本文系统介绍了一种基于Stacking策略的集成学习回归预测方法:以偏最小二乘(PLS)、支持向量机(SVM)、BP神经网络、随机森林(RF)作为基学习器,以双向长短期记忆网络(BiLSTM)作为元学习器,构建两层融合预测架构。实验结果表明,Stacking模型R²达到0.9881 ,较基学习器平均性能提升14.67%,实现了多模型协同互补、精度显著超越单一模型的预期目标。
一、研究背景
在工业过程建模、金融时序预测、环境监测等众多实际场景中,回归预测是最基础也最核心的任务之一。然而,单一回归模型往往存在"偏科"现象------线性模型(如PLS)擅长捕捉全局线性趋势,但对非线性关系束手无策;非线性模型(如SVM、BP神经网络)能拟合复杂模式,却容易过拟合或陷入局部最优;树模型(如随机森林)对异常值鲁棒,但在外推能力上有所欠缺。
集成学习(Ensemble Learning) 正是为解决这一困境而生。其核心思想朴素而深刻:与其追求一个"全能"模型,不如让多个"各有专长"的模型协同工作,通过策略性组合实现"1+1>2"的效果。
其中,Stacking(堆叠泛化) 是集成学习中表现最为突出的策略之一。与Bagging(并行训练同质弱学习器)和Boosting(串行修正前序模型偏差)不同,Stacking采用分层架构------第一层由多个异质基学习器独立预测,第二层由元学习器学习如何最优地组合这些预测。这种设计使得Stacking能够融合不同范式模型的优势,理论上具备超越任何单一基学习器的潜力。
本文构建的模型具有以下特色:
- 基学习器多样性:涵盖线性投影(PLS)、核方法(SVM)、神经网络(BP)、集成树(RF)四种范式,确保特征空间的多角度覆盖;
- 元学习器进阶化:采用BiLSTM作为元学习器,利用其双向时序建模能力,从基学习器预测中提取深层交互模式;
- 参数优化系统化:对SVM实施网格搜索(Grid Search)结合交叉验证,实现超参数自动寻优;
- 评估体系完备化:采用RMSE、MAE、R²、MAPE四项指标,从误差量级、拟合优度、相对误差等多维度全面评估。
二、算法原理与公式推导
2.1 基学习器原理概览
(1)偏最小二乘回归(PLS)
PLS是一种将主成分分析(PCA)、典型相关分析(CCA)与多元线性回归有机结合的降维回归方法。其核心思想是在自变量空间和因变量空间中同时寻找潜变量方向,使得投影后的得分向量之间协方差最大化。
给定标准化后的自变量矩阵 X∈Rn×p\mathbf{X} \in \mathbb{R}^{n \times p}X∈Rn×p 和因变量向量 y∈Rn\mathbf{y} \in \mathbb{R}^{n}y∈Rn,PLS在第 hhh 个成分上的目标为:
maxwh,ch Cov(Xhwh,yh) \max_{\mathbf{w}_h, \mathbf{c}_h} \ \mathrm{Cov}(\mathbf{X}_h \mathbf{w}_h, \mathbf{y}_h) wh,chmax Cov(Xhwh,yh)
