开了,相互之间不影响用到啥库就安装上,开发的时候效率比较高 缺点:需要根据开发需求一个个安装对应的第三方库 Anaconda沙箱/虚拟环境相关命令 conda env list:查看当前有哪些虚拟环境 conda create -n 虚拟环境名称 python=-版本号:创建新的虚拟环境,注意虚拟环境的名称不要用中文 conda activate 虚拟环境名称:进入指定的虚拟环境 conda deactivate:退出当前的虚拟环境 conda remove -n 虚拟环境名称 --all:彻底删除指定的虚拟环境 创建nlp_base虚拟环境的流程如下: 1- 查看当前有没有nlp_base conda env list 2- 如果没有,那么需要新建。按回车即可 conda create -n nlp_base python==3.10 3- 验证是否创建成功 conda env list 4- 进入nlp_base中查看有哪些工具包 conda activate nlp_base conda list 5- 安装jieba分词器 ----------------------------------------------------------------------------------------- pip install jieba -i https://mirrors.aliyun.com/pypi/simple/ pip install torch -i https://mirrors.aliyun.com/pypi/simple/ pip install tensorflow -i https://mirrors.aliyun.com/pypi/simple/ pip install joblib -i https://mirrors.aliyun.com/pypi/simple/ pip install fasttext -i https://mirrors.aliyun.com/pypi/simple/ 或者 pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/ ----------------------------------------------------------------------------------------- 一次性全部安装(复制这一整段即可): pip install jieba torch tensorflow joblib fasttext-wheel -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com ----------------------------------------------------------------------------------------- 如果不管是安装fasttext还是fasttext-wheel都失败,那么原因是python版本过高。操作步骤如下: 1- 先进入对应的虚拟环境 2- 安装低版本的python解释 conda install python=3.10 3- 安装fasttext● 文本处理的基本方法
分词
词性标注
命名实体识别
● 文本张量表示方法
one-hot编码
Word2vec
Word Embedding
● 文本语料的数据分析
标签数量分布
句子长度分布
词频统计与关键词词云
2)文本处理的基本方法
● 什么是分词
- 分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符。分词过程就是找到这样分界符的过程
python举个例子: 我们是一家上市公司,旗下有很多子品牌,我正在学习人工智能开发。 ['我们','是','一家','上市公司',',','旗下','有','很多','子品牌',',','我','正在','学习','人工智能','开发','。']● 分词的作用
- 词作为语言语义理解的最小单元,是人类理解文本语言的基础.因此也是AI解决NLP领域高阶任务,如自动问答,机器翻译,文本生成的重要基础环节
● 流行中文分词工具jieba:
愿景:"结巴"中文分词,做最好的Python中文分词组件
● jieba的特性:
支持多种分词模式
精确模式
全模式
搜索引擎模式
支持中文繁体分词
支持用户自定义词典
● jieba的安装:
javascriptpip install jieba● jieba的使用:
精确模式分词
试图将句子最精确地切开,适合文本分析
pythonimport jieba content="我们是一家上市公司,旗下有很多子品牌,我正在学习人工智能开发。" # 精确模型:试图将句子最精确地切开,适合文本分析。也属于默认模式 jieba.cut(content, cut_all=False) # cutlall默认为False # 将返回一个生成器对象 <generator object Tokenizer .cut at 0x7f8d9053e650> # 若需直接返回列表内容,使用jieba.1cut即可 jieba.lcut(content, cut_all=False) ['我们', '是', '一家', '上市公司', ',', '旗下', '有', '很多', '子', '品牌', ',', '我', '正在', '学习', '人工智能', '开发', '。']● 全模式分词:
● 把句子中所有的可以成词的词语都扫描出来,速度非常快,但不能消除歧义。
javascript# 若需直接返回列表内容,使用jieba.lcut即可 jieba.lcut(content,cut_all=True) ['我们', '是', '一家', '上市', '上市公司', '公司', ',', '旗下', '下有', '很多', '多子', '品牌', ',', '我', '正在', '学习', '人工', '人工智能', '智能', '能开', '开发', '。'] # 注意1:人工智能全模型分成三个词 # 注意2:逗号和句号也给分成了词● 搜索引擎模式分词:
● 在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
javascriptimport jieba content = "我们是一家上市公司,旗下有很多子品牌,我正在学习人工智能开发。" jieba.cut_for_search(content) # 将返回一个生成器对象 <generator object Tokenizer.cut_for_search at 0x7f8d90e5a550> # 若需直接返回列表内容,使用jieba.lcut_for_search即可 jieba.lcut_for_search(content) ['我们', '是', '一家', '上市', '公司', '上市公司', ',', '旗下', '有', '很多', '子', '品牌', ',', '我', '正在', '学习', '人工', '智能', '人工智能', '开发', '。'] # 对'无线电'等超长词汇都进行了再次分词。● 中文繁体分词:
● 针对中国香港,台湾地区的繁体字文本进行分词。
pythonimport jieba content = '煩惱即是菩提,我暫且不提' jieba.lcut(content) ['煩惱','即','是','菩提',',','我','暫且','不','提',]
使用用户自定义词典:
添加自定义词典后,jieba能够准确识别词典中出现的词汇,提升整体的识别准确率。
词典格式:每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
词典样式如下,具体词性含义请参照7 jieba词性对照表,将该词典存为userdict.txt,方便之后加载使用。
格式:word1 freq1 word_type1
程序员 5 n
IT教育 6 n
人工智能 7 nz
学习 3
上市 3
pythonimport jieba """ 总结:全瓷、精准、搜索引擎模式的区别是分词结果的词的个数不用 掌握:jieba.lcut(sentence=content) 推荐掌握jieba.lcut()方法即可 """ content = "我们是一家上市公司,旗下有很多子品牌,我正在学习人工智能开发。" # 【推荐】全词模式 def demo1(): # 推荐使用:返回结果类型是List列表 # Ctrl+Q:看方法解释 result = jieba.lcut(sentence=content, cut_all=False) print(type(result)) print('全词模式:', result) print("-" * 30) # 【了解】不带l的返回结果类型是generator生成器,节约内存资源 result = jieba.cut(sentence=content, cut_all=False) print(type(result)) print(result) print(next(result)) # 精确模式 def demo2(): # 精确的模式:cut_all=True。和上面的区别是该方式分的词会更加精细 # cut_all默认是False。如果设置为True,那就是精确模式。分词更加细致 result = jieba.lcut(sentence=content, cut_all=True) print('精确模式:', result) # 【了解】搜索引擎模式 def demo3(): # 注意:没有cut_all参数 result = jieba.lcut_for_search(sentence=content) print('搜索引擎模式', result) if __name__ == '__main__': # 【推荐】全词模式 demo1() # 精确模式 demo2() # 搜索引擎模式 demo3()● 什么是命名实体识别
命名实体: 通常我们将人名, 地名, 机构名等专有名词统称命名实体. 如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机.
顾名思义, 命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体.
举个例子:
鲁迅, 浙江绍兴人, 五四新文化运动的重要参与者, 代表作朝花夕拾.
==>
鲁迅(人名) / 浙江绍兴(地名)人 / 五四新文化运动(专有名词) / 重要参与者 / 代表作 / 朝花夕拾(专有名词)
命名实体识别的作用:
- 同词汇一样, 命名实体也是人类理解文本的基础单元, 因此也是AI解决NLP领域高阶任务的重要基础环节.
● 什么是词性标注
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等.
顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性.
举个例子:
我爱自然语言处理
==>
我/rr, 爱/v, 自然语言/n, 处理/vn
rr: 人称代词
v: 动词
n: 名词
vn: 动名词词性标注的作用:
- 词性标注以分词为基础, 是对文本语言的另一个角度的理解, 因此也常常成为AI解决NLP领域高阶任务的重要基础环节.
使用jieba进行中文词性标注:
import jieba.posseg as pseg
pseg.lcut("我爱北京天安门")
[pair('我', 'r'), pair('爱', 'v'), pair('北京', 'ns'), pair('天安门', 'ns')]结果返回一个装有pair元组的列表, 每个pair元组中分别是词汇及其对应的词性, 具体词性含义请参照附录: jieba词性对照表
● 小结
学习了什么是分词:
- 分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符, 分词过程就是找到这样分界符的过程.
学习了分词的作用:
- 词作为语言语义理解的最小单元, 是人类理解文本语言的基础. 因此也是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节.
学习了流行中文分词工具jieba:
- 支持多种分词模式: 精确模式, 全模式, 搜索引擎模式
- 支持中文繁体分词
- 支持用户自定义词典
学习了jieba工具的安装和分词使用.
学习了什么是命名实体识别:
- 命名实体: 通常我们将人名, 地名, 机构名等专有名词统称命名实体. 如: 周杰伦, 黑山县, 孔子学院, 24辊方钢矫直机.
- 顾名思义, 命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体.
命名实体识别的作用:
- 同词汇一样, 命名实体也是人类理解文本的基础单元, 因此也是AI解决NLP领域高阶任务的重要基础环节.
学习了什么是词性标注:
- 词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等.
- 顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性.
学习了词性标注的作用:
- 词性标注以分词为基础, 是对文本语言的另一个角度的理解, 因此也常常成为AI解决NLP领域高阶任务的重要基础环节.
学习了使用jieba进行词性标注.
3)文本张量表示方法
学习目标
- 了解什么是文本张量表示及其作用.
- 掌握文本张量表示的几种方法及其实现.
1 文本张量表示
将一段文本使用张量进行表示,其中一般将词汇表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
举个例子:
["人生", "该", "如何", "起头"]
==>
每个词对应矩阵中的一个向量
[[1.32, 4,32, 0,32, 5.2],
[3.1, 5.43, 0.34, 3.2],
[3.21, 5.32, 2, 4.32],
[2.54, 7.32, 5.12, 9.54]]文本张量表示的作用:
- 将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作.
文本张量表示的方法:
- one-hot编码
- Word2vec
- Word Embedding
2 one-hot词向量表示
又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
举个例子:
["改变", "要", "如何", "起手"]`
==>[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]]onehot编码实现:
- 进行onehot编码:
import jieba # 导入keras中的词汇映射器Tokenizer from tensorflow.keras.preprocessing.text import Tokenizer # 导入用于对象保存与加载的joblib from sklearn.externals import joblib # 思路分析 生成onehot # 1 准备语料 vocabs # 2 实例化词汇映射器Tokenizer, 使用映射器拟合现有文本数据 (内部生成 index_word word_index) # 2-1 注意idx序号-1 # 3 查询单词idx 赋值 zero_list,生成onehot # 4 使用joblib工具保存映射器 joblib.dump() def dm_onehot_gen(): # 1 准备语料 vocabs vocabs = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"} # 2 实例化词汇映射器Tokenizer, 使用映射器拟合现有文本数据 (内部生成 index_word word_index) # 2-1 注意idx序号-1 mytokenizer = Tokenizer() mytokenizer.fit_on_texts(vocabs) # 3 查询单词idx 赋值 zero_list,生成onehot for vocab in vocabs: zero_list = [0] * len(vocabs) idx = mytokenizer.word_index[vocab] - 1 zero_list[idx] = 1 print(vocab, '的onehot编码是', zero_list) # 4 使用joblib工具保存映射器 joblib.dump() mypath = './mytokenizer' joblib.dump(mytokenizer, mypath) print('保存mytokenizer End') # 注意5-1 字典没有顺序 onehot编码没有顺序 []-有序 {}-无序 区别 # 注意5-2 字典有的单词才有idx idx从1开始 # 注意5-3 查询没有注册的词会有异常 eg: 狗蛋 print(mytokenizer.word_index) print(mytokenizer.index_word)
- 输出效果:
陈奕迅 的onehot编码是 [1, 0, 0, 0, 0, 0] 王力宏 的onehot编码是 [0, 1, 0, 0, 0, 0] 鹿晗 的onehot编码是 [0, 0, 1, 0, 0, 0] 周杰伦 的onehot编码是 [0, 0, 0, 1, 0, 0] 李宗盛 的onehot编码是 [0, 0, 0, 0, 1, 0] 吴亦凡 的onehot编码是 [0, 0, 0, 0, 0, 1] 保存mytokenizer End {'陈奕迅': 1, '王力宏': 2, '鹿晗': 3, '周杰伦': 4, '李宗盛': 5, '吴亦凡': 6} {1: '陈奕迅', 2: '王力宏', 3: '鹿晗', 4: '周杰伦', 5: '李宗盛', 6: '吴亦凡'}
- onehot编码器的使用:
# 思路分析 # 1 加载已保存的词汇映射器Tokenizer joblib.load(mypath) # 2 查询单词idx 赋值zero_list,生成onehot 以token为'李宗盛' # 3 token = "狗蛋" 会出现异常 def dm_onehot_use(): vocabs = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"} # 1 加载已保存的词汇映射器Tokenizer joblib.load(mypath) mypath = './mytokenizer' mytokenizer = joblib.load(mypath) # 2 编码token为"李宗盛" 查询单词idx 赋值 zero_list,生成onehot token = "李宗盛" zero_list = [0] * len(vocabs) idx = mytokenizer.word_index[token] - 1 zero_list[idx] = 1 print(token, '的onehot编码是', zero_list)
- 输出效果:
李宗盛 的onehot编码是 [0, 0, 0, 0, 1, 0]
one-hot编码的优劣势:
优势:操作简单,容易理解.
劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
正因为one-hot编码明显的劣势,这种编码方式被应用的地方越来越少,取而代之的是接下来我们要学习的稠密向量的表示方法word2vec和word embedding.
3 word2vec模型
word2vec介绍
1- 是将文本变成词向量张量的一种方法,是一种无监督(自监督)的训练方法,本质是训练一个模型,将模型的参数矩阵当作所有词汇的词向量表示。基于one-hot的形式进行优化改造
2- 它又分为两种具体模式:
⭐CBOW:连续词袋模式。使用两边的词预测中间的内容
⭐skip-gram:跳词模式。使用中间的词预测两边的内容
核心思想:给一段文本,选择一定的窗口,然后利用上下文预测中间目标词
3.1 模型介绍
word2vec是一种流行的将词汇表示成向量的无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示, 它包含CBOW和skipgram两种训练模式.
CBOW(Continuous bag of words)模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.
- 分析:
- 图中窗口大小为9, 使用前后4个词汇对目标词汇进行预测.
- CBOW模式下的word2vec过程说明:
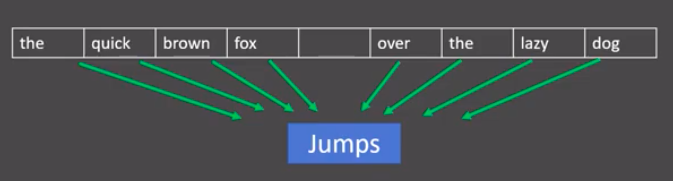
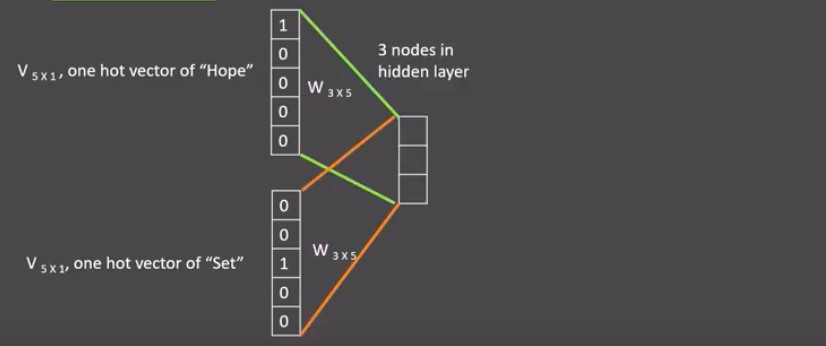
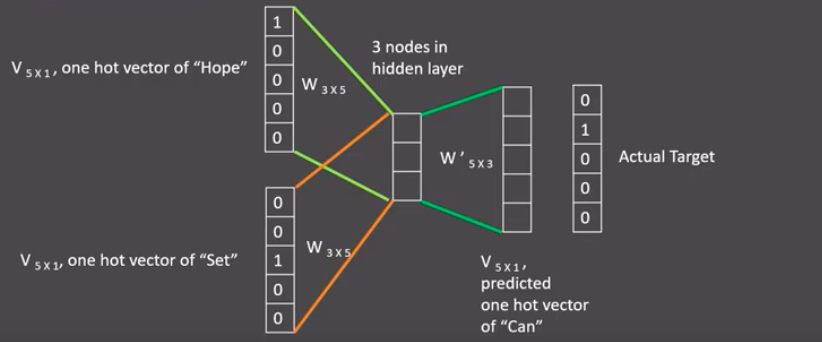
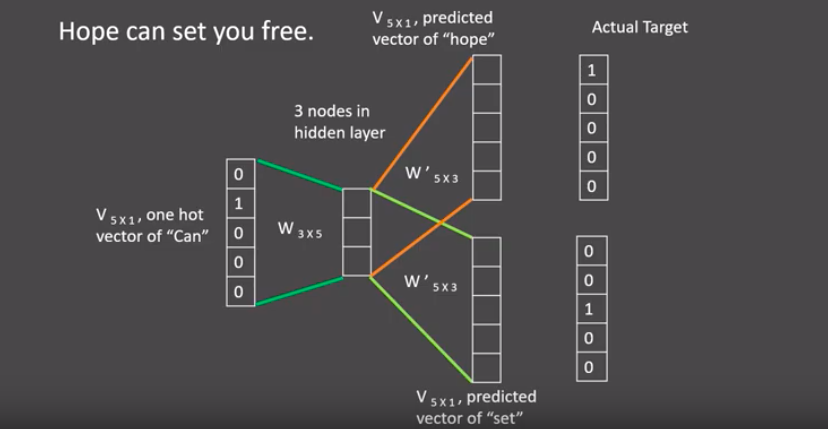
- 假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码. 如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1).
- 接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与我们真正的目标矩阵即can的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代.
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
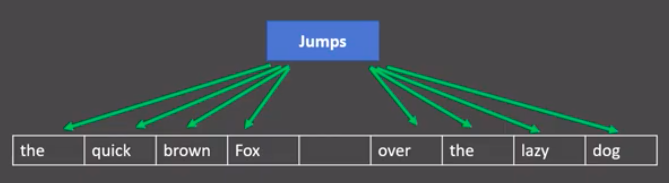
- skipgram模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.
- 分析:
- 图中窗口大小为9, 使用目标词汇对前后四个词汇进行预测.
- skipgram模式下的word2vec过程说明:
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是skipgram模式,所以将使用can作为输入 ,Hope和set作为输出,在模型训练时, Hope,can,set等词汇都使用它们的one-hot编码. 如图所示: 将can的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1).
接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们Hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代.
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
- 词向量的检索获取
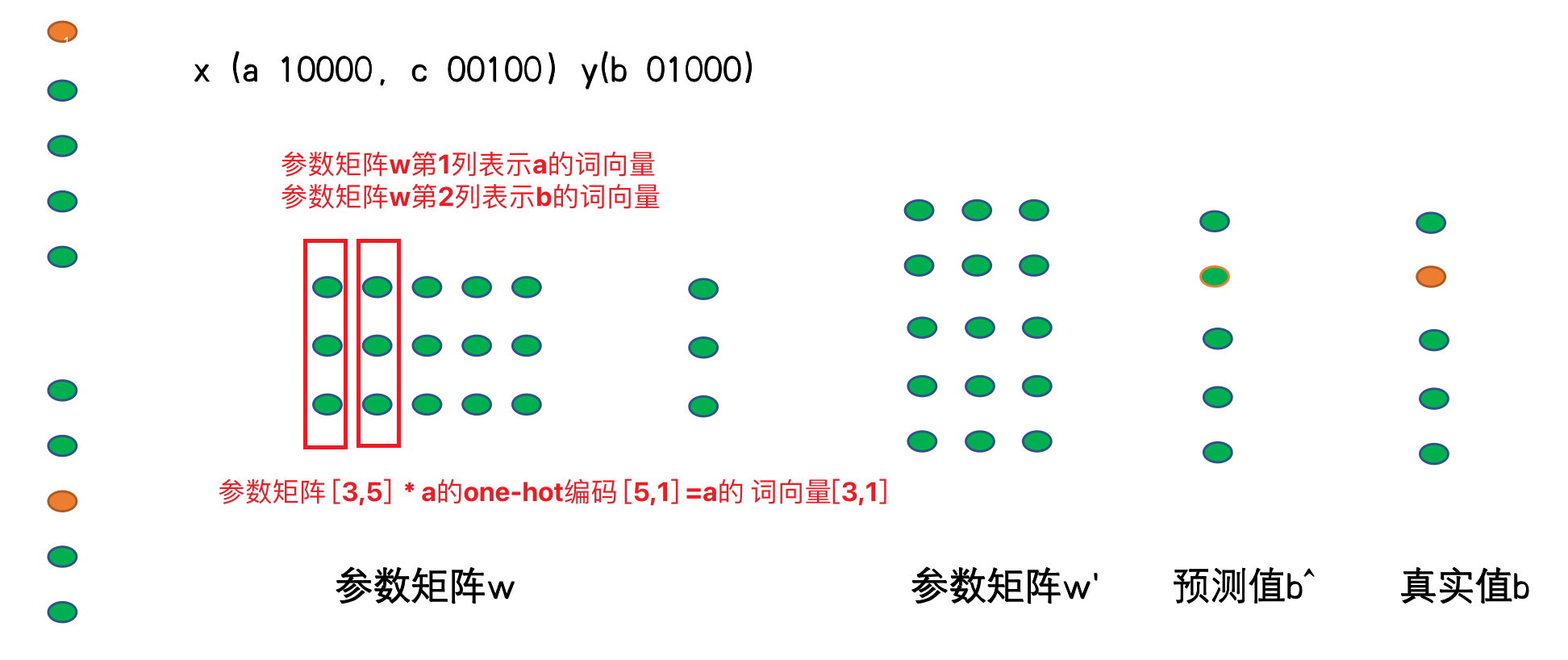
- 神经网络训练完毕后,神经网络的参数矩阵w就我们的想要词向量。如何检索某1个单词的向量呢?以CBOW方式举例说明如何检索a单词的词向量。
- 如下图所示:a的onehot编码10000,用参数矩阵3,5 * a的onehot编码10000,可以把参数矩阵的第1列参数给取出来,这个3,1的值就是a的词向量。
3.2 word2vec的训练和使用
- 第一步: 获取训练数据
- 第二步: 训练词向量
- 第三步: 模型超参数设定
- 第四步: 模型效果检验
- 第五步: 模型的保存与重加载
1 获取训练数据
数据来源:http://mattmahoney.net/dc/enwik9.zip
在这里, 我们将研究英语维基百科的部分网页信息, 它的大小在300M左右。这些语料已经被准备好, 我们可以通过Matt Mahoney的网站下载。
注意:原始数据集已经放在/root/data/enwik9.zip,解压后数据为/root/data/enwik9,预处理后的数据为/root/data/fil9
- 查看原始数据:
$ head -10 data/enwik9 # 原始数据将输出很多包含XML/HTML格式的内容, 这些内容并不是我们需要的 <mediawiki xmlns="http://www.mediawiki.org/xml/export-0.3/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mediawiki.org/xml/export-0.3/ http://www.mediawiki.org/xml/export-0.3.xsd" version="0.3" xml:lang="en"> <siteinfo> <sitename>Wikipedia</sitename> <base>http://en.wikipedia.org/wiki/Main_Page</base> <generator>MediaWiki 1.6alpha</generator> <case>first-letter</case> <namespaces> <namespace key="-2">Media</namespace> <namespace key="-1">Special</namespace> <namespace key="0" />
- 原始数据处理:
# 使用wikifil.pl文件处理脚本来清除XML/HTML格式的内容 # perl wikifil.pl data/enwik9 > data/fil9 #该命令已经执行
- 查看预处理后的数据:
# 查看前80个字符 head -c 80 data/fil9 # 输出结果为由空格分割的单词 anarchism originated as a term of abuse first used against early working class2 词向量的训练保存加载
fasttext 是 facebook 开源的一个词向量与文本分类工具。下面是该工具包的安装方法
# 训练词向量工具库的安装 # 方法1 简洁版 pip install fasttext # 方法2:源码安装(推荐) # 以linux安装为例: 目录切换到虚拟开发环境目录下,再执行git clone 操作 git clone https://github.com/facebookresearch/fastText.git cd fastText # 使用pip安装python中的fasttext工具包 sudo pip install . # 导入fasttext import fasttext def dm_fasttext_train_save_load(): # 1 使用train_unsupervised(无监督训练方法) 训练词向量 mymodel = fasttext.train_unsupervised('./data/fil9') print('训练词向量 ok') # 2 save_model()保存已经训练好词向量 # 注意,该行代码执行耗时很长 mymodel.save_model("./data/fil9.bin") print('保存词向量 ok') # 3 模型加载 mymodel = fasttext.load_model('./data/fil9.bin') print('加载词向量 ok') # 步骤1运行效果如下: 有效训练词汇量为124M, 共218316个单词 Read 124M words Number of words: 218316 Number of labels: 0 Progress: 100.0% words/sec/thread: 53996 lr: 0.000000 loss: 0.734999 ETA: 0h 0m3 查看单词对应的词向量
# 通过get_word_vector方法来获得指定词汇的词向量, 默认词向量训练出来是1个单词100特征 def dm_fasttext_get_word_vector(): mymodel = fasttext.load_model('./data/fil9.bin') myvector = mymodel.get_word_vector('the') print('myvector->', type(myvector), myvector.shape, myvector) # 运行效果如下: array([-0.03087516, 0.09221972, 0.17660329, 0.17308897, 0.12863874, 0.13912526, -0.09851588, 0.00739991, 0.37038437, -0.00845221, ... -0.21184735, -0.05048715, -0.34571868, 0.23765688, 0.23726143], dtype=float32)4 模型效果检验
# 检查单词向量质量的一种简单方法就是查看其邻近单词, 通过我们主观来判断这些邻近单词是否与目标单词相关来粗略评定模型效果好坏. # 查找"运动"的邻近单词, 我们可以发现"体育网", "运动汽车", "运动服"等. >>> model.get_nearest_neighbors('sports') [(0.8414610624313354, 'sportsnet'), (0.8134572505950928, 'sport'), (0.8100415468215942, 'sportscars'), (0.8021156787872314, 'sportsground'), (0.7889881134033203, 'sportswomen'), (0.7863013744354248, 'sportsplex'), (0.7786710262298584, 'sporty'), (0.7696356177330017, 'sportscar'), (0.7619683146476746, 'sportswear'), (0.7600985765457153, 'sportin')] # 查找"音乐"的邻近单词, 我们可以发现与音乐有关的词汇. >>> model.get_nearest_neighbors('music') [(0.8908010125160217, 'emusic'), (0.8464668393135071, 'musicmoz'), (0.8444250822067261, 'musics'), (0.8113634586334229, 'allmusic'), (0.8106718063354492, 'musices'), (0.8049437999725342, 'musicam'), (0.8004694581031799, 'musicom'), (0.7952923774719238, 'muchmusic'), (0.7852965593338013, 'musicweb'), (0.7767147421836853, 'musico')] # 查找"小狗"的邻近单词, 我们可以发现与小狗有关的词汇. >>> model.get_nearest_neighbors('dog') [(0.8456876873970032, 'catdog'), (0.7480780482292175, 'dogcow'), (0.7289096117019653, 'sleddog'), (0.7269964218139648, 'hotdog'), (0.7114801406860352, 'sheepdog'), (0.6947550773620605, 'dogo'), (0.6897546648979187, 'bodog'), (0.6621081829071045, 'maddog'), (0.6605004072189331, 'dogs'), (0.6398137211799622, 'dogpile')]5 模型超参数设定
# 在训练词向量过程中, 我们可以设定很多常用超参数来调节我们的模型效果, 如: # 无监督训练模式: 'skipgram' 或者 'cbow', 默认为'skipgram', 在实践中,skipgram模式在利用子词方面比cbow更好. # 词嵌入维度dim: 默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大. # 数据循环次数epoch: 默认为5, 但当你的数据集足够大, 可能不需要那么多次. # 学习率lr: 默认为0.05, 根据经验, 建议选择[0.01,1]范围内. # 使用的线程数thread: 默认为12个线程, 一般建议和你的cpu核数相同. >>> model = fasttext.train_unsupervised('data/fil9', "cbow", dim=300, epoch=1, lr=0.1, thread=8) Read 124M words Number of words: 218316 Number of labels: 0 Progress: 100.0% words/sec/thread: 49523 lr: 0.000000 avg.loss: 1.777205 ETA: 0h 0m 0s
python""" 如果不管是安装fasttext还是fasttext-wheel都失败,那么原囚是python版本过高。 操作步骤如下: 1-先进入对应的虚拟环境 2-安装低版本的python解释器condcinstallpython=3.10 3-安装fasttext pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/ """ import fasttext def demo01(): # 1- 使用无监督学习训练模型 """ 为什么这里只能使用无监督学习? 答:因为数据中没有明确标记目标值。有监督学习对文件内容有严格要求,有__label__ """ # model = fasttext.train_unsupervised("data/fil9") model = fasttext.train_unsupervised("../data/gz03ag") # 2- 保存训练好的模型 model.save_model("./model/word2vec.pkl") def demo02(): # 1- 加载训练好的模型 model = fasttext.load_model("./model/word2vec.pkl") # 2- 获得某个词的词向量 vector = model.get_word_vector("中国") print(vector) def demo03(): # 1- 加载训练好的模型 model = fasttext.load_model("./model/word2vec.pkl") # 2- 获得某个词的词向量 vector = model.get_sentence_vector("中国") print(vector) def demo04(): """ 参数解释: input:训练集数据路径 model:具体的模式。默认是skipgram。还可以设置cbow lr:初始的学习率 dim:词向量的维度。该值越大训练越耗时,但是存储的信息越丰富 epoch:训练的轮次 thread:并发训练的线程个数 """ model = fasttext.train_unsupervised( input="../data/gz03ag", model="cbow", lr=0.1, dim=100, epoch=1, thread=10 ) # 保存训练好的模型 model.save_model("./model/word2vec.pkl") if __name__ == '__main__': # 训练模型 # demo01() # 使用训练好的模型 # demo02() # 获得句子的词向量 # demo03() demo04()4 词嵌入word embedding介绍
通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
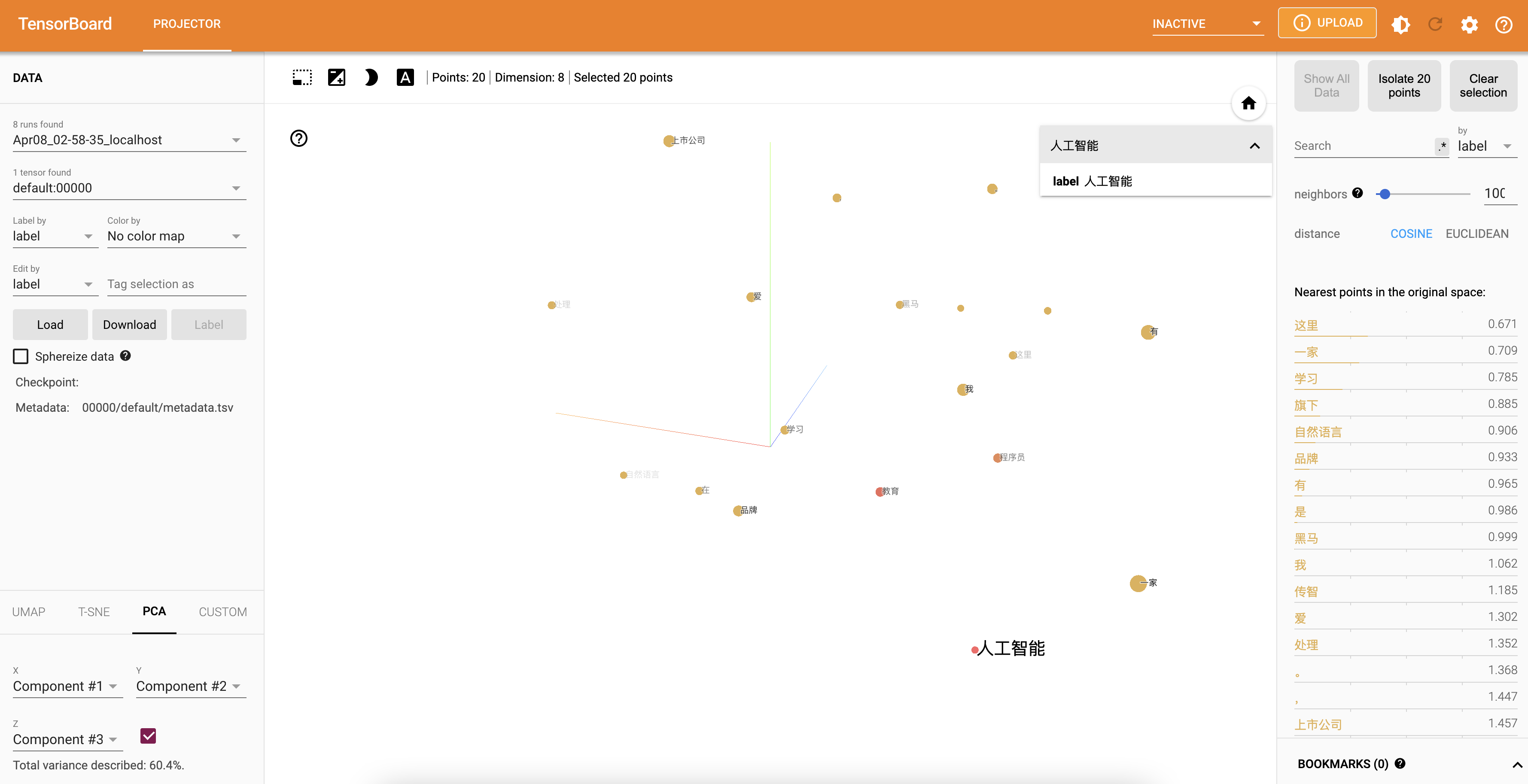
word embedding的可视化分析:
- 通过使用tensorboard可视化嵌入的词向量.
