Chrome上搜到一个比较好玩的插件
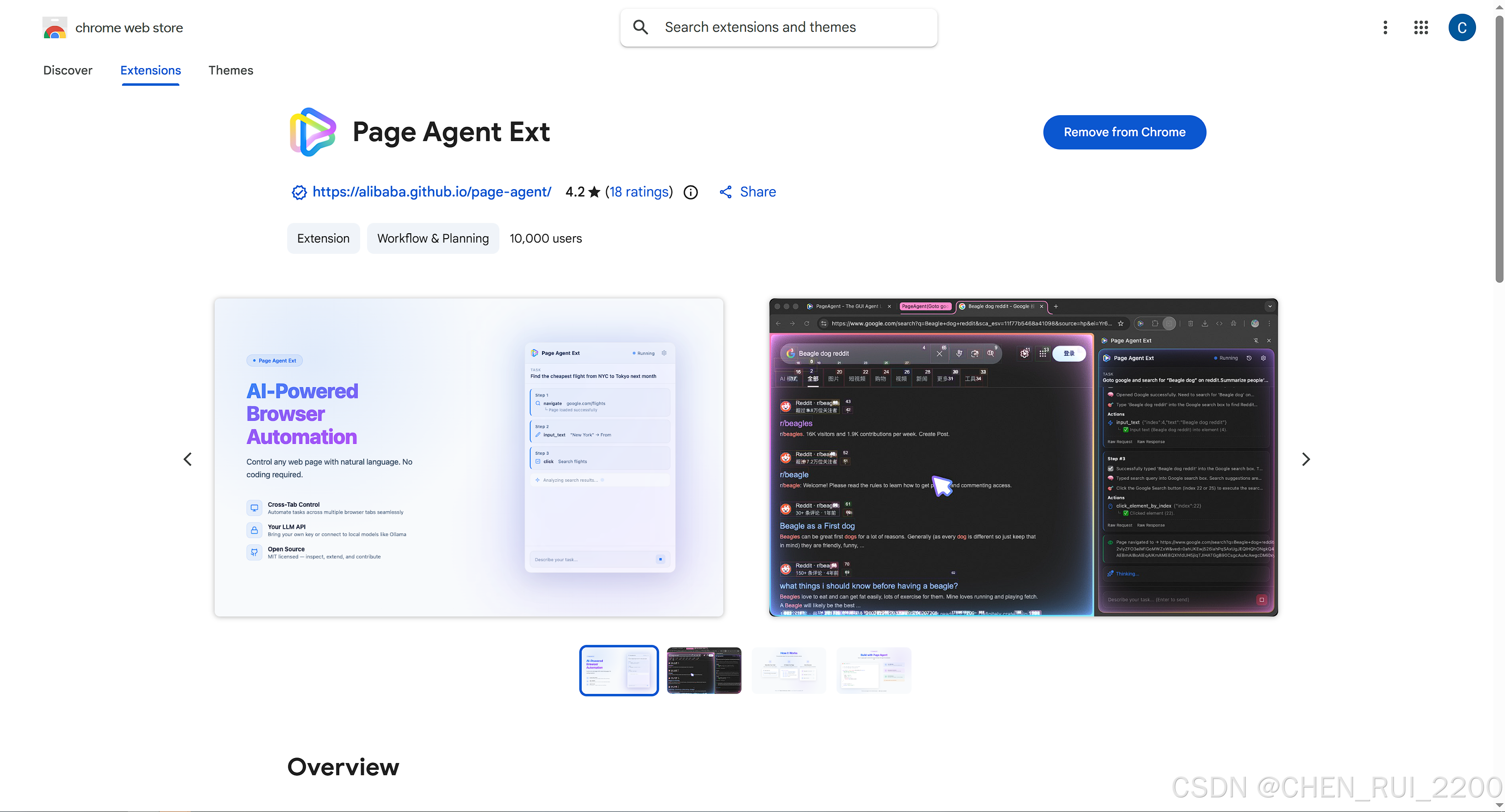
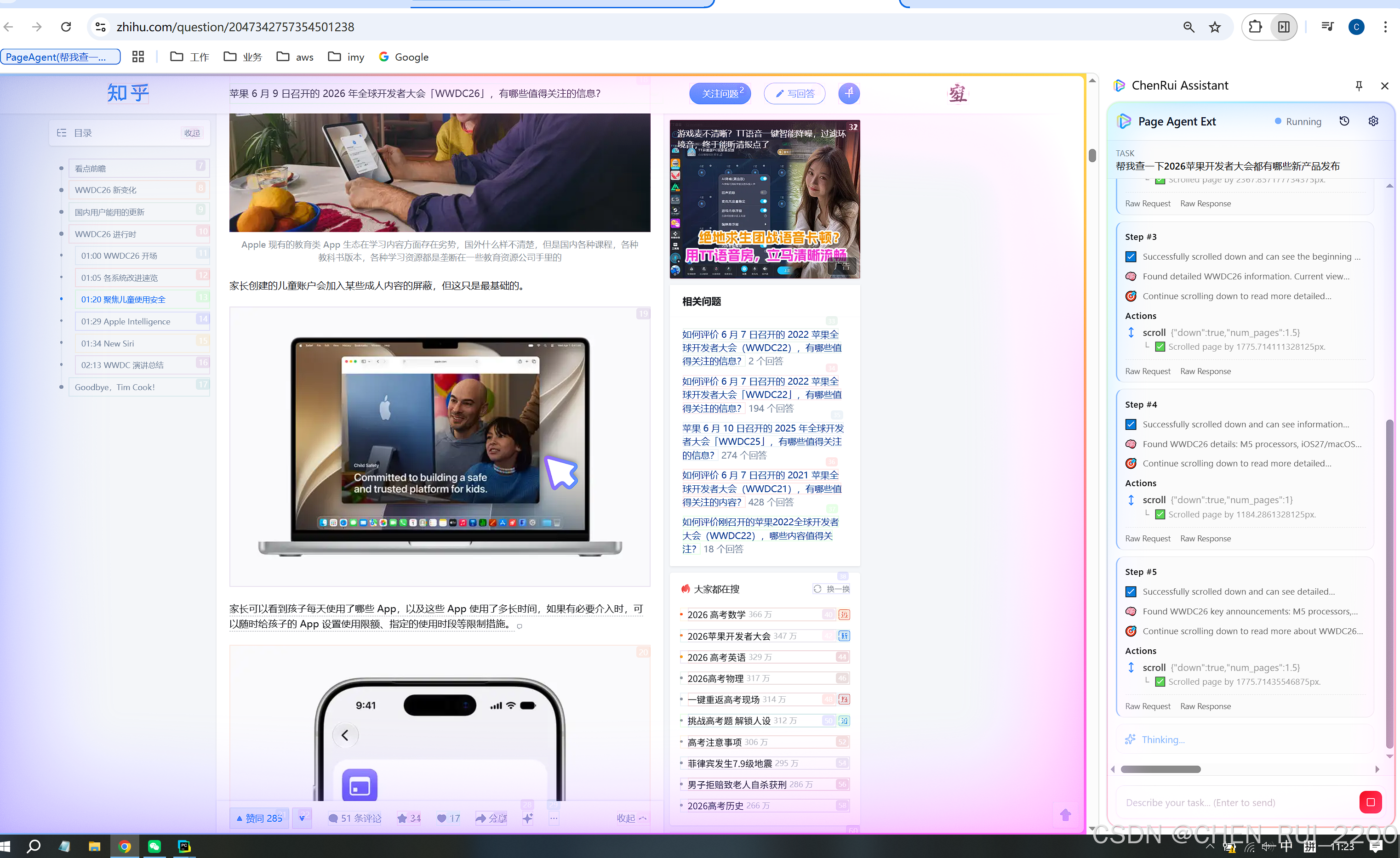
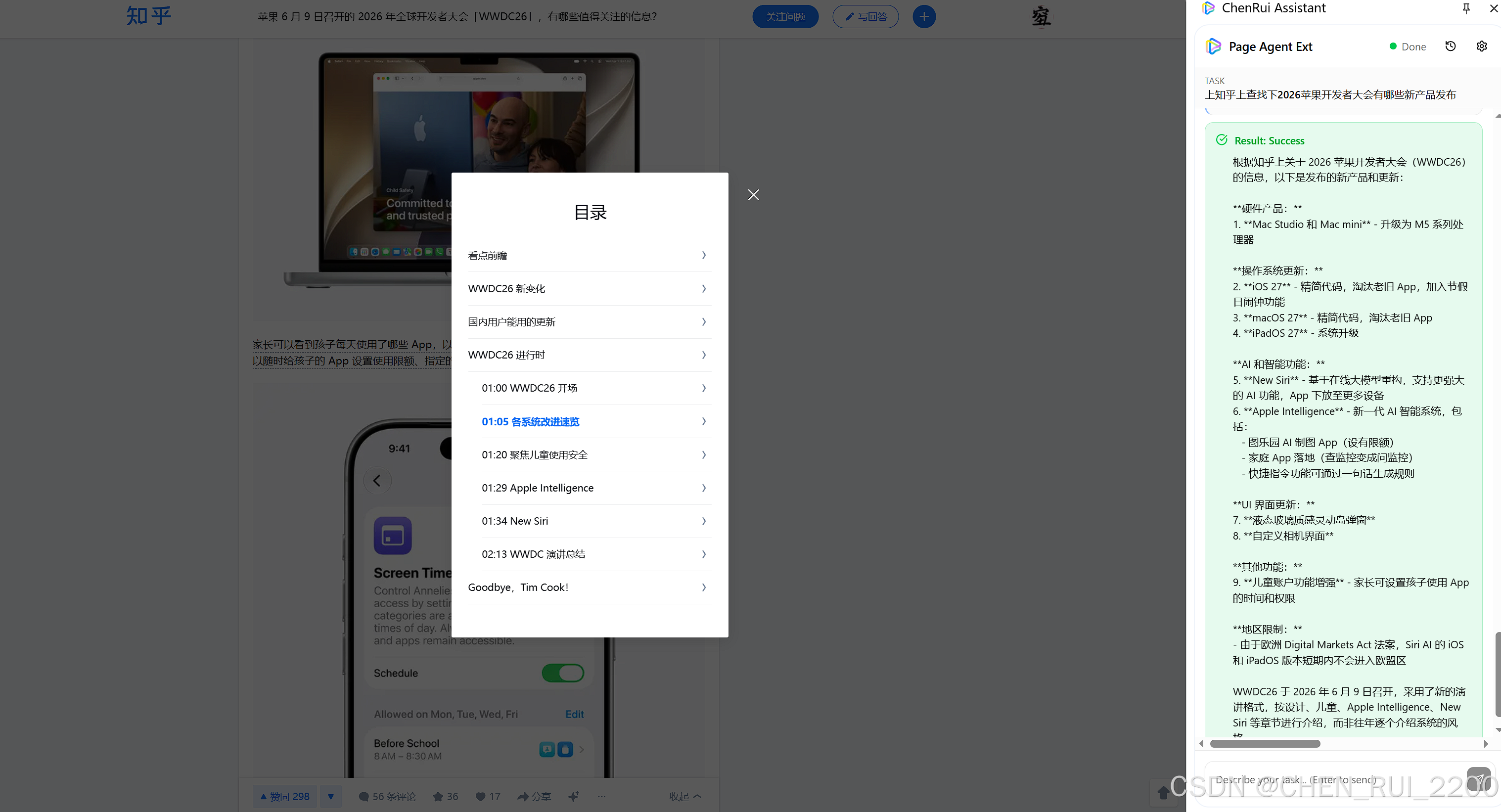
试验了下让分析2026苹果大会都发布了哪些好的产品
纯 JS 实现的 GUI agent。使用自然语言操作你的 Web 应用。无须后端、客户端、浏览器插件。
https://github.com/alibaba/page-agent
项目特点是
- 无需 浏览器插件 / Python / 无头浏览器,纯页面内 JavaScript
- 基于文本的 DOM 操作,无需截图,无需多模态模型或特殊权限
- 自备 LLM,可选的 Chrome 扩展,支持跨页面任务
当一个 AI Agent 要帮你在网页上完成一个任务------比如「帮我在电商网站上找到最便宜的蓝牙耳机」------它到底经历了什么?它不像你有眼睛,能一眼看到页面上的按钮和输入框;它也没有手指,没法直接点击屏幕。它唯一拥有的,是一个大语言模型,和一堆精心设计的「桥梁代码」。