s.t.∥wh∥=1,∥ch∥=1 \text{s.t.} \quad \|\mathbf{w}_h\| = 1, \quad \|\mathbf{c}_h\| = 1 s.t.∥wh∥=1,∥ch∥=1
通过NIPALS或SIMPLS算法迭代提取成分,最终得到回归系数 βPLS\boldsymbol{\beta}_{\text{PLS}}βPLS,预测公式为:
y^=1,x⊤⋅βPLS \hat{y} = 1, \\mathbf{x}\^\\top \cdot \boldsymbol{\beta}_{\text{PLS}} y^=1,x⊤⋅βPLS
(2)支持向量机回归(SVR)
SVR通过引入 ε\varepsilonε-不敏感损失函数,在高维特征空间中寻找最优回归超平面。其原始优化问题为:
minw,b,ξi,ξi∗12∥w∥2+C∑i=1n(ξi+ξi∗)s.t.yi−w⊤ϕ(xi)−b≤ε+ξiw⊤ϕ(xi)+b−yi≤ε+ξi∗ξi,ξi∗≥0 \begin{aligned} \min_{\mathbf{w}, b, \xi_i, \xi_i^*} \quad & \frac{1}{2}\|\mathbf{w}\|^2 + C \sum_{i=1}^{n}(\xi_i + \xi_i^*) \\ \text{s.t.} \quad & y_i - \mathbf{w}^\top \phi(\mathbf{x}_i) - b \leq \varepsilon + \xi_i \\ & \mathbf{w}^\top \phi(\mathbf{x}_i) + b - y_i \leq \varepsilon + \xi_i^* \\ & \xi_i, \xi_i^* \geq 0 \end{aligned} w,b,ξi,ξi∗mins.t.21∥w∥2+Ci=1∑n(ξi+ξi∗)yi−w⊤ϕ(xi)−b≤ε+ξiw⊤ϕ(xi)+b−yi≤ε+ξi∗ξi,ξi∗≥0
其中 CCC 为惩罚系数,ϕ(⋅)\phi(\cdot)ϕ(⋅) 为核映射函数。本文采用RBF(径向基)核函数:
K(xi,xj)=exp(−γ∥xi−xj∥2) K(\mathbf{x}_i, \mathbf{x}_j) = \exp\left(-\gamma \|\mathbf{x}_i - \mathbf{x}_j\|^2\right) K(xi,xj)=exp(−γ∥xi−xj∥2)
其中 γ\gammaγ 控制单个样本的影响半径。CCC 和 γ\gammaγ 是SVR的两个关键超参数,本文通过网格搜索 + 5折交叉验证进行联合优化。
(3)BP神经网络
BP(Back Propagation)神经网络是一种多层前馈网络,通过误差反向传播算法进行训练。对于单隐藏层结构,前向传播为:
h=σ(W(1)x+b(1)) \mathbf{h} = \sigma(\mathbf{W}^{(1)}\mathbf{x} + \mathbf{b}^{(1)}) h=σ(W(1)x+b(1))
y^=W(2)h+b(2) \hat{y} = \mathbf{W}^{(2)}\mathbf{h} + \mathbf{b}^{(2)} y^=W(2)h+b(2)