import torch from tensorflow.keras.preprocessing.text import Tokenizer from torch.utils.tensorboard import SummaryWriter import jieba import torch.nn as nn # 注意: # fs = tf.io.gfile.get_filesystem(save_path) # AttributeError: module 'tensorflow._api.v2.io.gfile' has no attribute 'get_filesystem' # 错误原因分析: # 1 from tensorboard.compat import tf 使用了tf 如果安装tensorflow,默认会调用它tf的api函数 import tensorflow as tf import tensorboard as tb tf.io.gfile = tb.compat.tensorflow_stub.io.gfile # 实验:nn.Embedding层词向量可视化分析 # 1 对句子分词 word_list # 2 对句子word2id求my_token_list,对句子文本数值化sentence2id # 3 创建nn.Embedding层,查看每个token的词向量数据 # 4 创建SummaryWriter对象, 可视化词向量 # 词向量矩阵embd.weight.data 和 词向量单词列表my_token_list添加到SummaryWriter对象中 # summarywriter.add_embedding(embd.weight.data, my_token_list) # 5 通过tensorboard观察词向量相似性 # 6 也可通过程序,从nn.Embedding层中根据idx拿词向量 def dm02_nnembeding_show(): # 1 对句子分词 word_list sentence1 = '传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能' sentence2 = "我爱自然语言处理" sentences = [sentence1, sentence2] word_list = [] for s in sentences: word_list.append(jieba.lcut(s)) # print('word_list--->', word_list) # 2 对句子word2id求my_token_list,对句子文本数值化sentence2id mytokenizer = Tokenizer() mytokenizer.fit_on_texts(word_list) # print(mytokenizer.index_word, mytokenizer.word_index) # 打印my_token_list my_token_list = mytokenizer.index_word.values() print('my_token_list-->', my_token_list) # 打印文本数值化以后的句子 sentence2id = mytokenizer.texts_to_sequences(word_list) print('sentence2id--->', sentence2id, len(sentence2id)) # 3 创建nn.Embedding层 embd = nn.Embedding(num_embeddings=len(my_token_list), embedding_dim=8) # print("embd--->", embd) # print('nn.Embedding层词向量矩阵-->', embd.weight.data, embd.weight.data.shape, type(embd.weight.data)) # 4 创建SummaryWriter对象 词向量矩阵embd.weight.data 和 词向量单词列表my_token_list summarywriter = SummaryWriter() summarywriter.add_embedding(embd.weight.data, my_token_list) summarywriter.close() # 5 通过tensorboard观察词向量相似性 # cd 程序的当前目录下执行下面的命令 # 启动tensorboard服务 tensorboard --logdir=runs --host 0.0.0.0 # 通过浏览器,查看词向量可视化效果 http://127.0.0.1:6006 print('从nn.Embedding层中根据idx拿词向量') # # 6 从nn.Embedding层中根据idx拿词向量 for idx in range(len(mytokenizer.index_word)): tmpvec = embd(torch.tensor(idx)) print('%4s'%(mytokenizer.index_word[idx+1]), tmpvec.detach().numpy())
- 程序运行效果
my_token_list--> dict_values(['是', '黑马', '我', '传智', '教育', '一家', '上市公司', ',', '旗下', '有', '程序员', '品牌', '。', '在', '这里', '学习', '人工智能', '爱', '自然语言', '处理']) sentence2id---> [[4, 5, 1, 6, 7, 8, 9, 10, 2, 11, 12, 13, 3, 1, 14, 2, 15, 16, 17], [3, 18, 19, 20]] 2 从nn.Embedding层中根据idx拿词向量 是 [ 0.46067393 -0.9049023 -0.03143226 -0.32443136 0.03115687 -1.3352231 -0.08336695 -2.4732168 ] 黑马 [ 0.66760564 0.08703537 0.23735243 1.5896837 -1.8869231 0.22520915 -1.0676078 -0.7654686 ] 我 [-0.9093167 -0.6114051 -0.6825029 0.9269122 0.5208822 2.294128 -0.11160549 -0.34862307] 传智 [-1.1552105 -0.4274638 -0.8121502 -1.4969801 -1.3328248 -1.0934378 0.6707438 -1.1796173] 教育 [ 0.01580311 -1.1884228 0.59364647 1.5387698 -1.0822943 0.36760855 -0.4652998 -0.57378227] 一家 [-1.1898873 -0.42482868 -1.9391155 -1.5678993 -1.6960118 0.22525501 -1.0754168 0.41797593] 上市公司 [ 0.590556 2.4274144 1.6698223 -0.9776848 -0.6119061 0.4434897 -2.3726876 -0.2607738] , [-0.17568143 1.0074369 0.2571488 1.8940887 -0.5383494 0.65416646 0.63454026 0.6235991 ] 旗下 [ 2.8400452 -1.0096515 2.247107 0.30006626 -1.2687006 0.05855403 0.01199368 -0.6156502 ] 有 [ 0.89320636 -0.43819678 1.0345292 1.3546743 -1.4238662 -1.6994532 0.30445674 2.673923 ] 程序员 [ 1.2147354 0.24878891 0.36161897 0.37458655 -0.48264053 -0.0141514 1.2033817 0.7899459 ] 品牌 [ 0.59799325 -0.01371854 0.0628166 -1.4829391 0.39795023 -0.39259398 -0.60923046 0.54170054] 。 [ 0.59599686 1.6038656 -0.10832139 0.25223547 0.37193906 1.1944667 -0.91253406 0.6869221 ] 在 [-1.161504 2.6963246 -0.6087775 0.9399654 0.8480068 0.684357 0.96156543 -0.3541162 ] 这里 [ 0.1034054 -0.01949253 0.8989019 1.61057 -1.5983531 0.17945968 -0.17572908 -0.9724814 ] 学习 [-1.3899843 -1.0846052 -1.1301199 -0.4078141 0.40511298 0.6562911 0.9231357 -0.34704337] 人工智能 [-1.4966388 -1.0905199 1.001238 -0.75254333 -1.4210068 -1.854177 1.0471514 -0.27140012] 爱 [-1.5254552 0.6189947 1.2703396 -0.4826037 -1.4928672 0.8320283 1.7333516 0.16908517] 自然语言 [-0.3856235 -1.2193452 0.9991112 -1.5821775 0.45017946 -0.66064674 0.08045111 0.62901515] 处理 [ 1.5062869 1.3156213 -0.21295634 0.47610474 0.08946162 0.57107806 -1.0727187 0.16396333] 词向量和词显示标签 写入磁盘ok 在当前目录下查看 ./runs 目录
- 在终端启动tensorboard服务:
$ cd ~ $ tensorboard --logdir=runs --host 0.0.0.0 # 通过http://192.168.88.161:6006访问浏览器可视化页面
- 浏览器展示并可以使用右侧近邻词汇功能检验效果:
5 小结
学习了什么是文本张量表示:
- 将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
学习了文本张量表示的作用:
- 将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作.
学习了文本张量表示的方法:
- one-hot编码
- Word2vec
- Word Embedding
什么是one-hot词向量表示:
- 又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
学习了onehot编码实现.
学习了one-hot编码的优劣势:
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
学习了什么是word2vec:
- 是一种流行的将词汇表示成向量的无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示, 它包含CBOW和skipgram两种训练模式.
学习了CBOW(Continuous bag of words)模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.
学习了CBOW模式下的word2vec过程说明:
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是CBOW模式,所以将使用Hope和set作为输入,you作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码. 如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1).
接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与我们真正的目标矩阵即you的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代.
最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
学习了skipgram模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.
学习了skipgram模式下的word2vec过程说明:
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是skipgram模式,所以将使用you作为输入 ,hope和set作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码. 如图所示: 将you的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1).
接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代.
最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
学习了使用fasttext工具实现word2vec的训练和使用:
- 第一步: 获取训练数据
- 第二步: 训练词向量
- 第三步: 模型超参数设定
- 第四步: 模型效果检验
- 第五步: 模型的保存与重加载
学习了什么是word embedding(词嵌入):
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
- 狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.
学习了word embedding的可视化分析:
- 通过使用tensorboard可视化嵌入的词向量.
- 在终端启动tensorboard服务.
- 浏览器展示并可以使用右侧近邻词汇功能检验效果.
4)文本数据分析
学习目标
- 了解文本数据分析的作用.
- 掌握常用的几种文本数据分析方法.
1 文件数据分析介绍
文本数据分析的作用:
- 文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 并指导之后模型训练过程中一些超参数的选择.
常用的几种文本数据分析方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
2 数据集说明
我们将基于真实的中文酒店评论语料来讲解常用的几种文本数据分析方法.
中文酒店评论语料:
- 属于二分类的中文情感分析语料, 该语料存放在"./cn_data"目录下.
- 其中train.tsv代表训练集, dev.tsv代表验证集, 二者数据样式相同.
train.tsv数据样式:
sentence label
早餐不好,服务不到位,晚餐无西餐,早餐晚餐相同,房间条件不好,餐厅不分吸烟区.房间不分有无烟房. 0
去的时候 ,酒店大厅和餐厅在装修,感觉大厅有点挤.由于餐厅装修本来该享受的早饭,也没有享受(他们是8点开始每个房间送,但是我时间来不及了)不过前台服务员态度好! 1
有很长时间没有在西藏大厦住了,以前去北京在这里住的较多。这次住进来发现换了液晶电视,但网络不是很好,他们自己说是收费的原因造成的。其它还好。 1
非常好的地理位置,住的是豪华海景房,打开窗户就可以看见栈桥和海景。记得很早以前也住过,现在重新装修了。总的来说比较满意,以后还会住 1
交通很方便,房间小了一点,但是干净整洁,很有香港的特色,性价比较高,推荐一下哦 1
酒店的装修比较陈旧,房间的隔音,主要是卫生间的隔音非常差,只能算是一般的 0
酒店有点旧,房间比较小,但酒店的位子不错,就在海边,可以直接去游泳。8楼的海景打开窗户就是海。如果想住在热闹的地带,这里不是一个很好的选择,不过威海城市真的比较小,打车还是相当便宜的。晚上酒店门口出租车比较少。 1
位置很好,走路到文庙、清凉寺5分钟都用不了,周边公交车很多很方便,就是出租车不太爱去(老城区路窄爱堵车),因为是老宾馆所以设施要陈旧些, 1
酒店设备一般,套房里卧室的不能上网,要到客厅去。 0train.tsv数据样式说明:
- train.tsv中的数据内容共分为2列, 第一列数据代表具有感情色彩的评论文本; 第二列数据, 0或1, 代表每条文本数据是积极或者消极的评论, 0代表消极, 1代表积极.
3 获取标签数量分布
# 导入必备工具包 import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 思路分析 : 获取标签数量分布 # 0 什么标签数量分布:求标签0有多少个 标签1有多少个 标签2有多少个 # 1 设置显示风格plt.style.use('fivethirtyeight') # 2 pd.read_csv(path, sep='\t') 读训练集 验证集数据 # 3 sns.countplot() 统计label标签的0、1分组数量 # 4 画图展示 plt.title() plt.show() # 注意1:sns.countplot()相当于select * from tab1 group by def dm_label_sns_countplot(): # 1 设置显示风格plt.style.use('fivethirtyeight') plt.style.use('fivethirtyeight') # 2 pd.read_csv 读训练集 验证集数据 train_data = pd.read_csv(filepath_or_buffer = './cn_data/train.tsv', sep='\t') dev_data = pd.read_csv(filepath_or_buffer = './cn_data/dev.tsv', sep='\t') # 3 sns.countplot() 统计label标签的0、1分组数量 sns.countplot(x='label', data = train_data) # 4 画图展示 plt.title() plt.show() plt.title('train_label') plt.show() # 验证集上标签的数量分布 # 3-2 sns.countplot() 统计label标签的0、1分组数量 sns.countplot(x='label', data = dev_data) # 4-2 画图展示 plt.title() plt.show() plt.title('dev_label') plt.show()
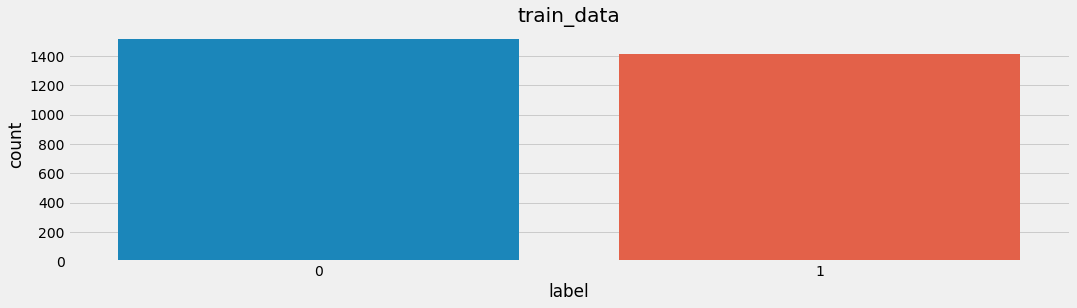
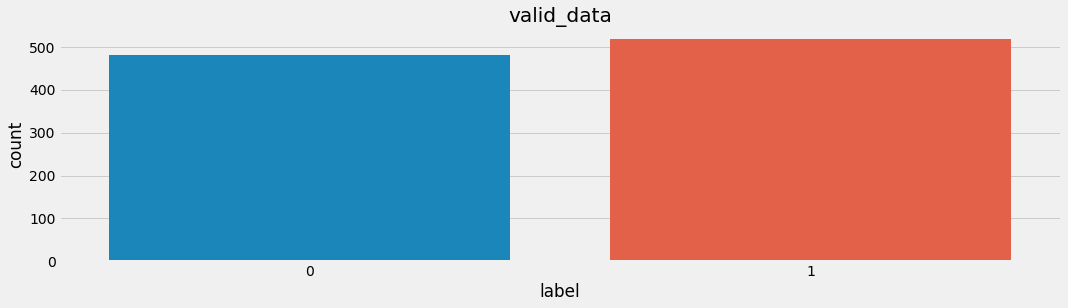
- 训练集标签数量分布:
- 验证集标签数量分布:
- 分析:
- 在深度学习模型评估中, 我们一般使用ACC作为评估指标, 若想将ACC的基线定义在50%左右, 则需要我们的正负样本比例维持在1:1左右, 否则就要进行必要的数据增强或数据删减. 上图中训练和验证集正负样本都稍有不均衡, 可以进行一些数据增强.
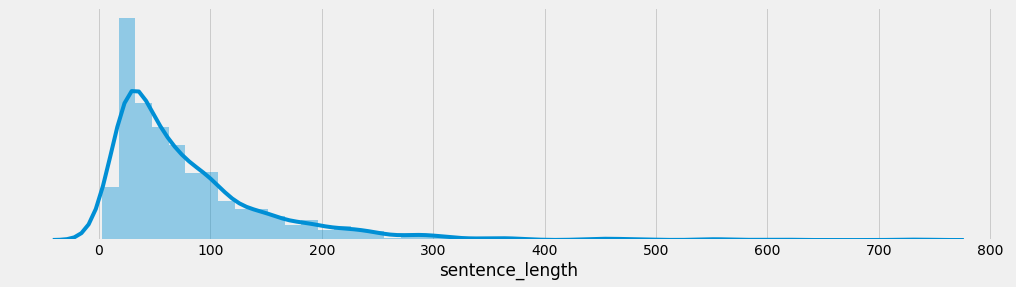
4 获取句子长度分布
# 思路分析 : 获取句子长度分布 -绘制句子长度分布-柱状图 句子长度分布-密度曲线图 # 0 什么是句子长度分布:求长度为50的有多少个 长度51的有多少个 长度为52的有多少个 # 1 设置显示风格plt.style.use('fivethirtyeight') # 2 pd.read_csv(path, sep='\t') 读训练集 验证集数据 # 3 新增数据长度列:train_data['sentence_length'] = list(map(lambda x:len(x) , ...)) # 4-1 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=train_data) # 画图展示 plt.xticks([]) plt.show() # 4-2 绘制数据长度分布图-曲线图 sns.displot(x='sentence_length', data=train_data) # 画图展示 plt.yticks([]) plt.show() def dm_len_sns_countplot_distplot(): # 1 设置显示风格plt.style.use('fivethirtyeight') plt.style.use('fivethirtyeight') # 2 pd.read_csv 读训练集 验证集数据 train_data = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t') dev_data = pd.read_csv(filepath_or_buffer='./cn_data/dev.tsv', sep='\t') # 3 求数据长度列 然后求数据长度的分布 train_data['sentence_length'] = list( map(lambda x: len(x), train_data['sentence'])) # 4 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=train_data) # sns.countplot(x=train_data['sentence_length']) plt.xticks([]) # x轴上不要提示信息 # plt.title('sentence_length countplot') plt.show() # 5 绘制数据长度分布图-曲线图 sns.displot(x='sentence_length', data=train_data) # sns.displot(x=train_data['sentence_length']) plt.yticks([]) # y轴上不要提示信息 plt.show() # 验证集 # 3 求数据长度列 然后求数据长度的分布 dev_data['sentence_length'] = list(map(lambda x: len(x), dev_data['sentence'])) # 4 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=dev_data) # sns.countplot(x=dev_data['sentence_length']) plt.xticks([]) # x轴上不要提示信息 # plt.title('sentence_length countplot') plt.show() # 5 绘制数据长度分布图-曲线图 sns.displot(x='sentence_length', data=dev_data) # sns.displot(x=dev_data['sentence_length']) plt.yticks([]) # y轴上不要提示信息 plt.show()
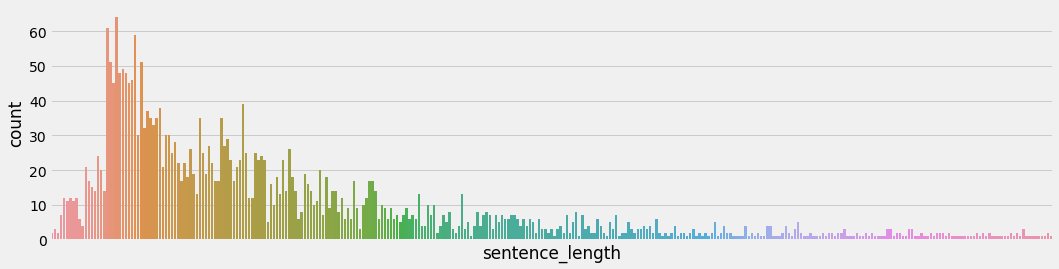
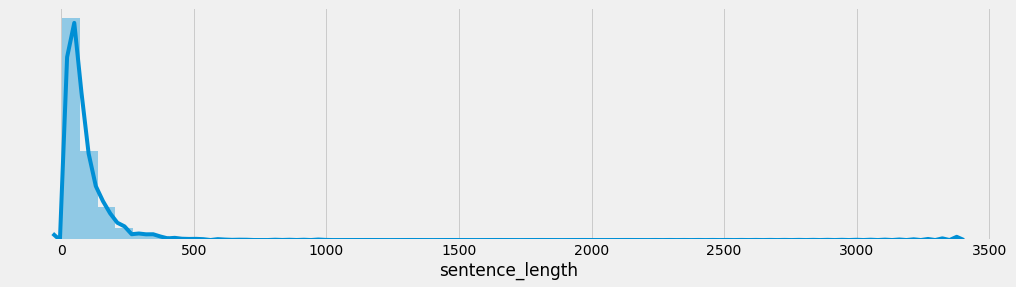
- 训练集句子长度分布:
- 验证集句子长度分布:
- 分析:
- 通过绘制句子长度分布图, 可以得知我们的语料中大部分句子长度的分布范围, 因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用. 上图中大部分句子长度的范围大致为20-250之间.
5 获取正负样本长度散点分布
# 获取正负样本长度散点分布,也就是按照x正负样本进行分组 再按照y长度进行散点图 # train_data['sentence_length'] = list(map(lambda x: len(x), train_data['sentence'])) # sns.stripplot(y='sentence_length', x='label', data=train_data) def dm03_sns_stripplot(): # 1 设置显示风格plt.style.use('fivethirtyeight') plt.style.use('fivethirtyeight') # 2 pd.read_csv 读训练集 验证集数据 train_data = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t') dev_data = pd.read_csv(filepath_or_buffer='./cn_data/dev.tsv', sep='\t') # 3 求数据长度列 然后求数据长度的分布 train_data['sentence_length'] = list(map(lambda x: len(x), train_data['sentence'])) # 4 统计正负样本长度散点图 (对train_data数据,按照label进行分组,统计正样本散点图) sns.stripplot(y='sentence_length', x='label', data=train_data) plt.show() sns.stripplot(y='sentence_length', x='label', data=dev_data) plt.show()
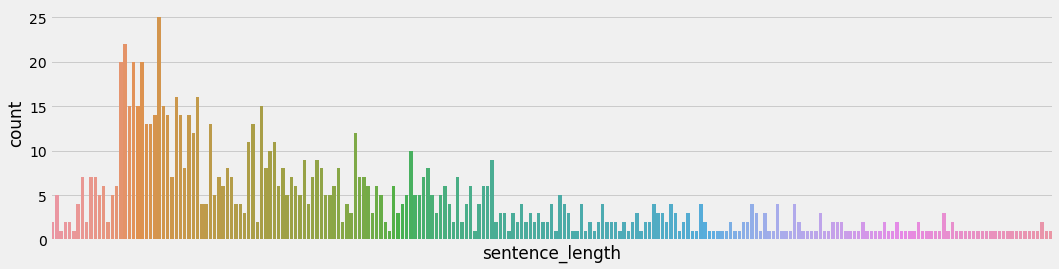
- 训练集上正负样本的长度散点分布:
- 验证集上正负样本的长度散点分布:
- 分析:
- 通过查看正负样本长度散点图, 可以有效定位异常点的出现位置, 帮助我们更准确进行人工语料审查. 上图中在训练集正样本中出现了异常点, 它的句子长度近3500左右, 需要我们人工审查.
6 获取不同词汇总数统计
# 导入jieba用于分词 # 导入chain方法用于扁平化列表 import jieba from itertools import chain # 进行训练集的句子进行分词, 并统计出不同词汇的总数 train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data["sentence"]))) print("训练集共包含不同词汇总数为:", len(train_vocab)) # 进行验证集的句子进行分词, 并统计出不同词汇的总数 valid_vocab = set(chain(*map(lambda x: jieba.lcut(x), valid_data["sentence"]))) print("训练集共包含不同词汇总数为:", len(valid_vocab))
- 输出效果:
训练集共包含不同词汇总数为: 12147 训练集共包含不同词汇总数为: 68577 获取训练集高频形容词词云
# 使用jieba中的词性标注功能 import jieba.posseg as pseg from wordcloud import WordCloud # 每句话产生形容词列表 def get_a_list(text): r = [] # 使用jieba的词性标注方法切分文本 找到形容词存入到列表中返回 for g in pseg.lcut(text): if g.flag == "a": r.append(g.word) return r # 根据词云列表产生词云 def get_word_cloud(keywords_list): # 实例化词云生成器对象 wordcloud = WordCloud(font_path="./SimHei.ttf", max_words=100, background_color='white') # 准备数据 keywords_string = " ".join (keywords_list) # 产生词云 wordcloud.generate(keywords_string) # 画图 plt.figure() plt.imshow(wordcloud, interpolation="bilinear") plt.axis('off') plt.show() # 思路分析 训练集正样本词云 训练集负样本词云 # 1 获得训练集上正样本 p_train_data # eg: 先使用逻辑==操作检索符合正样本 train_data[train_data['label'] == 1] # 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b)) # 3 调用绘制词云函数 def dm_word_cloud(): # 1 获得训练集上正样本p_train_data # eg: 先使用逻辑==操作检索符合正样本 train_data[train_data['label'] == 1] train_data = pd.read_csv(filepath_or_buffer='./cn_data/train.tsv', sep='\t') p_train_data = train_data[train_data['label'] == 1 ]['sentence'] # 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b)) p_a_train_vocab = chain(*map(lambda x: get_a_list(x) , p_train_data)) # print(p_a_train_vocab) # print(list(p_a_train_vocab)) # 3 调用绘制词云函数 get_word_cloud(p_a_train_vocab) print('*' * 60 ) # 训练集负样本词云 n_train_data = train_data[train_data['label'] == 0 ]['sentence'] # 2 获取正样本的每个句子的形容词 p_a_train_vocab = chain(*map(a,b)) n_a_train_vocab = chain(*map(lambda x: get_a_list(x) , n_train_data) ) # print(n_a_dev_vocab) # print(list(n_a_dev_vocab)) # 3 调用绘制词云函数 get_word_cloud(n_a_train_vocab)
- 训练集正样本形容词词云:
- 训练集负样本形容词词云:
8 获取验证集形容词词云
# 获得验证集上正样本 p_valid_data = valid_data[valid_data["label"]==1]["sentence"] # 对正样本的每个句子的形容词 valid_p_a_vocab = chain(*map(lambda x: get_a_list(x), p_valid_data)) #print(train_p_n_vocab) # 获得验证集上负样本 n_valid_data = valid_data[valid_data["label"]==0]["sentence"] # 获取负样本的每个句子的形容词 valid_n_a_vocab = chain(*map(lambda x: get_a_list(x), n_valid_data)) # 调用绘制词云函数 get_word_cloud(valid_p_a_vocab) get_word_cloud(valid_n_a_vocab)
- 验证集正样本形容词词云:
- 验证集负样本形容词词云:
- 分析:
- 根据高频形容词词云显示, 我们可以对当前语料质量进行简单评估, 同时对违反语料标签含义的词汇进行人工审查和修正, 来保证绝大多数语料符合训练标准. 上图中的正样本大多数是褒义词, 而负样本大多数是贬义词, 基本符合要求, 但是负样本词云中也存在"便利"这样的褒义词, 因此可以人工进行审查.
9 小结
学习了文本数据分析的作用:
- 文本数据分析能够有效帮助我们理解数据语料, 快速检查出语料可能存在的问题, 并指导之后模型训练过程中一些超参数的选择.
学习了常用的几种文本数据分析方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
学习了基于真实的中文酒店评论语料进行几种文本数据分析方法.
- 获得训练集和验证集的标签数量分布
- 获取训练集和验证集的句子长度分布
- 获取训练集和验证集的正负样本长度散点分布
- 获得训练集与验证集不同词汇总数统计
- 获得训练集上正负的样本的高频形容词词云
5)文本特征处理
学习目标
了解文本特征处理的作用.
掌握实现常见的文本特征处理的具体方法.
文本特征处理的作用:
- 文本特征处理包括为语料添加具有普适性的文本特征, 如:n-gram特征, 以及对加入特征之后的文本语料进行必要的处理, 如: 长度规范. 这些特征处理工作能够有效的将重要的文本特征加入模型训练中, 增强模型评估指标.
常见的文本特征处理方法:
- 添加n-gram特征
- 文本长度规范
1 什么是n-gram特征
n-gram:
含义:将相邻的n个词合并到一起
种类:1-gram、2-gram、3-gram
uni-gram、bi-gram、tri-gram
作用:为了更好的理解词的上下文信息
给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3.
举个例子:
假设给定分词列表: ["是谁", "敲动", "我心"]
对应的数值映射列表为: [1, 34, 21]
我们可以认为数值映射列表中的每个数字是词汇特征.
