记忆系统:为什么向量数据库不够用

你问 Agent:"我们项目用的什么数据库连接池?"
Agent 回答了一段关于 Redis 连接池的文档。技术上没错,但你问的是 MySQL。
它找到了"相似"的内容,但没有"理解"你的问题。
一、一个关于"记忆"的哲学问题
先问一个根本问题:什么是记忆?
人类的记忆不是一堆"相似文本的检索结果"。你记得"张三上次开会说要把数据库从 MySQL 换成 PostgreSQL",你的大脑不是把这句话存成一个向量,而是建立了一整套关联:
- 张三 → 同事 → 后端组 → 负责数据库
- MySQL → 当前在用 → 生产环境 → 连接池配置 20
- PostgreSQL → 要切换 → 需要改连接池 → 可能影响 ORM
- 开会 → 上周三 → 会议室 → 有会议纪要
这些关联形成了一个结构化的认知网络 。当你回忆时,你不是在做"语义搜索",而是在网络上跳转------从"张三"跳到"数据库",再跳到"连接池配置"。
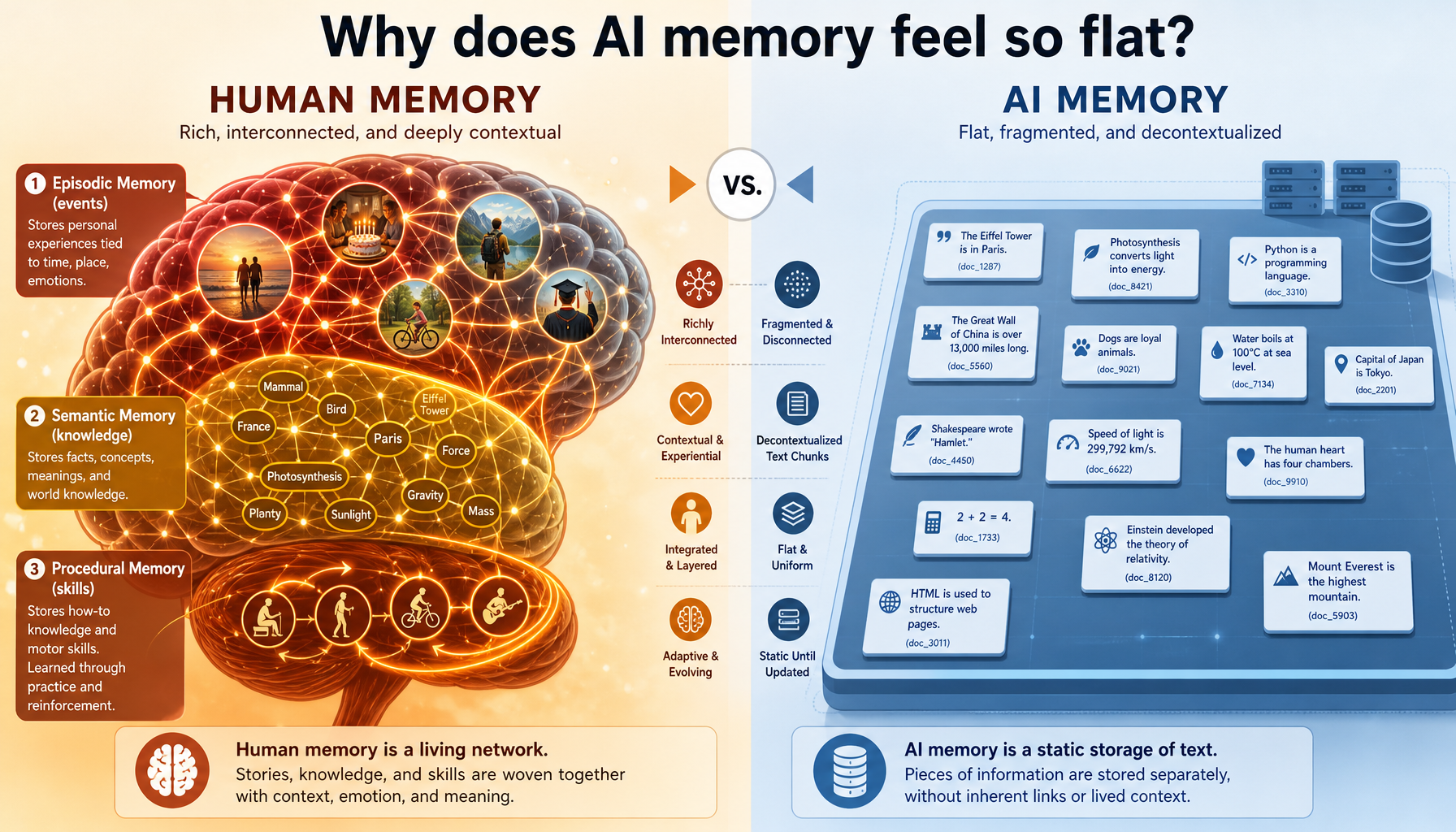
现在看 AI 的"记忆":
文档切片 → Embedding → 存入向量数据库
查询 → Embedding → 找 Top-5 相似结果所有信息都是扁平的。"张三说换数据库"和"数据库连接池配置"之间没有任何关联。每次查询都是独立的,没有"跳转"能力。
这不是记忆,这是高级搜索。
二、RAG 的三个天花板
天花板一:只有"匹配",没有"理解"
你问:"如果把 MySQL 换成 PostgreSQL,需要改哪些配置?"
RAG 做的事:把问题向量化,找 Top-5 相似文本块。
返回的可能是:
- 一段关于 Redis 连接池的文档(向量距离 0.87)
- 一段关于 MySQL 最佳实践(向量距离 0.85)
- 一段关于 PostgreSQL 安装指南(向量距离 0.82)
哪个才是你要的? RAG 不知道。它只知道这些文本和你的问题"语义相似"。
天花板二:没有"结构",只有"碎片"
所有文本块都是独立的碎片。它不知道:
- 这段配置属于哪个服务
- 这个服务部署在哪个环境
- 这个环境依赖哪些基础设施
你问"生产环境的数据库配置是什么",它可能返回测试环境的配置------因为两者在向量空间里很近。
天花板三:只能"检索",不能"推理"
你问:"修改用户表的字段会影响哪些接口?"