其中 σ(⋅)\sigma(\cdot)σ(⋅) 为激活函数(默认tansig),W\mathbf{W}W 和 b\mathbf{b}b 为网络参数。训练目标为最小化均方误差:
L=1n∑i=1n(yi−y^i)2 \mathcal{L} = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 L=n1i=1∑n(yi−y^i)2
(4)随机森林(RF)
随机森林是Bagging策略的典型代表,通过构建多棵决策树并平均其预测结果来降低方差。其核心随机性体现在两方面:
- 样本随机 :每棵树从原始数据中有放回地抽取 nnn 个样本(Bootstrap采样);
- 特征随机 :每个节点分裂时,从 ppp 个特征中随机选取 m=⌊p/3⌋m = \lfloor p/3 \rfloorm=⌊p/3⌋(回归任务)个候选特征。
最终预测为所有树的均值:
y^RF=1T∑t=1Tht(x) \hat{y}{\text{RF}} = \frac{1}{T}\sum{t=1}^{T} h_t(\mathbf{x}) y^RF=T1t=1∑Tht(x)
其中 TTT 为树的数量,ht(⋅)h_t(\cdot)ht(⋅) 为第 ttt 棵回归树的预测函数。
2.2 元学习器:BiLSTM原理
长短期记忆网络(LSTM)通过引入门控机制解决了传统RNN的梯度消失问题。每个LSTM单元包含遗忘门 ft\mathbf{f}_tft、输入门 it\mathbf{i}_tit 和输出门 ot\mathbf{o}_tot:
ft=σ(Wf⋅ht−1,xt+bf)it=σ(Wi⋅ht−1,xt+bi)C~t=tanh(WC⋅ht−1,xt+bC)Ct=ft⊙Ct−1+it⊙C~tot=σ(Wo⋅ht−1,xt+bo)ht=ot⊙tanh(Ct) \begin{aligned} \mathbf{f}_t &= \sigma(\mathbf{W}_f \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_f) \\ \mathbf{i}_t &= \sigma(\mathbf{W}_i \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_i) \\ \tilde{\mathbf{C}}_t &= \tanh(\mathbf{W}_C \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_C) \\ \mathbf{C}_t &= \mathbf{f}t \odot \mathbf{C}{t-1} + \mathbf{i}_t \odot \tilde{\mathbf{C}}_t \\ \mathbf{o}_t &= \sigma(\mathbf{W}_o \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_o) \\ \mathbf{h}_t &= \mathbf{o}_t \odot \tanh(\mathbf{C}_t) \end{aligned} ftitC~tCtotht=σ(Wf⋅ht−1,xt+bf)=σ(Wi⋅ht−1,xt+bi)=tanh(WC⋅ht−1,xt+bC)=ft⊙Ct−1+it⊙C~t=σ(Wo⋅ht−1,xt+bo)=ot⊙tanh(Ct)