Page-Agent 就是一个做这件事的开源项目。它把浏览器变成一个 AI 可以操作的「沙盒」,让 LLM 能像人一样看页面、点按钮、填表单、翻页、跨标签页操作。
我让AI帮我通读了下源码,发现里面藏了值得拿出来单独讲一讲的精巧设计。有些是巧妙绕过框架限制的黑魔法,有些是处理边界条件的防御性编程,还有些是架构层面的优雅决策。
这篇文章就带你逐个拆开看看。
整体架构:一场跨上下文的「远程手术」
在深入到细节之前,先理解一个最核心的约束:AI Agent 的代码和实际 DOM 操作跑在不同的上下文中。
┌──────────────────────────────────────────────────────────────┐
│ 扩展页面(sidepanel / popup) │
│ MultiPageAgent ── Agent 循环:LLM 调用 → 工具执行 │
│ │ │
│ ▼ │
│ chrome.runtime.sendMessage │
├──────────────────────────────────────────────────────────────┤
│ Background Service Worker(中转站) │
│ │ │
│ ▼ │
│ chrome.tabs.sendMessage │
├──────────────────────────────────────────────────────────────┤
│ Content Script(页面内) │
│ PageController ── 真实 DOM 操作 │
│ PageController ── 提取浏览器状态 │
└──────────────────────────────────────────────────────────────┘绕过 React 值追踪的「原型链劫持」
问题
想象一下,Agent 要往一个 React 应用的输入框里填文字。最直观的做法是什么?
javascript
element.value = "你好世界"然后呢?页面上什么都没发生。React 的表单状态没更新,按钮还是灰色的,表单还是没法提交。
为什么?因为 React 在内部维护了一个值追踪系统。当你在 <input> 上设置 value 时,React 会拦截这个操作,用自己的合成事件系统来管理值。直接通过 DOM API 赋值,React 根本不知道值变了。
解法
Page-Agent 的做法堪称优雅。它没有去模拟键盘输入(那样太慢了),而是直接「劫持」了原生属性设置器:
typescript
// utils/index.ts
export function getNativeValueSetter(element: HTMLInputElement | HTMLTextAreaElement) {
return Object.getOwnPropertyDescriptor(
Object.getPrototypeOf(element) as object,
'value'
)!.set as (v: string) => void
}
// actions.ts
getNativeValueSetter(element).call(element, text)
element.dispatchEvent(new Event('input', { bubbles: true }))这行代码在做什么?