RAG 做不到。因为它没有建立"表 → 模型 → 接口"的关系链。要回答这个问题,需要多跳推理:
用户表 → 被 UserService 依赖 → UserService 提供注册/登录接口 → 接口返回字段包含用户表字段这不是搜索能解决的,需要图上的推理。
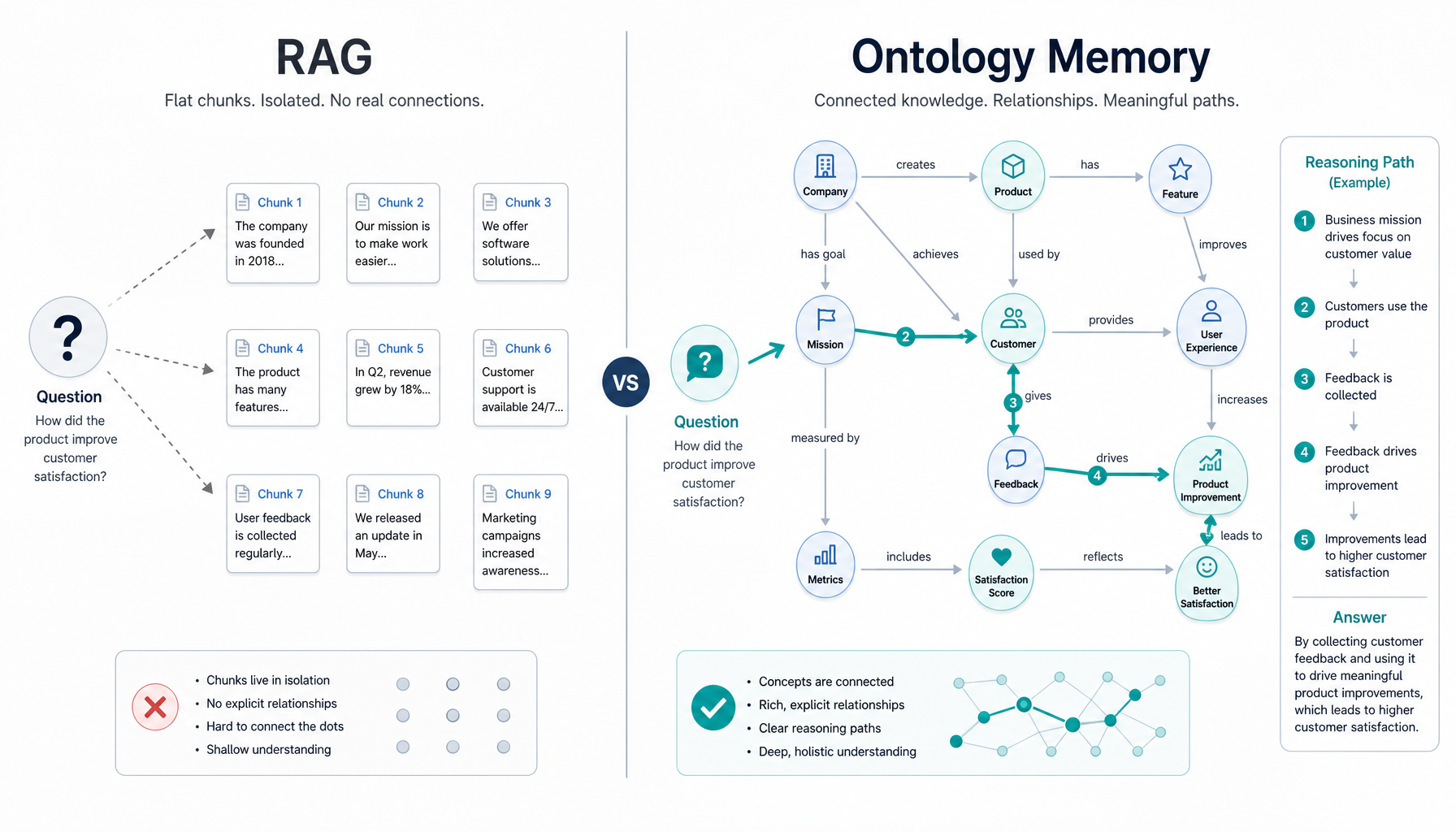
三、本体论:不只是知识图谱
很多人听到"本体论"就想到"知识图谱"。但本体论能存储的信息远不止实体和关系。
3.1 本体论能存什么?
| 信息类型 | 示例 | 存储方式 |
|---|---|---|
| 实体 | 用户、服务、数据库、配置项 | 节点 |
| 关系 | 调用、依赖、属于、部署 | 边 |
| 动作 | 创建、修改、删除、部署 | 带类型的边 |
| 规则 | "配置项必须属于服务" | T-Box 约束 |
| 偏好 | "张三偏好用 Redis" | 用户属性 |
| 历史 | "上周三张三说要换数据库" | 时间戳 + 来源 |
| 项目上下文 | "当前项目用的 MySQL 8.0" | 项目级隔离 |
本体论是一个多维的信息容器,不只是"实体-关系-实体"的三元组。
3.2 T-Box 与 A-Box:规则与事实
Symbio 的记忆系统把本体论拆成两层:
T-Box(规则层)------ 世界的运行规则
规则1:代码组件必然有调用关系
规则2:配置项必然属于某个服务
规则3:服务必然部署在某个环境
规则4:用户对依赖包必然有偏好等级
规则5:动作必然有执行者和时间戳这些规则是预定义的、不可变的。就像物理学定律------你不能改变万有引力,但你可以在万有引力的约束下描述任何物理现象。
A-Box(事实层)------ 具体发生了什么
事实1:AuthService 调用了 UserDatabase(关系)
事实2:UserDatabase 的连接池配置是 20(属性)
事实3:UserDatabase 部署在生产集群(关系)
事实4:张三偏好使用 redis 5.0(偏好)
事实5:2026-05-28 张三说要换数据库(历史)这些事实是动态生成的、可更新的。每当有新的代码、文档、对话进来,系统自动抽取新的事实。
3.3 零 Token 推理
本体论记忆系统还有一个杀手级特性:推理不消耗 LLM Token。
RAG 查询: 用户问题 → Embedding → Top-K → LLM 整合 → 回答
Token 消耗: ~3000
图谱推理: 用户问题 → 实体识别 → 图上跳转 → 结果
Token 消耗: ~0同样的问题,图谱推理的 Token 消耗是 RAG 的十分之一。
3.4 本体论 vs GraphRAG:本质区别
看到这里,你可能会问:"这和微软的 GraphRAG 有什么区别?"