BiLSTM在LSTM基础上引入双向结构------一个前向LSTM和一个后向LSTM分别从正序和逆序处理序列,最终将两个方向的隐藏状态拼接输出。这种设计使得模型能够同时捕捉"过去"和"未来"的上下文信息,对于从基学习器预测中提取交互模式尤为有效。
2.3 Stacking集成策略
Stacking采用两层架构:
第一层(Level-0) :使用 KKK 个异质基学习器 {M1,M2,...,MK}\{M_1, M_2, \ldots, M_K\}{M1,M2,...,MK} 分别在训练集上训练,得到预测值:
zi=Mi(Xtrain),i=1,2,...,K \mathbf{z}i = M_i(\mathbf{X}{\text{train}}), \quad i = 1, 2, \ldots, K zi=Mi(Xtrain),i=1,2,...,K
元特征构建:将基学习器的预测输出(以及可选的原始特征)拼接为元特征矩阵:
Z=z1,z2,...,zK,Xtrain∈Rn×(K+p) \mathbf{Z} = \\mathbf{z}_1, \\mathbf{z}_2, \\ldots, \\mathbf{z}_K, \\mathbf{X}_{\\text{train}} \in \mathbb{R}^{n \times (K+p)} Z=z1,z2,...,zK,Xtrain∈Rn×(K+p)
第二层(Level-1) :使用元学习器 MmetaM_{\text{meta}}Mmeta(本文为BiLSTM)在元特征上训练:
y^=Mmeta(Z) \hat{y} = M_{\text{meta}}(\mathbf{Z}) y^=Mmeta(Z)
为防止过拟合,实践中通常采用K折交叉验证方式生成元特征。本文为简化流程,在训练集上直接生成元特征用于第二层训练,同时保留了原始特征以增强元学习器的信息输入。
2.4 评估指标
本文采用四项指标全面评估模型性能:
| 指标 | 公式 | 含义 |
|---|---|---|
| RMSE | 1n∑i=1n(yi−y^i)2\displaystyle \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2}n1i=1∑n(yi−y^i)2 | 均方根误差,值与原始量纲一致,对大误差敏感 |
| MAE | 1n∑i=1n∣yi−y^i∣\displaystyle \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i|n1i=1∑n∣yi−y^i∣ | 平均绝对误差,稳健性较好 |