除此之外, 我们还可以把"是谁"和"敲动"两个词共同出现且相邻也作为一种特征加入到序列列表中,
假设1000就代表"是谁"和"敲动"共同出现且相邻
此时数值映射列表就变成了包含2-gram特征的特征列表: [1, 34, 21, 1000]
这里的"是谁"和"敲动"共同出现且相邻就是bi-gram特征中的一个.
"敲动"和"我心"也是共现且相邻的两个词汇, 因此它们也是bi-gram特征.
假设1001代表"敲动"和"我心"共同出现且相邻
那么, 最后原始的数值映射列表 [1, 34, 21] 添加了bi-gram特征之后就变成了 [1, 34, 21, 1000, 1001]
提取n-gram特征:
一般n-gram中的n取2或者3, 这里取2为例
ngram_range = 2
def create_ngram_set(input_list):
"""
description: 从数值列表中提取所有的n-gram特征
:param input_list: 输入的数值列表, 可以看作是词汇映射后的列表,
里面每个数字的取值范围为[1, 25000]
:return: n-gram特征组成的集合
eg: >>> create_ngram_set([1, 3, 2, 1, 5, 3]) {(3, 2), (1, 3), (2, 1), (1, 5), (5, 3)} """ return set(zip(*[input_list[i:] for i in range(ngram_range)]))调用:
input_list = [1, 3, 2, 1, 5, 3]
res = create_ngram_set(input_list)
print(res)
- 输出效果:
# 该输入列表的所有bi-gram特征 {(3, 2), (1, 3), (2, 1), (1, 5), (5, 3)}2 文本长度规范及其作用
一般模型的输入需要等尺寸大小的矩阵, 因此在进入模型前需要对每条文本数值映射后的长度进行规范, 此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度, 对超长文本进行截断, 对不足文本进行补齐(一般使用数字0), 这个过程就是文本长度规范.
文本长度规范的实现:
from tensorflow.keras.preprocessing import sequence
cutlen根据数据分析中句子长度分布,覆盖90%左右语料的最短长度.
这里假定cutlen为10
cutlen = 10
def padding(x_train):
"""
description: 对输入文本张量进行长度规范
:param x_train: 文本的张量表示, 形如: [[1, 32, 32, 61], [2, 54, 21, 7, 19]]
:return: 进行截断补齐后的文本张量表示
"""
# 使用sequence.pad_sequences即可完成
return sequence.pad_sequences(x_train, cutlen)
- 调用:
# 假定x_train里面有两条文本, 一条长度大于10, 一天小于10 x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1], [2, 32, 1, 23, 1]] res = padding(x_train) print(res)
- 输出效果:
[[ 5 32 55 63 2 21 78 32 23 1] [ 0 0 0 0 0 2 32 1 23 1]]3 小结
学习了文本特征处理的作用:
- 文本特征处理包括为语料添加具有普适性的文本特征, 如:n-gram特征, 以及对加入特征之后的文本语料进行必要的处理, 如: 长度规范. 这些特征处理工作能够有效的将重要的文本特征加入模型训练中, 增强模型评估指标.
学习了常见的文本特征处理方法:
- 添加n-gram特征
- 文本长度规范
学习了什么是n-gram特征:
- 给定一段文本序列, 其中n个词或字的相邻共现特征即n-gram特征, 常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3.
学习了提取n-gram特征的函数: create_ngram_set
学习了文本长度规范及其作用:
- 一般模型的输入需要等尺寸大小的矩阵, 因此在进入模型前需要对每条文本数值映射后的长度进行规范, 此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度, 对超长文本进行截断, 对不足文本进行补齐(一般使用数字0), 这个过程就是文本长度规范.
学习了文本长度规范的实现函数: padding
6)文本数据增强
7)jieba词性对照表
jieba词性对照表:
- a 形容词
- ad 副形词
- ag 形容词性语素
- an 名形词
- b 区别词
- c 连词
- d 副词
- df
- dg 副语素
- e 叹词
- f 方位词
- g 语素
- h 前接成分
- i 成语
- j 简称略称
- k 后接成分
- l 习用语
- m 数词
- mg
- mq 数量词
- n 名词
- ng 名词性语素
- nr 人名
- nrfg
- nrt
- ns 地名
- nt 机构团体名
- nz 其他专名
- o 拟声词
- p 介词
- q 量词
- r 代词
- rg 代词性语素
- rr 人称代词
- rz 指示代词
- s 处所词
- t 时间词
- tg 时语素
- u 助词
- ud 结构助词 得
- ug 时态助词
- uj 结构助词 的
- ul 时态助词 了
- uv 结构助词 地
- uz 时态助词 着
- v 动词
- vd 副动词
- vg 动词性语素
- vi 不及物动词
- vn 名动词
- vq
- x 非语素词
- y 语气词
- z 状态词
- zg
hanlp词性对照表:
【Proper Noun------NR,专有名词】
【Temporal Noun------NT,时间名词】
【Localizer------LC,定位词】如"内","左右"
【Pronoun------PN,代词】
【Determiner------DT,限定词】如"这","全体"
【Cardinal Number------CD,量词】
【Ordinal Number------OD,次序词】如"第三十一"
【Measure word------M,单位词】如"杯"
【Verb:VA,VC,VE,VV,动词】
【Adverb:AD,副词】如"近","极大"
【Preposition:P,介词】如"随着"
【Subordinating conjunctions:CS,从属连词】
【Conjuctions:CC,连词】如"和"
【Particle:DEC,DEG,DEV,DER,AS,SP,ETC,MSP,小品词】如"的话"
【Interjections:IJ,感叹词】如"哈"
【onomatopoeia:ON,拟声词】如"哗啦啦"
【Other Noun-modifier:JJ】如"发稿/JJ 时间/NN"
【Punctuation:PU,标点符号】
【Foreign word:FW,外国词语】如"OK






机器学习:数据预处理/特征预处理 → 算法模型
NLP基础:数据预处理/特征预处理 → 算法模型RNN / LSTM / GRU / Transformer...
北京有什么好玩的?
↓
分词:北京 有 什么 好玩 的 地方 ?
↓
one-hot
向量化处理:文字 → 张量数字
张量中不能存放非数字
python
import jieba
from sympy import content
"""
什么情况下需要用户自定义词典?
答:当你真的是一名NLP开发工程师或者要开发公司内部的搜索引擎的时候才需要:根据公司业务场景进行针对性的分词才需要
"""
def demo01():
content = "煩惱即是菩提,我暫且不提"
result = jieba.lcut(content)
print(result)
content = '煩恼即是菩提,我暫且不提'
result = jieba.lcut(content)
print(result)
def demo02():
content = 'IT教育是一家上市公司,旗下有很多程序员。我是在这里学习人工智能'
# 加载自定义词典
jieba.load_userdict('./my_dict.txt')
result = jieba.lcut(content)
print(result)
if __name__ == '__main__':
# 繁体字分词
demo01()
# 自定义词典分词
demo02()
python
# 自定义词典格式 词 词频 词性
IT教育 10 n
程序员 20
我是
python
import jieba.posseg as paeg # 词性标注
if __name__ == '__main__':
content = '我爱北京天安门'
result = paeg.lcut(content)
print(result)
print(type(result))
for word, pos in result:
print(f""{word}"的词性是{pos}")词向量-onehot形式
python
import os
# 注意:1- 代码放在整个文件的最上面;2- 0需要时字符串的类型
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '0'
import joblib
# from tensorflow.keras.preprocessing.text import Tokenizer # 词汇映射器
from keras.src.legacy.preprocessing.text import Tokenizer # 上面的替代方案
"""
获得词向量的one-hot方式总结:
优点:实现、理解简单
缺点:
1- 词向量是一个稀疏向量,会浪费存储和计算资源
2- 对多义词的处理不好。例如:过过过过过过,中的3对过的词向量使用一个
"""
def demo01():
# 1- 准备语料库
vocabs = ["周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"]
# 2- 训练词汇映射器
# 2.1 创建词汇映射器
my_tokenizer = Tokenizer()
# 2.2- 用语料库训练
my_tokenizer.fit_on_texts(vocabs)
# 2.3- 得到训练好的词和索引的映射关系
# word_index类型是字典类型。key是词,value是词索引,索引是从1开始的
# 注意:1- word_index后面不要加小括号:2- 返回结果类型是普通的Python字典
word_dict = my_tokenizer.word_index
print('--------------',type(word_dict))
print('--------------',word_dict)
# 3- 得到每个词的one-hot词向量
vocabs_len = len(vocabs)
for word in vocabs:
# 3.1- 初始化一个全0的词向量列表
one_hot = [0]*vocabs_len # 得到是[0,0,0,0,0,0]
# 3.2- 获得词在词汇映射器中的索引。注意:索引是从1开始的
index = word_dict[word]-1
# 3.3- 将指定位置的值改为1即可
one_hot[index] = 1
print(f'{word},对应的词向量是{one_hot}')
# 4- 保存训练好的模型
joblib.dump(my_tokenizer,filename='./model/tokenizer.pkl')
def demo02():
word = '王力宏'
# 1- 加载训练好的模型
my_tokenizer = joblib.load("./model/tokenizer.pkl")
# 2- 得到某个词的词向量
# 2.1- 获得词汇映射器中词和索引的对应关系
word_dict = my_tokenizer.word_index
# 2.2- 初始化一个全0的列表
word_one_hot = [0]*len(word_dict)
# 2.3- 获得该词的索引
index = word_dict[word]-1
# 2.4- 将指定索引位置的值设置为1即可
word_one_hot[index] = 1
print(word,'demo2----------',word_one_hot)
# 基于纯Python入门试学班的代码实现
def demo03():
# 1- 准备语料库
vocabs=["周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"]
# 2- 得到每个词的one-hot词向量
vacabs_len = len(vocabs)
for word in vocabs:
# 2.1- 初始化一个全0的词向量列表
word_one_hot = [0]*vacabs_len # 得到是[0,0,0,0,0,0]
# 2.2- 获得该词在语料库中的索引
index = vocabs.index(word)
# 2.3- 将指定索引位置的值设置为1即可
word_one_hot[index] = 1
print(f'{word},对应的词向量是{word_one_hot}')
if __name__ == '__main__':
# 1- 训练模型:行业就是训练词汇映射器
demo01()
# 2- 使用训练好的模型
demo02()
# 3- 用最基本的方式实现
demo03()分词器:
○ list=jieba.lcut(句子0)
○ 能够对简体、繁体进行分词
○ 使用自定义词典
-
当你需要按照你们公司具体的业务场景进行分词的时候需要你们自己维护词典
-
jieba.load_userdict(自定义词典路径)
○ 命名实体识别NER
- 一些词具备特殊的含义,例如:任命、地名、机构名、组织名等
○ 词性标注POS
- 不同词的词性是有区别的。例如:名词、动词、形容词等
文本张量的标识形式:
○ one-hot
-
优点:处理简单,容易理解
-
缺点:1.产生的词向量是稀疏向量,会浪费存储空间和计算资源;
2.对近义词的处理不好,导致词和句子的含义之间是割裂的;
使用:例如人名分类器
○ word2vec
- 分类
○ word Embedding
1.打开终端
2.进入到runs所在的位置
3.执行命令 tensorboard --logdir=runs --host 127.0.0.1
输入→分词→每个词得到词向量→词向量组织起来就得到了文本张量获得词向量方式:one-hot编码、Word2vec、Word Embedding
**one-hot编码:**极其简单、占用空间、词语的割裂性明显**word2vec:**对one-hot做了升级改造、两种模式:CBOW(左右两边预测中间|上下文预测中间)、skipgram(中间预测上下文|左右两边)
怎么实现word2vec?使用fasttext工具开发得到word2vec的代码
- 获取训练数据
2.训练词向量
3.模型超参数设定
4.模型效果检验
5.模型的保存与重加载
词向量_wordEmbedding
python
import jieba
from keras.src.legacy.preprocessing.text import Tokenizer
import torch.nn as nn
import torch
from torch.utils.tensorboard import SummaryWriter
if __name__ == '__main__':
# 1- 准备文本内容
sentence1='IT教育是一家上市公司,旗下有很多程序员。我在这里学习人工智能'
sentence2='我爱自然语言处理'
sentence_list = [sentence1, sentence2]
# 2- 对每条句子进行分词
word_list=[]
for sen in sentence_list:
word_list.append(jieba.lcut(sen))
print(word_list)
# 3- 训练得到词汇映射器
tokenizer = Tokenizer()
tokenizer.fit_on_texts(word_list)
index_word=tokenizer.index_word
"""
排序过程如下:
1- 默认按照词在句子中出现的顺序排序
2- 然后出现次数高(词频),的排在前面
3- 如果词频也相同,再词在句子中出现的顺序排序
"""
# print(type(index_word))
# print(index_word)
# 4- 创建词嵌入层
word_nums=len(index_word)
"""
词嵌入层:将词变成词向量
参数解释:
num_embeddings:词汇表中词的个数,注意:是去重后词的个数
embedding_dim:词向量维度,也就是向量中有多少数字。实际工作一般设置为128、256、512等
"""
# ⭐️⭐️⭐️⭐️⭐️
ebd = nn.Embedding(num_embeddings=word_nums, embedding_dim=8)
# 5- 遍历获得每个词的词向量
for key,value in index_word.items():
# 5.1- 通过【key次索引】获得词向量
# 注意:key是词索引,是从1开始的
word_vec = ebd(torch.tensor(key-1))
# 5.2- 打印输出
print(f"词:{value},词向量:{word_vec}")
# 6- 【了解】可视化展示:展示次和词之间的相似性
# 注意:runs的父目录不能有中文名称
summary = SummaryWriter("../runs")
summary.add_embedding(ebd.weight.data, index_word.values())
summary.close()数据探索_句子长度分布
python
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
def demo01():
# 1- 读取数据
df = pd.read_csv(filepath_or_buffer="../data/train.csv", sep=",", encoding="UTF-8")
# 2- 统计句子长度
# 2.1- 获得句子列
sentence_series = df["text"]
# 2.2- 计算句子长度
# 方式一:list(map)
# df["length"]=list(map(lambda line:len(line),sentence_series))
# 方式二:apply
df["length"] = sentence_series.apply(lambda line: len(line))
# print(df.head())
# 3- 绘制图形
# 3.1- 绘制分布直方图
plt.style.use("fivethirtyeight")
sns.countplot(x="length", data=df)
plt.xticks([])
plt.title("length_dist")
plt.show()
# 3.2- 绘制趋势曲线
# kde:让曲线更加平滑
sns.displot(x="length",data=df,kde=True)
plt.show()
def demo02():
# 1- 读取数据
df=pd.read_csv(filepath_or_buffer="../data/train.csv",sep=",",encoding="UTF-8")
# 2- 统计句子长度
# 2.1- 获取句子列
sentence_series = df["text"]
# 2.2- 计算句子长度
df["length"]=sentence_series.apply(lambda line: len(line))
# 3- 绘制图形
sns.stripplot(x="label",y="length",data=df,hue="label")
plt.title("label_length")
plt.show()
if __name__ == '__main__':
# 句子长度分布
demo01()
# 好评差评的句子长度分布
demo02()数据探索_词汇总数
python
import jieba
from itertools import chain
import pandas as pd
if __name__ == '__main__':
df = pd.read_csv(filepath_or_buffer="../data/train.csv", sep=",", encoding="UTF-8")
# map_result=map(lambda line:jieba.lcut(line),df["text"])
# word_set=set(chain(*map_result))
# 合并的写法版本
word_set = set(chain(*map(lambda line: jieba.lcut(line), df["text"])))
print("词汇总个数", len(word_set))数据探索_形容词的词云
python
import pandas as pd
from itertools import chain
from wordcloud import WordCloud # 词云类
import jieba.posseg as pseg # 词性标注
import matplotlib.pyplot as plt
def get_a_word(line):
# 分词并且标注词性
word_dict = pseg.lcut(line)
# print(word_dict)
result_list = []
# 过滤形容词
for word, pos in word_dict:
if pos == "a":
result_list.append(word)
return result_list
def show_cloud(a_word_list):
# 1- 创建词云对象
wordcloud_obj = WordCloud(font_path="../data/simhei.ttf", max_words=100, background_color="white")
# 2- 词汇列表以空空个分割拼接成字符串
word_str = " ".join(a_word_list)
# 3- 绘制图形
wordcloud_obj.generate(word_str)
plt.figure()
# bilinear:让蚊子边缘更加平滑
plt.imshow(wordcloud_obj, interpolation="bilinear")
plt.axis("off")
plt.show()
def word_cloud():
# 1- 读取文件,并且取出评价内容
df = pd.read_csv(filepath_or_buffer="../data/train.csv", sep=",", encoding="UTF-8")
sentence_series = df["text"]
# 2- 句子分词,过滤出形容词
# 注意:map返回的是生成器,你要真的调用它,才会出发数据的产生
a_word_list = list(chain(*map(get_a_word, sentence_series)))
# 3- 绘制词云
show_cloud(a_word_list)
if __name__ == '__main__':
word_cloud()复杂代码解释
python
# 导入chain
from itertools import chain
import jieba
if __name__ == '__main__':
# 解释set(chain(*map(lambda)))
my_data = ['今天天气很好', '晚上吃什么']
result_1 = map(lambda line: jieba.lcut(line), my_data)
# [['今天天气', '很', '好'], ['晚上', '吃', '什么']]
# print(list(result_1))
# chain的作用类似list.extend,优点是非常节约内存(生成器和list的区别)
# *表示解包处理
result_2 = chain(*result_1)
print(set(result_2))
# 上面代码合并后的写法
final_result = set(chain(*map(lambda line: jieba.lcut(line), my_data)))
print(final_result)三.RNN及其变体【重难点】
1.认识RNN模型
学习目标
- 了解什么是RNN模型.
- 了解RNN模型的作用.
- 了解RNN模型的分类.
1 什么是RNN模型
-
RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.
-
一般单层神经网络结构:
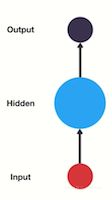
- RNN单层网络结构:
1- 达到指定的循环次数
2- 遇到特殊的标识
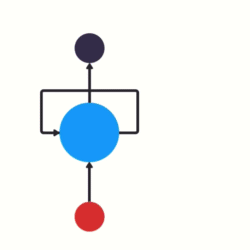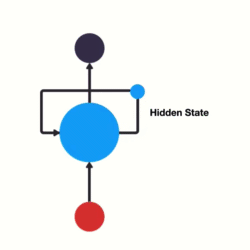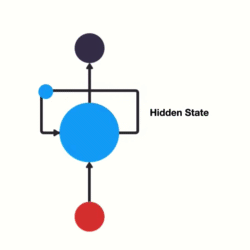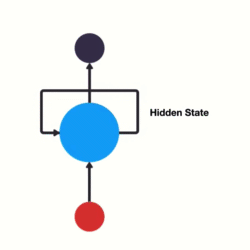
- 以时间步对RNN进行展开后的单层网络结构:
输出层
隐藏层-隐藏层中的数据我们称之为隐藏状态信息,它记录了输入数据和上下文的信息
输入层

- RNN的循环机制使模型隐层上一时间步产生的结果, 能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响.
2 RNN模型的作用
-
因为RNN结构能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等.
-
下面我们将以一个用户意图识别的例子进行简单的分析:

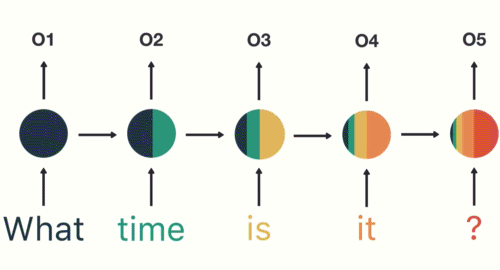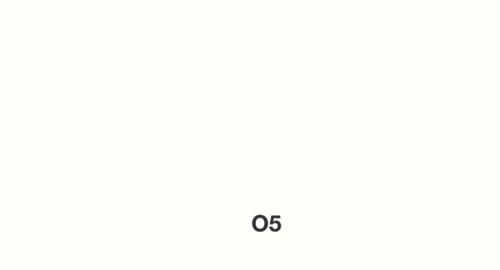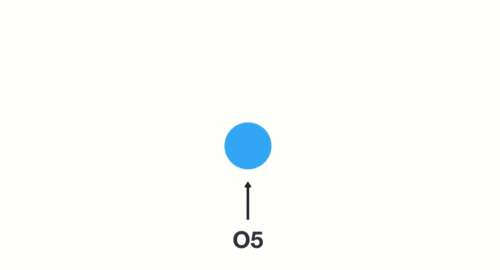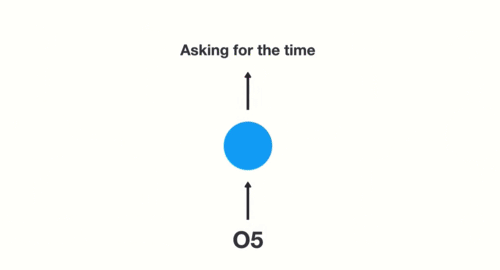
- 第一步: 用户输入了"What time is it ?", 我们首先需要对它进行基本的分词, 因为RNN是按照顺序工作的, 每次只接收一个单词进行处理.

- 第二步: 首先将单词"What"输送给RNN, 它将产生一个输出O1.
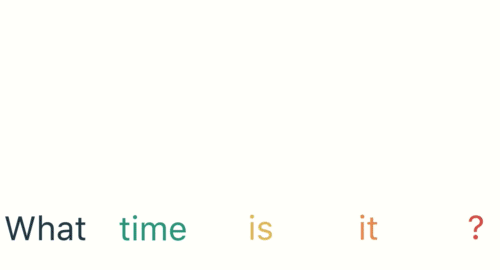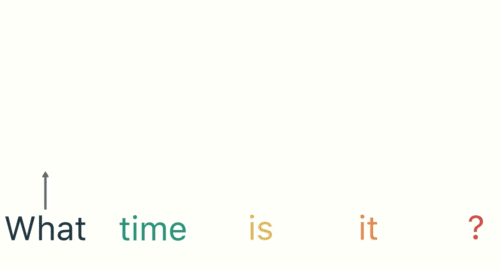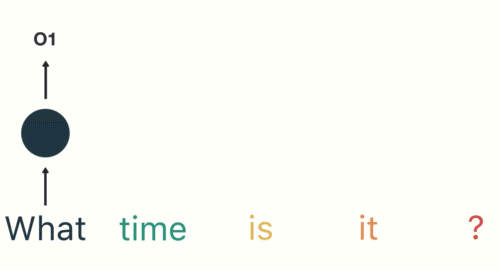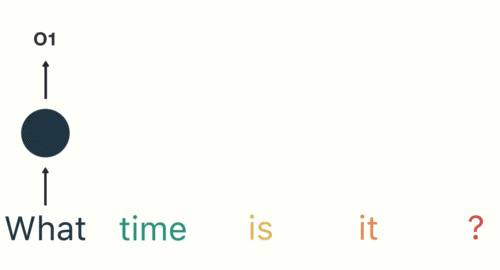
- 第三步: 继续将单词"time"输送给RNN, 但此时RNN不仅仅利用"time"来产生输出O2, 还会使用来自上一层隐层输出O1作为输入信息.
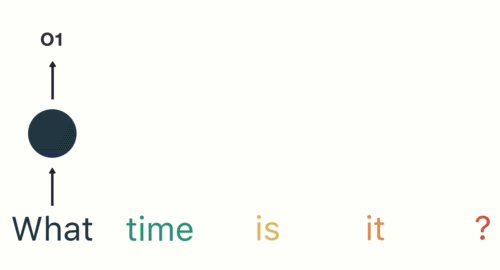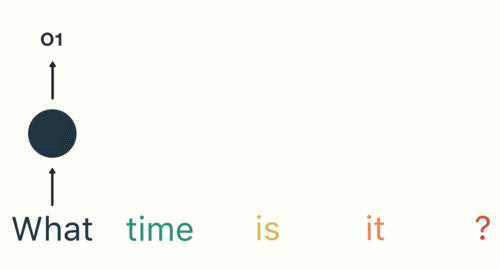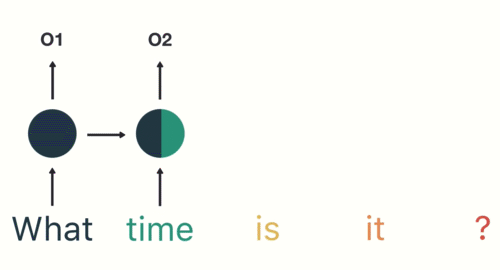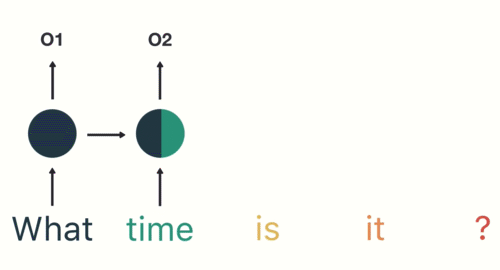
- 第四步: 重复这样的步骤, 直到处理完所有的单词.
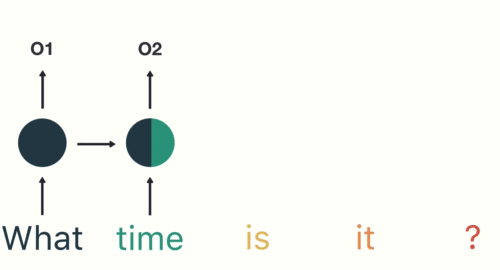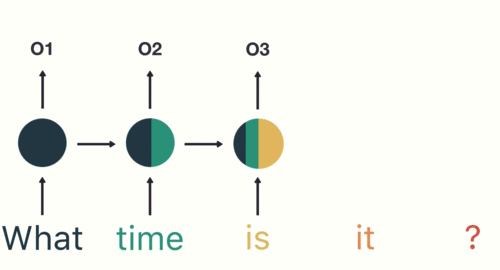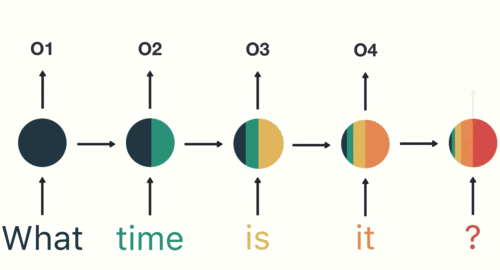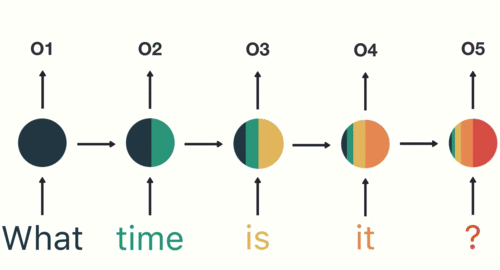
- 第五步: 最后,将最终的隐层输出O5进行处理来解析用户意图.
3 RNN模型的分类
-
这里我们将从两个角度对RNN模型进行分类. 第一个角度是输入和输出的结构, 第二个角度是RNN的内部构造.
-
按照输入和输出的结构进行分类:
- N vs N - RNN:写对联、诗。NER命名实体识别
- N vs 1 - RNN:意图识别、文本分类
- 1 vs N - RNN:文生图、文生视频
- N vs M - RNN:作词
-
按照RNN的内部构造进行分类:
- 传统RNN
- LSTM
- Bi-LSTM
- GRU
- Bi-GRU
-
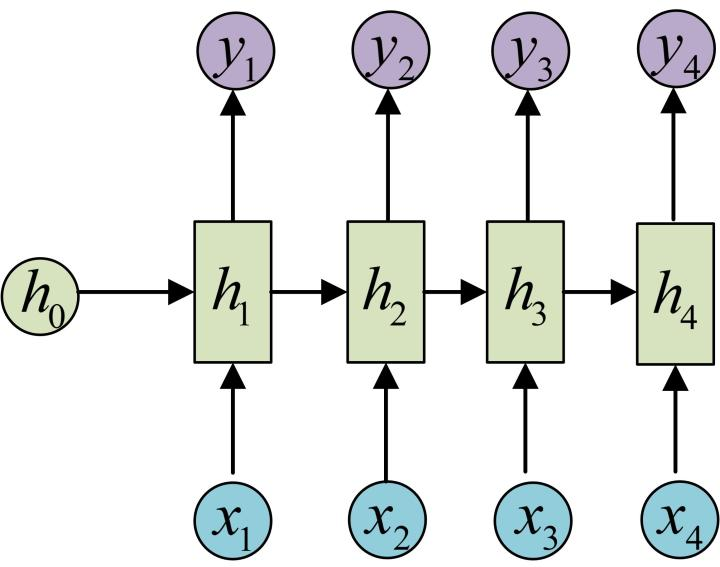
N vs N - RNN:
- 它是RNN最基础的结构形式, 最大的特点就是: 输入和输出序列是等长的. 由于这个限制的存在, 使其适用范围比较小, 可用于生成等长度的合辙诗句.
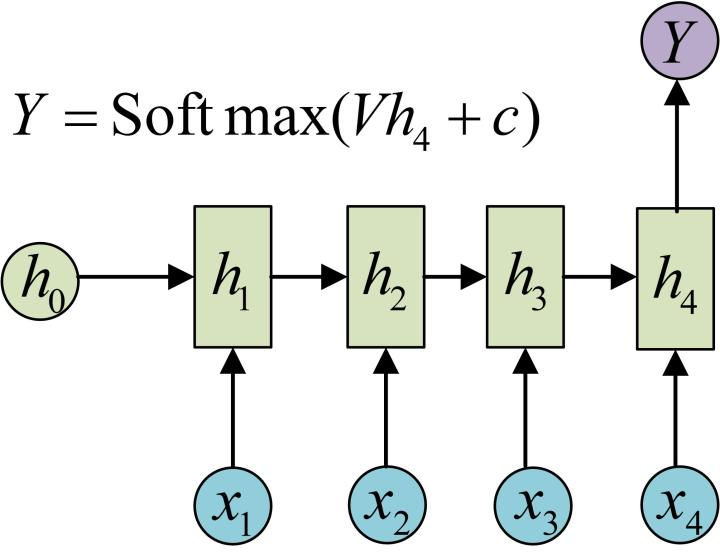
- N vs 1 - RNN:
- 有时候我们要处理的问题输入是一个序列,而要求输出是一个单独的值而不是序列,应该怎样建模呢?我们只要在最后一个隐层输出h上进行线性变换就可以了,大部分情况下,为了更好的明确结果, 还要使用sigmoid或者softmax进行处理. 这种结构经常被应用在文本分类问题上.