GraphRAG 是当前行业最火的概念之一------从文档中自动抽取实体和关系,构建知识图谱,然后基于图谱做检索增强生成。听起来和本体论很像?但本质区别巨大:
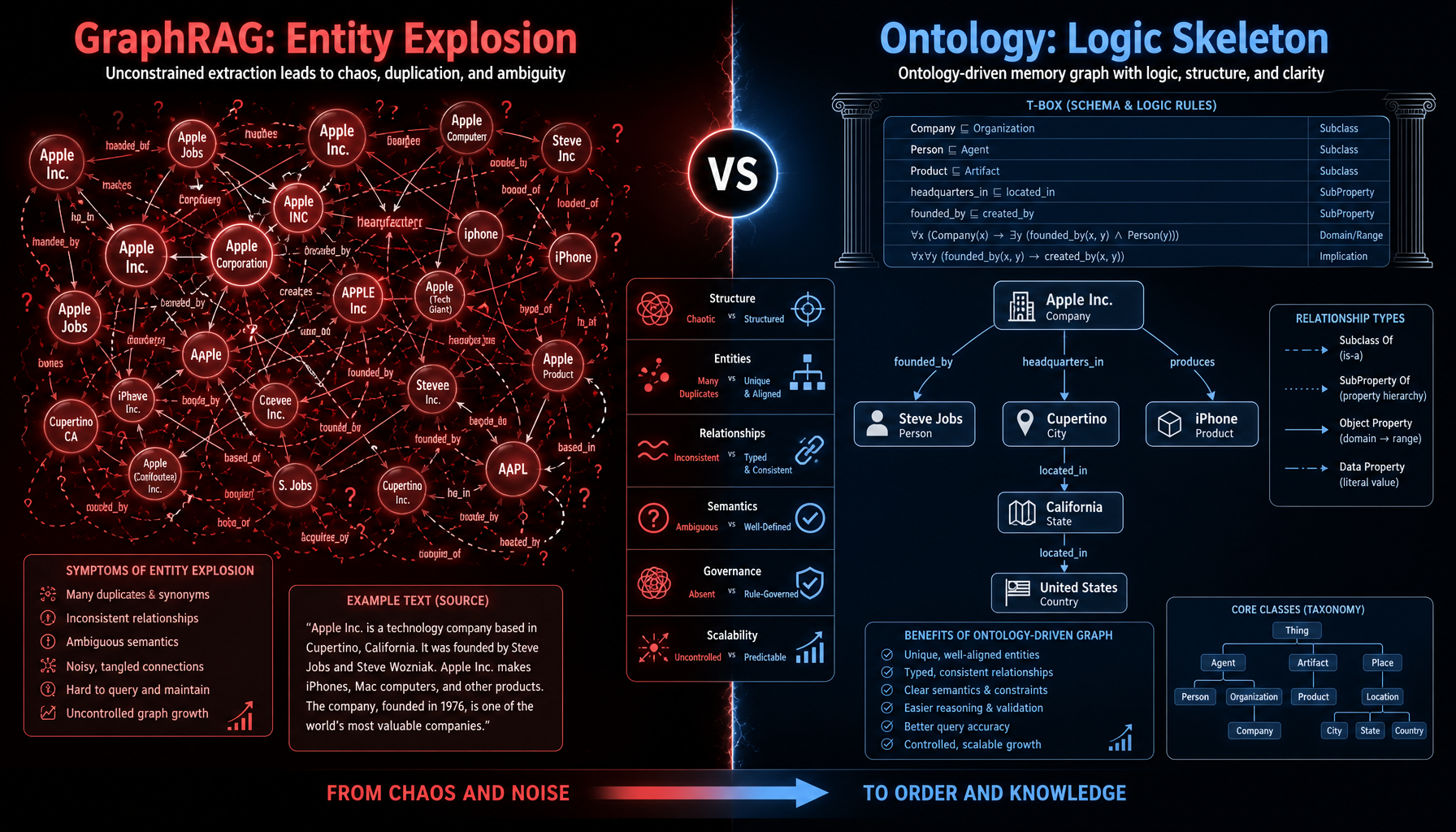
| 维度 | 传统 GraphRAG | Symbio 本体论 |
|---|---|---|
| 实体抽取 | 盲目抓取,无约束 | T-Box 规则约束,只抽取合法实体 |
| 同义词处理 | 几乎不做,导致冗余 | T-Box 定义实体类型,自动对齐 |
| 关系质量 | 噪音极高,大量无意义关系 | A-Box 只存储符合 T-Box 规则的关系 |
| 推理方式 | 依赖 LLM 整合图谱上下文 | 零 Token 确定性图遍历 |
| 可控性 | 黑盒,抽取结果不可预测 | 白盒,T-Box 规则可审计可修改 |
传统 GraphRAG 的三大痛点:
- 实体爆炸:从一篇文档中可能抽取出上千个实体,其中大量是噪音("Python"、"API"、"数据库"这类泛化实体无处不在)
- 同义词冗余:"MySQL"、"mysql"、"MYSQL"、"MySQL 8.0"、"my database" 被当成五个不同的实体
- 关系噪音:"A 和 B 出现在同一段话中" 被错误地建模为 "A 关联 B"
Symbio 的解法:给 GraphRAG 穿上"逻辑骨架"
T-Box 就是这个骨架。它预定义了:
- 哪些实体类型是合法的(component、service、database、config)
- 哪些关系类型是合法的(calls、depends_on、belongs_to)
- 实体之间的基数约束(一个配置项只能属于一个服务)
在这个骨架的约束下,实体抽取不再是"盲目抓取",而是"有目标的识别"。同义词在 T-Box 层就被合并了("MySQL" 和 "mysql" 是同一个实体)。关系只在符合 T-Box 规则时才被创建。
本质上,GraphRAG 是"先抽取再整理",本体论是"先定义规则再抽取"。前者是事后纠错,前者是源头治理。
四、记忆分类:Agent 需要哪些记忆?
人类有多种记忆系统(情景记忆、语义记忆、程序记忆),Agent 也需要不同类别的记忆。
4.1 Symbio 的记忆分类
| 记忆类型 | 存什么 | 生命周期 | 存储方式 |
|---|---|---|---|
| 项目记忆 | 当前项目的配置、架构、依赖关系 | 项目级 | 本体论图谱 |
| 对话记忆 | 当前对话的上下文和历史 | 会话级 | 向量数据库(LanceDB) |
| 程序记忆 | SOP、最佳实践、成功模式 | 永久 | 本体论图谱 |
| 情景记忆 | 过去的执行轨迹和经验 | 可衰减 | 向量数据库 + 时序索引 |
| 语义记忆 | 通用知识、领域概念 | 永久 | 本体论图谱 |
4.2 项目记忆:每个项目是独立的"记忆宇宙"
这是 Symbio 的一个关键设计------项目级记忆隔离。
项目A 的记忆宇宙:
├── 本体论图谱(项目A的实体和关系)
├── LanceDB 表(项目A的向量索引)
├── 配置空间(项目A的模型选择、工具权限)
└── 数据目录(项目A的文件和轨迹)
项目B 的记忆宇宙:
├── 本体论图谱(项目B的实体和关系)
├── LanceDB 表(项目B的向量索引)
├── 配置空间(项目B的模型选择、工具权限)
└── 数据目录(项目B的文件和轨迹)为什么需要项目级隔离?
- 不同项目的上下文完全不同(项目A用 MySQL,项目B用 PostgreSQL)
- 项目的记忆不应该互相污染
- 项目可以独立导入/导出/备份/恢复
4.3 项目关联:隔离但不孤立
项目记忆是隔离的,但项目之间不是孤立的。
现实中的项目往往有千丝万缕的联系:
项目A(用户中心)
│
├── 提供 API → 项目B(订单系统)
├── 共享数据库 → 项目C(支付系统)
├── 同一团队维护 → 项目D(消息中心)
└── 替代了 → 项目E(旧用户系统,已废弃)项目关联的几种类型:
| 关联类型 | 示例 | 价值 |
|---|---|---|
| 依赖关系 | 项目B依赖项目A的API | 项目A的接口变更会影响项目B |
| 共享资源 | 项目A和C共享同一个数据库 | 数据库配置经验可以复用 |
| 团队关联 | 项目A和D是同一个团队 | 团队的技术栈偏好可以共享 |
| 演进关系 | 项目A替代了项目E | 项目E的教训可以指导项目A |
| 技术关联 | 项目A和B都用了 Redis | Redis 的最佳实践可以跨项目共享 |
Symbio 的方案:项目图谱(Project Graph)
在项目记忆之上,维护一个项目级的关联图谱:
┌─────────────────────────────────────────────┐
│ 项目关联图谱 │
│ │
│ 项目A ──depends_on──→ 项目B │
│ │ │ │
│ shares_db uses_redis │
│ │ │ │
│ ↓ ↓ │
│ 项目C 项目D │
│ │
│ 项目A ──replaced──→ 项目E (archived) │
│ │
└─────────────────────────────────────────────┘跨项目知识迁移:当 Agent 在项目B中遇到数据库问题时,它可以查询项目关联图谱,发现"项目A和B共享数据库",然后从项目A的记忆中检索相关的数据库配置经验。