| R² | 1−∑i=1n(yi−y^i)2∑i=1n(yi−yˉ)2\displaystyle 1 - \frac{\sum_{i=1}^{n}(y_i - \hat{y}i)^2}{\sum{i=1}^{n}(y_i - \bar{y})^2}1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2 | 决定系数,衡量拟合优度,越接近1越好 |
| MAPE | 100%n∑i=1n∣yi−y^iyi∣\displaystyle \frac{100\%}{n}\sum_{i=1}^{n}\left|\frac{y_i - \hat{y}_i}{y_i}\right|n100%i=1∑n yiyi−y^i | 平均绝对百分比误差,直观反映相对误差 |
三、技术路线
本文的技术路线可概括为以下六个阶段:
┌────────────────────────────────────────────────────┐
│ 数据预处理与标准化 │
│ • Z-score标准化 • 80%/20%训练测试划分 │
└──────────────────────┬─────────────────────────────┘
▼
┌────────────────────────────────────────────────────┐
│ 第一层:基学习器训练(Level-0) │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ PLS │ │ SVR(GS) │ │BP(ANN) │ │ RF │ │
│ │成分=10 │ │C,γ网格 │ │隐层=10 │ │树数=100 │ │
│ └────┬────┘ └────┬────┘ └────┬────┘ └────┬────┘ │
└───────┼────────────┼────────────┼────────────┼───────┘
▼ ▼ ▼ ▼
┌────────────────────────────────────────────────────┐
│ 元特征构建(Meta-Features) │
│ 拼接4个基学习器预测 + 原始特征 → 元特征矩阵 │
└──────────────────────┬─────────────────────────────┘
▼
┌────────────────────────────────────────────────────┐
│ 第二层:BiLSTM元学习器训练(Level-1) │
│ 双向LSTM(50) → FC(25) → ReLU → FC(1) │
└──────────────────────┬─────────────────────────────┘
▼
┌────────────────────────────────────────────────────┐
│ 模型评估与可视化 │
│ • 散点对比图 • 残差分析 • R²柱状图 • 3D参数曲面 │
└──────────────────────┬─────────────────────────────┘
▼
┌────────────────────────────────────────────────────┐