React 确实在 element 实例上拦截了 value 属性的赋值------但它没有拦截原型链上 的那个原生 setter。通过 Object.getPrototypeOf(element) 拿到 HTMLInputElement.prototype,再取出原始的 set 方法,然后 .call(element, text) 把它绑定回实际的 DOM 元素。
这就像 React 在前门装了保安,但代码从后门(原型链)悄悄进去了。
最后再 dispatch 一个 input 事件,通知 React 的变更检测系统:"嘿,值变了,该更新了。"
contenteditable 的「双计划」策略
问题
如果说 <input> 和 <textarea> 还算好对付,那 contenteditable 元素才是真正的泥潭。
网页上有无数种富文本编辑器:Quill、Slate.js、Draft.js、Monaco/CodeMirror......它们各有各的方式来管理内容。有些监听 input 事件,有些监听 beforeinput,有些完全不管标准事件,只认浏览器原生的编辑命令。
一个 Agent 怎么可能适配所有情况?
解法
Page-Agent 采用了一个「先礼后兵」的双计划策略:
typescript
// Plan A:派发合成事件 + 直接设置 innerText
element.dispatchEvent(
new InputEvent('beforeinput', {
bubbles: true, cancelable: true,
inputType: 'insertText', data: text,
})
)
element.innerText = text
element.dispatchEvent(new InputEvent('input', {
bubbles: true, inputType: 'insertText', data: text,
}))
// 验证 Plan A 是否成功
const planASucceeded = element.innerText.trim() === text.trim()
// Plan B:回退到 execCommand
if (!planASucceeded) {
element.focus()
const range = doc.createRange()
range.selectNodeContents(element)
selection?.removeAllRanges()
selection?.addRange(range)
doc.execCommand('delete', false)
doc.execCommand('insertText', false, text)
}这招妙在哪里?
Plan A 是现代的、干净的方式:派发标准事件,直接设置文本。这能搞定 React 的 contenteditable 和 Quill 等主流编辑器。
但它加了一个验证步骤 ------设完之后检查 innerText 是不是真的变成了目标文本。如果没有,说明这个编辑器不吃这一套。
于是 Plan B 出场:document.execCommand。这个方法已经被 W3C 废弃了,但浏览器仍然支持它。更重要的是,它是浏览器原生的编辑命令,Slate.js 这类富文本编辑器对它处理得非常好。
代码里还明明白白地写了不支持的清单:Monaco/CodeMirror 需要 JS 实例访问,Draft.js 对两种方式都不响应(且本身已经不再维护)。
LLM 告诉 Agent:「点击索引 42 的元素」。Agent 找到了那个元素,是一个 <div>。它直接 div.click() 就行了吗?
不行。因为这个 <div> 里面可能有一个 <button>,一个 <img>,一个 <span> 图标。在真实的浏览器里,用户的鼠标点击永远落在最深层的那个元素上------这是浏览器的事件模型决定的。
如果 Agent 点击的是父容器而不是里面的按钮,事件处理函数可能根本不会触发。
解法
typescript
// actions.ts - clickElement
// 1. 移动虚拟指针到元素中心
const { x, y } = getCenterPosition(element)
// 2. 临时启用遮罩穿透(否则 elementFromPoint 只能看到遮罩层)
await enablePassThrough()
// 3. 命中测试:找到坐标处最深的元素
const hitTarget = doc.elementFromPoint(x, y)
await disablePassThrough()
// 4. 安全检查:确保命中的元素确实是原元素的后代
const target = hitTarget instanceof HTMLElement && element.contains(hitTarget)
? hitTarget
: element这个流程的精妙之处:
第一步 ,enablePassThrough()。Page-Agent 在页面上有一个可视化的遮罩层(SimulatorMask),用来显示 Agent 的操作动画。但遮罩层会挡住 elementFromPoint------因为遮罩层永远在最上层。所以要先设置 pointerEvents: 'none' 让遮罩层「穿透」。
第二步 ,document.elementFromPoint(x, y)。这是浏览器原生 API,返回指定坐标处最深的那个元素。完美模拟了真实用户点击的行为。
第三步 ,安全检查。element.contains(hitTarget) ? hitTarget : element。如果命中测试返回了一个毫不相干的元素(比如一个浮动的 tooltip),它会安全地回退到原始元素。
还有一个细节:element.focus() 是在原始元素 上调用的,不是在命中测试的目标上。这匹配真实浏览器行为------点击一个 <label> 里的图标,焦点仍然会跑到对应的 <input> 上。
Page-Agent 用了一个极简的 lerp(线性插值)方案,每帧移动剩余距离的 20%:
typescript
#moveCursorToTarget() {
const newX = this.#currentCursorX +
(this.#targetCursorX - this.#currentCursorX) * 0.2
const newY = this.#currentCursorY +
(this.#targetCursorY - this.#currentCursorY) * 0.2
// 距离小于 2px 时直接吸附,避免无限微调
if (Math.abs(newX - this.#targetCursorX) < 2) {
this.#currentCursorX = this.#targetCursorX
} else {
this.#currentCursorX = newX
}
this.#cursor.style.left = `${this.#currentCursorX}px`
this.#cursor.style.top = `${this.#currentCursorY}px`
requestAnimationFrame(() => this.#moveCursorToTarget())
}这招妙在哪?