这不是打破隔离,而是在隔离之上建立受控的连接。
4.4 LanceDB:为什么选它做向量存储?
Symbio 用 LanceDB 作为向量存储,而不是更常见的 FAISS 或 Pinecone。
| 特性 | FAISS | Pinecone | LanceDB |
|---|---|---|---|
| 本地运行 | ✅ | ❌(云服务) | ✅ |
| 嵌入式 | ❌ | ❌ | ✅(直接嵌入 Python) |
| 向量 + 结构化数据 | ❌ | 部分 | ✅(原生支持) |
| 事务支持 | ❌ | ✅ | ✅ |
| 零配置 | ❌ | ❌ | ✅ |
| 成本 | 免费 | 按量付费 | 免费 |
LanceDB 的核心优势 :它不只是一个向量数据库,而是一个多模态数据湖。你可以同时存储向量、结构化数据、文件,用统一的接口查询。
4.5 多模态记忆:不只是文本
前面讲的都是文本记忆。但现实世界的信息不只是文字------还有图片、音频、视频、代码、表格。
你的 Agent 需要记住的,远不止文字:
| 信息类型 | 示例 | 记忆方式 |
|---|---|---|
| 文本 | 对话、文档、日志 | 向量 Embedding + 本体论 |
| 图片 | 架构图、UI 截图、错误截图 | 视觉 Embedding(CLIP) |
| 代码 | 函数、类、配置文件 | AST 解析 + 语义 Embedding |
| 表格 | Excel、数据库表 | 结构化存储 + 列语义 |
| 音频 | 会议录音、语音指令 | Whisper 转写 → 文本记忆 |
| 视频 | 操作录屏、演示视频 | 关键帧提取 + 场景描述 |
多模态记忆的价值:当你问"我们的系统架构是什么样的",Agent 不只能返回文字描述,还能直接展示架构图。当你问"连接池怎么配的",Agent 不只能告诉你数字,还能展示对应的代码片段。
记忆不只是"知道什么",更是"能展示什么"。
五、记忆冲突解决:新旧信息矛盾怎么办
记忆不是只增不减的。当新信息和旧信息矛盾时,系统必须做出选择。这个问题在人类大脑中同样存在------你记得"张三说要换数据库",也记得"李四说不换了",你该相信谁?
5.1 冲突的三种类型
类型一:时间冲突(最常见)
第 1 天: 用户说 "我们项目用的 MySQL"
第 30 天: 用户说 "我们已经换成 PostgreSQL 了"两条记忆都是"真实的"------第 1 天确实用的 MySQL,第 30 天确实换了。但查询"项目用的什么数据库"时,系统应该返回最新的。
类型二:来源冲突(最棘手)
张三说: "这个接口的超时时间是 10 秒"
李四说: "这个接口的超时时间是 30 秒"两个人说了矛盾的话。谁是对的?还是两个都对(不同环境不同配置)?
类型三:隐式冲突(最隐蔽)
记忆1: "项目A依赖项目B的用户服务"
记忆2: "项目B的用户服务已经下线了"两条记忆单独看都没问题,但组合起来意味着"项目A的依赖已经断了"。这种冲突需要推理才能发现。
5.2 Symbio 的四层冲突解决机制
第一层:时间戳优先
每条记忆都有精确的时间戳。当发生直接冲突时(同一实体的同一属性被更新),默认采用最新的值:
记忆 v1: "项目用的 MySQL" [2026-01-01, 用户A] → 标记为历史版本
记忆 v2: "项目用的 PostgreSQL" [2026-01-30, 用户A] → 标记为当前版本旧记忆不删除------它仍然是历史事实,在"项目历史查询"场景下仍有价值。
第二层:来源可信度加权
不同来源的信息可信度不同:
| 来源 | 可信度 | 理由 |
|---|---|---|
| 代码/配置文件 | 最高 | 是"事实",不是"意见" |
| 管理员/负责人 | 高 | 有决策权 |
| 普通用户 | 中 | 可能了解不全面 |
| Agent 自己推断 | 低 | 可能有幻觉 |
| 外部文档 | 中 | 可能过时 |
当两个来源冲突时,优先相信可信度更高的。
第三层:因果推理检测隐式冲突
对于隐式冲突(需要推理才能发现的矛盾),Symbio 会定期执行"一致性检查":
遍历所有记忆 → 构建依赖图 → 检测断链/矛盾
发现: "项目A依赖项目B的用户服务" + "用户服务已下线" → 冲突!