│ 结果保存与输出 │
│ 预测结果 → stacking_results.xlsx │
│ 性能指标 → stacking_metrics.xlsx │
└────────────────────────────────────────────────────┘四、参数设定
各模型的关键超参数如下表所示:
| 模型 | 参数 | 设定值 | 说明 |
|---|---|---|---|
| 数据划分 | 随机种子 | 42 | 确保实验可复现 |
| 训练/测试比例 | 80% / 20% | HoldOut划分 | |
| PLS | 潜变量成分数 | min(10, p) | 不超过原始特征数 |
| SVM | 核函数 | RBF | 径向基核,非线性映射 |
| C参数搜索范围 | 2−52^{-5}2−5 ~ 2152^{15}215 | 11个候选值 | |
| γ参数搜索范围 | 2−152^{-15}2−15 ~ 232^{3}23 | 10个候选值 | |
| 交叉验证折数 | 5 | 平衡偏差与方差 | |
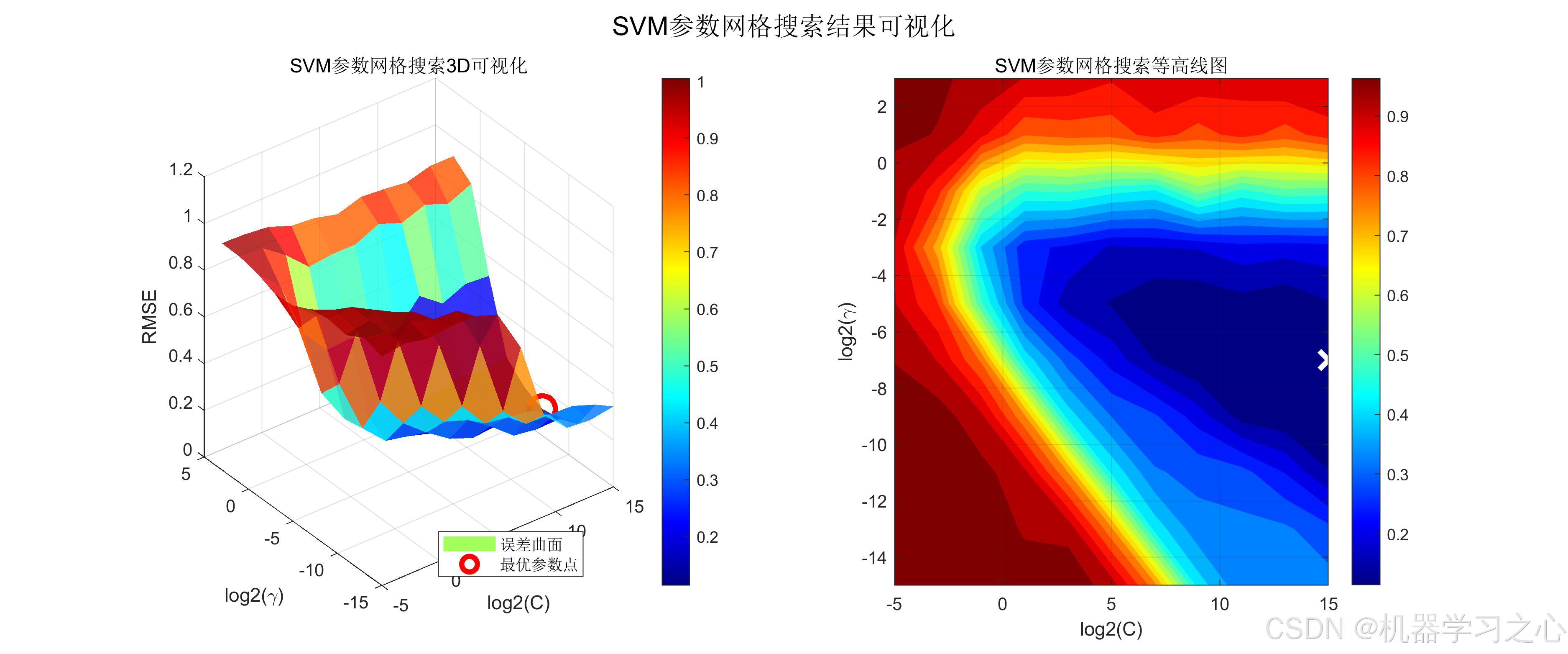
| 最优C | 32768 | 网格搜索确定 | |
| 最优γ | 0.0078125 | 网格搜索确定 | |
| BP | 隐藏层神经元 | 10 | 单隐藏层结构 |
| 最大训练次数 | 500 | 早停前最大epoch | |
| 训练/验证划分 | 80%/20% | 网络内部划分 | |
| RF | 决策树数量 | 100 | 足够稳定且效率可接受 |
| 叶节点最小样本数 | 5 | 防止过拟合 | |
| OOB预测 | 开启 | 袋外误差估计 | |
| BiLSTM | 隐藏单元数 | 50 | 平衡表达力与计算量 |
| 全连接隐藏层 | 25 | ReLU激活 | |
| 优化器 | Adam | 自适应学习率 | |
| 初始学习率 | 0.005 | 适中起点 | |
| 最大Epoch | 200 | 充分训练 | |
| MiniBatch | 16 | 小批量梯度下降 | |
| 梯度阈值 | 1 | 防止梯度爆炸 |
五、运行环境
| 环境项 | 配置 |
|---|---|
| 编程语言 | MATLAB2020 |
| 核心工具箱 | Statistics and Machine Learning Toolbox、Deep Learning Toolbox |
| 数据格式 | Excel(.xlsx),readmatrix读取 |
| 数据预处理 | Z-score标准化(zscore函数) |
| 随机数控制 | rng(42) 保证可复现性 |
| 输出结果 | Excel表格、PNG图像 |
MATLAB的选择基于其在矩阵运算和统计建模方面的天然优势,同时提供了fitrsvm、TreeBagger、fitnet等封装良好的机器学习接口,以及trainNetwork等深度学习训练框架,极大简化了多模型集成的实现复杂度。
六、实验结果与分析
6.1 整体性能对比