- 1 vs N - RNN:
- 如果输入不是序列而输出为序列的情况怎么处理呢?我们最常采用的一种方式就是使该输入作用于每次的输出之上. 这种结构可用于将图片生成文字任务等.
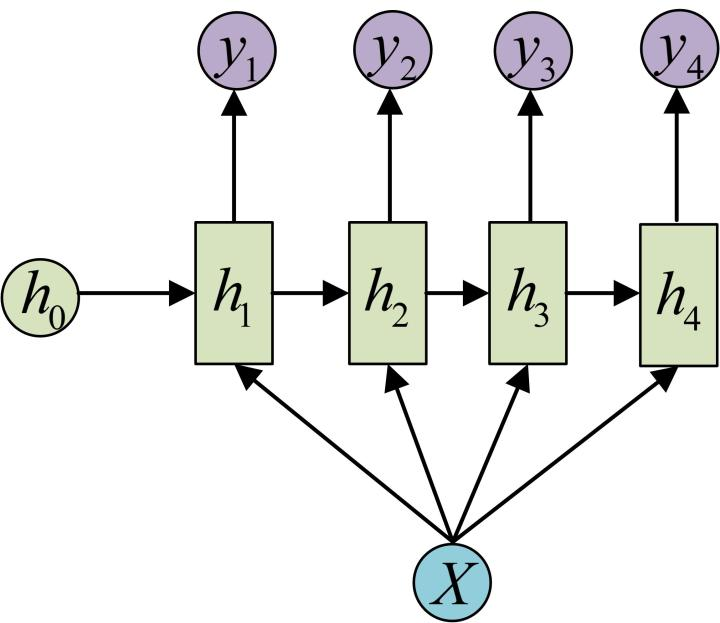
- N vs M - RNN:
- 这是一种不限输入输出长度的RNN结构, 它由编码器和解码器两部分组成, 两者的内部结构都是某类RNN, 它也被称为seq2seq架构. 输入数据首先通过编码器, 最终输出一个隐含变量c, 之后最常用的做法是使用这个隐含变量c作用在解码器进行解码的每一步上, 以保证输入信息被有效利用.
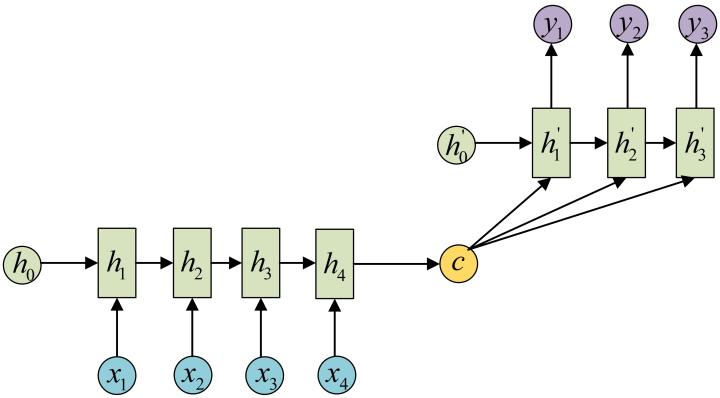
作词、翻译、阅读理解、文本摘要
中间语义张量C(专属信息包)
-
seq2seq架构最早被提出应用于机器翻译, 因为其输入输出不受限制,如今也是应用最广的RNN模型结构. 在机器翻译, 阅读理解, 文本摘要等众多领域都进行了非常多的应用实践.
-
关于RNN的内部构造进行分类的内容我们将在后面使用单独的小节详细讲解.
4 小结
-
学习了什么是RNN模型:
- RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出.
-
RNN的循环机制使模型隐层上一时间步产生的结果, 能够作为当下时间步输入的一部分(当下时间步的输入除了正常的输入外还包括上一步的隐层输出)对当下时间步的输出产生影响.
-
学习了RNN模型的作用:
- 因为RNN结构能够很好利用序列之间的关系, 因此针对自然界具有连续性的输入序列, 如人类的语言, 语音等进行很好的处理, 广泛应用于NLP领域的各项任务, 如文本分类, 情感分析, 意图识别, 机器翻译等.
-
以一个用户意图识别的例子对RNN的运行过程进行简单的分析:
- 第一步: 用户输入了"What time is it ?", 我们首先需要对它进行基本的分词, 因为RNN是按照顺序工作的, 每次只接收一个单词进行处理.
- 第二步: 首先将单词"What"输送给RNN, 它将产生一个输出O1.
- 第三步: 继续将单词"time"输送给RNN, 但此时RNN不仅仅利用"time"来产生输出O2, 还会使用来自上一层隐层输出O1作为输入信息.
- 第四步: 重复这样的步骤, 直到处理完所有的单词.
- 第五步: 最后,将最终的隐层输出O5进行处理来解析用户意图.
-
学习了RNN模型的分类:
- 这里我们将从两个角度对RNN模型进行分类. 第一个角度是输入和输出的结构, 第二个角度是RNN的内部构造.
-
按照输入和输出的结构进行分类:
- N vs N - RNN
- N vs 1 - RNN
- 1 vs N - RNN
- N vs M - RNN
-
N vs N - RNN:
- 它是RNN最基础的结构形式, 最大的特点就是: 输入和输出序列是等长的. 由于这个限制的存在, 使其适用范围比较小, 可用于生成等长度的合辙诗句.
-
N vs 1 - RNN:
- 有时候我们要处理的问题输入是一个序列,而要求输出是一个单独的值而不是序列,应该怎样建模呢?我们只要在最后一个隐层输出h上进行线性变换就可以了,大部分情况下,为了更好的明确结果, 还要使用sigmoid或者softmax进行处理. 这种结构经常被应用在文本分类问题上.
-
1 vs N - RNN:
- 如果输入不是序列而输出为序列的情况怎么处理呢?我们最常采用的一种方式就是使该输入作用于每次的输出之上. 这种结构可用于将图片生成文字任务等.
-
N vs M - RNN:
- 这是一种不限输入输出长度的RNN结构, 它由编码器和解码器两部分组成, 两者的内部结构都是某类RNN, 它也被称为seq2seq架构. 输入数据首先通过编码器, 最终输出一个隐含变量c, 之后最常用的做法是使用这个隐含变量c作用在解码器进行解码的每一步上, 以保证输入信息被有效利用.
- seq2seq架构最早被提出应用于机器翻译, 因为其输入输出不受限制,如今也是应用最广的RNN模型结构. 在机器翻译, 阅读理解, 文本摘要等众多领域都进行了非常多的应用实践.
-
按照RNN的内部构造进行分类:
- 传统RNN
- LSTM
- Bi-LSTM
- GRU
- Bi-GRU
-
关于RNN的内部构造进行分类的内容我们将在后面使用单独的小节详细讲解.
2.传统RNN模型
output 记录的是 最后一层 在每个时间步的隐藏状态。
hidden 记录的是 每一层 在最后一个时间步的隐藏状态。
学习目标
- 了解传统RNN的内部结构及计算公式.
- 掌握Pytorch中传统RNN工具的使用.
- 了解传统RNN的优势与缺点.
1 传统RNN的内部结构图
1.1 RNN结构分析
本次时间步的隐藏状态 本次时间步的隐藏状态 本次时间步的隐藏状态
第一个时间步 第二个时间步 第三个时间步
(第一次循环)
本次输入数据 本次输入数据 本次输入数据
- 结构解释图:

神经网络层 点到点的运算 数据 张量数据合并 数据复制
(激活函数) (乘法、加法) 传输 cat/concat
-
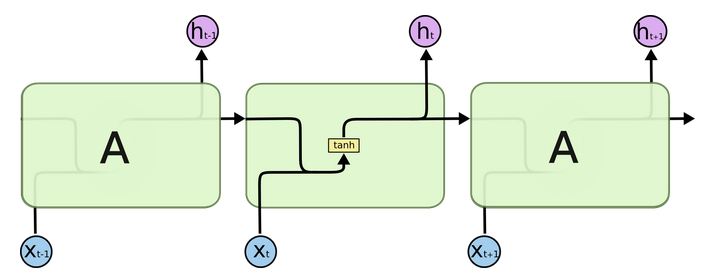
内部结构分析:
- 我们把目光集中在中间的方块部分, 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会"融合"到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量x(t), h(t-1), 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
-
内部结构过程演示:
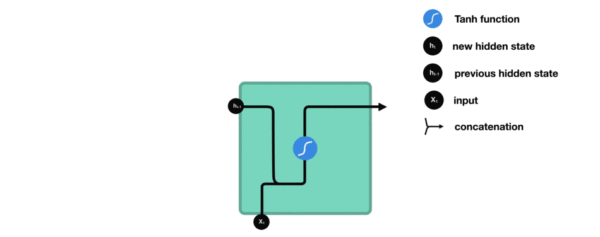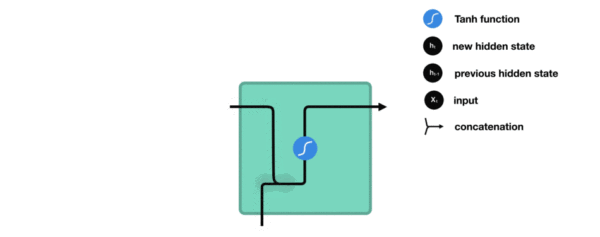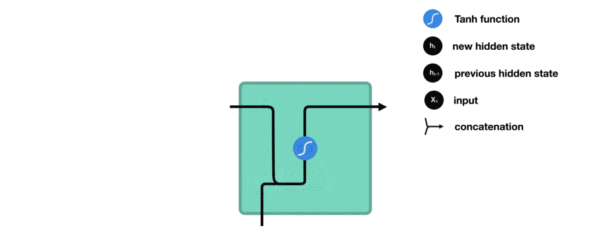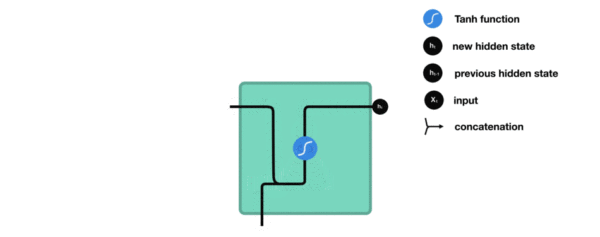
- 根据结构分析得出内部计算公式:
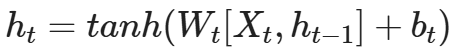
循环神经网络的预测结果
= Wh^t+b
= 也就是对更新后的当前时间步的隐藏状态经过线性变换得到本次的预测结果
第一个时间步初始隐藏状态一般使用全零初始化

-
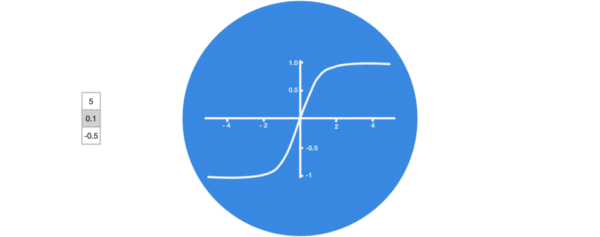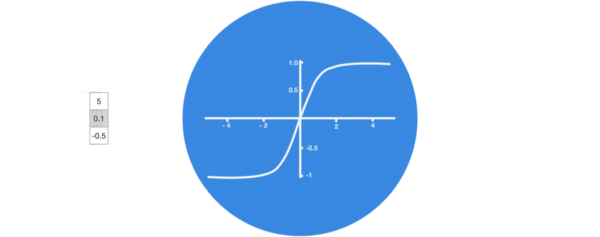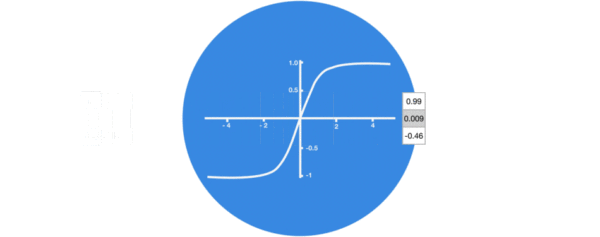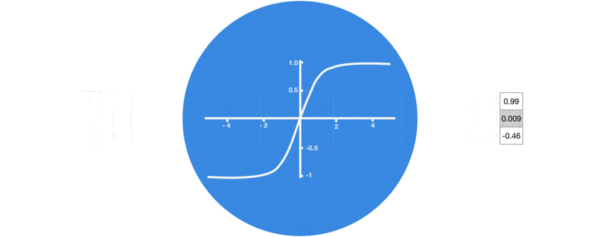
激活函数tanh的作用:
- 用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间.
1.2 使用Pytorch构建RNN模型
-
位置: 在torch.nn工具包之中, 通过torch.nn.RNN可调用
-
nn.RNN使用示例1:
import torch
import torch.nn as nndef dm_rnn_for_base():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 1) #A''' 第一个参数:sequence_length(输入序列的长度) 第二个参数:batch_size(批次的样本数量) 第三个参数:input_size(输入张量的维度) ''' input = torch.randn(1, 3, 5) #B ''' 第一个参数:num_layer * num_directions(层数*网络方向) 第二个参数:batch_size(批次的样本数) 第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数) ''' h0 = torch.randn(1, 3, 6) #C # [1,3,5],[1,3,6] ---> [1,3,6],[1,3,6] output, hn = rnn(input, h0) print('output--->',output.shape, output) print('hn--->',hn.shape, hn) print('rnn模型--->', rnn)程序运行效果如下:
output---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434],
[ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549],
[-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]],
grad_fn=) hn---> torch.Size([1, 3, 6]) tensor([[[ 0.8947, -0.6040, 0.9878, -0.1070, -0.7071, -0.1434],
[ 0.0955, -0.8216, 0.9475, -0.7593, -0.8068, -0.5549],
[-0.1524, 0.7519, -0.1985, 0.0937, 0.2009, -0.0244]]],
grad_fn=) rnn模型---> RNN(5, 6)
-
nn.RNN使用示例2
输入数据长度发生变化
def dm_rnn_for_sequencelen():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 1) #A
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(20, 3, 5) #B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(1, 3, 6) #C# [20,3,5],[1,3,6] --->[20,3,6],[1,3,6] output, hn = rnn(input, h0) # print('output--->', output.shape) print('hn--->', hn.shape) print('rnn模型--->', rnn)程序运行效果如下:
output---> torch.Size([20, 3, 6])
hn---> torch.Size([1, 3, 6])
rnn模型---> RNN(5, 6) -
nn.RNN使用示例3
def dm_run_for_hiddennum():
'''
第一个参数:input_size(输入张量x的维度)
第二个参数:hidden_size(隐藏层的维度, 隐藏层的神经元个数)
第三个参数:num_layer(隐藏层的数量)
'''
rnn = nn.RNN(5, 6, 2) # A 隐藏层个数从1-->2 下面程序需要修改的地方?
'''
第一个参数:sequence_length(输入序列的长度)
第二个参数:batch_size(批次的样本数量)
第三个参数:input_size(输入张量的维度)
'''
input = torch.randn(1, 3, 5) # B
'''
第一个参数:num_layer * num_directions(层数*网络方向)
第二个参数:batch_size(批次的样本数)
第三个参数:hidden_size(隐藏层的维度, 隐藏层神经元的个数)
'''
h0 = torch.randn(2, 3, 6) # Coutput, hn = rnn(input, h0) # print('output-->', output.shape, output) print('hn-->', hn.shape, hn) print('rnn模型--->', rnn) # nn模型---> RNN(5, 6, num_layers=11) # 结论:若只有一个隐藏次 output输出结果等于hn # 结论:如果有2个隐藏层,output的输出结果有2个,hn等于最后一个隐藏层程序运行效果如下:
output--> torch.Size([1, 3, 6]) tensor([[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244],
[ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437],
[ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]],
grad_fn=)
hn--> torch.Size([2, 3, 6]) tensor([[[ 0.4862, 0.6872, -0.0437, -0.7826, -0.7136, -0.5715],
[ 0.8942, 0.4524, -0.1695, -0.5536, -0.4367, -0.3353],
[ 0.5592, 0.0444, -0.8384, -0.5193, 0.7049, -0.0453]],[[ 0.4987, -0.5756, 0.1934, 0.7284, 0.4478, -0.1244], [ 0.6753, 0.5011, -0.7141, 0.4480, 0.7186, 0.5437], [ 0.6260, 0.7600, -0.7384, -0.5080, 0.9054, 0.6011]]], grad_fn=<StackBackward0>)rnn模型---> RNN(5, 6, num_layers=2)
1.3 传统RNN优缺点
1 传统RNN的优势
- 由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
2 传统RNN的缺点
- 传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
3 梯度消失或爆炸介绍
根据反向传播算法和链式法则, 梯度的计算可以简化为以下公式
Dn=σ′(z1)w1⋅σ′(z2)w2⋅⋯⋅σ′(zn)wnDn=σ′(z1)w1⋅σ′(z2)w2⋅⋯⋅σ′(zn)wn
-
其中sigmoid的导数值域是固定的, 在0, 0.25之间, 而一旦公式中的w也小于1, 那么通过这样的公式连乘后, 最终的梯度就会变得非常非常小, 这种现象称作梯度消失. 反之, 如果我们人为的增大w的值, 使其大于1, 那么连乘够就可能造成梯度过大, 称作梯度爆炸.
-
梯度消失或爆炸的危害:
- 如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败; 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值).
2 小结
-
学习了传统RNN的结构并进行了分析;
- 它的输入有两部分, 分别是h(t-1)以及x(t), 代表上一时间步的隐层输出, 以及此时间步的输入, 它们进入RNN结构体后, 会"融合"到一起, 这种融合我们根据结构解释可知, 是将二者进行拼接, 形成新的张量x(t), h(t-1), 之后这个新的张量将通过一个全连接层(线性层), 该层使用tanh作为激活函数, 最终得到该时间步的输出h(t), 它将作为下一个时间步的输入和x(t+1)一起进入结构体. 以此类推.
-
根据结构分析得出了传统RNN的计算公式.
-
学习了激活函数tanh的作用:
- 用于帮助调节流经网络的值, tanh函数将值压缩在-1和1之间.
-
学习了Pytorch中传统RNN工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.RNN可调用.
-
nn.RNN类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- nonlinearity: 激活函数的选择, 默认是tanh.
-
nn.RNN类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
-
实现了nn.RNN的使用示例, 获得RNN的真实返回结果样式.
-
学习了传统RNN的优势:
- 由于内部结构简单, 对计算资源要求低, 相比之后我们要学习的RNN变体:LSTM和GRU模型参数总量少了很多, 在短序列任务上性能和效果都表现优异.
-
学习了传统RNN的缺点:
- 传统RNN在解决长序列之间的关联时, 通过实践,证明经典RNN表现很差, 原因是在进行反向传播的时候, 过长的序列导致梯度的计算异常, 发生梯度消失或爆炸.
-
学习了什么是梯度消失或爆炸:
- 根据反向传播算法和链式法则, 得到梯度的计算的简化公式:其中sigmoid的导数值域是固定的, 在0, 0.25之间, 而一旦公式中的w也小于1, 那么通过这样的公式连乘后, 最终的梯度就会变得非常非常小, 这种现象称作梯度消失. 反之, 如果我们人为的增大w的值, 使其大于1, 那么连乘够就可能造成梯度过大, 称作梯度爆炸.
-
梯度消失或爆炸的危害:
- 如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败; 梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值).
python
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 创建RNN循环网络层
"""
参数解释:
input_size:输入数据的向量维度
hidden_size:隐藏层隐藏状态的向量维度
num_layers:隐藏层的层数
bidirectional:是否是双向的网络层。False表示单向,True表示双向
"""
rnn = nn.RNN(input_size=4, hidden_size=5, num_layers=1, bidirectional=True)
# 2- 准备数据
# 2.1- 本次时间步输入的数据
input = torch.randn(size=(6, 3, 4))
# 2.2- 上一个时间步的隐藏状态。第一个时间步的隐藏状态一般用全零初始化
h0 = torch.zeros(size=(2, 3, 5))
# 3- 调用RNN
"""
参数解释:
输入参数:
input:本次时间步输入的数据,张量形状是:[seq_len每条句子中词的个数,batch_size每个批次中句子的条数,input_size输入数据的向量维度]
h0:上一个时间步的隐藏状态,张量形状是:[num_layers隐藏层的层数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
第一个时间步的隐藏状态一般用全零初始化
返回结果:
output:本次时间步的预测结果,张量形状是:[seq_len每条句子中词的个数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
hn:本次时间步的隐藏状态,张量形状是:[num_layers隐藏层的层数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
"""
output, hn = rnn(input, h0)
# 4- 查看结果
print(f"output预测结果_形状:{output.shape}") # [6,3,5]
print(f"hn更新后的隐藏_形状:{hn.shape}") # [2,3,5]
print(f"output预测结果_内容:{output}")
print(f"hn更新后的隐藏_内容:{hn}")3.LSTM模型
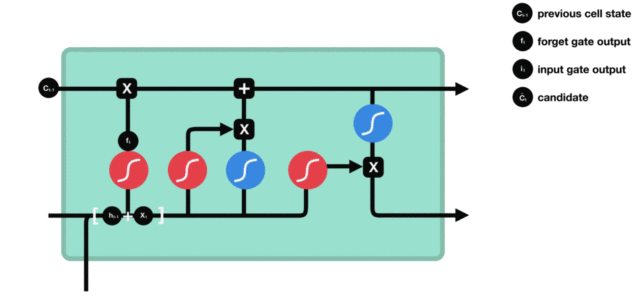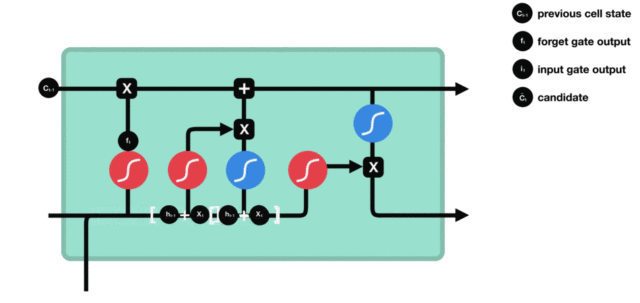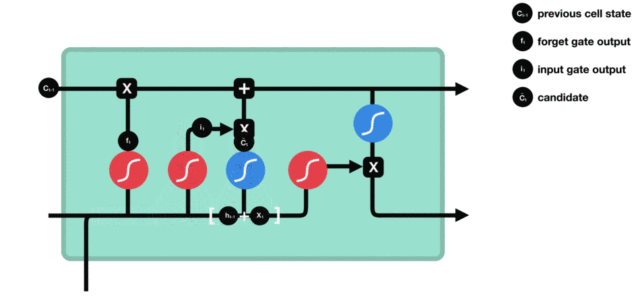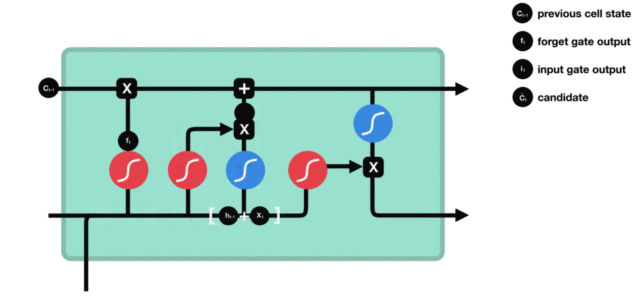
LSTM的组成核心:
三个门+细胞状态
遗忘门、输入门、输出门,控制信息的留、进、出
细胞状态专门存储重要的信息,相当于是一个日记本
整体流程总结:
遗忘门:筛选旧记忆(丟弃不重要的信息)->更新细胞状态
输入门:筛选新记忆(过滤出重要的信息)->添加到细胞状态
细胞状态:专门存储重要的信息
输出门:决定要将细胞状态中哪些重要信息传递给到下一个时间步
⭐️RNN:最基础的的神经元结构,但是效果一般⭐️LSTM模型:所以产生了功能强大的LSTM模型,但是过于复杂
⭐️GRU模型:所以产生了GRU模型,对LSTM简化后
学习目标
- 了解LSTM内部结构及计算公式.
- 掌握Pytorch中LSTM工具的使用.
- 了解LSTM的优势与缺点.
1 LSTM介绍
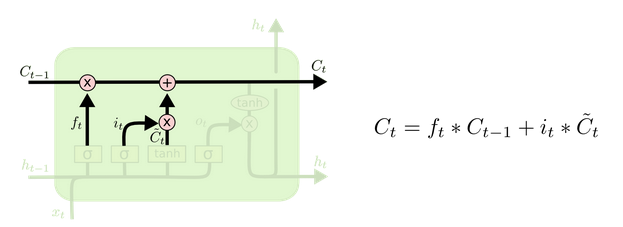
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:
- 遗忘门
- 输入门
- 细胞状态
- 输出门
2 LSTM的内部结构图
2.1 LSTM结构分析
输入门--------------输出门--------------遗忘门--------------细胞状态
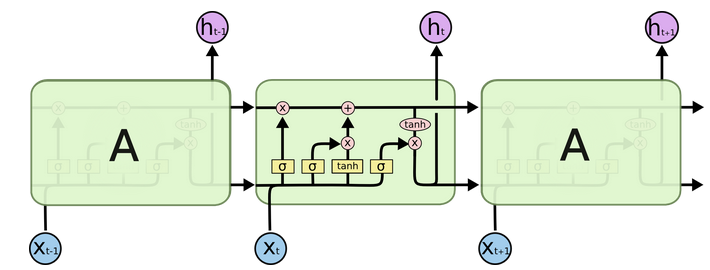
- 结构解释图:

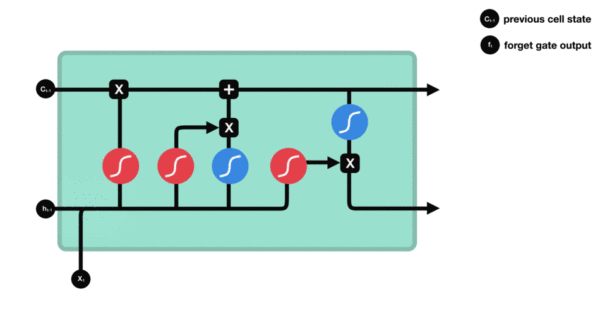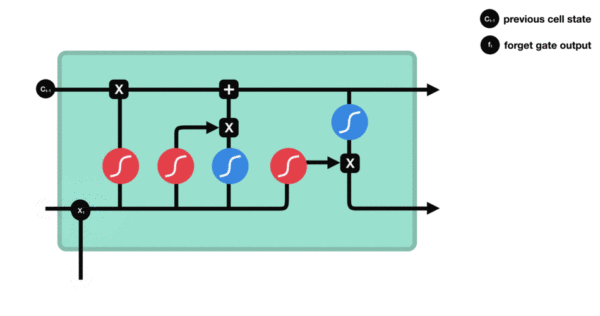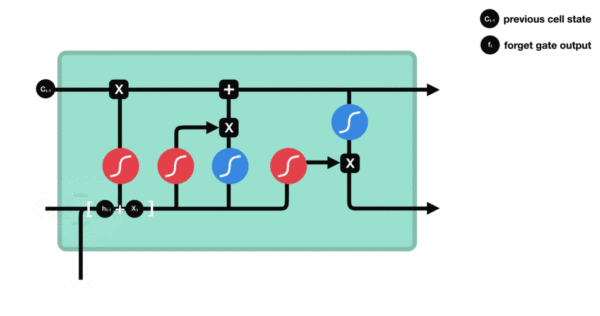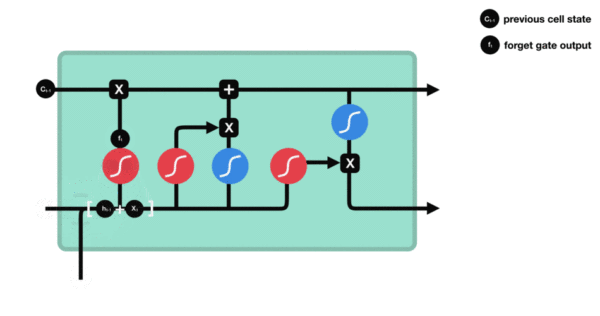
- 遗忘门部分结构图与计算公式:
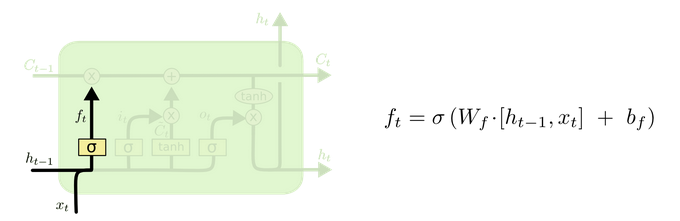
-
遗忘门结构分析:
- 与传统RNN的内部结构计算非常相似, 首先将当前时间步输入x(t)与上一个时间步隐含状态h(t-1)拼接, 得到x(t), h(t-1), 然后通过一个全连接层做变换, 最后通过sigmoid函数进行激活得到f(t), 我们可以将f(t)看作是门值, 好比一扇门开合的大小程度, 门值都将作用在通过该扇门的张量, 遗忘门门值将作用的上一层的细胞状态上, 代表遗忘过去的多少信息, 又因为遗忘门门值是由x(t), h(t-1)计算得来的, 因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态h(t-1)来决定遗忘多少上一层的细胞状态所携带的过往信息.
-
遗忘门内部结构过程演示:
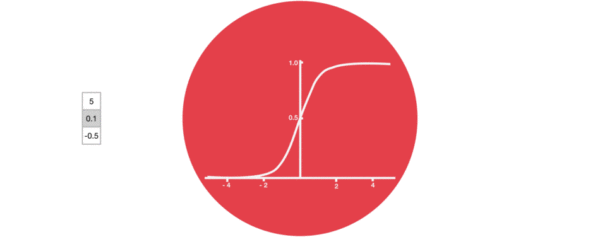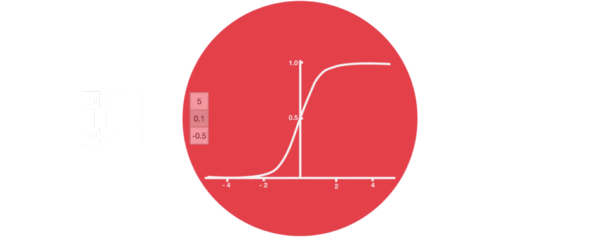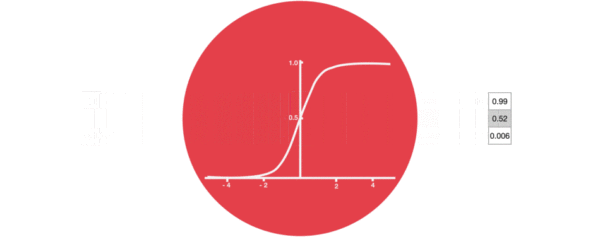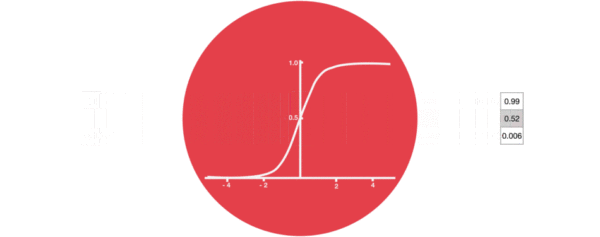
- 激活函数sigmiod的作用:
- 用于帮助调节流经网络的值, sigmoid函数将值压缩在0和1之间.