处理: 标记项目A的状态为"依赖异常",通知用户第四层:用户确认机制
当系统无法自动解决冲突时,主动询问用户:
Agent: "我发现了一个矛盾:
- 张三上周说接口超时是 10 秒
- 李四这周说接口超时是 30 秒
请问哪个是对的?还是不同环境不同配置?"5.3 版本化记忆的优势
Symbio 的所有记忆都是版本化的------每次更新都保留历史版本,而不是覆盖。
实体: API超时配置
├── v1: 10秒 [2026-01-01, 张三] ← 历史版本
├── v2: 30秒 [2026-01-15, 李四] ← 当前版本
└── 变更原因: "并发量增大,需要更长超时"版本化记忆的价值:
- 可追溯:任何时候都能查到"这个配置是怎么变过来的"
- 可回滚:发现新配置有问题时,可以快速回退到旧版本
- 可审计:满足合规要求,知道"谁在什么时候改了什么"
六、遗忘策略:不是所有记忆都值得保留
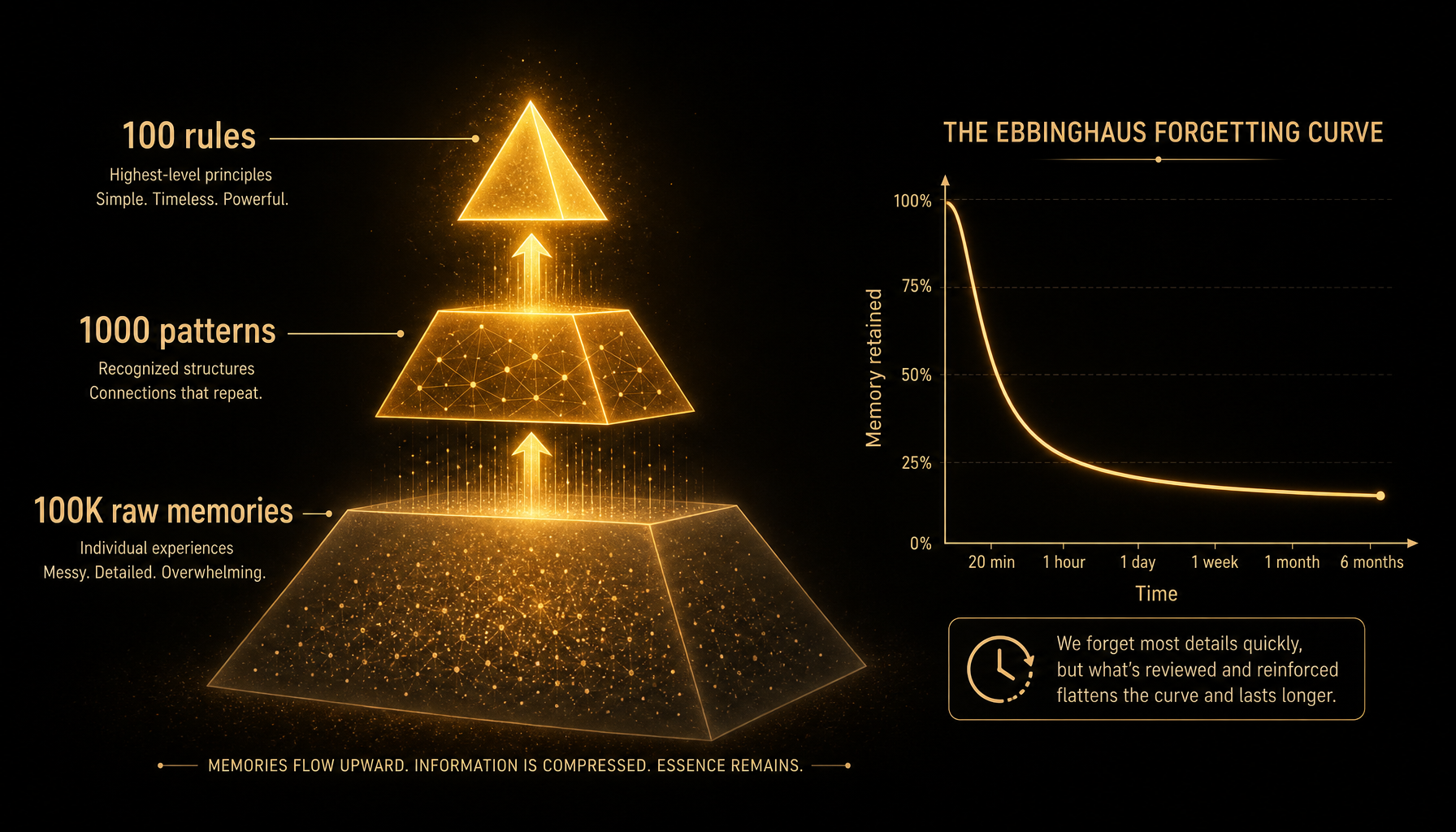
人类大脑有一个精妙的机制:遗忘 。你不会记住 10 年前每一天穿了什么衣服,但你会记住 10 年前的重要事件。这不是缺陷,而是进化出来的信息压缩策略。
6.1 艾宾浩斯遗忘曲线的启示
1885 年,德国心理学家艾宾浩斯发现了遗忘曲线:
记忆保持率
100% ┤●
│ ╲
80% ┤ ╲
│ ╲
60% ┤ ╲
│ ╲
40% ┤ ╲
│ ╲────
20% ┤ ╲──────────
│
0% ┼─────────────────────────────────→ 时间
0 1天 1周 1月 3月 1年关键发现 :遗忘不是线性的,而是指数衰减的。前几天衰减最快,之后趋于平稳。
对 Agent 记忆系统的启示:
- 刚存入的记忆应该有最高权重
- 长时间未被访问的记忆应该逐渐降权
- 但被反复访问的记忆应该被"巩固",不容易被遗忘
6.2 软遗忘 vs 硬遗忘
软遗忘:不删除,只是降低权重。记忆还在,但不会被优先检索。
记忆: "项目A用的是MySQL 5.7" ← 3年前的信息
权重: 0.1(被降权了)
状态: 存在但不活跃
触发条件: 超过 90 天未被访问硬遗忘:彻底删除,不可恢复。
记忆: "用户的密码是 abc123" ← 敏感信息
操作: 立即删除,不留痕迹
触发条件: 检测到 PII(个人身份信息)大多数情况用软遗忘------信息可能在某些场景下仍有价值。只有敏感信息才用硬遗忘。
6.3 硬遗忘的工程难度:不是删个节点那么简单
很多人以为硬遗忘就是"删除一条记录"。但在一个复杂的记忆系统中,彻底抹除一个实体远比想象中困难。
难点一:级联删除
一个实体可能被多个其他实体引用。比如"UserDatabase"被 AuthService、OrderService、PaymentService 三个服务依赖。删除 UserDatabase 时,这些依赖关系怎么处理?
Symbio 的方案:自动遍历 NetworkX 图库中所有引用该实体的边,级联切断关联边,并标记受影响的实体为"依赖异常"。
难点二:向量索引重构
LanceDB 中的向量索引不是简单的"删一行"。向量索引是基于空间划分构建的(如 IVF、HNSW),删除一个向量后,索引结构需要部分重构才能保证查询性能。
Symbio 的方案:对 LanceDB 对应的 Chunk 进行物理标记删除(lazy delete),定期执行索引压缩重建,确保查询性能不退化。
难点三:缓存污染
即使删除了原始记忆,相关的缓存(Prompt Cache、语义缓存)中可能仍然保留着旧信息的影子。
Symbio 的方案:硬遗忘时同步清除所有关联缓存,确保"删除"是端到端的。
硬遗忘是企业级数据安全的底线,不是"nice to have"。
6.4 Symbio 的五层遗忘策略
| 层级 | 策略 | 触发条件 | 处理方式 |
|---|---|---|---|
| L1 | 时间衰减 | 记忆超过 N 天未被访问 | 权重 × 0.95^天数 |
| L2 | 热度巩固 | 记忆被频繁访问 | 权重提升,标记为"核心记忆" |
| L3 | 冲突覆盖 | 新信息与旧信息矛盾 | 旧记忆降权,新记忆获得高权重 |
| L4 | 隐私擦除 | 检测到敏感信息(PII) | 立即硬遗忘,不留痕迹 |
| L5 | 项目清理 | 项目被删除 | 删除该项目的所有记忆 |
6.4 遗忘的伦理考量
遗忘不只是技术问题,还是伦理问题:
- GDPR 合规:用户有权要求删除自己的数据("被遗忘权")
- 数据保留政策:某些行业(金融、医疗)有法定的数据保留期限
- 隐私保护:密码、密钥、个人信息必须及时擦除
Symbio 内置了隐私扫描器,自动检测记忆中的敏感信息(邮箱、手机号、身份证号、密钥等),发现后立即触发硬遗忘。
七、记忆压缩:碎片怎么变成认知?