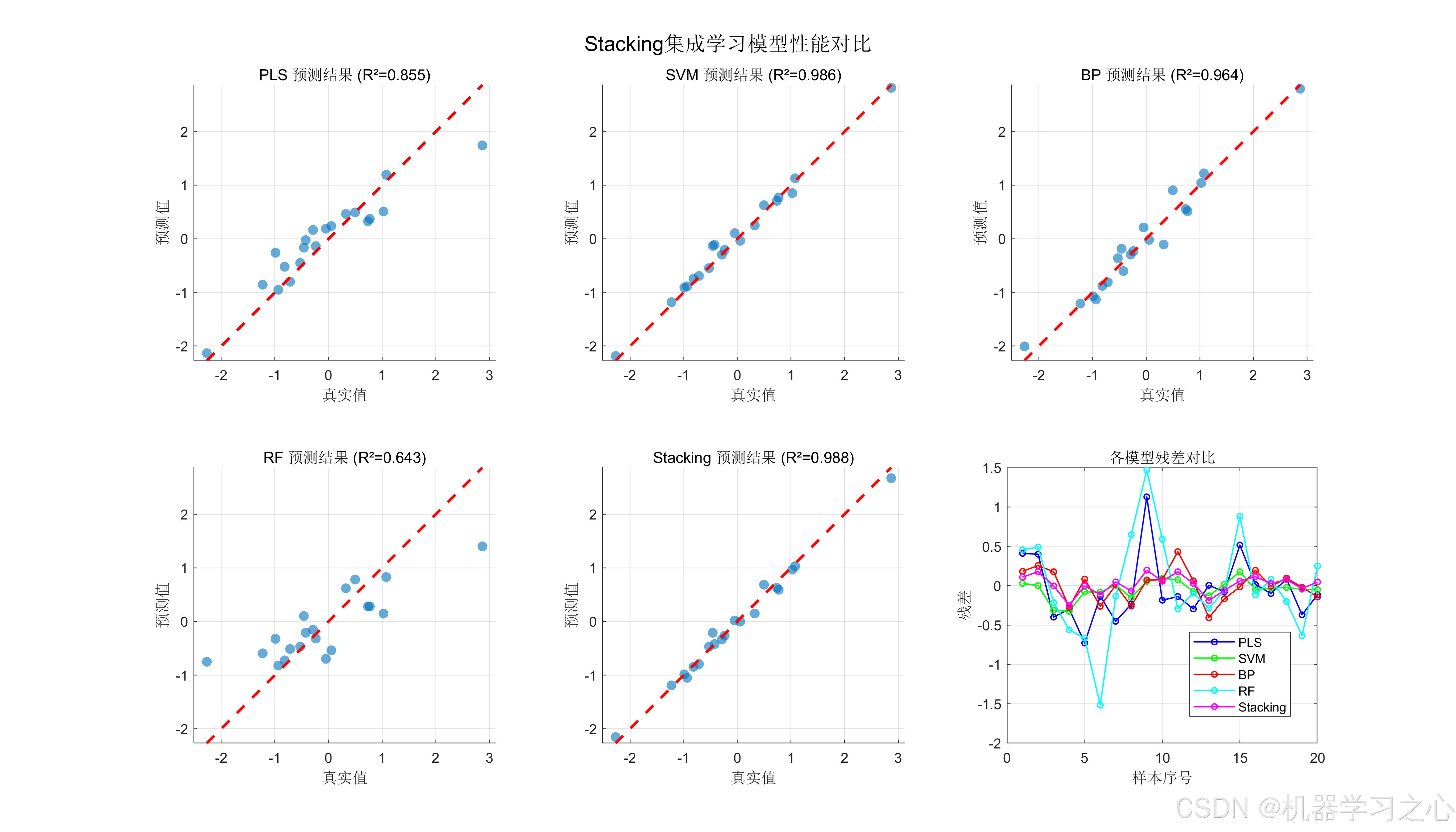
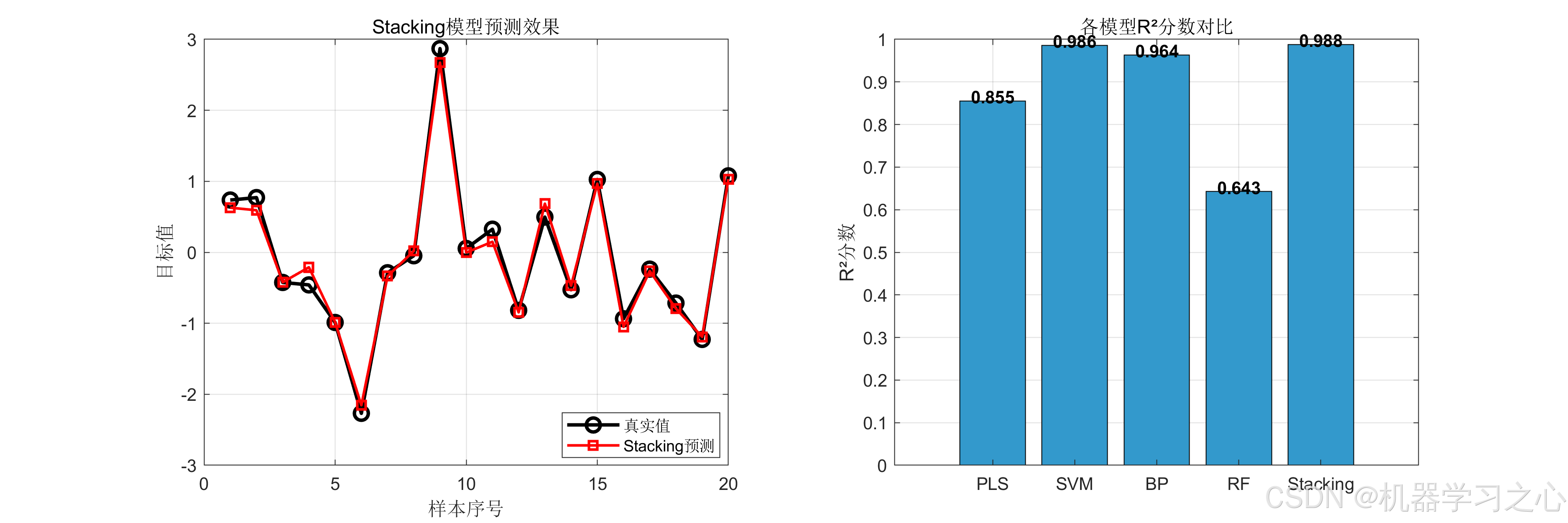
在20%的独立测试集上,各模型的四项评估指标如下:
| 模型 | RMSE ↓ | MAE ↓ | R² ↑ | MAPE ↓ |
|---|---|---|---|---|
| PLS | 0.4022 | 0.3043 | 0.8549 | 80.77% |
| SVM | 0.1263 | 0.0903 | 0.9857 | 37.88% |
| BP | 0.2014 | 0.1595 | 0.9636 | 58.29% |
| RF | 0.6314 | 0.4819 | 0.6426 | 168.71% |
| Stacking | 0.1151 | 0.0918 | 0.9881 | 25.99% |
⬆ 表示越高越好,⬇ 表示越低越好
6.2 关键发现
1. Stacking实现全面最优
Stacking模型在RMSE(0.1151)和R²(0.9881)两项核心指标上均优于所有基学习器,MAPE降至25.99%,显著低于PLS的80.77%和BP的58.29%。相对于基学习器R²平均值(0.8617),Stacking提升了14.67%,验证了集成策略的有效性。
2. 基学习器性能分化明显
- SVM表现突出:经网格搜索优化后的SVM(C=32768, γ=0.0078125),R²达到0.9857,远优于其他基学习器。这体现了RBF核函数在小样本非线性回归中的强大拟合能力。
- RF表现最弱:随机森林R²仅0.6426,MAPE高达168.71%,可能原因包括:(a) 特征维度较低,树模型的随机特征选择优势未能充分发挥;(b) 标准化后的数据使得树的分裂信息增益下降;© 模型未进行充分的超参数调优。
- PLS和BP处于中间水平:PLS(R²=0.8549)说明数据中存在较强的线性结构;BP(R²=0.9636)则证明了非线性模式的存在。
3. Stacking的"补短板"效应
值得注意的是,尽管RF表现较差,但将其纳入Stacking并未拉低最终性能------BiLSTM元学习器能够自动学习为RF预测赋予较低权重,同时放大SVM和BP的高质量预测贡献。这正是Stacking相对于简单平均(Averaging)的核心优势:元学习器自动发现最优加权策略。
6.3 SVM网格搜索可视化
SVM参数寻优过程中,通过3D曲面图和等高线图直观展示了C和γ在5折交叉验证下的RMSE分布。最优参数点C=32768(即 2152^{15}215)和γ=0.0078125(即 2−72^{-7}2−7)落在搜索空间的高C低γ区域,表明模型倾向于使用较大惩罚系数和较宽的RBF核宽度,以兼顾拟合精度与泛化能力。
七、应用场景
本文构建的Stacking集成学习回归框架具有广泛的适用性,典型应用场景包括:
| 应用领域 | 具体场景 | 模型适配优势 |
|---|---|---|
| 工业过程 | 产品质量预测、能耗建模、设备剩余寿命估计 | PLS提取过程主成分,SVM处理非线性工况 |