0.2 的插值因子创造了一条指数衰减的缓动曲线------距离目标远的时候移动快,接近目标时逐渐减速。就像你用手去拿桌上的东西,手也是先快后慢的。
而且它比 CSS transition 更优雅:无论目标距离多远,运动的「感觉」都是一样的,因为缓动是基于比例的,不是基于绝对时间的。
< 2px 的吸附阈值避免了浮点数精度导致的无限微调问题------经典的「Zeno 悖论」式 bug。
点击动画的重启 trick
typescript
triggerClickAnimation() {
this.#cursor.classList.remove(cursorStyles.clicking)
void this.#cursor.offsetHeight // 强制 reflow 来重启动画
this.#cursor.classList.add(cursorStyles.clicking)
}void this.#cursor.offsetHeight 是一个经典的黑魔法:读取 offsetHeight 会触发浏览器的 layout 计算,从而强制一次 reflow。这个 reflow 会让浏览器「注意到」class 已经先移除再加上了,于是 CSS 动画会重新开始。
LLM 响应格式化器:五种畸形输入的「急诊室」
问题
LLM 是出了名的「不按格式出牌」。即使你给了明确的 JSON schema,它有时也会:
- 直接把工具名作为最外层 key
- 把 JSON 藏在字符串里(双序列化)
- 把 JSON 嵌在自然语言文本中间
- 只返回反思字段,忘了返回 action
- 把原始值当成对象(
{"click_element_by_index": 2}而不是{"click_element_by_index": {"index": 2}})
解法
autoFixer.ts 是一个响应急诊室,专门救治各种畸形的 LLM 输出:
typescript
// Case 1: 模型直接返回工具名作为 key
// {"click_element_by_index": {"index": 2}}
// → 包装为 { action: {"click_element_by_index": {"index": 2}} }
// Case 2: JSON 藏在 message.content 里
// {"name": "AgentOutput", "arguments": "{...}"}
// → 解包到内部 arguments
// Case 3: 双层嵌套
// {"type": "function", "function": {"arguments": "{...}"}}
// → 解包到 arguments
// Case 4: 缺少 action 包装,原始工具对象
// {"click_element_by_index": 2}
// → 包装为 { action: {"click_element_by_index": 2} }
// Case 5: 完全缺失 action
// {"memory": "remembering stuff"}
// → 补上默认 action: { wait: { seconds: 1 } }还有两层额外处理:
双字符串参数修复:
typescript
// LLM 有时会把参数序列化成两次 JSON
if (typeof argString === 'string') {
try { argString = JSON.parse(argString) } catch {}
}原始值强制转换:
typescript
// {"click_element_by_index": 2} 需要转为 {"click_element_by_index": {"index": 2}}
// 方法:读取 Zod schema,找到第一个 required 字段,把原始值塞进去从散文里提取 JSON:
typescript
function retrieveJsonFromString(text: string): unknown | null {
// 用正则 ({[\s\S]*}) 匹配花括号包裹的内容
const match = text.match(/({[\s\S]*})/)
if (match) return JSON.parse(match[1])
}Page-Agent 浏览器操作机制分析
整体架构:跨上下文
MultiPageAgent (扩展页面/sidepanel)
│
├── TabsController ──── chrome.runtime.sendMessage ──→ Background ──→ chrome.tabs.* API
│
└── RemotePageController ── chrome.runtime.sendMessage ──→ Background ──→ chrome.tabs.sendMessage
↓
Content Script
↓
PageController (真实 DOM 操作)核心设计原则:实际 DOM 操作只在 Content Script 中执行,Agent 侧通过消息传递代理调用。