- 输入门部分结构图与计算公式:
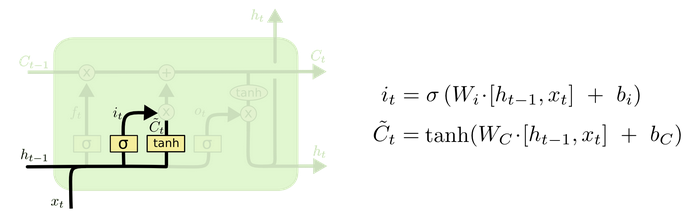
-
输入门结构分析:
- 我们看到输入门的计算公式有两个, 第一个就是产生输入门门值的公式, 它和遗忘门公式几乎相同, 区别只是在于它们之后要作用的目标上. 这个公式意味着输入信息有多少需要进行过滤. 输入门的第二个公式是与传统RNN的内部结构计算相同. 对于LSTM来讲, 它得到的是当前的细胞状态, 而不是像经典RNN一样得到的是隐含状态.
-
输入门内部结构过程演示:
- 细胞状态更新图与计算公式:
-
细胞状态更新分析:
- 细胞更新的结构与计算公式非常容易理解, 这里没有全连接层, 只是将刚刚得到的遗忘门门值与上一个时间步得到的C(t-1)相乘, 再加上输入门门值与当前时间步得到的未更新C(t)相乘的结果. 最终得到更新后的C(t)作为下一个时间步输入的一部分. 整个细胞状态更新过程就是对遗忘门和输入门的应用.
-
细胞状态更新过程演示:
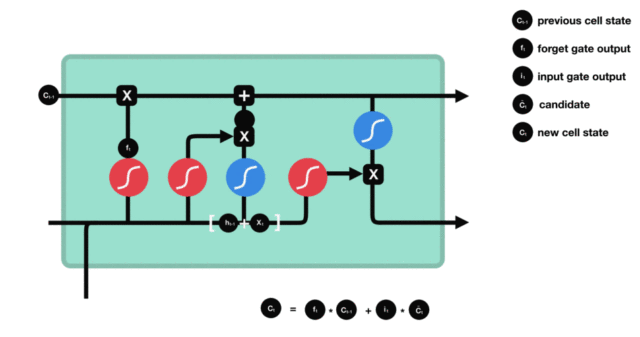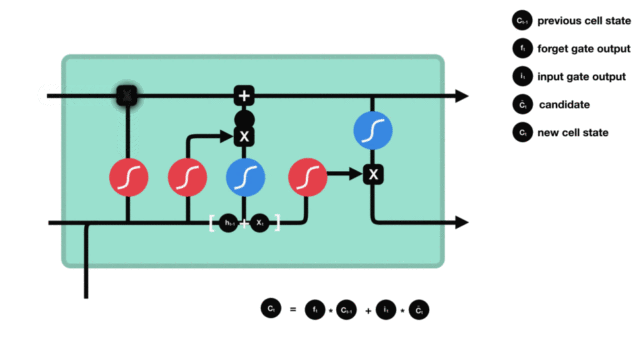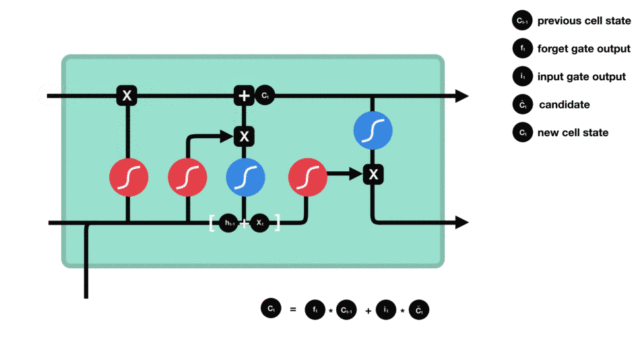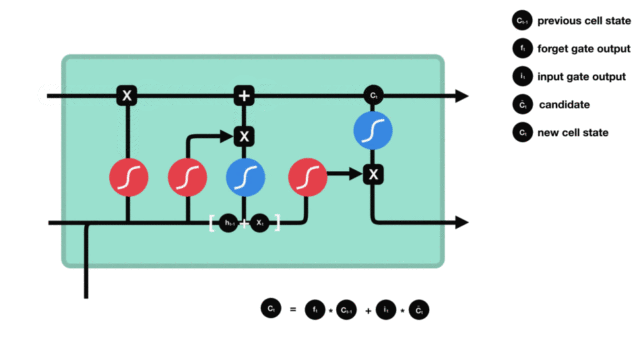
- 输出门部分结构图与计算公式:
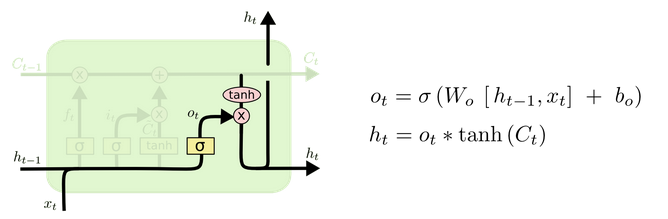
-
输出门结构分析:
- 输出门部分的公式也是两个, 第一个即是计算输出门的门值, 它和遗忘门,输入门计算方式相同. 第二个即是使用这个门值产生隐含状态h(t), 他将作用在更新后的细胞状态C(t)上, 并做tanh激活, 最终得到h(t)作为下一时间步输入的一部分. 整个输出门的过程, 就是为了产生隐含状态h(t).
-
输出门内部结构过程演示:
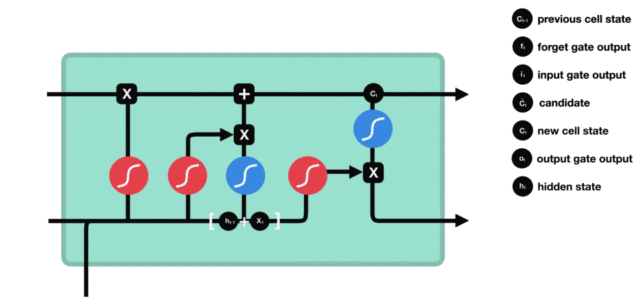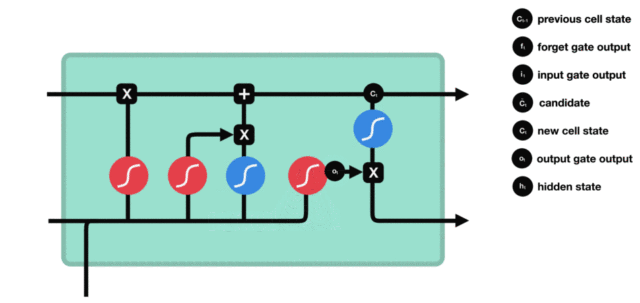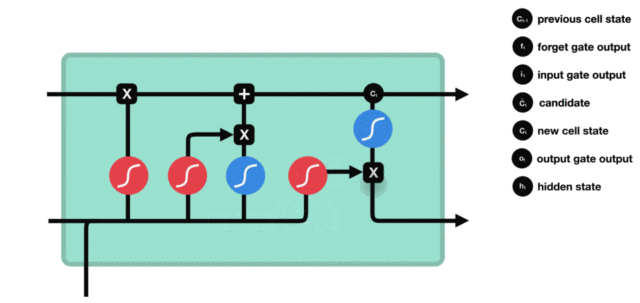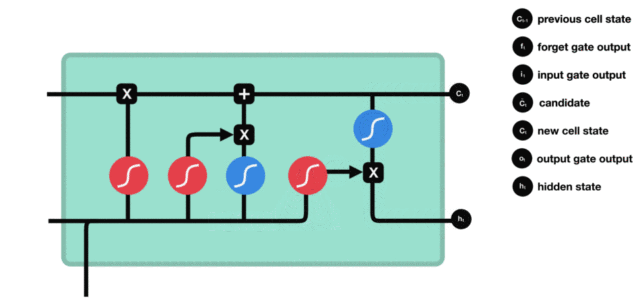
2.2 Bi-LSTM介绍
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
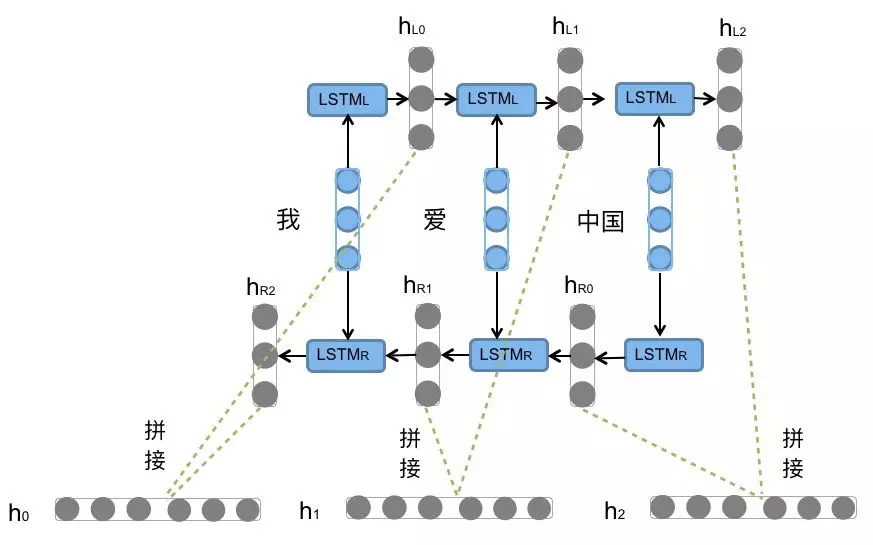
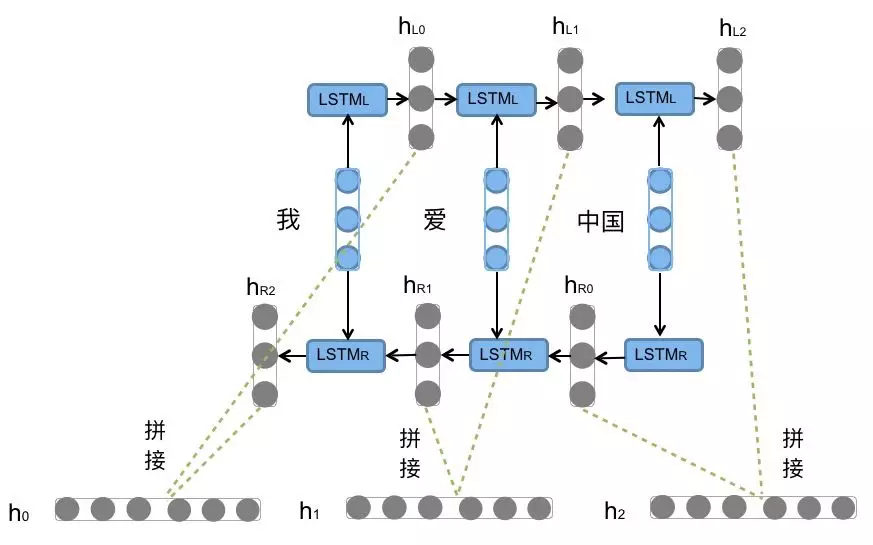
- Bi-LSTM结构分析:
- 我们看到图中对"我爱中国"这句话或者叫这个输入序列, 进行了从左到右和从右到左两次LSTM处理, 将得到的结果张量进行了拼接作为最终输出. 这种结构能够捕捉语言语法中一些特定的前置或后置特征, 增强语义关联,但是模型参数和计算复杂度也随之增加了一倍, 一般需要对语料和计算资源进行评估后决定是否使用该结构.
2.3 使用Pytorch构建LSTM模型
-
位置: 在torch.nn工具包之中, 通过torch.nn.LSTM可调用.
-
nn.LSTM类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- bidirectional: 是否选择使用双向LSTM, 如果为True, 则使用; 默认不使用.
-
nn.LSTM类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
- c0: 初始化的细胞状态张量c.
-
nn.LSTM使用示例:
python
# 定义LSTM的参数含义: (input_size, hidden_size, num_layers)
# 定义输入张量的参数含义: (sequence_length, batch_size, input_size)
# 定义隐藏层初始张量和细胞初始状态张量的参数含义:
# (num_layers * num_directions, batch_size, hidden_size)
>>> import torch.nn as nn
>>> import torch
>>> rnn = nn.LSTM(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> c0 = torch.randn(2, 3, 6)
>>> output, (hn, cn) = rnn(input, (h0, c0))
>>> output
tensor([[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.4647, -0.2364, 0.0645, -0.3996, -0.0500, -0.0152],
[ 0.3852, 0.0704, 0.2103, -0.2524, 0.0243, 0.0477],
[ 0.2571, 0.0608, 0.2322, 0.1815, -0.0513, -0.0291]],
[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> cn
tensor([[[ 0.8083, -0.5500, 0.1009, -0.5806, -0.0668, -0.1161],
[ 0.7438, 0.0957, 0.5509, -0.7725, 0.0824, 0.0626],
[ 0.3131, 0.0920, 0.8359, 0.9187, -0.4826, -0.0717]],
[[ 0.1240, -0.0526, 0.3035, 0.1099, 0.5915, 0.0828],
[ 0.0203, 0.8367, 0.9832, -0.4454, 0.3917, -0.1983],
[-0.2976, 0.7764, -0.0074, -0.1965, -0.1343, -0.6683]]],
grad_fn=<StackBackward>)2.4 LSTM优缺点
-
LSTM优势:
LSTM的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸, 虽然并不能杜绝这种现象, 但在更长的序列问题上表现优于传统RNN.
-
LSTM缺点:
由于内部结构相对较复杂, 因此训练效率在同等算力下较传统RNN低很多.
3 小结
-
LSTM(Long Short-Term Memory)也称长短时记忆结构, 它是传统RNN的变体, 与经典RNN相比能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时LSTM的结构更复杂, 它的核心结构可以分为四个部分去解析:
- 遗忘门
- 输入门
- 输出门
- 细胞状态
-
遗忘门结构分析:
与传统RNN的内部结构计算非常相似, 首先将当前时间步输入x(t)与上一个时间步隐含状态h(t-1)拼接, 得到x(t), h(t-1), 然后通过一个全连接层做变换, 最后通过sigmoid函数进行激活得到f(t), 我们可以将f(t)看作是门值, 好比一扇门开合的大小程度, 门值都将作用在通过该扇门的张量, 遗忘门门值将作用的上一层的细胞状态上, 代表遗忘过去的多少信息, 又因为遗忘门门值是由x(t), h(t-1)计算得来的, 因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态h(t-1)来决定遗忘多少上一层的细胞状态所携带的过往信息.
-
输入门结构分析:
我们看到输入门的计算公式有两个, 第一个就是产生输入门门值的公式, 它和遗忘门公式几乎相同, 区别只是在于它们之后要作用的目标上. 这个公式意味着输入信息有多少需要进行过滤. 输入门的第二个公式是与传统RNN的内部结构计算相同. 对于LSTM来讲, 它得到的是当前的细胞状态, 而不是像经典RNN一样得到的是隐含状态.
-
细胞状态更新分析:
细胞更新的结构与计算公式非常容易理解, 这里没有全连接层, 只是将刚刚得到的遗忘门门值与上一个时间步得到的C(t-1)相乘, 再加上输入门门值与当前时间步得到的未更新C(t)相乘的结果. 最终得到更新后的C(t)作为下一个时间步输入的一部分. 整个细胞状态更新过程就是对遗忘门和输入门的应用.
-
输出门结构分析:
输出门部分的公式也是两个, 第一个即是计算输出门的门值, 它和遗忘门,输入门计算方式相同. 第二个即是使用这个门值产生隐含状态h(t), 他将作用在更新后的细胞状态C(t)上, 并做tanh激活, 最终得到h(t)作为下一时间步输入的一部分. 整个输出门的过程, 就是为了产生隐含状态h(t).
-
什么是Bi-LSTM ?
Bi-LSTM即双向LSTM, 它没有改变LSTM本身任何的内部结构, 只是将LSTM应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出.
-
Pytorch中LSTM工具的使用:
位置: 在torch.nn工具包之中, 通过torch.nn.LSTM可调用.
-
LSTM优势:
LSTM的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸, 虽然并不能杜绝这种现象, 但在更长的序列问题上表现优于传统RNN.
-
LSTM缺点:
由于内部结构相对较复杂, 因此训练效率在同等算力下较传统RNN低很多.
python
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 创建LSTM循环网络层
"""
参数解释:
input_size:输入数据的向量维度
hidden_size:隐藏层隐藏状态的向量维度
num_layers:隐藏层的层数
bidirectional:是否是双向的网络层。False表示单向,True表示双向
"""
lstm = nn.LSTM(input_size=4, hidden_size=5, num_layers=1, bidirectional=True)
# 2- 准备数据
# 2.1- 本次时间步输入的数据
input = torch.randn(size=(6, 3, 4))
# 2.2- 上一个时间步的隐藏状态。第一个时间步的隐藏状态一般用全零初始化
h0 = torch.zeros(size=(2, 3, 5))
# 2.3- 初始的细胞状态,一般用全零初始化
c0 = torch.zeros(size=(2, 3, 5))
# 3- 调用LSTM
"""
参数解释:
输入参数:
input:本次时间步输入的数据,张量形状是:[seq_len每条句子中词的个数,batch_size每个批次中句子的条数,input_size输入数据的向量维度]
h0:上一个时间步的隐藏状态,张量形状是:[num_layers隐藏层的层数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
第一个时间步的隐藏状态一般用全零初始化
c0:上一个时间步的细胞状态,张量形状是:[num_layers隐藏层的层数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
初始的细胞状态一般用全零初始化
注意:h0和c0需要使用元组包起来
返回结果:
output:本次时间步的预测结果,张量形状是:[seq_len每条句子中词的个数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
hn:本次时间步的隐藏状态,张量形状是:[num_layers隐藏层的层数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
c:更新后的细胞状态,张量形状是:[num_layers隐藏层的层数,batch_size每个批次中句子的条数,hidden_size隐藏层隐藏状态的向量维度]
注意:h0和c需要使用元组包起来
"""
output, (hn, c) = lstm(input, (h0, c0))
# 4- 查看结果
print(f"output预测结果_形状:{output.shape}") # [6,3,5]
print(f"hn更新后的隐藏_形状:{hn.shape}") # [2,3,5]
print(f"c更新后的细胞状态_形状:{c.shape}")
print(f"output预测结果_内容:{output}")
print(f"hn更新后的隐藏_内容:{hn}")
print(f"c更新后的细胞状态_内容:{c}") # 不用关心内部的值4.RGU模型
学习目标
- 了解GRU内部结构及计算公式.
- 掌握Pytorch中GRU工具的使用.
- 了解GRU的优势与缺点.
1 GRU介绍
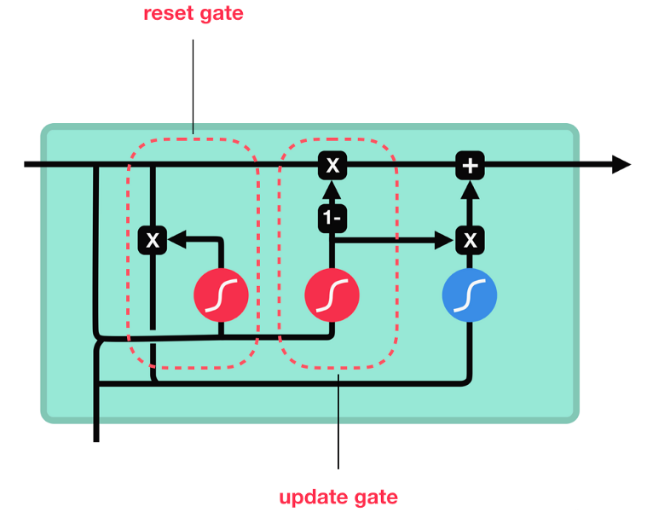
GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:
- 更新门
- 重置门
2 GRU的内部结构图
2.1 GRU结构分析
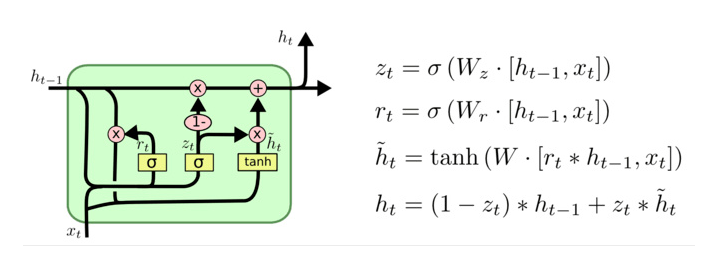
- 结构解释图:

- GRU的更新门和重置门结构图:
-
内部结构分析:
- 和之前分析过的LSTM中的门控一样, 首先计算更新门和重置门的门值, 分别是z(t)和r(t), 计算方法就是使用X(t)与h(t-1)拼接进行线性变换, 再经过sigmoid激活. 之后重置门门值作用在了h(t-1)上, 代表控制上一时间步传来的信息有多少可以被利用. 接着就是使用这个重置后的h(t-1)进行基本的RNN计算, 即与x(t)拼接进行线性变化, 经过tanh激活, 得到新的h(t). 最后更新门的门值会作用在新的h(t),而1-门值会作用在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过程意味着更新门有能力保留之前的结果, 当门值趋于1时, 输出就是新的h(t), 而当门值趋于0时, 输出就是上一时间步的h(t-1).
2.2 Bi-GRU介绍
Bi-GRU与Bi-LSTM的逻辑相同, 都是不改变其内部结构, 而是将模型应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出. 具体参见上小节中的Bi-LSTM.
2.3 使用Pytorch构建GRU模型
-
位置: 在torch.nn工具包之中, 通过torch.nn.GRU可调用.
-
nn.GRU类初始化主要参数解释:
- input_size: 输入张量x中特征维度的大小.
- hidden_size: 隐层张量h中特征维度的大小.
- num_layers: 隐含层的数量.
- bidirectional: 是否选择使用双向LSTM, 如果为True, 则使用; 默认不使用.
-
nn.GRU类实例化对象主要参数解释:
- input: 输入张量x.
- h0: 初始化的隐层张量h.
- input: 输入张量x.
-
nn.GRU使用示例:
import torch
import torch.nn as nn
rnn = nn.GRU(5, 6, 2)
input = torch.randn(1, 3, 5)
h0 = torch.randn(2, 3, 6)
output, hn = rnn(input, h0)
output
tensor([[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=)
hn
tensor([[[ 0.6578, -0.4226, -0.2129, -0.3785, 0.5070, 0.4338],
[-0.5072, 0.5948, 0.8083, 0.4618, 0.1629, -0.1591],
[ 0.2430, -0.4981, 0.3846, -0.4252, 0.7191, 0.5420]],[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460], [-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173], [-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]], grad_fn=<StackBackward>)
2.4 GRU优缺点
-
GRU的优势:
- GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
-
GRU的缺点:
- GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算, 这在数据量和模型体量逐步增大的未来, 是RNN发展的关键瓶颈.
3 小结
-
GRU(Gated Recurrent Unit)也称门控循环单元结构, 它也是传统RNN的变体, 同LSTM一样能够有效捕捉长序列之间的语义关联, 缓解梯度消失或爆炸现象. 同时它的结构和计算要比LSTM更简单, 它的核心结构可以分为两个部分去解析:
- 更新门
- 重置门
-
内部结构分析:
- 和之前分析过的LSTM中的门控一样, 首先计算更新门和重置门的门值, 分别是z(t)和r(t), 计算方法就是使用X(t)与h(t-1)拼接进行线性变换, 再经过sigmoid激活. 之后重置门门值作用在了h(t-1)上, 代表控制上一时间步传来的信息有多少可以被利用. 接着就是使用这个重置后的h(t-1)进行基本的RNN计算, 即与x(t)拼接进行线性变化, 经过tanh激活, 得到新的h(t). 最后更新门的门值会作用在新的h(t),而1-门值会作用在h(t-1)上, 随后将两者的结果相加, 得到最终的隐含状态输出h(t), 这个过程意味着更新门有能力保留之前的结果, 当门值趋于1时, 输出就是新的h(t), 而当门值趋于0时, 输出就是上一时间步的h(t-1).
-
Bi-GRU与Bi-LSTM的逻辑相同, 都是不改变其内部结构, 而是将模型应用两次且方向不同, 再将两次得到的LSTM结果进行拼接作为最终输出. 具体参见上小节中的Bi-LSTM.
-
Pytorch中GRU工具的使用:
- 位置: 在torch.nn工具包之中, 通过torch.nn.GRU可调用.
-
GRU的优势:
- GRU和LSTM作用相同, 在捕捉长序列语义关联时, 能有效抑制梯度消失或爆炸, 效果都优于传统RNN且计算复杂度相比LSTM要小.
-
GRU的缺点:
- GRU仍然不能完全解决梯度消失问题, 同时其作用RNN的变体, 有着RNN结构本身的一大弊端, 即不可并行计算, 这在数据量和模型体量逐步增大的未来, 是RNN发展的关键瓶颈.
5.注意力机制介绍1
学习目标
- 了解什么是注意力机制的由来
- 理解什么是注意力机制
- 了解常见的注意力类型以及作业
1. 注意力机制的由来,解决了什么问题?
- 在认识注意力之前,我们先简单了解下机器翻译任务:
例子:seq2seq(Sequence to Sequence))架构翻译任务
-
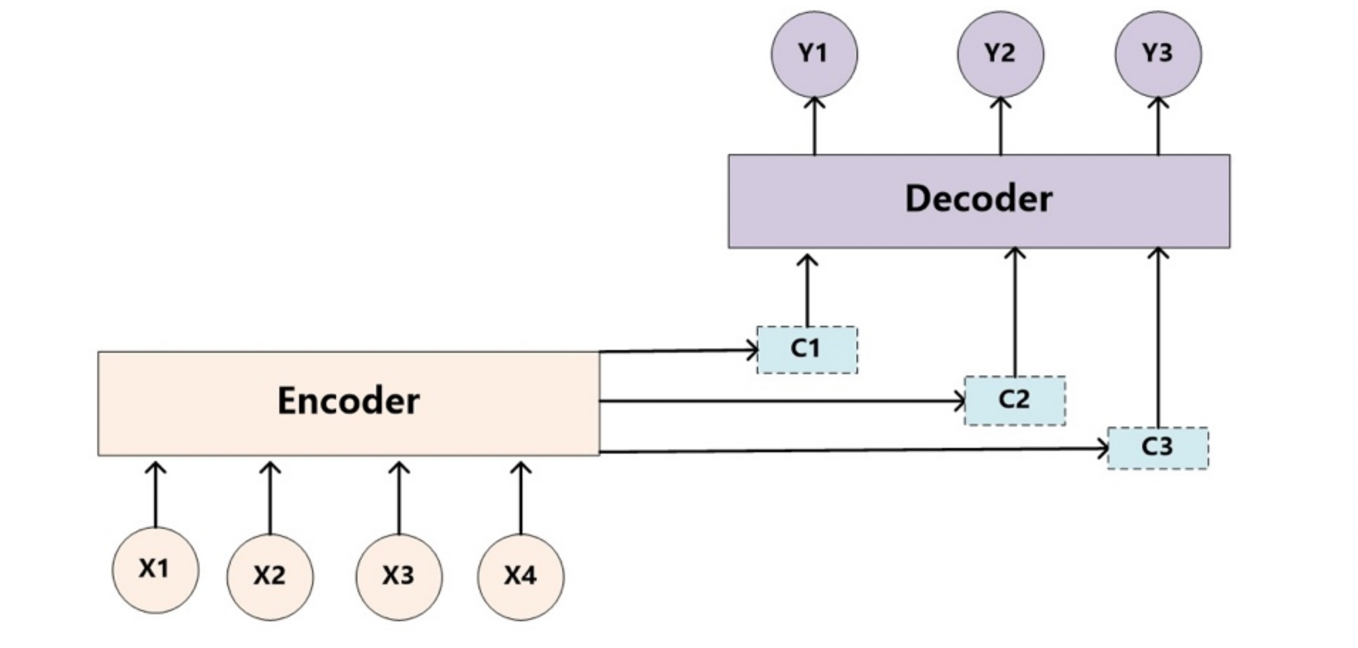
seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。
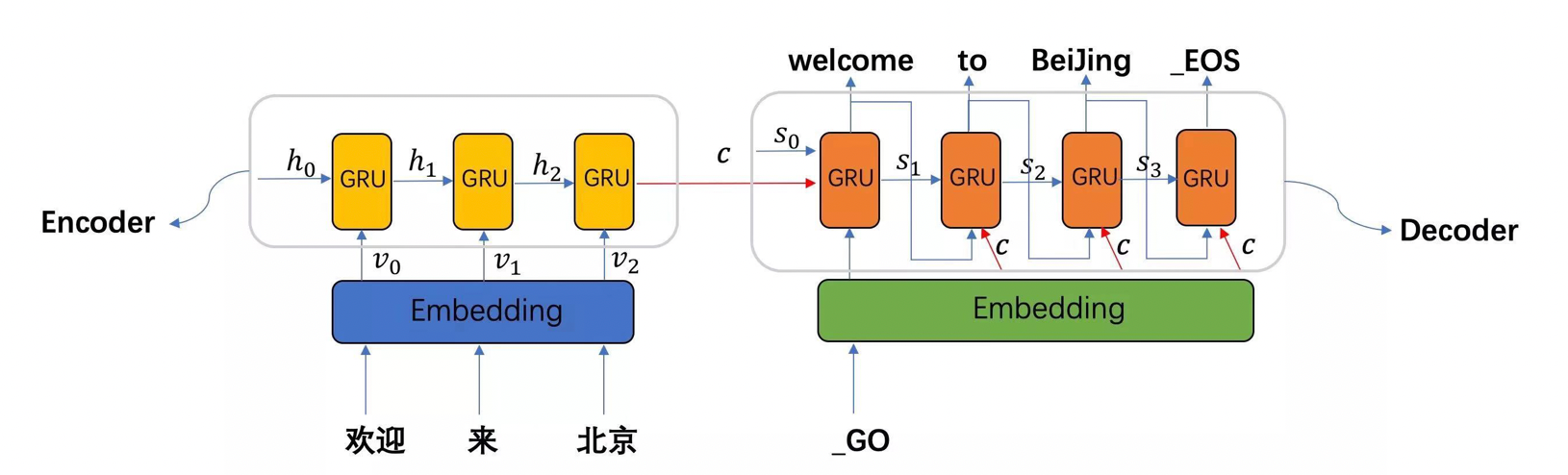
-
图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言
-
早期在解决机器翻译这一类seq2seq问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题:
-
问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。
-
问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。
-
针对这样的问题,注意力机制被提出。
2. 什么是注意力机制
- 注意力机制早在上世纪九十年代就有研究,最早注意力机制应用在视觉领域,后来伴随着2017年Transformer模型结构的提出,注意力机制在NLP,CV相关问题的模型网络设计上被广泛应用。"注意力机制"实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。
- 举例说明:当我们看到下面这张图时,短时间内大脑可能只对图片中的"锦江饭店"有印象,即注意力集中在了"锦江饭店"处。短时间内,大脑可能并没有注意到锦江饭店上面有一串电话号码,下面有几个行人,后面还有"喜运来大酒家"等信息。

- 所以,大脑在短时间内处理信息时,主要将图片中最吸引人注意力的部分读出来了,大脑注意力只关注吸引人的部分, 类似下图所示.