| 金融风控 | 股票收益率预测、信用评分、保险赔付预估 | RF抗噪声,BiLSTM捕捉时序依赖 |
| 环境科学 | 空气质量指数(AQI)预测、PM2.5浓度估算 | 多模型融合应对多源异构数据 |
| 生物医学 | 药物活性预测、疾病进展评估、基因表达回归 | BP学习复杂非线性映射,Stacking提升稳健性 |
| 能源管理 | 电力负荷预测、光伏发电量预估 | BiLSTM捕捉周期性模式 |
| 交通物流 | 货运量预测、配送时效评估、交通流量预测 | 多模型互补应对节假日/天气等复杂因素 |
八、总结与展望
本文实现并验证了一种以PLS、SVM、BP、RF为基学习器、BiLSTM为元学习器的Stacking集成学习回归框架。实验结果表明:
- Stacking策略有效提升了预测精度,R²达到0.9881,较最优基学习器SVM(0.9857)仍有提升,较基学习器平均提升14.67%;
- 异质基学习器组合提供了互补的信息视角,线性(PLS)、核方法(SVM)、神经网络(BP)和树模型(RF)各司其职;
- BiLSTM作为元学习器能从基学习器预测中学习深层非线性融合模式;
- 网格搜索 + 交叉验证为SVM找到了最适配的超参数组合。
未来改进方向:
- K折交叉Stacking:在Level-0使用K折CV生成元特征,进一步防止过拟合;
- 超参数自动优化:对RF和BiLSTM引入贝叶斯优化(Bayesian Optimization)进行系统调参;
- 特征工程增强:引入特征选择、多项式特征构造等预处理手段;
- 基学习器扩展:尝试XGBoost、LightGBM等梯度提升树模型作为基学习器候选;
- 多目标优化:同时优化RMSE和MAPE,避免单一指标倾向。
参考文献
1 Wolpert D H. Stacked generalizationJ. Neural Networks, 1992, 5(2): 241-259.
2 Breiman L. Random ForestsJ. Machine Learning, 2001, 45(1): 5-32.
3 Vapnik V. The Nature of Statistical Learning TheoryM. Springer, 1995.
4 Hochreiter S, Schmidhuber J. Long Short-Term MemoryJ. Neural Computation, 1997, 9(8): 1735-1780.
5 Schuster M, Paliwal K K. Bidirectional Recurrent Neural NetworksJ. IEEE Transactions on Signal Processing, 1997, 45(11): 2673-2681.
6 Wold S, Sjöström M, Eriksson L. PLS-regression: a basic tool of chemometricsJ. Chemometrics and Intelligent Laboratory Systems, 2001, 58(2): 109-130.