1. DOM 提取:页面状态读取
每步循环调用 pageController.getBrowserState(),内部流程:
updateTree()
│
├─ ① 临时禁用遮罩 (pointerEvents='none')
├─ ② 清除上次高亮标记
├─ ③ dom.getFlatTree() 重建 DOM 树
├─ ④ dom.flatTreeToString() 生成 LLM 可读文本
├─ ⑤ 重建 selectorMap (index → HTMLElement)
└─ ⑥ 重建 elementTextMap (index → 描述文本)交互式元素识别 (isInteractiveElement) 多层检测:
| 层级 | 检测方式 |
|---|---|
| 1 | 黑名单/白名单过滤 |
| 2 | 鼠标光标样式(25 种:pointer, text, grab 等) |
| 3 | 原生 HTML 标签(a, button, input, select, textarea 等) |
| 4 | ARIA 角色(button, tab, switch, combobox 等) |
| 5 | contenteditable 属性 |
| 6 | 类名启发式(.button, .dropdown-toggle, [data-toggle="dropdown"]) |
| 7 | 事件监听器检测(getEventListeners() 或 onclick 属性) |
| 8 | 可滚动容器(检查 overflowX/Y + scroll 尺寸) |
生成的简化 HTML 格式:
[0]<a aria-label=首页 />
[1]<div >P />
[5]<a role=button>快速开始 />2. 点击操作:W3C 指针事件序列
actions.ts 中 clickElement(element) 模拟完整点击流程:
1. blur 上次聚焦元素
→ pointerout → pointerleave → mouseout → mouseleave → .blur()
2. 滚动到可视区域
→ scrollIntoViewIfNeeded() / scrollIntoView({block: 'center'})
3. 移动虚拟指针
→ CustomEvent('PageAgent::MovePointerTo') → 视觉光标动画
4. 命中测试 (hit-test)
→ document.elementFromPoint(x, y) 找到最深层元素
5. 完整事件序列:
pointerover → pointerenter → mouseover → mouseenter
pointerdown → mousedown
element.focus({preventScroll: true})
pointerup → mouseup
target.click() ← 触发默认行为(导航/提交等)
6. 等待 200ms 让动画/状态变化生效3. 文本输入:三种输入方式适配
inputTextElement(element, text) 针对不同元素类型:
| 元素类型 | 实现方式 |
|---|---|
<input> / <textarea> |
getNativeValueSetter() 绕过 React 合成值追踪 → element.value = text → dispatch input 事件 |
contenteditable Plan A |
dispatch beforeinput 事件 → 直接设置 element.innerText(适用于 React/Quill) |
contenteditable Plan B |
document.execCommand('delete') + execCommand('insertText')(Slate.js 等富文本编辑器 fallback) |
<select> |
selectElement.value = option.value → dispatch change 事件 |
4. 滚动操作
scrollVertically() / scrollHorizontally():
指定元素 index:
→ 向上遍历 DOM 树(最多 10 层祖先)
→ 检查 overflowY/X CSS + scrollHeight vs clientHeight
→ 直接设置 scrollTop / scrollLeft
页面级滚动(无元素 index):
→ 从 document.activeElement 向上找可滚动祖先
→ fallback: querySelectorAll('*') 扫描
→ 最终: window.scrollBy()5. 消息传递协议
Agent → Content Script 消息格式:
typescript
{
type: 'PAGE_CONTROL',
action: string, // 'click_element', 'input_text', 'scroll'...