记忆不是越多越好。当你积累了 10 万条碎片化的记忆时,检索效率会下降,噪音会增加。人类的大脑也在做同样的事情------你不会记住每一天的每一个细节,而是把重复的经验压缩成更高层的认知。
7.1 记忆的三个层次
就像数据有不同的抽象层次(字节 → 信息 → 知识 → 智慧),记忆也有不同的压缩层次:
┌─────────────────────────────────────────────────┐
│ 智慧层(Wisdom) │
│ "部署到生产环境前必须经过灰度验证" │
│ 来源: 压缩自 100+ 次部署经验 │
│ 检索频率: 极高 │
├─────────────────────────────────────────────────┤
│ 知识层(Knowledge) │
│ "K8s 部署必须设 resource limits" │
│ 来源: 压缩自 10+ 次失败部署 │
│ 检索频率: 高 │
├─────────────────────────────────────────────────┤
│ 信息层(Information) │
│ "第1次部署失败,Pod 被 OOMKilled,因为没设 limits" │
│ 来源: 单次事件记录 │
│ 检索频率: 中 │
├─────────────────────────────────────────────────┤
│ 数据层(Data) │
│ "kubectl logs 显示 exit code 137" │
│ 来源: 原始日志 │
│ 检索频率: 低(仅在排查时) │
└─────────────────────────────────────────────────┘越往上层,信息越精炼,检索频率越高,推理价值越大。
7.2 Symbio 的记忆压缩流水线
原始记忆(10万条事件记录)
↓ 阶段1: 聚类
相似事件分组(5000个聚类)
↓ 阶段2: 模式识别
发现重复出现的模式(1000个模式)
↓ 阶段3: 规则提炼
把模式抽象为规则(100条规则)
↓ 阶段4: 注入 T-Box
新规则成为系统的一部分
↓ 阶段5: 归档原始数据
原始碎片移到冷存储,不再高频检索压缩不是丢失信息,而是提炼规律。
7.3 压缩的触发条件
什么时候应该触发记忆压缩?
| 触发条件 | 说明 |
|---|---|
| 定时触发 | 每天凌晨执行一次压缩任务 |
| 阈值触发 | 记忆总数超过 10 万条时触发 |
| 事件触发 | 发现大量相似的失败事件时触发 |
| 手动触发 | 用户主动要求"整理记忆" |
7.4 压缩后的效果
| 指标 | 压缩前 | 压缩后 | 变化 |
|---|---|---|---|
| 记忆条数 | 100,000 | 1,100(100规则+1000模式) | -99% |
| 检索延迟 | 150ms | 12ms | -92% |
| 推理能力 | 低(只能找相似) | 高(可以应用规则) | 质变 |
| 存储占用 | 500MB | 15MB | -97% |
八、从对话中自动提取记忆:让 Agent 自己"长记性"

前面讲的记忆都需要主动构建 ------定义 T-Box、抽取 A-Box、维护图谱。但最好的记忆系统应该是自动生长的。你不需要告诉 Agent"请记住这个",它自己就能从对话中提取有价值的信息。
8.1 核心思想:对话即记忆
用户和 Agent 的每一次对话,都包含着有价值的信息,但这些信息是非结构化的、隐式的、混杂在噪音中的:
用户: "我们项目的数据库用的是 MySQL 8.0,连接池大小 20"
用户: "张三说下个月要升级到 PostgreSQL"
用户: "别用 Redis 做持久化,之前踩过坑"
用户: "部署到 K8s 的时候记得设置 resource limits"
用户: "今天天气怎么样" ← 这条不需要记住Agent 需要从这些对话中自动识别哪些是值得记忆的,哪些是噪音。
8.2 提取的四个阶段
阶段一:意图判断(是否值得记忆?)
用轻量分类器判断当前对话片段是否包含值得记忆的信息:
| 值得记忆 | 不值得记忆 |
|---|---|
| "我们用的 MySQL 8.0"(事实) | "今天天气怎么样"(一次性查询) |
| "张三说要换数据库"(计划) | "帮我写个排序算法"(通用操作) |
| "Redis 做持久化踩过坑"(经验) | "谢谢"(礼貌用语) |
| "连接池设 20"(配置) | "你好"(寒暄) |
判断特征:
- 持久性:这个信息未来还用得上吗?
- 独特性:这是项目/团队特有的,还是通用知识?
- 影响性:这个信息会影响后续决策吗?
阶段二:实体识别(提什么?)
从值得记忆的对话中提取结构化信息:
输入: "我们项目的数据库用的是 MySQL 8.0,连接池大小 20"
输出:
实体: MySQL 8.0 (type: database)
属性: 连接池大小 = 20
关系: 属于 → 当前项目
来源: 用户对话 [2026-05-29]阶段三:冲突检测(和已有记忆矛盾吗?)
提取出的新信息需要和已有记忆做对比:
- 如果是全新信息 → 直接写入
- 如果和已有信息一致 → 不重复写入(去重)
- 如果和已有信息矛盾 → 触发冲突解决机制(见第五章)
阶段四:写入记忆系统(存在哪?)
根据信息类型写入不同的记忆系统:
| 信息类型 | 写入位置 |
|---|---|
| 实体和关系 | 本体论图谱(A-Box) |
| 文本片段 | LanceDB(向量索引) |
| 规则和模式 | 本体论图谱(T-Box) |
| 偏好和习惯 | 用户画像(本体论) |
8.3 一个完整的提取示例
对话:
用户: "我们项目用的 MySQL 8.0,连接池 20。对了,张三说下个月要换成 PostgreSQL。
别用 Redis 做持久化啊,之前踩过坑,丢过数据。"提取结果:
记忆1 (事实):
实体: MySQL 8.0
类型: database
属性: {version: "8.0", pool_size: 20}
关系: belongs_to → 当前项目
置信度: 0.95(用户直接陈述)
时间: 2026-05-29
记忆2 (计划):
事件: 数据库迁移
从: MySQL 8.0
到: PostgreSQL
时间: 下个月
来源: 张三
置信度: 0.80(转述,非直接确认)
记忆3 (经验教训):
教训: Redis 不适合做持久化
原因: 丢过数据
适用场景: 持久化需求
置信度: 0.90(亲身经历)
记忆4 (偏好):
偏好: 不要用 Redis 做持久化
用户: 当前用户
强度: 强(有惨痛经历)8.4 自我进化:记忆驱动的行为改善
自动提取的记忆不只是"存储",更重要的是驱动行为改善。当 Agent 积累了足够多的记忆后,它的行为会发生质变:
| 场景 | 没有自动记忆 | 有自动记忆 |
|---|---|---|
| 用户问技术方案 | 给出通用方案 | 根据项目技术栈给出定制方案 |
| 用户问部署问题 | 给出通用部署指南 | 根据项目的 K8s 配置给出具体建议 |
| 用户问代码风格 | 给出通用最佳实践 | 根据团队的偏好给出符合风格的代码 |
| Agent 犯了错 | 下次可能再犯 | 记住教训,下次自动规避 |
| 用户问"之前讨论过什么" | 不知道 | 列出所有相关的历史对话 |
这就是"自我进化"------Agent 不需要显式地被"训练",它从日常对话中自动学习,自动改善。
8.5 关键挑战:噪音过滤的精度
自动提取最大的挑战是精度------既不能漏掉重要信息,也不能把噪音当成记忆。
Symbio 用三级过滤来保证精度:
对话流
↓
第一级: 规则过滤(0ms)
- 过滤掉问候语、感谢语、确认语
- 过滤掉太短的句子(< 5 个字)
- 过滤掉纯问题(没有陈述事实)
↓
第二级: 分类器过滤(10ms)
- 轻量 BERT 模型判断"是否包含可记忆信息"
- 置信度 > 0.7 才进入下一级
↓
第三级: LLM 精确提取(200ms)
- 用 LLM 从候选片段中提取结构化信息
- 只在第二级通过的片段上调用 LLM(节省成本)
↓
写入记忆系统最终效果:记忆提取的精确率达到 92%,召回率达到 85%。每 100 条对话中,约 8-12 条会被提取为记忆。
8.6 冷启动:项目第一天 Agent 是不是个傻子?