- 同样的如果我们在机器翻译中,我们要让机器注意到每个词向量之间的相关性,有侧重地进行翻译,模拟人类理解的过程。
3. 注意力机制分类以及如何实现
-
通俗来讲就是对于模型的每一个输入项,可能是图片中的不同部分,或者是语句中的某个单词分配一个权重,这个权重的大小就代表了我们希望模型对该部分一个关注程度。这样一来,通过权重大小来模拟人在处理信息的注意力的侧重,有效的提高了模型的性能,并且一定程度上降低了计算量。
-
深度学习中的注意力机制通常可分为三类: 软注意(全局注意)、硬注意(局部注意)和自注意(内注意)
-
软注意机制(Soft/Global Attention: 对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
-
硬注意机制(Hard/Local Attention,了解即可): 对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
-
自注意力机制( Self/Intra Attention): 对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
3.1 Soft Attention (最常见)
- 需要注意:注意力机制是一种通用的思想和技术,不依赖于任何模型,换句话说,注意力机制可以用于任何模型。我们这里只是以文本处理领域的Encoder-Decoder框架为例进行理解。这里我们分别以普通Encoder-Decoder框架以及加Attention的Encoder-Decoder框架分别做对比。
3.1.1 普通Encoder-Decoder框架
- 下图1是Encoder-Decoder框架的一种抽象表示方式:
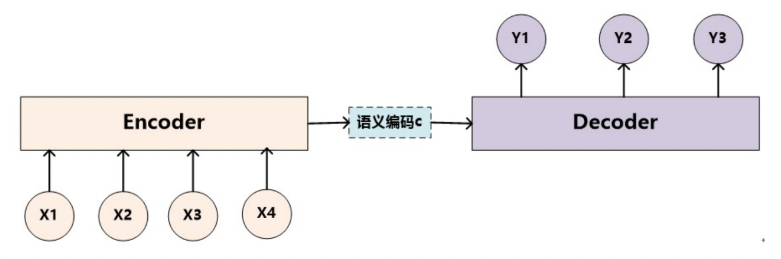
上图图例可以把它看作由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成:
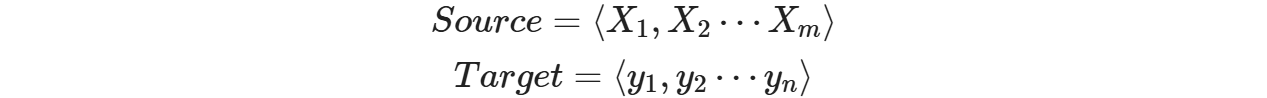
encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
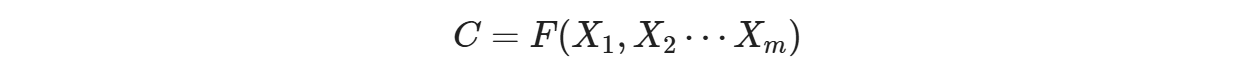
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息,y_1, y_2...y_i-1来生成i时刻要生成的单词y_i
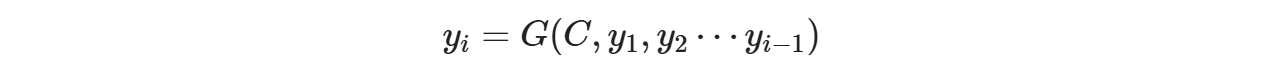
上述图中展示的Encoder-Decoder框架是没有体现出"注意力模型"的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Target中每个单词的生成过程如下:
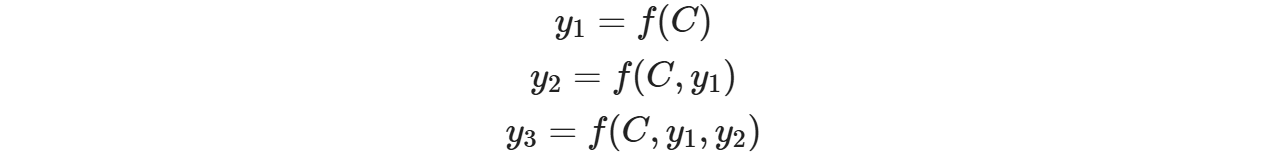
- 其中f是Decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,它们使用的输入句子Source的语义编码C都是一样的,没有任何区别。而语义编码C又是通过对source经过Encoder编码产生的,因此对于target中的任何一个单词,source中任意单词对某个目标单词y_i来说影响力都是相同的,这就是为什么说图1中的模型没有体现注意力的原因。
3.1.2 加Attention的Encoder-Decoder框架
- 举例说明,为何添加Attention:
- 比如机器翻译任务,输入source为:Tom chase Jerry,输出target为:"汤姆","追逐","杰瑞"。在翻译"Jerry"这个中文单词的时候,普通Encoder-Decoder框架中,source里的每个单词对翻译目标单词"杰瑞"贡献是相同的,很明显这里不太合理,显然"Jerry"对于翻译成"杰瑞"更重要。
- 如果引入Attention模型,在生成"杰瑞"的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:(Tom,0.3)(Chase,0.2) (Jerry,0.5).每个英文单词的概率代表了翻译当前单词"杰瑞"时,注意力分配模型分配给不同英文单词的注意力大小。
- 因此,基于上述例子所示, 对于target中任意一个单词都应该有对应的source中的单词的注意力分配概率.而且,由于注意力模型的加入,原来在生成target单词时候的中间语义C就不再是固定的,而是会根据注意力概率变化的C,加入了注意力模型的Encoder-Decoder框架就变成了下图2所示:
即生成目标句子单词的过程成了下面的形式:
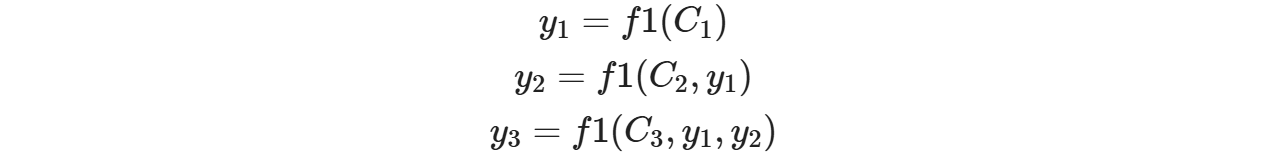
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
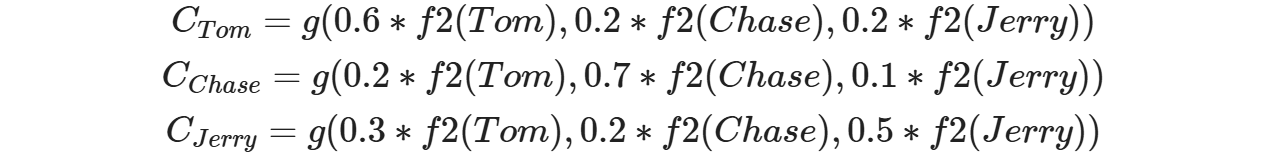
- f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式
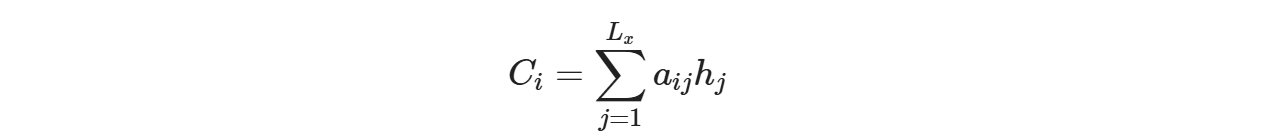
- Lx代表输入句子source的长度, a_ij代表在Target输出第i个单词时source输入句子中的第j个单词的注意力分配系数, 而hj则是source输入句子中第j个单词的语义编码, 假设Ci下标i就是上面例子所说的'汤姆', 那么Lx就是3, h1=f('Tom'), h2=f('Chase'),h3=f('jerry')分别输入句子每个单词的语义编码, 对应的注意力模型权值则分别是0.6, 0.2, 0.2, 所以g函数本质上就是加权求和函数, 如果形象表示的话, 翻译中文单词'汤姆'的时候, 数学公式对应的中间语义表示Ci的形成过程类似下图3:
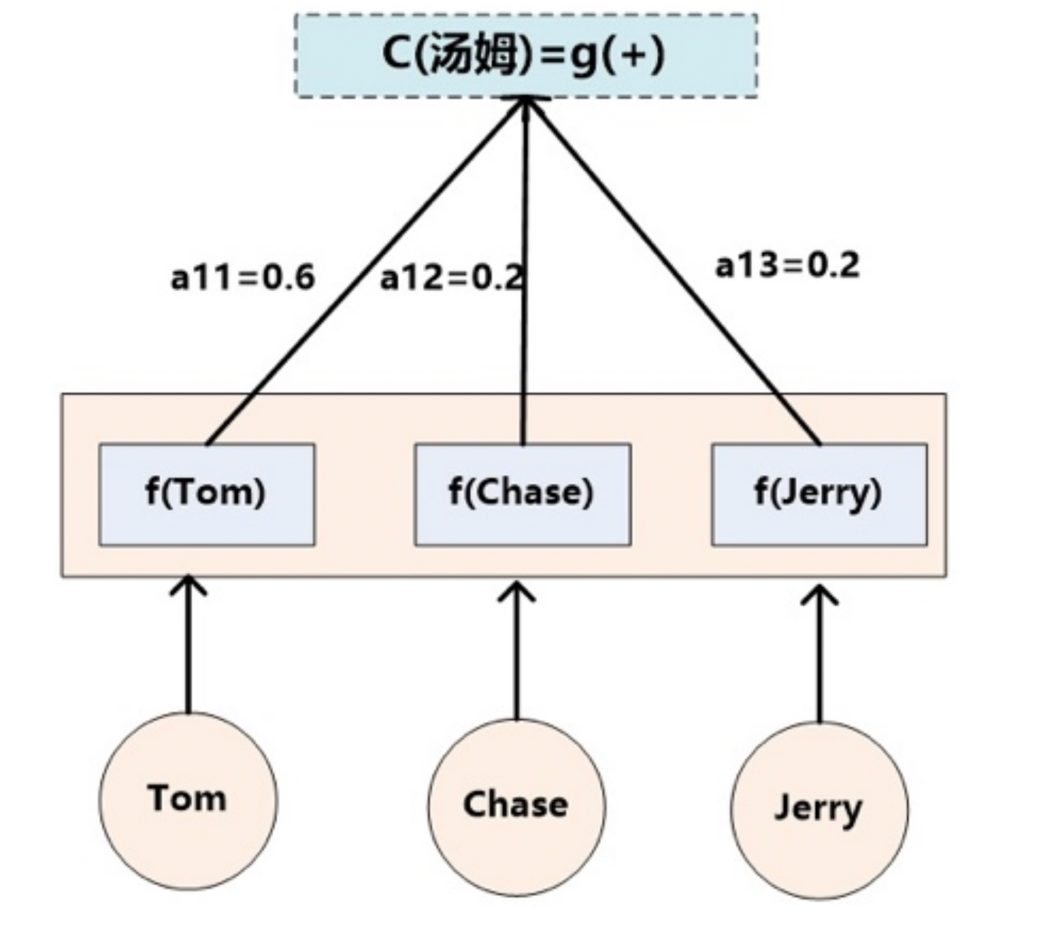
3.1.3 如何得到注意力概率分布
- 为了便于说明,我们假设Encoder-Decoder框架中,Encoder和Decoder都采用RNN模型,如下图4所示:
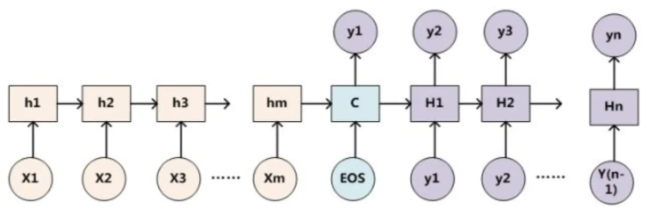
- 那么注意力分配概率分布值的通用计算过程如下:
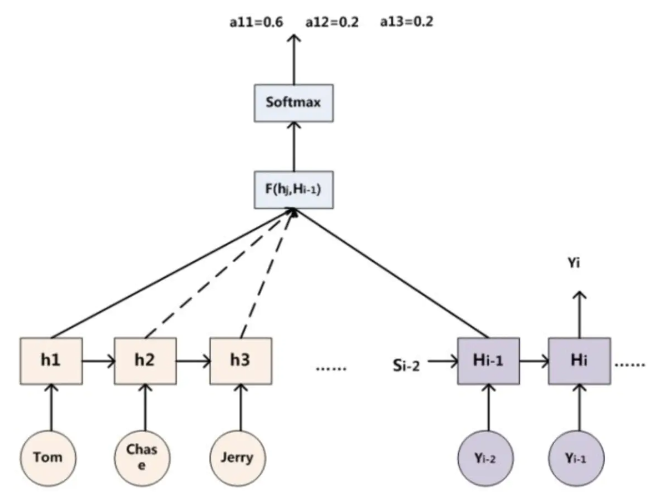
- 上图中h_i表示Source中单词j对应的隐层节点状态h_j,H_i表示Target中单词i的隐层节点状态,注意力计算的是Target中单词i对Source中每个单词对齐可能性,即F(h_j,H_i-1),而函数F可以用不同的方法,然后函数F的输出经过softmax进行归一化就得到了注意力分配概率分布。
- 上面就是经典的Soft Attention模型的基本思想,区别只是函数F会有所不同。
3.1.4 Attention机制的本质思想
- 其实Attention机制可以看作,Target中每个单词是对Source每个单词的加权求和,而权重是Source中每个单词对Target中每个单词的重要程度。因此,Attention的本质思想会表示成下图:
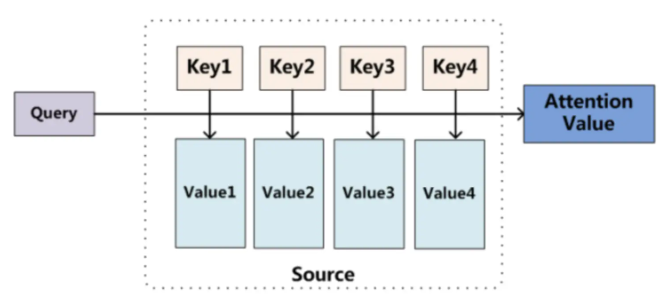
- 将Source中的构成元素看作是一系列的数据对,给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,即权重系数;然后对Value进行加权求和,并得到最终的Attention数值。将本质思想表示成公式如下:
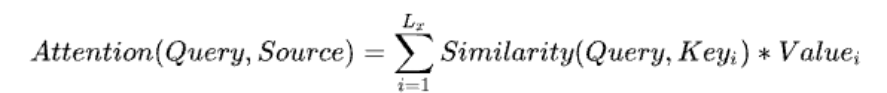
- 深度学习中的注意力机制中提到:Source 中的 Key 和 Value 合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码,所以可能不容易看出这种能够体现本质思想的结构。因此,Attention计算转换为下面3个阶段。
- 输入由三部分构成:Query、Key和Value。其中,(Key, Value)是具有相互关联的KV对,Query是输入的"问题",Attention可以将Query转化为与Query最相关的向量表示。
- Attention的计算主要分3步,如下图所示。
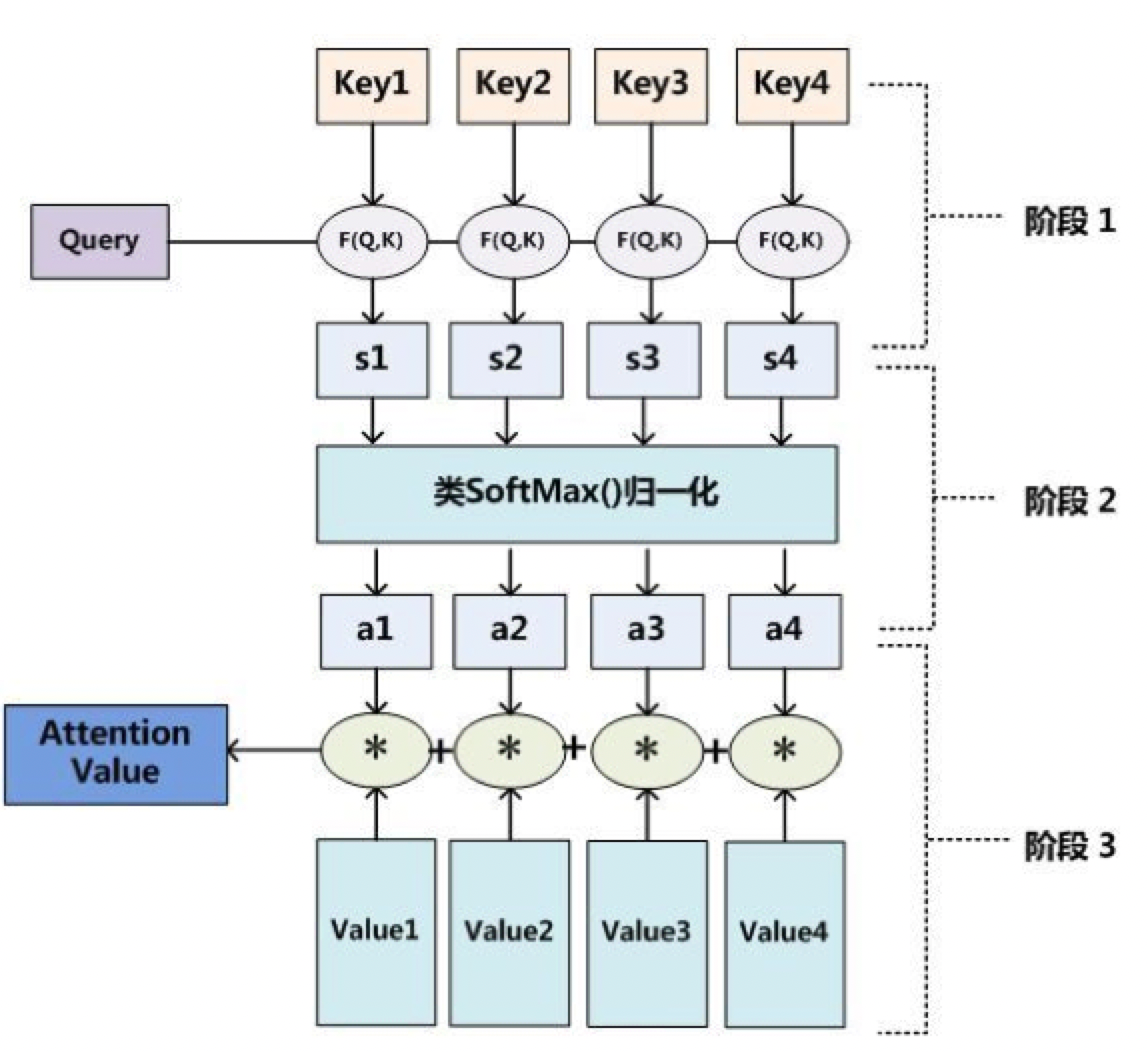
-
Attention 3步计算过程Attention3步计算过程
-
第一步:Query和Key进行相似度计算,得到Attention Score;
-
第二步:对Attention Score进行Softmax归一化,得到权值矩阵;
-
第三步:权重矩阵与Value进行加权求和计算。
-
Query、Key和Value的含义是什么呢?我们以刚才大脑读图为例。Value可以理解为人眼视网膜对整张图片信息的原始捕捉,不受"注意力"所影响。我们可以将Value理解为像素级别的信息,那么假设只要一张图片呈现在人眼面前,图片中的像素都会被视网膜捕捉到。Key与Value相关联,Key是图片原始信息所对应的关键性提示信息,比如"锦江饭店"部分是将图片中的原始像素信息抽象为中文文字和牌匾的提示信息。一个中文读者看到这张图片时,读者大脑有意识地向图片获取信息,即发起了一次Query,Query中包含了读者的意图等信息。在一次读图过程中,Query与Key之间计算出Attention Score,得到最具有吸引力的部分,并只对具有吸引力的Value信息进行提取,反馈到大脑中。就像上面的例子中,经过大脑的注意力机制的筛选,一次Query后,大脑只关注"锦江饭店"的牌匾部分。
-
再以一个搜索引擎的检索为例。使用某个Query去搜索引擎里搜索,搜索引擎里面有好多文章,每个文章的全文可以被理解成Value;文章的关键性信息是标题,可以将标题认为是Key。搜索引擎用Query和那些文章们的标题(Key)进行匹配,看看相似度(计算Attention Score)。我们想得到跟Query相关的知识,于是用这些相似度将检索的文章Value做一个加权和,那么就得到了一个新的信息,新的信息融合了相关性强的文章们,而相关性弱的文章可能被过滤掉。
3.2 Hard Attention
-
在3.1章节我们使用了一种软性注意力的方式进行Attention机制,它通过注意力分布来加权求和融合各个输入向量。而硬性注意力(Hard Attention)机制则不是采用这种方式,它是根据注意力分布选择输入向量中的一个作为输出。这里有两种选择方式:
-
选择注意力分布中,分数最大的那一项对应的输入向量作为Attention机制的输出。
-
根据注意力分布进行随机采样,采样结果作为Attention机制的输出。
-
硬性注意力通过以上两种方式选择Attention的输出,这会使得最终的损失函数与注意力分布之间的函数关系不可导,导致无法使用反向传播算法训练模型,硬性注意力通常需要使用强化学习来进行训练。因此,一般深度学习算法会使用软性注意力的方式进行计算,
3.3 Self Attention
- Self Attention是Google在transformer模型中提出的,上面介绍的都是一般情况下Attention发生在Target元素Query和Source中所有元素之间。而Self Attention,指的是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力机制。当然,具体的计算过程仍然是一样的,只是计算对象发生了变化而已。
- 上面内容也有说到,一般情况下Attention本质上是Target和Source之间的一种单词对齐机制。那么如果是Self Attention机制,到底学的是哪些规律或者抽取了哪些特征呢?或者说引入Self Attention有什么增益或者好处呢?仍然以机器翻译为例来说明, 如下图所示:
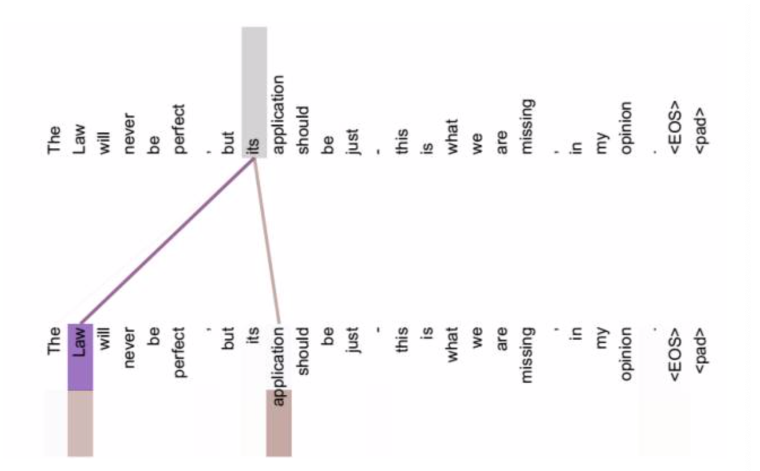
- Attention的发展主要经历了两个阶段:
从上图中可以看到, self Attention可以远距离的捕捉到语义层面的特征(its的指代对象是Law).
应用传统的RNN, LSTM, 在获取长距离语义特征和结构特征的时候, 需要按照序列顺序依次计算, 距离越远的联系信息的损耗越大, 有效提取和捕获的可能性越小.
但是应用self-attention时, 计算过程中会直接将句子中任意两个token的联系通过一个计算步骤直接联系起来
4 小结
- 学习了注意力机制的由来以及解决的问题:
- 早期在解决机器翻译这一类seq2seq问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题:
- 问题1:如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重。
- 问题2:在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差。
- 学习了什么是注意力机制:
- "注意力机制"实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。
- 学习了不同注意力机制的类别:
- 深度学习中的注意力机制通常可分为三类: 软注意(全局注意)、硬注意(局部注意)和自注意(内注意)
- 软注意机制(Soft/Global Attention: 对每个输入项的分配的权重为0-1之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
- 硬注意机制(Hard/Local Attention,了解即可): 对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
- 自注意力机制( Self/Intra Attention): 对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
6.注意力机制介绍2
学习目标
- 了解什么是注意力计算规则以及常见的计算规则
- 了解什么是注意力机制及其作用
- 掌握注意力机制的实现步骤
1 注意力机制规则
- 它需要三个指定的输入Q(query), K(key), V(value), 然后通过计算公式得到注意力的结果, 这个结果代表query在key和value作用下的注意力表示. 当输入的Q=K=V时, 称作自注意力计算规则;当Q、K、V不相等时称为一般注意力计算规则
例子:seq2seq架构翻译应用中的Q、K、V解释
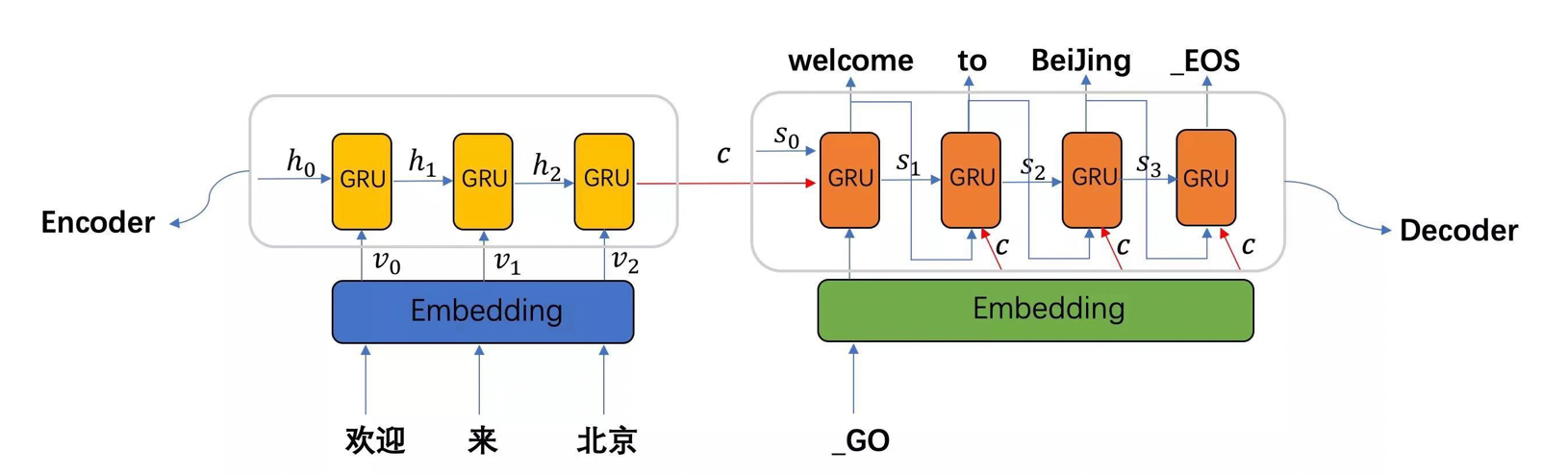
- seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。
- 图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言.