targetTabId: number, // 目标标签页 ID
payload?: any[] // 操作参数
}路由流程:
RemotePageController.clickElement(5)
→ sendMessage({ type: 'PAGE_CONTROL', action: 'click_element', targetTabId, payload: [5] })
→ Background: handlePageControlMessage()
→ chrome.tabs.sendMessage(targetTabId, message)
→ Content Script: PageController.clickElement(5)遮罩层协调 :Content Script 每 500ms 轮询 chrome.storage.local:
isAgentRunning:Agent 是否运行中agentHeartbeat:时间戳(每 1000ms 更新)currentTabId:Agent 当前操作的标签页
6. 标签页管理 (TabsController)
init(task)
├─ 获取当前活动标签页
├─ 创建标签页组 `PageAgent(<task>)`
└─ 连接事件流: chrome.runtime.connect('tab-events')
openNewTab(url)
├─ chrome.tabs.create() → 新标签页
├─ 加入标签页组
├─ 切换到新标签页
└─ waitUntilTabLoaded()
switchToTab(tabId)
├─ 验证 tabId 在追踪列表中
└─ 更新 currentTabId (本地 + storage)
closeTab(tabId)
├─ 不能关闭初始标签页
└─ 关闭后自动切换到最后一个剩余标签页
summarizeTabs()
└─ 返回 Markdown 表格,显示在 browser_state 头部给 LLM与 Agent 循环的协调:
onBeforeTask:初始化 TabsController + 心跳onBeforeStep:waitUntilTabLoaded()确保标签页加载完成onAfterTask:停止心跳
7. 视觉反馈系统
Content Script 中 SimulatorMask 监听 CustomEvent 实现:
| 事件 | 效果 |
|---|---|
PageAgent::MovePointerTo |
平滑插值动画移动光标(damping 0.2) |
PageAgent::ClickPointer |
显示点击动画 |
PageAgent::EnablePassThrough |
遮罩穿透(允许用户交互) |
PageAgent::DisablePassThrough |
遮罩拦截(Agent 独占控制) |
同时生成高亮标记框(可选),显示数字标签对应简化 HTML 中的 [index]。
总结:一个 Agent 是怎么「活」起来的
读完 Page-Agent 的源码,我最大的感受是:好的 Agent 代码不是「调个 API 就完了」,而是把 LLM 的不可靠性当做一等公民来设计。
你看这些设计:
- LLM 返回的格式不一定对?加一个急诊室级别的格式化器
- LLM 容易忘记之前做了什么?强制它每一步都写反思
- LLM 可能无限等待?累计等待时间超过 3 秒就警告
- LLM 重试时容易犯同样的错?把温度调到 0.7
- 不同 LLM 行为不同?给每个模型家族开小灶
- 网络可能抖动?自动重试 2 次
- 认证可能失效?立即放弃,不浪费时间
每一个设计点都指向同一个哲学:LLM 是一个不可靠的协作者,你需要为它的每个可能的失败模式准备一条路。
这不是一个 LLM 的「客户端」,这是一个 LLM 的「监护人」。
而浏览器操作那一层------绕过 React 的值追踪、双计划 contenteditable、命中测试找最深元素、多点采样检查遮挡------每一个都是在跟真实世界的混乱作斗争。网页不是标准测试页面,它们充满了框架、覆盖层、自定义事件、废弃 API。Agent 要能在这种环境下存活,代码必须比 LLM 的 prompt 更聪明。
Page-Agent 的源码告诉我们:做一个好用的浏览器 AI Agent,LLM 只占一半的功夫,剩下的一半在于------你怎么把 LLM 的「想法」安全、可靠、优雅地变成页面上的真实操作。
这,才是真正有趣的部分。