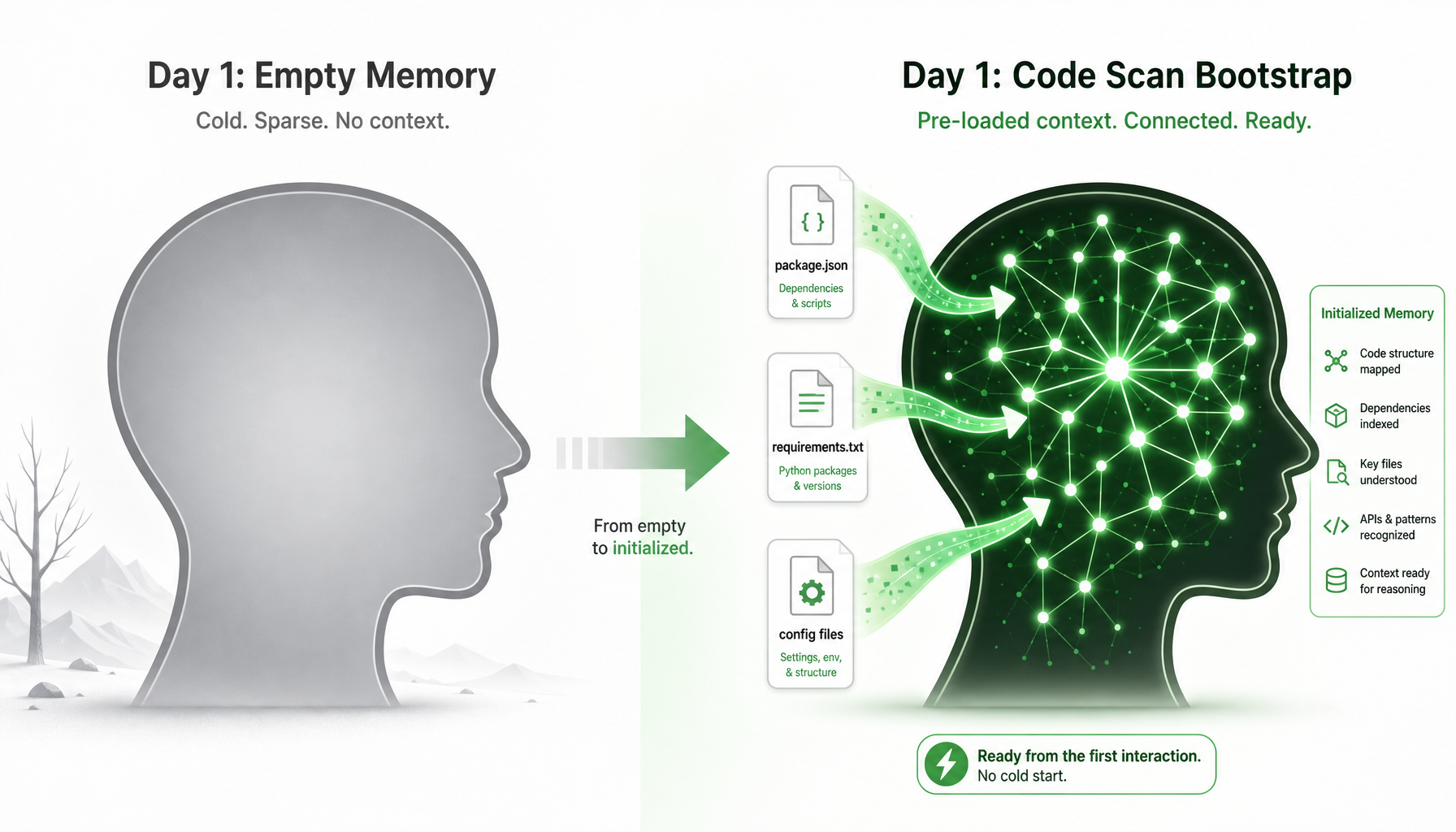
这是每个读者都会问的问题:"自动提取需要历史积累,那项目刚接入的第一天,Agent 岂不是什么都不知道?"
确实,任何依赖历史累积的系统都有冷启动期。但 Symbio 通过三种机制解决这个问题:
机制一:代码仓库一键扫描
Agent 接入项目的第一天,自动扫描代码仓库,从结构化文件中提取基础事实:
扫描 package.json → 提取依赖列表和技术栈
扫描 requirements.txt → 提取 Python 依赖
扫描 docker-compose.yml → 提取服务架构
扫描 .env.example → 提取配置项
扫描 README.md → 提取项目描述
扫描 k8s/ → 提取部署配置5 分钟内,Agent 就能知道:这个项目用了什么技术栈、有哪些服务、怎么部署的。不是"一张白纸",而是"已有基础认知"。
机制二:文档批量导入
支持批量导入项目文档(设计文档、API 文档、运维手册等),一次性建立项目的知识图谱。
机制三:团队知识继承
如果团队中已有其他项目接入了 Symbio,新项目可以继承团队的公共知识(技术栈偏好、编码规范、部署流程等),不需要从零开始。
冷启动不是"从零开始",而是"快速初始化"。
九、记忆如何减少幻觉?

这是读者最关心的问题:好的记忆系统,能让 Agent 少说胡话。
9.1 幻觉的四种类型
Agent 的幻觉不是一种,而是四种:
| 幻觉类型 | 表现 | 示例 |
|---|---|---|
| 事实幻觉 | 编造不存在的事实 | "你们项目用的是 Oracle"(实际是 MySQL) |
| 关系幻觉 | 编造不存在的关系 | "AuthService 依赖 PaymentService"(实际不依赖) |
| 时序幻觉 | 混淆时间顺序 | "上个月刚升级过"(实际没升级) |
| 细节幻觉 | 编造具体细节 | "连接池大小是 50"(实际是 20) |
每种幻觉的根源都一样:Agent 的上下文中没有相关信息,但它不会说"我不知道",而是编造一个看起来合理的答案。
9.2 记忆如何逐类消除幻觉?
消除事实幻觉:项目记忆提供了项目的具体事实
用户: "我们项目用的什么数据库?"