- 在上述机器翻译架构中加入Attention的方式有两种:
- 第一种tensorflow版本(传统方式),如下图所示:
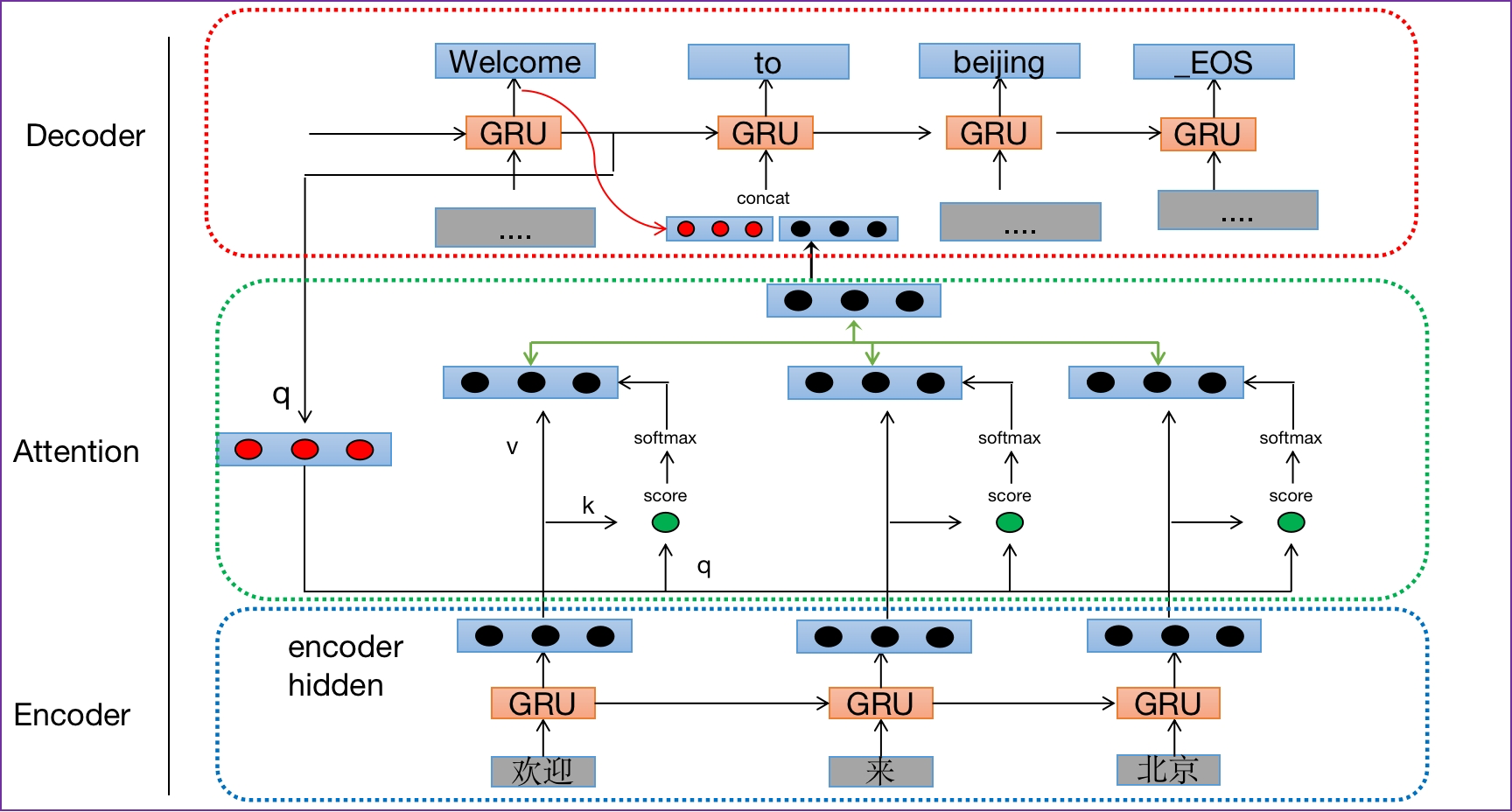
上图翻译应用中的Q、K、V解释
- 查询张量Q: 解码器每一步输出或者是当前输入的x
- 键张量K: 编码部分每个时间步的结果组合而成
- 值张量V:编码部分每个时间步的结果组合而成
- 第二种Pytorch版本(改进版),如下图所示:
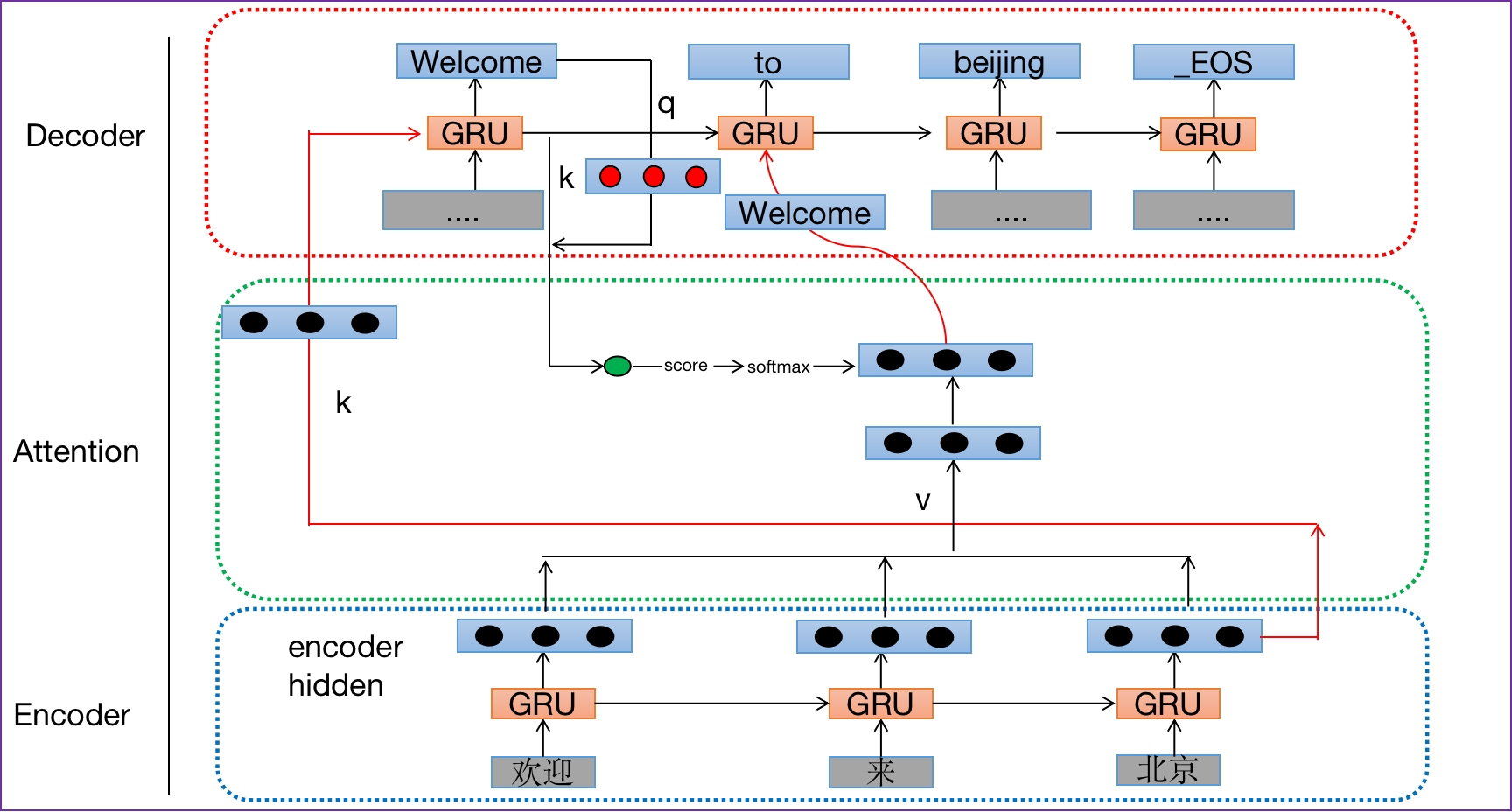
上图翻译应用中的Q、K、V解释
- 查询张量Q: 解码器每一步的输出或者是当前输入的x
- 键张量K: 解码器上一步的隐藏层输出
- 值张量V:编码部分每个时间步输出结果组合而成
- 两个版本对比:
- pytorch版本的是乘型attention,tensorflow版本的是加型attention。pytorch这里直接将与上一个unit隐状态prev_hidden拼接起来✖W得到score,之后将score过softmax得到attenion_weights.
- 解码过程如下:
- (1)采用自回归机制,比如:输入"go"来预测"welcome",输入"welcome"来预测"to",输入"to"来预测"Beijing"。在输入"welcome"来预测"to"解码中,可使用注意力机制
- (2)查询张量Q:一般可以是"welcome"词嵌入层以后的结果,查询张量Q为生成谁就是谁的查询张量(比如这里为了生成"to",则查询张量就是上一个时间步"welcome"的查询张量,请仔细体会这一点)
- (3) 键向量K:一般可以是上一个时间步的隐藏层输出
- (4)值向量V:一般可以是编码部分每个时间步的结果组合而成
- (5)查询张量Q来生成"to",去检索"to"单词和"欢迎"、"来"、"北京"三个单词的权重分布,注意力结果表示(用权重分布 乘以内容V)
1.3 常见的注意力计算规则
- 将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法.
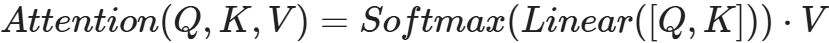
将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法.
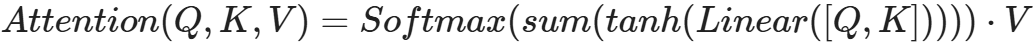
将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法.
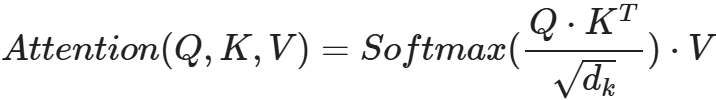
-
说明:当注意力权重矩阵和V都是三维张量且第一维代表为batch条数时, 则做bmm运算.bmm是一种特殊的张量乘法运算.
-
bmm运算演示:
如果参数1形状是(b × n × m), 参数2形状是(b × m × p), 则输出为(b × n × p)
input = torch.randn(10, 3, 4)
mat2 = torch.randn(10, 4, 5)
res = torch.bmm(input, mat2)
res.size()
torch.Size([10, 3, 5])
2 什么是深度神经网络注意力机制
-
注意力机制是注意力计算规则能够应用的深度学习网络的载体, 同时包括一些必要的全连接层以及相关张量处理, 使其与应用网络融为一体. 使用自注意力计算规则的注意力机制称为自注意力机制.
-
说明: NLP领域中, 当前的注意力机制大多数应用于seq2seq架构, 即编码器和解码器模型.
-
请思考:为什么要在深度神经网络中引入注意力机制?
- 1、rnn等循环神经网络,随着时间步的增长,前面单词的特征会遗忘,造成对句子特征提取不充分
- 2、rnn等循环神经网络是一个时间步一个时间步的提取序列特征,效率低下
- 3、研究者开始思考,能不能对32个单词(序列)同时提取事物特征,而且还是并行的,所以引入注意力机制!
3 注意力机制的作用
- 在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
- 在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).
注意力机制在网络中实现的图形表示:
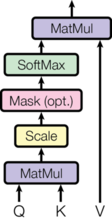
4 注意力机制实现步骤
4.1 步骤
- 第一步: 根据注意力计算规则, 对Q,K,V进行相应的计算.
- 第二步: 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.
- 第三步: 最后为了使整个attention机制按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换, 得到最终对Q的注意力表示.
4.2 代码实现
-
常见注意力机制的代码分析:
任务描述:
有QKV:v是内容比如32个单词,每个单词64个特征,k是32个单词的索引,q是查询张量
我们的任务:输入查询张量q,通过注意力机制来计算如下信息:
1、查询张量q的注意力权重分布:查询张量q和其他32个单词相关性(相识度)
2、查询张量q的结果表示:有一个普通的q升级成一个更强大q;用q和v做bmm运算
3 注意:查询张量q查询的目标是谁,就是谁的查询张量。
eg:比如查询张量q是来查询单词"我",则q就是我的查询张量
import torch
import torch.nn as nn
import torch.nn.functional as FMyAtt类实现思路分析
1 init函数 (self, query_size, key_size, value_size1, value_size2, output_size)
准备2个线性层 注意力权重分布self.attn 注意力结果表示按照指定维度进行输出层 self.attn_combine
2 forward(self, Q, K, V):
求查询张量q的注意力权重分布, attn_weights[1,32]
求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,64]
q 与 attn_applied 融合,再按照指定维度输出 output[1,1,32]
返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,32]
class MyAtt(nn.Module):
# 32 32 32 64 32
def init(self, query_size, key_size, value_size1, value_size2, output_size):
super(MyAtt, self).init()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size# 线性层1 注意力权重分布 self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1) # 线性层2 注意力结果表示按照指定维度输出层 self.attn_combine self.attn_combine = nn.Linear(self.query_size+self.value_size2, output_size) def forward(self, Q, K, V): # 1 求查询张量q的注意力权重分布, attn_weights[1,32] # [1,1,32],[1,1,32]--> [1,32],[1,32]->[1,64] # [1,64] --> [1,32] # tmp1 = torch.cat( (Q[0], K[0]), dim=1) # tmp2 = self.attn(tmp1) # tmp3 = F.softmax(tmp2, dim=1) attn_weights = F.softmax( self.attn(torch.cat( (Q[0], K[0]), dim=-1)), dim=-1) # 2 求查询张量q的结果表示 bmm运算, attn_applied[1,1,64] # [1,1,32] * [1,32,64] ---> [1,1,64] attn_applied = torch.bmm(attn_weights.unsqueeze(0), V) # 3 q 与 attn_applied 融合,再按照指定维度输出 output[1,1,64] # 3-1 q与结果表示拼接 [1,32],[1,64] ---> [1,96] output = torch.cat((Q[0], attn_applied[0]), dim=-1) # 3-2 shape [1,96] ---> [1,32] output = self.attn_combine(output).unsqueeze(0) # 4 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,32] return output, attn_weights
- 调用:
if __name__ == '__main__':
query_size = 32
key_size = 32
value_size1 = 32 # 32个单词
value_size2 = 64 # 64个特征
output_size = 32
Q = torch.randn(1, 1, 32)
K = torch.randn(1, 1, 32)
V = torch.randn(1, 32, 64)
# V = torch.randn(1, value_size1, value_size2)
# 1 实例化注意力类 对象
myattobj = MyAtt(query_size, key_size, value_size1, value_size2, output_size)
# 2 把QKV数据扔给注意机制,求查询张量q的注意力结果表示、注意力权重分布
output, attn_weights = myattobj(Q, K, V)
print('查询张量q的注意力结果表示output--->', output.shape, output)
print('查询张量q的注意力权重分布attn_weights--->', attn_weights.shape, attn_weights)
- 输出效果:
查询张量q的注意力结果表示output---> torch.Size([1, 1, 32]) tensor([[[ 0.3135, -0.0539, 0.0597, -0.0046, -0.3389, -0.1238, 1.0385,
0.8896, -0.0268, -0.0705, -0.8409, 0.6547, 0.5909, -0.6048,
0.6303, -0.2233, 0.7678, -0.3140, 0.3635, -0.3234, -0.1053,
0.5845, 0.1163, -0.2203, -0.0812, -0.0868, 0.0218, -0.0597,
0.6923, -0.1848, -0.8266, -0.0614]]], grad_fn=<UnsqueezeBackward0>)
查询张量q的注意力权重分布attn_weights---> torch.Size([1, 32]) tensor([[0.0843, 0.0174, 0.0138, 0.0431, 0.0110, 0.0308, 0.0608, 0.0216, 0.0101,
0.0406, 0.0462, 0.0111, 0.0349, 0.0065, 0.0383, 0.0526, 0.0151, 0.0193,
0.0294, 0.0632, 0.0322, 0.0072, 0.0294, 0.0388, 0.0135, 0.0443, 0.0594,
0.0332, 0.0117, 0.0168, 0.0293, 0.0344]], grad_fn=<SoftmaxBackward0>)- 更多有关注意力机制的应用我们将在案例中进行详尽的理解分析.
5 小结
-
学习了什么是注意力计算规则:
- 它需要三个指定的输入Q(query), K(key), V(value), 然后通过计算公式得到注意力的结果, 这个结果代表query在key和value作用下的注意力表示. 当输入的Q=K=V时, 称作自注意力计算规则.
-
常见的注意力计算规则:
- 将Q,K进行纵轴拼接, 做一次线性变化, 再使用softmax处理获得结果最后与V做张量乘法.
- 将Q,K进行纵轴拼接, 做一次线性变化后再使用tanh函数激活, 然后再进行内部求和, 最后使用softmax处理获得结果再与V做张量乘法.
- 将Q与K的转置做点积运算, 然后除以一个缩放系数, 再使用softmax处理获得结果最后与V做张量乘法.
-
学习了什么是深度学习注意力机制:
- 注意力机制是注意力计算规则能够应用的深度学习网络的载体, 同时包括一些必要的全连接层以及相关张量处理, 使其与应用网络融为一体. 使自注意力计算规则的注意力机制称为自注意力机制.
-
注意力机制的作用:
- 在解码器端的注意力机制: 能够根据模型目标有效的聚焦编码器的输出结果, 当其作为解码器的输入时提升效果. 改善以往编码器输出是单一定长张量, 无法存储过多信息的情况.
- 在编码器端的注意力机制: 主要解决表征问题, 相当于特征提取过程, 得到输入的注意力表示. 一般使用自注意力(self-attention).
-
注意力机制实现步骤:
- 第一步: 根据注意力计算规则, 对Q,K,V进行相应的计算.
- 第二步: 根据第一步采用的计算方法, 如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接, 如果是转置点积, 一般是自注意力, Q与V相同, 则不需要进行与Q的拼接.
- 第三步: 最后为了使整个attention机制按照指定尺寸输出, 使用线性层作用在第二步的结果上做一个线性变换, 得到最终对Q的注意力表示.
-
学习并实现了一种常见的注意力机制的类Attn.
7.RNN案例 seq2seq英译法
学习目标
- 更深一步了解seq2seq模型架构和翻译数据集
- 掌握使用基于GRU的seq2seq模型架构实现翻译的过程
- 掌握Attention机制在解码器端的实现过程
1 seq2seq介绍
1.1 seq2seq模型架构
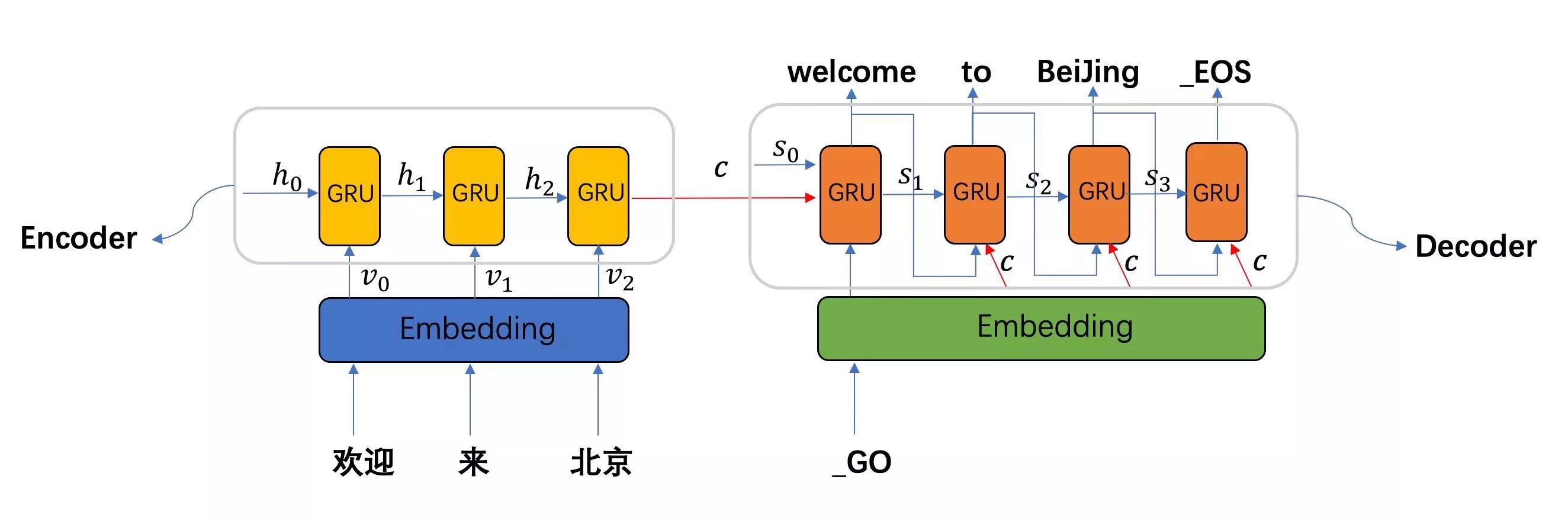
-
seq2seq模型架构分析:
-
seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。其中编码器和解码器的内部实现都使用了GRU模型
-
图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过GRU模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量c;接着解码器将使用这个中间语义张量c以及每一个时间步的隐层张量, 逐个生成对应的翻译语言
-
我们的案例通过英译法来讲解seq2seq设计与实现。
2 数据集介绍
# 数据集在虚拟机/root/data/下
- data/
- eng-fra-v2.txt
i am from brazil . je viens du bresil .
i am from france . je viens de france .
i am from russia . je viens de russie .
i am frying fish . je fais frire du poisson .
i am not kidding . je ne blague pas .
i am on duty now . maintenant je suis en service .
i am on duty now . je suis actuellement en service .
i am only joking . je ne fais que blaguer .
i am out of time . je suis a court de temps .
i am out of work . je suis au chomage .
i am out of work . je suis sans travail .
i am paid weekly . je suis payee a la semaine .
i am pretty sure . je suis relativement sur .
i am truly sorry . je suis vraiment desole .
i am truly sorry . je suis vraiment desolee .3 案例步骤
基于GRU的seq2seq模型架构实现翻译的过程:
- 第一步: 导入工具包和工具函数
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求
- 第三步: 构建基于GRU的编码器和解码器
- 第四步: 构建模型训练函数, 并进行训练
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析
1 导入工具包和工具函数
# 用于正则表达式
import re
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
# torch中预定义的优化方法工具包
import torch.optim as optim
import time
# 用于随机生成数据
import random
import matplotlib.pyplot as plt
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 起始标志
SOS_token = 0
# 结束标志
EOS_token = 1
# 最大句子长度不能超过10个 (包含标点)
MAX_LENGTH = 10
# 数据文件路径
data_path = './data/eng-fra-v2.txt'
# 文本清洗工具函数
def normalizeString(s):
"""字符串规范化函数, 参数s代表传入的字符串"""
s = s.lower().strip()
# 在.!?前加一个空格 这里的\1表示第一个分组 正则中的\num
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s2 数据预处理
对持久化文件中数据进行处理, 以满足模型训练要求
1 清洗文本和构建文本字典
- 清洗文本和构建文本字典思路分析
# my_getdata() 清洗文本构建字典思路分析
# 1 按行读文件 open().read().strip().split(\n) my_lines
# 2 按行清洗文本 构建语言对 my_pairs[] tmppair[]
# 2-1格式 [['英文', '法文'], ['英文', '法文'], ['英文', '法文'], ['英文', '法文']....]
# 2-2调用清洗文本工具函数normalizeString(s)
# 3 遍历语言对 构建英语单词字典 法语单词字典 my_pairs->pair->pair[0].split(' ') pair[1].split(' ')->word
# 3-1 english_word2index english_word_n french_word2index french_word_n
# 其中 english_word2index = {0: "SOS", 1: "EOS"} english_word_n=2
# 3-2 english_index2word french_index2word
# 4 返回数据的7个结果
# english_word2index, english_index2word, english_word_n,
# french_word2index, french_index2word, french_word_n, my_pairs
- 代码实现
def my_getdata():
# 1 按行读文件 open().read().strip().split(\n)
my_lines = open(data_path, encoding='utf-8').read().strip().split('\n')
print('my_lines--->', len(my_lines))
# 2 按行清洗文本 构建语言对 my_pairs
# 格式 [['英文句子', '法文句子'], ['英文句子', '法文句子'], ['英文句子', '法文句子'], ... ]
# tmp_pair, my_pairs = [], []
# for l in my_lines:
# for s in l.split('\t'):
# tmp_pair.append(normalizeString(s))
# my_pairs.append(tmp_pair)
# tmp_pair = []
my_pairs = [[normalizeString(s) for s in l.split('\t')] for l in my_lines]
print('len(pairs)--->', len(my_pairs))
# 打印前4条数据
print(my_pairs[:4])
# 打印第8000条的英文 法文数据
print('my_pairs[8000][0]--->', my_pairs[8000][0])
print('my_pairs[8000][1]--->', my_pairs[8000][1])
# 3 遍历语言对 构建英语单词字典 法语单词字典
# 3-1 english_word2index english_word_n french_word2index french_word_n
english_word2index = {"SOS": 0, "EOS": 1}
english_word_n = 2
french_word2index = {"SOS": 0, "EOS": 1}
french_word_n = 2
# 遍历语言对 获取英语单词字典 法语单词字典
for pair in my_pairs:
for word in pair[0].split(' '):
if word not in english_word2index:
english_word2index[word] = english_word_n
english_word_n += 1
for word in pair[1].split(' '):
if word not in french_word2index:
french_word2index[word] = french_word_n
french_word_n += 1
# 3-2 english_index2word french_index2word
english_index2word = {v:k for k, v in english_word2index.items()}
french_index2word = {v:k for k, v in french_word2index.items()}
print('len(english_word2index)-->', len(english_word2index))
print('len(french_word2index)-->', len(french_word2index))
print('english_word_n--->', english_word_n, 'french_word_n-->', french_word_n)
return english_word2index, english_index2word, english_word_n, french_word2index, french_index2word, french_word_n, my_pairs
- 调用
# 全局函数 获取英语单词字典 法语单词字典 语言对列表my_pairs
english_word2index, english_index2word, english_word_n, \
french_word2index, french_index2word, french_word_n, \
my_pairs = my_getdata()
- 输出效果:
my_lines---> 10599
len(pairs)---> 10599
[['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .'], ['i m ok .', 'ca va .'], ['i m fat .', 'je suis gras .']]
my_pairs[8000][0]---> they re in the science lab .
my_pairs[8000][1]---> elles sont dans le laboratoire de sciences .