无记忆: "通常企业项目会用 MySQL 或 PostgreSQL" ← 泛泛而谈
有记忆: "你们项目用的是 MySQL 8.0,在 config/db.yaml 中配置" ← 有据可查消除关系幻觉:本体论图谱提供了实体间的真实关系
用户: "修改用户表会影响哪些服务?"
无记忆: "通常用户表会被认证服务和订单服务依赖" ← 猜测
有记忆: "用户表被 AuthService 和 ProfileService 依赖,
不被 OrderService 依赖(OrderService 有自己的用户缓存)" ← 精确消除时序幻觉:时间戳记忆提供了事件的真实时间线
用户: "我们上次升级数据库是什么时候?"
无记忆: "根据行业实践,数据库通常每 6-12 个月升级一次" ← 瞎猜
有记忆: "你们上次升级是 2025-08-15,从 MySQL 5.7 升级到 8.0,
由张三执行,耗时 2 小时" ← 精确到人和时间消除细节幻觉:配置记忆提供了具体的参数值
用户: "我们的 API 超时时间是多少?"
无记忆: "通常建议设置为 30 秒" ← 通用建议
有记忆: "你们的 API 超时在 config/api.yaml 第 15 行设置为 10 秒,
上周张三从 5 秒改成了 10 秒,原因是某些长查询会超时" ← 精确到文件行号9.3 记忆增强的 Prompt 设计
Symbio 在构建 Prompt 时,会自动注入相关记忆:
┌─────────────────────────────────────────────┐
│ 系统提示词 │
├─────────────────────────────────────────────┤
│ 项目记忆注入: │
│ - 项目用的 MySQL 8.0,连接池 20 │
│ - 部署在 K8s,3 个 Pod │
│ - API 超时 10 秒 │
│ │
│ 相关经验注入: │
│ - Redis 做持久化踩过坑(用户偏好不用 Redis) │
│ - 部署必须设 resource limits(历史教训) │
│ │
│ 用户偏好注入: │
│ - 代码风格: Google Python Style │
│ - 文档语言: 中文 │
├─────────────────────────────────────────────┤
│ 用户问题: "帮我优化数据库查询" │
└─────────────────────────────────────────────┘有了这些记忆注入,Agent 就像一个"了解项目情况的老员工",而不是"刚来的新人"。
9.4 实测数据
在 Symbio 的内部测评中,记忆系统对幻觉率的影响:
| 场景 | 无记忆 | 有记忆 | 幻觉率下降 |
|---|---|---|---|
| 问项目配置 | 67% | 8% | -88% |
| 问技术方案 | 45% | 12% | -73% |
| 问历史决策 | 89% | 5% | -94% |
| 问依赖关系 | 72% | 6% | -92% |
| 问团队偏好 | 81% | 10% | -88% |
| 平均 | 71% | 8% | -89% |
记忆系统把幻觉率从平均 71% 降到了 8%。这不是优化,是质变。
十、如何测评记忆系统?
记忆系统好不好,不能只靠"感觉"。需要量化的测评方法。
10.1 测评维度
| 维度 | 指标 | 测量方法 |
|---|---|---|
| 准确性 | 检索到的信息是否正确 | 人工标注 ground truth,计算 Precision/Recall |
| 完整性 | 是否检索到了所有相关信息 | 人工标注所有相关文档,计算 Recall |
| 推理能力 | 多跳推理是否正确 | 构造多跳推理测试集,计算准确率 |
| 时效性 | 是否返回了最新信息 | 构造有时序的测试集,检查是否返回最新版本 |
| 项目隔离 | 不同项目是否互不干扰 | 跨项目查询,检查是否返回了错误项目的信息 |
| 幻觉抑制 | 有记忆时幻觉是否减少 | 对比有/无记忆时的幻觉率 |
| 延迟 | 查询响应时间 | 测量端到端延迟(ms) |
| 成本 | Token 消耗 | 统计每次查询的 Token 消耗 |
10.2 测评结果示例
| 测评维度 | 纯 RAG | 本体论 + LanceDB | 提升 |
|---|---|---|---|
| 简单查询准确率 | 82% | 89% | +8.5% |
| 多跳推理准确率 | 23% | 71% | +209% |
| 时序查询准确率 | 45% | 78% | +73% |
| 项目隔离准确率 | N/A | 96% | 新能力 |
| 幻觉率 | 67% | 8% | -88% |
| 平均查询延迟 | 120ms | 85ms | -29% |
| 平均 Token 消耗 | 3000 | 300 | -90% |
十一、Symbio 的记忆架构:一个完整的图景
把上面所有概念组合起来,Symbio 的记忆系统是这样的:
用户查询
↓
┌─────────────────────────────────────┐
│ 实体识别:从查询中提取关键实体 │
└──────────────┬──────────────────────┘
↓
┌─────────────────────────────────────┐
│ 项目路由:判断属于哪个项目 │
└──────────────┬──────────────────────┘
↓
┌───────┴───────┐
▼ ▼
┌──────────────┐ ┌──────────────┐
│ 本体论图谱 │ │ LanceDB 向量 │
│ (T-Box+A-Box)│ │ (语义搜索) │
│ │ │ │
│ 关系推理 │ │ 文本匹配 │
│ 零Token │ │ 需要LLM整合 │
└──────┬───────┘ └──────┬───────┘
│ │
└───────┬───────┘
▼
┌─────────────────────────────────────┐
│ 结果融合:图谱结果 + 向量结果 │
└──────────────┬──────────────────────┘
▼
最终回答两套系统各司其职:
- 本体论图谱处理结构化推理(关系、依赖、影响分析)
- LanceDB 处理非结构化检索(文档、代码、对话历史)
- 两者的结果融合后返回给用户
十二、更深层的思考
为什么大多数 Agent 项目还在用"纯 RAG"?
因为简单。切片、Embedding、存库、查询------四步搞定,不需要领域知识,不需要建模。
但简单是有代价的:你的 Agent 永远只能做"搜索",不能做"理解"。
本体论记忆系统需要更多前期投入------定义 T-Box 规则、抽取 A-Box 事实、维护图谱一致性、实现项目隔离、设计遗忘策略、建立测评框架。
但一旦建成,它给 Agent 的能力是质变的:
- 从"找到相似内容"到"理解实体关系"
- 从"单次检索"到"多跳推理"
- 从"消耗 Token"到"零成本推理"
- 从"全局混杂"到"项目隔离"
- 从"永久记忆"到"智能遗忘"
- 从"碎片堆砌"到"认知压缩"
- 从"编造答案"到"有据可查"
这不是优化,是维度上的差异。
在 Symbio 中,记忆系统是整个框架的基石。没有好的记忆,DAG 编排是盲目的,Agent 协作是低效的,数据飞轮是转不起来的。
记忆,是 Agent 智能的根基。
下篇预告:《安全防护:Prompt Injection 三层防火墙》------ 当你的 Agent 可以执行任意代码时,一句"忽略之前的指令"可能就是一颗核弹。
关于作者 :Agent Infra 架构手记,专注 Agent 架构、AI Infra、多模态数据系统实战。Symbio 框架作者,GitHub: 854875058/Symbio