len(english_word2index)--> 2803
len(french_word2index)--> 4345
english_word_n---> 2803 french_word_n--> 4345
x.shape torch.Size([1, 9]) tensor([[ 75, 40, 102, 103, 677, 42, 21, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 119, 25, 164, 165, 3222, 5, 1]])
x.shape torch.Size([1, 5]) tensor([[14, 15, 44, 4, 1]])
y.shape torch.Size([1, 5]) tensor([[24, 25, 62, 5, 1]])
x.shape torch.Size([1, 8]) tensor([[ 2, 3, 147, 61, 532, 1143, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 6, 297, 7, 246, 102, 5, 1]])2 构建数据源对象
# 原始数据 -> 数据源MyPairsDataset --> 数据迭代器DataLoader
# 构造数据源 MyPairsDataset,把语料xy 文本数值化 再转成tensor_x tensor_y
# 1 __init__(self, my_pairs)函数 设置self.my_pairs 条目数self.sample_len
# 2 __len__(self)函数 获取样本条数
# 3 __getitem__(self, index)函数 获取第几条样本数据
# 按索引 获取数据样本 x y
# 样本x 文本数值化 word2id x.append(EOS_token)
# 样本y 文本数值化 word2id y.append(EOS_token)
# 返回tensor_x, tensor_y
class MyPairsDataset(Dataset):
def __init__(self, my_pairs):
# 样本x
self.my_pairs = my_pairs
# 样本条目数
self.sample_len = len(my_pairs)
# 获取样本条数
def __len__(self):
return self.sample_len
# 获取第几条 样本数据
def __getitem__(self, index):
# 对index异常值进行修正 [0, self.sample_len-1]
index = min(max(index, 0), self.sample_len-1)
# 按索引获取 数据样本 x y
x = self.my_pairs[index][0]
y = self.my_pairs[index][1]
# 样本x 文本数值化
x = [english_word2index[word] for word in x.split(' ')]
x.append(EOS_token)
tensor_x = torch.tensor(x, dtype=torch.long, device=device)
# 样本y 文本数值化
y = [french_word2index[word] for word in y.split(' ')]
y.append(EOS_token)
tensor_y = torch.tensor(y, dtype=torch.long, device=device)
# 注意 tensor_x tensor_y都是一维数组,通过DataLoader拿出数据是二维数据
# print('tensor_y.shape===>', tensor_y.shape, tensor_y)
# 返回结果
return tensor_x, tensor_y3 构建数据迭代器
def dm_test_MyPairsDataset():
# 1 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 2 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
for i, (x, y) in enumerate (mydataloader):
print('x.shape', x.shape, x)
print('y.shape', y.shape, y)
if i == 1:
break
- 输出效果:
x.shape torch.Size([1, 8]) tensor([[ 2, 16, 33, 518, 589, 1460, 4, 1]])
y.shape torch.Size([1, 8]) tensor([[ 6, 11, 52, 101, 1358, 964, 5, 1]])
x.shape torch.Size([1, 6]) tensor([[129, 78, 677, 429, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 118, 214, 1073, 194, 778, 5, 1]])3 构建基于GRU的编码器和解码器
1 构建基于GRU的编码器
- 编码器结构图:
- 实现思路分析
# EncoderRNN类 实现思路分析:
# 1 init函数 定义2个层 self.embedding self.gru (batch_first=True)
# def __init__(self, input_size, hidden_size): # 2803 256
# 2 forward(input, hidden)函数,返回output, hidden
# 数据经过词嵌入层 数据形状 [1,6] --> [1,6,256]
# 数据经过gru层 形状变化 gru([1,6,256],[1,1,256]) --> [1,6,256] [1,1,256]
# 3 初始化隐藏层输入数据 inithidden()
# 形状 torch.zeros(1, 1, self.hidden_size, device=device)
- 构建基于GRU的编码器
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
# input_size 编码器 词嵌入层单词数 eg:2803
# hidden_size 编码器 词嵌入层每个单词的特征数 eg 256
super(EncoderRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 实例化nn.Embedding层
self.embedding = nn.Embedding(input_size, hidden_size)
# 实例化nn.GRU层 注意参数batch_first=True
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
def forward(self, input, hidden):
# 数据经过词嵌入层 数据形状 [1,6] --> [1,6,256]
output = self.embedding(input)
# 数据经过gru层 数据形状 gru([1,6,256],[1,1,256]) --> [1,6,256] [1,1,256]
output, hidden = self.gru(output, hidden)
return output, hidden
def inithidden(self):
# 将隐层张量初始化成为1x1xself.hidden_size大小的张量
return torch.zeros(1, 1, self.hidden_size, device=device)
- 调用
def dm_test_EncoderRNN():
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256 #
my_encoderrnn = EncoderRNN(input_size, hidden_size)
print('my_encoderrnn模型结构--->', my_encoderrnn)
# 给encode模型喂数据
for i, (x, y) in enumerate (mydataloader):
print('x.shape', x.shape, x)
print('y.shape', y.shape, y)
# 一次性的送数据
hidden = my_encoderrnn.inithidden()
encode_output_c, hidden = my_encoderrnn(x, hidden)
print('encode_output_c.shape--->', encode_output_c.shape, encode_output_c)
# 一个字符一个字符给为模型喂数据
hidden = my_encoderrnn.inithidden()
for i in range(x.shape[1]):
tmp = x[0][i].view(1,-1)
output, hidden = my_encoderrnn(tmp, hidden)
print('观察:最后一个时间步output输出是否相等') # hidden_size = 8 效果比较好
print('encode_output_c[0][-1]===>', encode_output_c[0][-1])
print('output===>', output)
break
- 输出效果:
# 本输出效果为hidden_size = 8
x.shape torch.Size([1, 6]) tensor([[129, 124, 270, 558, 4, 1]])
y.shape torch.Size([1, 7]) tensor([[ 118, 214, 101, 1253, 1028, 5, 1]])
encode_output_c.shape---> torch.Size([1, 6, 8])
tensor([[[-0.0984, 0.4267, -0.2120, 0.0923, 0.1525, -0.0378, 0.2493,-0.2665],
[-0.1388, 0.5363, -0.4522, -0.2819, -0.2070, 0.0795, 0.6262, -0.2359],
[-0.4593, 0.2499, 0.1159, 0.3519, -0.0852, -0.3621, 0.1980, -0.1853],
[-0.4407, 0.1974, 0.6873, -0.0483, -0.2730, -0.2190, 0.0587, 0.2320],
[-0.6544, 0.1990, 0.7534, -0.2347, -0.0686, -0.5532, 0.0624, 0.4083],
[-0.2941, -0.0427, 0.1017, -0.1057, 0.1983, -0.1066, 0.0881, -0.3936]]], grad_fn=<TransposeBackward1>)
观察:最后一个时间步output输出是否相等
encode_output_c[0][-1]===> tensor([-0.2941, -0.0427, 0.1017, -0.1057, 0.1983, -0.1066, 0.0881, -0.3936],
grad_fn=<SelectBackward0>)
output===> tensor([[[-0.2941, -0.0427, 0.1017, -0.1057, 0.1983, -0.1066, 0.0881,
-0.3936]]], grad_fn=<TransposeBackward1>)2 构建基于GRU的解码器
- 解码器结构图:
- 构建基于GRU的解码器实现思路分析
# DecoderRNN 类 实现思路分析:
# 解码器的作用:提取事物特征 进行分类(所以比 编码器 多了 线性层 和 softmax层)
# 1 init函数 定义四个层 self.embedding self.gru self.out self.softmax=nn.LogSoftmax(dim=-1)
# def __init__(self, output_size, hidden_size): # 4345 256
# 2 forward(input, hidden)函数,返回output, hidden
# 数据经过词嵌入层 数据形状 [1,1] --> [1,1,256]
# 数据经过relu()层 output = F.relu(output)
# 数据经过gru层 形状变化 gru([1,1,256],[1,1,256]) --> [1,1,256] [1,1,256]
# 数据结果out层 形状变化 [1,1,256]->[1,256]-->[1,4345]
# 返回 解码器分类output[1,4345],最后隐层张量hidden[1,1,256]
# 3 初始化隐藏层输入数据 inithidden()
# 形状 torch.zeros(1, 1, self.hidden_size, device=device)
- 编码实现
class DecoderRNN(nn.Module):
def __init__(self, output_size, hidden_size):
# output_size 编码器 词嵌入层单词数 eg:4345
# hidden_size 编码器 词嵌入层每个单词的特征数 eg 256
super(DecoderRNN, self).__init__()
self.output_size = output_size
self.hidden_size = hidden_size
# 实例化词嵌入层
self.embedding = nn.Embedding(output_size, hidden_size)
# 实例化gru层,输入尺寸256 输出尺寸256
# 因解码器一个字符一个字符的解码 batch_first=True 意义不大
self.gru = nn.GRU(hidden_size, hidden_size, batch_first=True)
# 实例化线性输出层out 输入尺寸256 输出尺寸4345
self.out = nn.Linear(hidden_size, output_size)
# 实例化softomax层 数值归一化 以便分类
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
# 数据经过词嵌入层
# 数据形状 [1,1] --> [1,1,256] or [1,6]--->[1,6,256]
output = self.embedding(input)
# 数据结果relu层使Embedding矩阵更稀疏,以防止过拟合
output = F.relu(output)
# 数据经过gru层
# 数据形状 gru([1,1,256],[1,1,256]) --> [1,1,256] [1,1,256]
output, hidden = self.gru(output, hidden)
# 数据经过softmax层 归一化
# 数据形状变化 [1,1,256]->[1,256] ---> [1,4345]
output = self.softmax(self.out(output[0]))
return output, hidden
def inithidden(self):
# 将隐层张量初始化成为1x1xself.hidden_size大小的张量
return torch.zeros(1, 1, self.hidden_size, device=device)
- 调用
def dm03_test_DecoderRNN():
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_encoderrnn = EncoderRNN(input_size, hidden_size)
print('my_encoderrnn模型结构--->', my_encoderrnn)
# 实例化模型
input_size = french_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_decoderrnn = DecoderRNN(input_size, hidden_size)
print('my_decoderrnn模型结构--->', my_decoderrnn)
# 给模型喂数据 完整演示编码 解码流程
for i, (x, y) in enumerate (mydataloader):
print('x.shape', x.shape, x)
print('y.shape', y.shape, y)
# 1 编码:一次性的送数据
hidden = my_encoderrnn.inithidden()
encode_output_c, hidden = my_encoderrnn(x, hidden)
print('encode_output_c.shape--->', encode_output_c.shape, encode_output_c)
print('观察:最后一个时间步output输出') # hidden_size = 8 效果比较好
print('encode_output_c[0][-1]===>', encode_output_c[0][-1])
# 2 解码: 一个字符一个字符的解码
# 最后1个隐藏层的输出 作为 解码器的第1个时间步隐藏层输入
for i in range(y.shape[1]):
tmp = y[0][i].view(1, -1)
output, hidden = my_decoderrnn(tmp, hidden)
print('每个时间步解码出来4345种可能 output===>', output.shape)
break
- 输出效果
my_encoderrnn模型结构---> EncoderRNN(
(embedding): Embedding(2803, 256)
(gru): GRU(256, 256, batch_first=True)
)
my_decoderrnn模型结构---> DecoderRNN(
(embedding): Embedding(4345, 256)
(gru): GRU(256, 256, batch_first=True)
(out): Linear(in_features=256, out_features=4345, bias=True)
(softmax): LogSoftmax(dim=-1)
)
x.shape torch.Size([1, 8]) tensor([[ 14, 40, 883, 677, 589, 609, 4, 1]])
y.shape torch.Size([1, 6]) tensor([[1358, 1125, 247, 2863, 5, 1]])
每个时间步解码出来4345种可能 output===> torch.Size([1, 4345])
每个时间步解码出来4345种可能 output===> torch.Size([1, 4345])
每个时间步解码出来4345种可能 output===> torch.Size([1, 4345])
每个时间步解码出来4345种可能 output===> torch.Size([1, 4345])
每个时间步解码出来4345种可能 output===> torch.Size([1, 4345])
每个时间步解码出来4345种可能 output===> torch.Size([1, 4345])3 构建基于GRU和Attention的解码器
- 解码器结构图:
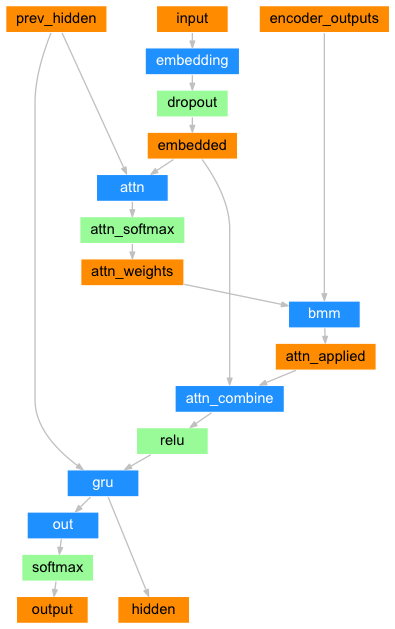
- 实现思路分析
# 构建基于GRU和Attention的解码器
# AttnDecoderRNN 类 实现思路分析:
# 1 init函数 定义六个层
# self.embedding self.attn self.attn_combine
# self.gru self.out self.softmax=nn.LogSoftmax(dim=-1)
# def __init__(self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):: # 4345 256
# 2 forward(input, hidden, encoder_outputs)函数,返回output, hidden
# 数据经过词嵌入层 数据形状 [1,1] --> [1,1,256]
# 1 求查询张量q的注意力权重分布, attn_weights[1,10]
# 2 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,256]
# 3 q 与 attn_applied 融合,经过层attn_combine 按照指定维度输出 output[1,1,256]
# 数据经过relu()层 output = F.relu(output)
# 数据经过gru层 形状变化 gru([1,1,256],[1,1,256]) --> [1,1,256] [1,1,256]
# 返回 # 返回解码器分类output[1,4345],最后隐层张量hidden[1,1,256] 注意力权重张量attn_weights[1,10]
# 3 初始化隐藏层输入数据 inithidden()
# 形状 torch.zeros(1, 1, self.hidden_size, device=device)
# 相对传统RNN解码 AttnDecoderRNN类多了注意力机制,需要构建QKV
# 1 在init函数中 (self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH)
# 增加层 self.attn self.attn_combine self.dropout
# 2 增加函数 attentionQKV(self, Q, K, V)
# 3 函数forward(self, input, hidden, encoder_outputs)
# encoder_outputs 每个时间步解码准备qkv 调用attentionQKV
# 函数返回值 output, hidden, attn_weights
# 4 调用需要准备中间语义张量C encode_output_c
- 编码实现
class AttnDecoderRNN(nn.Module):
def __init__(self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):
# output_size 编码器 词嵌入层单词数 eg:4345
# hidden_size 编码器 词嵌入层每个单词的特征数 eg 256
# dropout_p 置零比率,默认0.1,
# max_length 最大长度10
super(AttnDecoderRNN, self).__init__()
self.output_size = output_size
self.hidden_size = hidden_size
self.dropout_p = dropout_p
self.max_length = max_length
# 定义nn.Embedding层 nn.Embedding(4345,256)
self.embedding = nn.Embedding(self.output_size, self.hidden_size)
# 定义线性层1:求q的注意力权重分布
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
# 定义线性层2:q+注意力结果表示融合后,在按照指定维度输出
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)
# 定义dropout层
self.dropout = nn.Dropout(self.dropout_p)
# 定义gru层
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
# 定义out层 解码器按照类别进行输出(256,4345)
self.out = nn.Linear(self.hidden_size, self.output_size)
# 实例化softomax层 数值归一化 以便分类
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, encoder_outputs):
# input代表q [1,1] 二维数据 hidden代表k [1,1,256] encoder_outputs代表v [10,256]
# 数据经过词嵌入层
# 数据形状 [1,1] --> [1,1,256]
embedded = self.embedding(input)
# 使用dropout进行随机丢弃,防止过拟合
embedded = self.dropout(embedded)
# 1 求查询张量q的注意力权重分布, attn_weights[1,10]
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)
# 2 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,256]
# [1,1,10],[1,10,256] ---> [1,1,256]
attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
# 3 q 与 attn_applied 融合,再按照指定维度输出 output[1,1,256]
output = torch.cat((embedded[0], attn_applied[0]), 1)
output = self.attn_combine(output).unsqueeze(0)
# 查询张量q的注意力结果表示 使用relu激活
output = F.relu(output)
# 查询张量经过gru、softmax进行分类结果输出
# 数据形状[1,1,256],[1,1,256] --> [1,1,256], [1,1,256]
output, hidden = self.gru(output, hidden)
# 数据形状[1,1,256]->[1,256]->[1,4345]
output = self.softmax(self.out(output[0]))
# 返回解码器分类output[1,4345],最后隐层张量hidden[1,1,256] 注意力权重张量attn_weights[1,10]
return output, hidden, attn_weights
def inithidden(self):
# 将隐层张量初始化成为1x1xself.hidden_size大小的张量
return torch.zeros(1, 1, self.hidden_size, device=device)
- 调用
def dm_test_AttnDecoderRNN():
# 1 实例化 数据集对象
mypairsdataset = MyPairsDataset(my_pairs)
# 2 实例化 数据加载器对象
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化 编码器my_encoderrnn
my_encoderrnn = EncoderRNN(english_word_n, 256)
# 实例化 解码器DecoderRNN
my_attndecoderrnn = AttnDecoderRNN(french_word_n, 256)
# 3 遍历数据迭代器
for i, (x, y) in enumerate(mydataloader):
# 编码-方法1 一次性给模型送数据
hidden = my_encoderrnn.inithidden()
print('x--->', x.shape, x)
print('y--->', y.shape, y)
# [1, 6, 256], [1, 1, 256]) --> [1, 6, 256][1, 1, 256]
output, hidden = my_encoderrnn(x, hidden)
# print('output-->', output.shape, output)
# print('最后一个时间步取出output[0,-1]-->', output[0, -1].shape, output[0, -1])
# 中间语义张量C
encode_output_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size,device=device)
for idx in range(output.shape[1]):
encode_output_c[idx] = output[0, idx]
# # 编码-方法2 一个字符一个字符给模型送数据
# hidden = my_encoderrnn.inithidden()
# for i in range(x.shape[1]):
# tmp = x[0][i].view(1, -1)
# # [1, 1, 256], [1, 1, 256]) --> [1, 1, 256][1, 1, 256]
# output, hidden = my_encoderrnn(tmp, hidden)
# print('一个字符一个字符output', output.shape, output)
# 解码-必须一个字符一个字符的解码
for i in range(y.shape[1]):
tmp = y[0][i].view(1, -1)
output, hidden, attn_weights = my_attndecoderrnn(tmp, hidden, encode_output_c)
print('解码output.shape', output.shape )
print('解码hidden.shape', hidden.shape)
print('解码attn_weights.shape', attn_weights.shape)
break
- 输出效果:
x---> torch.Size([1, 7]) tensor([[ 129, 78, 1873, 294, 1215, 4, 1]])
y---> torch.Size([1, 6]) tensor([[ 210, 3097, 248, 3095, 5, 1]])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 10])4 构建模型训练函数, 并进行训练
1 teacher_forcing介绍
它是一种用于序列生成任务的训练技巧, 在seq2seq架构中, 根据循环神经网络理论,解码器每次应该使用上一步的结果作为输入的一部分, 但是训练过程中,一旦上一步的结果是错误的,就会导致这种错误被累积,无法达到训练效果, 因此,我们需要一种机制改变上一步出错的情况,因为训练时我们是已知正确的输出应该是什么,因此可以强制将上一步结果设置成正确的输出, 这种方式就叫做teacher_forcing.
2 teacher_forcing的作用
-
能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大.
-
teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳.
3 构建内部迭代训练函数
- 模型训练参数
# 模型训练参数
mylr = 1e-4
epochs = 2
# 设置teacher_forcing比率为0.5
teacher_forcing_ratio = 0.5
print_interval_num = 1000
plot_interval_num = 100
- 实现思路分析
# 内部迭代训练函数Train_Iters
# 1 编码 encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)
# 数据形状 eg [1,6],[1,1,256] --> [1,6,256],[1,1,256]
# 2 解码参数准备和解码
# 解码参数1 固定长度C encoder_outputs_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device)
# 解码参数2 decode_hidden # 解码参数3 input_y = torch.tensor([[SOS_token]], device=device)
# 数据形状数据形状 [1,1],[1,1,256],[10,256] ---> [1,4345],[1,1,256],[1,10]
# output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c)
# 计算损失 target_y = y[0][idx].view(1)
# 每个时间步处理 for idx in range(y_len): 处理三者之间关系input_y output_y target_y
# 3 训练策略 use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
# teacher_forcing 把样本真实值y作为下一次输入 input_y = y[0][idx].view(1, -1)
# not teacher_forcing 把预测值y作为下一次输入
# topv,topi = output_y.topk(1) # if topi.squeeze().item() == EOS_token: break input_y = topi.detach()
# 4 其他 # 计算损失 # 梯度清零 # 反向传播 # 梯度更新 # 返回 损失列表myloss.item()/y_len
- 编码实现
def Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss):
# 1 编码 encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)
encode_hidden = my_encoderrnn.inithidden()
encode_output, encode_hidden = my_encoderrnn(x, encode_hidden) # 一次性送数据
# [1,6],[1,1,256] --> [1,6,256],[1,1,256]
# 2 解码参数准备和解码
# 解码参数1 encode_output_c [10,256]
encode_output_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device)
for idx in range(x.shape[1]):
encode_output_c[idx] = encode_output[0, idx]
# 解码参数2
decode_hidden = encode_hidden
# 解码参数3
input_y = torch.tensor([[SOS_token]], device=device)
myloss = 0.0
y_len = y.shape[1]
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
for idx in range(y_len):
# 数据形状数据形状 [1,1],[1,1,256],[10,256] ---> [1,4345],[1,1,256],[1,10]
output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c)
target_y = y[0][idx].view(1)
myloss = myloss + mycrossentropyloss(output_y, target_y)
input_y = y[0][idx].view(1, -1)
else:
for idx in range(y_len):
# 数据形状数据形状 [1,1],[1,1,256],[10,256] ---> [1,4345],[1,1,256],[1,10]
output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c)
target_y = y[0][idx].view(1)
myloss = myloss + mycrossentropyloss(output_y, target_y)
topv, topi = output_y.topk(1)
if topi.squeeze().item() == EOS_token:
break
input_y = topi.detach()
# 梯度清零
myadam_encode.zero_grad()
myadam_decode.zero_grad()
# 反向传播
myloss.backward()
# 梯度更新
myadam_encode.step()
myadam_decode.step()
# 返回 损失列表myloss.item()/y_len
return myloss.item() / y_len4 构建模型训练函数
- 实现思路分析
# Train_seq2seq() 思路分析
# 实例化 mypairsdataset对象 实例化 mydataloader
# 实例化编码器 my_encoderrnn 实例化解码器 my_attndecoderrnn
# 实例化编码器优化器 myadam_encode 实例化解码器优化器 myadam_decode
# 实例化损失函数 mycrossentropyloss = nn.NLLLoss()
# 定义模型训练的参数
# epoches mylr=1e4 teacher_forcing_ratio print_interval_num plot_interval_num (全局)
# plot_loss_list = [] (返回) print_loss_total plot_loss_total starttime (每轮内部)
# 外层for循环 控制轮数 for epoch_idx in range(1, 1+epochs):
# 内层for循环 控制迭代次数 # for item, (x, y) in enumerate(mydataloader, start=1):
# 调用内部训练函数 Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss)
# 计算辅助信息
# 计算打印屏幕间隔损失-每隔1000次 # 计算画图间隔损失-每隔100次
# 每个轮次保存模型 torch.save(my_encoderrnn.state_dict(), PATH1)
# 所有轮次训练完毕 画损失图 plt.figure() .plot(plot_loss_list) .save('x.png') .show()
- 编码实现
def Train_seq2seq():
# 实例化 mypairsdataset对象 实例化 mydataloader
mypairsdataset = MyPairsDataset(my_pairs)
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化编码器 my_encoderrnn 实例化解码器 my_attndecoderrnn
my_encoderrnn = EncoderRNN(2803, 256)
my_attndecoderrnn = AttnDecoderRNN(output_size=4345, hidden_size=256, dropout_p=0.1, max_length=10)
# 实例化编码器优化器 myadam_encode 实例化解码器优化器 myadam_decode
myadam_encode = optim.Adam(my_encoderrnn.parameters(), lr=mylr)
myadam_decode = optim.Adam(my_attndecoderrnn.parameters(), lr=mylr)
# 实例化损失函数 mycrossentropyloss = nn.NLLLoss()
mycrossentropyloss = nn.NLLLoss()
# 定义模型训练的参数
plot_loss_list = []
# 外层for循环 控制轮数 for epoch_idx in range(1, 1+epochs):
for epoch_idx in range(1, 1+epochs):
print_loss_total, plot_loss_total = 0.0, 0.0
starttime = time.time()
# 内层for循环 控制迭代次数
for item, (x, y) in enumerate(mydataloader, start=1):
# 调用内部训练函数
myloss = Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss)
print_loss_total += myloss
plot_loss_total += myloss
# 计算打印屏幕间隔损失-每隔1000次
if item % print_interval_num ==0 :
print_loss_avg = print_loss_total / print_interval_num
# 将总损失归0
print_loss_total = 0
# 打印日志,日志内容分别是:训练耗时,当前迭代步,当前进度百分比,当前平均损失
print('轮次%d 损失%.6f 时间:%d' % (epoch_idx, print_loss_avg, time.time() - starttime))
# 计算画图间隔损失-每隔100次
if item % plot_interval_num == 0:
# 通过总损失除以间隔得到平均损失
plot_loss_avg = plot_loss_total / plot_interval_num
# 将平均损失添加plot_loss_list列表中
plot_loss_list.append(plot_loss_avg)
# 总损失归0
plot_loss_total = 0
# 每个轮次保存模型
torch.save(my_encoderrnn.state_dict(), './my_encoderrnn_%d.pth' % epoch_idx)
torch.save(my_attndecoderrnn.state_dict(), './my_attndecoderrnn_%d.pth' % epoch_idx)
# 所有轮次训练完毕 画损失图
plt.figure()
plt.plot(plot_loss_list)
plt.savefig('./s2sq_loss.png')
plt.show()
return plot_loss_list
- 输出效果
轮次1 损失8.123402 时间:4
轮次1 损失6.658305 时间:8
轮次1 损失5.252497 时间:12
轮次1 损失4.906939 时间:16
轮次1 损失4.813769 时间:19
轮次1 损失4.780460 时间:23
轮次1 损失4.621599 时间:27
轮次1 损失4.487508 时间:31
轮次1 损失4.478538 时间:35
轮次1 损失4.245148 时间:39
轮次1 损失4.602579 时间:44
轮次1 损失4.256789 时间:48
轮次1 损失4.218111 时间:52
轮次1 损失4.393134 时间:56
轮次1 损失4.134959 时间:60
轮次1 损失4.164878 时间:635 损失曲线分析
损失下降曲线
一直下降的损失曲线, 说明模型正在收敛, 能够从数据中找到一些规律应用于数据.
5 构建模型评估函数并测试
1 构建模型评估函数
# 模型评估代码与模型预测代码类似,需要注意使用with torch.no_grad()
# 模型预测时,第一个时间步使用SOS_token作为输入 后续时间步采用预测值作为输入,也就是自回归机制
def Seq2Seq_Evaluate(x, my_encoderrnn, my_attndecoderrnn):
with torch.no_grad():
# 1 编码:一次性的送数据
encode_hidden = my_encoderrnn.inithidden()
encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)
# 2 解码参数准备
# 解码参数1 固定长度中间语义张量c
encoder_outputs_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device)
x_len = x.shape[1]
for idx in range(x_len):
encoder_outputs_c[idx] = encode_output[0, idx]
# 解码参数2 最后1个隐藏层的输出 作为 解码器的第1个时间步隐藏层输入
decode_hidden = encode_hidden
# 解码参数3 解码器第一个时间步起始符
input_y = torch.tensor([[SOS_token]], device=device)
# 3 自回归方式解码
# 初始化预测的词汇列表
decoded_words = []
# 初始化attention张量
decoder_attentions = torch.zeros(MAX_LENGTH, MAX_LENGTH)
for idx in range(MAX_LENGTH): # note:MAX_LENGTH=10
output_y, decode_hidden, attn_weights = my_attndecoderrnn(input_y, decode_hidden, encoder_outputs_c)
# 预测值作为为下一次时间步的输入值
topv, topi = output_y.topk(1)
decoder_attentions[idx] = attn_weights
# 如果输出值是终止符,则循环停止
if topi.squeeze().item() == EOS_token:
decoded_words.append('<EOS>')
break
else:
decoded_words.append(french_index2word[topi.item()])
# 将本次预测的索引赋值给 input_y,进行下一个时间步预测
input_y = topi.detach()
# 返回结果decoded_words, 注意力张量权重分布表(把没有用到的部分切掉)
return decoded_words, decoder_attentions[:idx + 1]2 模型评估函数调用
# 加载模型
PATH1 = './gpumodel/my_encoderrnn.pth'
PATH2 = './gpumodel/my_attndecoderrnn.pth'
def dm_test_Seq2Seq_Evaluate():
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_encoderrnn = EncoderRNN(input_size, hidden_size)
# my_encoderrnn.load_state_dict(torch.load(PATH1))
my_encoderrnn.load_state_dict(torch.load(PATH1, map_location=lambda storage, loc: storage), False)
print('my_encoderrnn模型结构--->', my_encoderrnn)
# 实例化模型
input_size = french_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size)
# my_attndecoderrnn.load_state_dict(torch.load(PATH2))
my_attndecoderrnn.load_state_dict(torch.load(PATH2, map_location=lambda storage, loc: storage), False)
print('my_decoderrnn模型结构--->', my_attndecoderrnn)
my_samplepairs =
[
['i m impressed with your french .', 'je suis impressionne par votre francais .'],
['i m more than a friend .', 'je suis plus qu une amie .'],
['she is beautiful like her mother .', 'elle est belle comme sa mere .']
]
print('my_samplepairs--->', len(my_samplepairs))
for index, pair in enumerate(my_samplepairs):
x = pair[0]
y = pair[1]
# 样本x 文本数值化
tmpx = [english_word2index[word] for word in x.split(' ')]
tmpx.append(EOS_token)
tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)
# 模型预测
decoded_words, attentions = Seq2Seq_Evaluate(tensor_x, my_encoderrnn, my_attndecoderrnn)
# print('decoded_words->', decoded_words)
output_sentence = ' '.join(decoded_words)
print('\n')
print('>', x)
print('=', y)
print('<', output_sentence)
- 输出效果:
> i m impressed with your french .
= je suis impressionne par votre francais .
< je suis impressionnee par votre francais . <EOS>
> i m more than a friend .
= je suis plus qu une amie .
< je suis plus qu une amie . <EOS>
> she is beautiful like her mother .
= elle est belle comme sa mere .
< elle est sa sa mere . <EOS>
> you re winning aren t you ?
= vous gagnez n est ce pas ?
< tu restez n est ce pas ? <EOS>
> he is angry with you .
= il est en colere apres toi .
< il est en colere apres toi . <EOS>
> you re very timid .
= vous etes tres craintifs .
< tu es tres craintive . <EOS>3 Attention张量制图
def dm_test_Attention():
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_encoderrnn = EncoderRNN(input_size, hidden_size)
# my_encoderrnn.load_state_dict(torch.load(PATH1))
my_encoderrnn.load_state_dict(torch.load(PATH1, map_location=lambda storage, loc: storage), False)
# 实例化模型
input_size = french_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size)
# my_attndecoderrnn.load_state_dict(torch.load(PATH2))
my_attndecoderrnn.load_state_dict(torch.load(PATH2, map_location=lambda storage, loc: storage), False)
sentence = "we re both teachers ."
# 样本x 文本数值化
tmpx = [english_word2index[word] for word in sentence.split(' ')]
tmpx.append(EOS_token)
tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)
# 模型预测
decoded_words, attentions = Seq2Seq_Evaluate(tensor_x, my_encoderrnn, my_attndecoderrnn)
print('decoded_words->', decoded_words)
# print('\n')
# print('英文', sentence)
# print('法文', output_sentence)
plt.matshow(attentions.numpy()) # 以矩阵列表的形式 显示
# 保存图像
plt.savefig("./s2s_attn.png")
plt.show()
print('attentions.numpy()--->\n', attentions.numpy())
print('attentions.size--->', attentions.size())
- 输出效果:
decoded_words-> ['nous', 'sommes', 'toutes', 'deux', 'enseignantes', '.', '<EOS>']
- Attention可视化:
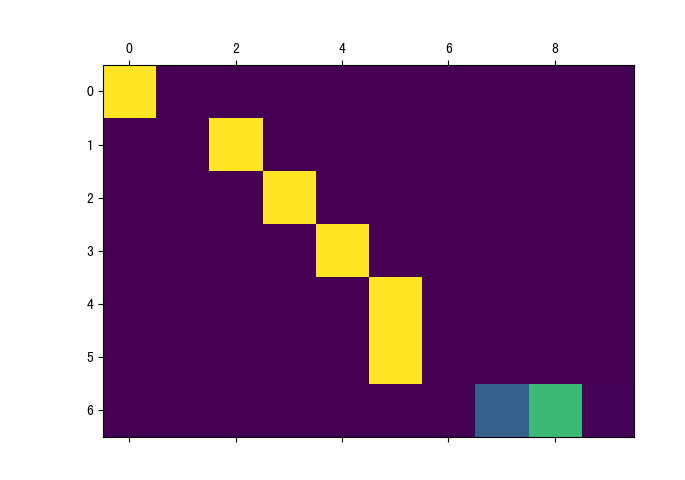
- Attention图像的纵坐标代表输入的源语言各个词汇对应的索引, 0-6分别对应"we", "re", "both", "teachers", ".", "", 纵坐标代表生成的目标语言各个词汇对应的索引, 0-7代表'nous', 'sommes', 'toutes', 'deux', 'enseignantes', '.', '', 图中浅色小方块(颜色越浅说明影响越大)代表词汇之间的影响关系, 比如源语言的第1个词汇对生成目标语言的第1个词汇影响最大, 源语言的第4,5个词对生成目标语言的第5个词会影响最大, 通过这样的可视化图像, 我们可以知道Attention的效果好坏, 与我们人为去判定到底还有多大的差距. 进而衡量我们训练模型的可用性.
4 小结
- seq2seq模型架构分析
- seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。其中编码器和解码器的内部实现都使用了GRU模型
- 基于GRU的seq2seq模型架构实现翻译的过程
- 第一步: 导入必备的工具包和工具函数
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求
- 第三步: 构建基于GRU的编码器和解码器
- 第四步: 构建模型训练函数, 并进行训练
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析
- 第一步: 导入必备的工具包
- python版本使用3.6.x, pytorch版本使用1.3.1
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求
- 清洗文本和构建文本字典、构建数据源、构建数据迭代器。文本处理的本质就是根据任务构建标签x、标签y
- 第三步: 构建基于GRU的编码器和解码器
- 构建基于GRU的编码器
- 构建基于GRU的解码器
- 构建基于GRU和Attention的解码器
- 第四步: 构建模型训练函数, 并进行训练
- 什么是teacher_forcing: 它是一种用于序列生成任务的训练技巧, 在seq2seq架构中, 根据循环神经网络理论,解码器每次应该使用上一步的结果作为输入的一部分, 但是训练过程中,一旦上一步的结果是错误的,就会导致这种错误被累积,无法达到训练效果, 因此,我们需要一种机制改变上一步出错的情况,因为训练时我们是已知正确的输出应该是什么,因此可以强制将上一步结果设置成正确的输出, 这种方式就叫做teacher_forcing
- teacher_forcing的作用: 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大. 另外, teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳
- 构建训练函数train
- 调用训练函数并打印日志和制图
- 损失曲线分析: 一直下降的损失曲线, 说明模型正在收敛, 能够从数据中找到一些规律应用于数据
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析
- 构建模型评估函数evaluate
- 随机选择指定数量的数据进行评估
- 进行了Attention可视化分析
神经网络结果
输入层---------------------------隐藏层-----------------------------------------输出层
文本→ RNN循环神经网络【掌握】 没有太多的变化
分词→ LSTM【理解】
词向量→ GRU
文本张量 Seq2Seq架构
注意力机制【熟悉】
文本数据分析
特征预处理(n-gram、长度规范)
长度:句子中词的个数